少し時間が経ってしまっていますが, 8 月に Prometheus に特化したカンファレンス PromCon 2017 がミュンヘンにて開かれたので, Z Lab からは私と @tkusumi が参加して来ました.
この記事ではそこで聞いたセッションの中から, 先日リリースされた Prometheus 2.0 での最も大きな変更の一つである Time Series Database (TSDB) に関するセッションについて, 紹介させてもらおうと思います.
概要
スピーカー: Fabian Reinartz (CoreOS)
ビデオ: https://youtu.be/b_pEevMAC3I
スライド: https://www.slideshare.net/FabianReinartz/storing-16-bytes-at-scale-81282712
Prometheus 2.0 で刷新される TSDB の実装者による, 詳解とベンチマークについてのセッションでした.
NOTE: この記事で使われている画像は全て, スピーカーからの承諾を得た上で上記のスライドから引用しています.
内容
Prometheus の TSDB のデータ構造

TSDB のデータ構造を模式化すると上の図のようになります. 縦軸は time series の列を表していて, 一つ一つがメトリクスとそれに付けられたラベルの組み合わせに対応します. 例えば次のようなメトリクスのそれぞれが time series のそれぞれに対応します.
requests_total{path="/status", method="GET", instance=”10.0.0.1:80”}
requests_total{path="/status", method="POST", instance=”10.0.0.3:80”}
requests_total{path="/", method="GET", instance=”10.0.0.2:80”}
...
横軸は時間を表していて, 時間が経つに連れ Prometheus がスクレイプを行うことにより図の右端にデータサンプルが追加されていきます. 図で歯抜けている部分があるように見えるのはスクレイプに失敗する可能性などを考慮しているからです.
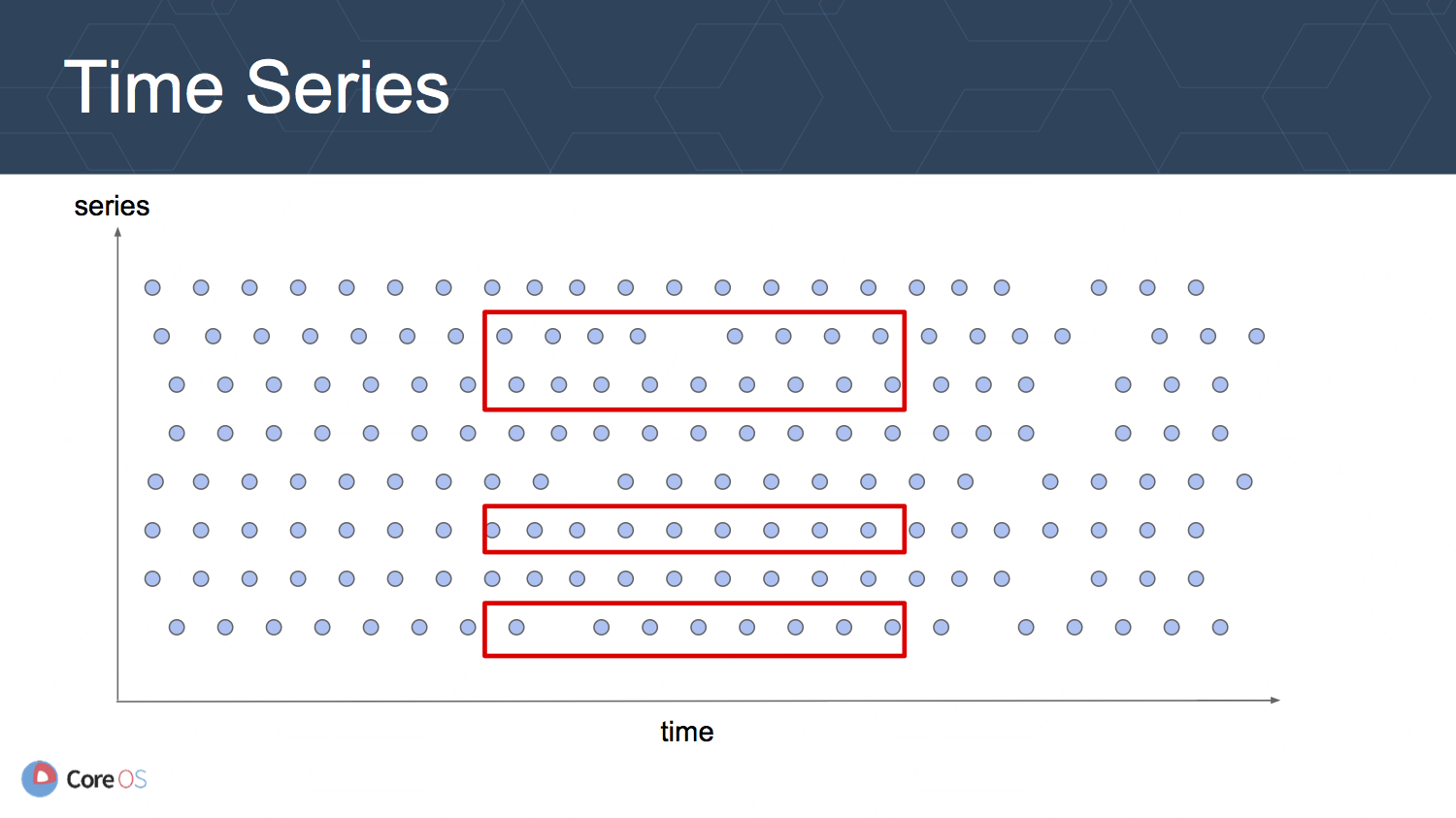
TSDB にクエリを実行する際には, メトリクスを取得した期間と, 複数のメトリクス名やラベルの組み合わせに対応した time series が関連します. そのため, 取得する必要のあるサンプルの範囲は赤い矩形で囲まれた複数の範囲に広がっていることになります.
