cvpr.challengeの活動でCVPR2019網羅的サーベイ報告会の物体検知についての発表を聴講しての私の受け取った内容を抜粋しました。大きな流れとトレンドを作っている最近までの重要論文を知ることができ、勉強になった。
物体検知(Object Detection)とは、コンピュータビジョンの中でも、画像中に「何」(複数の場合もあり)が「どこ」にあるというタスクの解決を目指します。(画像中で検出した領域へのBounding Boxという形で示すことが多い)
講演:物体検知メタサーベイ
- 発表者 東京電機大学/産総研 美濃口宗尊氏
物体検知手法の変遷Overview
物体検知手法の歴史(2001~2019年)は下の図のようになっている。
2000年代初頭にエポックメイキングな出来事として、デジカメに顔認識機能が実装された。それは、Viola-JonesによるHaar-like特徴 + Adaboostであった。しばらく、人が特徴量抽出アルゴリズムを頑張る時代が続き、HoG + SVM, Deformable Parts Model + Latent SVMなどのトレンドがあった。
2012年以降は、Deep Learningが勃興し、物体検知のタスクにおいてR-CNNの系譜の発展、高速化を目指したOne-shot Detectorの系譜(SSD, YOLO)の発展が続いた。
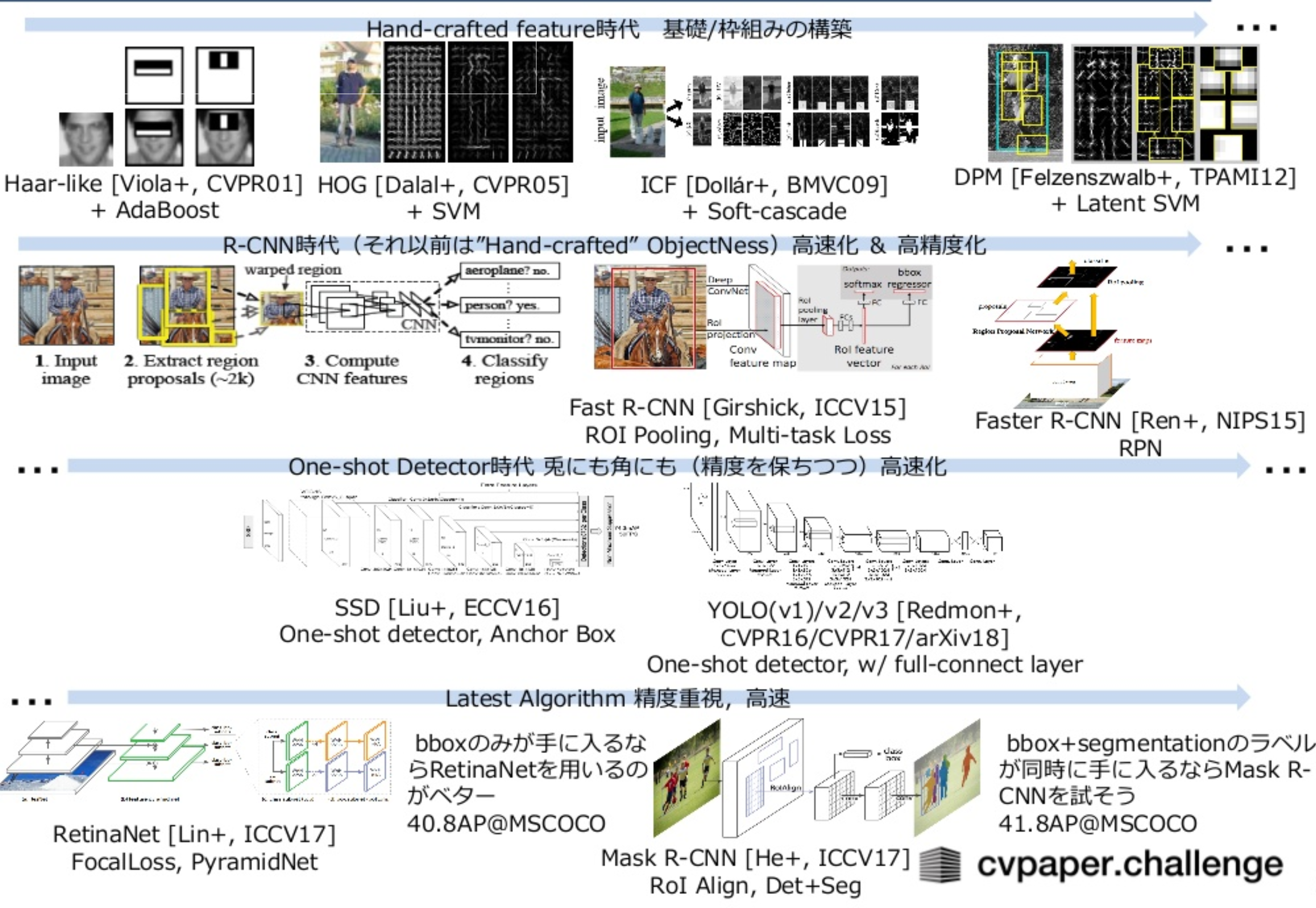
その後、高速化(≒リアルタイム)で高精度を目指した手法が提案されてきている。
Deep Learning時代の代表手法
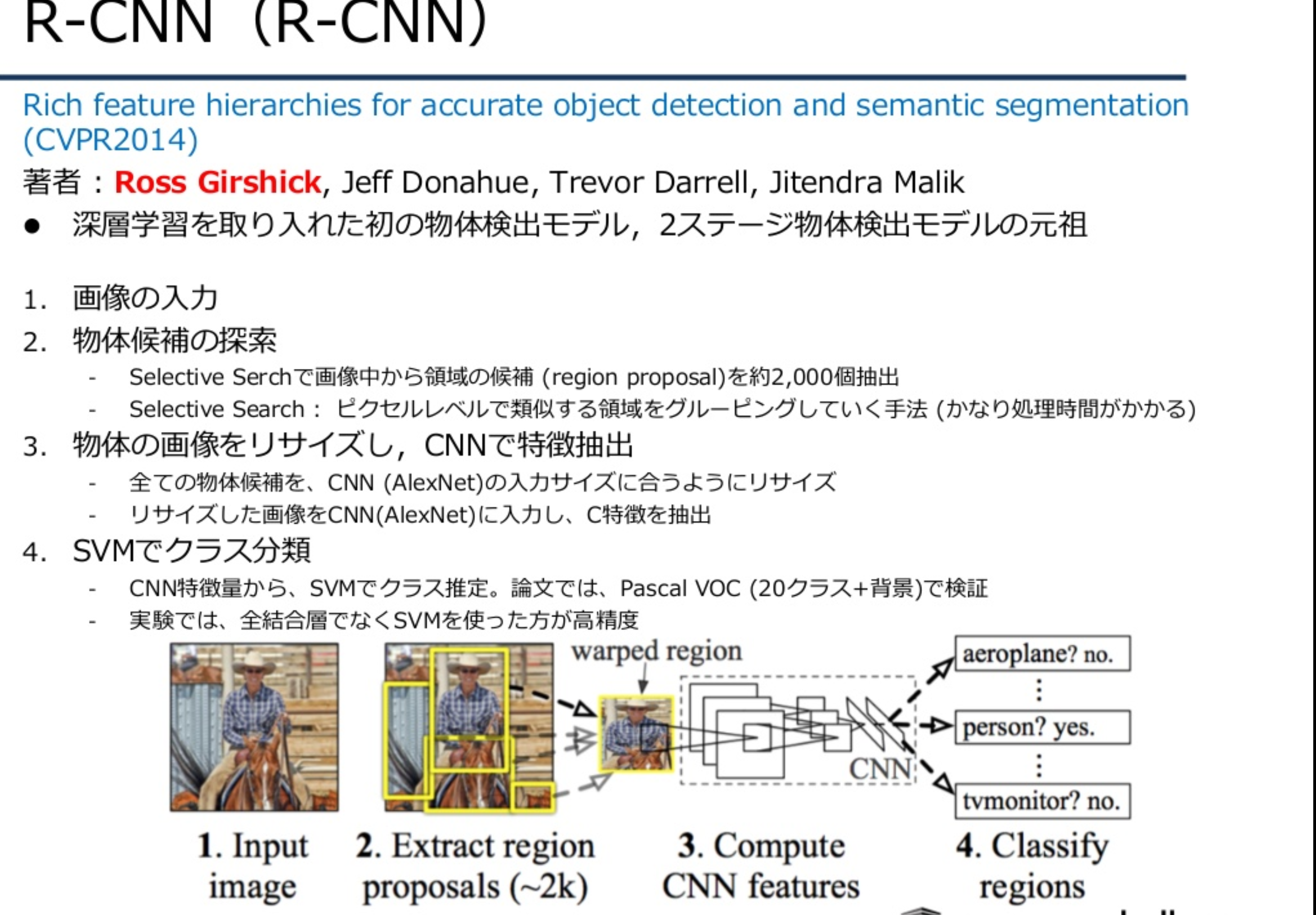
R-CNN
2ステージ構成 –「 Selective Searchで画像中から候補領域抽出」と「CNN(AlexNet)で特徴抽出+SVMでクラス分類」
Ross Girshick氏はR-CNN研究で毎回登場する重要人物。
