はじめに
前回PythonからAzure AutoMLを使ってトレーニングを行いました。今回はトレーニングしてできたモデルをデプロイしてみようと思います。
開発環境
- OS Windows 10(NVIDIA GTX 1650Ti,16GB RAM, i5-10300H CPU)
- Visual Studio Code 1.73.1
- Python 3.9
モデルの登録
まずは前回トレーニングしたジョブの中で一番精度が良いモデルのパスを取得します。
そのためにはまずジョブの名前(ジョブID)、モデル名が必要となります。
ジョブIDの取得
前回のトレーニング時にジョブの返り値をprintするようにしていました。
returned_job = ml_client.jobs.create_or_update(classification_job)
print(f"Created job: {returned_job}")
その結果
Created job: ClassificationJob({'log_verbosity': <LogVerbosity.INFO: 'Info'>, 'target_column_name': 'Class', 'weight_column_name': None, 'validation_data_size': None, 'cv_split_column_names': None, 'n_cross_validations': 2, 'test_data_size': None, 'task_type': <TaskType.CLASSIFICATION: 'Classification'>, 'training_data': {'type': 'mltable', 'path': 'azureml://datastores/XXX'}, 'validation_data': {'type': 'mltable'}, 'test_data': None, 'environment_id': None, 'environment_variables': None, 'outputs': {}, 'type': 'automl', 'status': 'NotStarted', 'log_files': None, 'name': 'loyal_steelpan_wg197t69nt', 'description': None, 'tags': {}, 'properties': {}, 'id': '/subscriptions/XXX', 'Resource__source_path': None, 'base_path': 'C:\\Users\\XXX', 'creation_context': <azure.ai.ml._restclient.v2022_10_01_preview.models._models_py3.SystemData object at >, 'serialize': <msrest.serialization.Serializer object at >, 'inputs': {}, 'display_name': 'loyal_steelpan_wg197t69nt', 'experiment_name': 't-kawano-1216', 'compute': 'cpu-cluster', 'services': {'Tracking': <azure.ai.ml._restclient.v2022_10_01_preview.models._models_py3.JobService object at >, 'Studio': <azure.ai.ml._restclient.v2022_10_01_preview.models._models_py3.JobService object at >}, 'resources': <azure.ai.ml._restclient.v2022_10_01_preview.models._models_py3.JobResourceConfiguration object at 0>, 'identity': None, 'featurization': None, 'limits': <azure.ai.ml.entities._job.automl.tabular.limit_settings.TabularLimitSettings object at >, 'training': <azure.ai.ml.entities._job.automl.training_settings.ClassificationTrainingSettings object at >, 'primary_metric': <ClassificationPrimaryMetrics.AUC_WEIGHTED: 'AUCWeighted'>, 'positive_label': None})
この中の
'status': 'NotStarted', 'log_files': None, 'name': 'loyal_steelpan_wg197t69nt'
nameのところに書いているのがジョブの名前およびジョブIDです。
ドキュメントを参照してみると、statusやnameだけを取り出したい場合は次のようにします。
print(returned_job.status)
このstatusが
'status': 'Completed'
となったのを確認したらベストモデルの名前を探してみます。
ベストモデルの名前
では、ジョブの名前がわかったので、今度は1番良いモデルの名前を得るためにMLClientクラスからジョブの詳細を出します。
from azure.ai.ml.entities import Job
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
credential = DefaultAzureCredential()
subscription_id="<サブスクリプションID>"