必要なディスク容量の見積もり

Prometheus では timestamp と値に 8 byte ずつが必要なため, そのままディスクへ格納すると, 必要なディスク容量は次の要件の場合には約 7 TB となります.
| 項目 | 値 |
|---|---|
| アクティブな time series 数 | 500 万 |
| スクレイプ間隔 | 30 秒に 1 回 |
| データ保持期間 | 1 ヶ月 |
どうやって圧縮するか
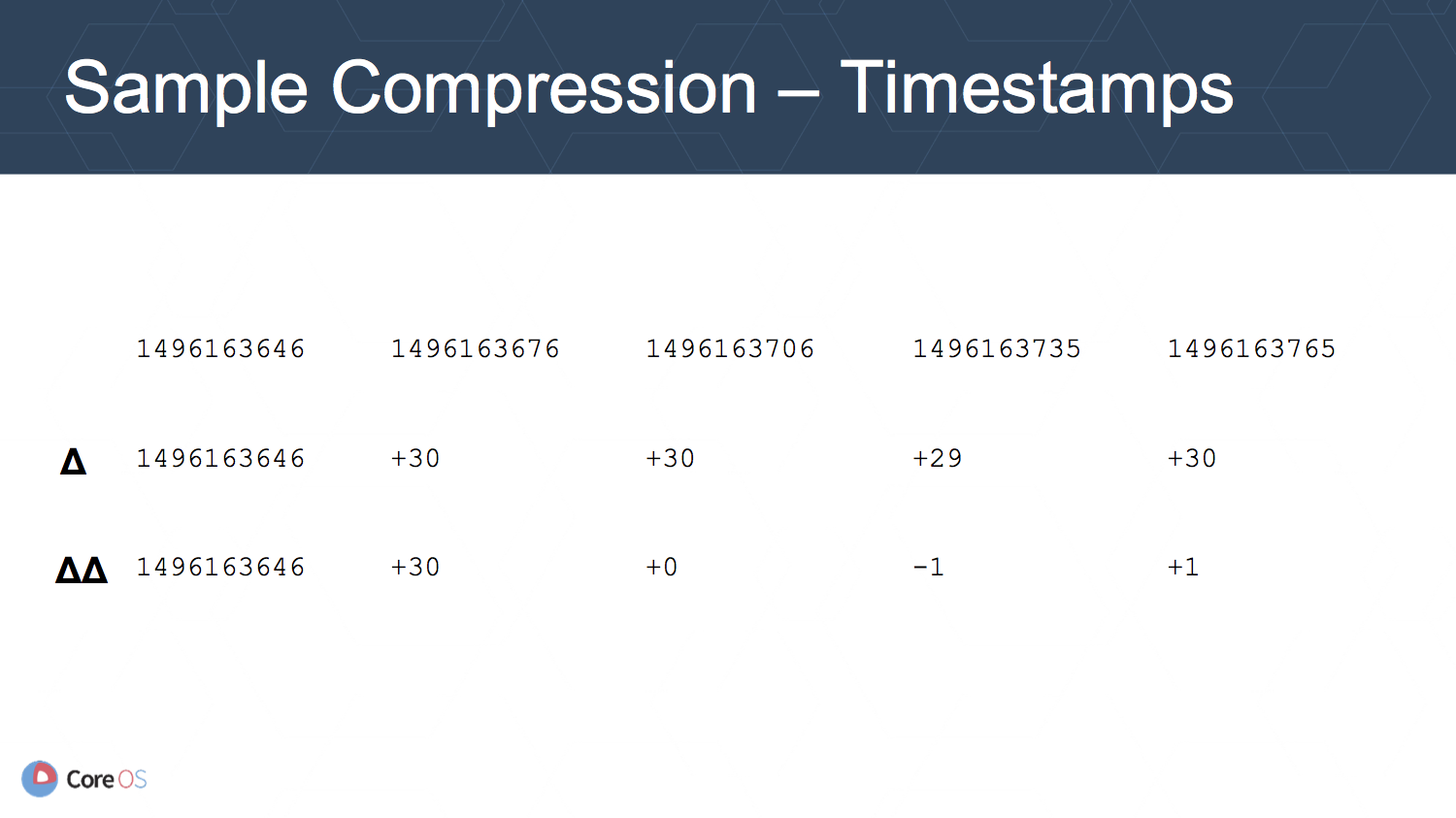
timestamp の圧縮には, サンプル間の timestamp の差分が timestamp そのものより小さな値になることを利用して行います. さらに, 差分同士の差分を取ることでより小さな値にすることができます.

値の圧縮も同様に差分を取ることで小さな値にできる場合が多いことを利用します.

この圧縮により同じ要件による必要ディスク容量が 7 TB から 0.8 TB へ改善することができるようです.
NOTE: この圧縮方法については v1 の段階でも起動オプションの追加により利用できるようです. (Refs: https://prometheus.io/docs/prometheus/1.8/storage/#chunk-encoding)
インデクスの改善

Prometheus を Kubernetes で利用する際, ローリングアップデートなどにより Pod が作り直されると, Pod やコンテナの ID などがメトリクスのラベルに入っている場合は time series がそこで途切れてしまい, 上の図のように全体のうちのアクティブな time series の比が小さくなってしまいます.

そのため, このような環境ではアクティブな time series の数よりも, 非アクティブなものを含む全体の time series の数がクエリのパフォーマンスに影響を与えます.