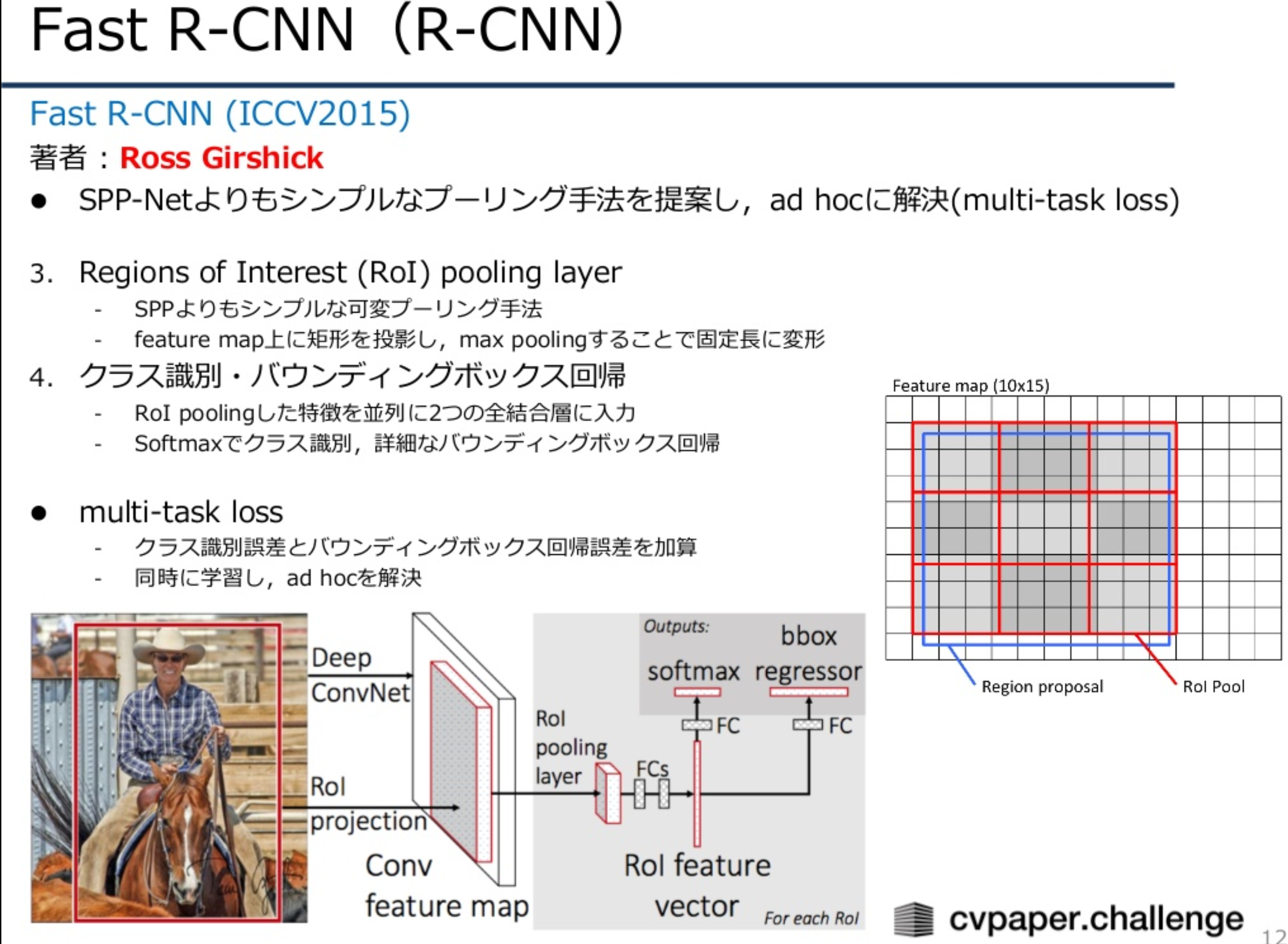
Fast R-CNN
CNNによるFeature map算出後、RoI pooling layerの導入、Feature map上に矩形を投影しmax poolingすることで固定等に変形。RoI pooling layerで得た特徴を2つの並列な処理に流す。OutputはSoftmaxでクラス識別、Bounding Box回帰で詳細な位置を得る。
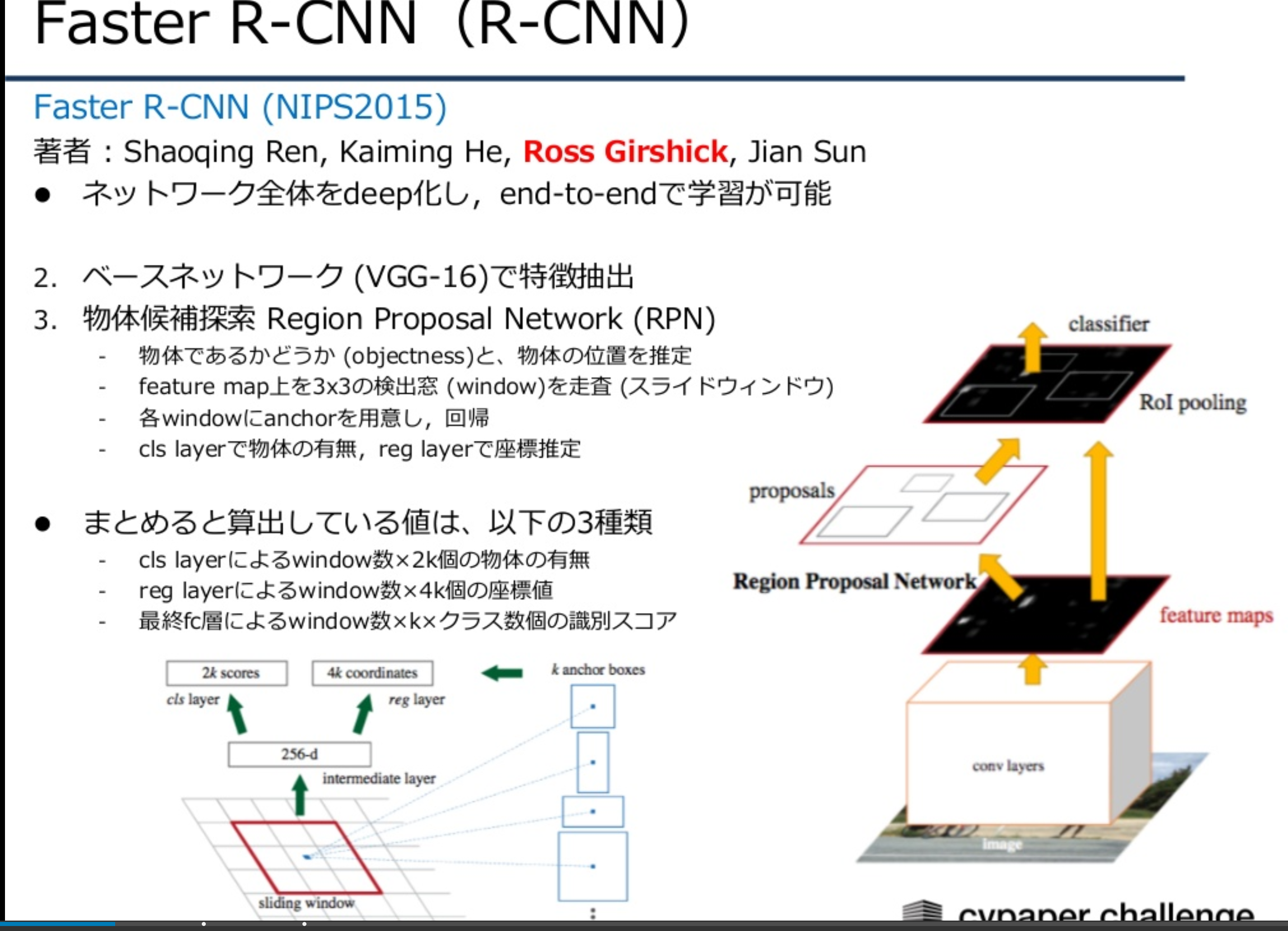
Faster R-CNN
