本記事は、サムザップ Advent Calendar 2021 の12/10の記事です。
はじめに
この記事では、表題の通り億単位のレコード数のテーブルを含むDBをAWSのDMS(Database Migration Service)を使ってデータ移行する検証をしていた際に、時間が掛かり過ぎることが分かったので、それを解消するためにやったことを記載したいと思います。
普段はあまり使うことのないサービスだと思いますが、お引越し(オンプレ->クラウドやクラウドA->クラウドB)するときだけでなく、運用が長くなり、DBサーバーを統廃合するようなシチュエーションでも役に立つサービスだと思います。
弊社ではスマートフォン向けのゲームを数々運用してきましたが、運用が長くなり、ユーザーデータは増え続ける一方、アクセス数がピーク程ではななくなってきたサービス等において、DBサーバーを統廃合する際に重宝しています。
普段使わないだけに、いざやろうと思うと色々分からないことや躓きポイントがあったり、今回のように想定していた時間内にデータ移行が終わらない!!となって、困ることもあると思います。
少しでもそんな方々のお役に立てれば嬉しいです。
要約
データ移行時間を短縮するためにやったこと、その他各種Tipsを記載
- タスクを分割する
- 特定のテーブルを別タスクに切り出す
- 更にそのタスクをfilterを使って分割する
用語
本記事では、基本的にDMSを利用したことがある方、利用しようとしてある程度ドキュメントを読んでいる方を対象としていますが、一応基本的なワードだけ簡単に説明します。
DMS
データベースを AWS に迅速かつ安全に移行するためのサービス
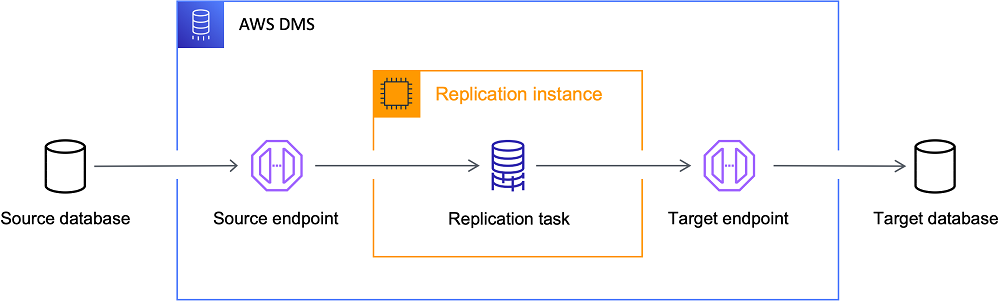
引用元:https://docs.aws.amazon.com/ja_jp/dms/latest/userguide/Welcome.html
タスク
データ移行の単位であり、それらの処理が行うもの・場所
AnAWSDatabase Migration Service (AWS DMS) タスクは、すべての処理が行われる場所です。ログ記録要件、制御テーブルデータ、エラー処理など、移行と特別な処理に使用するテーブル(またはビュー)とスキーマを指定します。
引用元:https://docs.aws.amazon.com/ja_jp/dms/latest/userguide/CHAP_Tasks.html
テーブルマッピング
ソースフィルター
ミッション
今回のミッションは、水平分割用に用意されたAuroraクラスターをメンテナンス時間10時間以内に半分にすること。
メンテナンス中にはその他作業もあるため、データ移行に当てられる時間は正味4時間くらい。
環境
- Aurora MySQL
- エンジンバージョン:5.7.mysql_aurora.2系
経緯
とあるプロジェクトにおいて、DBサーバーの統廃合が遡上に登り、事前に実行時間を計測したところ、約6時間掛かることが分かりました。
メンテナンス時間を考慮すると、4時間以内に抑えたかったため、再度DBサーバー及びレプリケーションインスタンスをスケールアップし、4時間程度で完了できることを確認しました。
その後しばらくして運用中の各種施策のスケジュールを加味し、メンテナンス日時が確定し、改めてデータ移行を実施してみると…
6時間経っても終わらない!!状態になっていました。。
ということで、急ぎデータ移行時間を短縮する必要に迫られました。
確認したこと
多くはAWS様のドキュメントにまとまっており、そちらを参考にさせていただきました。
移行タスクの実行が遅くなる最も一般的な原因は、AWS DMSレプリケーションインスタンス。インスタンスのリソースが実行中のタスクのために十分であることを確認するには、レプリケーションのインスタンスの CPU、メモリ、スワップファイル、および IOPS の使用率をチェックします。
しかしいずれのリソースを確認しても特に問題があるように見えませんでした。
実施したこと
そこで社内の他プロジェクトの方に相談し、どうやらタスクを分割すると速くなるという助言をもらいました。
元々は1DBスキーマ:1タスクという基本的な設定でしたが、これをテーブル単位に分割し、テーブルAはタスク1、テーブルBはタスク2…のような形(テーブルマッピング)にしました。
更にタスクのテーブル統計を確認したところ、レコード数が多い、もしくはデータ量の大きい一部のテーブルが突出して時間が掛かっていることが分かったため、ソースフィルターを使って1000万レコードずつ別タスクに分割しました。
1DBスキーマ1タスクのルール
例1:
Testスキーマ配下の全テーブルを対象とする場合
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "Test",
"table-name": "%"