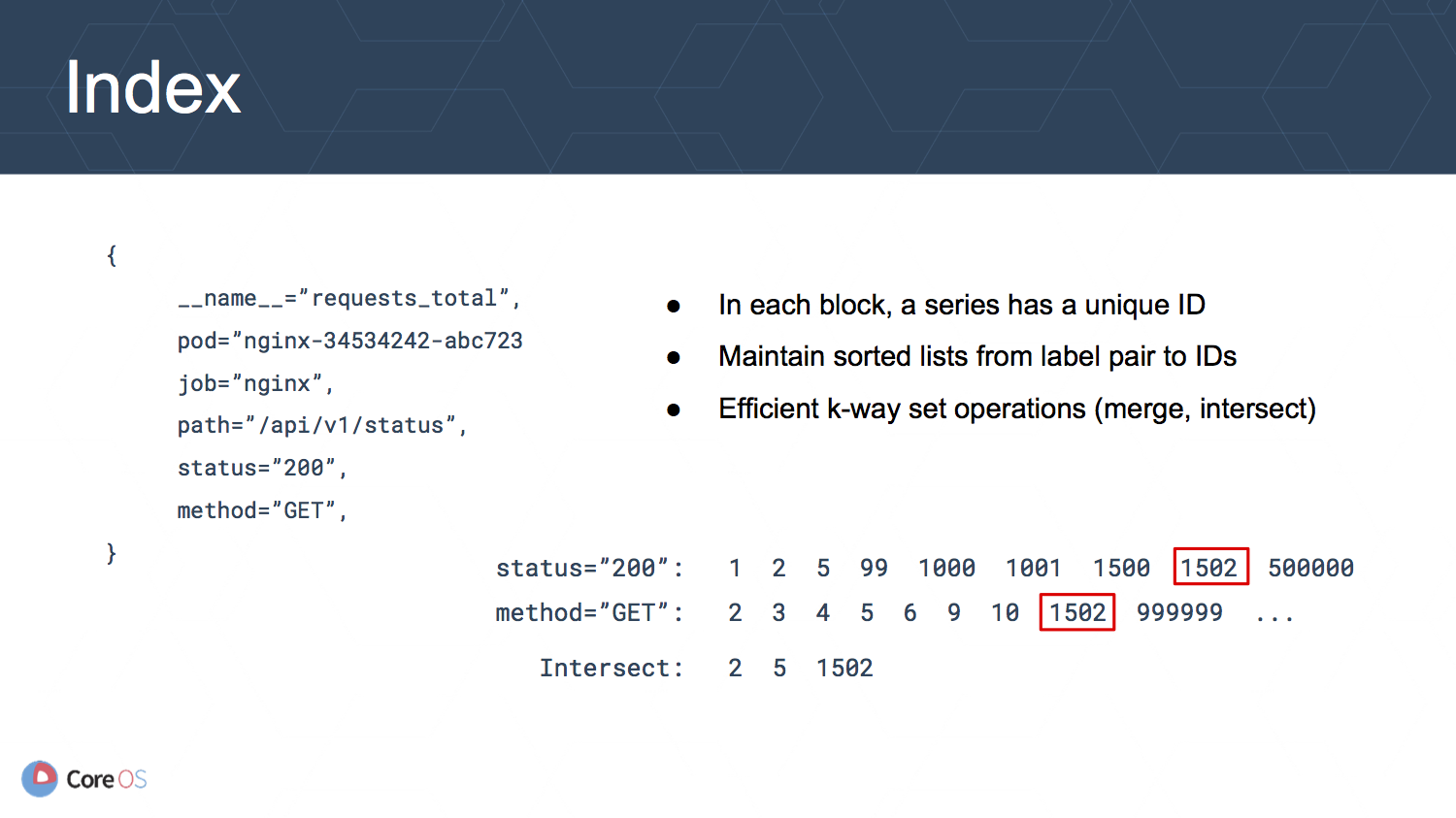
Prometheus v2 ではラベルと time series (メトリクス) の間の転置インデクスを導入することで改善を図っています. 各 time series は ID を持ち, その ID は任意のラベルとその値の組み合わせを持つ time series のリスト (転置インデクス) の中で利用されます. このリストをメンテナンスしていくことで, クエリの実行時には検索条件に対応したリストの共通部分を探すだけで目的の time series を見つけることができます.
ストレージレイアウトの変更

Prometheus v1 では一つの time series に付き, 一つのファイルを用意することで管理しています. また, ファイルへの書き込みはチャンクと呼ばれる単位で行われています.