Deep LearningによるEnd-to-Endの学習を実現。CNNによるFeature Map抽出後、Region Proposal Networkに加え、分類・回帰の結果を出力するネットワークで構成される。領域抽出に従来Selective Searchを使っていたがRegion Proposal Networkの導入で、精度・速度の向上を図った。
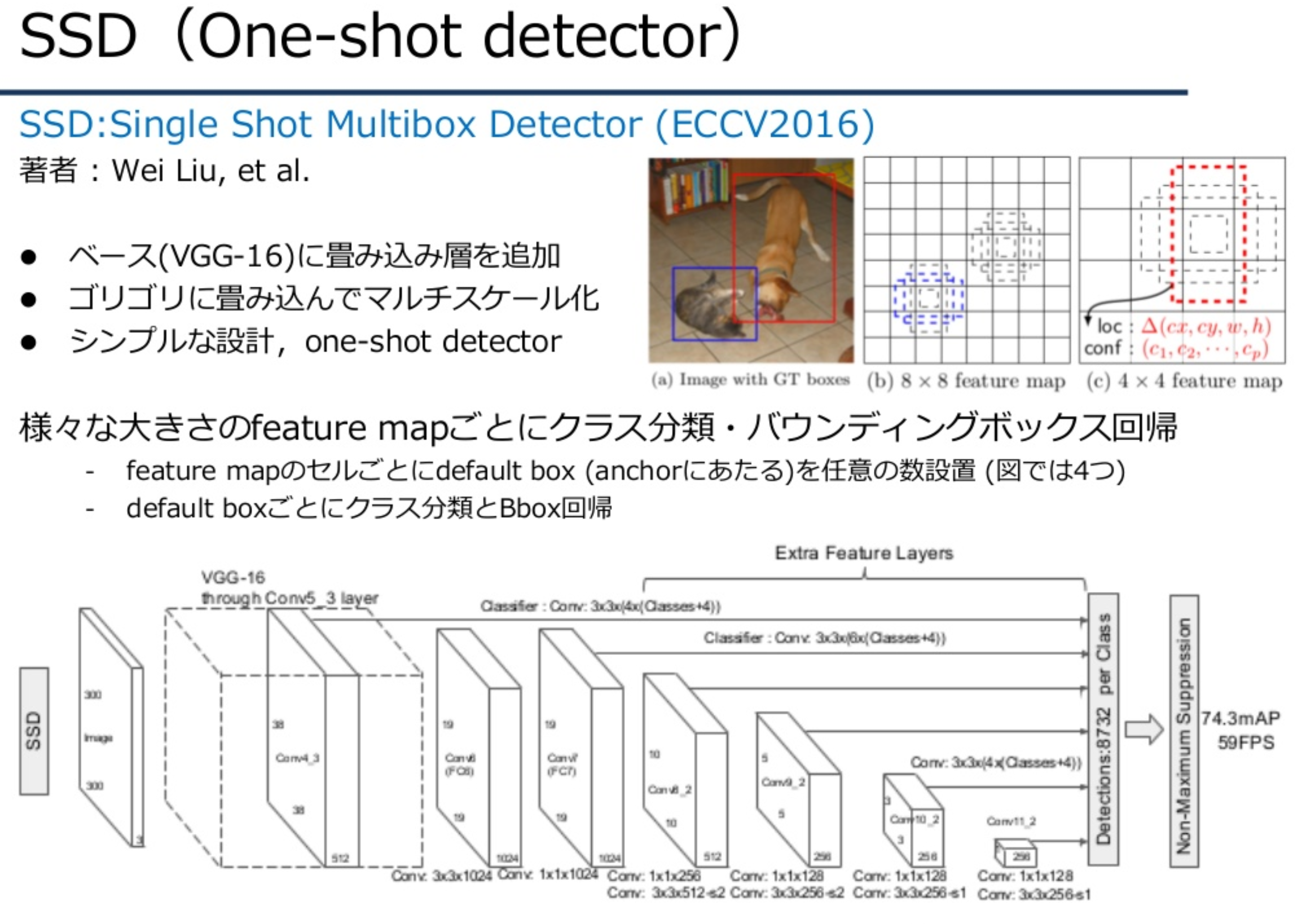
SSD
VGG-16に畳み込み層を追加する。マルチスケールに畳み込みを入れ、様々な大きさのFeature mapごとにクラス分類・Bounding Box回帰を行う。
