この記事はCA Tech Lounge Advent Calendar 2024 20日目の記事です。19日目は@FJ2123さんによる「なんちゃって情報学部生の就活体験記」でした。
こんにちは、@kod-yです。大学院で経済学、とりわけ実証産業組織論を専攻しています。本稿では、CA Tech Lounge Advent Calendar 2024 13日目にて生成したダミーデータで反実仮想分析を行います。前回の記事はこちらからご覧ください。
推定モデルの導入
前回は真のデータを生成する際に従うモデルを用意しましたが、ここでは生成されたダミーデータを推定する際に考えるモデルを用意します。
$[0, 1] \times [0, 1]$ 区間を $0.2$ 四方のメッシュに分け、それぞれブロック $1, \cdots, 25$ とします。個人 $i$ がブロック $K$ からブロック $L$ まで移動することから得られる効用を次のように仮定します。
$$
u_{iKL} = \beta_0 + \beta_1 d_{KL} + \beta_2 ba_K + \beta_3 da_L + \beta_4 sc_K + \beta_5 sc_L + \xi_{KL} + \epsilon_{iKL} \quad \textrm{for all}:KL
$$
ここで、前回導入した真の効用関数は以下のような形でした。
$$
u_{iklt} = \beta_0 + \beta_1d_{kl} + \xi_{kl} + \epsilon_{iklt} \quad \mathrm{for}:kl \in C_t
$$
これらを比較して主に異なる点は以下の通りです。
- 真の効用関数は時点ごとに変化する選択集合を持つが、推定に用いる効用関数は時間を通じて共通の選択集合を想定している
- 真の効用関数はstation-to-stationのルートを選択するモデルだが、推定に用いる効用関数はblock-to-blockのブロック間移動を選択するモデルである
- 真の効用関数では時点によって変化するheterogeneityを部分的に認めているが、推定では認めていない
ここでは詳細を割愛しますが、選択集合 $C_t$ は各ルートの観察されない属性 $\xi_{kl}$ から影響を受ける内生変数であり、古典的な離散選択モデルでは推定されるパラメターにバイアスを生む原因となってしまいます。そこで、He, Zheng, Belavina and Girotra (2020) や同様のシェアサイクル系の研究ではbike availabilityやdock availabilityで $C_t$ を近似し、それらに対して操作変数を当てることで内生性の問題を解決しています。このシミュレーションでは、availability measureによる近似の妥当性を確認することが主目的の一つです。
データの整形
真のモデルから生成されたデータは個人レベルのデータだったので、ブロックごとにまとめて推定モデルの各変数を作成していきます。
ブロック $B$ にあるステーションの数の対数 $sc_B = \log(\#Stations\:in\:B)$
data_block <- data_station_block %>%
group_by(block) %>%
summarize(
log_S = log(n())
) %>%
ungroup()
ブロック $K$ にあるステーションとブロック $L$ にあるステーションの平均距離 $d_{KL}$
data_route_block <- data_route %>%
left_join(
data_station_block,
by = c(
"station_id.x" = "station_id"
)
) %>%
select(
station_id.x,
station_id.y,
distance,
block
) %>%
rename(
block.x = block
) %>%
left_join(
data_station_block,
by = c(
"station_id.y" = "station_id"
)
) %>%
select(
station_id.x,
station_id.y,
distance,
block.x,
block
) %>%
rename(
block.y = block
) %>%
group_by(block.x, block.y) %>%
summarize(
d = mean(distance)
) %>%
ungroup()
ブロック $KL$ 間の観察されない効用 $\xi_{KL}$
data_route_block <- data_route_block %>%
