はじめに
本記事は、LOCAL学生部アドベントカレンダー2019の12日目の記事になります。
https://adventar.org/calendars/4020
アドベントカレンダーのネタ探しに時間がかかりすぎてなかなか決まらなかったので、既出ではありますが、Pix2Pixという生成モデルを使用したモノクロ画像の着色にチャレンジしたお話をします。
(Speech Synthesisやりたかった.....)
Pix2Pixとは
arXiv:https://arxiv.org/abs/1611.07004
GANの手法を利用し、様々なドメイン画像間の変換を統一的なネットワーク、誤差関数で行えるようにしたもの。
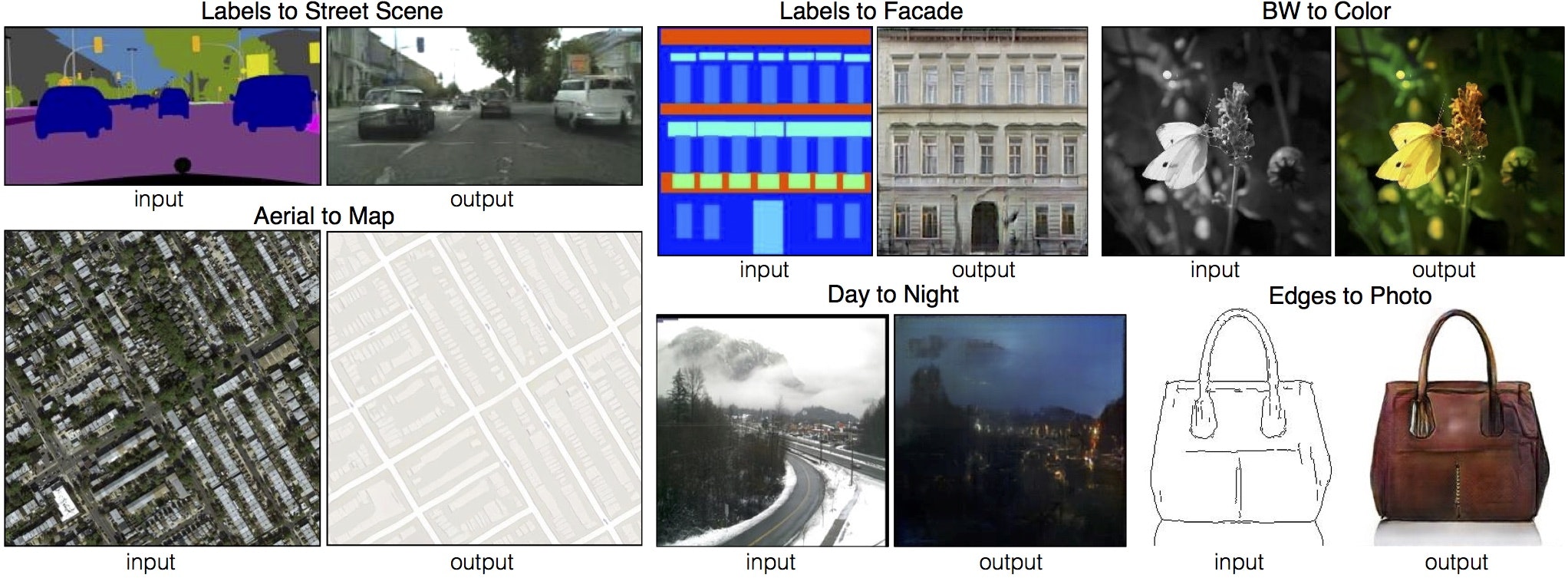
論文で紹介されているのは、
- マスク画像から元画像
- モノクロ画像からカラー画像
- 航空写真から地図
- 輪郭から色ぬり画像
もちろんこれらを逆に変換するよう訓練することも可能です。
ネットワークアーキテクチャ
Generator
Generatorのネットワークは、以下のようになっています。
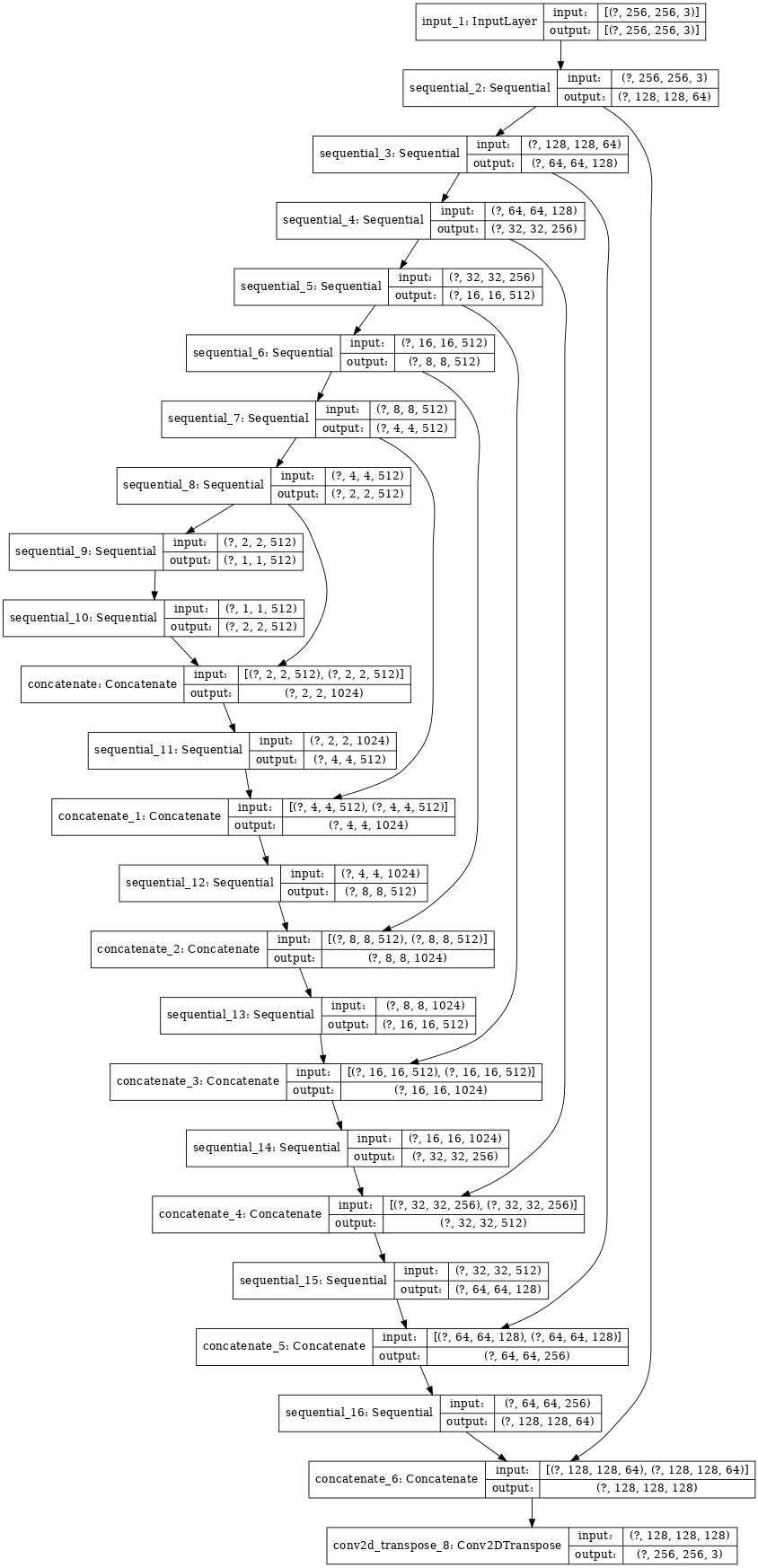
U-Netのモデルを修正したオートエンコーダになっています。
Conv -> Batchnorm -> Leaky ReLU
と画像を畳み込んで行き、デコーダーでは
Transposed Conv -> Batchnorm -> Dropout -> ReLU
と言った風に画像を拡大するように畳み込んで行きます。
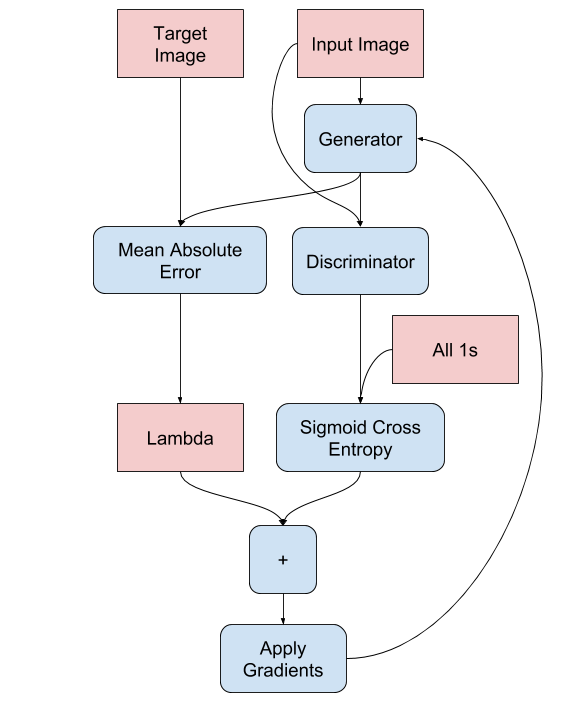
入力画像とGeneratorの生成画像との絶対値誤差(MAE)と、Discriminator(後述)の出力による交差エントロピー(Sigmoid cross entropy)、この二つを足し合わせてGeneratorの損失関数とします。
Discriminator
Discriminatorの方のネットワークは以下の通りです。
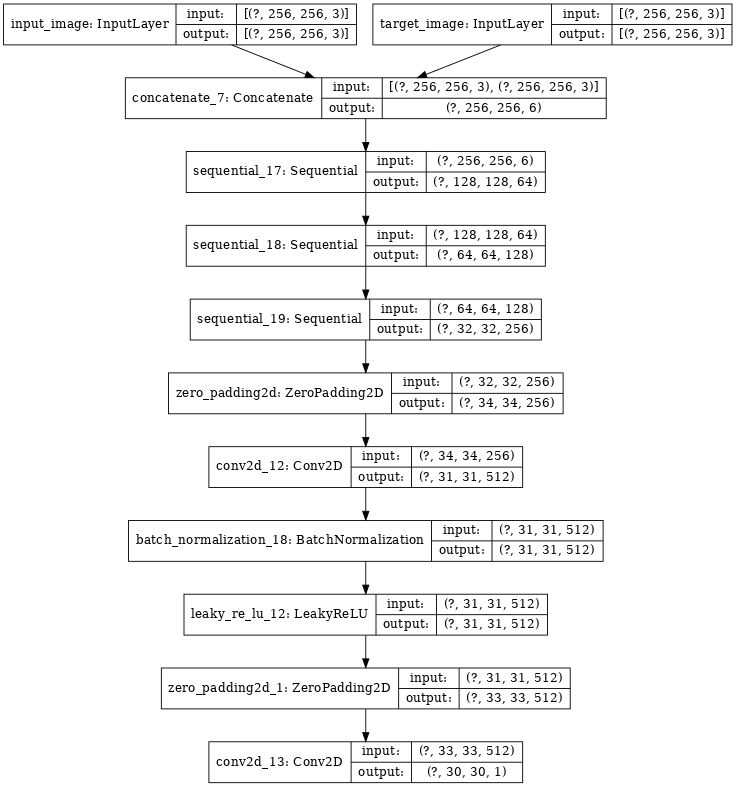
Discriminatorは、Generatorが生成した画像と教師データとして与えられている画像を識別するためのネットワークです。生成画像と訓練画像を入力として、本物か偽物(生成されたもの)かを見極めます。
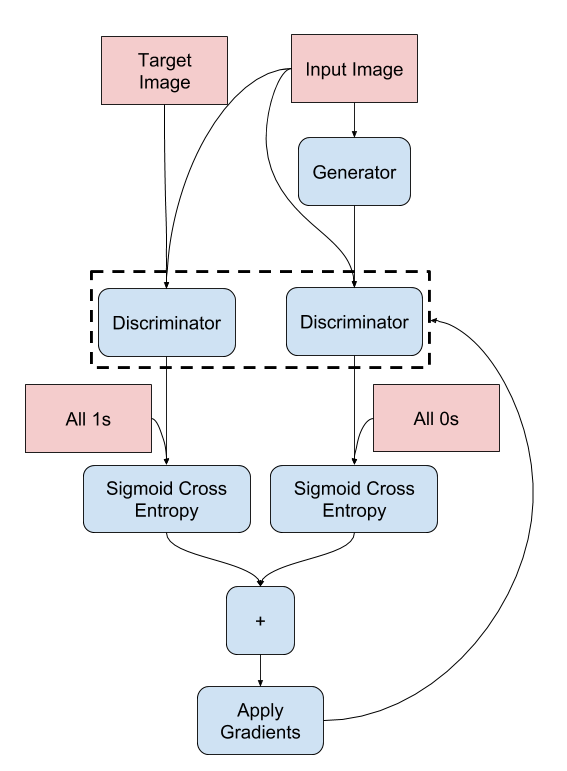
訓練フェーズでは、GeneratorとDiscriminatorとが互いに競い合うようにして精度を高めていきます。
実装
Tensorflow公式のチュートリアルを参考に実装しました。2.0の波に乗れてなかった人なので新しくなった関数群に戸惑いながら作りました。
今回チャレンジするタスクは、入力としてモノクロ画像を与え、カラー画像を出力させるというタスクです。データセットは、Googleが公開しているOpen Images dataset V5を使いました。
全体の実装はGithubにあります。
https://github.com/kodamanbou/Pix2Pix
Input pipeline
画像データのロードを行い、リサイズ、ランダムクロップ、グレースケール化します。
