MirrorGANとは
先月(2019年3月)に発表された、GANを使ったテキストから画像を生成する(text to image)研究の論文です。現在、CVPR2019にも承認されているようです。
MirrorGANの本家論文
実装したコードはこちらです!

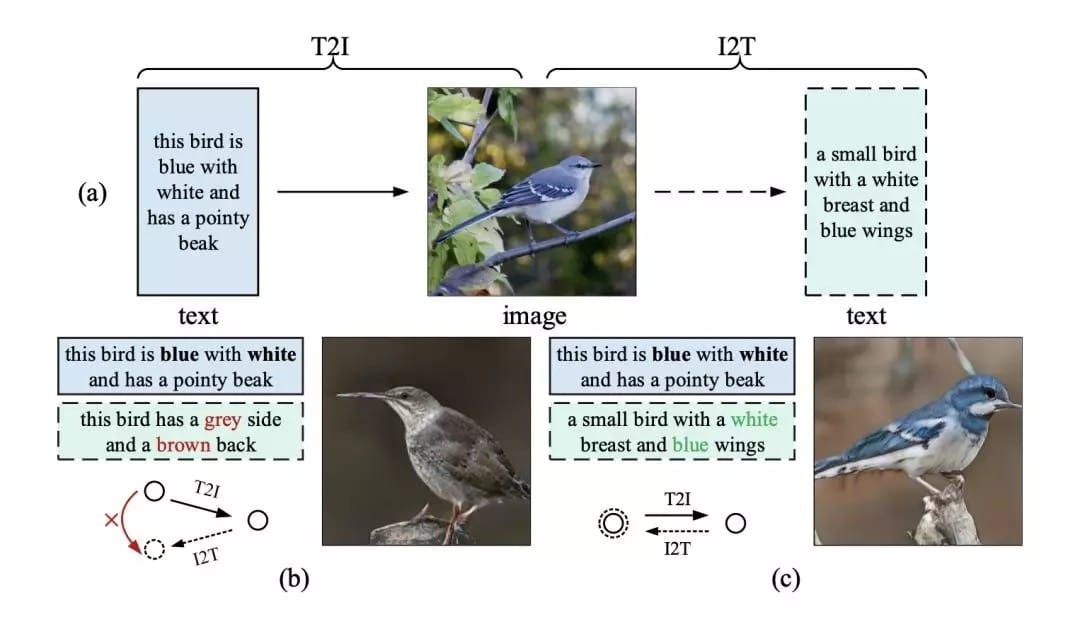
インプットのテキストと生成された画像
ミラー構造
MirrorGANはT2I(text to image)とI2T(image to text)の両方を統合することによってミラー構造となっています。
文章からGANで画像を出力し、それを元に文章を再生成することでT2I生成を学ぶという仕組みです。
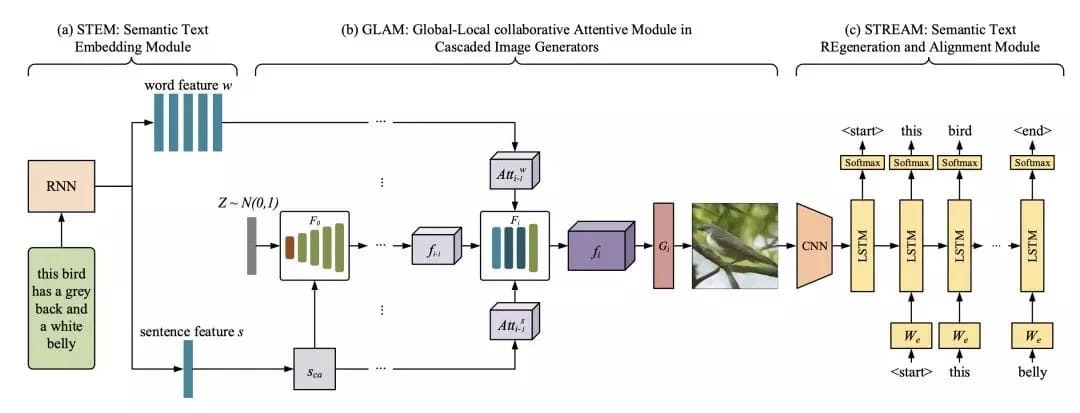
MirrorGANの3つのコアモジュールの構造
MirrorGANは、「テキストから画像への再記述学習生成」という3つのモジュールからなリます。
・ セマンティックテキスト埋め込みモジュール(STEM)
・ カスケード画像生成グローバル - ローカル共同注意モジュール(GLAM)
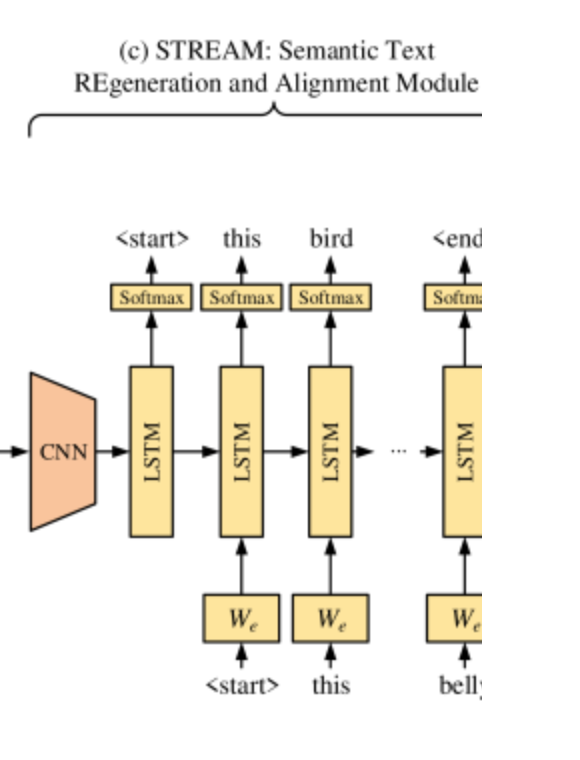
