はじめに
Google Cloud Firestoreについて調べていたところ公式Youtubeの説明が一番詳しかったので翻訳しつつまとめてみました。
今回はデータベースの構造についてのみの記事です。
執筆:2021年5月2日
基本的なデータ構造
まずはCloud Firestoreの基本的なデータ構造について説明します。
元の動画はこちら
Firestoreではまずコレクションがあり、その中にドキュメントを複数持つことができます。
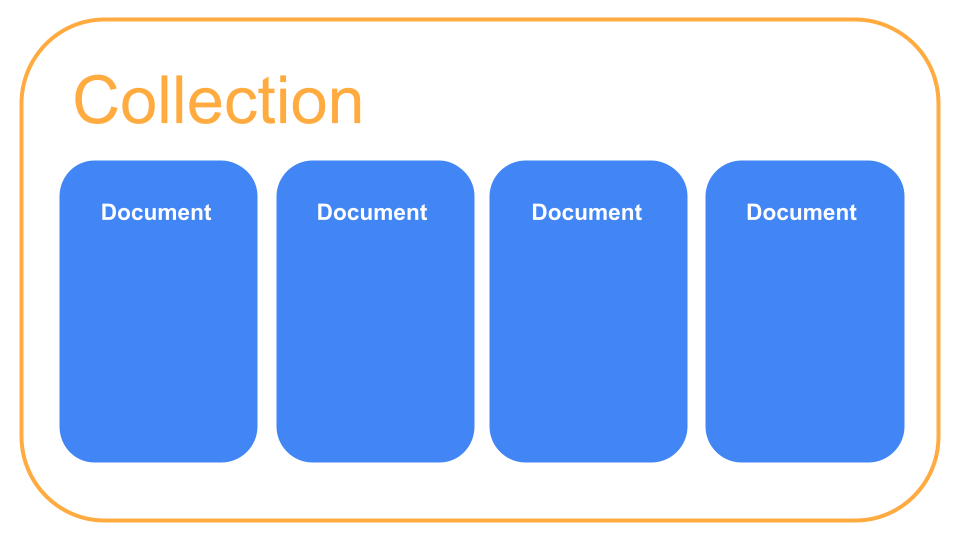
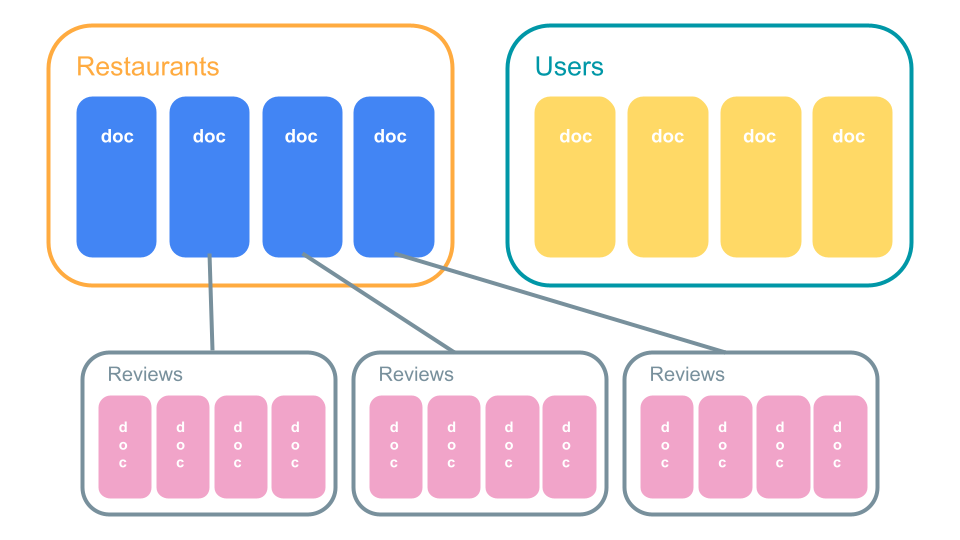
コレクションを複数作ることもでき、ドキュメント内にコレクションを作ることもできます。これをサブコレクションと言います。(画像のReviewsがサブコレクション)
サブコレクション内のドキュメントのサブコレクションを作成することもでき、データは最大100レベルまでネストできます。
ドキュメント内のデータ構造は以下の通りで、各項目はフィールドと呼ばれます。
json型のようなmapとarray(配列)も保持できます。

公式ドキュメント
https://firebase.google.com/docs/firestore/manage-data/structure-data
Cloud Firestoreの6つのルール
Firestoreには大きく分けて6つのルールがあり、それを理解した上でデータ構造を決める必要があります。
変更された点もありますが、動画に沿って変更前と変更後の説明をしています。
元の動画はこちら↓
① ドキュメントの制限
- 1つのドキュメントに格納できるデータは1MBまで
- 300ページの本の文章を格納した場合770KB
- 写真などの格納は難しい
- フィールドは20,000まで
- 全てのフィールドにインデックスが発行される仕組みになっているためmapもフィールドにカウントされるので注意
// map: フィールド数4
address: {
city: "Tokyo"
region: "chiyoda-ku"
zipcode: 1111111
}
// フィールド数3
city: "Tokyo"
region: "chiyoda-ku"
zipcode: 1111111
- 同じドキュメントへの書き込みは1秒間に1回まで
- 複数人が同時に1つのドキュメントへ書き込みをしようとすると失敗する
- 異なるドキュメントへ同時に書き込むのはOK