def load(image_file):
image = tf.io.read_file(image_file)
image = tf.image.decode_jpeg(image)
input_image = tf.image.rgb_to_grayscale(image)
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(image, tf.float32)
print(input_image.shape)
print(real_image.shape)
return input_image, real_image
def resize(input_image, real_image, height, width):
input_image = tf.image.grayscale_to_rgb(input_image)
input_image = tf.image.resize(input_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
real_image = tf.image.resize(real_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return input_image, real_image
def random_crop(input_image, real_image):
stacked_image = tf.stack([input_image, real_image], axis=0)
cropped_image = tf.image.random_crop(
stacked_image, size=[2, hp.image_size, hp.image_size, 3])
return cropped_image[0], cropped_image[1]
def normalize(input_image, real_image):
input_image = (input_image / 127.5) - 1
real_image = (real_image / 127.5) - 1
return input_image, real_image
@tf.function
def random_jitter(input_image, real_image):
# resizing to 286 x 286 x 3
input_image, real_image = resize(input_image, real_image, 286, 286)
# randomly cropping to 256 x 256 x 3
input_image, real_image = random_crop(input_image, real_image)
if tf.random.uniform(()) > 0.5:
# random mirroring
input_image = tf.image.flip_left_right(input_image)
real_image = tf.image.flip_left_right(real_image)
