はじめに
この記事は「NTTテクノクロス Advent Calendar 2022」の15日目の記事です。
こんにちは!NTTテクノクロスの中村です。
本記事は、PostgreSQL の情報収集ツール「pg_statsinfo」を使用している人向けに作成しました。
ツールを導入したものの「レポートは見たことがない」ってこと、結構ありますよね。
そんなときの調査の取っ掛かりになればよいなぁ、と思いながらこの記事を書きました。
前提
今回は、PostgreSQL14 をターゲットにします。
(pg_statsinfo は毎年2月ごろに、最新のPostgreSQL対応版がリリースされています)
解析の準備をしよう
まず、簡易レポートをもらったら、解析のために以下の情報ソースを準備しましょう。
簡易レポートの項目が示す内容は、このドキュメントとEXCELファイルがリファレンスになります。
・pg_statsinfo のWEBドキュメントを開く
https://github.com/ossc-db/pg_statsinfo/blob/main/doc/pg_statsinfo-ja.md
・レポート項目が記載されているEXCELファイルを開く
https://github.com/ossc-db/pg_statsinfo/blob/14.0/doc/files/pg_statsinfo_v14_report_infomation.xls
(上記WEBドキュメント内からリンクされています)
pg_statsinfo簡易レポートとは?
pg_statsinfoは、データベース内のシステムビューやマシンリソースの情報を定期的に蓄積しています。
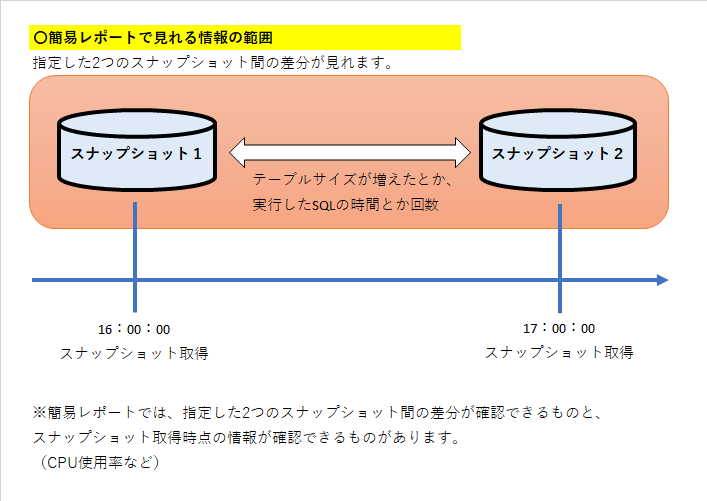
ある時点の情報をまるごと写し取っているため、「スナップショット」と呼んでいます。
2つのスナップショットを指定して、その差分情報を整理したものをテキストで出力してくれる。これが簡易レポートです。
簡易というのはテキストベースだからですね。
レポートされる情報は、レポート作成時に指定した、スナップショットの開始時点と終了時点の差分もしくは、終了時点の情報になります。
レポートに出力されている情報がどの時点の情報なのかは、EXCELの「レポート項目一覧」シートの「特記事項」に記載されています。
イメージとしては以下のような形になります。
ちなみに簡易じゃないレポート(pg_stats_reporter)もあります。こちらはグラフや表付きで豪華なうえ、ブラウザで見ることができます。
https://github.com/ossc-db/pg_stats_reporter
確認する項目はここ!まずは10個の着目点!
簡易レポートは情報がいっぱいあり、どこから見ればいいか悩みますね。そこで、いくつかの観点に絞り込んでみました。
ここでは、性能が出ない(遅い)理由として、以下の5つにアタリを付けて確認していきます。
- 設定値が誤っていないか
- キャッシュヒット率が低くないか
- サーバが重くないか
- WAL更新量が多くないか
- 非効率なアクセスがないか
●設定値が誤っていないか
①postgresql.conf の設定パラメータを確認
まず、設定変更した postgresql.conf のパラメータがきちんと反映されているかを確認します。
設定漏れ、設定値誤りがないか等をチェックします。
■確認する箇所
/* Setting Parameters */
ここに、postgresql.conf でデフォルト値から変更したパラメータがリストされます。
設計書と突き合わせたりし、明らかにおかしな設定値がないかを確認します。
----------------------------------------
/* Setting Parameters */
----------------------------------------
Name Setting Unit Source
-------------------------------------------------------------------------------------------------------
TimeZone Asia/Tokyo configuration file
lc_messages C configuration file
log_checkpoints on configuration file
log_destination csvlog override
log_min_messages log configuration file
logging_collector on override
pg_statsinfo.repolog_min_messages disable configuration file
pg_statsinfo.textlog_line_prefix %t %p %c-%l %x %q(%u, %d, %r, %a) configuration file
shared_buffers 16384 8kB configuration file
shared_preload_libraries pg_stat_statements, pg_statsinfo configuration file
●キャッシュヒット率が低くないか
②キャッシュヒット率を確認
データベース毎の平均値と、アクセス頻度の高いテーブル別にキャッシュヒット率を確認します。
キャッシュヒット率99%以上はOKと判断してよいと思います。
極端に小さい場合は、問題がないか確認する必要があります。
■確認する箇所
/* Database Statistics */
データベース全体のキャッシュヒット率を「Cache Hit Ratio」の値から確認します。
データベース別に複数出力されていますので、全て確認しましょう。ここでは、「Database Name : testdb」の「Cache Hit Ratio : 62.0 %」と低いことがわかりますね。
----------------------------------------
/* Database Statistics */
----------------------------------------
(略)
Database Name : testdb
Database Size : 1519 MiB
Database Size Increase : 1487 MiB
Commit/s : 76.118
Rollback/s : 0.000
Cache Hit Ratio : 62.0 % ★ココが低いことがわかる★
Block Read/s (disk+cache) : 4013.144
Block Read/s (disk) : 1524.757
Rows Read/s : 27679.582
Temporary Files : 4
Temporary Bytes : 191 MiB
Deadlocks : 0
Block Read Time : 0.000 ms
Block Write Time : 0.000 ms
