GrubCutを使ってそこそこ背景除去ができたので、そのデータを使って画像生成にチャレンジしてみました。今回はGANではなくWasserstein AutoEncoderを使っています。
Adversarial AutoEncoder
当初、Adversarial AutoEncoderの利用を考えていました。これはAutoEncoderをGANのアプローチで実現するもので、一般的なAutoEncoderと異なり画像の特徴を特定の分布に従った潜在空間に埋め込むもので、VAEに近いものと理解しています。
参考: [Survey]Adversarial Autoencoders - Qiita
Wasserstein AutoEncoder
Wasserstein AutoEncoderの符号化器は決定的ではなく確率的である方が潜在変数の次元数がデータの有効次元数と合わない場合でもうまく学習できる(元の論文の主張である生成がシャープになる利点は失われるが)。さらに情報の分解力はβVAEより優れている。https://t.co/SH6bsGiMTb
— Daisuke Okanohara (@hillbig) 2018年3月8日
WAEは訓練データに対する真の潜在変数とジェネレータ画像を生成するときに用いる潜在変数を考え、この2つの分布を近づけるために輸送最適化問題を考え、確率分布間の距離であるWasserstein distanceが最小となるようにEncoder-Decoderモデルの中間表現(潜在空間)を学習させるもの、と理解しています。
VAEを訓練する場合はreparameterization trickを行いますが、この時にはある分布に従った乱数を毎回サンプリングして、その乱数(潜在ベクトル)に対してDecoderを訓練するため、同じポイントに対して異なる画像を再構成するような訓練が発生してしまい、その結果鮮明な結果が得られなくなるという問題があります。
WAEではその問題を解決しています。
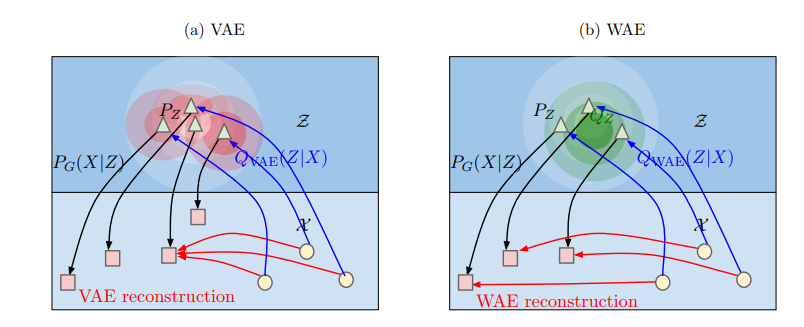
論文より抜粋(Figure 1)
AAEの一般化
WAEの論文では2種類の方法が提案されており、そのうちGANのようにG, Dを交互に訓練することでGの潜在空間の分布を真の分布に近づける方法はAdversarial AutoEncodrをより一般化したものとなるそうです。
MMD(Maximum Mean Discrepancy)
GAN的でないアプローチとして、MMDに基づく訓練方法も提案されています。これについては理解が追い付いていませんが、核再生ヒルベルト空間に写像することで2つの異なる確率分布のモーメントが計算でき、両者を近づけることができる、と理解しています。これによって、真の潜在変数と異なる次元数であっても性質の良い近似が得られるのだろうと理解しています。
実装
既存のTensorFlow実装を参考に、いくつかの修正をしたものを使いました。
-
knok/wae: Wasserstein Auto-Encoders
- Python3用に修正
- TensorBoardで損失、画像、グラフを確認できるように
- 任意の64x64カラー画像を処理できるように
- ランダム生成とアナロジーを行うスクリプトの作成
訓練