・ セマンティックテキストの再生成および整列モジュール(STREAM)
セマンティックテキスト埋め込みモジュール STEM
Embedding(埋め込み)を行い、RNNを通しています。
RNNの$h_t$(つまりシーケンスごとの出力)がword_feature_w(ワードごとの特徴)。
最終の出力がsentence_feature_s(文章全体の特徴)となります。
今回の実装では、Embeddingレイヤーと双方向GRUを使用しました。

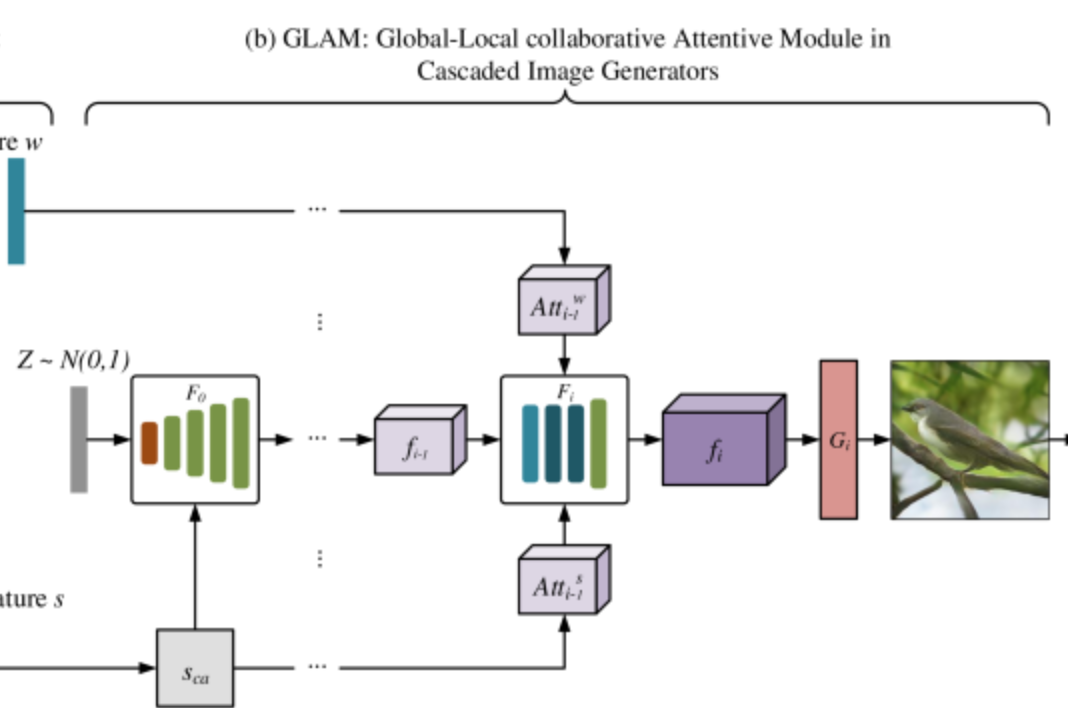
カスケード画像生成グローバル - ローカル共同注意モジュール GLAM
ここがGANで画像生成する部分になります。
図ではわかりにくいのですが、実はGANが3層構造になっています。
Generator=$G_i$
$G_0$で64x64サイズの$f_0$を出力→$G_1$で128x128サイズの$f_1$を出力→$G_2$で256x256サイズの画像を出力という形です。各Gに対応するDiscriminatorもそれぞれ3つ存在しています。
これはいきなり256x256のサイズでトレーニングしてもうまくいかないからです。$G_0$だけでまずトレーニングを始めることになるので階層になっています。
