はじめに
Sagemaker studio でとりあえず Pyspark 試したい。。
でも実装するには IAM とか VPC とか細かく設定しなきゃいけないっぽい。。しかも後ろで EMR が動いてるとかもう無理。。
そう思って断念しかけたのですが、とても便利なテンプレートがありました!!!
こちらの記事で紹介されている CloudFormation スタックのテンプレートです。
以下のリンクからスタックの作成画面に飛びます。
https://console.aws.amazon.com/cloudformation/home?region=us-east-1#/stacks/new?stackName=blog&templateURL=https://aws-ml-blog.s3.amazonaws.com/artifacts/ml-1954/template.yaml
実装手順
今回はとにかく最小限の労力で SageMaker Studio で PySpark が使える環境を作ることを目的としています。(なので、権限設定やネットワークについてはデフォルトの設定で行います)
スタックの作成
以下のテンプレートリンクをクリックして AWS のコンソールにサインインし、スタックの作成画面を開く(サインインしたら自動で遷移します)。「次へ」をクリック。
https://console.aws.amazon.com/cloudformation/home?region=us-east-1#/stacks/new?stackName=blog&templateURL=https://aws-ml-blog.s3.amazonaws.com/artifacts/ml-1954/template.yaml
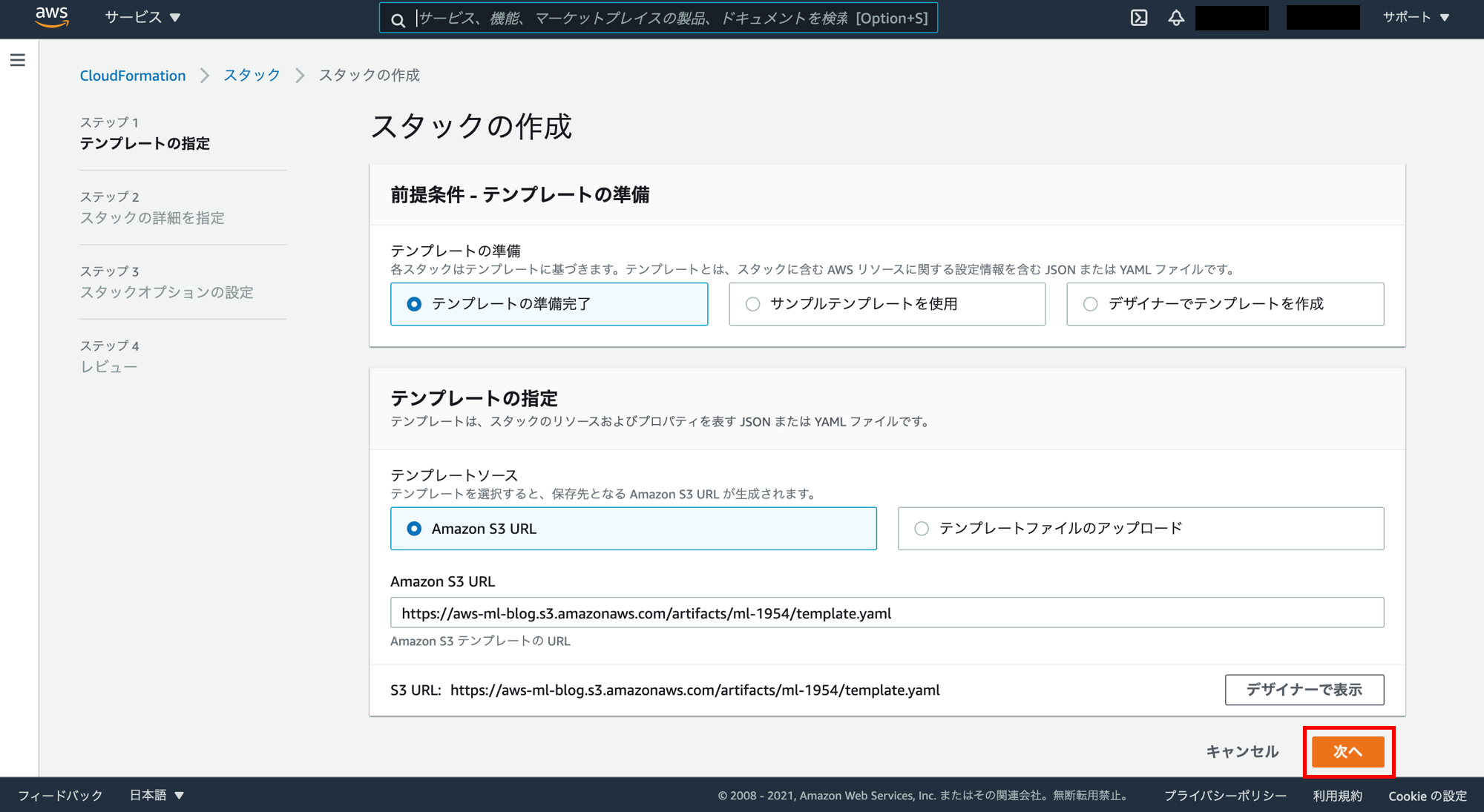
スタックの詳細を指定の画面。「次へ」をクリック。
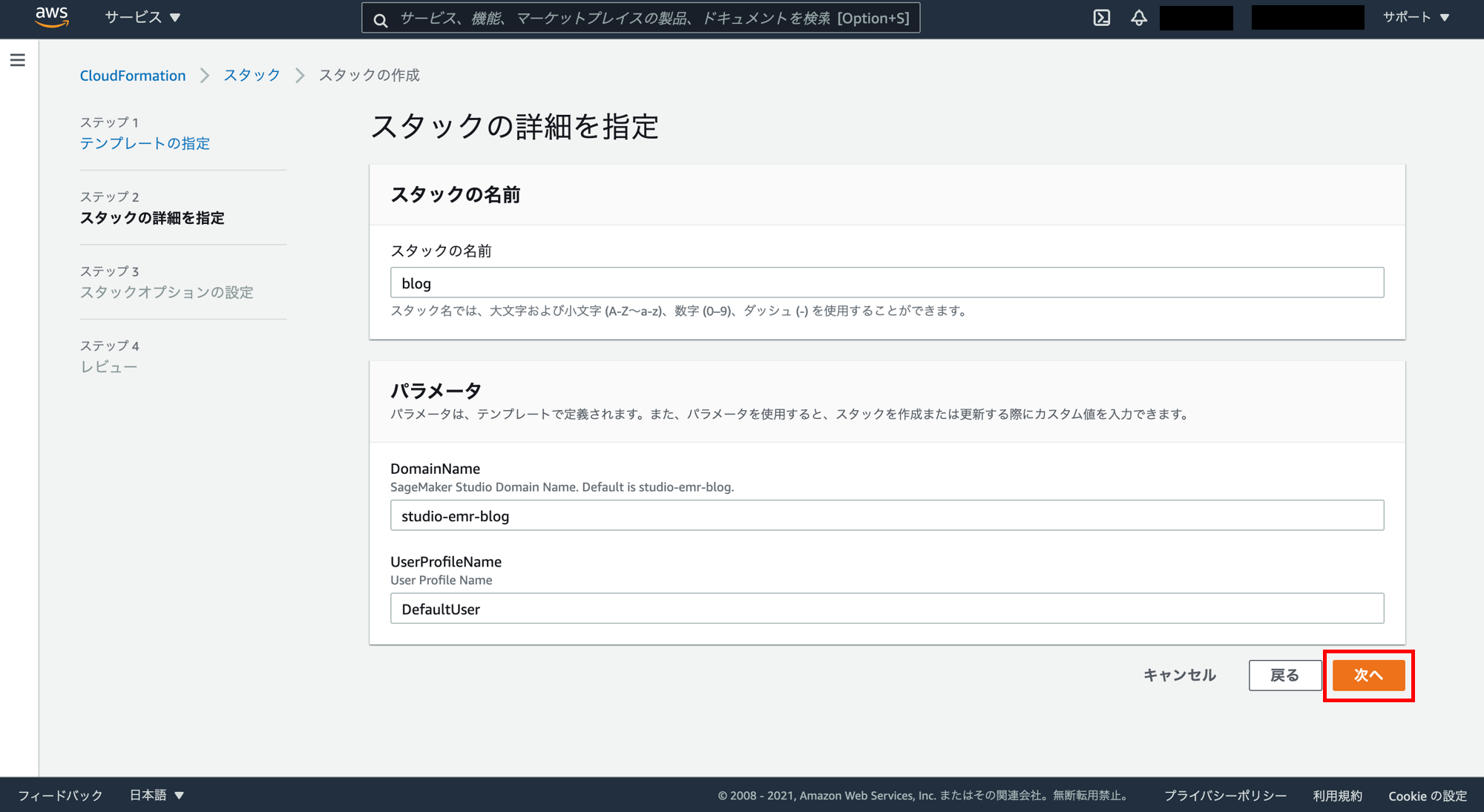
スタックオプションの設定の画面。「次へ」をクリック。
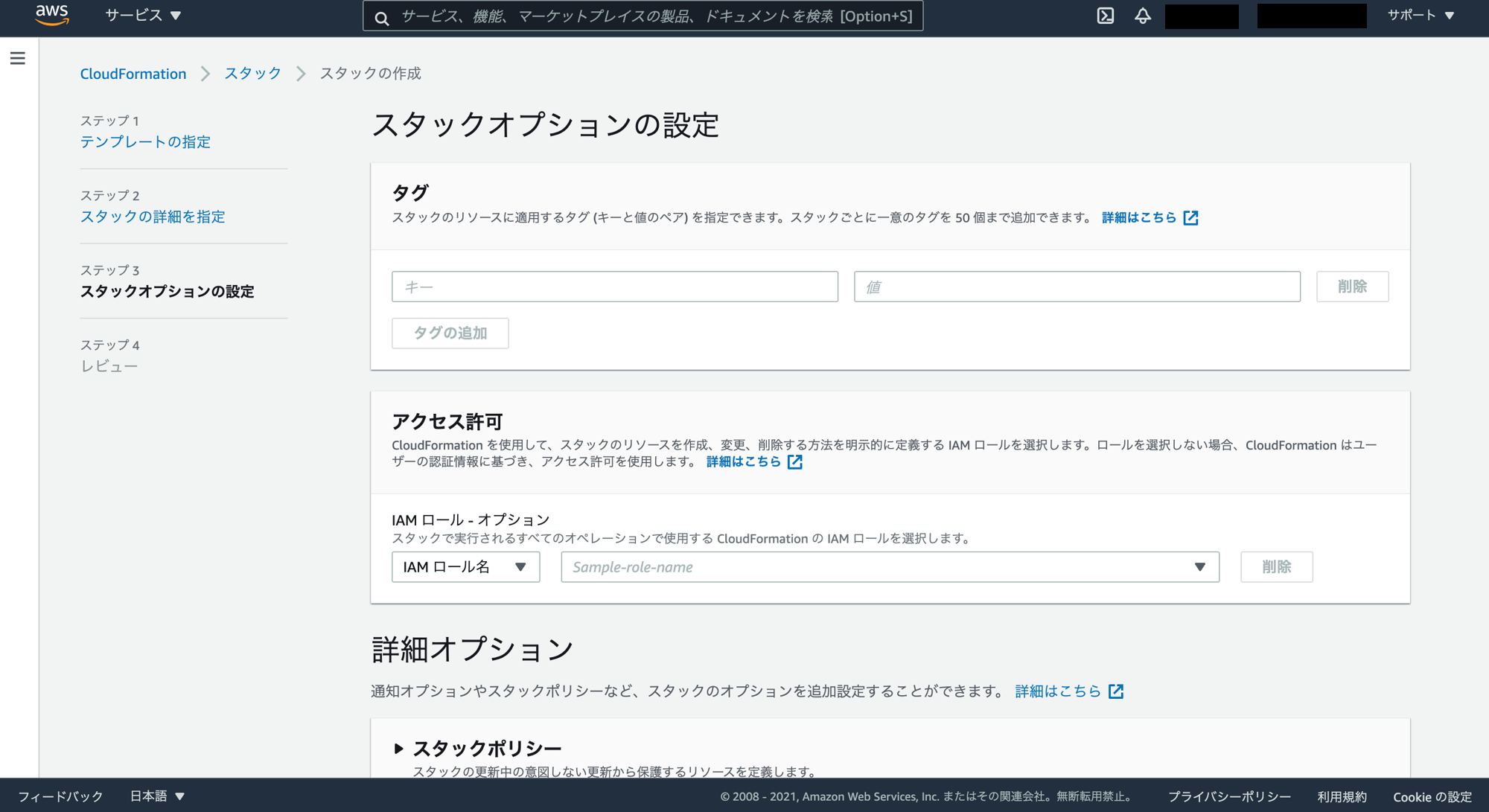
レビューの画面まで来たら一番下までスクロール。
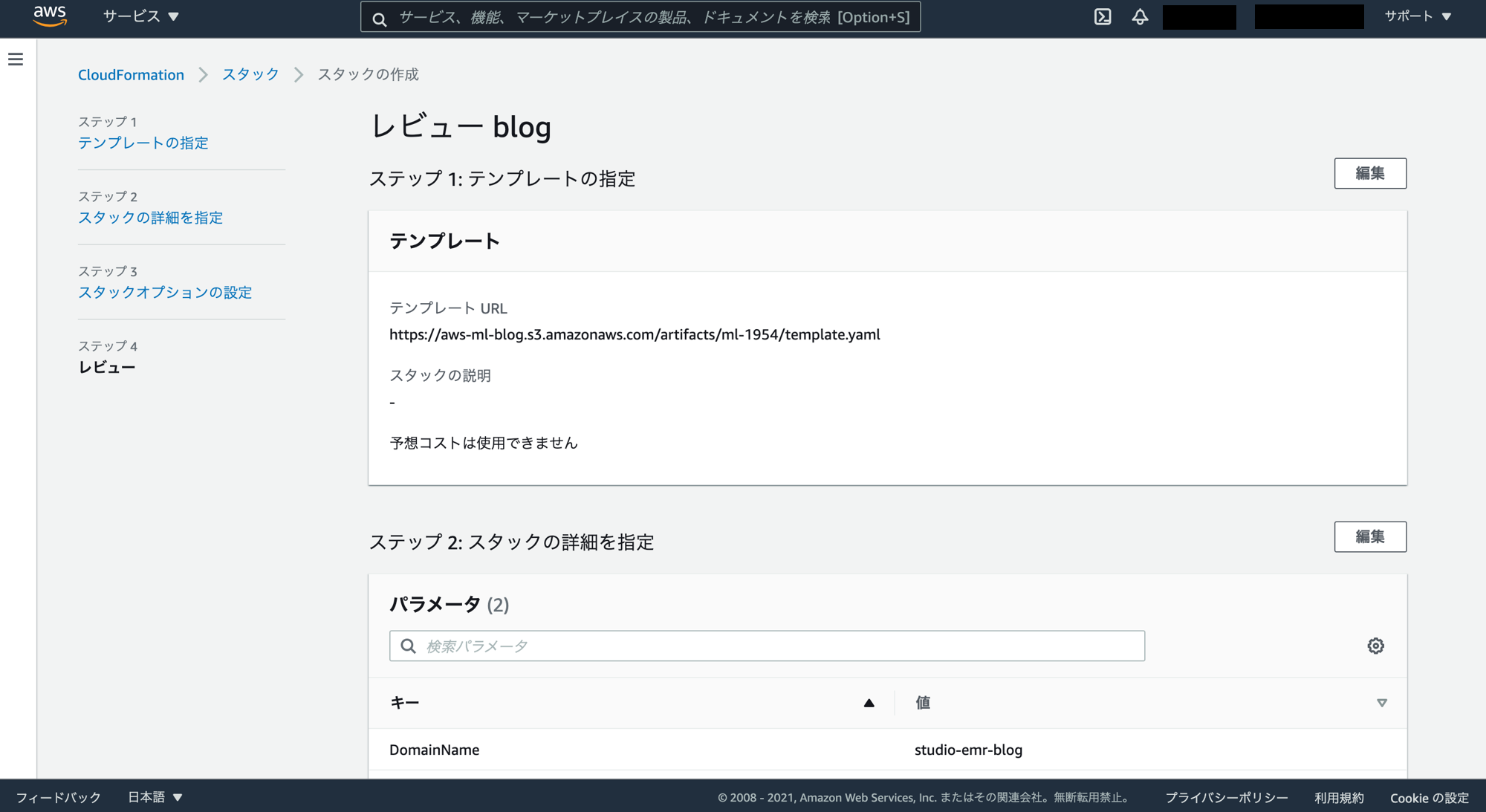
「AWS CloudFormation によって IAM リソースがカスタム名で作成される場合があることを承認します。」にチェックを入れ、「スタックの作成」をクリック。
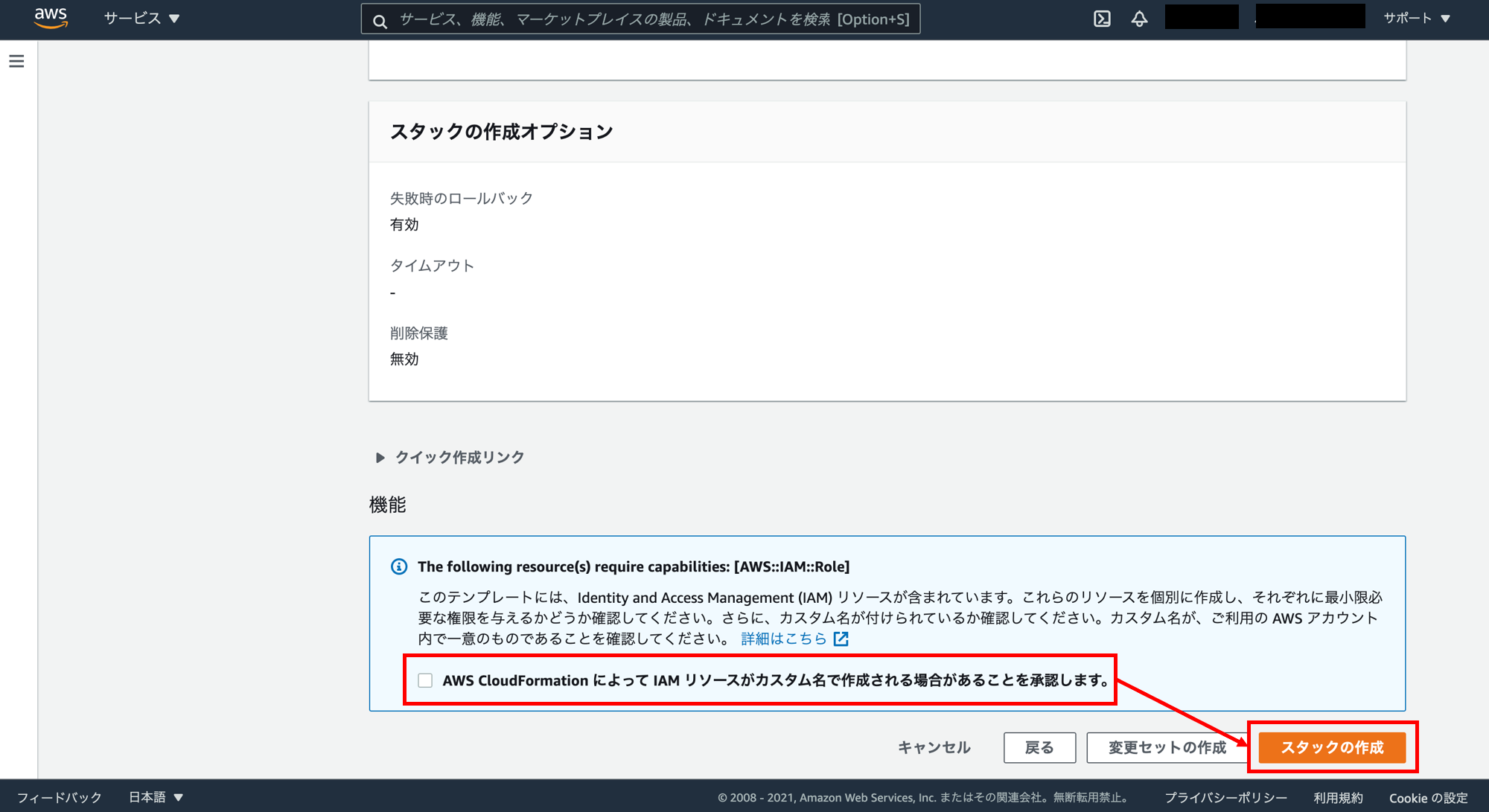