resource_group="<リソース名>"
workspace_name="<ワークスペース名>"
ml_client = MLClient(credential, subscription_id, resource_group, workspace_name)
returned_job = ml_client.jobs.get(name="loyal_steelpan_wg197t69nt")
print(returned_job)
実行すると
ClassificationJob({'log_verbosity': <LogVerbosity.INFO: 'Info'>, 'target_column_name': 'Class', 'weight_column_name': None, 'validation_data_size': None, 'cv_split_column_names': None, 'n_cross_validations': 2, 'test_data_size': None, 'task_type': <TaskType.CLASSIFICATION: 'Classification'>, 'training_data': {'type': 'mltable', 'path': 'azureml://XXX'}, 'validation_data': {'type': 'mltable'}, 'test_data': None, 'environment_id': None, 'environment_variables': None, 'outputs': {}, 'type': 'automl', 'status': 'Completed', 'log_files': None, 'name': 'loyal_steelpan_wg197t69nt', 'description': None, 'tags': {'_aml_system_automl_mltable_data_json': '{"Type":"MLTable","TrainData":{"Uri":"azureml://XXX","ResolvedUri":null,"AssetId":null},"TestData":null,"ValidData":null}', 'model_explain_run': 'best_run', '_aml_system_automl_run_workspace_id': '', '_aml_system_azureml.automlComponent': 'AutoML', '_azureml.ComputeTargetType': 'STANDARD_D2_V2', 'pipeline_id': '', 'score': '', 'predicted_cost': '', 'fit_time': '', 'training_percent': '', 'iteration': '', 'run_preprocessor': '', 'run_algorithm': '', 'automl_best_child_run_id': 'loyal_steelpan_wg197t69nt_4', 'model_explain_best_run_child_id': 'loyal_steelpan_wg197t69nt_4'}, 'properties': {'num_iterations': '5', 'training_type': 'TrainFull', 'acquisition_function': 'EI', 'primary_metric': 'AUC_weighted', 'train_split': '0', 'acquisition_parameter': '0', 'num_cross_validation': '2', 'target': 'cpu-cluster', 'AMLSettingsJsonString': '{"path":"./sample_projects/","subscription_id":"XXX","resource_group":"t-kawano","workspace_name":"t-kawano-test","compute_target":"cpu-cluster","iterations":5,"primary_metric":"AUC_weighted","task_type":"classification","IsImageTask":false,"IsTextDNNTask":false,"n_cross_validations":2,"preprocess":true,"is_timeseries":false,"time_column_name":null,"grain_column_names":null,"max_cores_per_iteration":-1,"max_concurrent_iterations":1,"iteration_timeout_minutes":20,"enforce_time_on_windows":false,"experiment_timeout_minutes":600,"exit_score":"NaN","experiment_exit_score":"NaN","blacklist_models":["XGBoostClassifier"],"blacklist_algos":["XGBoostClassifier","TensorFlowLinearClassifier","TensorFlowDNN"],"auto_blacklist":false,"blacklist_samples_reached":false,"exclude_nan_labels":false,"verbosity":20,"model_explainability":true,"enable_onnx_compatible_models":true,"enable_feature_sweeping":false,"