},
"rule-action": "include"
}
]
}
テーブル毎にタスクを分割したルール
例2-1:
Testスキーマ配下のtestテーブルのみを対象とする場合
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "Test",
"table-name": "test"
},
"rule-action": "include"
}
]
}
例2-2:
Testスキーマ配下のtestテーブル以外のテーブルを対象とする場合
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "Test",
"table-name": "%"
},
"rule-action": "include"
},
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "Test",
"table-name": "test"
},
"rule-action": "exclude"
}
]
}
ソースフィルターで更にテーブルを分割した図
例3:
Testスキーマ配下のtestテーブル、かつid列の値が1〜10,000,000のレコードを対象とする場合
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "Test",
"table-name": "test"
},
"rule-action": "include",
"filters": [{
"filter-type": "source",
"column-name": "id",
"filter-conditions": [{
"filter-operator": "between",
"value": "",
"start-value": "1",
"end-value": "10000000"
}]
}]
}
]
}
※例えば3億レコードあれば、start-valueとend-valueを変えて、30タスクの定義が必要
結果、データ移行自体は約2時間半程度で完了できるようになりました。
と、ここまでが今回の対応の主な内容となっています。
以下ここに到達するまでに試行錯誤した際のTIPSを記載します。
その他のTIPSや試したこと(試そうと思ったこと)
timezoneに気をつける
mysqlのtimestamp型は、システム変数time_zoneの影響を受けるため、ソースエンドポイント側のextra connection attributesにserverTimezone=Asia/Tokyo;を設定しないと、データ移行した際に-9時間でデータが生成されてしまいました。
※逆にターゲットエンドポイント側に設定しても良いかも!?
ワイルドカード
タスクのルールの定義内のobject-locator内のtable-nameは、状況によってワイルドカード(%)が使えたり、使えなかったりするので注意。
rule-typeがselectionで、かつrule-actionがincludeもしくはexcludeの場合は、ワイルドカードが使えると記載があり、実際使えるのですが、filters(ソースフィルタ)を指定した場合は使えないので注意。
タスクの起動数について
タスクを多数に分割した結果、一度にタスクを起動すると、そもそもタスクが起動できず、失敗になるケースもありました。
再実行で正常に実行できましたが、エラー処理タスクの設定によっても挙動が変わると思いますので、同時起動するタスク数を調整した方が良いと思います。
同様にリソースを限界まで有効に使おうと、インスタンスタイプを調整したのですが、ある程度余裕がないと、途中でタスクが進捗しなくなり、最終的に失敗するケースがありました。
インスタンスタイプを変更する場合は、各種メトリクスや各DBのprocessの実行状況を確認し、ある程度余裕をもったインスタンスを用意することをオススメします。
(検証してから、本番までの間にもデータ量が増えると思いますし)
MaxFullLoadSubTasks
DMSには、上記のように手動でタスクを分割しなくてもタスク設定のFullLoadSettings内にMaxFullLoadSubTasksという設定があり、こちらを増やせば速度が上がりそうと思いましたが、レプリケーションインスタンスのコア数の2倍に設定しても、同じに設定しても変わらなかったので、コア数に合わせました。
まとめ
AWS様のドキュメントにある通り、CPU、メモリ、スワップファイル、およびIOPSの使用率に問題がなく、スケールアップしてもデータ移行時間が短縮できない場合は、こちらで紹介したようにタスクを分割し、並列実行数を上げると劇的に速くなる場合があることが分かりました。
同じようにデータ移行の時間が長くて困っている方の一助となれば幸いです。
明日は @KoniroIris さんの記事です。