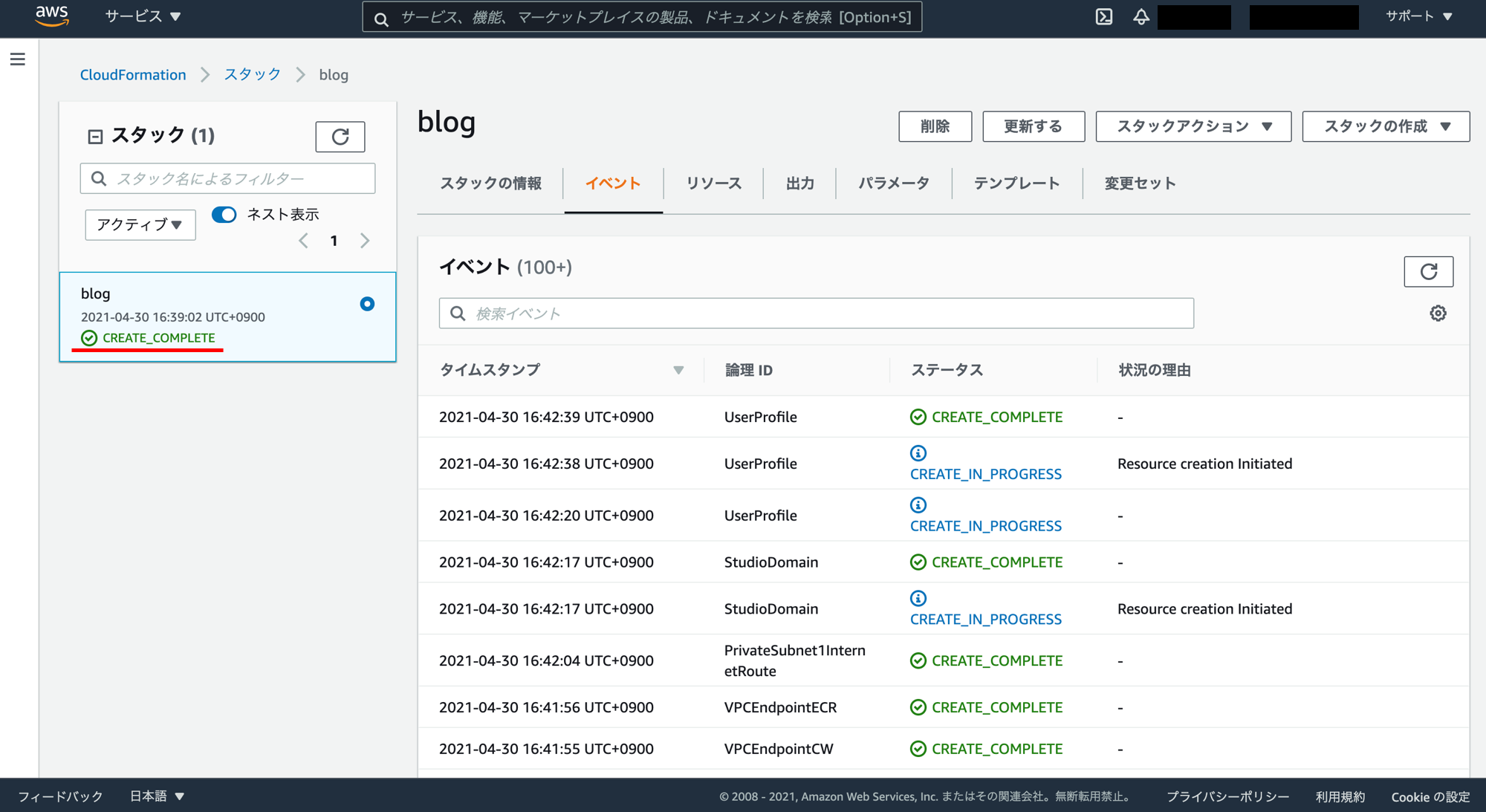
スタックの作成の進捗画面です。スタック名の下の「CREATE_IN_PROGRESS」が「CREATE_COMPLETE」になるまで待ちます。大体15分くらいかかります。
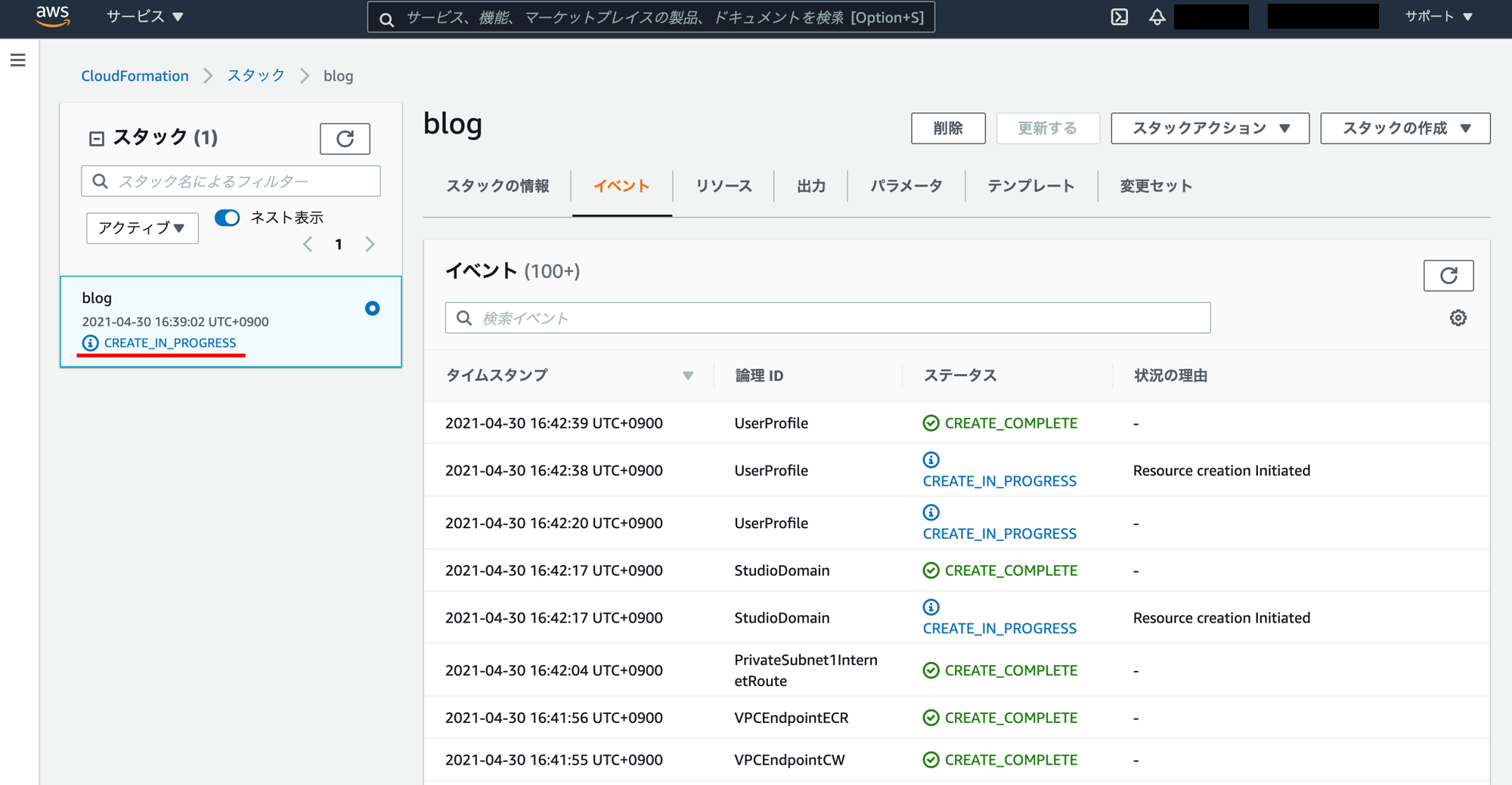
「CREATE_COMPLETE」になりました。
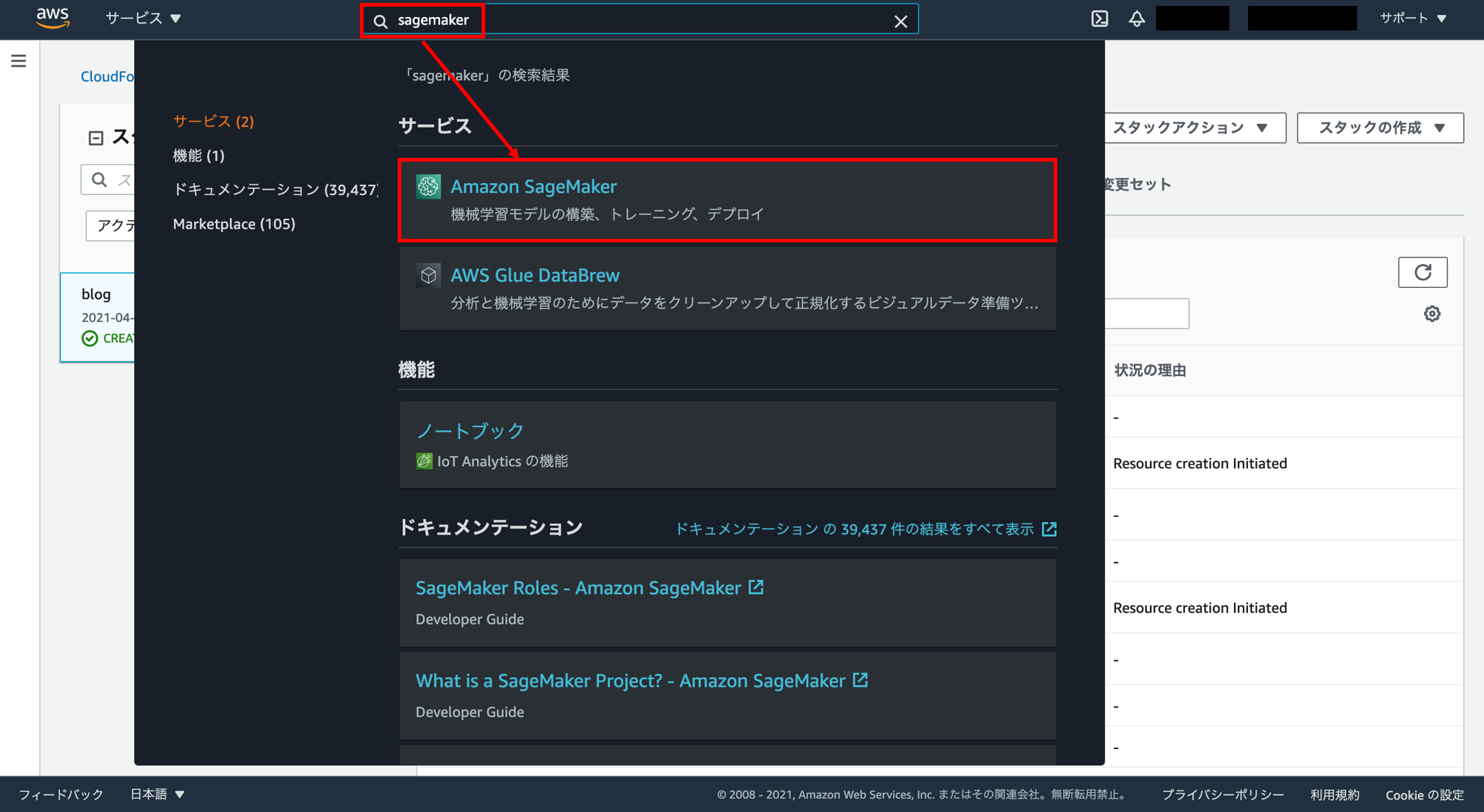
SageMaker Studio の起動
次に SageMaker を開きます。コンソールの検索窓に「sagemaker」と入力し、「Amazon SageMaker」をクリック。
「Open SageMaker Studio」をクリック。
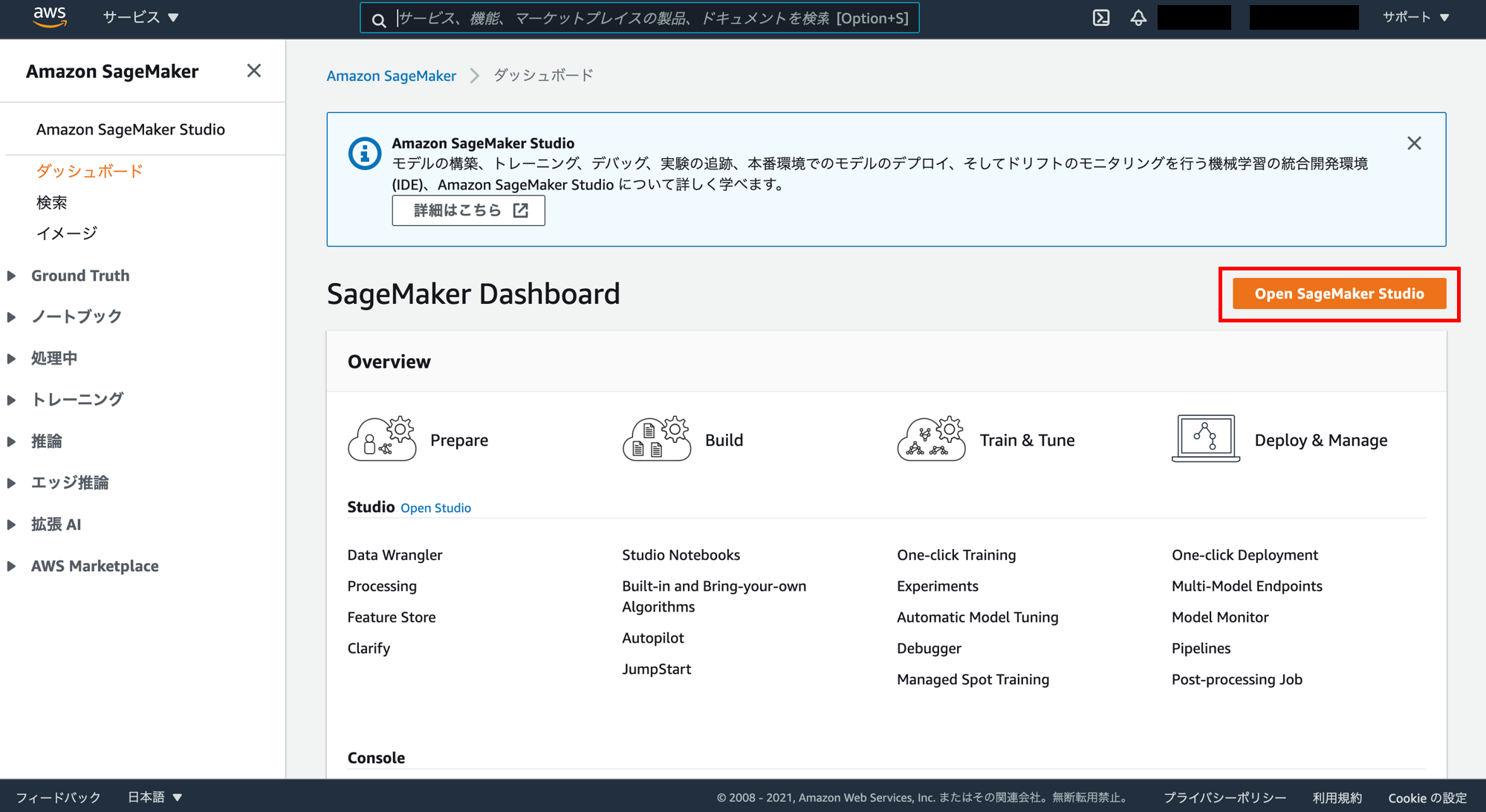
