概要
今回はABEJA Platformを利用し、ローカル学習 (train-local) を紹介します。
なぜローカル学習なの?
ABEJA Platformは、機械学習におけるデータ準備・アノテーション・開発・学習・モデル変換・デプロイ、これら全体のパイプラインをサポートしているサービスです。もちろん、その機能の一部を使うことも可能です。例えば、開発のみをABEJA Platform のJupyter Notebookで行うことや、学習・デプロイのみをABEJA Platform上で行うことも可能です。今回は、すでに機械学習環境(GPUマシンなど)を保有しているユーザが、既存のオンプレミス環境を、なるべく活用し、ABEJA Platformと連携利用する方法を紹介します。
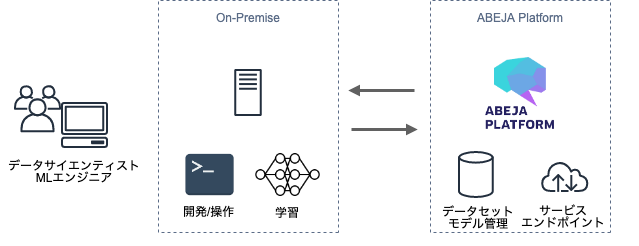
実施すること
サンプルコード (KerasでVGG16を利用した画像分類判別) を利用し、モデル作成をローカルで実施していきましょう。
早速やってみる
前準備
ローカル学習(train-local)では、ABEJA Platform CLIを利用します。
ABEJA Platform CLIの導入については、こちらをご参考ください。
※注意
- ABEJA Platform CLIはPython3.5以降が対応しています。
- Windowsには一部対応しているのですが、動作保証対象外となっていますので、ご注意ください!
- Dockerが必要になりますので、事前にDockerを起動しておきます。
- もし、Amazon Linux2などでDockerが起動しないようなら、以下のコマンドを試してみましょう。その後、SSHなどで繋げている場合は、一度、ログアウト/ログインを実施してください。
docker Groupに[username]のユーザを参加させます。
$ sudo gpasswd -a [username] docker
ローカル学習(train-local)の実施
train-localコマンド
ABEJA Platformでは、以下のコマンド(CLI)を利用し、ローカル学習を実行できます。
$ abeja training train-local
利用方法は公式ドキュメントにも記載されています。
いくつか、利用方法をご紹介します。 (以下のようなmain.pyを利用の場合)
... (省略)
def handler(context):
dataset_alias = context.datasets
dataset_id = dataset_alias['dataset_name']
... (省略)
■サンプル①
-
-h:呼び出す関数のパスを指定。サンプルはmain.pyのhandlerを呼び出し。 -
-i:イメージの指定。「abeja/all-cpu:18.10」or 「abeja/all-gpu:18.10」を選択指定 -
--organization_id:ABEJA Platform組織ID。組織IDの確認方法はこちら -
--datasets:使用するデータセットを次のフォーマットにて指定。{dataset_name}:{dataset_id}
( 例えば、ABEJA Platform上にあるデータセットdemo-dataset(データセット名:demo-dataset、データセットID:1000000000) を上記のmain.pyを使って呼び出す場合、データセット名dataset_name、データセットID1000000000を指定
$ abeja training train-local \
-h main:handler \
-i abeja/all-cpu:18.10 \
--organization_id 1234567890123 \
--datasets dataset_1:1000000000
■サンプル②
-
-h:呼び出す関数のパスを指定。サンプルはmain.pyのhandlerを呼び出し -
-i:イメージの指定。「abeja/all-cpu:18.10」or 「abeja/all-gpu:18.10」を選択指定 -
--organization_id:ABEJA Platform組織ID。組織IDの確認方法はこちら -
--environment:環境変数を指定。NUM_EPOCHS:10など -
--no_cache:再ビルドを行い、イメージを作り直し
$ abeja training train-local \
-h main:handler \
-i abeja/all-cpu:18.10 \
--organization_id XXXXXXXXXXXXXX \ # 組織IDを入力してください
--environment NUM_EPOCHS:10 \
--no_cache
他に以下のようなオプションも選択いただけます。
-
--runtime:docker run コマンドの --runtime オプションに相当。例えば、「nvidia-docker」など。 -
--build-only:imageのビルドだけを実施。学習は行わない場合に指定 -
--quiet:info ログの出力を抑制
実行
今回はタイトルの通りKerasでVGG16を利用し、画像分類判定を実施します。
サンプルコードはこちらです。
ローカルで学習を実施したい端末にコードを配置します。
今回はtrain_vgg.pyのhandlerを呼び出し、ローカルで学習させます。
すでにPlatform上で作成したデータセットも利用できます。
コードを配置したフォルダ上で、以下のコマンドを実行します。
$ abeja training train-local \
-h train_vgg:handler \
-i abeja/all-cpu:18.10 \
--organization_id XXXXXXXXXXXXXX \ # 組織IDを入力してください
--datasets train:XXXXXXXXXXXXXX # データセットIDを入力してください
すると、以下のような実行状況(infoログ)が出力されてきます。 ( --quitで出力を抑制することも可能です。)
[username@XXXXXX train-folder]$ abeja training train-local -h train_vgg:handler -i abeja/all-cpu:18.10 --organization_id XXXXXXXXXXXXXX --datasets train:XXXXXXXXXXXXXX
[info] preparing image : abeja/all-cpu:18.10
[info] building image
[info] start training job
INFO: start installing packages from requirements.txt
INFO: packages are installed from requirements.txt
INFO: Loading user model handler with train_vg:handler...
