はじめに
「ChatGPTのような文章生成AIを自分でも作ってみたいけど、環境構築が大変そう...」
そう思ったことはありませんか?
実は、Hugging FaceのTransformersライブラリを使えば、たった数行のコードで実現できます。
近年、大規模言語モデル(LLM)が注目を集めていますが、実は数行のPythonコードで誰でも簡単に最先端のAIモデルを利用できる時代になっています。この記事では、Hugging FaceのTransformersライブラリを使って、実際に文章生成を体験してみます。
Hugging Face
Hugging Faceは、最先端のAIモデル(特に大規模言語モデル)を誰でも簡単に利用・共有できるオープンなプラットフォームです。ユーザーは自分のモデルやデータセットをアップロードしたり、他のユーザーが公開したものを検索・利用したりできます。特に自然言語処理分野において、開発者や研究者にとって欠かせないツールとなっています。
Transformers
Hugging Faceの代表的なライブラリがTransformersです。このライブラリを使うことで、学習済みモデルの利用・微調整が簡単にでき、テキスト分類、質問応答、テキスト生成などの自然言語処理タスクを手軽に実行できます。
参考:
実践1:まずは動かしてみる
最も簡単な使い方: pipeline で使用
Transformersの最も簡単な利用方法はpipeline()関数の利用です。
まずは文章生成をさせるコードを作成してみます。
from transformers import pipeline
# パイプラインの作成 タスクとモデルを指定
pipe = pipeline(
"text-generation",
model="gpt2",
)
# テキスト生成の実行
result = pipe(
"The first thing I do when I wake up is",
max_new_tokens=50,
temperature=0.7
)
print(result)
解説①:パイプラインの作成
pipeline()の呼び出し時に実行するタスク種別と使用するモデル種を指定します。
# パイプラインの作成 タスクとモデルを指定
pipe = pipeline(
"text-generation", # 文章生成
model="gpt2",
)
解説②:テキスト生成の実行
プロンプトを与えることで、後続に続く文章を生成してくれます。
今回はThe first thing I do when I wake up is (朝起きて最初にやることは…)としてみました。
生成結果を制御するパラメータを指定することができます。