send_telemetry":true,"enable_early_stopping":true,"early_stopping_n_iters":20,"distributed_dnn_max_node_check":false,"enable_distributed_featurization":false,"enable_distributed_dnn_training":true,"enable_distributed_dnn_training_ort_ds":false,"ensemble_iterations":5,"enable_tf":false,"enable_cache":false,"enable_subsampling":false,"metric_operation":"maximize","enable_streaming":false,"use_incremental_learning_override":false,"force_streaming":false,"enable_dnn":false,"is_gpu_tmp":false,"enable_run_restructure":false,"featurization":"auto","label_column_name":"Class","weight_column_name":null,"miro_flight":"default","many_models":false,"many_models_process_count_per_node":0,"automl_many_models_scenario":null,"enable_batch_run":true,"save_mlflow":true,"track_child_runs":true,"start_auxiliary_runs_before_parent_complete":false,"test_include_predictions_only":false,"enable_mltable_quick_profile":"True","has_multiple_series":false,"enable_ensembling":true,"enable_stack_ensembling":true,"ensemble_download_models_timeout_sec":300.0,"stack_meta_learner_train_percentage":0.2}', 'DataPrepJsonString': None, 'EnableSubsampling': 'False', 'runTemplate': 'AutoML', 'azureml.runsource': 'automl', 'ClientType': 'Mfe', '_aml_system_scenario_identification': 'Remote.Parent', 'environment_cpu_name': 'AzureML-AutoML', 'environment_cpu_label': 'prod', 'environment_gpu_name': 'AzureML-AutoML-GPU', 'environment_gpu_label': 'prod', 'root_attribution': 'automl', 'attribution': 'AutoML', 'Orchestrator': 'AutoML', 'CancelUri': 'https://XXX', 'mltable_data_json': '{"Type":"MLTable","TrainData":{"Uri":"azureml://XXX","AssetId":"azureml://XXX"},"TestData":null,"ValidData":null}', 'ClientSdkVersion': '1.48.0', 'snapshotId': '00000000-0000-0000-0000-000000000000', 'SetupRunId': 'loyal_steelpan_wg197t69nt_setup', 'SetupRunContainerId': 'dcid.loyal_steelpan_wg197t69nt_setup', 'ProblemInfoJsonString': '{"dataset_num_categorical": 0, "is_sparse": false, "subsampling": false, "has_extra_col": true, "dataset_classes": 2, "dataset_features": 30, "dataset_samples": 284807, "single_frequency_class_detected": false}', 'FeaturizationRunJsonPath': 'featurizer_container.json', 'FeaturizationRunId': 'loyal_steelpan_wg197t69nt_featurize', 'ModelExplainRunId': 'loyal_steelpan_wg197t69nt_ModelExplain'}, 'id': '/subscriptions/XXX', 'Resource__source_path': None, 'base_path': 'C:\\Users\\XXX', 'creation_context': <azure.ai.ml._restclient.v2022_10_01_preview.models._models_py3.SystemData object at 0x0000014B4EEF6670>, 'serialize': <msrest.serialization.Serializer object at 0x0000014B4EF58730>, 'inputs': {}, 'display_name': 