※これは2019/1/13時点の情報です。
最近Firestoreを触りはじめました。
(メインはiOSです。)
今までRDBを使ってきましたが
NoSQLはほとんど経験がなく
どういうデータ構造で設計すれば良いのかがいまいちわからなかったので
色々と調べています。
その中でFirebaseの↓の動画を見つけ
具体例と共にデータ構造についての決め方などが話されており
整理をするためにも記録としてまとめてみました。
6つのルール
データ構造を考える前に
現時点でのルールがいくつかあるらしく
それについては↓の動画で言及されており
それについても記載します。
1. ドキュメントに上限がある
1つのドキュメントに格納できるのは1MBまで
画像など格納するは難しそうです。
フィールドは20,000まで
マップにするとマップ自体も1つとしてカウントされます。
これはFirestoreが各フィールドに自動でインデックスを作成することによるものだそうです。
同じドキュメントへは1秒に1つしか書き込みができない
複数の端末から同じドキュメントへ
同時に書き込みを行おうとすると1つ以外は失敗します。
クライアントライブラリは失敗時の再送機能を有しているとは思いますが
できる限り避けたい状況ではあります。
一方で
同じコレクション内の異なるドキュメントへの書き込みは問題ありません。
これも構造の選択するための考慮する点として考える必要がありそうです。
2. ドキュメントの部分取得ができない
つまり、一つ一つのドキュメントが大きい場合、そんれだけ取得するデータ量が増え、
使用メモリを増やし、バッテリーの消耗を早めることにも繋がります。
動画だと本のタイトルと中身全部を格納していた場合に
タイトルだけ欲しいとしても本の中身も全部取ってきてしまう、という例を出しています。
セキュリティルールも同様
ドキュメント全体にしか適用ができません。
解決方法としてはドキュメントにサブコレクションを持たせて
細かく、細かくしていくという方法がありますが
次の制限との兼ね合いを考慮する必要が出てきます。
3. クエリはサブコレクションのデータを一緒に取得しない
あるドキュメントを取得したとしてもその下にあるサブコレクションのデータは取得しないということです。
これはサブコレクションのデータが不要であった場合
余計なデータの取得せずメモリの浪費を防ぐことができるなど良い部分もあります。
反対に
サブコレクションのデータが必要であった場合は
さらにクエリを発行する必要が出てくるなどコード量の増加など処理が煩雑になりがちになってしまいます。
動画では同時に必要になりそうなものは元のドキュメントに入れてしまうのが良いのでは
という風に言っています。
4. 課金単位が読み込みまたは書き込みごと
3の状況をもう少し拡大してみます。
例えば日本の住所をFirestoreに格納していたとします。
top-levelに都道府県コレクションがあり
各都道府県ドキュメントが市区町村コレクションを持ち、
各市区町村ドキュメントがそれ以降の住所のコレクションを持ち、
各それ以降の住所ドキュメントが郵便番号を持つ
"東京都"
"千代田区"
"神田一丁目"
"111-1111"
"中央区"
"銀座2丁目"
"222-2222"
みたいなイメージでいきます。
※とにかく階層が深いということを表したかったためデータに意味はないです。
これを一覧画面を表示したいと思った際に