GrubCutで背景を除去したフレンズ画像284枚を対象として学習を行いました。
$ python run.py --exp dir64 --zdim 2 --epoch_num 5000 \
---work_dir result-d64-z2-e5000
- ハイパーパラメータ
- Encoder構造: dcgan
- Decoder構造: dcgan-mod
- MMDでの訓練
- MMD kernel: Inverce multiquadric (IMQ)
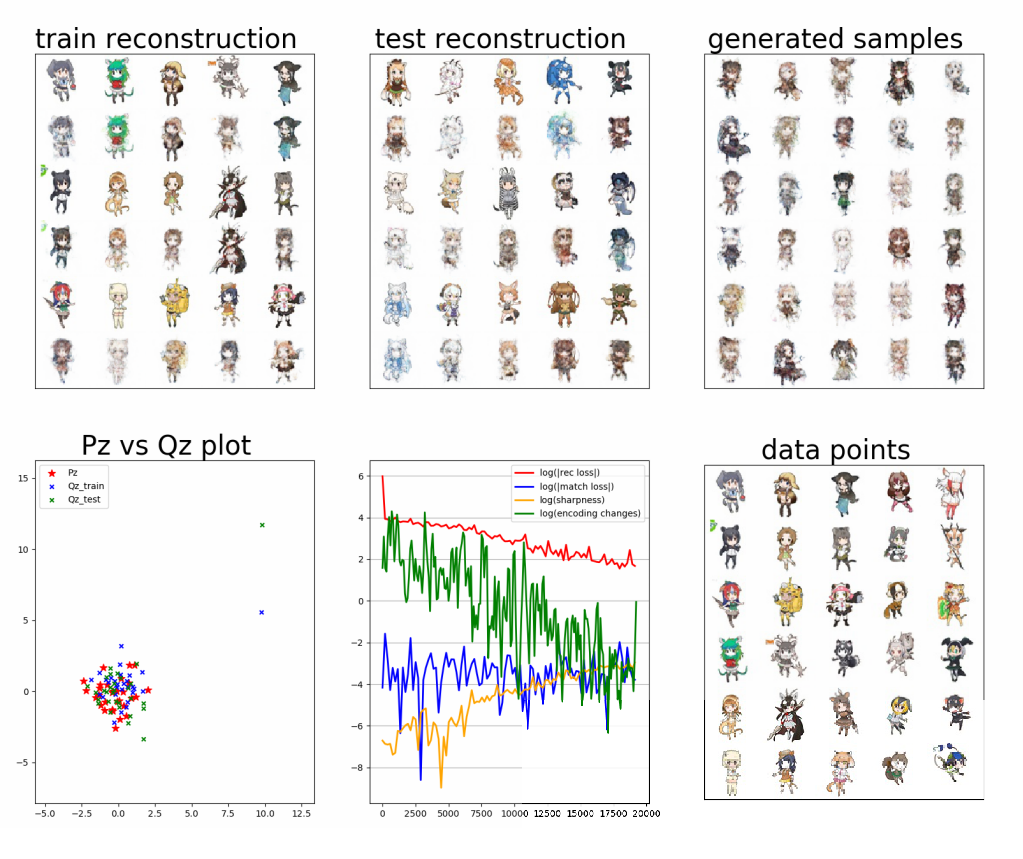
訓練途中の出力
ランダム生成
$ python gen.py --exp dir64 --zdim 2 \
--checkpoint result-d64-z2-e5000/checkpoints/trained-wae-22500
# img.pngが生成される

生成された画像
アナロジー
$ python analogy.py --exp dir64 --zdim 2 \
--checkpoint result-d64-z2-e5000/checkpoints/trained-wae-22500
# analogy.pngが生成される

所感
- まだ再構成誤差は結構大きい (訓練中間出力の下中央グラフ赤線)
- もう少し訓練を進めたほうがより鮮明になることは期待できる
- AutoEncoderベースであるため訓練画像そのままを生成するポイントが存在する
- 著作権的におそらく問題になる?
- 当初の目的である「既存のフレンズ画像から新しいフレンズ画像を生成する」こと自体はある程度達成できた
- アナロジーは2つの訓練画像に対応する潜在空間を10分割して移動させたときのそれぞれの出力
- 一応2つの画像の中間的なものができている
- モーフィングと比較して優位性はあるのか?
- ハイパーパラメータはまだ探索不足
- 潜在変数の次元数はどれぐらいが適切か
- 訓練画像が少ないのでもう少しencoder/decoderの中間層などを減らせるのではないか
おまけ: 異常検知としてのVAE/GAN/AAE/WAE
正解画像しかない(あるいは不正解画像があっても少ない)ような状況で異常検知することを考えてみました。VAEを使った手法はすでに提案されていました。
-
深層学習による胸部X線写真からの診断補助
- 異常のある画像をモデルに与えた時、正常画像と比較して変分下界はより大きな値が得られることが期待できる
VAEは鮮明な画像が得られないという問題があるため、GANを使う方法も考えてみました。これも手法として提案されているものがありました。
-
GANによる医療画像の異常検知 - 緑茶思考ブログ
- 異常画像に対応する潜在空間の点を探索するのが難しい
- 提案手法は探索に時間がかかる
ここでEncoder-Decoderモデルをベースとしていれば、潜在空間の取得が容易だろうと考え、AAEにたどり着きました。そして先のツイートでWAEの存在を知り今に至ります。
正常な画像のみを訓練したAAE/WAEに異常値を含む画像を与えると、出力画像は正常画像を与えた時と比較して、再構成誤差が大きくなることが期待できると思います。
それがダメでも、Encoderに画像を与えれば正解画像と比較してことなる特徴が出てくることを期待できそうです。