'loyal_steelpan_wg197t69nt', 'experiment_name': 't-kawano-1227', 'compute': '/subscriptions/XXX', 'services': {'Tracking': <azure.ai.ml._restclient.v2022_10_01_preview.models._models_py3.JobService object at 0x0000014B4EEF6700>, 'Studio': <azure.ai.ml._restclient.v2022_10_01_preview.models._models_py3.JobService object at 0x0000014B4EEF69D0>}, 'resources': <azure.ai.ml._restclient.v2022_10_01_preview.models._models_py3.JobResourceConfiguration object at 0x0000014B4EEF6460>, 'identity': None, 'featurization': None, 'limits': <azure.ai.ml.entities._job.automl.tabular.limit_settings.TabularLimitSettings object at 0x0000014B4E4E1E80>, 'training': <azure.ai.ml.entities._job.automl.training_settings.ClassificationTrainingSettings object at 0x0000014B4E4E1F70>, 'primary_metric': <ClassificationPrimaryMetrics.AUC_WEIGHTED: 'AUCWeighted'>, 'positive_label': None})
この中に
'automl_best_child_run_id': 'loyal_steelpan_wg197t69nt_4'
という項目があります。これが一番良いモデルの名前です。
モデル登録
では、モデル名がわかったのでモデル登録をしていきます。
from azure.ai.ml.entities import Model
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
subscription_id="<サブスクリプションID>"
resource_group="<リソース名>"
workspace_name="<ワークスペース名>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
run_model = Model(
path="azureml://subscriptions/<サブスクリプションID>/resourceGroups/<リソースグループ名>/workspaces/<ワークスペース名>/datastores/workspaceartifactstore/paths/ExperimentRun/dcid.<モデルの名前>/outputs/mlflow-model/",
name="creditcardmodel"
)
ml_client.models.create_or_update(run_model)
AutoMLで作成されたモデルはdatastoresの固定の場所に入るため、先ほど取得したモデルの名前をdcid.の次に入力します。
path="azureml://subscriptions/<サブスクリプションID>/resourceGroups/<リソースグループ名>/workspaces/<ワークスペース名>/datastores/workspaceartifactstore/paths/ExperimentRun/dcid.loyal_steelpan_wg197t69nt_4/outputs/mlflow-model/"
実際に実行してPythonからモデルを登録してみると…
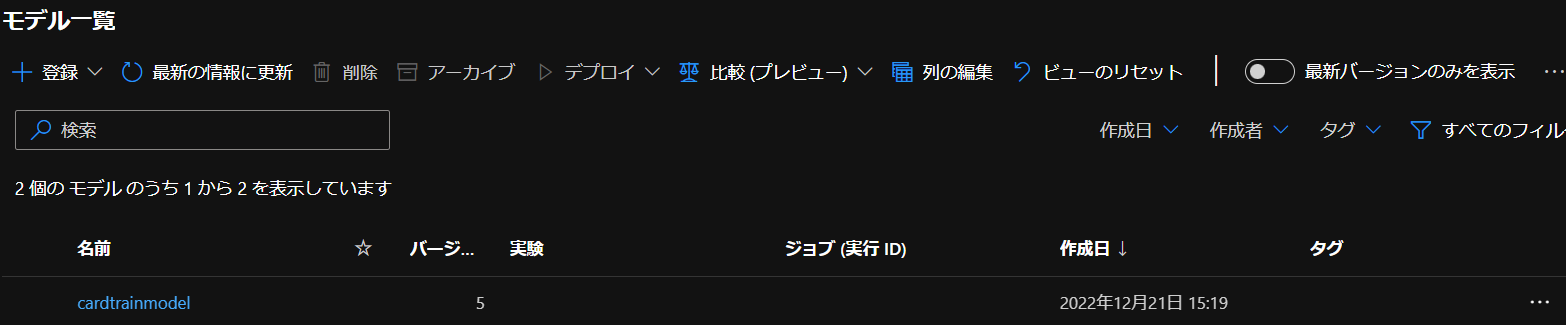
モデル一覧にちゃんとできていました。
モデルのデプロイ
まずは登録したモデルのエンドポイントを作成します。
エンドポイント作成
from azure.ai.ml import MLClient
from azure.ai.ml.entities import ManagedOnlineEndpoint
from azure.identity import DefaultAzureCredential
subscription_id="<サブスクリプションID>"
resource_group="<リソース名>"
workspace_name="<ワークスペース名>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
endpoint_name = "test-kawano-endpoint"
endpoint = ManagedOnlineEndpoint(
name=endpoint_name, description="this is a sample local endpoint"
)
ml_client.online_endpoints.begin_create_or_update(endpoint)
実行後、このように作成できました!

Pythonからエンドポイントが作成できたかどうか調べるときは次のコードでできます。
from azure.ai.ml.entities import OnlineEndpoint
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
credential = DefaultAzureCredential()
subscription_id="<サブスクリプションID>"
resource_group="<リソース名>"