まず、sentence_feature_s(文章全体の特徴)をconditioning augmentationします。
テキストのエンコードは非線形の変換となるため、Generatorへの入力となる潜在変数は偏りが生じることがわかっていて、この問題を解決するために、conditioning augmentationを行なっています。
conditioning augmentationすることで多様性を維持することができ、少ない入力テキスト表現から幅広い分布を生成することができるようです。詳しくはStackGANの論文をみてみてください。

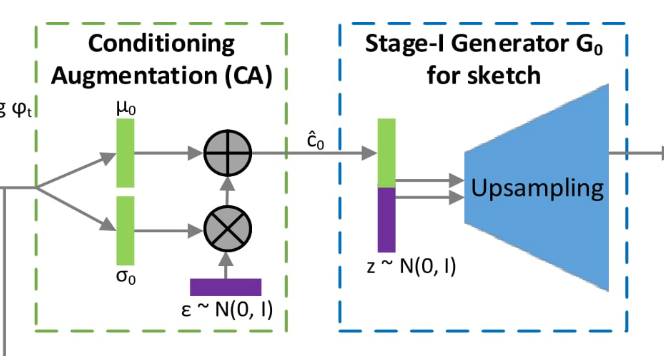 conditioning augmentationの実装。
conditioning augmentationの実装。

そして$Sca$と$Z$をconcatします。これが最初のGenerater($G_0$)の入力になります。
$I_i$は出力された画像。
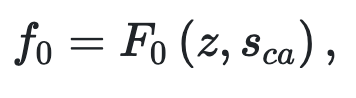
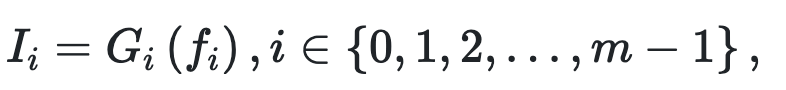
Attention
Source-Target-Attentionで