郵便番号まで表示しようとすると
ドキュメントからサブコレクションを取得し、
さらにサブコレクションそれぞれドキュメントからサブコレクションを取得し。。。
となってしまうようなこともあるのではないかと思います。
増えれば増えるほど課金もどんどんされていくことになります。
もちろん絶対にいけないということはなく、クエリの発行頻度と処理の実装にかかる手間などの
費用対効果を検討する必要があるとは思いますが、
データ構造に影響を与える状況も少なからずあるのではないかと思います。
5. クエリは1つのコレクションの中のドキュメントしか探すことができない できるようになりました
今年のGoogle I/O2019で
collectionGroupというクエリの実行が可能になり
ドキュメントをまたがったクエリの検索ができるようになりました。
iOSの場合はFirebase SDKのバージョン6.0以降で可能です。
https://firebase.google.com/support/release-notes/ios#version_600_-_may_7_2019
公式のドキュメントの例によると下記のようなデータに対して
let citiesRef = db.collection("cities")
var data = ["name": "Golden Gate Bridge", "type": "bridge"]
citiesRef.document("SF").collection("landmarks").addDocument(data: data)
data = ["name": "Legion of Honor", "type": "museum"]
citiesRef.document("SF").collection("landmarks").addDocument(data: data)
data = ["name": "Griffith Park", "type": "park"]
citiesRef.document("LA").collection("landmarks").addDocument(data: data)
data = ["name": "The Getty", "type": "museum"]
citiesRef.document("LA").collection("landmarks").addDocument(data: data)
data = ["name": "Lincoln Memorial", "type": "memorial"]
citiesRef.document("DC").collection("landmarks").addDocument(data: data)
data = ["name": "National Air and Space Museum", "type": "museum"]
citiesRef.document("DC").collection("landmarks").addDocument(data: data)
data = ["name": "Ueno Park", "type": "park"]
citiesRef.document("TOK").collection("landmarks").addDocument(data: data)