/** Heavily Accessed Tables **/
テーブル単位のキャッシュヒット率を「Cache Hit Ratio(%)」(一番右の列)の値から確認します。
こちらはアクセス頻度の高いテーブルの情報のみが出力されています。ここでは、「pgbench_accounts」テーブルのキャッシュヒット率が50.9%と低いことがわかります。
/** Heavily Accessed Tables **/
-----------------------------------
Database Schema Table Seq Scans Read Rows Read Rows/Scan Cache Hit Ratio(%)
-----------------------------------------------------------------------------------------------------------------------
testdb public pgbench_accounts 2 10000000 5000000.000 50.9
testdb public pgbench_tellers 1 1000 1000.000 99.7
testdb public pgbench_branches 141 14100 100.000 99.8
●サーバが重くないか
③CPU使用率を確認
CPU使用率と、ロードアベレージを確認します。
ここの値はスナップショット取得時の情報となります。スナップショット間に高負荷になっているような状態を確認するために、VMSTATやSARなどの情報も別途取得しておくほうが良いです。
■確認する箇所
/** CPU Usage + Load Average **/
全て確認しましょう。
ロードアベレージは平均値なので、CPUコア数より大きな値になっていないかを確認します。
/** CPU Usage + Load Average **/
-----------------------------------
DateTime User System Idle IOwait Loadavg1 Loadavg5 Loadavg15
------------------------------------------------------------------------------------------
2022-12-06 17:30 0.3 % 0.2 % 97.6 % 1.9 % 0.510 0.560 0.260
2022-12-06 17:31 0.1 % 0.1 % 99.8 % 0.0 % 0.230 0.450 0.250
Average 0.2 % 0.2 % 98.7 % 1.0 % 0.370 0.505 0.255
●WAL更新量が多くないか
④WAL出力量を確認
WALの出力量が期待値(処理内容に見合った更新量)より多くないかを確認します。
■確認箇所
/** WAL Statistics **/
「WAL Write Total」で WALの出力量がわかります。出力量が妥当かどうかの観点も必要ですが、単純にサーバスペックに対して書き込み量が多そうかどうかの判断もできますね。
/** WAL Statistics **/
-----------------------------------
WAL Write Total : 1454.396 MiB
WAL Write Speed : 2.562 MiB/s
WAL Archive Total : 91 file(s)
WAL Archive Failed : 0 file(s)
⑤WAL書き込み待ちの確認
WAL出力量が多い場合、WALの書き込み待ちになっていないかを合わせて確認します。
■確認箇所
/** Wait Sampling per Database **/
各データベースの「Event Type」と「Event」、「Count」を確認します。
PostgreSQL 13以前では対応してません
WAL出力量が多い場合は、「Event Type」に「LWLock(軽量ロック)」の「WALWrite」が多い場合、WALの書き込み待ちが発生して更新性能に影響している可能性があります。
/** Wait Sampling per Database **/
-----------------------------------
(略)
Database
---------------------------------------------------------------------------------------
testdb
Top 10 Events:
Event Type Event Count Ratio(%)
-------------------------------------------------------------------------------
LWLock WALWrite 235254 79.874
Lock transactionid 40626 13.794
IO WALSync 10984 3.729
Lock tuple 3448 1.171
Client ClientRead 2195 0.745
IO WALInitSync 1477 0.501
IO DataFileImmediateSync 192 0.065
IO DataFileRead 132 0.045
IO DataFileWrite 65 0.022
IO DataFileExtend 51 0.017
⑥WAL契機のチェックポイント回数を確認
WAL出力量が多い場合、チェックポイントの発生回数も確認します。
チェックポイント自体重い処理になるので、WAL契機でのチェックポイントが発生している場合は負荷が高いことがわかります。
■確認箇所
/* Checkpoint Activity */
「Checkpoints By WAL」の数が多い場合、WAL契機のチェックポイントが発生し、I/O負荷が高くなっている可能性があります。ここではWAL契機のチェックポイントが2回発生していることがわかりますね。
----------------------------------------
/* Checkpoint Activity */
----------------------------------------
Total Checkpoints : 2
Checkpoints By Time : 0
Checkpoints By WAL : 2
Written Buffers Average : 913.000
Written Buffers Maximum : 1556.000
Write Duration Average : 84.306 sec
Write Duration Maximum : 146.292 sec
●非効率なアクセスがないか
⑦テーブルサイズが肥大化していないかを確認
■確認箇所
/** Tables **/
「Size Incr」(増加サイズ)が想定より大きくなっていないかを確認します。
/** Tables **/
