導入部分
tensorflowって何?どのように実装するの?数式も機械学習も知らん。だけどtensorflowのtutorialやってみたいなぁって考えている人向けにtensorflow tutorial:mnist for beginnersについて解説サイトをよりわかりやすく書いて自分の知識理解を増やすのとメモとして理解しておきたいと思います
間違っているところや自分の理解の認識が違うところがあると思うで、鵜呑みにするのはよくないと思います。
tensorflowのチュートリアルではmnistを行っていきます。
MNISTとは
画像を見てそれが何のデータなのか予測すること
コンピュータ・ビジョンと呼ばれる方法である。
MNISTデータについて
MNIST データは、3つの部分に分かれます。
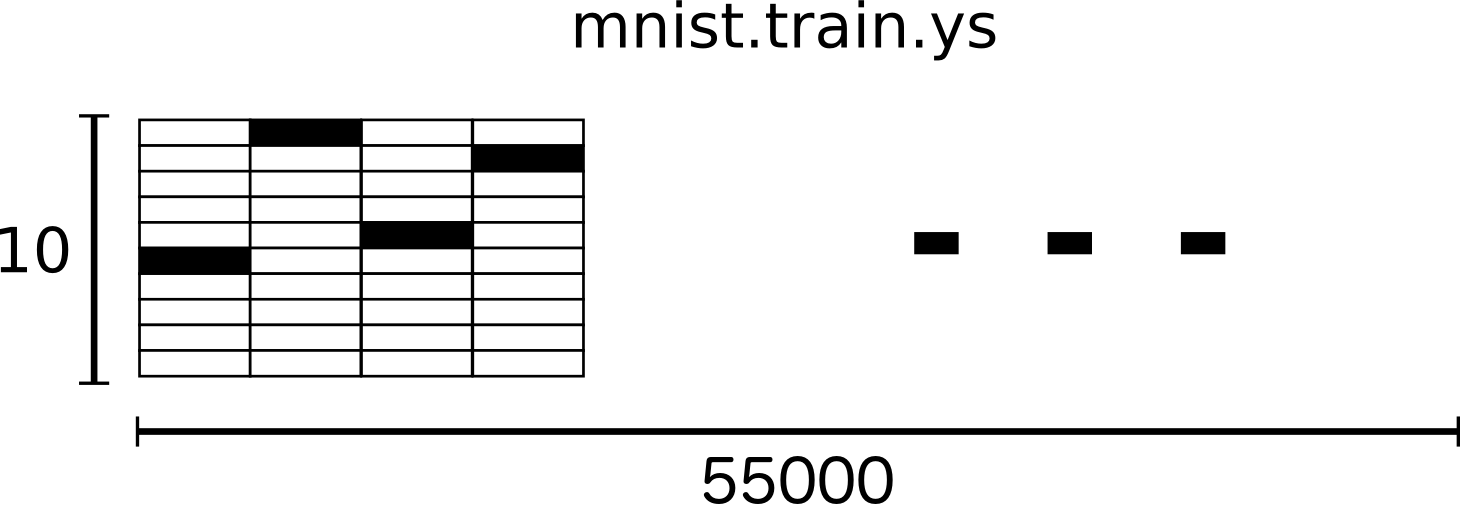
訓練データ(mnist.train)の 55,000 データポイント
テストデータ(mnist.test)の 10,000 データポイント
検証データ(mnist.valid)の 5,000 データポイント
の70000データがweb上でホストされているので、これを元に進めて行くことができる
全ての MNIST データポイントは2つのパートを持っていて、手書き数字の画像と該当ラベルです。
画像を “xs” そしてラベルを “ys” と呼ぶことにします。
訓練セットとテストセットの両方とも xs と ys を含み、例えば訓練イメージは mnist.train.images(xs:画像データのこと) で訓練ラベルは mnist.train.labels(xy:画像につけられたラベルのこと) です。
角画像は28ピクセル x 28ピクセルであり、これは数値の大きな配列と解釈することができる。
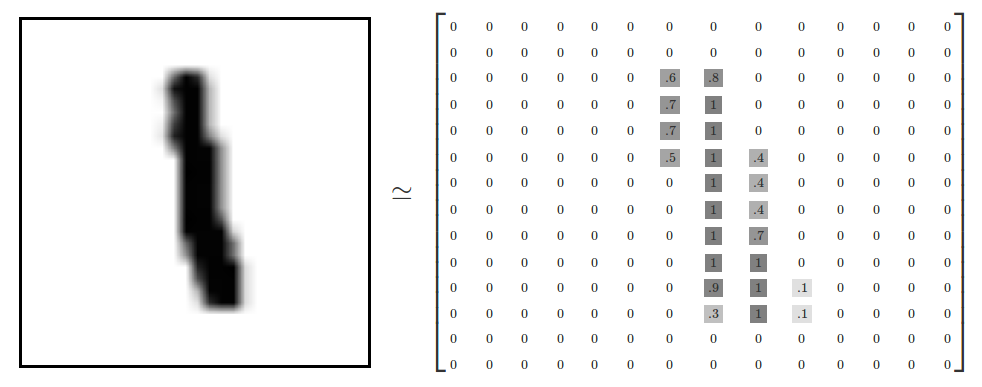

よってmnist.train.imagesは[55000, 784]の形状を持つテンソルになる。

ラベルは0〜9の間の数字で、与えられた画像がどの数字であるかを示す、チュートリアルのためのラベルには「one-hotベクタ」を要求する