data = ["name": "National Museum of Nature and Science", "type": "museum"]
citiesRef.document("TOK").collection("landmarks").addDocument(data: data)
data = ["name": "Jingshan Park", "type": "park"]
citiesRef.document("BJ").collection("landmarks").addDocument(data: data)
data = ["name": "Beijing Ancient Observatory", "type": "museum"]
citiesRef.document("BJ").collection("landmarks").addDocument(data: data)
下記のようなクエリの実行が可能になっています。
db.collectionGroup("landmarks").whereField("type", isEqualTo: "museum").getDocuments { (snapshot, error) in
// ...
}
先ほどの都道府県の例で考えてみますと、
都道府県コレクションの中で
「中央」という名前のつく市区町村を探し出すことができるようになります。
2019/05/23時点で公式のドキュメントは
まだ英語版しか更新されていませんが
collectionGrpoupクエリを実行するためには
いくつか設定が必要になります。
検索にはインデックスの設定が必要
これは一度クエリを実行をするとエラーとなり、コンソールにURLが表示されるのでそこから登録が可能です。
事前にConsoleから設定も可能です。
https://firebase.google.com/docs/firestore/query-data/indexing
セキュリティルールの設定が必要
セキュリティルールにも更新がありグループクエリ用の条件が設定する必要があります。
公式のドキュメントには下記のような例が提示されています。
// ↓バージョンの指定が必要
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
// 認証されたユーザのみがpostsコレクションに対して
// collectionGroupのクエリを実行することが可能です。
// 実行できるのはcollection、collectionGroup、個々のpostドキュメントの取得
match /{path=**}/posts/{post} {
allow read: if request.auth.uid != null;
}
match /forums/{forumid}/posts/{postid} {
// postの作者のみが書き込み可能
allow write: if request.auth.uid == resource.data.author;
}
}
}
詳しくは英語版のドキュメントや
Google I/O2019の動画をご参照ください。
https://firebase.google.com/docs/firestore/query-data/queries#collection-group-query