workspace_name="<ワークスペース名>"
ml_client = MLClient(credential, subscription_id, resource_group, workspace_name)
endpoint = ml_client.online_endpoints.get(name="test-kawano-endpoint")
print(endpoint)
MLClientクラスを使ってstatusチェックしたいエンドポイント名を入力すると、
ManagedOnlineEndpoint({'public_network_access': 'Enabled', 'provisioning_state': 'Succeeded', 'scoring_uri': 'https://XXX', 'openapi_uri': 'https://XXX', 'name': 'test-kawano-endpoint', 'description': 'this is a sample local endpoint', 'tags': {}, 'properties': {'azureml.onlineendpointid': '/subscriptions/XXX', 'AzureAsyncOperationUri': 'https://XXX'}, 'id': '/subscriptions/XXX', 'Resource__source_path': None, 'base_path': 'C:\\Users\\XXX': None, 'serialize': <msrest.serialization.Serializer object at XXX>, 'auth_mode': 'key', 'location': 'japaneast', 'identity': <azure.ai.ml.entities._credentials.IdentityConfiguration object at XXX>, 'traffic': {}, 'mirror_traffic': {}, 'kind': 'Managed'})
こちらが返ってきます。
'provisioning_state': 'Succeeded'
エンドポイントが正常に作成されていたら、上記のようにSucceededとなります。
デプロイ
それでは登録したモデルのデプロイを行います。
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration,
)
from azure.identity import DefaultAzureCredential
subscription_id="<サブスクリプションID>"
resource_group="<リソース名>"
workspace_name="<ワークスペース名>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
local_endpoint_name = "t-kawano-1216"#エンドポイント名
model = Model(
path="azureml://subscriptions/<サブスクリプションID>/resourceGroups/<リソースグループ名>/workspaces/<ワークスペース名>/datastores/workspaceartifactstore/paths/ExperimentRun/dcid.<モデル名>/outputs/mlflow-model/",
name="cardtrainmodel"
)
env = Environment(
conda_file="conda_env_v_1_0_0.yml",
image="mcr.microsoft.com/azureml/minimal-ubuntu20.04-py38-cpu-inference:latest",
)
deployment = ManagedOnlineDeployment(
name="model-1216-deploy",
endpoint_name=local_endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="./",
scoring_script="scoring_file_v_2_0_0.py"
),
instance_type="Standard_DS2_v2",
instance_count=1,
)
ml_client.online_deployments.begin_create_or_update(deployment=deployment)
conda_env_v_1_0_0.ymlとscoring_file_v_2_0_0.pyは作成された1番良いモデルの「出力とログ」から取得しました。
出力とログ
「出力とログ」にはベストモデルの説明するためのexplanationフォルダとoutputsフォルダが生成されています。

この「outputs」フォルダの中身はコチラ
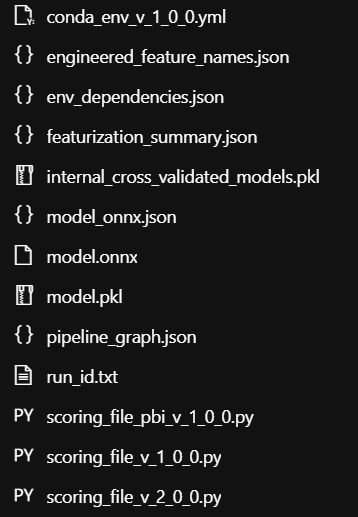
onnx形式のモデルや3種類のscoring_fileがあります。
今回はcondaファイルはバージョン1を選択しましたが、scoring_fileの方がバージョン2なので、condaファイルは今後修正が必要かと思われます。
name: project_environment
dependencies:
# The python interpreter version.
# Currently Azure ML only supports 3.8 and later.
- python=3.7.9
- pip:
- azureml-train-automl-runtime==1.47.0
- inference-schema
- azureml-interpret==1.47.0
- azureml-defaults==1.47.0
- numpy==1.21.6