今回はmax_new_tokens(生成するトークン数) とtemperature(テキスト生成時のランダム性)を指定しています。
temperature = 0.7 とすることで適度にランダム性をもって出力されます
※ temperature の詳細については今後深堀りする予定です
# テキスト生成の実行
result = pipe(
"The first thing I do when I wake up is",
max_new_tokens=50, # 生成するトークン数を指定
temperature=0.7 # テキスト生成時のランダム性
)
print(result)
出力結果(複数回実施)
# 1回目
[{'generated_text': "The first thing I do when I wake up is open the door of my room and open the door. I feel like I'm about to fall down, and when I do, I don't want to get up, because the door is gonna catch me and I just wanna go straight to my room"}]
(訳)目が覚めたらまず最初に、部屋のドアを開けて、ドアを開ける。倒れそうなんだ、倒れたら起き上がらないでいたい、だってドアが私を受け止めてくれるから、ただ自分の部屋に直行したいだけなんだ
# 2回目
[{'generated_text': 'The first thing I do when I wake up is to take a few naps. It\'s very relaxing."\n\nI was just a kid and the internet was like, "What the hell is this?" I started to think about it from the point of view of my husband. It felt like'}]
(訳)目が覚めたらまず最初に、少し昼寝をするんだ。すごくリラックスできるんだ。私はまだ子供で、インターネットは「一体全体これは何だ?」って感じだった。夫の視点から考え始めたんだ。それはまるで
# 3回目
[{'generated_text': "The first thing I do when I wake up is call my wife and tell her about my wife. That really makes me feel good. I wish I knew how to do that. I don't know if she's really going to know how to read or write. Maybe she's going to say something"}]