input_image = tf.image.rgb_to_grayscale(input_image)
return input_image, real_image
def load_image_train(image_file):
input_image, real_image = load(image_file)
input_image, real_image = random_jitter(input_image, real_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
def load_image_test(image_file):
input_image, real_image = load(image_file)
input_image, real_image = resize(input_image, real_image,
hp.image_size, hp.image_size)
input_image = tf.image.rgb_to_grayscale(input_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
Generator
Generatorは、先ほど説明したU-Net likeなネットワークになります。
def downsample(filters, size, apply_batchnorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
def Generator():
inputs = tf.keras.layers.Input(shape=[256, 256, 1])
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (bs, 128, 128, 64)
downsample(128, 4), # (bs, 64, 64, 128)
downsample(256, 4), # (bs, 32, 32, 256)
downsample(512, 4), # (bs, 16, 16, 512)
downsample(512, 4), # (bs, 8, 8, 512)
downsample(512, 4), # (bs, 4, 4, 512)
downsample(512, 4), # (bs, 2, 2, 512)
downsample(512, 4), # (bs, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (bs, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (bs, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (bs, 8, 8, 1024)
upsample(512, 4), # (bs, 16, 16, 1024)
upsample(256, 4), # (bs, 32, 32, 512)
upsample(128, 4), # (bs, 64, 64, 256)
