はじめに
みなさんはDBのインデックスを正しく使えていますか?
私はなんとなく「DBのパフォーマンスを向上するためのもの」という認識はあったのですが、
どのような場面で使うものなのか、逆にどのような場面では使うべきでないのかなど
明確に理解できていませんでした。
今回はそんなインデックスについての理解を深めたいと思います。
インデックスとは
インデックスとは、その名の通り「索引」です。
表現の仕方と変えると、(x, a)という形式の配列であるとも言えます。
xというキー値とそれに結びつくaというデータ情報があり、
これを利用することですべてのデータを網羅して見ることなく、
まさに本の索引のように目的のデータにたどり着くことができます。
インデックスはSQLのパフォーマンスを改善するための非常にポピュラーな手段であり、
理由としては下記の3点が挙げられます。
- アプリケーションのコードに影響を与えない
- テーブルのデータに影響を与えない
- 性能改善の効果が大きい
それぞれ説明していきます。
1. アプリケーションのコードに影響を与えない
インデックスを使うかどうかはDBMSが自動的に判断します。
そのため、インデックスを使う場合はDBにインデックスを作成するだけで良く、
アプリケーションの実装を変更する必要はありません。
DBMSが常にユーザーの意図した実行計画を作成出来るとは限らないため、
意図しない実行計画が作成されないよう、必要に応じてSQLのヒント句で利用するインデックスを指定しなければならない場合もあります。
2. テーブルのデータに影響を与えない
インデックスを作成してもデータの中身が影響を受けたり、テーブルの構造が変化することはありません。
3. 性能改善の効果が大きい
インデックスの性能はデータ量に対して劣化しにくいため、
多くの場合デメリットをメリットが大きく上回ります。
代表的なインデックス
インデックスにはいくつかの種類がありますが、代表的なものがB-treeインデックスです。
B-treeインデックスは各キー値の間で検索速度にばらつきが少ない、パフォーマンスが低下しにくい、検索・挿入・更新・削除のいずれの処理もそこそこ速い、不等号を使っても効果が出る、など利用することでバランス良く効果が出るようなインデックスです。
B-treeインデックス
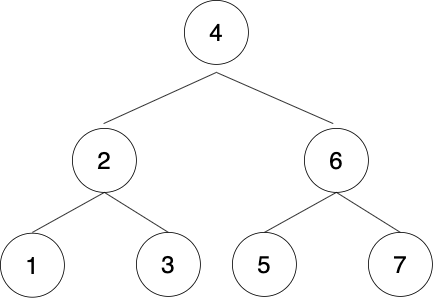
B-treeは木構造でデータを保持します。
最下位のリーフと呼ばれるノードだけが実データに対するポインタを保持しており、
最上位のノードから順にノードをたどってリーフから実データを見つけにいきます。
例えば、「5」というデータを探す場合、
木構造でデータを保持していないと
1→2→3→4→5 と先頭から順に探していきます。
一方下図のように木構造でデータを保持している場合、
- 5は4より大きいので右側に進む
- 5は6より小さいので左側に進む
- 5が見つかる
というように、少ない計算量で目的のデータを見つけることができます。
以降、本記事ではインデックスと呼ぶものはB-treeインデックスとして記述します。
インデックスはどの列に作れば良いか?
インデックスはやみくもに作ればよいわけではなくいくつかの指針があります。
それは主に下記のような指針です。
- 大規模なテーブルに対して作成する
- カーディナリティの高い列に作成する
- WHERE句の選択条件または結合条件に使用されている列に作成する
1. 大規模なテーブルに対して作成する
データ量が少ないときにはインデックスを使うよりもフルスキャンのほうが高速な場合もあります。
環境によって差はありますが、あまりデータ量が多くないテーブルに対してインデックスを作成しても
効果は薄いと考えられます。
2. カーディナリティの高い列に作成する
カーディナリティとは、「特定の列の値がどのぐらいの種類の多さを持つか」を表す概念です。
例えば、「性別」というテーブルがあった場合、
- 男性
- 女性
- 不詳
という3つの種類しかない場合、カーディナリティは「3」です。
一方で、「口座番号」のように多くの種類があると想定される列に対しては
インデックスの効果が高いと考えられます。
3. WHERE句の選択条件または結合条件に使用されている列に作成する
先にも説明したように、B-treeインデックスでは特定のデータと比較することで
目的のデータまで効率的にたどり着くことができます。
そのためインデックスはSQLで検索条件や結合条件として使用される列に作成する必要があります。
また、検索条件に使用する場合も下記のようなパターンではインデックスを利用できていません。
パターン1: インデックス列に演算を行っている
SELECT * FROM SomeTable WHERE col_1 * 1.1 > 100;
上記のようなSQLの場合、col_1という列にインデックスが存在していても
インデックスを利用することができません。
これはあくまでインデックスの中で保持されているデータは「col_1」に対してであり、
「col_1 * 1.1」ではないためです。
SELECT * FROM SomeTable WHERE col_1 > 100/1.1
のように書けばこの問題は回避することができます。
パターン2: 索引列に対してSQL関数を適用している
SELECT * FROM SomeTable WHERE SUBSTR(col_1, 1, 1) = 'a';
この場合もパターン1と同様、インデックスの中に存在する値はあくまでcol_1のため
インデックスを利用できません。
パターン3: IS NULL述語を使っている
SELECT * FROM SomeTable WHERE col_1 IS NULL;
B-treeインデックスは一般的にnullについてはデータの値とはみなさず、保持していません。
そのためIS NULLまたはIS NOT NULL述語に対しては有効ではありません。
パターン4: 否定形を用いている
SELECT * FROM SomeTable WHERE col_1 <> 100;
否定形の場合、利用したとしても検索範囲が広すぎて役に立たないという意味でインデックスは有効ではありません。
パターン5: ORを用いている
SELECT * FROM SomeTable WHERE col_1 = 99 OR col_1 = 100;
ORを用いた場合はインデックスが利用されませんが、INで書き換えることで回避できます。
SELECT * FROM SomeTable WHERE col_1 IN (99, 100);
パターン6: 後方一致、または 中間一致のLIKE述語を用いている
SELECT * FROM SomeTable WHERE col_1 LIKE '%a';
SELECT * FROM SomeTable WHERE col_1 LIKE '%a%';
上記のように後方一致または中間一致のLIKE述語を用いている場合、インデックスは利用できません。
これは、1文字目がワイルドカードになっている場合、B-treeインデックスの構造上フルスキャンするしかないためです。
下記のように前方一致検索の場合のみインデックスは利用可能です。
SELECT * FROM SomeTable WHERE col_1 LIKE 'a%';
パターン7: 暗黙の型変換を行っている
SELECT * FROM SomeTable WHERE col_1 = 10;
col_1列が文字列型の場合、上記のSQL文では暗黙の型変換が行われますが、
この場合インデックスは利用されません。
その他の注意点
インデックスは主キー及び一意制約の列には作成不要です。
これは、主キー制約や一意制約を作成する際、内部的にはB-treeインデックスを作成しているためです。