はじめに
今回はAzure Auto MLで作成したモデルをPythonからデプロイ・推論まで行ってみます。
開発環境
- OS Windows 10(NVIDIA GTX 1650Ti,16GB RAM, i5-10300H CPU)
- Visual Studio Code 1.73.1
- Python 3.7
モデルのデプロイ・推論を行う
前回作成したトレーニング済みのモデルをデプロイしていきます。
(Pythonからトレーニングさせる方法についてはこちらを参照ください。)
モデルの登録
from azureml.core.experiment import Experiment
from azureml.core import Workspace
from azureml.train.automl.run import AutoMLRun
ws = Workspace.from_config()
experiment = ws.experiments["t-kawano-1207"]#実験名
automl_run = AutoMLRun(experiment, run_id='AutoML_XXX')#実行ID
best_run = automl_run.get_best_child()
model = automl_run.register_model(model_name="trainmodel")#モデル名
まずはワークスペースへの接続を行い、登録するモデルがある実験の内容を取得します。
実行IDは、Pythonからトレーニングする際に
run = experiment.submit(automl_classifier)
print(run)
runを表示するようにしたらこちらの「AutoML_XXX」の部分から取得できます。
Submitting remote run.
Run(Experiment: t-kawano-1207,
Id: AutoML_XXX,
Type: automl,
Status: NotStarted)
もしくは完了したジョブの「名前」のところから実行IDを取得することもできます。
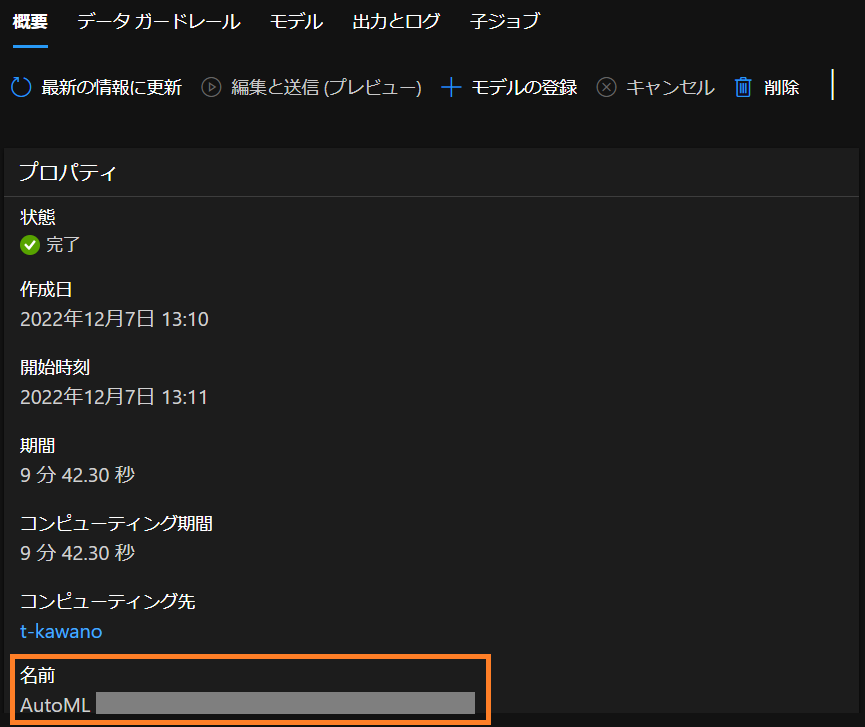
そしてget_best_child()メソッドによって、作成されたモデルの中で最も良いスコアを持つモデルを選択。これをregister_model()で名前を決め、モデルを登録します。
実行後、ワークスペースに戻って「モデル」タグから一覧を確認すると

「trainmodel」という名前のモデルが登録されているのを確認できました。
登録したモデルをデプロイする
from azureml.core import Workspace
from azureml.core.model import InferenceConfig
from azureml.core.webservice.aci import AciWebservice
from azureml.core.model import Model
ws = Workspace.from_config()
model = ws.models["trainmodel"]#モデル名