upsample(64, 4), # (bs, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(3, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (bs, 256, 256, 3)
x = inputs
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
for up, skip in zip(up_stack, skips):
x = up(x)
x = tf.keras.layers.Concatenate()([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
def generator_loss(disc_gen_out, gen_out, target):
gan_loss = loss_object(tf.ones_like(disc_gen_out), disc_gen_out)
l1_loss = tf.reduce_mean(tf.abs(gen_out - target))
total_gen_loss = gan_loss + (hp.LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss
Discriminator
識別側のネットワークです。
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # [N, 256, 256, 4]
down1 = downsample(64, 4, False)(x) # [N, 128, 128, 64]
down2 = downsample(128, 4)(down1) # [N, 64, 64, 128]
down3 = downsample(256, 4)(down2) # [N, 32, 32, 256]
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # [N, 34, 34, 256]
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # [N, 31, 31, 512]
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # [N, 33, 33, 512]
last = tf.keras.layers.Conv2D(1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # [N, 30, 30, 1]
return tf.keras.Model(inputs=[inp, tar], outputs=last)
def discriminator_loss(disc_real_out, disc_gen_out):
real_loss = loss_object(tf.ones_like(disc_real_out), disc_real_out)
gen_loss = loss_object(tf.zeros_like(disc_gen_out), disc_gen_out)
total_disc_loss = real_loss + gen_loss