(訳)目が覚めたらまず妻に電話して、妻のことを話すんだ。それが本当に気持ちいいんだよ。私もそうできたらなあ。彼女が本当に読み書きできるかどうかはわからない。たぶん何か言うだろうけど
翻訳はDeepL翻訳を使用しました。
3回とも異なる生成結果が得られました。
一応意味は通っているようですが、かなり文語的?な表現かなと感じました。
(補足) pipelineで実行できるタスク
pipelineで指定できるタスクは他にも様々あり、"sentiment-analysis"(感情分析)、"zero-shot-classification"(ゼロショット分析)、"fill-mask"(空所穴埋め)などが実行できます。
Huggingfaceの公式ハンズオンが分かりやすかったです。
読みながら手元で動かすことで理解が進みました。
https://huggingface.co/learn/llm-course/ja/chapter1/3
Hugging Faceでのモデル検索
Hugging Faceの Model Hub を使うことでオープンソースモデルを検索して利用することができます。
実際に使ってみたところ、前提知識がなくてもかなり直感的に使用することができました。
Hugging Face の画面からヘッダー「Models」をクリックすることでモデルの一覧画面が表示されます。
https://huggingface.co/models
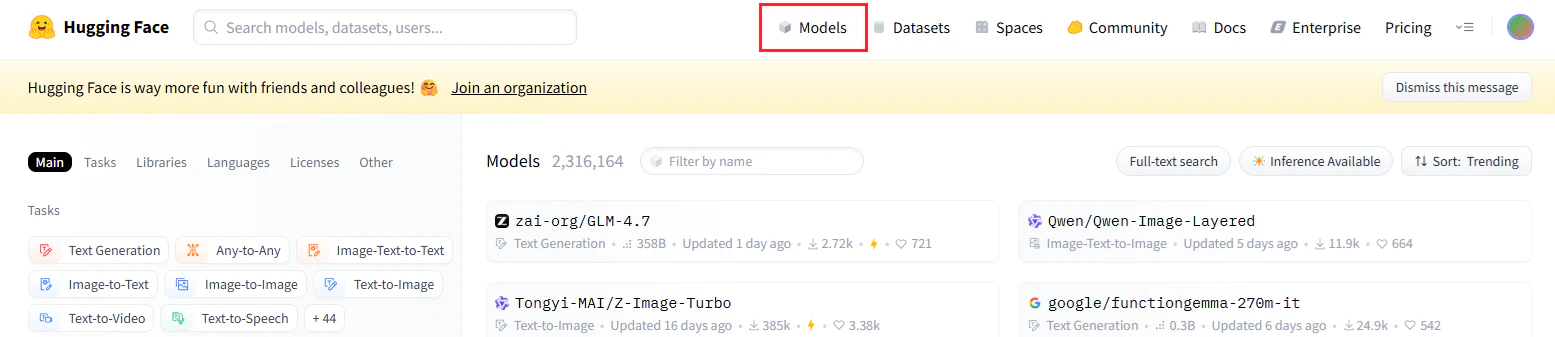
モデルを検索する
左側のタブから条件を設定することで対応するモデルを簡単に検索できます。
タスク

対応言語
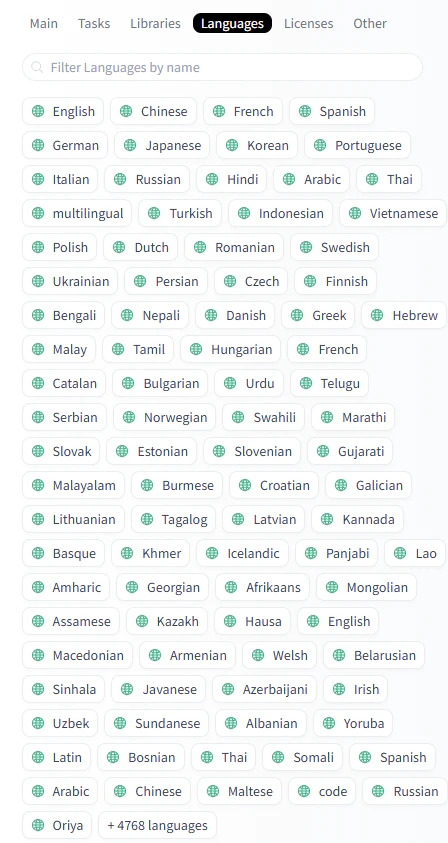
文章生成(Text Generation) × 対応言語(日本語:Japanese) のような条件の組み合わせでも検索が可能です。
モデルを選択する
試しにQwen/Qwen3-0.6Bのページを確認してみます。
https://huggingface.co/Qwen/Qwen3-0.6B
実際のモデルの利用方法を確認したい場合は、右上の「Use This Model」から「Transformers」を選択します。
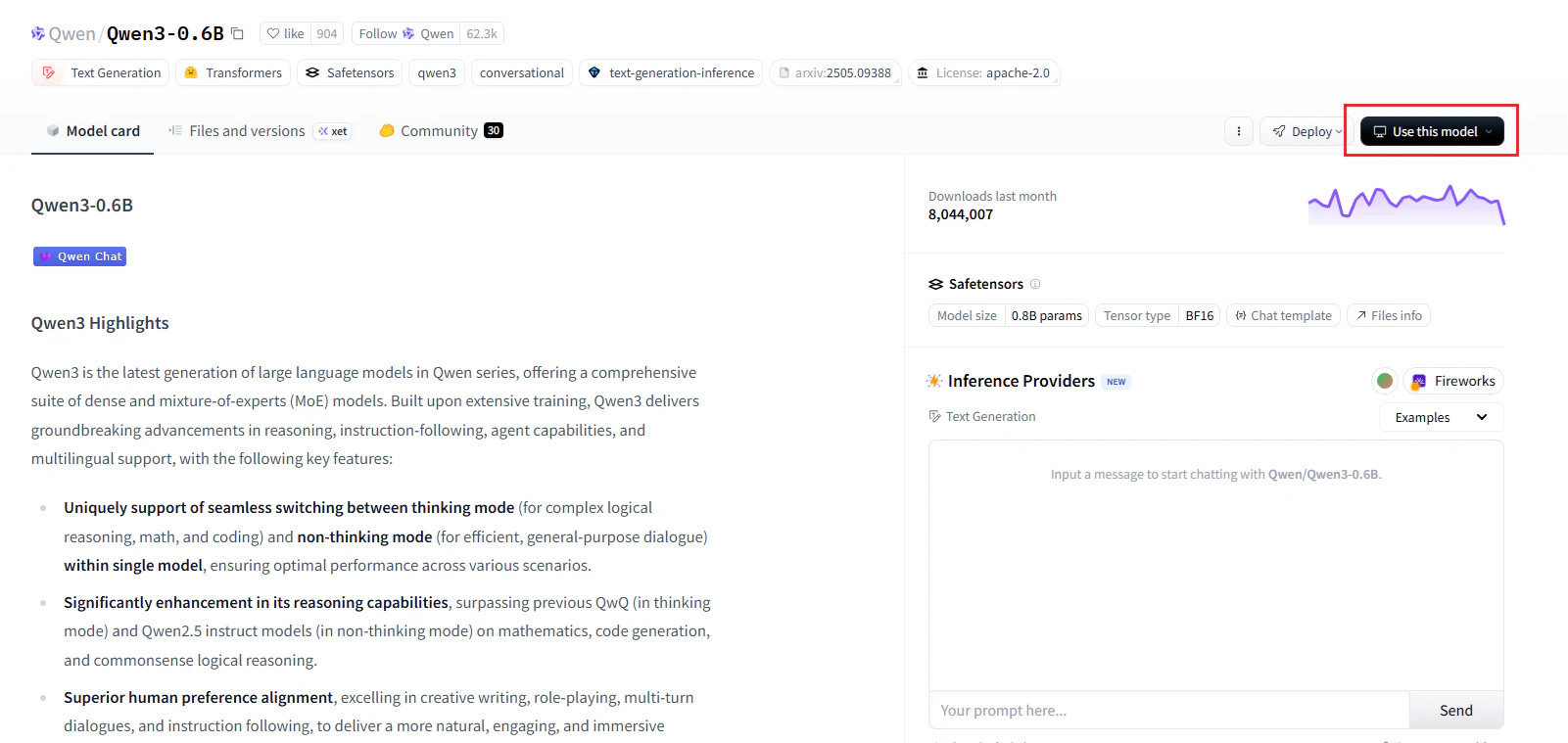
Transformersライブラリでの該当モデルの使用方法が記載されているので、そのまま使用することができます!