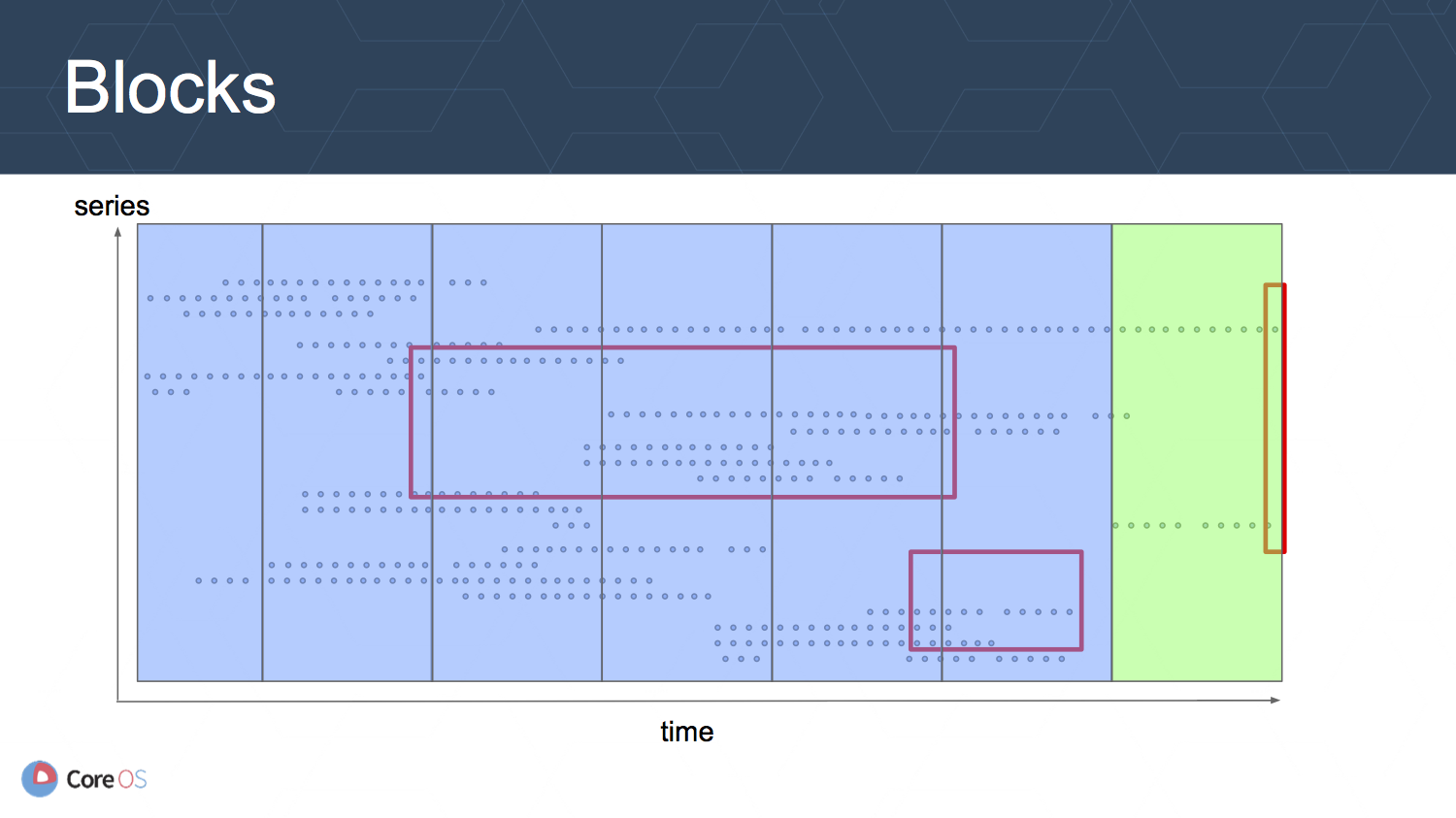
Prometheus v2 では時刻で区切られたブロックにより, 全ての time series を管理するように変更されています.
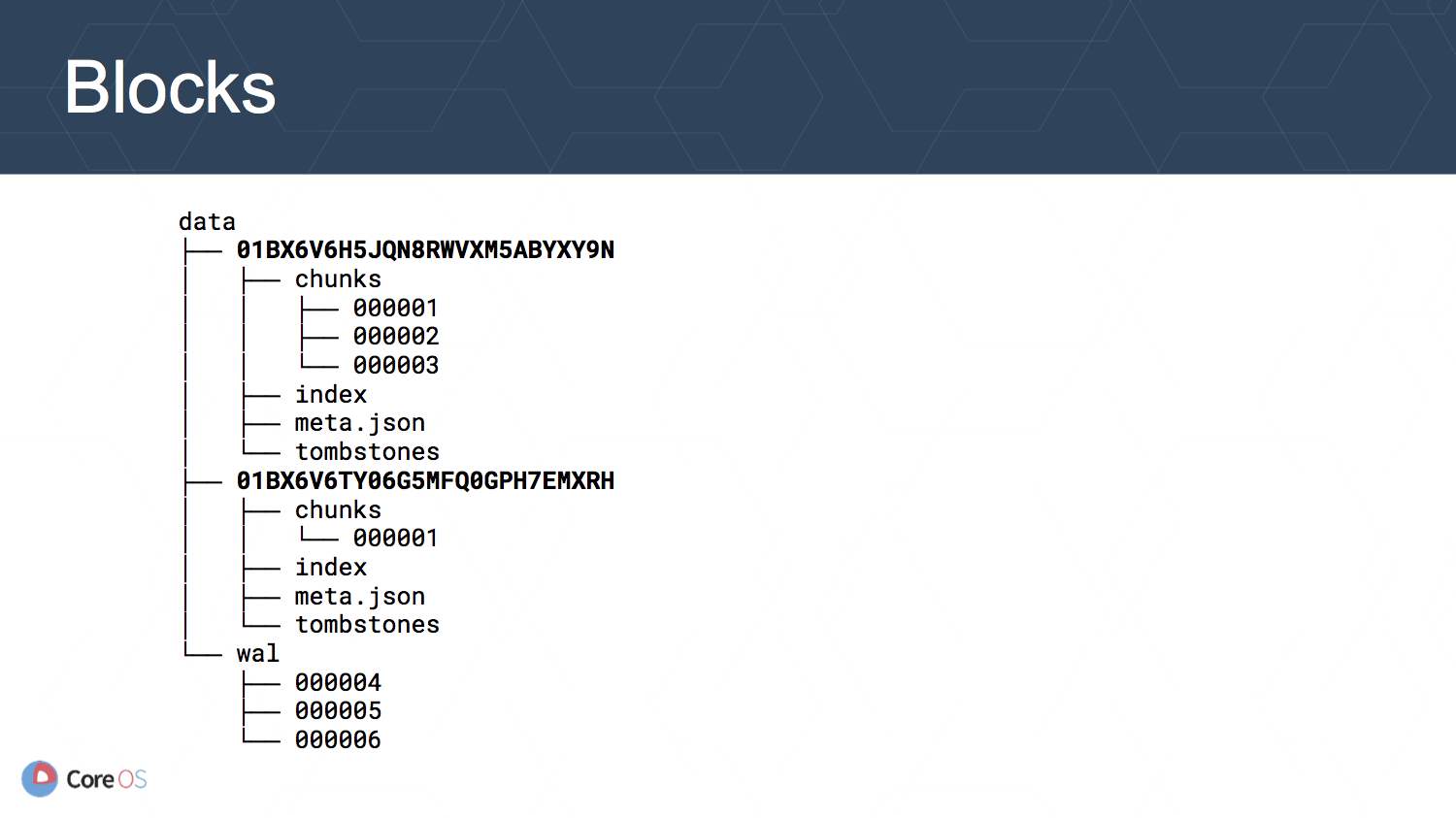
それぞれのブロックはディレクトリに分けて管理され, それぞれにインデクスとチャンクが用意されています. 新しいデータは Write Ahead Log (WAL) に書き込まれ, ある程度の時間が経つとブロックとして書き出されます. そのため, ブロックへの書き込みは行なわれないような設計になっています.