② ドキュメントは部分的に取得することができない
例えば以下のようなコレクションで本のタイトルだけ取得したい時、同じドキュメント内に本文(contents)が入っているので同時にそれも取得してしまいます。
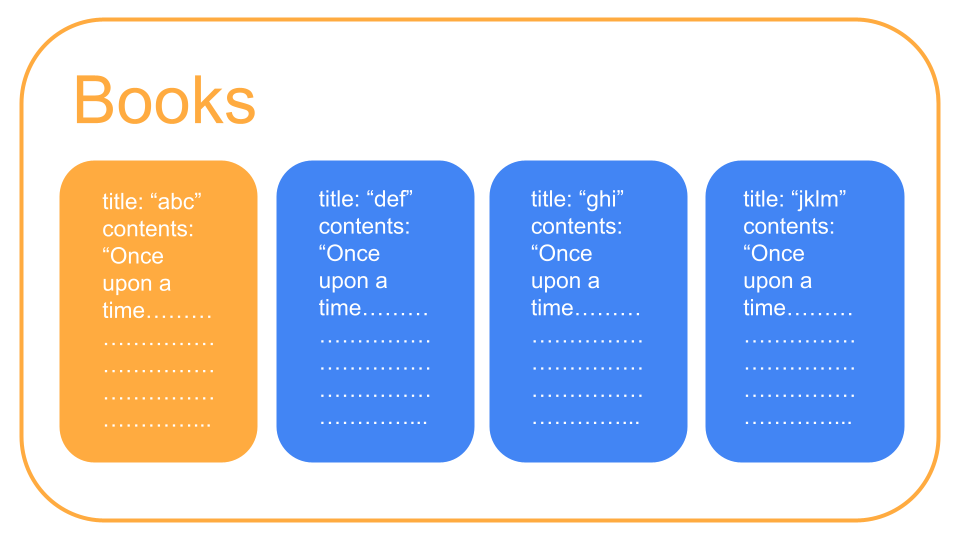
- アプリのパフォーマンス低下
- メモリ消費がすごいことになる
- 電池消費もすごいことになる
といったことになってしまい、ユーザーがアンインストールしてしまう原因になるので注意が必要です。
セキュリティルールも同様にドキュメントを部分的に保護することができません。
同じドキュメント内のフィールドで別々のルールを設けたい場合別ドキュメントとして保存する必要があります。
③ クエリは深い階層のデータまで取得することができない
あるドキュメントを取得した時、そのドキュメントのサブコレクションを取得することはありません。
これは余計な読み込みをしない点でメモリ消費の節約にもなる一方、
そのサブコレクションを読み込みたい場合更にクエリを発行しなければいけないためコードが煩雑になる危険を孕んでいます。
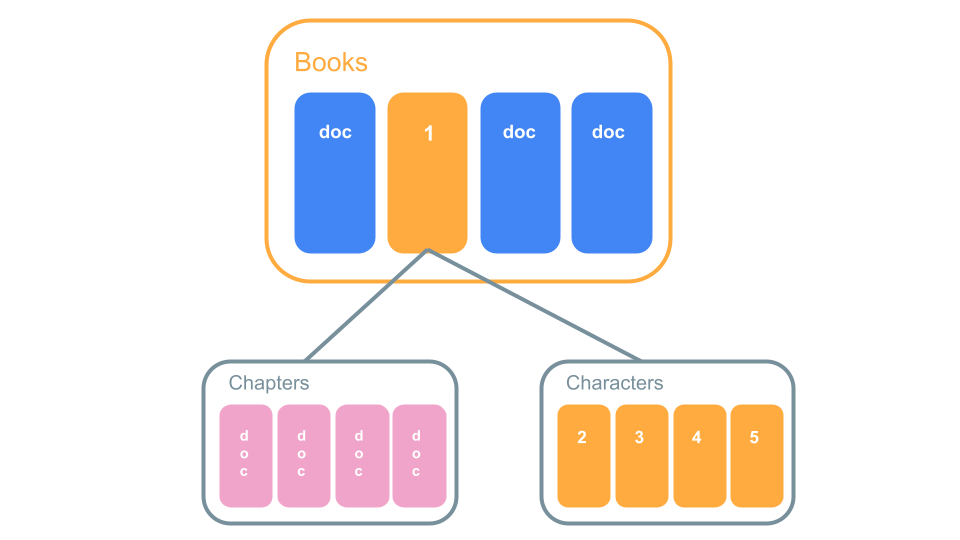
②の例では本のcontentsはチャプターごとのサブコレクションを作って読み込むのが良さそうです。
ここで登場人物もサブコレクション化している場合を考えてみます。
本の詳細を表示するページで登場人物を表示しないのであれば1回の読み込みで足りますが、
登場人物を一緒に表示させたいと思った場合、登場人物のドキュメントの数の回数分読み込まなくてはいけなくなります。
④ 使用料金は読み込みと書き込みの回数で決まる
③のルールと関連してきますが、サブコレクションが何重にもなっているとその分読み込み回数が増え、料金が増えてしまいます。
なので、一緒に表示させたいデータは基本的に同じドキュメントに入れるのが良いとされています。
しかし、サブコレクションにしたほうが良い場合もあるため費用と効果のバランスを検討しながらデータ構造を決定する必要があります。
⑤ クエリは1つのコレクション内のドキュメントしか探すことができない → クエリは複数のコレクションにまたがってドキュメントを探すことができる
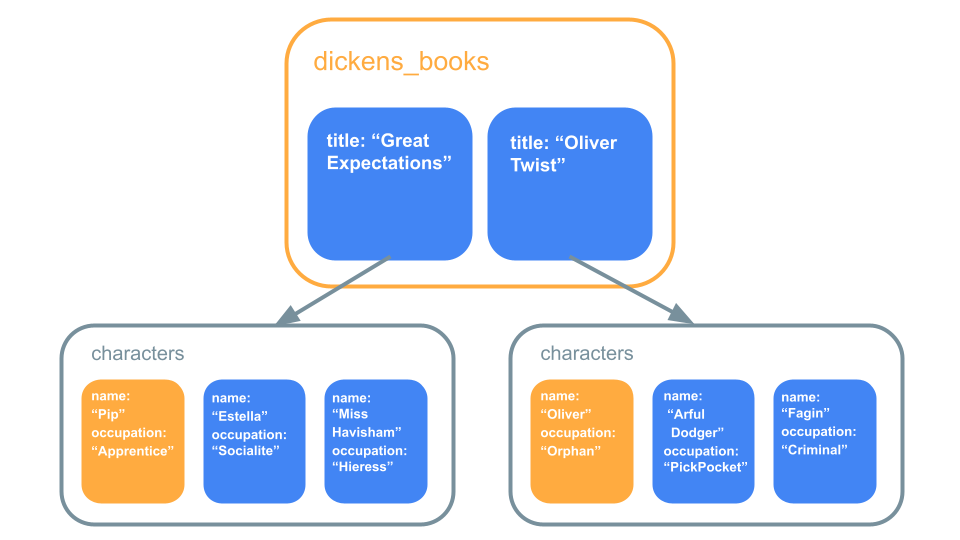
例えば上記の例で「"GreatExpectations"のPから始まるキャラクターを探す」というのは以下のようにできます。
//"GreatExpectations"のPから始まるキャラクターを探す