return total_disc_loss
Training
定義したネットワークを呼び出し、実際にトレーニング、モデルの保存などを行います。
@tf.function
def train_step(input_image, target, epoch):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_total_loss,
generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients,
discriminator.trainable_variables))
with summary_writer.as_default():
tf.summary.scalar('gen_total_loss', gen_total_loss, step=epoch)
tf.summary.scalar('gen_gan_loss', gen_gan_loss, step=epoch)
tf.summary.scalar('gen_l1_loss', gen_l1_loss, step=epoch)
tf.summary.scalar('disc_loss', disc_loss, step=epoch)
def fit(train_ds, epochs, test_ds):
for epoch in range(epochs):
start = time.time()
for example_input, example_target in test_ds.take(1):
generate_images(generator, example_input, example_target)
print("Epoch: ", epoch)
# Train
for n, (input_image, target) in train_ds.enumerate():
print('.', end='')
if (n + 1) % 100 == 0:
print()
train_step(input_image, target, epoch)
print()
# saving (checkpoint) the model every 20 epochs
if (epoch + 1) % 20 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
print('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time() - start))
checkpoint.save(file_prefix=checkpoint_prefix)
結果
Epoch 0

Epoch 1

Epoch 15

追加で載せていきます...
まとめ
ほぼチュートリアル通りの実装ですが、他のタスクにも簡単に応用できそうです。
参考サイト
https://www.tensorflow.org/tutorials/generative/pix2pix
http://yusuke-ujitoko.hatenablog.com/entry/2017/06/25/165008