mutate(
unobserved = rnorm(n())
)
ブロック $B$ の平均的なbike availability $ba_B$ とdock availability $da_B$
data_station_time_block <- lapply(
data_station_time,
function(data) {
data <- data %>%
left_join(
data_station_block,
by = "station_id",
suffix = c("", "_b")
) %>%
select(
-contains("_b"),
-block_x,
-block_y
)
}
)
data_station_summarized <- lapply(
data_station_time_block,
function(data) {
data <- data %>%
group_by(station_id) %>%
mutate(
ba_ratio = sum(station_availability_status >= 1) / n(),
da_ratio = sum(station_availability_status <= 1) / n()
) %>%
ungroup() %>%
select(
station_id,
ba_ratio,
da_ratio,
block
) %>%
group_by(block) %>%
summarize(
ba = mean(ba_ratio),
da = mean(da_ratio)
) %>%
ungroup()
}
)
データの推定
真のモデルと推定モデルは明らかに異なる関数形を想定しているため、たとえ推定モデルを正しく推定したとしてもその係数を解釈することに意味はありません。しかし、後続の反実仮想分析にてここで推定したパラメター $\hat{\beta} = (\hat{\beta_0}, \hat{\beta_1},\hat{\beta_2},\hat{\beta_3},\hat{\beta_4},\hat{\beta_5})$ を用いるため、推定しておく必要があります。
ここでは標準的な最尤推定を想定し、次のような尤度関数を最大化します。
$$
\log L = \sum_{KL} \# \left(\mathbf{1}\left(\textrm{choose}:KL\right)\right) \log \left(p_{KL}\right)
$$
mle <- function(beta_init, data_exp, data_obs) {
# beta_init: initial parameter vector
# data_exp: data for the choice probability
# data_obs: observed data
# define the objective function
obj <- function(beta) {
-log_likelihood(beta, data_exp, data_obs)
}
# optimize the objective function
result <- optim(
par = beta_init,
fn = obj,
method = "BFGS"
)
return(result$par)
}
反実仮想分析
分析意図
反実仮想分析では現実に起こっていない何らかのシナリオを考え、それを推定したモデルで表現します。ここでは、既存のステーションネットワークに1つだけ新たなステーションを追加することを考えます。分析結果の妥当性を検討するための指標として、導入後のシェアサイクルのマーケットシェアを算出します。まず、真のモデルでのマーケットシェアは次のように表されます。
$$
\sum_{kl}\frac{1}{T}\sum_{t=1}^{T} p_{klt}^{'B}
$$
なお、 $\hat{p}_{klt}^{'B}$ は時期 $t$ にブロック $B$ にステーションが追加されたときのルート $kl$ の選択確率を表しています。
次に、推定モデルでのマーケットシェアは次のように表されます。
$$
\sum_{KL}\frac{1}{T}\sum_{t=1}^{T} \hat{p}_{KLt}^{'B}
$$
ここで、 $\hat{p}_{KLt}^{'B}$ は時期 $t$ にブロック $B$ にステーションが追加されたときのブロック $KL$ 間の移動の選択確率を表しています。なお、 $\hat{p}_{KLt}^{'B}$ の計算には先ほど推定したパラメター $\hat{\beta}$ を使用しています。これらを用いて、相対誤差 $err$ を求めます。