実践2:モデルを変えてみる
先ほどgpt2を使用したコードを、使用するモデルのみQwen/Qwen3-0.6Bに変更してみます。
モデル変更後のコード
実際に使用するモデルを変更する場合はmodelの指定を変更するだけです。
初回実行時に必要なモデルがダウンロードされます。
from transformers import pipeline
# パイプラインの作成 タスクとモデルを指定
pipe = pipeline(
"text-generation",
model="Qwen/Qwen3-0.6B", ## 使用するモデルを変更
)
# テキスト生成の実行
result = pipe(
"The first thing I do when I wake up is",
max_new_tokens=50,
temperature=0.7
)
print(result)
実行結果
1回目
[{'generated_text': "The first thing I do when I wake up is to make sure I have a good breakfast. It's important for me to have a good breakfast, and I know that it's the first thing I do when I wake up. So, what is the best breakfast I can eat?\n\nI need to"}]
(訳)目が覚めたらまず最初に、しっかりとした朝食をとるようにしています。朝食をしっかり摂ることは私にとって重要で、それが目覚めて最初に行うことだとわかっています。では、私が食べるべき最高の朝食とは何でしょうか?私は必要です
2回目
[{'generated_text': "The first thing I do when I wake up is to take a look at my phone. It's always been my first thing to do, and I'm pretty much a morning person. But now, I realize that I have to be more careful about how I use my phone. I know that I"}]
(訳)目が覚めたらまず最初にスマホをチェックする。昔からそうしてきたし、私はどちらかというと朝型人間だ。でも今は、スマホの使い方に気をつけなきゃいけないと気づいている。私は知っている、自分が
3回目
[{'generated_text': "The first thing I do when I wake up is to take a deep breath and check my phone. I don't want to miss anything important. I want to be ready for whatever happens to happen. I check my phone because it's the only way I can see the world. I know that it"}]
(訳)目が覚めたらまず深呼吸をしてスマホを確認する。大切なことを見逃したくない。どんなことが起きても対応できるように準備しておきたい。スマホをチェックするのは、それが世界で起きていることを見る唯一の方法だからだ。わかっているんだ、それが
どうでしょうか?gpt2を使用した場合より、より実用的で自然な文章になっているかなと感じました。
Transformersを利用することで、使用するモデルを変更・比較したい場合も1行の変更で対応できます。
ポイント
- Hugging Faceが提供するTransformersモデルを使用することで、簡単に自然言語処理を実行できる。
- pipeline()関数を利用することで、様々なタスクを簡単に実行できる
- Model Hub からオープンソースのモデルを簡単に検索、利用できる。
- Transformersなら使用するモデルを簡単に差し替えられるので、モデル間の性能比較も容易。
次回
pipeline()関数を利用することで簡単に文章生成が再現できることが分かりました。
次回はpipeline()関数の裏側で起こっていることを解明し、文章生成プロセスを再現してみます。
作成コード
環境構築もこちら参照
https://github.com/abi-inami/Transformers-sample
翻訳ツール
参考