inference_config = InferenceConfig(entry_script="score.py")#エントリスクリプトを入力
deployment_config = AciWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "t-kawano-test", [model], inference_config, deployment_config)#サービス名を入力
デプロイするモデル名を入れ、エントリスクリプトのファイル名を入力します。
そして作成するWebサービスエンドポイントに割り当てるCPUのコア数とメモリ量を指定し、サービス名を入力します。
これを実行すると、デプロイができます。
また、エントリスクリプトの中身はこちらです。
import pandas as pd
import json
from azureml.core.model import Model
import joblib
import io
def init():
global model
model_path = Model.get_model_path('trainmodel')
model = joblib.load(model_path)
def run(raw_data):
df = pd.read_csv(io.StringIO(json.loads(raw_data)['data']))
predictions = model.predict(df)
df["Class"] = predictions
return df.to_csv(index=False)
initで登録したモデルのロードを行い、runで推論を行うという構成です。
APIからCSV形式のデータが入力されるので、これをpandasで読み込みます。
その後、model.predictで推論を行い、この結果を'Class'列に追加し、CSV形式で出力するという流れです。
デプロイした後確認すると…
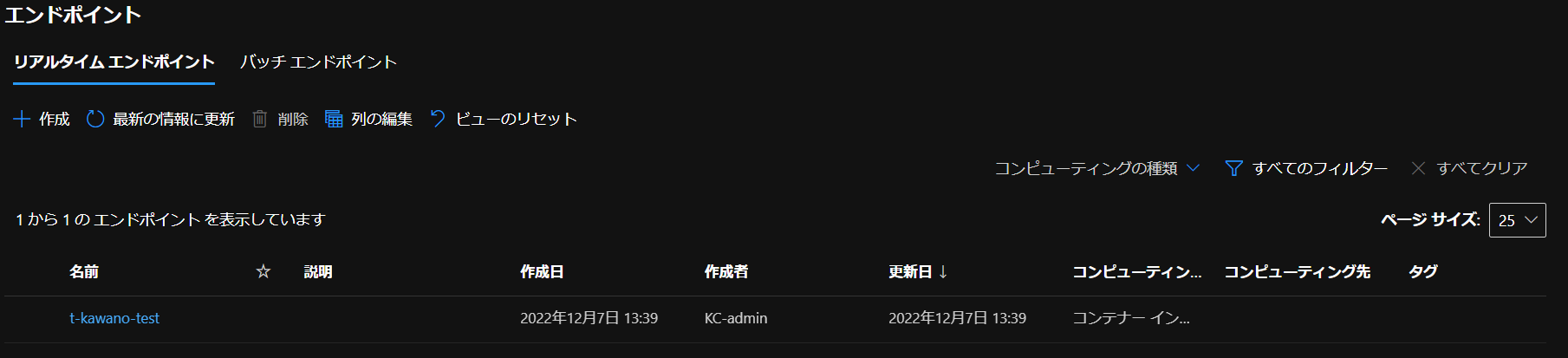
大体10分ほどでエンドポイントが作成されました!
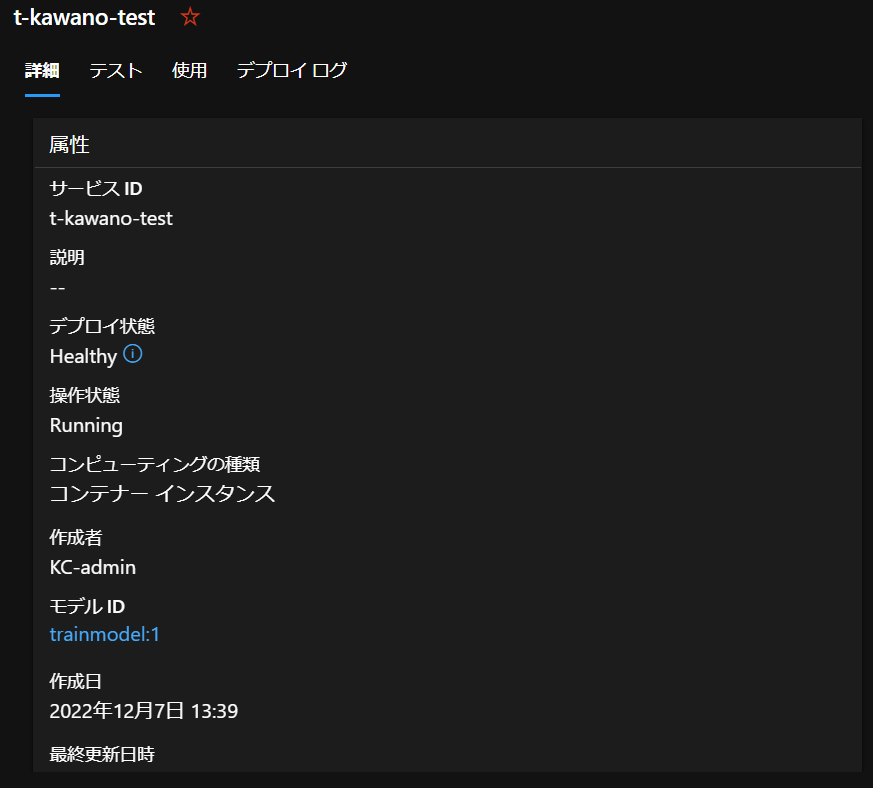
デプロイ状態も「Healthy」となっており、エンドポイントを使用できる状態になっています。
デプロイしたモデルを使う
import json
import pandas as pd
import requests
df = pd.read_csv("creditcard_NoClass.csv")
data = { "data": df.to_csv(index=False) }
body = str.encode(json.dumps(data))
print(body)
url = 'http://XXX'
headers = {'Content-Type':'application/json'}
response = requests.post(url, data=body, headers=headers)
print(response.text)