one-hot ベクタはほとんどの次元で 0 で一つの次元で 1 であるベクタです。この場合、n 番目の数字は n 番目の次元が 1 のベクタとして表されます。例えば 3 は [0,0,0,1,0,0,0,0,0,0] になります。結果的に mnist.train.labels は float の [55000, 10] 配列になります。
流れ
単語の説明は下で行って行く。
問題設定は28x28のピクセルデータを入力して、10クラス分の分類問題を解くというものであり、
今回使うニューラルネットワークは普通のニューラルネットワークですので、28x28=784のユニットを入力層として使う、
出力層はデータがあるクラスに属する確率を出力する。よって答えである10クラス分のユニットが出力層に置かれる。
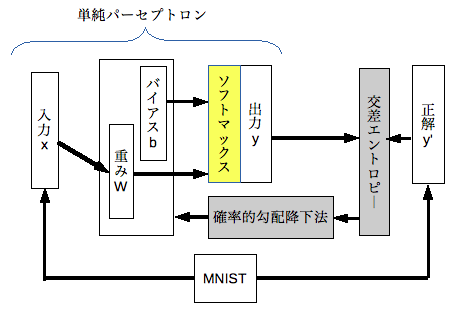
Biggnersでは最も単純に入力層と出力層だけのニューラルネットワークを使う。
→入力層と出力層だけの順伝播型ニューラルネットワークの事を単純パーセプトロンという。
→よってこのチュートリアルは深層学習(ディープラーニング)といえるものではない。
か
入力した手書き数字画像から数値を予測する多クラス分類問題を解けるように、MNISTデータセットを単純パーセプトロンに教師あり学習させる。
→学習とは得られた入力データから予測される値が正解の値になるように重みを変えていくこと
教師した学習データに出力層である活性化関数にsoftmax関数を用いる。
→学習した重みを用いてsoftmax関数で複数ある事象のうちある事象が起きる確率を求める関数のこと
→出力層の結果を確率分布にすること
学習させるにあたって予測と正解の差を求める損失関数には交差エントロピーを用いて、それを確率的勾配降下法で行う。
(簡単に言うと?)→予測した値と正解した値の差を最小にするように重みを変える
→損失関数の最小→正しい値に近い→そのために変数である重みを変えて行く。
ここから出てきた単語の説明を自分なりにおこなっていく。