https://firebase.google.com/docs/firestore/query-data/queries#collection-group-query
※LanguageをEnglishにしてください
https://www.youtube.com/watch?v=lW7DWV2jST0
※26分くらいのところで出てきます。
先ほどの都道府県の例で考えてみますと、
都道府県コレクションの中で
「中央」という名前のつく市区町村を探し出すことができます。
↓は過去の内容です
先ほどの都道府県の例で考えてみますと、
例えば、東京都ドキュメントの中の市区町村コレクションの中で
「中央」という名前のつく市区町村を探し出すことは可能です。
一方で、都道府県コレクションの中で
「中央」という名前のつく市区町村を探し出すということはできません。
※2019/1/13の執筆時点の内容です。将来的に複数コレクションをまたがったクエリが利用可能になるかもしれません。
これを解決する方法としては、
市区町村コレクションをtop-levelに持ってきて、
都道府県をフィールドとして持って参照できるようにする
などということが挙げられていました。
こうすることで、他の検索にも対応することが可能になります。
6. Arrayの挙動が不思議
Firestoreの性質上、同じデータを複数の端末で操作することが可能であり、
インデックスで操作を行う配列は予期せぬ動作をする可能性が多いにあります。
イメージとして
// こんな配列があったとして
var arr = ["dog", "monkey", "cat"]
// Bさんが別の端末から値を変えていた
arr[2] = "cap"
// Aさんは猫だと思って取得したら帽子になっていた
var neko = arr[2] // cap
// Cさんが削除
arr.remove(at: 2)
// Aさんはデータあると思って取得しようとしたらクラッシュした
var a = arr[2] // Fatal error: Index out of range
みたいなことが起きます。
動画の中ではArrayに関しては複数のflagを管理する例を挙げており、
下記のような形で使用していました。
collection("books").where("keywords", "array-contains", "love")
※ちなみにArrayの仕組みですが、
内部でArrayの値をKey、ValueをtrueにしたMapを作成し、
イコールtrueで検索をするようにしているようです。
keywords: ["love", "drama", "comedy"]
keywords.contains("love")
// これを↓に変換
keywords: {"love":true,"drama": true,"comedy":true}
keywords.love == true
※ arrayUnionとarrayRemoveで削除ができるようになったので
インデックスを意識することは少ないのかもしれません。
基本的なデータ構造のルール
では、データ構造に関して記載していきます。
下記のものは上記のルールに関する動画の最後に出てきた一般的なデータ構造の設計の指針のようなものです。
一緒に表示するものは同じドキュメントに入れる
サイズはちょうど良い大きさにする
