目的
Google Colab で GPU を ON にして PyTorch で MNIST データセットを用いた深層学習を試しました。以下実施手順と簡単な説明を示します。
手順
1. Google Colab へログイン
ブラウザから Google Colab にアクセスして、ファイル > Python3 の新しいノートブックを選択し、開きます。
ノートブック画面で ランタイム > ランタイムのタイプを変更 を選択し、ハードウェアアクセラレータをデフォルトの "None" から "GPU" に変更します。
2. ノートブックの編集
ノートブックのコードセルに下記一つずつ順番に入力し、Shift + Enter にて実行していきます(全実行結果はこちら)。
まず、今回利用するライブラリとして PyTorch と scikit-learn をインストールします。
# 0. PyTorch と scikit-learn のインストール
!pip install torch torchvision
!pip install scikit-learn
インストールしたライブラリの import とGPUを利用するフラグを ON にし、学習データとして "mnist_784" を用います。
"mnist_784" は元々は MNIST Database にあるものを28×28ピクセルの画像データとして適宜整形されたものとの。詳しくはそれらサイトか こちらの解説 を参照。
# 1. ライブラリインポートと学習データのダウンロード
import torch
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
X, y = fetch_openml('mnist_784', version=1, return_X_y=True)
X = X / 255
y = [float(s) for s in y]
仮に7番目のデータを表示させてみます。
# 学習データの表示例
plt.imshow(X[7].reshape(28,28), cmap=plt.cm.gray)
print("{:.0f}".format(y[7]))
PyTorch で学習させるにあたって DataLoader というデータ形式に落とし込む必要があり、次のようにダウンロードしてきたデータをトレーニング用と検証用に分けた上で作成します。
# 2. DataLoader作成
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/7, random_state=0)
print(type(y_train[0]))
X_train = torch.Tensor(X_train)
X_test = torch.Tensor(X_test)
y_train = torch.LongTensor(y_train)
y_test = torch.LongTensor(y_test)
ds_train = TensorDataset(X_train, y_train)
ds_test = TensorDataset(X_test, y_test)
loader_train = DataLoader(ds_train, batch_size=64, shuffle=True)
loader_test = DataLoader(ds_test, batch_size=64, shuffle=False)
ネットワークとしてここでは入力層のデータ数は 画像のピクセル数と同じ "28×28", 2つの隠れ層のデータ数は "100" とし、出力層は"0, 1, 2, ..., 9" という文字数に対応する "10" とし、層同士の接続は全結合(Full Connected = fc)で活性化関数は ReLU を用いています。
こちら の記事では、例として 入力層"4", 隠れ層1つ目 "10" で2つ目 "8" , 出力層 "4" の場合のネットワークが示されています(下図引用)。
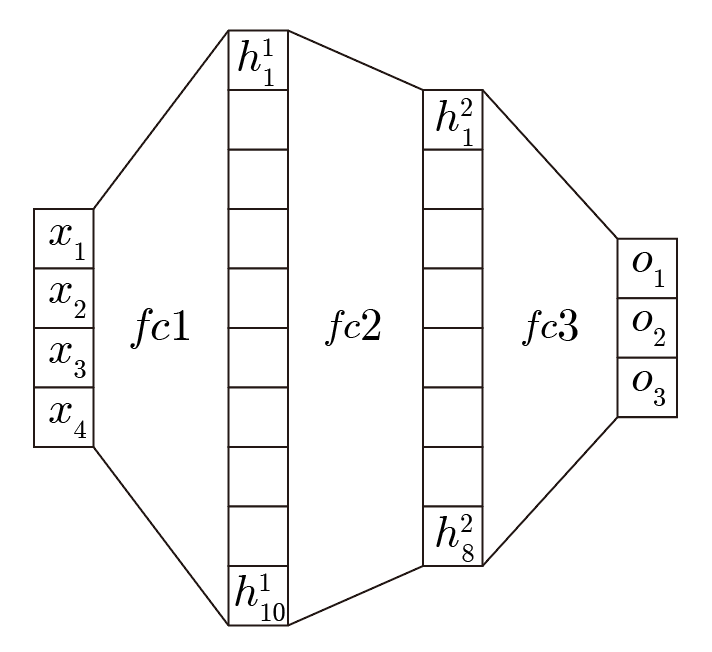
またネットワークの書き方についてもいくつか書き方があるそうで、こちらでは Keras の Sequential な書き方を用いました。
# 3. ネットワーク構築
from torch import nn
model = nn.Sequential()
model.add_module('fc1', nn.Linear(28*28*1, 100))
model.add_module('relu1', nn.ReLU())
model.add_module('fc2', nn.Linear(100, 100))
model.add_module('relu2', nn.ReLU())
model.add_module('fc3', nn.Linear(100, 10))
model.to(device)
print(model)
学習で利用する誤差関数をクロスエントロピー損失関数、最適化手法をAdam を設定します。
# 4. 誤差関数と最適化手法の設定
from torch import optim
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
学習1回あたりの手続きを次のように関数にします。今回 GPU で学習させるため data.cuda() や target.cuda() というように途中で cuda 用のデータに変換しています。
# 5. 学習の設定
def train(epoch):
model.train()
for data, targets in loader_train:
data, targets = data.cuda(), targets.cuda()
optimizer.zero_grad()
outputs = model(data)
loss = loss_fn(outputs, targets)
loss.backward()
optimizer.step()
print("epoch{}:終了\n".format(epoch))
モデルにデータ与えて推論処理させた結果がどれほどの精度かチェックする関数を次のように定義します。
# 6. 推論の設定
def test():
model.eval()
correct = 0
with torch.no_grad():
for data, targets in loader_test:
data, targets = data.cuda(), targets.cuda()
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
correct += predicted.eq(targets.data.view_as(predicted)).sum()
data_num = len(loader_test.dataset)
print('\nテストデータの正解率:{}/{}({:.0f}%)\n'.format(correct, data_num, 100. * correct /data_num))
確認として、学習前のモデルで精度を観てみます。
# 学習前のテストデータ正解率
test()
3回学習させて改めて精度を確認してみます。結果 をみると、学習前が 20% → 95% となっており、3エポックながら学習が有効であることが分かります。
# 7. 学習後のテストデータ正解率
for epoch in range(3):
train(epoch)
test()
試しに 2019番目のデータで予測結果と正解を比べてみます。正しく予想されています。
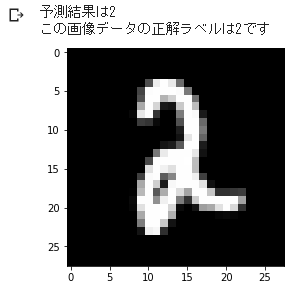
# 8. 2019番目データの予測と正解結果の確認
index = 2019
model.eval()
data = X_test[index]
data = data.cuda()
output = model(data)
_, predicted = torch.max(output.data, 0)
print("予測結果は{}".format(predicted))
X_test_show = (X_test[index]).numpy()
plt.imshow(X_test_show.reshape(28, 28), cmap='gray')
print("この画像データの正解ラベルは{:.0f}です".format(y_test[index]))
最後に利用した PyTorch のバージョンをみておきます。
# 利用した PyTorch のバージョン
print(torch.__version__)