collection("dickens_books/great_exp/characters")
.where(name >= "P")
.where(name < "Q")
当初クエリは1つのコレクション内でしかドキュメントを探すことができず、「全ての本の中からキャラクターの名前がOliverの本を探す」というのは複数のコレクションにまたがって探す必要があるためできませんでした。
が、2019年に改善され、今は以下のコードでできるようになっています。
//全ての本の中からキャラクターの名前がOliverの本を探す
collectionGroup("characters")
.where("name", "==", "Oliver")
注意点
- CollectionGroupクエリの実行にはインデックスの設定が必要
- 一度クエリを実行するとコンソールにURLが表示されるため、そこから簡単に登録できる
- Firebase Consoleから自分で設定することも可能
- インデックスは最大200まで登録可能
- 同じ名前のコレクション全てでクエリを実行してしまうので命名には気をつけること
- 上記の例だと全ての "characters" コレクションでクエリを実行している
公式ドキュメント
https://firebase.google.com/docs/firestore/query-data/queries#collection-group-query
インデックスについてはこちら
https://firebase.google.com/docs/firestore/query-data/indexing
ではCollectionGroupクエリが使える以前はどうやって「全ての本の中からキャラクターの名前がOliverの本を探す」ことをしていたのかというと2通りのやり方があります。
1. Collection内にmapを保持する方法

//全ての本の中からキャラクターの名前がOliverの本を探す
collection("dickens_Books")
.where("characters.Oliver", ">=", "")
- 「occupationがsocialiteのキャラクターを探す」「名前順に並び替える」というようなクエリは実行不可能であり、検索オプションが限られている
- Map内fieldの値をキーとするのは間違えやすくエラーが起きやすい
- ドキュメント内の不必要な情報も一緒に取ってきてしまう
という理由で推奨されていません。