「defaultuser」というユーザーが作成されています。このユーザーの「Studioを開く」をクリック。
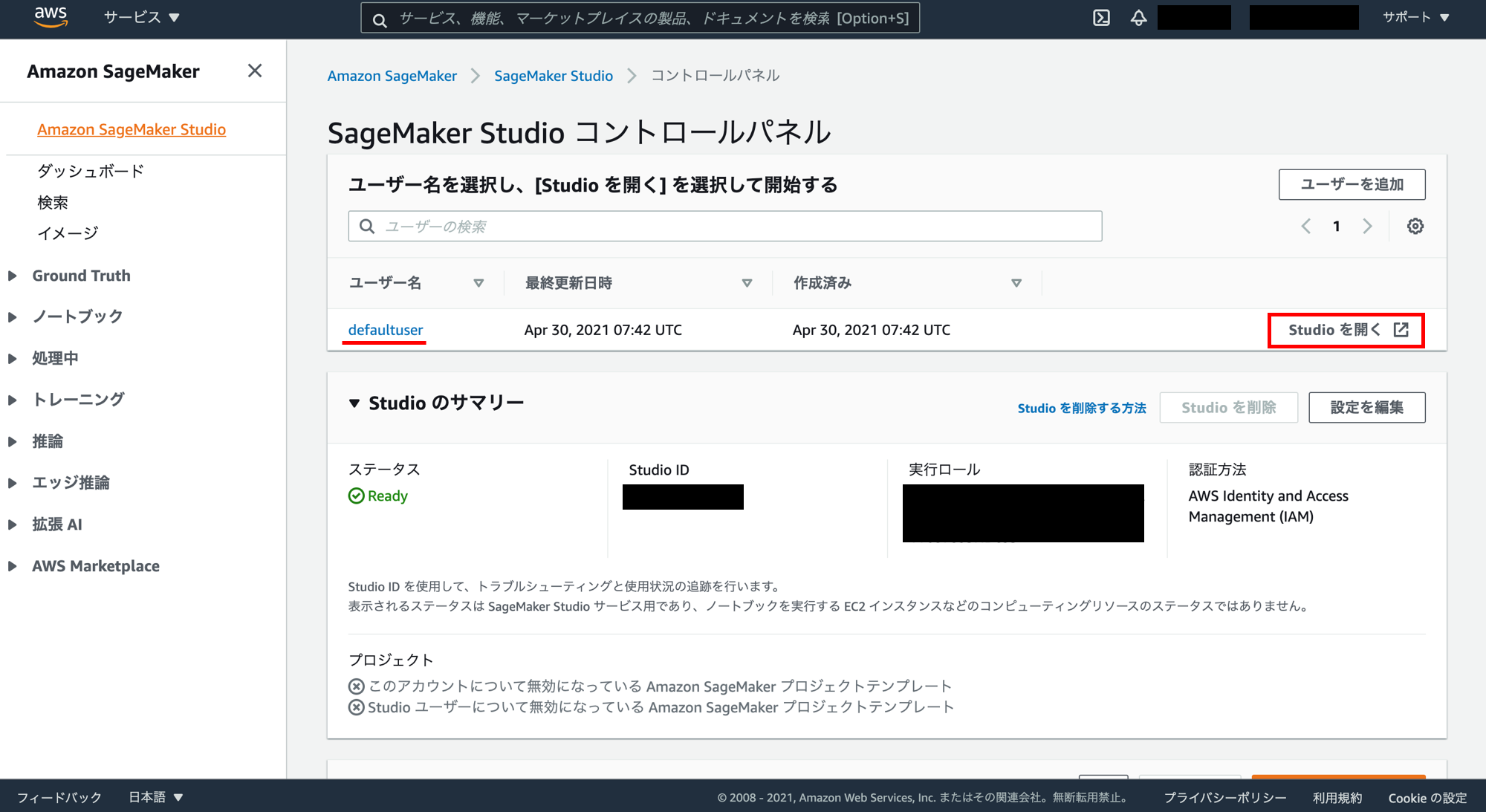
ブラウザの別タブで Amazon SageMaker Studio が開いたら「File」→「New」→「Terminal」をクリック。
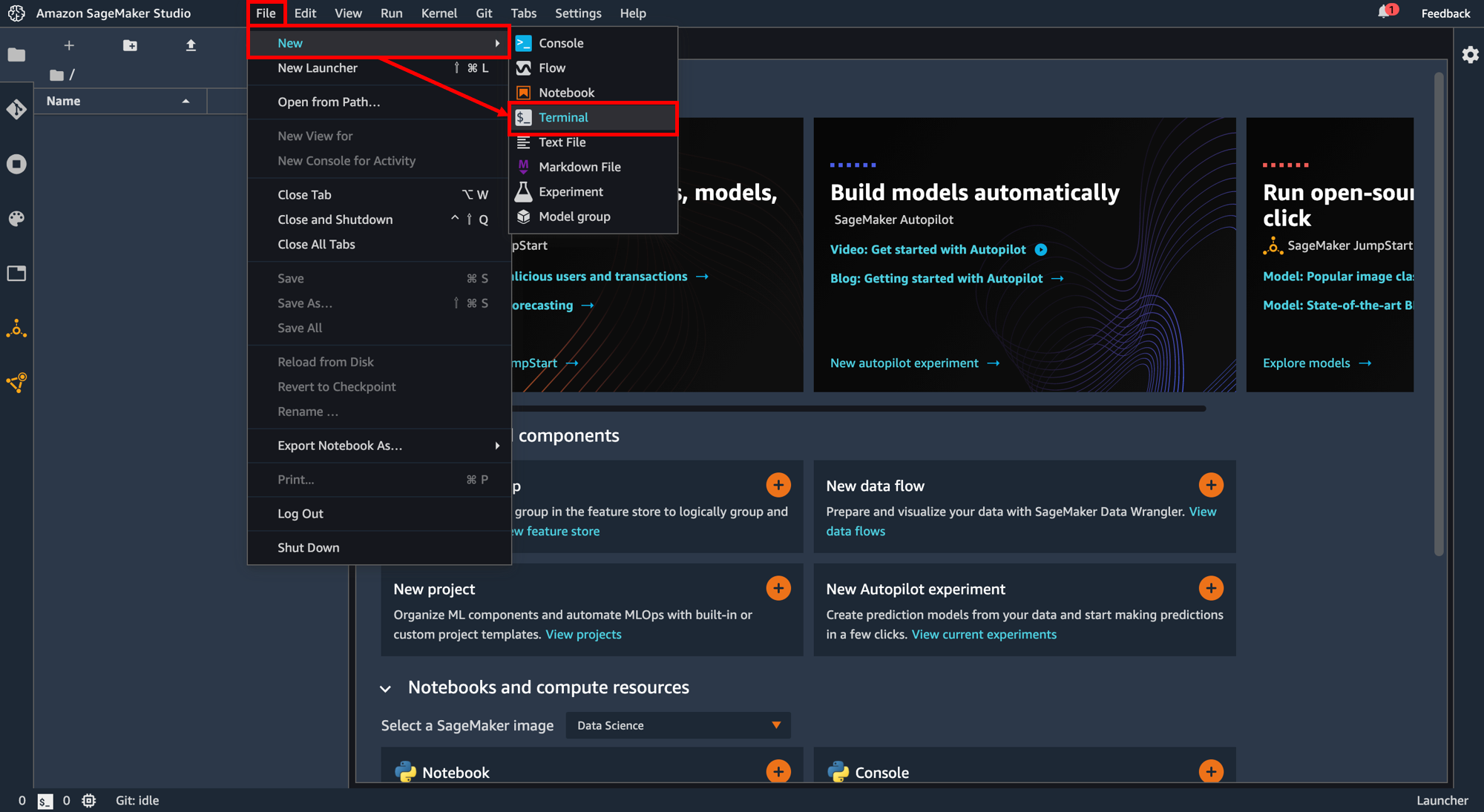
ターミナル画面が開きます。
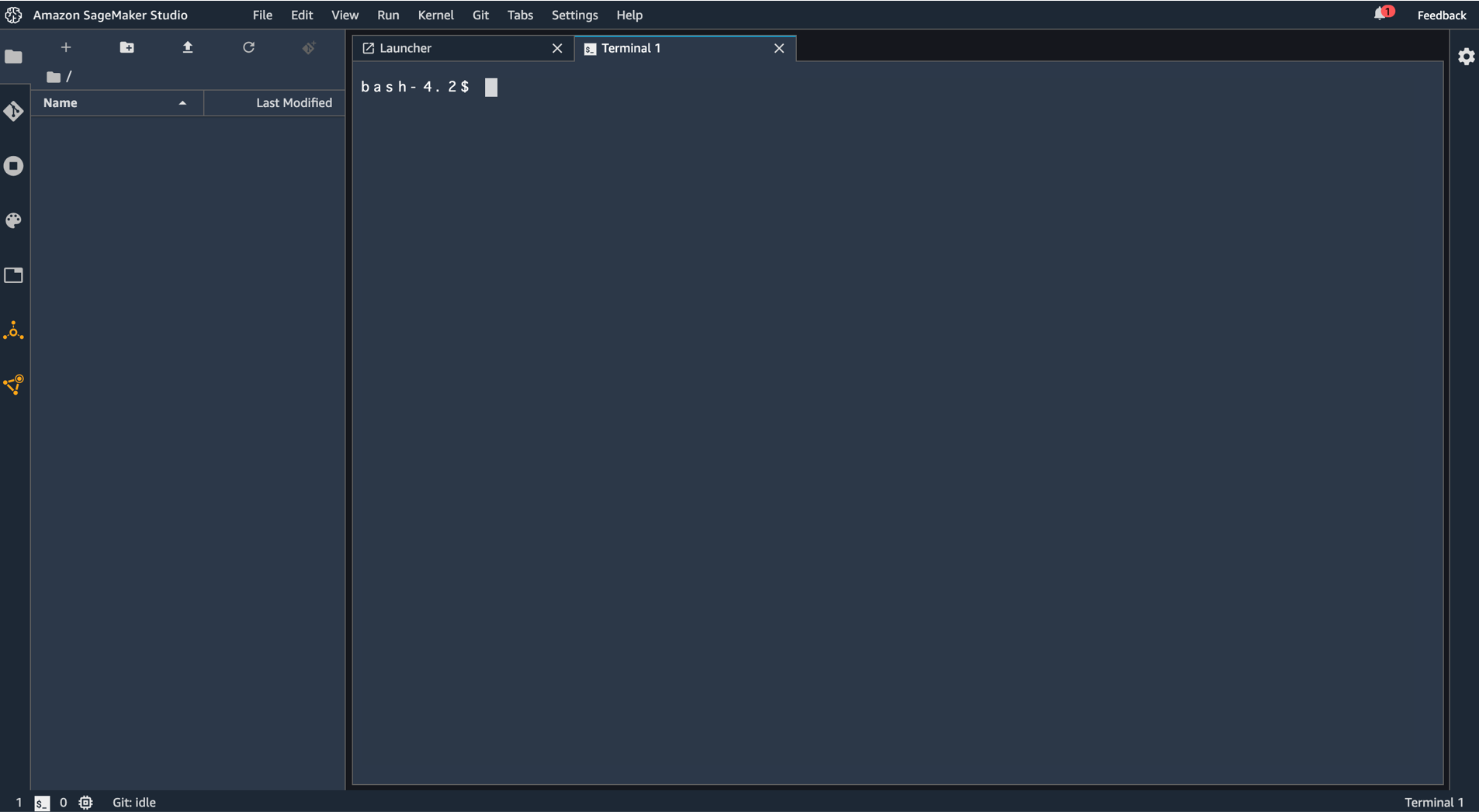
ここに以下のコマンドを打ち込みます。(最後の"."忘れに注意)
aws s3 cp s3://aws-ml-blog/artifacts/ml-1954/smstudio-pyspark-hive-sentiment-analysis.ipynb .