ベンチマーク
ベンチマークの環境は次の通りです.
| 項目 | 値 |
|---|---|
| 取得するサンプル数 | 110,000 個毎秒 |
| ターゲット数 | 850 |
比較する Prometheus の設定は次の通りです.
- Prometheus v1.5.2 - クエリの負荷あり
- Prometheus v1.5.2 - クエリの負荷なし
- Prometheus v2 (どの時点のものか不明) - クエリの負荷あり
- Prometheus v2 (どの時点のものか不明) - クエリの負荷なし
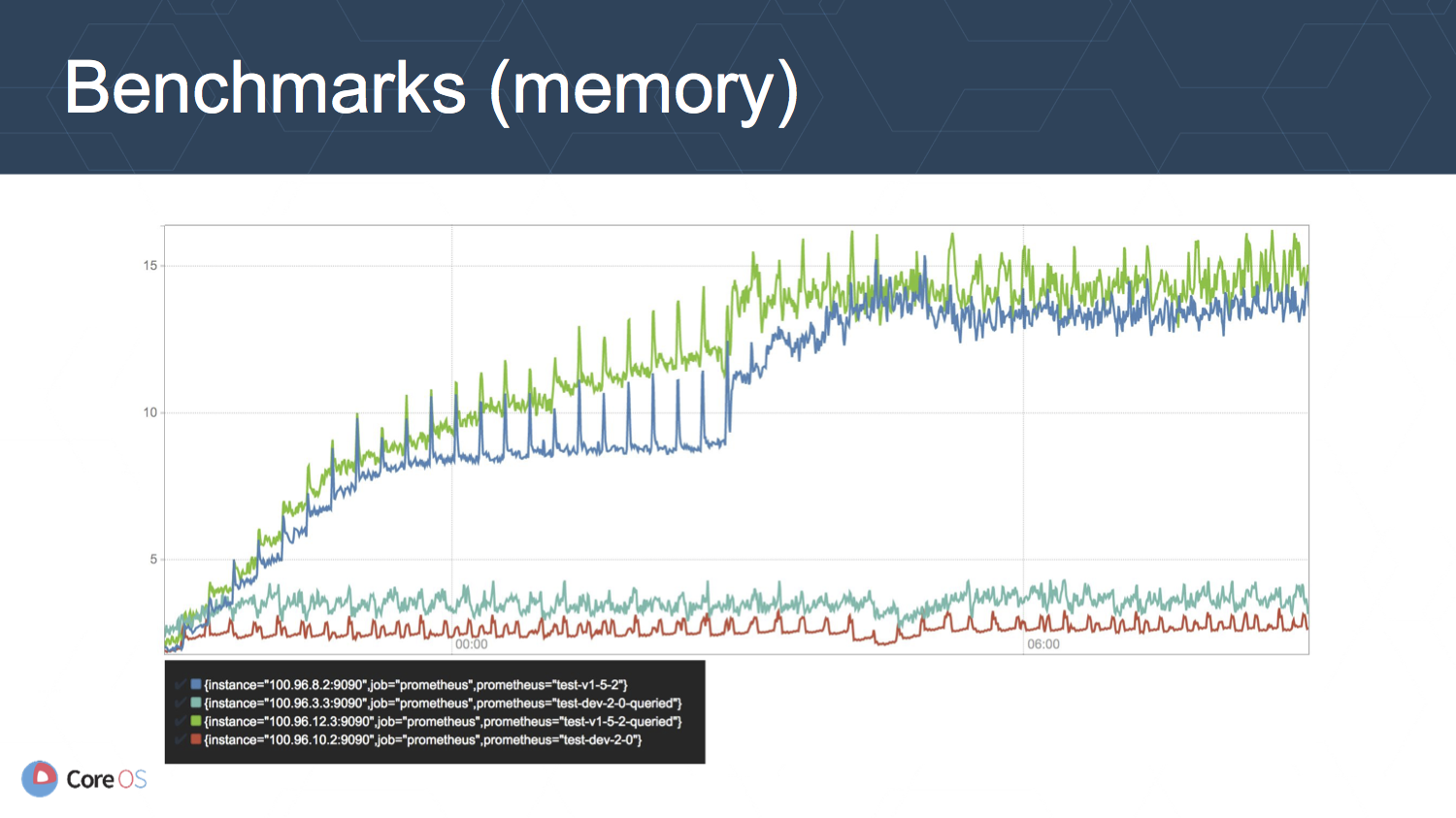
上の図はメモリの使用量 (GB) の推移を表しています. クエリの負荷のあり, なしに関わらず, v2 のメモリ使用量が v1.5.2 に比べて 3-4 分の 1 程度に抑えられています. 6 時間経過したあたりで v1.5.2 がスパイクしているのは, それがデータ保持期間に到達したからで, データの削除にもある程度の負荷がかかっていることを意味しています.
