JMVAEとは
一言でいうと,潜在空間上に2つのモダリティを埋め込むことができるモデル
グラフィカルモデルは下図のようになっており,例えばxを画像,yをラベルとすると情報の質が異なるがこれらの情報を同じ潜在空間上に埋め込むことができる

ロス関数は次のようになる.
LOSS = E_{q_\phi(z|x, y)}\left[\log p_\theta(x, y|z)\right] - KL(q_\phi(z|x, y)||p(z)) \\
- KL(q_\phi(z|x, y)||q_{\phi_x}(z|x)) - KL(q_\phi(z|x, y)||q_{\phi_y}(z|y))
一項目は再構成するための項で,各モダリティから潜在表現を獲得し,潜在表現から各モダリティに復元する.ここで,$p_\theta(x, y|z) = p_{\theta_x}(x|z)p_{\theta_y}(y|z)$である.
二項目は事後分布$q_\phi(z|x, y)$を事前分布$p(z)=N(0, I)$に近づける項である.普通のVAEのKL項の部分に対応する.
三項目,四項目は,事後分布$q_\phi(z|x, y)$を各モーダルからの事後分布に近づける項である.これにより,どちらかのモーダル情報が欠損していたとしても,潜在変数を推論することができる.
関連研究 (Generative Models of Visually Grounded Imagination)
JMVAE(suzuki+ 2017)の後にTELBO(Vedantam+ 2018)が提案されている.
この論文はJMVAEの後継とも言え,異なるのはロス関数の部分だけである.
LOSS =
E_{q_\phi(z|x, y)}\left[\log p_\theta(x, y|z)\right] - KL(q_\phi(z|x, y)||p(z)) \\ + E_{q_{\phi_x}(z|x)}\left[\log p_\theta(x|z)\right] - KL(q_{\phi_x}(z|x)||p(z)) \\
+ E_{q_{\phi_y}(z|y)}\left[\log p_\theta(y|z)\right] - KL(q_{\phi_w}(z|y)||p(z))
3つのELBOがあるのでTriple ELBOと呼ばれている
参考資料
- JMVAE(https://arxiv.org/abs/1611.01891)
- TELBO(https://openreview.net/forum?id=HkCsm6lRb)
- TELBOのわかりやすいスライド(https://www.slideshare.net/DeepLearningJP2016/dlgenerative-models-of-visually-grounded-imagination)
実験
データセット
二種類の属性をもったMNISTを作成した
上の説明において,画像がx,属性ラベルがyに対応する
- 位置 $y_1$: 左 or 右
- 数字 $y_2$: 1 or 2

データセットには,2(位置)x2(数字)の4種類のラベルが存在する
データ: (画像x, 属性ラベルy)
確率分布
エンコーダ: ガウス分布
- $q_\phi(z|x, y)$
- $q_{\phi_x}(z|x)$
- $q_{\phi_{y1}}(z|y_1)$
- $q_{\phi_{y2}}(z|y_2)$
ただし,$y=(y_1, y_2)$
また,Product of Expert(Hinton, 2002)より,$q_{\phi_y}(z|y) = p(z)q_{\phi_{y1}}(z|y_1)q_{\phi_{y2}}(z|y_2)$を使う
デコーダ: ベルヌーイ分布
- $p_{\theta_x}(x|z)$
- $p_{\theta_y}(y|z)$
ただし,$p_\theta(x, y|z) = p_{\theta_x}(x|z)p_{\theta_y}(y|z)$
実験結果
y1,y2からzを推論し,zからxを生成する
まず,両方のラベルを与えて画像を生成する.図の上のタイトルは与えたラベル

最下段二番目は生成ミスしている.これは,yからzを推論する分布とxからzを推論する分布が完全には一致しないことが原因だと考えられる.すなわち,q(z|y)はガウス分布と仮定しているが,すべてのxのデータに対応するzの分布はガウス分布にはならない(後で可視化を行う).
y1からzを推論し,zからxを生成する
次に位置のラベルを与えて,画像を生成する.
例えば上二段は左というラベルを与えているだけなので,1と2両方の数字が現れるのが面白い

最下段二番目は生成ミス
y2からzを推論し,zからxを生成する
次に数字のラベルを与えて,画像を生成する.

y1,y2からzを推論し,可視化
zは二次元なので可視化可能
ガウス分布を仮定しているため,ガウス分布の散布図となる.

y1からzを推論し,可視化
片方のラベルしか指定していないため,上図よりもより広いガウス分布となっていることがわかる
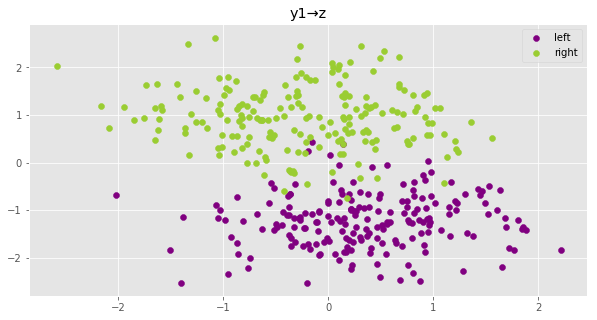
y2からzを推論し,可視化