word_feture_wと$Sca$の情報を前のGeneratorからの出力である$f_{i-1}$とconcatします。
concat後の特徴マップが$f_i$となります。
${Target}$が$f_{i-1}$ ${Source}$がword_feture_w もしくは $Sca$ です。
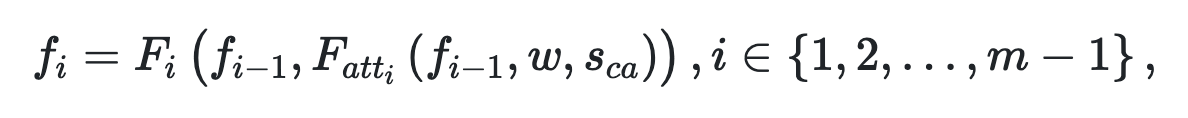


セマンティックテキストの再生成および整列モジュール(STREAM)
CNNはInceptionV3をimagenetの重みを凍結して使用します。
実装ではCNNの出力(global_averege_pooliingまで)とembeddingを通したテキストデータをシーケンス方向にconcatしました。
論文でSTREAMを事前にトレーニングしないとうまくいかないと書かれていましたので、
2日ほどpretrainingしています。
 実装。Gの出力サイズがそれぞれ違うため、まず入力画像に対して、
Lambdaレイヤーとtf.image.resize_imagesを使ってInceptionV3の標準入力である299x299にサイズ変更をかけています。
実装。Gの出力サイズがそれぞれ違うため、まず入力画像に対して、