左のウインドウにノーブックファイルがコピーされていることが確認できます。これを開きます。
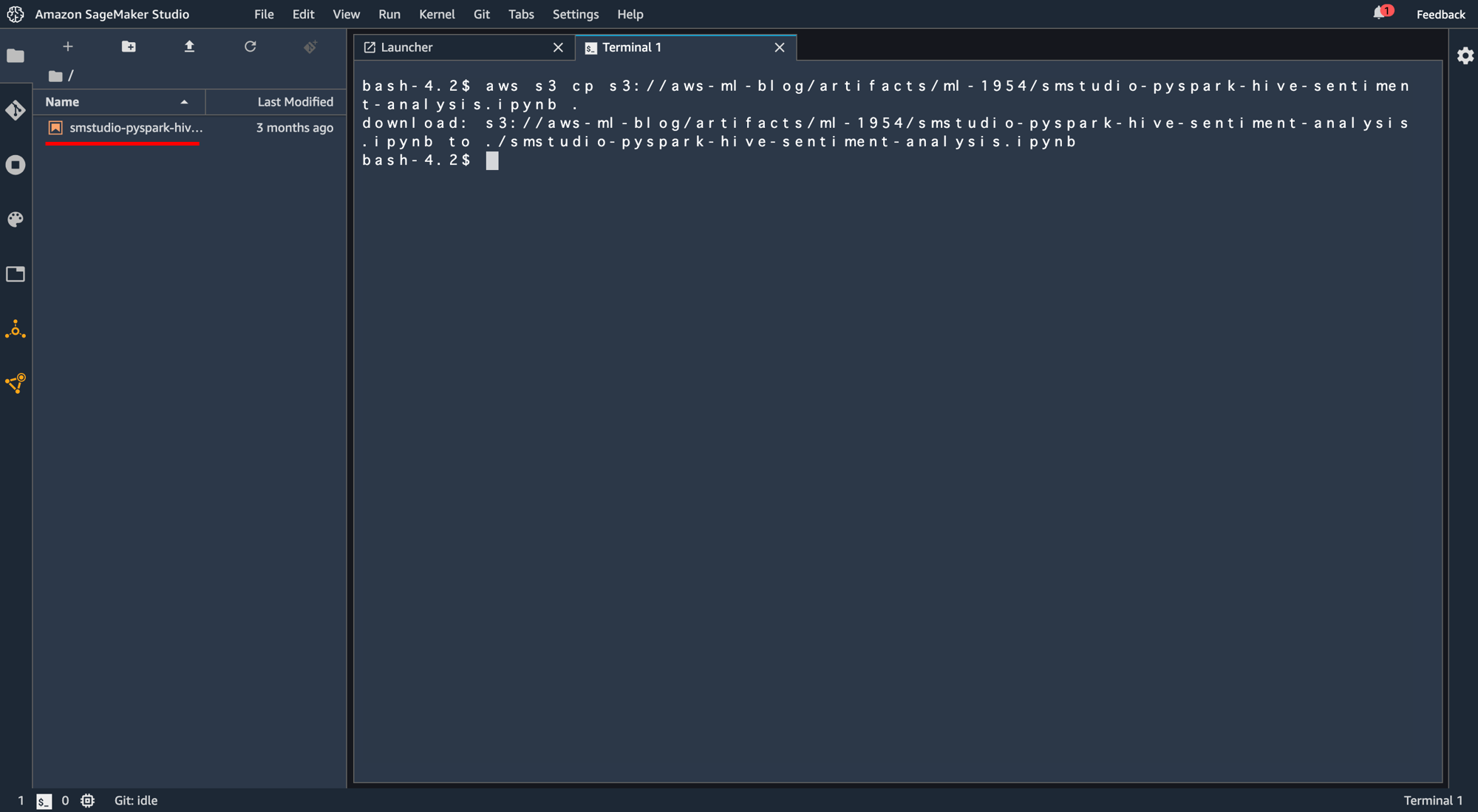
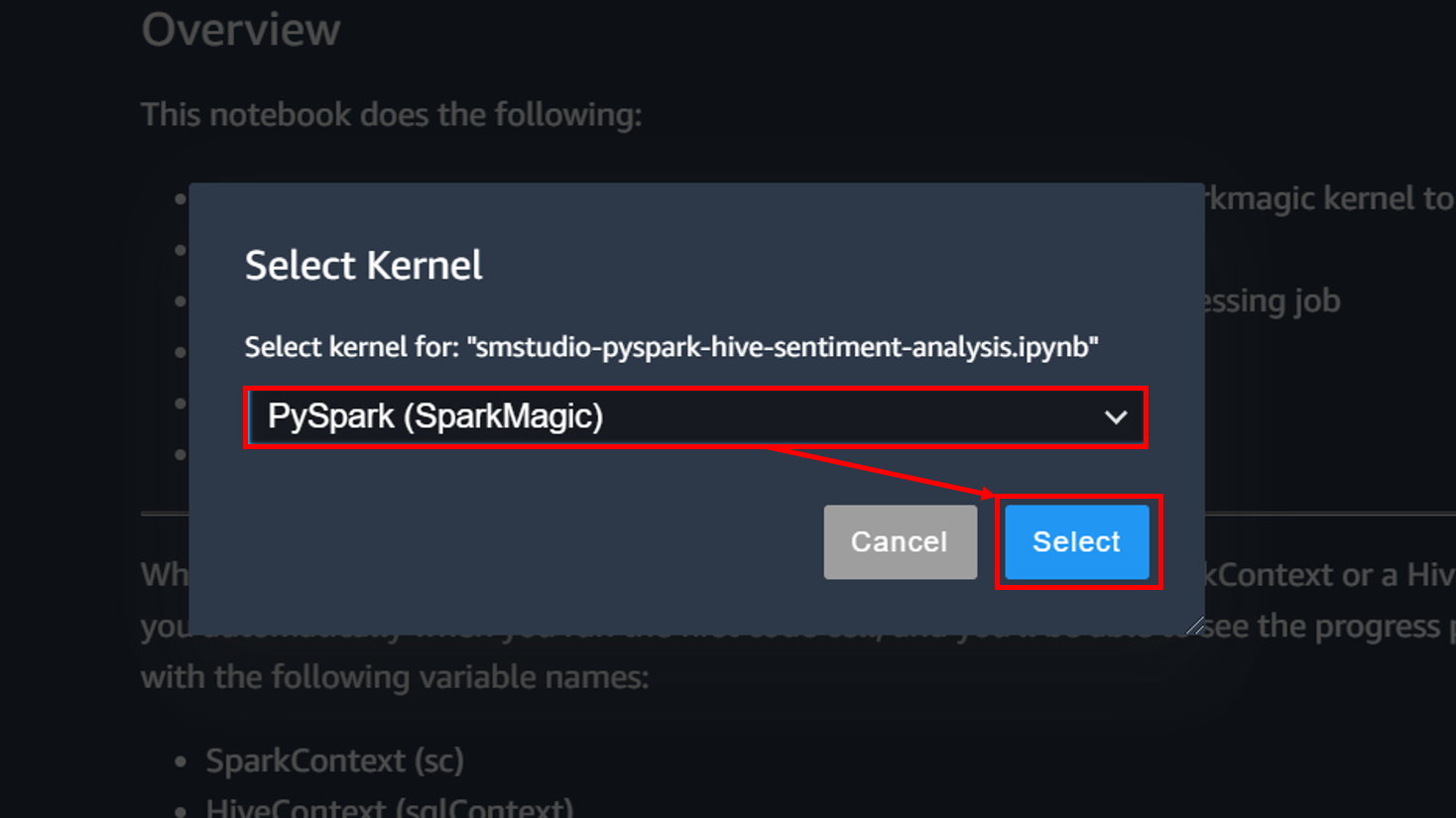
ノートブックを開くにはカーネルを選択する必要があります。「PySpark(SparkMagic)」を選択し、「Select」をクリック。
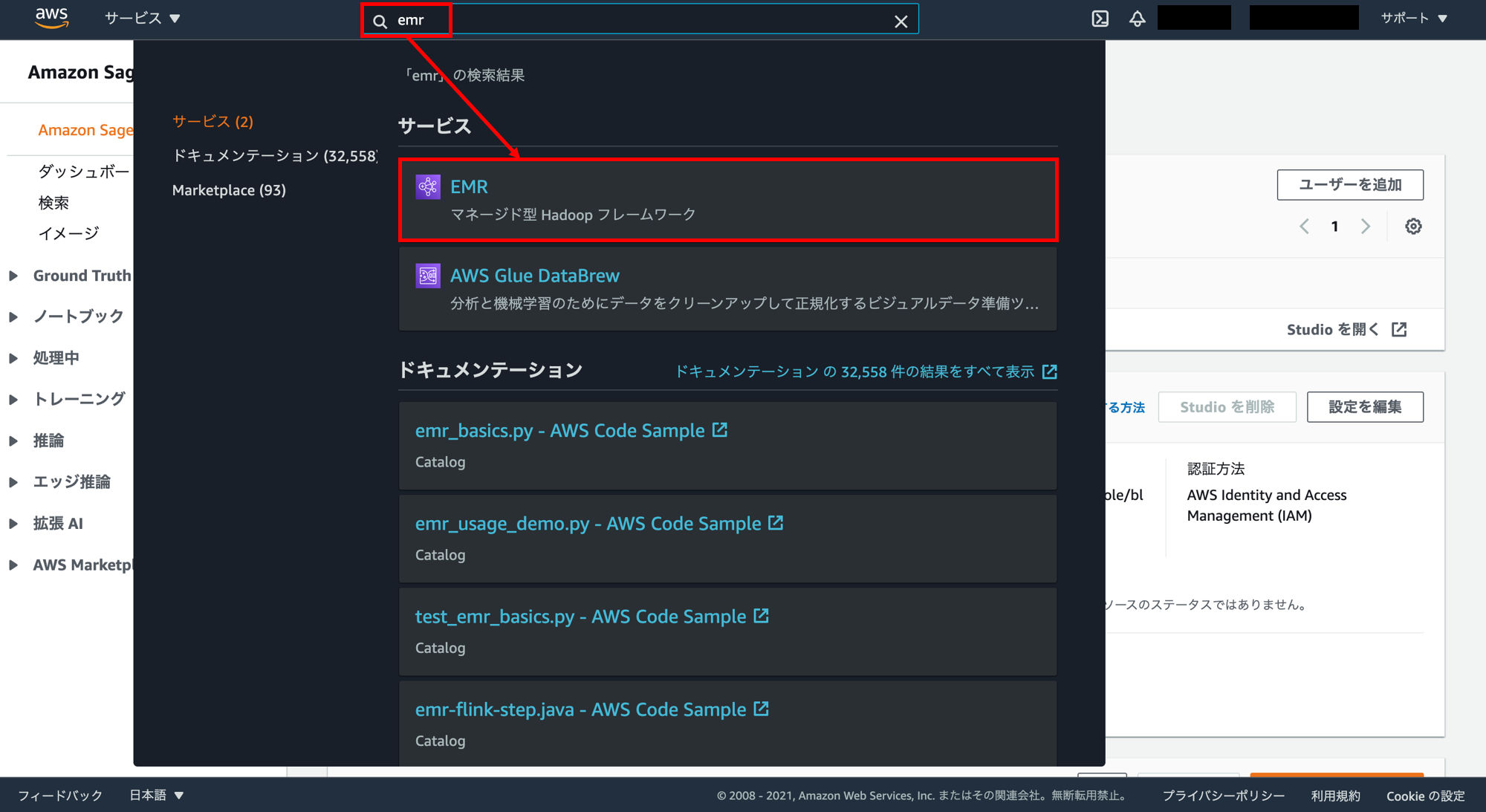
マネジメントコンソール画面に戻ってEMRの画面を開きます。検索窓に「emr」と入力し「EMR」をクリック。
クラスターが作成されています。クラスターの「ID」をコピーします。
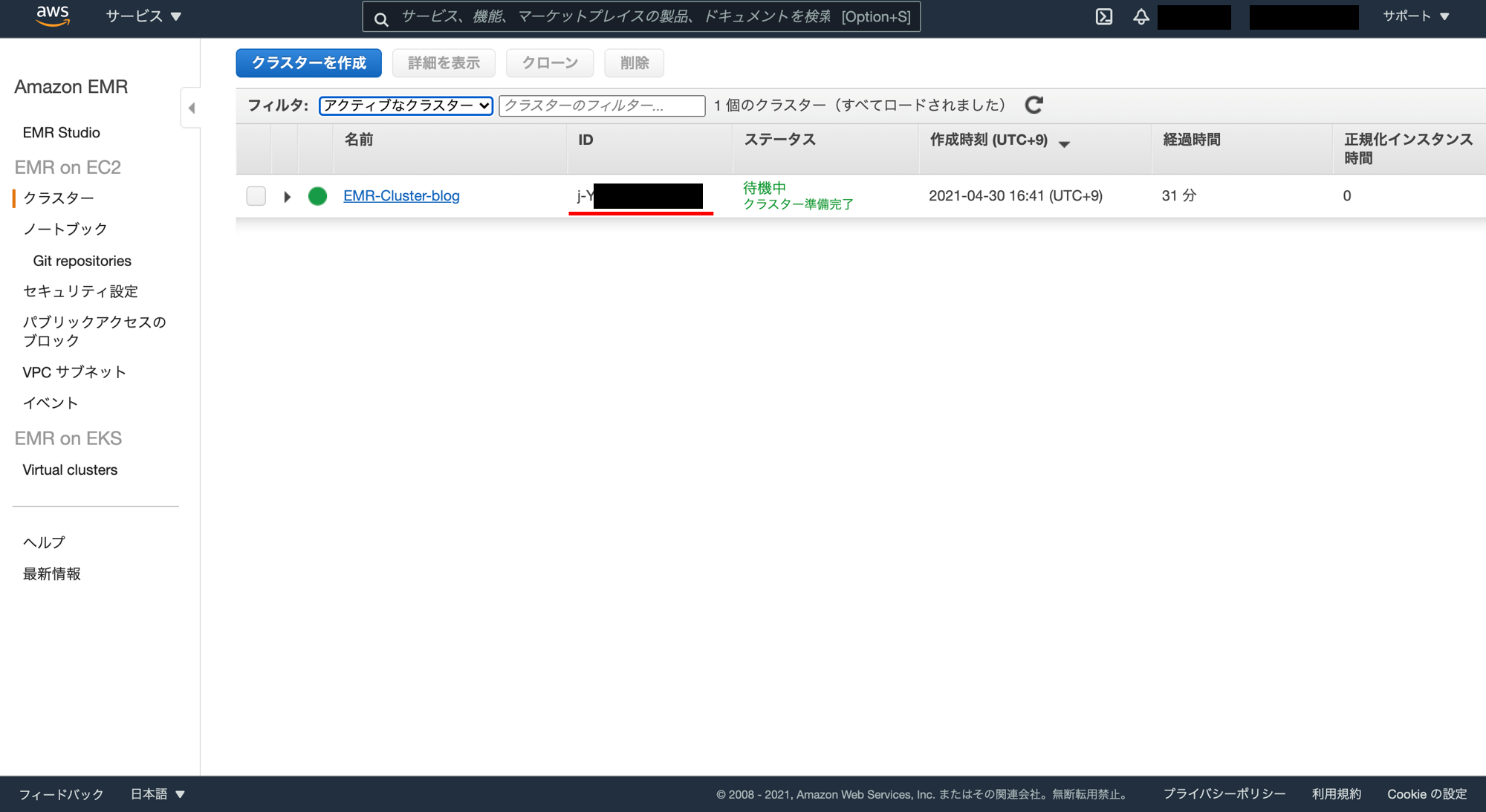
次に SageMaker Studio の画面に戻り、以下のように記載されているセルの"x-XXXXXXXXXXXX"の部分を先ほどのクラスターの「ID」に書き換えて実行します。
%%local
emr_cluster_id="x-XXXXXXXXXXXX"