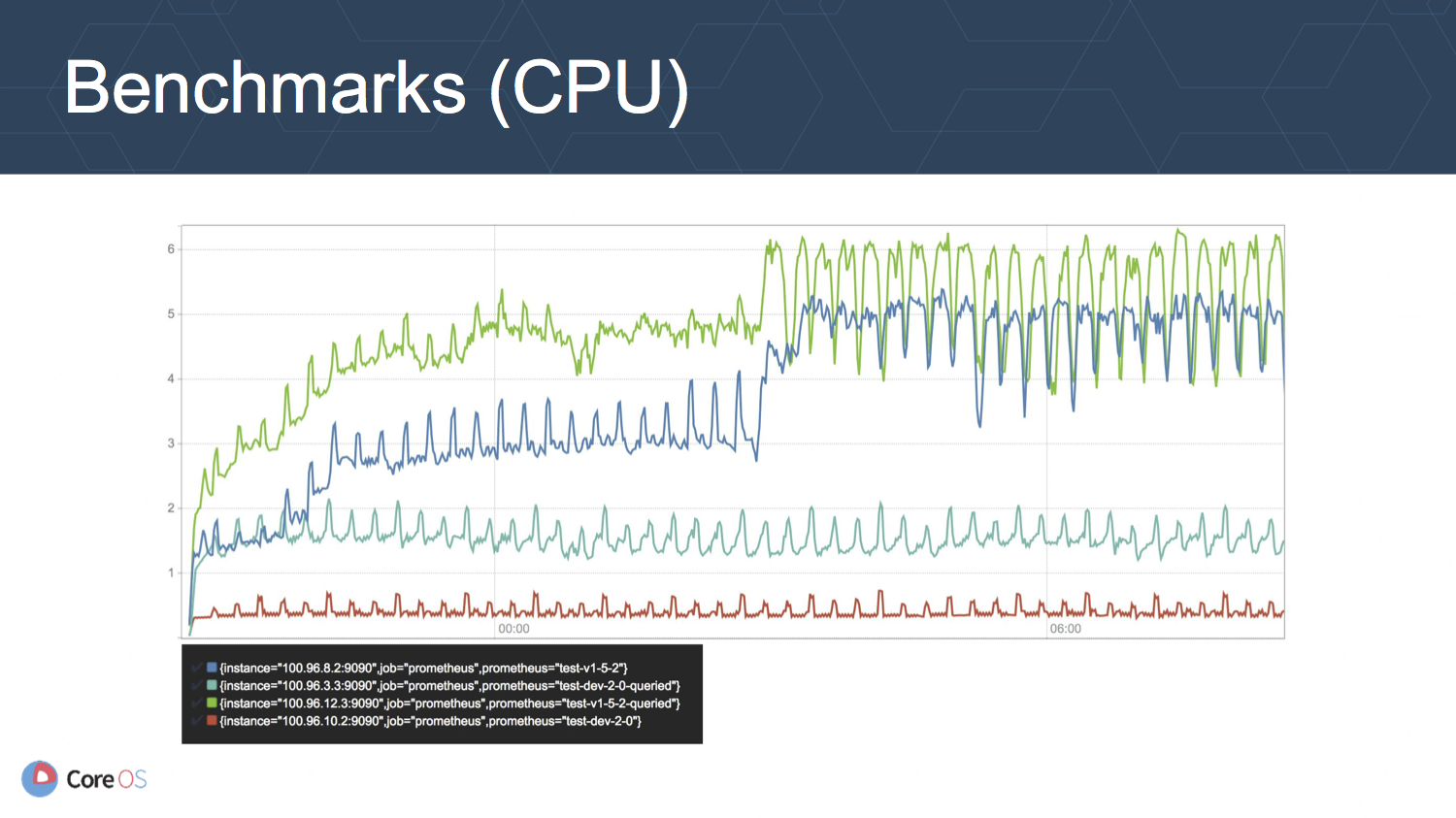
上の図は CPU 使用率 (cores/second) の推移を表しています. メモリ使用率の場合と同様の傾向ですが, v1.5.2 に比べて v2 が 3-10 分の 1 程度の使用率に抑えられています.