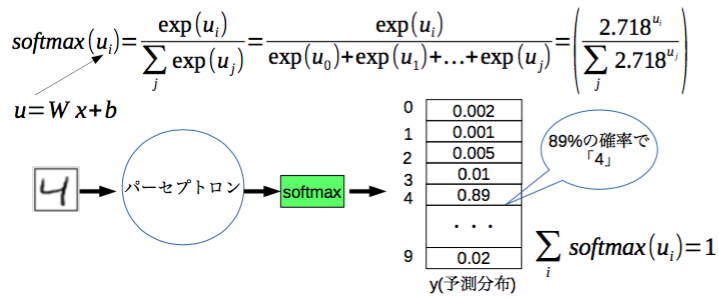
Softmax回帰
全ての画像が0〜9の中にあると知った上で、その画像を見て、その画像が各々の数字である確率を与える
いくつかの異なるものの1つであるオブジェクトに確率を割り当てたい場合はソフトマックスを使用すべきである。ソフトマックスは0〜1までのあたいのリストで合計1になるものをもたらす。
のちに、より洗礼されたモデルを訓練する場合でも、最後のステプはソフトマックスの層になる。
ソフトマックス回帰には2つのステップがある。最初に、入力がある特定のクラスに含まれる証拠を足し合わせ、次に、この証拠を確率に変換します。
与えられた画像が特定のクラスに含まれる証拠を合計するために、ピクセル強度の加重和を行います。クラスに含まれる画像に反して、ピクセルが高い強度を持つ場合は重みは負であり、支持する証拠である場合には正です。
また、基本的にいくつかのものは入力に関わらず、可能性が高いと言えるようにしたいためバイアスと呼ばれるいくつかの余分な証拠を追加したい。
とりあえず分かりやすくするために、入力層と出力層を3とおいて式を作ると
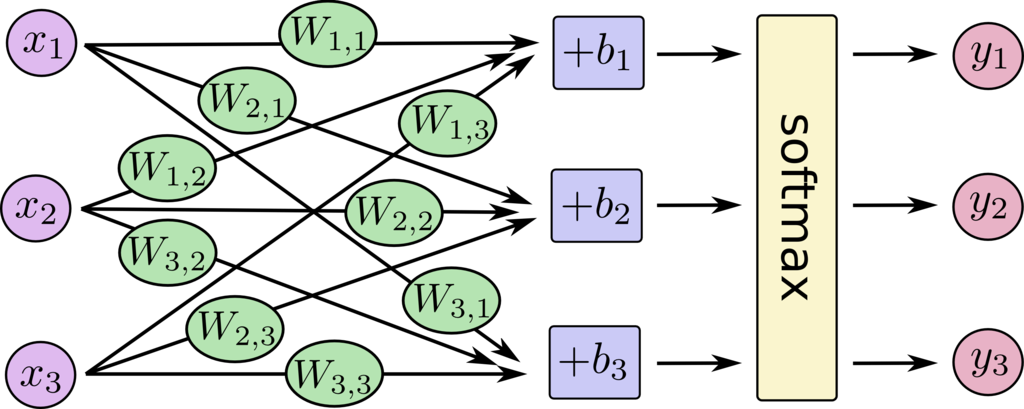
y = softmax(Wx + b) とモデル化できるので
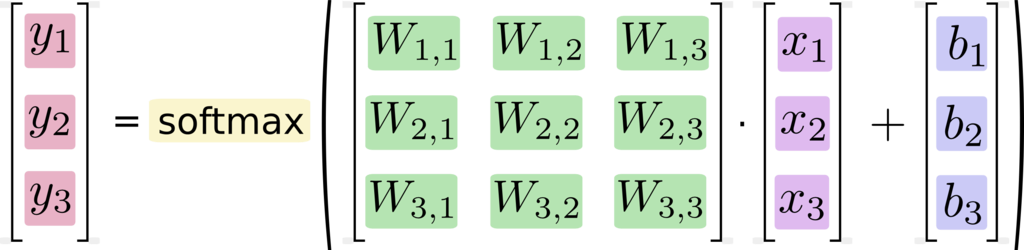
今回はこのようにして得られるyを正解ラベルtに、Wとbを調整して近づけていきます。
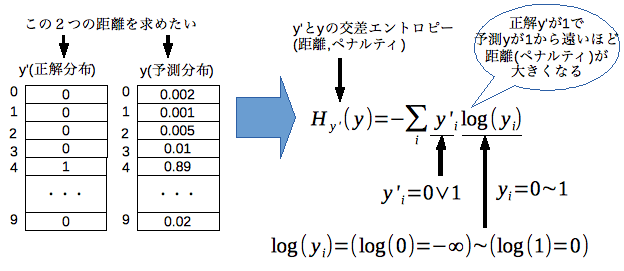
交差エントロピー
機械学習における教師あり学習では、入力に対してパラメータ(重み)wを用いて関数f(w,x)を構築し、それと正解データ(t)を使って損失関数というものを作る。
この損失関数の最小化する手続きを行うことが機械学習の目的でもある。
→最小化することで重みが正常に働き、入力データを受け取った時に正解データに近づくことがわかる。
*メモ
ニューラルネットワークでは通常2種類の損失をメインにやっていく??