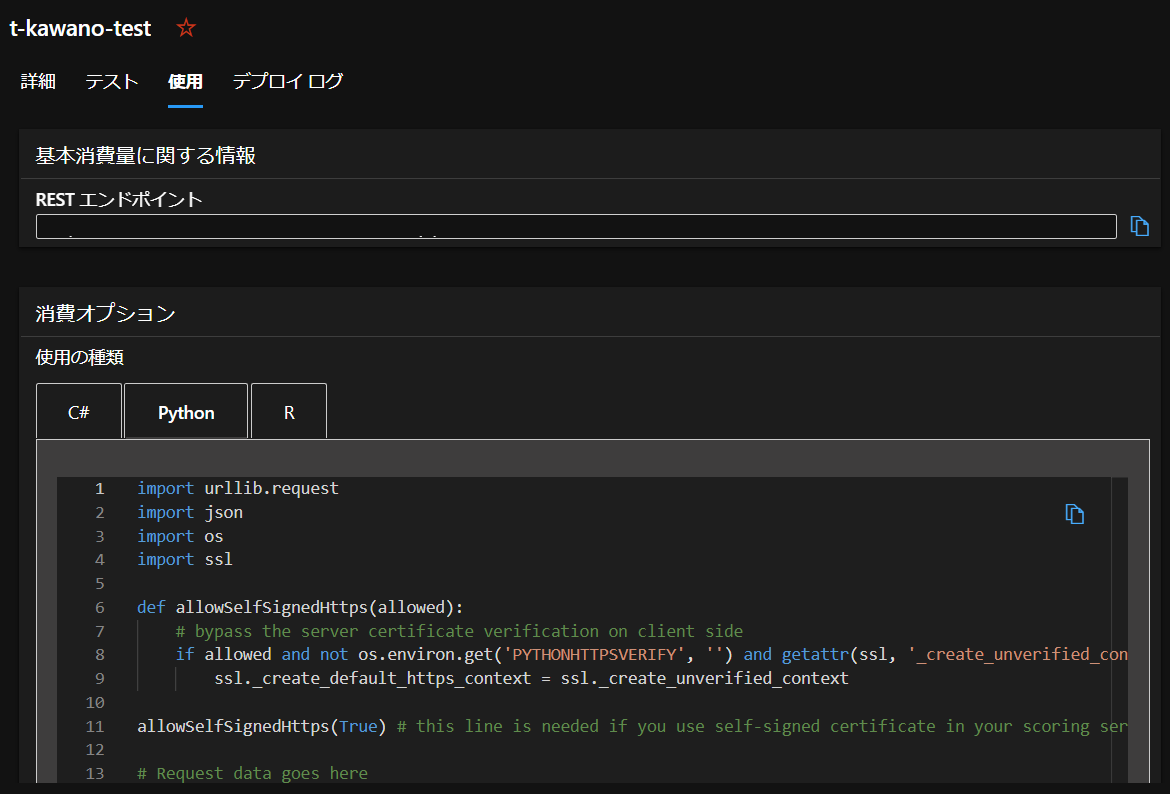
作成したエンドポイントから「RESTエンドポイント」と書かれたところにURLがあります。
creditcard.csvのClass列を削除したデータでテストを行ってみます。
413 Request Entity Too Large
実行途中、status code 413のこちらのエラーが出ました。
これは送ったファイルのデータ量が多いときに出るエラーみたいです。
そのため、このように

テストデータは1行のみで推論することにしました。
入力したテストデータはpandasを用いて読み込み、辞書型にした後JSON形式に成型して使うようにしました。
こちらが入力データです。
b'{"data": "Time,V1,V2,V3,V4,V5,V6,V7,V8,V9,V10,V11,V12,V13,V14,V15,V16,V17,V18,V19,V20,V21,V22,V23,V24,V25,V26,V27,V28,Amount\\r\\n0,-1.359807134,-0.072781173,2.536346738,1.3781552240000001,-0.33832077,0.46238777799999997,0.239598554,0.09869790099999999,0.36378697,0.09079417199999999,-0.551599533,-0.617800856,-0.991389847,-0.311169354,1.468176972,-0.470400525,0.207971242,0.02579058,0.40399296,0.25141209800000003,-0.018306778,0.27783757600000003,-0.11047391,0.066928075,0.12853935800000002,-0.18911484399999998,0.133558377,-0.021053053,149.62\\r\\n"}'
あとはPOSTメソッドを使って実行してみます。
"Time,V1,V2,V3,V4,V5,V6,V7,V8,V9,V10,V11,V12,V13,V14,V15,V16,V17,V18,V19,V20,V21,V22,V23,V24,V25,V26,V27,V28,Amount,Class\n0.0,-1.3598071,-0.072781175,2.5363467,1.3781552,-0.33832076,0.46238777,0.23959856,0.0986979,0.36378697,0.09079417,-0.55159956,-0.61780083,-0.9913899,-0.31116936,1.468177,-0.4704005,0.20797125,0.02579058,0.40399295,0.2514121,-0.018306779,0.27783757,-0.11047391,0.066928074,0.12853935,-0.18911484,0.13355838,-0.021053053,149.62,False\n"
実行後、結果はエントリスクリプトで指定したようにCSV形式で返ってきました。