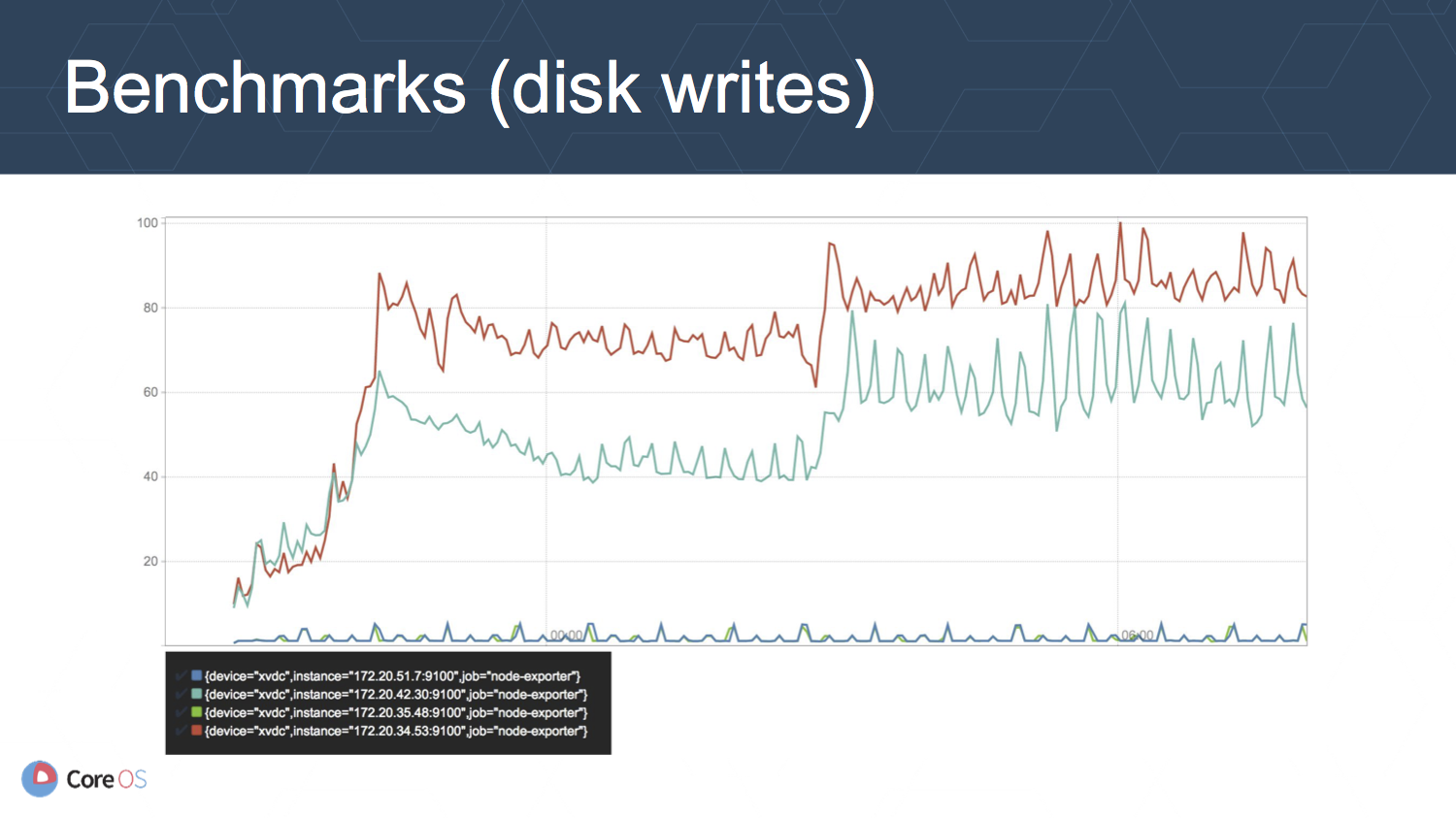
上の図はディスクへの書き込み (MB/second) の推移を表しています. このメトリクスが最も劇的に改善されています.
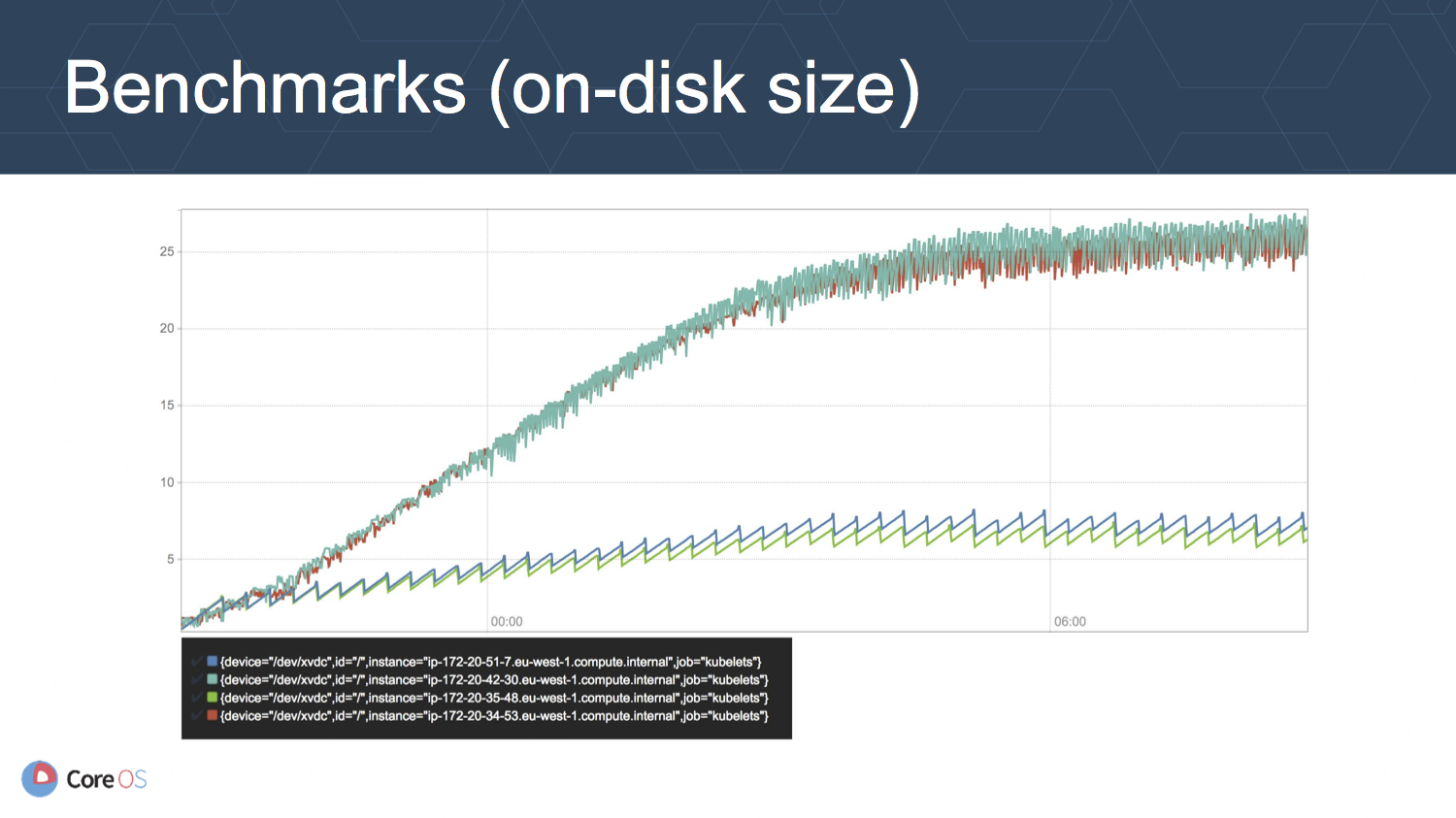
上の図はディスクサイズ (GB) の推移を表しています. v1.5.2 に比べて v2 では 5 分の 1 以下に抑えられていることが分かります.