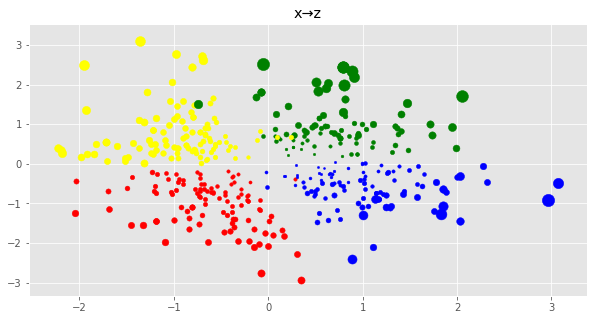
xからzを推論し,可視化
テストデータxを使ってzを推論する.点の大きさは分散の大きさに対応している
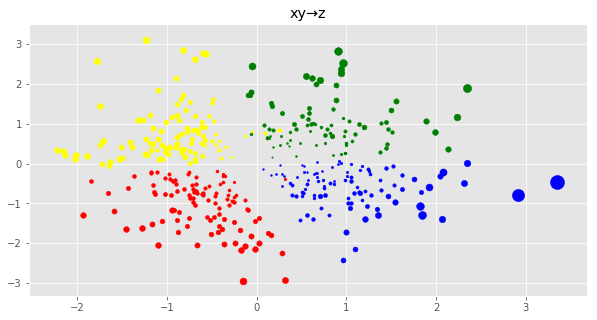
x,yからzを推論し,可視化
テストデータx,yを使ってzを推論する.点の大きさは分散の大きさに対応している
上図よりも分散が小さくなっていて,クラスの境界も広いことがわかる.
これはxとy両方の情報を使って推論しているからだと考えられる
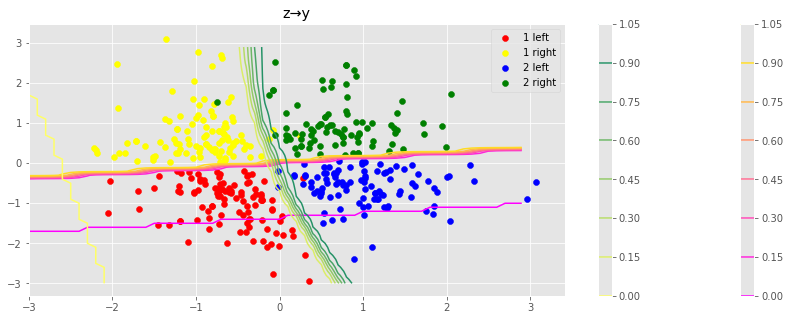
zからyを生成する
zを与えればそれぞれのラベルが変化する境界線も求められる
散布図はテストデータであり,うまくわけられていることがわかる
zからxを生成する
対応する潜在変数zから画像xを生成する
zは各軸で-3~3の値を使った


pixyzを使った実装紹介
pixyzとは深層生成モデルを簡単に書くことができるライブラリである.
可視化も含めたすべての実装はここにあげた.
実装参考
実装
Network Architecture
長いのでmodels.pyにまとめた
Distribution
必要な確率分布を準備する.
上で作ったモデルをインスタンス化する.
z_dim = 2
loc = torch.tensor(0.).to(device)
scale = torch.tensor(1.).to(device)
prior = Normal(loc=loc, scale=scale, var=["z"], dim=z_dim, name="p_prior")
# encoder
q_y1 = Encoder_Y1().to(device)
q_y2 = Encoder_Y2().to(device)
q_y = ProductOfNormal([q_y1, q_y2])
q = Encoder_XY().to(device)
q_x = Encoder_X().to(device)
# decoder
p_x = Decoder_X().to(device)
p_y1 = Decoder_Y1().to(device)
p_y2 = Decoder_Y2().to(device)
p = p_x * p_y1 * p_y2
Loss + model
$$
E_{q_\phi(z|x, y)}\left[\log p_\theta(x, y|z)\right] - KL(q_\phi(z|x, y)||p(z)) - KL(q_\phi(z|x, y)||p(z|x)) - KL(q_\phi(z|x, y)||p(z|y))
$$
from pixyz.losses import KullbackLeibler, CrossEntropy
kl = KullbackLeibler(q, prior)
kl_x = KullbackLeibler(q, q_x)
kl_y = KullbackLeibler(q, q_y)
regularizer = kl + kl_x + kl_y
model = VAE(q, p, other_distributions=[q_x, q_y],
regularizer=regularizer, optimizer=optim.Adam, optimizer_params={"lr":1e-3})
for i in range(10):
for batch_idx, (x, y) in tqdm(enumerate(train_loader)):
x = x.to(device)
y = label2onehot(y)
y = y.to(device)
loss = model.train({"x": x, "y1": y[:, :1], "y2": y[:, 1:]})