※細かすぎる基準は1つのスクリーンの表示のために2つの異なるdatabaseから30のドキュメントが必要になるなど
一部を検索する必要があったり、今後数が増える可能性があるデータはコレクションとして保持しておく
逆にそのデータから親階層のデータを検索するようなケースがある場合は親階層にMapとして保持しておく
Mapを使うもう1つの例として関連が深いデータのまとまりをまとめておくと名前の衝突なども避けられて良い(住所情報、位置情報など)
フラグとして使用する複数の項目はArrayとしてまとめておくと良い
レストランのレビューアプリの例
動画の中で紹介されているのは下記の機能を持ったごくシンプルなアプリです。
- レストラン一覧表示画面(レストラン情報を検索して一覧を表示する)
- レストラン詳細表示画面(一覧で選択されたレストランの詳細情報を表示する。最近のレビューのスニペットも表示される)
- レビュー表示画面(詳細画で選択されたレビューの全情報を表示する。)
最初のデータ構造
top-levelにRestaurantsのコレクションがあり、その下にReviewsの構造があります。
おそらく最初に思い浮かぶのがこのような構造ではないでしょうか(私はそうでした。)
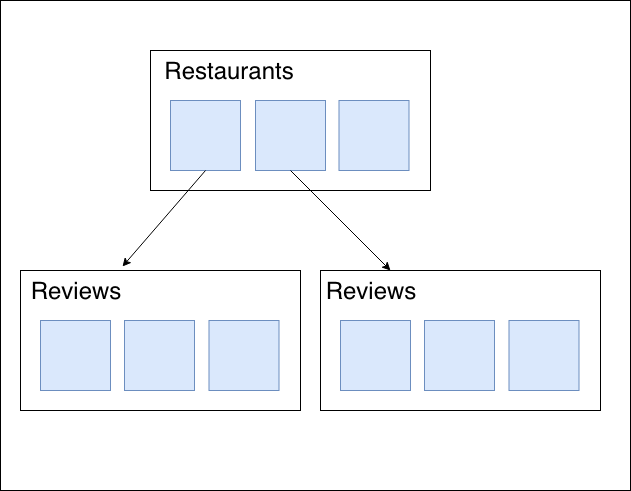
ここから、状況によってどういう構造が適しているのかの検討に入ります。
RestaurantのドキュメントにReview情報をMapやArrayで保持する
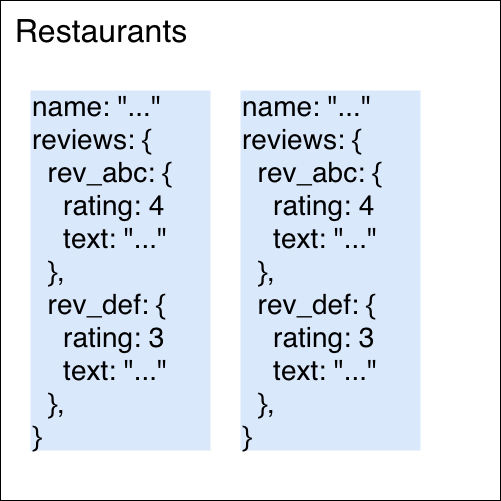
メリット
- 一覧画面ですでに必要な情報を取得済みなので詳細画面をすぐに表示することができる
- 余計な追加の読み込みの必要がない
デメリット
- 一覧画面で再検索を行なった際にReviewのデータも全て取得してしまうのでデータ量が多くなる
- Reviewが増えてくると、ルール1によってドキュメントの上限に達する可能性がある
- filterなどをデータ取得後に行わなければならなくなる(最近のReview10個など)
こういったことから
Reviewはサブコレクションとして持っておいた方が良いと判断をしています。
Reviewsのコレクションをtop-levelに持ってくる
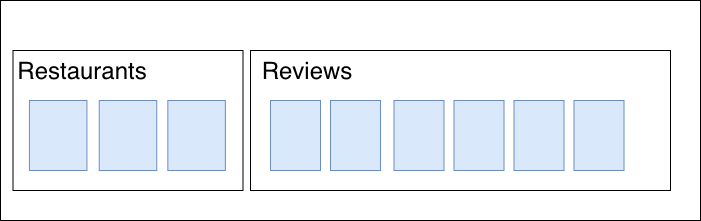
一見するとあるRestaurantに対するReviewを取得する際の検索量が増え
パフォーマンスが悪くなるという懸念があるかもしれませんが
Firestoreではサブコレクションを検索する際と速度は変わらずに十分に速いと言っています。
メリット
- 複数のRestaurantに対するReviewの検索やあるUserのReviewの検索など様々な検索ができる
※例えば最初の構造で実現しようとするとUserが自分のReviewを保持する必要があったり、
Reviewが追加された際などは Cloud Functionなどでデータの同期が必要になってきます。
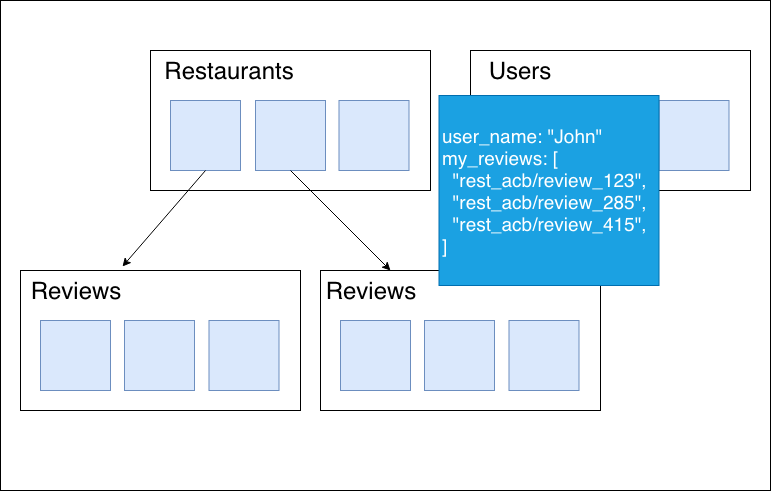
デメリット
- sortを使用して検索した場合にcomposite indexが必要になる
- セキュリティルールの書き方が難しくなる(サブコレクションは親の情報を元に記述できる)
※composite indexは下記の「複合インデックス」を参照