2. charactersコレクションをtop-levelのコレクションにする

//全ての本の中からキャラクターの名前がOliverの本を探す
collection("characters")
.where("name", "==", "Oliver")
//occupationがsocialiteのキャラクターを探す
collection("characters")
.where("occupation", "==", "Socialite")
//"GreatExpectations"の登場人物を探して名前順に並び替える
//2つ以上のクエリを実行するにはインデックスの設定が必要
collection("characters")
.where("book", "==", "great_exp").orderBy("name")
幅広い検索が容易にできるためこちらの方法が推奨されていました。
top levelのコレクションから検索する場合検索量が増えてパフォーマンスが悪くなるのではないかと考える人もいると思いますが、サブコレクションを検索する場合と速度にほとんど差はないそうです。
結局どれを使えば良いのか
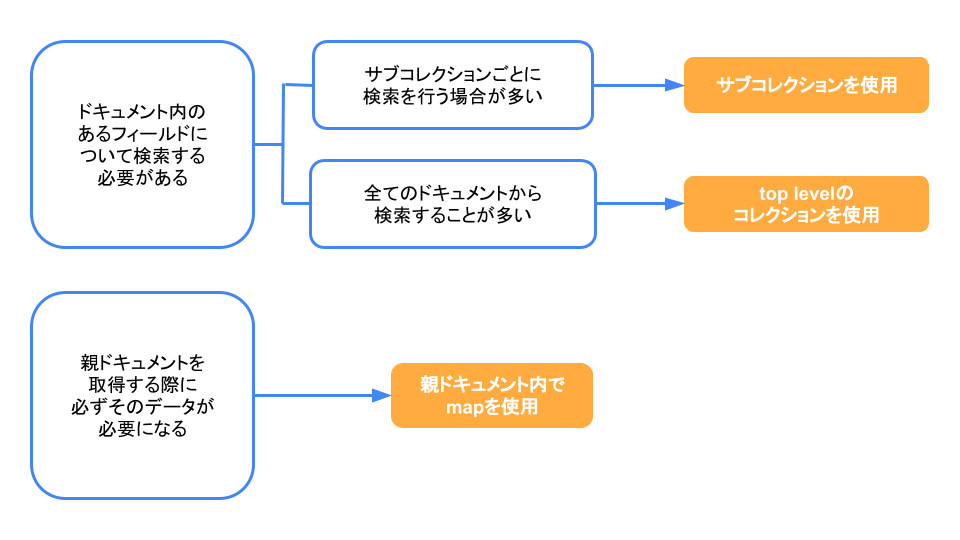
現時点(2021年5月2日時点)では、以下がどの方法を使うかを決めるガイドラインだと言っています。
- ドキュメントの中のあるフィールドについて検索したい場合コレクションに追加する
- サブコレクションでもtop-levelのコレクションでも可能
- サブコレクションごとに検索することが多く、たまにcollectionGroupクエリを使いたい時はサブコレクション
- 全てのドキュメントにまたがって検索することが多く、サブコレクションごとに検索する場合が少ない時はtop-levelのコレクション
- 親ドキュメントを読み込んだ際に必ずそのデータが必要になる時はmapを使う
簡単なフローチャートを作成してみました。
⑥ Arrayの挙動が異質
Firestoreでは同じデータに複数の端末からアクセスすることが可能であり、
インデックス操作でデータを書き換えることが容易なArrayは現在どのフィールドで何の書き込みがされているのか把握することが難しく、思った通りの結果が得られない可能性があります。
例えばAさんが配列の2番目に書き込みをしようとしている時に、Bさんは配列の2番目の要素を削除しようとしており、更にCさんは配列の一番最初にデータを挿入しようとしている場合、それぞれで違う結果が得られてしまいクラッシュしてしまいます。