その次に以下のコマンドが書いてあるセルを実行します。
%%local
!sm-sparkmagic connect --cluster-id {emr_cluster_id} --user-name "user1"
ここまでできたら「Launch terminal icon」をクリック。
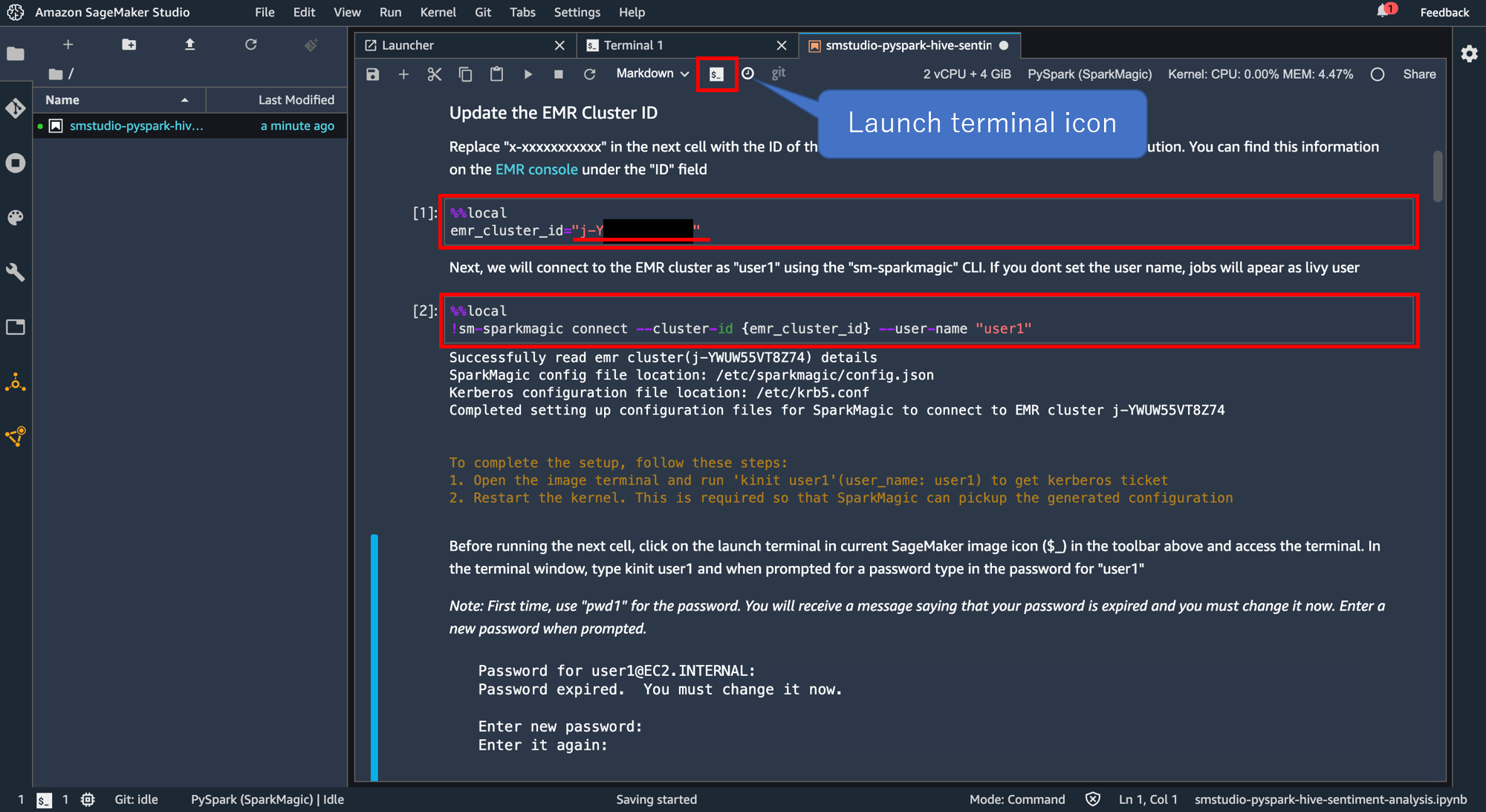
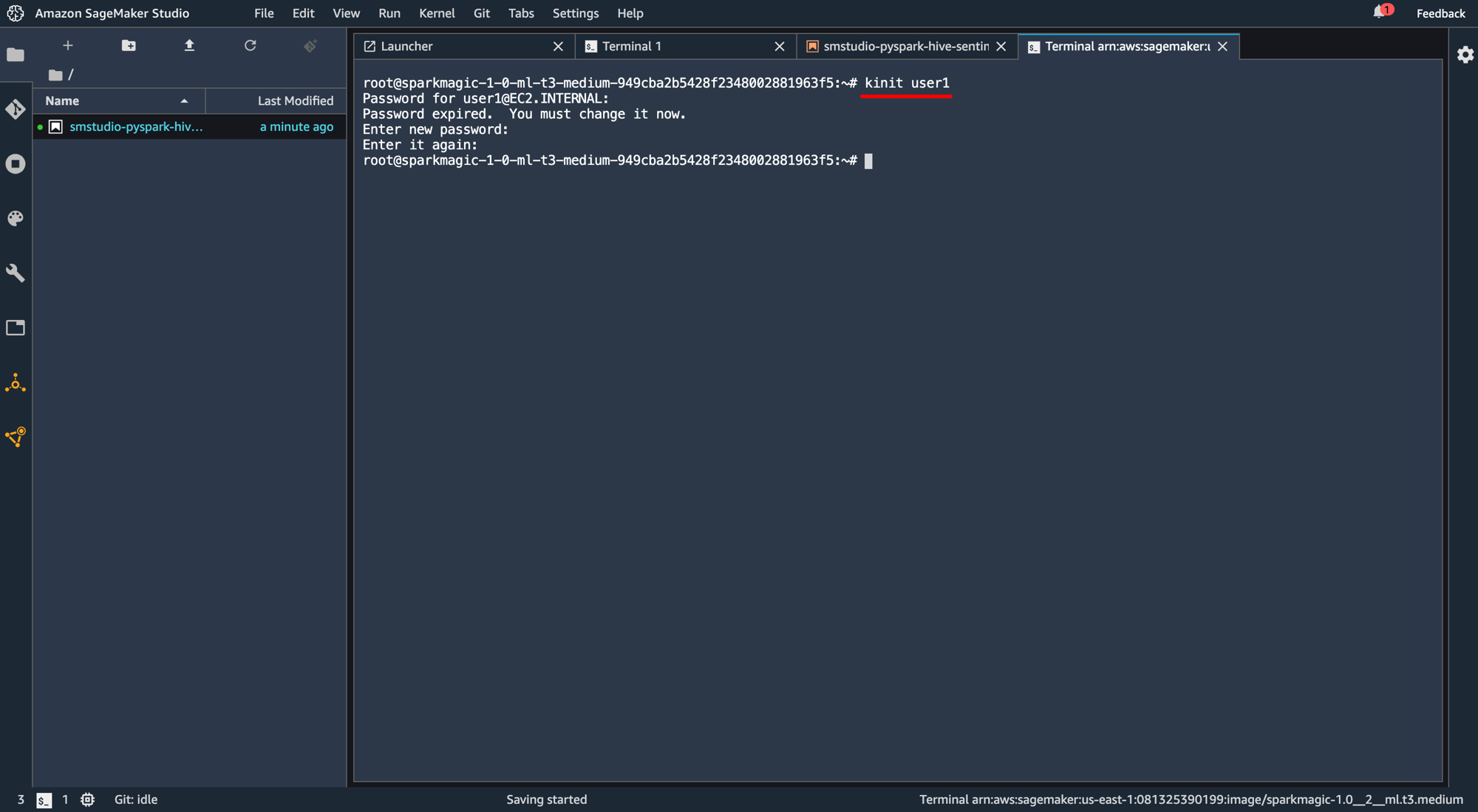
ターミナル画面が開くので"kinit user1"と打ち込んで実行。初期パスワードは"pwd1"に設定されています。
任意の新しいパスワードを入力し、そのパスワードを再度入力します。
ノートブックのタブに戻り、「Restart kernel icon」をクリック。
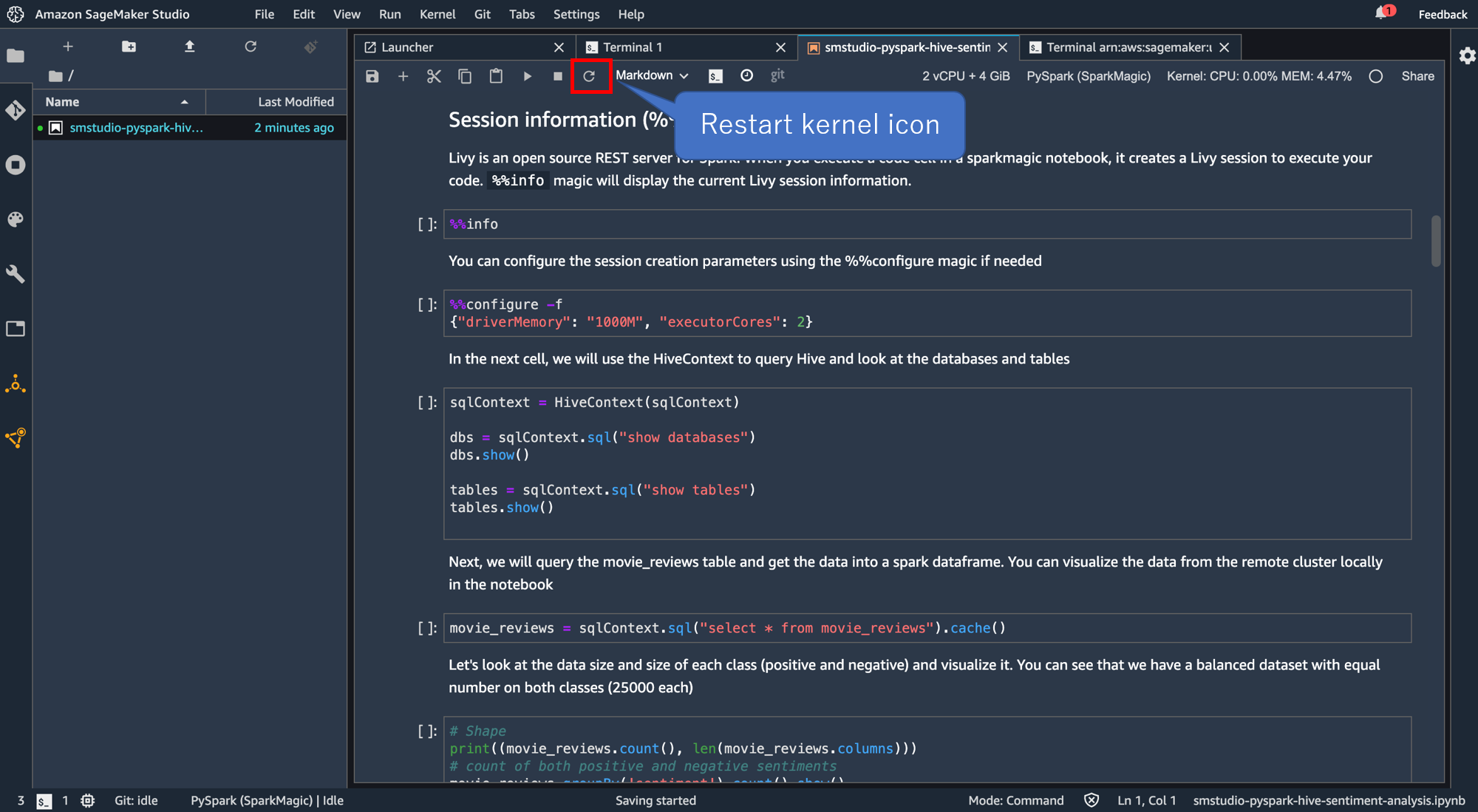
カーネルが再起動したら、
%%info
を実行します。以下のような出力がでていればokです。