Using TensorFlow backend.
load dataset from api
x_train shape: (2367, 128, 128, 3)
2367 train samples
1015 test samples
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
8192/58889256 [..............................] - ETA: 18:33
40960/58889256 [..............................] - ETA: 7:25
106496/58889256 [..............................] - ETA: 4:16
245760/58889256 [..............................] - ETA: 2:28
524288/58889256 [..............................] - ETA: 1:26
974848/58889256 [..............................] - ETA: 55s
1974272/58889256 [>.............................] - ETA: 31s
... (省略)
Dockerイメージが準備され、必要なパッケージのインストール、学習に必要なデータセット、Weights File(重みデータ)のダウンロードが開始されているのがわかります。
その後、以下のinfoログが出力され、学習が始まります。
... (省略)
Train on 2367 samples, validate on 1015 samples
Epoch 1/5
32/2367 [..............................] - ETA: 2:00 - loss: 0.8370 - acc: 0.5312
64/2367 [..............................] - ETA: 1:54 - loss: 0.8450 - acc: 0.5000
96/2367 [>.............................] - ETA: 1:51 - loss: 0.8465 - acc: 0.5104
128/2367 [>.............................] - ETA: 1:49 - loss: 0.8477 - acc: 0.5078
160/2367 [=>............................] - ETA: 1:47 - loss: 0.8147 - acc: 0.5312
192/2367 [=>............................] - ETA: 1:45 - loss: 0.8184 - acc: 0.5208
224/2367 [=>............................] - ETA: 1:43 - loss: 0.8072 - acc: 0.5357
256/2367 [==>...........................] - ETA: 1:42 - loss: 0.8042 - acc: 0.5391
... (省略)
今回はEpochを[5]に指定していますが、学習にあわせてこちらは調整してください。
しばらく待つと、以下のような結果が表示されます。
... (省略)
2112/2367 [=========================>....] - ETA: 12s - loss: 0.4488 - acc: 0.7784
2144/2367 [==========================>...] - ETA: 10s - loss: 0.4485 - acc: 0.7775
2176/2367 [==========================>...] - ETA: 9s - loss: 0.4500 - acc: 0.7753
2208/2367 [==========================>...] - ETA: 7s - loss: 0.4501 - acc: 0.7754
2240/2367 [===========================>..] - ETA: 6s - loss: 0.4504 - acc: 0.7750
2272/2367 [===========================>..] - ETA: 4s - loss: 0.4508 - acc: 0.7742
2304/2367 [============================>.] - ETA: 3s - loss: 0.4497 - acc: 0.7747
2336/2367 [============================>.] - ETA: 1s - loss: 0.4484 - acc: 0.7740
2367/2367 [==============================] - 156s 66ms/step - loss: 0.4495 - acc: 0.7727 - val_loss: 0.4417 - val_acc: 0.7980
Test loss: 0.44168092913815543
Test accuracy: 0.7980295571200366
INFO: resource usage. execution duration: 829 seconds, memory: 5 MB
Validation datasets Test結果がlossとaccuracyと表示され精度を確認することが可能です。
その後、コマンド実行フォルダに**「model.h5」**というモデルファイルが生成されています。
このモデルファイルを利用し、ABEJA Platform上でデプロイを実施することで、HTTPサービスや、トリガーに利用することも可能です。
最後に
今回はローカル学習(train-local)を利用し、ローカル環境で学習・モデルファイルを作成するまでを実施してみました。
オンプレミス環境で機械学習を行っているデータサイエンティストや ML エンジニアに向けて、オンプレミス環境を活かしつつ、必要に応じて ABEJA Platformを利用する方法となります。また、今後、ABEJA Platformでは、train-localをより大幅に使いやすくアップデートが予定されています。是非、ご期待ください。
ABEJA Platformは、ユーザとコミュニティを形成しながら、速いスピードで開発を進めていきます。
以下、フォーラムもありますので、是非、ご活用ください!