そのため以下のような配列操作や検索方法は使えません。
my_array[2] = "tackle"
my_array.deleteAt(2)
my_array.insertAt(0, "hello")
collection.where(my_array[2] == "larry")
じゃあArrayはどのように使えばいいのかというと、flagの管理用として使用します。
以下は"drama"というキーワードを持つ本を検索しています。
カテゴリ分けの際に使えそうです。
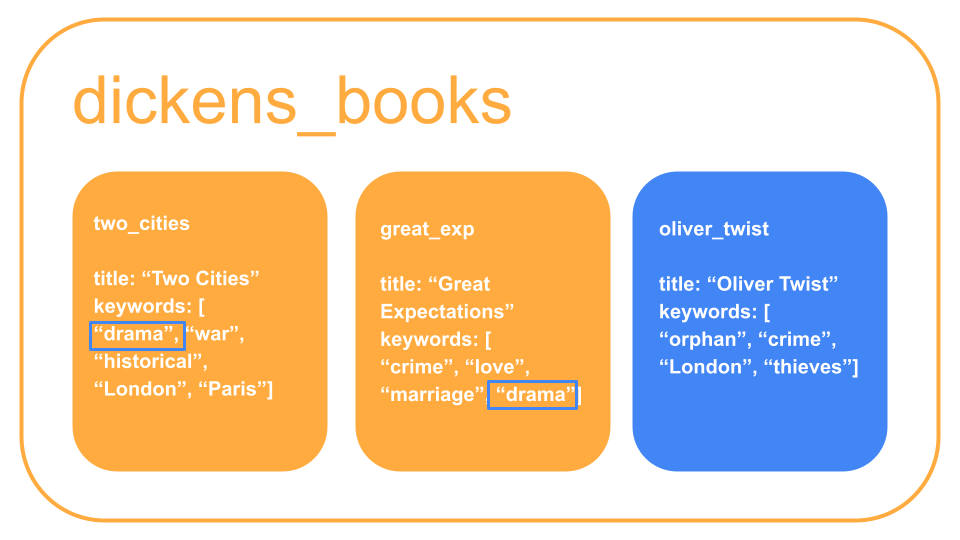
collection("dickens_books").where("keywords", "array-contains", "drama")
とはいえ、現在はインデックスに関係なく配列にデータを追加する、削除するarrayUnionとarrayRemoveが追加されたので異なる結果になりクラッシュするということは無くなったと言っています。
詳細はこちら
https://firebase.google.com/docs/firestore/manage-data/add-data
まとめ Firestoreデータ構造の決め方
動画の最後でデータ構造を決めるガイドラインについて触れていました。
- 同時に使用するデータは全て同じドキュメント内に保存する
- 丁度いいサイズで格納する
- 例として1つの画面表示のために2つの異なるデータベースから30ドキュメントを取得する必要がある設計は細かすぎると言っていました
- 一部を検索する必要があるもの、今後データが増えていく可能性があるものはコレクションにする
- 逆にそのデータから親ドキュメントの中身を検索したい場合はmapを親ドキュメントに格納する
- 住所や位置情報など関連が深いデータのまとまりもmapを使うと良い
- フィールドで保存する場合よりもキーワードのコンフリクトを避けることができる
- flagを管理したいときはArrayを使う
また動画の続きを引き続き記事にしていきたいと思います。
次はレビュー機能、お気に入り機能付きのレビューアプリのデータ構造を考えていくという実践的な内容です。
間違っている箇所などありましたらコメントでお知らせください。
参考になった記事
【Firebase】Cloud Firestoreのデータ構造の決め方をFirebaseの動画から学ぶ
Cloud Firestore公式Youtube