前言
AE = Autoencoder
VAE = Variational Autoencoder
本文假定读者拥有AE的知识。从直观上,我们可以把AE理解成一个压缩器,事实上据我所知谷歌就有用AE来压缩文件,效率非常之高。
AE的缺点是: 不同的输入被映射到潜在空间中离散的点,点与点之间没有任何联系,白白浪费了大片的潜在空间,如下图。
而VAE的引入恰恰是为了填补点与点之间的真空。为了达到这一目的,只需要简单的两步操作,下面逐一解析。
扩大离散点范围
为了填补点与点之间的真空,很简单,扩大离散点的范围就可以了。那么,要怎么扩大一个点的范围呢?答案就是引入随机扰动,如下图:
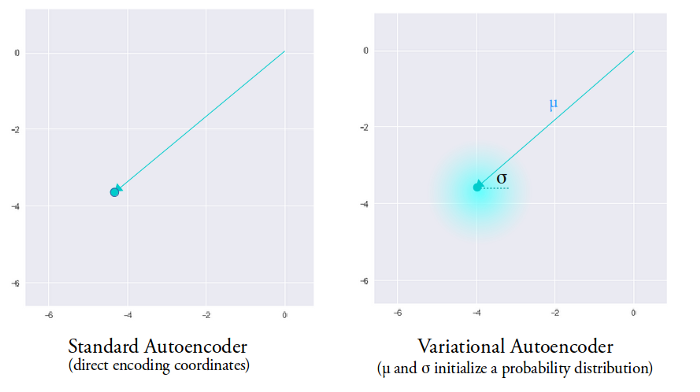
上帝赐予我们的随机数,将初始手枪变成了散弹枪。
关于VAE的解释,我强烈推荐一篇博客:《Intuitively Understanding Variational Autoencoders》。谷歌一下就能找到,在我找到窍门之前花了很长时间翻了许多博客,这篇绝对是讲的最好的(写有Intuitive的总是好的)。
可是几乎所有人,都遵循原论文的步骤引入随机数——使用mean和varian来模拟概率分布。这就是使用VAE的最大门槛。
事实上,要使用随机数可以很简单——直接使用随机数就好了,没必要人为模拟概率分布,随机数本身就是符合正态分布的。示例代码如下,效果完全符合上图。
def add_disturbance(self, z):
epsilon = torch.randn(z.shape)
return z + epsilon
可是,加入随机变量之后,各个点还是可以分的很开,因为潜在空间是无限大的,在没有加入限制的情况下,各个点没有理由聚合到一起,所以我们必须引入下一步,也是最后一步:
聚合离散点
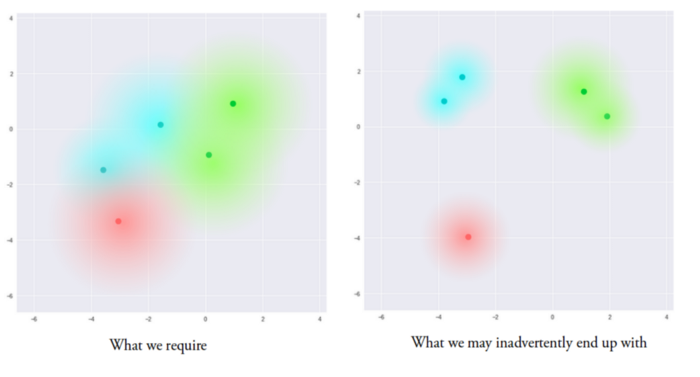
如上图所示,左边是我们想要的,可是如果没有聚合限制,经过步骤一我们只能得到右图的结果。
那么怎么才能聚合离散点呢? 很简单,我们只要引入一个锚点就好了。这个锚点可以是潜在空间的任意一个点,直接用torch.randn就能得到——或者,我们可以直接用坐标原点。接下来我们可以计算各个点到锚点的距离,将这个距离定义为我们的loss,接下来只要减小loss就好了。事实上唬人的KL Loss做的正是这样一件事。
KL = z.pow(2).sum().sqrt() # Force z decay to zero
如果只有KL loss,各个点只要落到原点就完事了,这不是我们想要的,可是因为我们还有重建Loss(不要忘了,这是AE的主要目标),只要将两个loss加起来一起优化,就会达到一个平衡。
这就是VAE。
再说说重建Loss,原论文的重建Loss也显得非常吓人,所以下面我再将重建loss简化一下作为收尾。
简化重建Loss
# Pre define
self.MSE = nn.MSELoss(reduction='sum') # Sum is important
# ...
# x from input
z = self.get_z(x)
y = self.get_y(z)
reconstruction = self.MSE(y, x)
# sum up loss
loss = reconstruction + KL
以上就是VAE。
以下是结果示意图。第一行是原图,第二行是重建后的图,第三行是第一个数字到第二个数字的变迁图。
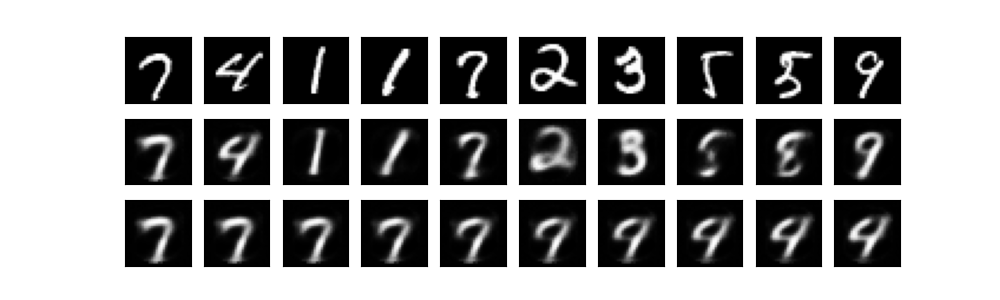
我们可以看到要实现VAE根本不需要概率论,少一点概率论,我们能够活的更好。我将这个实现命名为poor man's VAE,如果有人在论文里用到了这个实现,请至少告知我,谢谢。
代码
代码托管在github: https://github.com/zhuobinggang/poor-man-VAE 主要部分如下:
class My_VAE_V2(nn.Module):
def __init__(self, z_dim):
super().__init__()
self.fw1 = nn.Linear(28*28, 28*14)
self.z_layer = nn.Linear(28*14, z_dim)
self.fw2 = nn.Linear(z_dim, 28*14)
self.recover_layer = nn.Linear(28*14, 28*28)
self.MSE = nn.MSELoss(reduction='sum')
def _encoder(self, x):
z = self.add_disturbance(self.z_layer(F.sigmoid(self.fw1(x))))
return z
def add_disturbance(self, z):
epsilon = torch.randn(z.shape)
return z + epsilon
def _decoder(self, z):
o = F.sigmoid(self.recover_layer(F.sigmoid(self.fw2(z))))
return o
def forward(self, x):
z = self._encoder(x)
o = self._decoder(z)
return o, z
def loss(self, x):
z = self._encoder(x)
KL = z.pow(2).sum().sqrt() # Force z decay to zero
y = self._decoder(z)
reconstruction = self.MSE(y, x)
return KL + reconstruction