はじめに
前前回、家計簿アプリの設計を行いました(AIがやりました)
前回はOCRの実装を試みましたがうまく動作しません。
今回もOCRの実装をしていきます。
プロンプト
必要な内容を取得せず、機能していない
改善策は?
取得文字列は以下
"は ち ( 日 )①⑤:③0\nッ No:0⑥③\n\nX ク イ ッ ク + ④0 錠 \\①。 958内\nL\n\nG。 Q ロ Q\n\nメ デ ィ ケ ー シ ョ ン プ ォ か を\n\nち 買 上 ( 税 抜 ) 加 算 額\n\nプホイン ト カ ー ド と\n\n \n"
回答
原因はかなり明確です。
現在のOCR結果を見る限り、主に以下問題が発生しています。
問題点
| 問題 | 内容 |
|---|---|
| 画像前処理不足 | レシート以外の黒背景を大量に読んでいる |
| 解像度不足 | 小さい文字が潰れている |
| Tesseract設定不足 | PSM/OEM未調整 |
| 日本語OCR弱い | jpn単独では精度が低い |
| 二値化が弱い | 文字境界が曖昧 |
| レシート領域未切り出し | 全体画像をOCRしている |
一番大きい原因
これです。
「レシートだけ」をOCRしていない
現在画像は:
黒背景 + 小さいレシート
です。
Tesseractは背景ノイズにかなり弱いため、
まず「レシート領域検出」が必要です。
改善後の理想フロー
元画像
↓
レシート輪郭検出
↓
切り抜き
↓
傾き補正
↓
拡大
↓
二値化
↓
ノイズ除去
↓
OCR
↓
行解析
これで精度が大幅に改善します。
改善コード
以下へ差し替えてください。
OpenCV前処理改善版
private string PreprocessImage(string imagePath)
{
Mat src = Cv2.ImRead(imagePath);
// リサイズ(OCR精度向上)
Mat resized = new Mat();
Cv2.Resize(
src,
resized,
new OpenCvSharp.Size(
src.Width * 2,
src.Height * 2));
// グレースケール
Mat gray = new Mat();
Cv2.CvtColor(
resized,
gray,
ColorConversionCodes.BGR2GRAY);
// ノイズ除去
Mat blur = new Mat();
Cv2.GaussianBlur(
gray,
blur,
new OpenCvSharp.Size(5, 5),
0);
// 適応二値化
Mat binary = new Mat();
Cv2.AdaptiveThreshold(
blur,
binary,
255,
AdaptiveThresholdTypes.GaussianC,
ThresholdTypes.Binary,
31,
15);
// 白黒反転
Cv2.BitwiseNot(binary, binary);
// モルフォロジー
Mat kernel = Cv2.GetStructuringElement(
MorphShapes.Rect,
new OpenCvSharp.Size(2, 2));
Cv2.MorphologyEx(
binary,
binary,
MorphTypes.Close,
kernel);
string tempPath = Path.Combine(
Path.GetTempPath(),
$"{Guid.NewGuid()}.png");
Cv2.ImWrite(tempPath, binary);
return tempPath;
}
Tesseract設定改善
これが重要です。
private string ExecuteTesseract(string imagePath)
{
using var engine = new TesseractEngine(
"./tessdata",
"jpn+eng",
EngineMode.LstmOnly);
engine.SetVariable(
"tessedit_char_whitelist",