・回帰
→正解tと関数f(w,x)が近くなるようにすること
・分類
→正解t(i)と出力f(w,x(i))をそれぞれ確率分布とみなして、確率分布を近づける。
→今回は分類問題と考えて確率分布を近づけるようにして行く
そこで交差エントロピーとは、確率分布間のエントロピー(ここではそれぞれの確率の混合度合い)の距離の事。
単純パーセプトロンが導いた結果と正解の差を求めるための損失関数として用いる
確率的勾配降下法
確率的勾配降下法とは、ある関数の極小値を算出する手法である。
単純パーセプトロンの重みやバイアスを調整する教師あり学習のために用いる。
勾配降下法は、教師データに対する損失関数が小さくなる方向に重み(W)を更新し徐々に理想のWへと近づけて行くこと。
動かす方向は傾きが負となる方向になる。傾きに掛け合わせる学習係数により動かす大きさが決まる
確率的勾配降下法とは全ての学習データを対象とせずに一部のデータに限定して計算量を抑えた方式のこと。
コード
# データのインポート
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# モデルの作成
# 画像データをxとする
x = tf.placeholder(tf.float32, [None, 784])
# モデルの重みをwと設定する
W = tf.Variable(tf.zeros([784,10]))
# モデルのバイアス
b = tf.Variable(tf.zeros([10]))
# トレーニングデータ
y = tf.nn.softmax(tf.matmul(x, W) + b)
# 正解のデータ
y_ = tf.placeholder(tf.float32, [None, 10])
# 損失関数をクロスエントロピーとする
#
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
# 学習係数を指定して勾配降下アルゴリズムを用いてクロスエントロピーを最小化する
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
# 変数の初期化
init = tf.initialize_all_variables()
# セッションの作成
sess = tf.Session()
# セッションの開始及び初期化
sess.run(init)
# 学習
for i in range(1000):
#トレーニングデータからランダムに100個抽出する
batch_xs, batch_ys = mnist.train.next_batch(100)
#確率的勾配降下法によりクロスエントロピーを最小化するような重みを更新する
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
#予測値と正解値を比較してbool値にする
#argmax(y,1)は予測値の各行で最大となるインデックスをひとつ返す
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
#boole値を0もしくは1に変換して平均値をとる、これを正解率とする
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
まとめ
参考サイト
tensorflowのチュートリアルをやってみる
TensorFlow : コード解説 : ML 初心者向けの MNIST
TensorFlowのtutorial:MNIST For Beginners解説
TensorFlow MNIST For ML Beginners チュートリアルの実施
TensorFlowチュートリアル - ML初心者のためのMNIST(翻訳)
[TensorFlowの手書き数字認識チュートリアルからざっくりディープラーニングを勉強して見ました]
(http://nihemak.hatenablog.com/entry/2016/07/02/205330)