$$
err = \frac{1}{25} \sum_{B=1}^{25} \frac{\left| \sum_{KL}\frac{1}{T}\sum_{t=1}^{T} \hat{p}_{KLt}^{'B} - \sum_{kl}\frac{1}{T}\sum_{t=1}^{T} p_{klt}^{'B}\right|}{\sum_{kl}\frac{1}{T}\sum_{t=1}^{T} p_{klt}^{'B}}
$$
この $err$ を求める計算を50回行い、平均及び標準誤差を求めます。
simulate <- function(p_mix, beta, beta_hat, df_station_block, df_station_time, df_route) {
err <- sapply(
1:B,
function(b) {
df_station_block_cf <- add_station(
df_station_block,
b
)
# get counterfactual value under the true model
results <- get_share_true(
p_mix,
beta,
df_station_block_cf,
df_station_time,
df_route
)
share_true <- results[[1]]
df_route_new <- results[[2]]
df_station_time_new <- results[[3]]
# get counterfactual value under the block-level model
share_block <- get_share_block(
p_mix,
beta_hat,
df_station_block_cf,
df_route_new,
df_station_time_new
)
# compare them to calculate err
err_b <- abs(share_true - share_block) / share_true
return(err_b)
}
)
err <- sum(err) / B
return(err)
}
分析結果
He, Zheng, Belavina and Girotra (2020) は分析の結果を以下のように報告しました。
Table 17 from He, Zheng, Belavina and Girotra (2020)
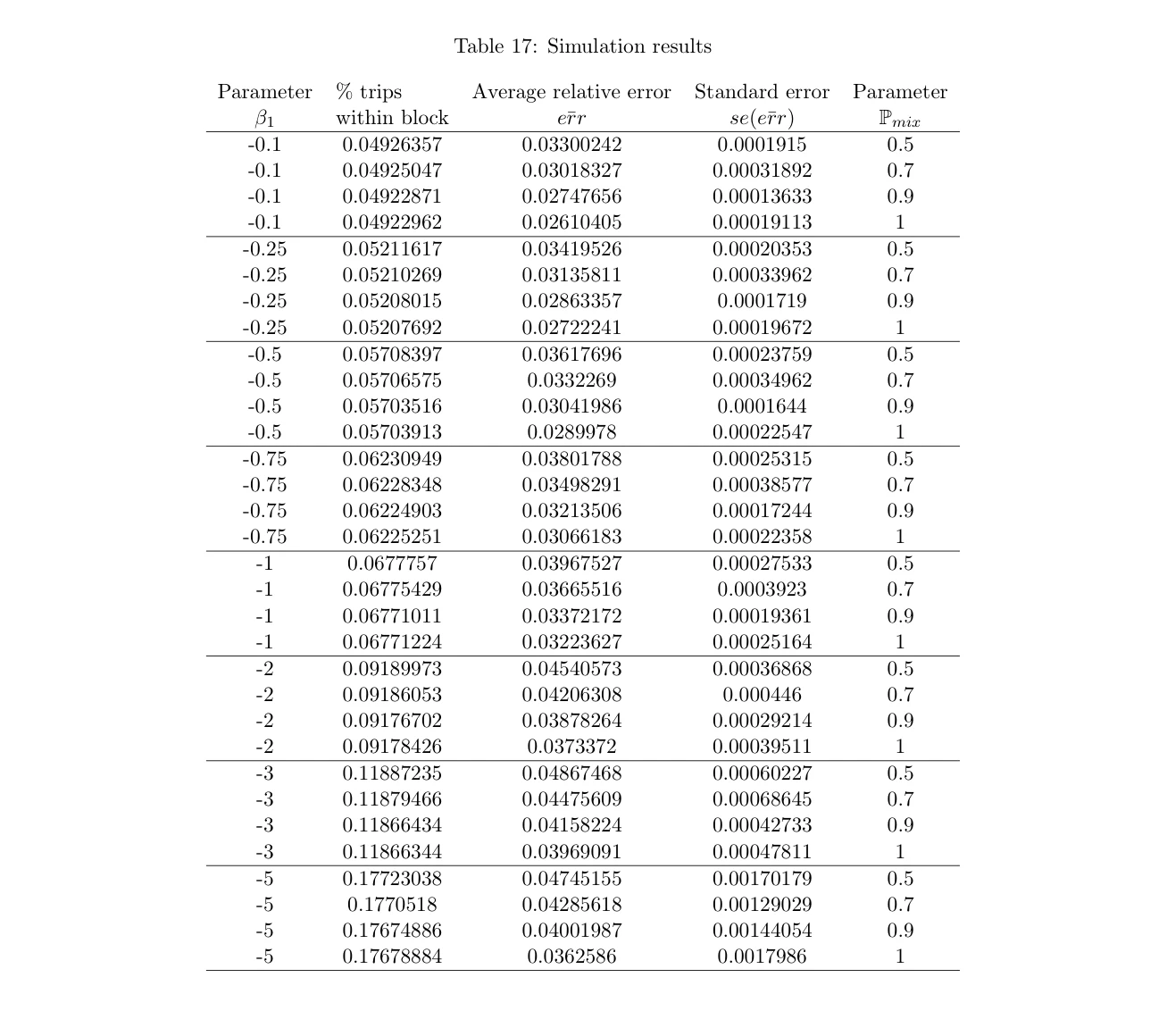
主に着目すべきは平均相対誤差 $\hat{err}$ です。どのパラメター設定の場合でも高々 $0.05$ に収まっており、推定モデルで真のモデルの動きを捉えられています。ここから、次のような示唆が得られます。
- 時点によって変化する選択集合を時間に依存しないavailability measureで代替しても致命的なバイアスは生じない
- 個人ごとの意思決定をブロック間の移動に代替しても致命的なバイアスは生じない
上記は今回のモデルの設定上自然と言えます。なぜならば、前者については選択集合が適当にドローした確率変数 bike_availability と dock_availability に依存して定まり、その平均がavailability measureそのものだからです。後者については、真のモデルの効用関数では移動に対する不効用が $\beta_1d_{kl}$ の形で与えられていますが、 $\beta_1$ は $-0.1$ から $-5$ の範囲で定められていることから不効用が比較的小さく設計されており、ブロックをまたぐような移動が起きやすい設計になっています。
まとめ
今回は、生成されたダミーデータをもとに推定し、反実仮想分析を行うまでの流れを実装例とともにご紹介しました。実装をする中で私自身もモデル自体の理解が深まるとともに、ハイパーパラメターの設定によって結果が大きく変わることを実感し、自らで設計する際には望ましい見せ方に合わせた設定が必要だろうと感じました。
また、コードの実装に関しては実行速度の面で効率的でない部分を含む拙いコードであったことをお詫びいたします。コードに限らず記事の不備等ございましたらお気軽にご連絡ください。
参考文献
- Pu He, Fanyin Zheng, Elena Belavina, Karan Girotra (2020) Customer Preference and Station Network in the London Bike-Share System. Management Science 67(3):1392-1412.