-----------------------------------
Database Schema Table Columns Rows Size Size Incr Table Scans Index Scans
-----------------------------------------------------------------------------------------------------------------------------
testdb public pgbench_accounts 4 10000035 1284 MiB 1284 MiB 2 56474
testdb public pgbench_branches 3 100 0 MiB 0 MiB 141 28098
testdb public pgbench_history 6 28237 2 MiB 2 MiB 0 0
testdb public pgbench_tellers 4 1000 0 MiB 0 MiB 1 28237
⑧自動VACUUMの効果を確認
テーブルサイズが想定より大きくなっている場合、VACUUMが正常に動作しているかを確認します。
■確認箇所
/** Vacuum Basic Statistics (Average) **/
「Remain Dead」(回収されなかったデッドタプル)の数が多くないかを確認します。
この値が大きい場合は何らかの理由によってデッドタプルが回収されていないことが懸念されますので、調査したほうがよさそう、といった判断ができます。
/** Vacuum Basic Statistics (Average) **/
-----------------------------------
Table Count Index Scanned Index Skipped Removed Rows Remain Rows Remain Dead Scan Pages Scan Pages Ratio Removed Lp Dead Lp Index Scans Duration Duration(Max) Cancels
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
testdb.public.pgbench_tellers 3 1 2 2749.333 1021.333 21.333 6.000 6.820 596.000 0.000 0.333 0.000 s 0.000 s 0
testdb.public.pgbench_branches 3 1 2 2603.667 208.333 13.667 1.000 1.590 94.000 0.000 0.333 0.000 s 0.000 s 0
postgres.pg_catalog.pg_statistic 1 1 0 34.000 478.000 0.000 15.000 50.000 166.000 0.000 1.000 0.010 s 0.010 s 0
testdb.public.pgbench_history 3 0 3 0.000 15934.333 0.000 0.000 0.000 0.000 0.000 0.000 0.000 s 0.000 s 0
⑨負荷の高いTOP20のSQLを確認
実行されたSQLごとに、実行回数やトータルの実行時間を確認します。
1回あたりの実行時間も確認できますので、負荷の高いSQLのチェックが可能です。
■確認箇所
/** Statements **/
実行回数(Calls)、総実行時間(Total Time)、1回あたりの実行時間(Time/Call)を確認します。
「Total Time」で降順に出力されますので、データベースに対して負荷をかけている可能性の高いSQLの順に並んでいます。
1回あたりの実行時間(Time/Call)が長い場合、適切な実行計画になっているかなど、改善を検討する対象とすることができます。
/** Statements **/
-----------------------------------
User Database Calls Total Time Time/Call Block Read Time Block Write Time Query
------------------------------------------------------------------------------------------------------------------------
postgres testdb 58534 834.138 sec 0.014 sec 0.000 ms 0.000 ms UPDATE pgbench_branches SET bbalance = bbalance + $1 WHERE bid = $2
postgres testdb 58534 94.652 sec 0.002 sec 0.000 ms 0.000 ms UPDATE pgbench_tellers SET tbalance = tbalance + $1 WHERE tid = $2
postgres testdb 2 43.839 sec 21.920 sec 0.000 ms 0.000 ms copy pgbench_accounts from stdin
postgres postgres 317465 11.110 sec 0.000 sec 0.000 ms 0.000 ms SELECT statsinfo.sample_wait_sampling()
postgres testdb 1 10.853 sec 10.853 sec 0.000 ms 0.000 ms delete from pgbench_accounts where aid > $1
⑩シーケンシャルスキャンが多いテーブルを確認する
シーケンシャルスキャンの多いテーブルは、インデックスを張ることで性能改善が見込めます。
大きいテーブルに対してシーケンシャルスキャンが発生している場合は要注意です。
■確認箇所
/** Tables **/
「Table Scans」の回数を確認します。
該当するテーブルが「負荷の高いTOP20のSQL」でアクセスしているかどうかも突き合わせましょう。
特に対処するべき点になるかもしれません。
(⑦と同じ個所の別列を確認します。)
まとめ
いかがでしたでしょうか?
pg_statsinfo の簡易レポートから性能問題の要因になりそうな「怪しい」箇所を探す手助けになります。
本記事に記載したもの以外にも、有用な情報はたくさんありますので、徐々に慣れていくと良いですね。また、定期的に取得しているであろう、VMSTAT や SAR の情報も併せて確認するとより全体が見えてくると思います。
NTTテクノクロスのWEBサイトでも PostgreSQLの技術記事を掲載しておりますので、ぜひこちらもご覧ください。
明日は、@iiyaman さんです!
引き続き、NTTテクノクロス Advent Calendar 2022 をお楽しみください。