https://firebase.google.com/docs/firestore/query-data/index-overview?hl=ja
※セキュリティルールの書き方は下記を参照
https://firebase.google.com/docs/firestore/security/rules-conditions?hl=ja
一覧と詳細画面間の遷移時の読み込み量を減らす
現在の構造ですと
一覧から詳細へ遷移をするごとに
Reviewsのコレクションから10個のReviewsを取得してくることになります。
ルール4にもあるように課金はクエリの回数に依るので、
遷移の数が増えれば増えるほど料金も増えていきます。
これはあまりよろしい状態ではありません。
そこでRestaurantのドキュメントにReviewのSnippetを項目に持つことを検討します。
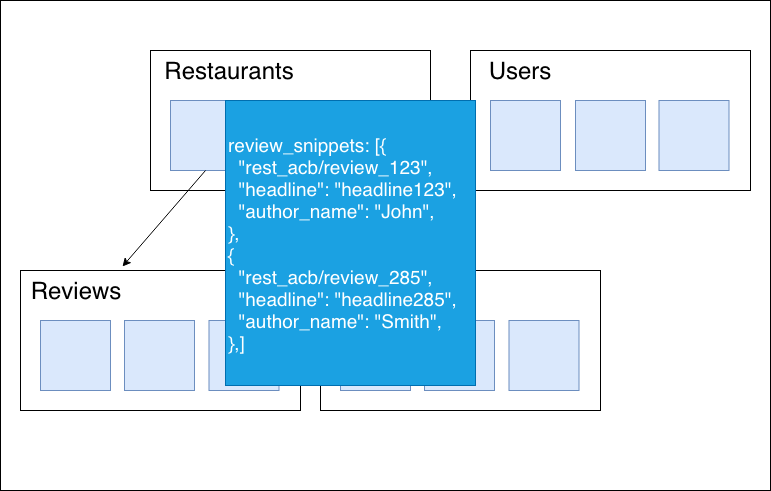
こうすれば、画面を開いた際に必要な情報は揃っており、
詳細画面に遷移する場合も1つのReviewドキュメントを取得するだけで済みます。
※もちろん同期は必要になりますがCloud Functionを活用することで解消できます。
https://firebase.google.com/docs/functions/?hl=ja
注意点
これは費やす労力に見合った効果が得られるかがあるかを考える必要があります。
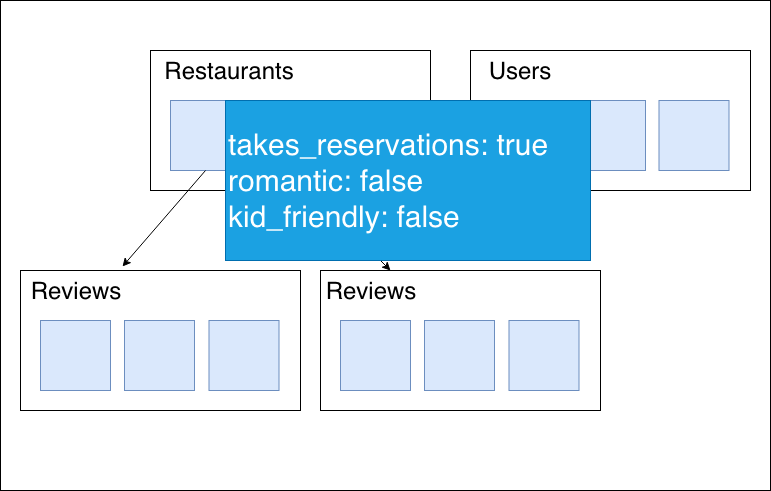
フラグを管理する
レストラン詳細画面に
予約の有無やロマンチックでるかどうか、子供に優しいかどうかなどを表示をするとします。
その場合のフラグの管理方法として3つを挙げています。
項目として保持
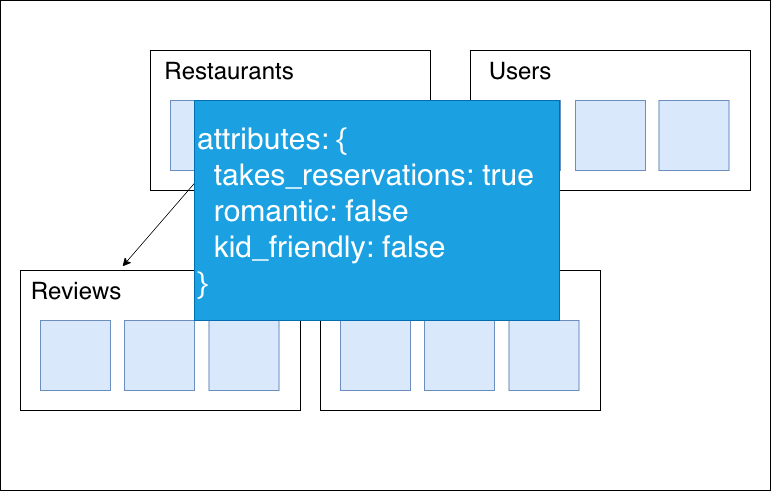
Mapとして保持
Arrayとして保持
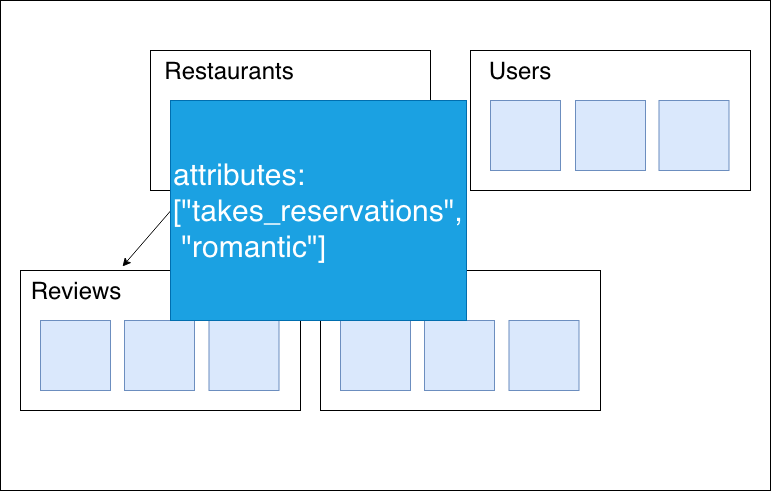
Arrayはarray_containsが使えるため、予約済みのレストランの検索などが
とても簡単にすることが可能です。
しかし、現在の問題点として
同じArrayにarray-containsが2回使えません。
そのため複合条件(ロマンチックかつ子供に優しいなど)が必要な場合は
別々の項目として持っておかなければなりません。
セキュリティの管理
例えば、ある特定のユーザーのみレストランの情報を編集できるようにしたいとします。
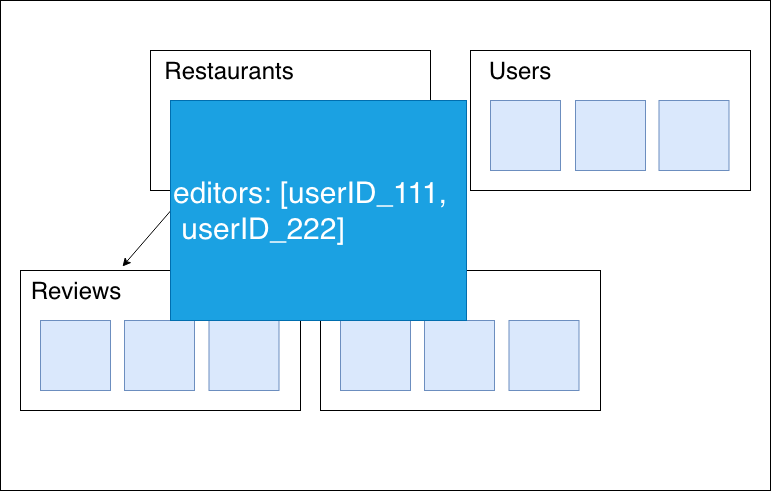
上記のように保持し、セキュリティルールをuserIDが含まれているかどうかで定義をすることもできますが、
Mapで保持した方がより汎用的にセキュリティルールの定義が可能です。
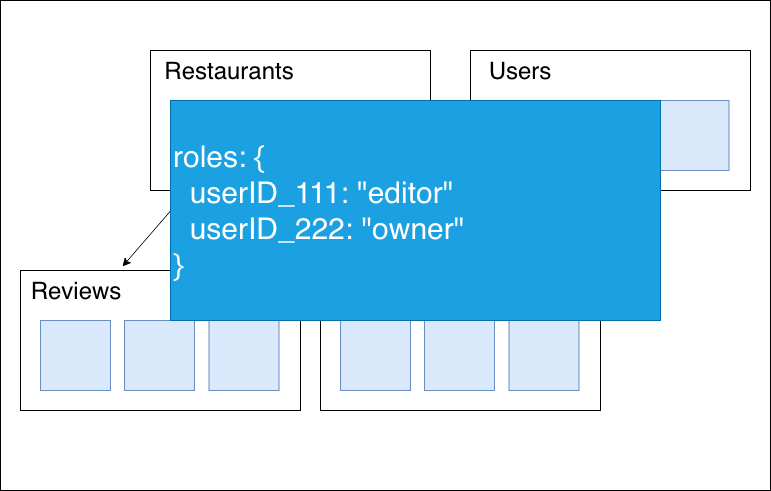
こうすることで
allow write if: restaurant.roles[userID] = "editor"
と書けますし、他の役割に対してのセキュリティルールも設定することが可能になります。
ただし、これにも少し問題があります。
ルール2に関連していますが
Restaurantの情報を取得する際に
全てのデータを取得してしまうため
先ほどのセキュリティ情報も取得されてしまいます。
仮にUserのIDが完全に暗号化されて守られているものだとしても