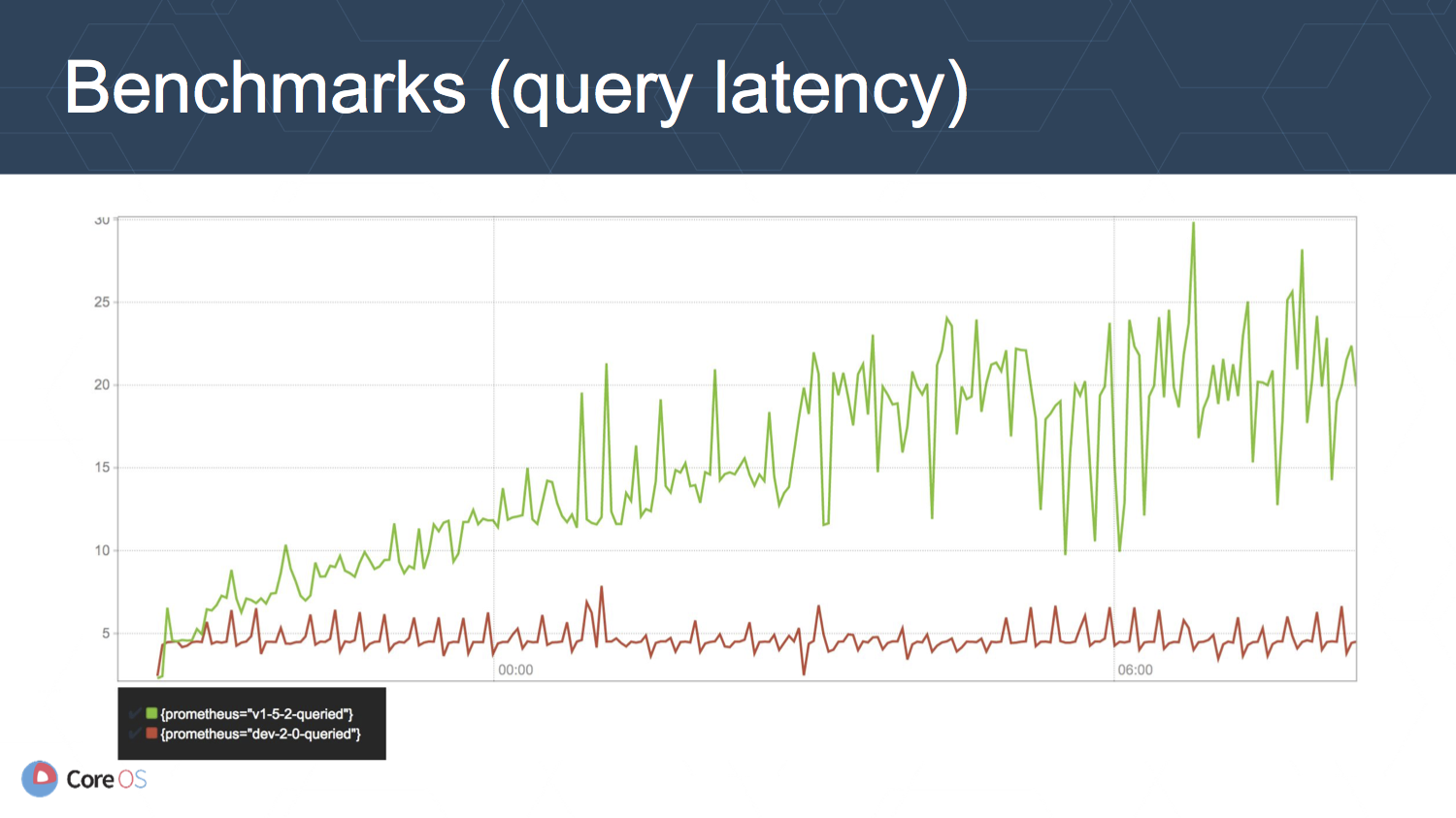
上の図はクエリのレイテンシ (秒, 99パーセンタイル) の推移を表しています.