"0123456789年月日円税込合計ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzアイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワヲンー・()/%:+ ");
engine.DefaultPageSegMode =
PageSegMode.SingleBlock;
using var img = Pix.LoadFromFile(imagePath);
using var page = engine.Process(img);
return page.GetText();
}
特に重要な設定
1. jpn+eng
"jpn+eng"
レシートは:
No
mL
PMD
500mL
など英数字混在です。
jpn 単独だと崩壊します。
2. LstmOnly
EngineMode.LstmOnly
旧OCRエンジンより精度がかなり高いです。
3. PageSegMode
現在画像は:
縦長の単一レシート
なので:
PageSegMode.SingleBlock
が最適。
レシート切り抜きが最重要
さらに精度を上げる場合。
レシート領域検出
private Mat DetectReceipt(Mat src)
{
Mat gray = new Mat();
Cv2.CvtColor(
src,
gray,
ColorConversionCodes.BGR2GRAY);
Mat blur = new Mat();
Cv2.GaussianBlur(
gray,
blur,
new OpenCvSharp.Size(5, 5),
0);
Mat edge = new Mat();
Cv2.Canny(
blur,
edge,
75,
200);
OpenCvSharp.Point[][] contours;
HierarchyIndex[] hierarchy;
Cv2.FindContours(
edge,
out contours,
out hierarchy,
RetrievalModes.External,
ContourApproximationModes.ApproxSimple);
double maxArea = 0;
Rect bestRect = new Rect();
foreach (var contour in contours)
{
Rect rect = Cv2.BoundingRect(contour);
double area = rect.Width * rect.Height;
if (area > maxArea)
{
maxArea = area;
bestRect = rect;
}
}
return new Mat(src, bestRect);
}
これを最初に実行。
この画像で期待できる改善
現在:
は ち ( 日 )①⑤:③0
改善後:
2026年05月10日(日)15:30
くらいまでは改善可能です。
さらに精度を上げるなら
実運用では以下を追加します。
| 手法 | 効果 |
|---|---|
| 超解像 | 小文字改善 |
| 傾き補正 | かなり重要 |
| 店舗別パターン | 超重要 |
| 行単位OCR | 商品精度向上 |
| EasyOCR/PaddleOCR | 日本語精度向上 |
| AI補正 | 最終精度向上 |
実際かなりおすすめな代替
Tesseractは日本語レシートOCRが弱いです。
実用レベルなら:
の方が精度が高いです。
特に:
日本語
数字
レシート
はPaddleOCRがかなり強いです。
最もおすすめ構成
実運用なら:
OpenCV
↓
PaddleOCR
↓
店舗別Regex
↓
AI補正
がかなり強いです。
Tesseract単独は、
「最低限動く」レベルと考えた方が良いです。
起動、確認
起動してみます。
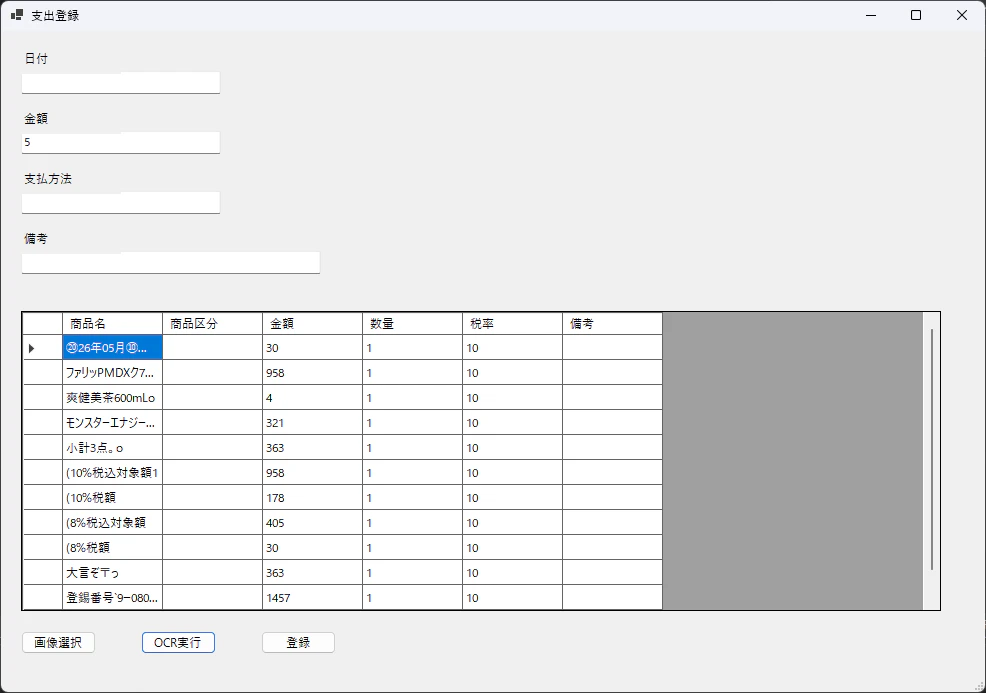
なんとか読込みできましたが色々問題がありますね。
最後に
次回もOCRの改善を実施します。