- pandas==1.1.5
- scikit-learn==0.22.1
- py-xgboost==1.3.3
- fbprophet==0.7.1
- holidays==0.10.3
- psutil==5.9.0
channels:
- anaconda
- conda-forge
scoring_file_v_2_0_0.pyの中身を見てみるとこんな感じです。
import json
import logging
import os
import pickle
import numpy as np
import pandas as pd
import joblib
import azureml.automl.core
from azureml.automl.core.shared import logging_utilities, log_server
from azureml.telemetry import INSTRUMENTATION_KEY
from inference_schema.schema_decorators import input_schema, output_schema
from inference_schema.parameter_types.numpy_parameter_type import NumpyParameterType
from inference_schema.parameter_types.pandas_parameter_type import PandasParameterType
from inference_schema.parameter_types.standard_py_parameter_type import StandardPythonParameterType
data_sample = PandasParameterType(pd.DataFrame({"Time": pd.Series([0.0], dtype="float64"), "V1": pd.Series([0.0], dtype="float64"), "V2": pd.Series([0.0], dtype="float64"), "V3": pd.Series([0.0], dtype="float64"), "V4": pd.Series([0.0], dtype="float64"), "V5": pd.Series([0.0], dtype="float64"), "V6": pd.Series([0.0], dtype="float64"), "V7": pd.Series([0.0], dtype="float64"), "V8": pd.Series([0.0], dtype="float64"), "V9": pd.Series([0.0], dtype="float64"), "V10": pd.Series([0.0], dtype="float64"), "V11": pd.Series([0.0], dtype="float64"), "V12": pd.Series([0.0], dtype="float64"), "V13": pd.Series([0.0], dtype="float64"), "V14": pd.Series([0.0], dtype="float64"), "V15": pd.Series([0.0], dtype="float64"), "V16": pd.Series([0.0], dtype="float64"), "V17": pd.Series([0.0], dtype="float64"), "V18": pd.Series([0.0], dtype="float64"), "V19": pd.Series([0.0], dtype="float64"), "V20": pd.Series([0.0], dtype="float64"), "V21": pd.Series([0.0], dtype="float64"), "V22": pd.Series([0.0], dtype="float64"), "V23": pd.Series([0.0], dtype="float64"), "V24": pd.Series([0.0], dtype="float64"), "V25": pd.Series([0.0], dtype="float64"), "V26": pd.Series([0.0], dtype="float64"), "V27": pd.Series([0.0], dtype="float64"), "V28": pd.Series([0.0], dtype="float64"), "Amount": pd.Series([0.0], dtype="float64")}))
input_sample = StandardPythonParameterType({'data': data_sample})
method_sample = StandardPythonParameterType("predict")
sample_global_params = StandardPythonParameterType({"method": method_sample})
result_sample = NumpyParameterType(np.array([False]))
output_sample = StandardPythonParameterType({'Results':result_sample})
try:
log_server.enable_telemetry(INSTRUMENTATION_KEY)
log_server.set_verbosity('INFO')
logger = logging.getLogger('azureml.automl.core.scoring_script_v2')
except:
pass
def init():
global model