外に出ている以上は確からしいとしか言えません。
できれば外には出したくないですね。
そのためのいくつかの方法を検討します。
サブコレクションを作成する
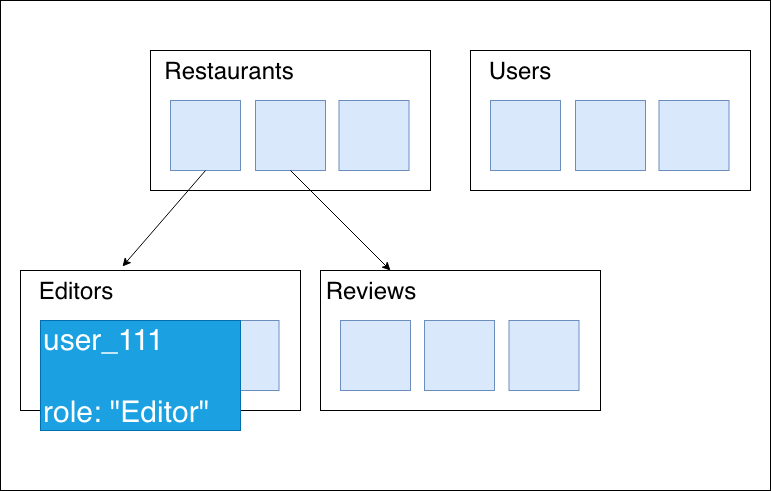
private dataを作成する

これは1つのドキュメントで内部の人間しか見ることができないドキュメントです。
この中に定義しておくことで外部からは参照できなくします。
多対多の関係を管理する
ユーザーがお気に入りのレストランを設定できる仕様が追加になったとします。
いくつかの方法を検討します。
Userがお気に入りのArrayを保持する

メリット
- arrayUnionやarrayRemoveで追加、削除が容易
- タグ的な役割としての操作が簡単(レストラン一覧でお気に入りに星をつけるなど)
デメリット
- お気にレストラン一覧としてRestaurantのデータが必要になった場合、1つ1つクエリを発行しなければならない
※ただし、利用頻度が低い場合はこの選択でも良いということもある。
データを非正規化して保持する
必要なデータを丸ごと保存していくような方法です。

メリット
- お気に入り一覧ですでに必要な情報を取得済みで追加読み込みが必要ない
- 詳細情報が必要な場合でも1つのドキュメント情報の取得で済む
デメリット
- User取得時に余計なデータも読み込む必要がある
- データの同期が頻繁に必要になる
- お気に入りが増えるとルール1のドキュメントの上限に達する可能性がある
※お気に入りがそんなにたくさんできて良いのかという問題は別の話
サブコレクションを作成する
お気に入りRestaurantのIDはArrayとして保持し、
付加情報はサブコレクションに保持します。

メリット
- 非正規化時のメリットに加え、必要なときにだけ付加情報を取得することができる
- 特定のRestaurantをお気入りにしているUserの検索もできる
(結果としてRestaurantに変更があった場合に変更が必要なUserのサブコレクションも特定できる)
userRef.where("favorites", "array-contains", "rest_4215")
デメリット
- お気に入りが増えるとルール1のドキュメントの上限に達する可能性は解消できていない
別のtop-levelのコレクションを作成する
現状、これが一番よい方法と紹介されています。
FavoriteRestaurantsを作成します。

メリット
- 特定のUser、Restaurantどちらに対しても検索ができる
- 検索方法がとてもシンプル
まとめ
Firestoreについては基本的な部分しか触れておらず
まだまだ知らなければならないことがいっぱいあるなと感じました。
(Firebase自体ほとんど使ったこともないというのが正直なところですが。。。)
ただ、iOS、Android、Web問わず
今後の開発スタイルとしてサーバレスに開発をするというスタイルは
必要になってくる可能性は大いにあるため必要性は強く感じています。
これからさらに色々な機能が増えていくとは思いますので
引き続き調査とアウトプットを繰り返して頭を整理して
実装を通して使い慣れていけるようにしていきたいと考えております。
間違いなどございましたらぜひご指摘いただけますと嬉しいです![]()