Lambdaレイヤーとtf.image.resize_imagesを使ってInceptionV3の標準入力である299x299にサイズ変更をかけています。

損失関数
左の項普通のGのロス
右の項 sをIに加えている
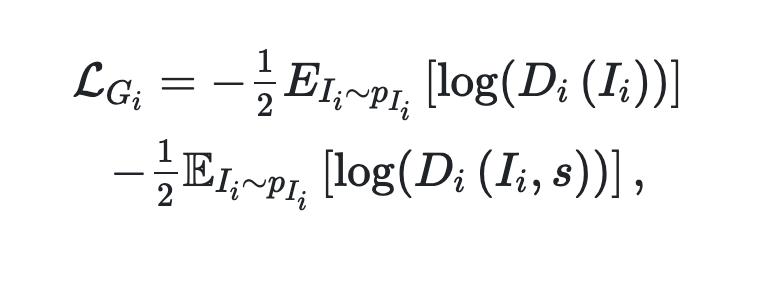
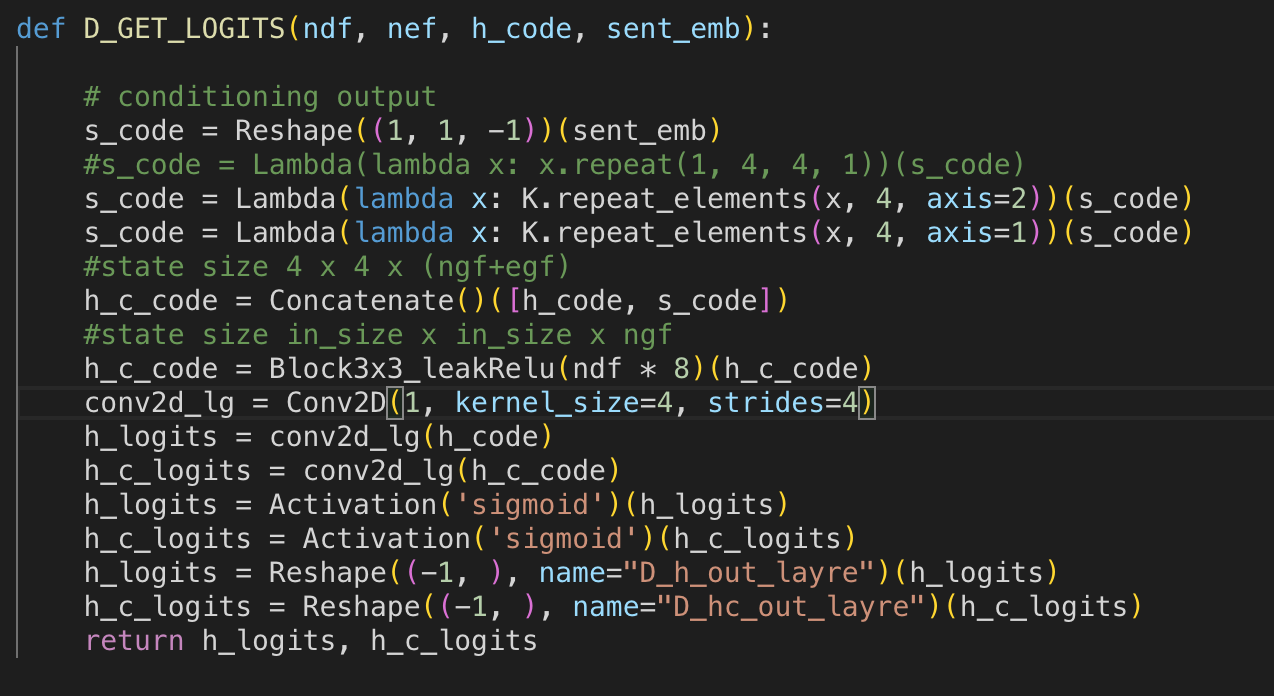
実装。I (h_code)のshapeが(batch x 4 x 4 x c), s(sent_emb)のshapeが(batch x c)
Iとsのshapeが合わないため、Reshapeで軸を増やした後にrepeat_elementsでテンソルをコピーして合わせています。
streamのロス 普通のカテゴリカルクロスエントロピー
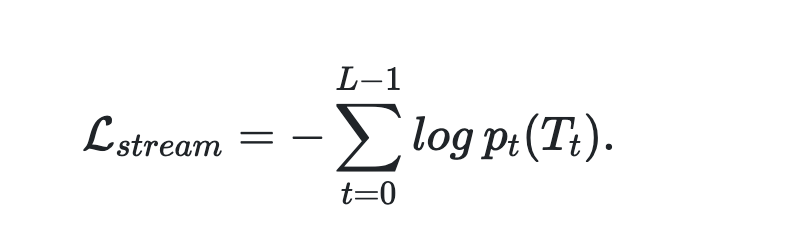
Gの統合されたloss
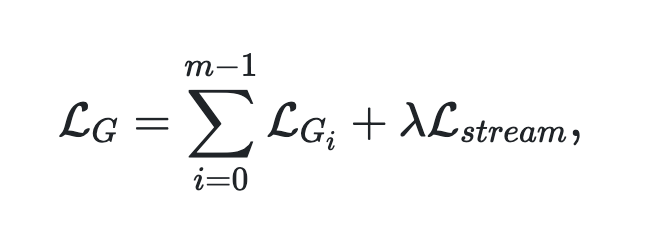
Dのloss
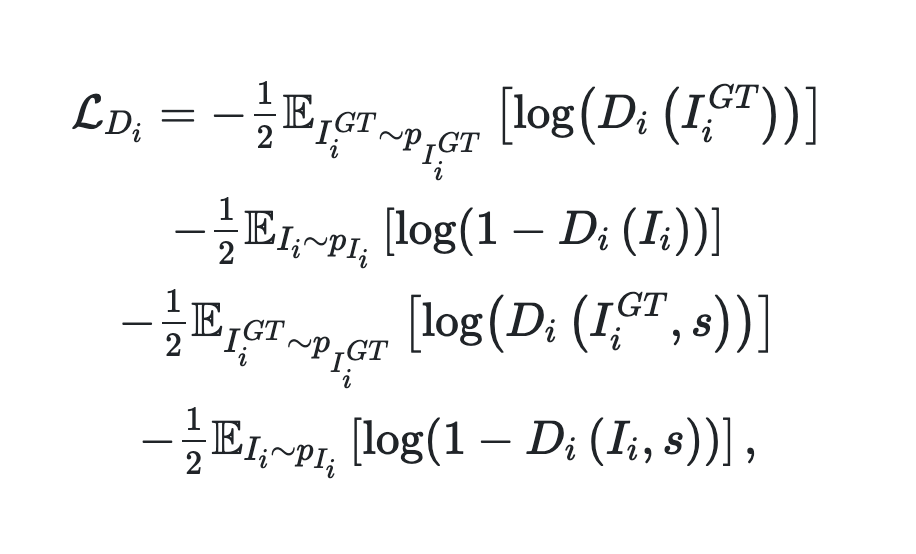
途中経過
鳥っぽい何かが出力されています。まだまだトレーニングが足りなそうですね。
現在64x64サイズでトレーニング中です。