model_path = os.path.join(os.getenv('AZUREML_MODEL_DIR'), 'model.pkl')
path = os.path.normpath(model_path)
path_split = path.split(os.sep)
log_server.update_custom_dimensions({'model_name': path_split[-3], 'model_version': path_split[-2]})
try:
logger.info("Loading model from path.")
model = joblib.load(model_path)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
@input_schema('GlobalParameters', sample_global_params, convert_to_provided_type=False)
@input_schema('Inputs', input_sample)
@output_schema(output_sample)
def run(Inputs, GlobalParameters={"method": "predict"}):
data = Inputs['data']
if GlobalParameters.get("method", None) == "predict_proba":
result = model.predict_proba(data)
elif GlobalParameters.get("method", None) == "predict":
result = model.predict(data)
else:
raise Exception(f"Invalid predict method argument received. GlobalParameters: {GlobalParameters}")
if isinstance(result, pd.DataFrame):
result = result.values
return {'Results':result.tolist()}
これでデプロイ行い、完了後テストを行うと…
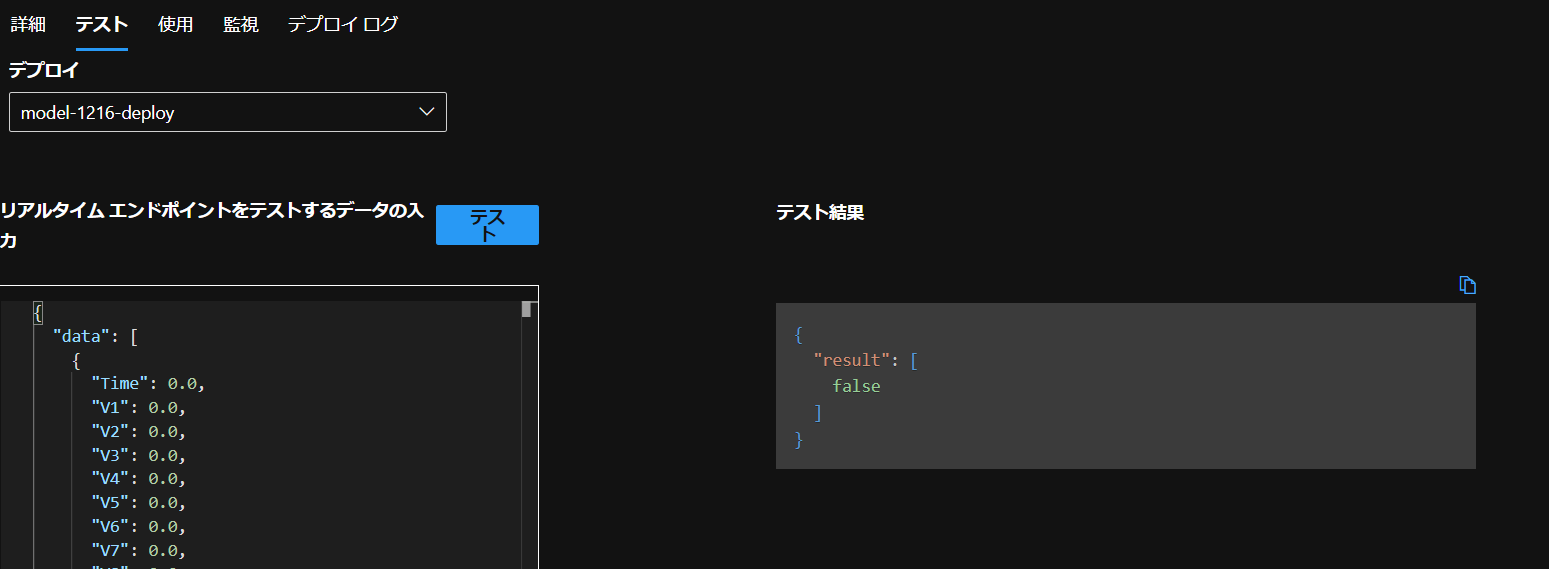
このように結果が返ってきました。
推論
「使用」タブからpythonコードを取得できるので、これを使って推論を行います。
import urllib.request
import json
import os
import ssl
def allowSelfSignedHttps(allowed):
if allowed and not os.environ.get('PYTHONHTTPSVERIFY', '') and getattr(ssl, '_create_unverified_context', None):
ssl._create_default_https_context = ssl._create_unverified_context
allowSelfSignedHttps(True)
data = {
"Inputs": {
"data": [
{
"Time": 0.0,
"V1": 0.0,
"V2": 0.0,
"V3": 0.0,
"V4": 0.0,
"V5": 0.0,
"V6": 0.0,
"V7": 0.0,
"V8": 0.0,
"V9": 0.0,
"V10": 0.0,
"V11": 0.0,
"V12": 0.0,
"V13": 0.0,
"V14": 0.0,
"V15": 0.0,
"V16": 0.0,
"V17": 0.0,
"V18": 0.0,
"V19": 0.0,
"V20": 0.0,
"V21": 0.0,
"V22": 0.0,
"V23": 0.0,
"V24": 0.0,
"V25": 0.0,
"V26": 0.0,
"V27": 0.0,
"V28": 0.0,
"Amount": 0.0
}
]
},
"GlobalParameters": {
"method": "predict"
}
}
body = str.encode(json.dumps(data))
url = 'https://XXX'
api_key = '<主キー>'
if not api_key:
raise Exception("A key should be provided to invoke the endpoint")
headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key), 'azureml-model-deployment': 'model-1227-deploy' }
req = urllib.request.Request(url, body, headers)
try:
response = urllib.request.urlopen(req)
result = response.read()
print(result)
except urllib.error.HTTPError as error:
print("The request failed with status code: " + str(error.code))
print(error.info())
print(error.read().decode("utf8", 'ignore'))
修正した箇所はapi_keyのみです。
ここは主キーのところから取得できます。
実行したら、
b'{"Results": [false]}'
と結果が返ってきました。今回のcreditcardの学習についてはClass列がfalseとtrueどちらになるかを予測するものだったので、動いていることが確認できました。
まとめ
- AutoMLをPythonからデプロイしてみた
- ベストモデルの名前はMLClientのjobsの詳細で取得可能