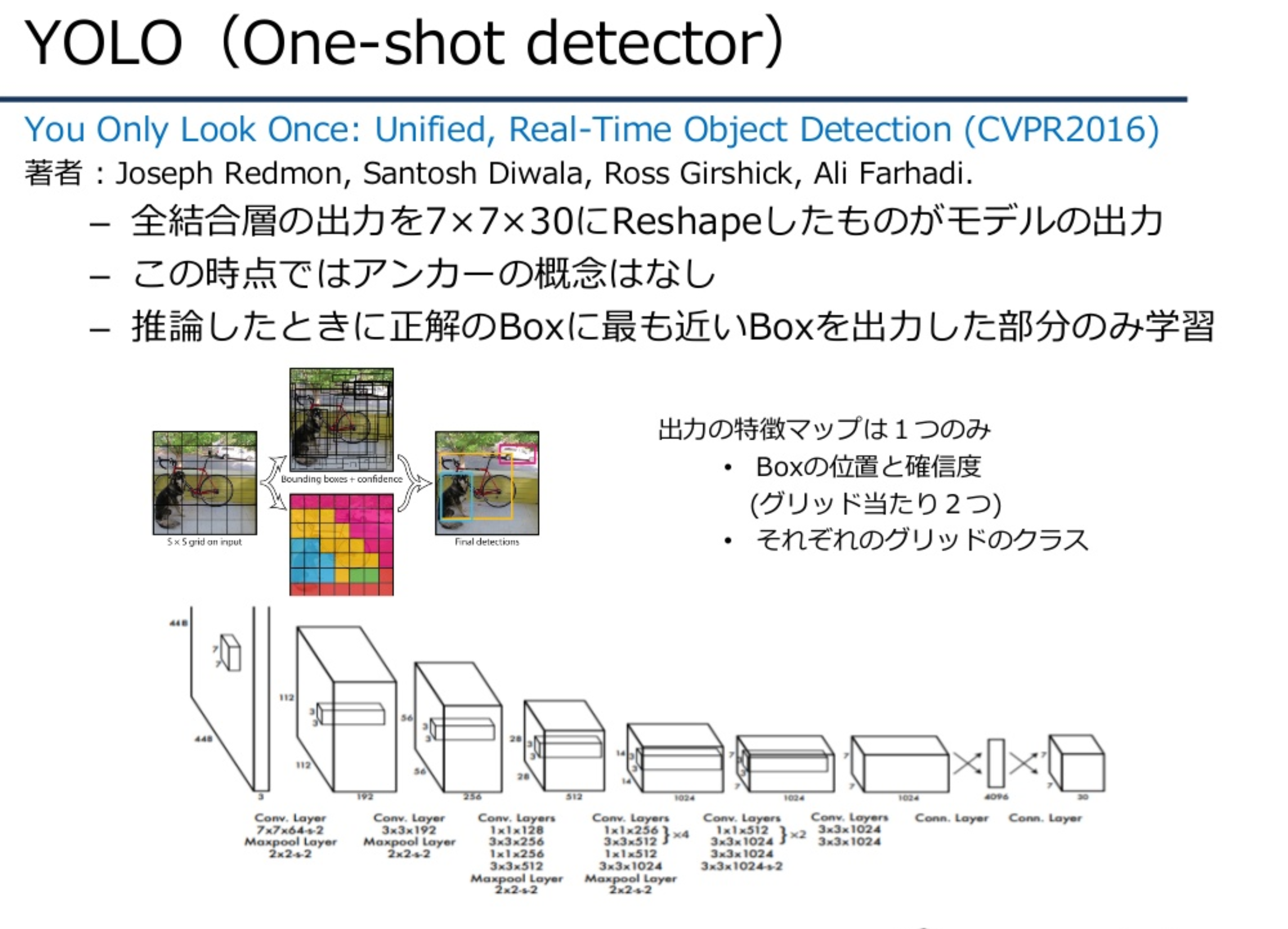
YOLO
単一のCNNネットワーク構造からなり、高速な検出が可能となる。画像をS x Sでグリッド分割し、各グリッドセルでB個のBouding boxと各Bouding boxの信頼度を推測する。
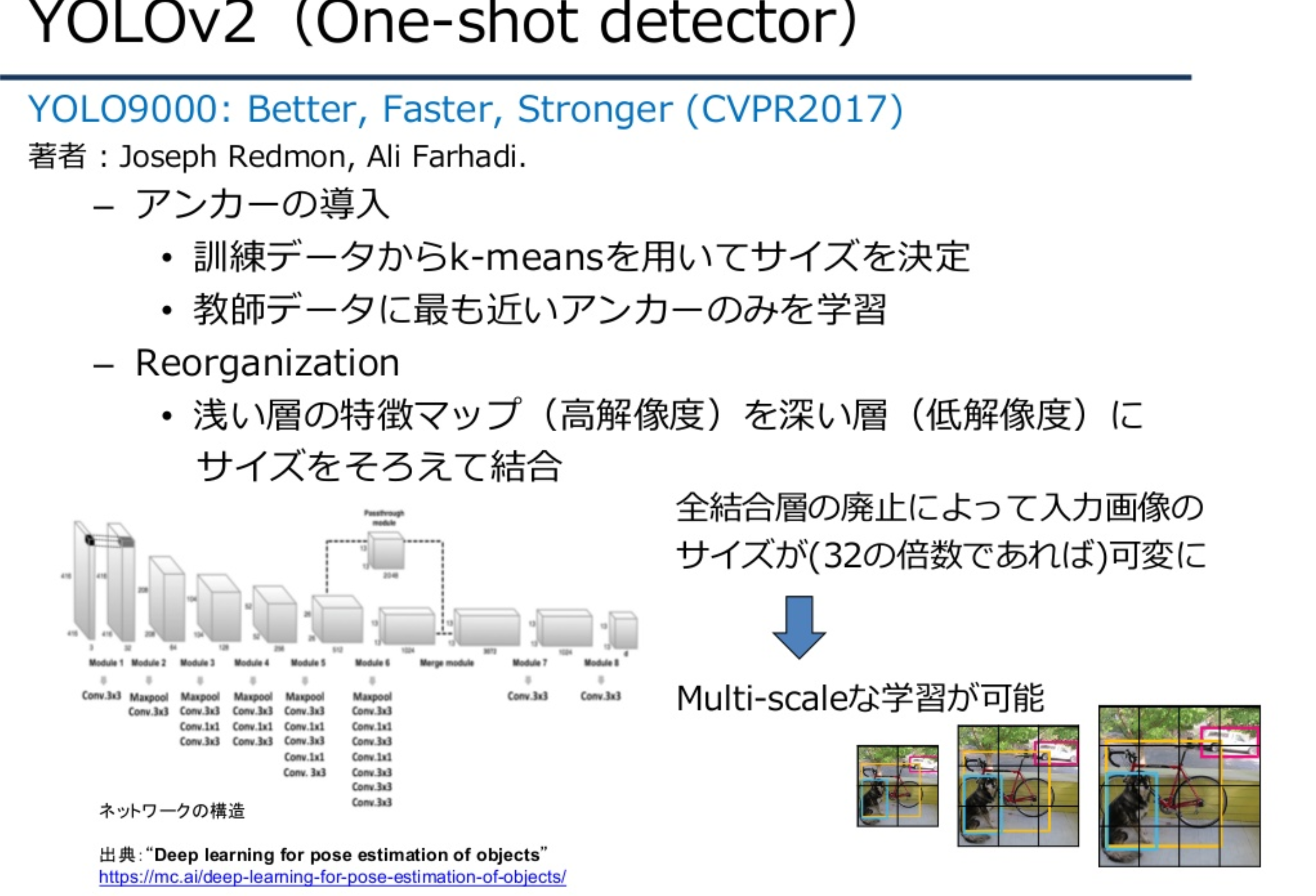
YOLO v2
初代YOLOに対して、以下のような改良点を加えることで精度、速度が向上している。

YOLO v3
ネットワークはv2より大規模になり、精度向上。

RetinaNet
SSD系で、クラス間のアンバランスにloss functionの工夫を入れている。
Residual構造を入れ、ネットワークをより深くし、Feature Pyramid Networkとする。

Mask R-CNN
Faster R-CNNと同様に2ステージ構造。ROI PoolingからROI Alignに変え、精度を向上する。
これは読むべきObject Detection in CVPR 2019
物体検知について、新たな注目の論文として紹介されたものです。
詳細は把握できていないので、スライドの転載のみさせてもらいます。



物体検知分野での有名な研究者、研究機関
Facebook AI Research(FAIR)
強い研究者が集結し、物体検知分野の研究を牽引する成果を挙げている。
Max Planck Institute for Informatics
歩行者検知で成果を出しています。網羅的な調査やアノテーション付け替え、地道なモデル改善など粘り強い研究には定評がある。
YOLOの著者 Joseph Redmon
強力なキャラクター + ユーモアある展示 + ネットを使った拡散戦略で毎回注目される。
発表資料へのリンク
https://www.slideshare.net/cvpaperchallenge/meta-study-group?from_action=save