Current session configs:{'driverMemory': '1000M', 'executorCores': 2, 'kind': 'pyspark'}
No active sessions.
PySpark の実行
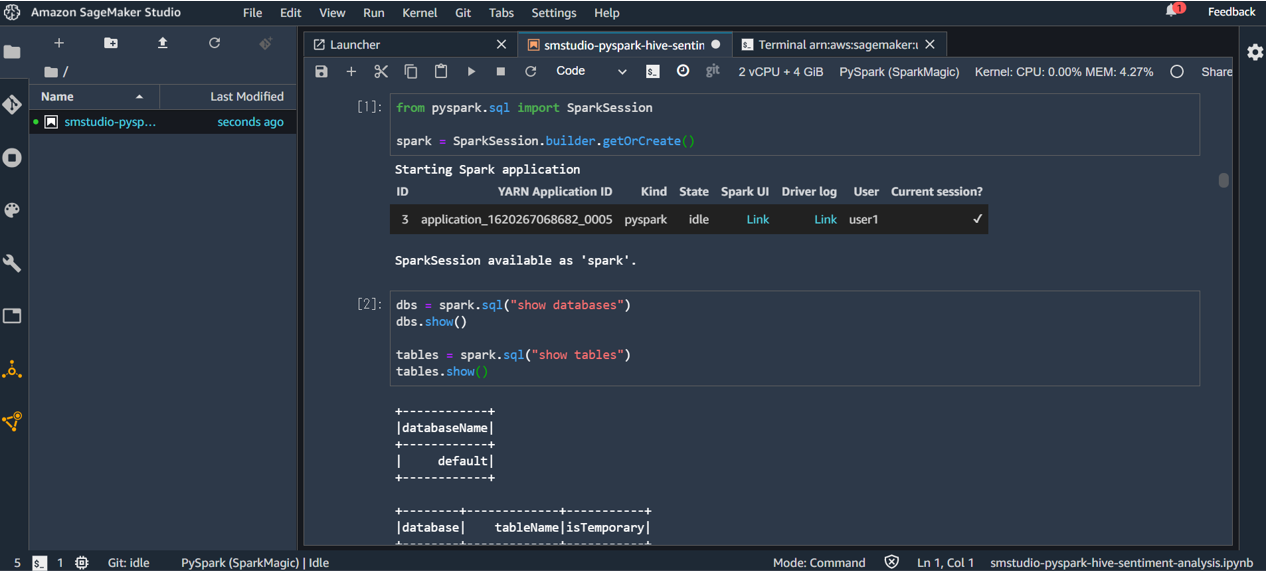
SparkSessionを生成します。
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
"SparkSession available as 'spark'"と表示されればokです。
サンプルノートの後続のコードを PySpark でやってみます。
dbs = spark.sql("show databases")
dbs.show()
tables = spark.sql("show tables")
tables.show()
実行可能であることが確認できます。
おわりに
Amazon SageMaker Studio で PySpark を実行できる環境を作成しました。
テンプレート、ほんとに便利です。。
参考