記事を書いた理由
Neo4jで最短経路を取得するとき、どのように実行計画が動いているのか気になったので、まとめてみました。
Oracle PGXでも同様の検証をしています。詳しくは、こちらの記事をご覧ください。
Predicateによって実行計画が変わる
・経路探索中にPredicateが評価可能なとき⇒幅優先探索
例)対象の全てのノードが同じラベルを持っているときに最短経路を探索する場合
・経路探索時にパス全体をチェックする必要があるとき⇒深さ優先探索(しらみつぶし探索)
例)パスの中にname='Charlie Sheen'というプロパティをもつノードが存在する必要がある場合
実際に実行してみた
字面だけでは理解しづらいので、実際に実行してみました。
サンプルデータのインポートは、以下の記事を参考にしてください。
https://qiita.com/kk31108424/items/715f82fa62db6040c805
演算子の名称
ここで、この後の図で出てくる演算子の読み方をまとめておきます。
・Estimated Rows
コストベースの実行計画で見積した予測の行数。
・Rows
演算子によって絞り出された実際のデータの行数
幅優先探索
MATCH (s:Place{name:"Paris"}), (f:Place{name:"Roma"}), p = shortestPath((s)-[:EROAD*]-(f))
WHERE ALL (r IN relationships(p) WHERE exists(r.distance))
RETURN p
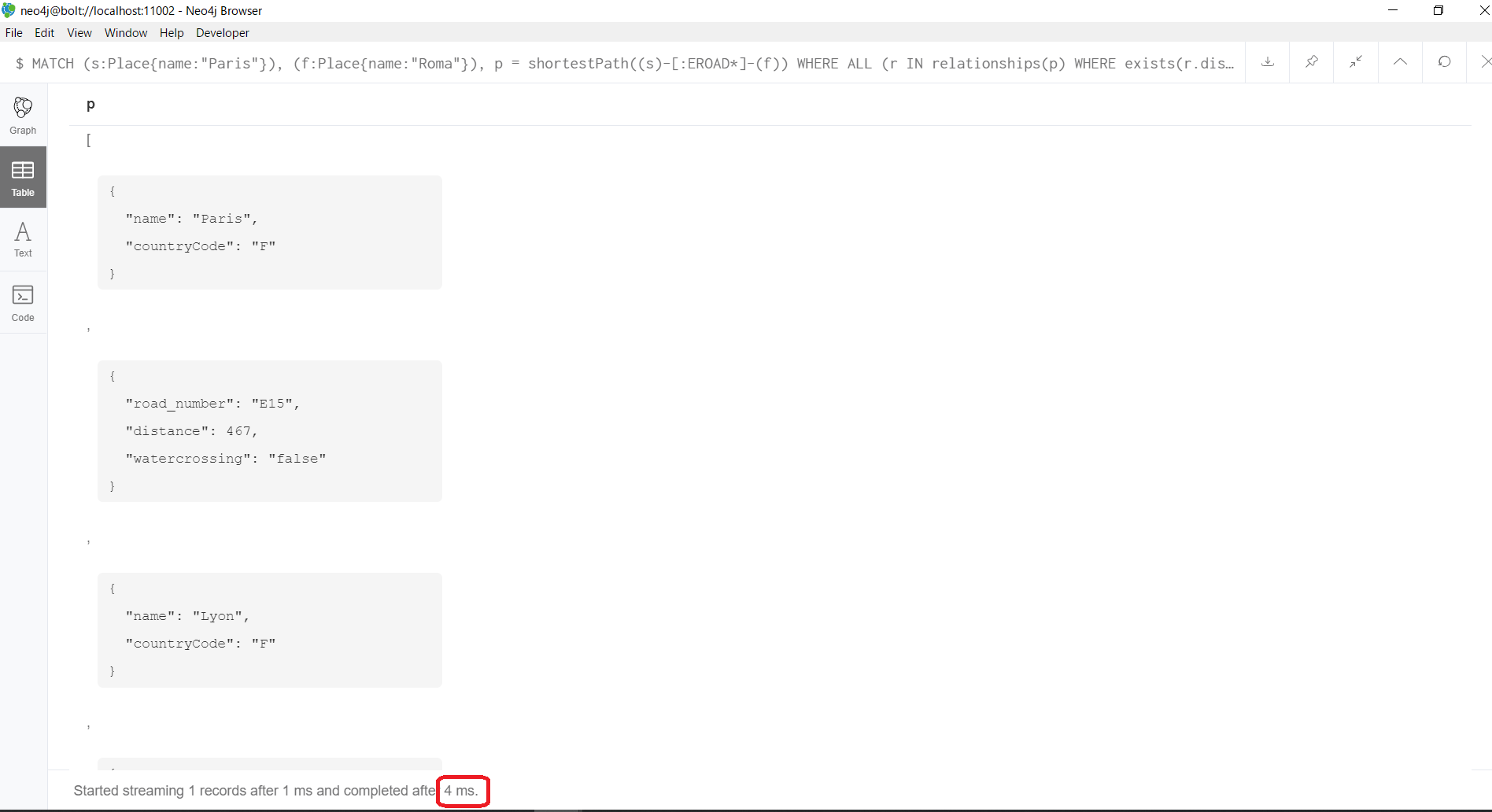
結果が返ってくるまでは4msでした。
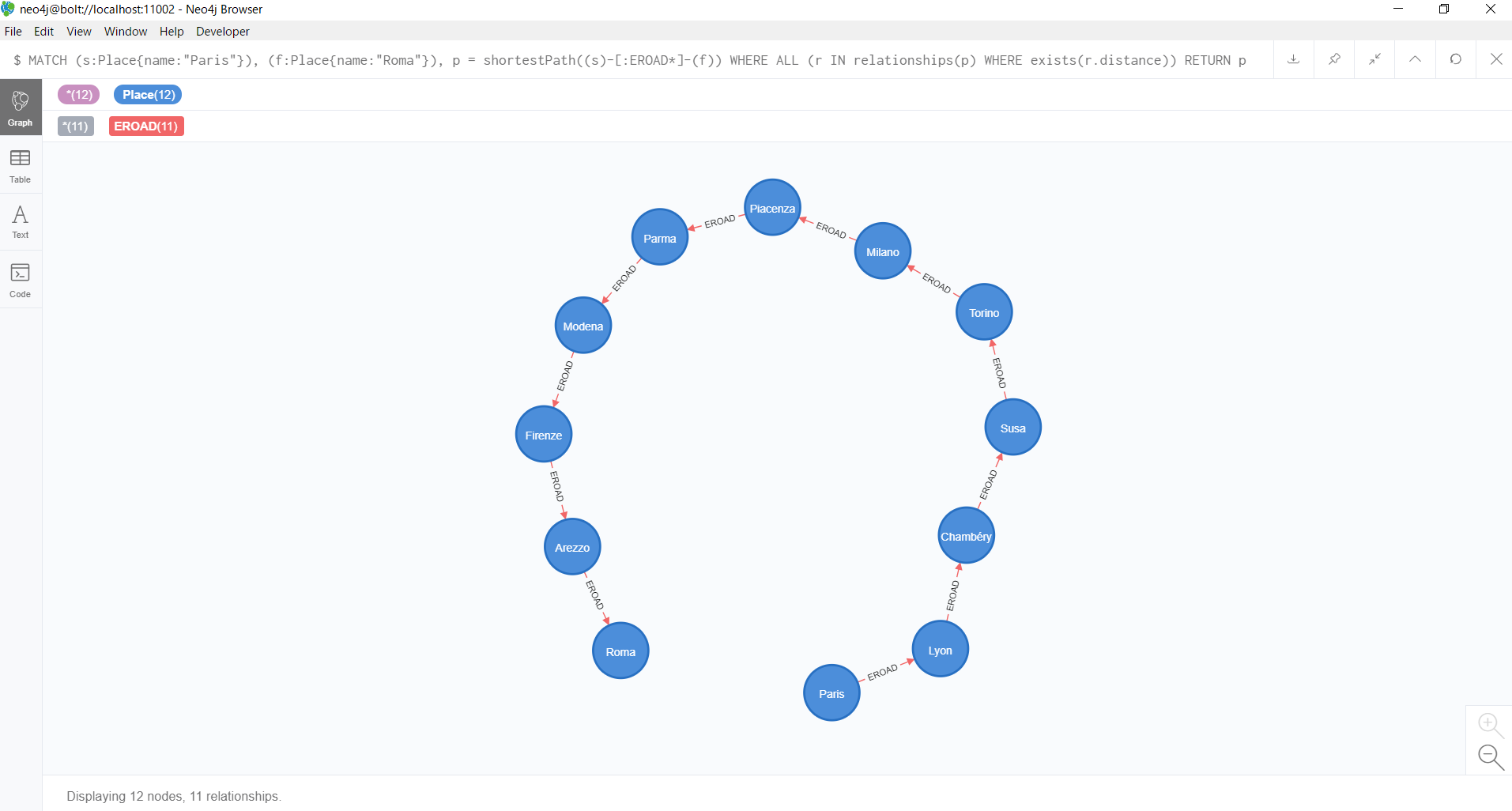
グラフ形式で表示すると、以下のようになります。
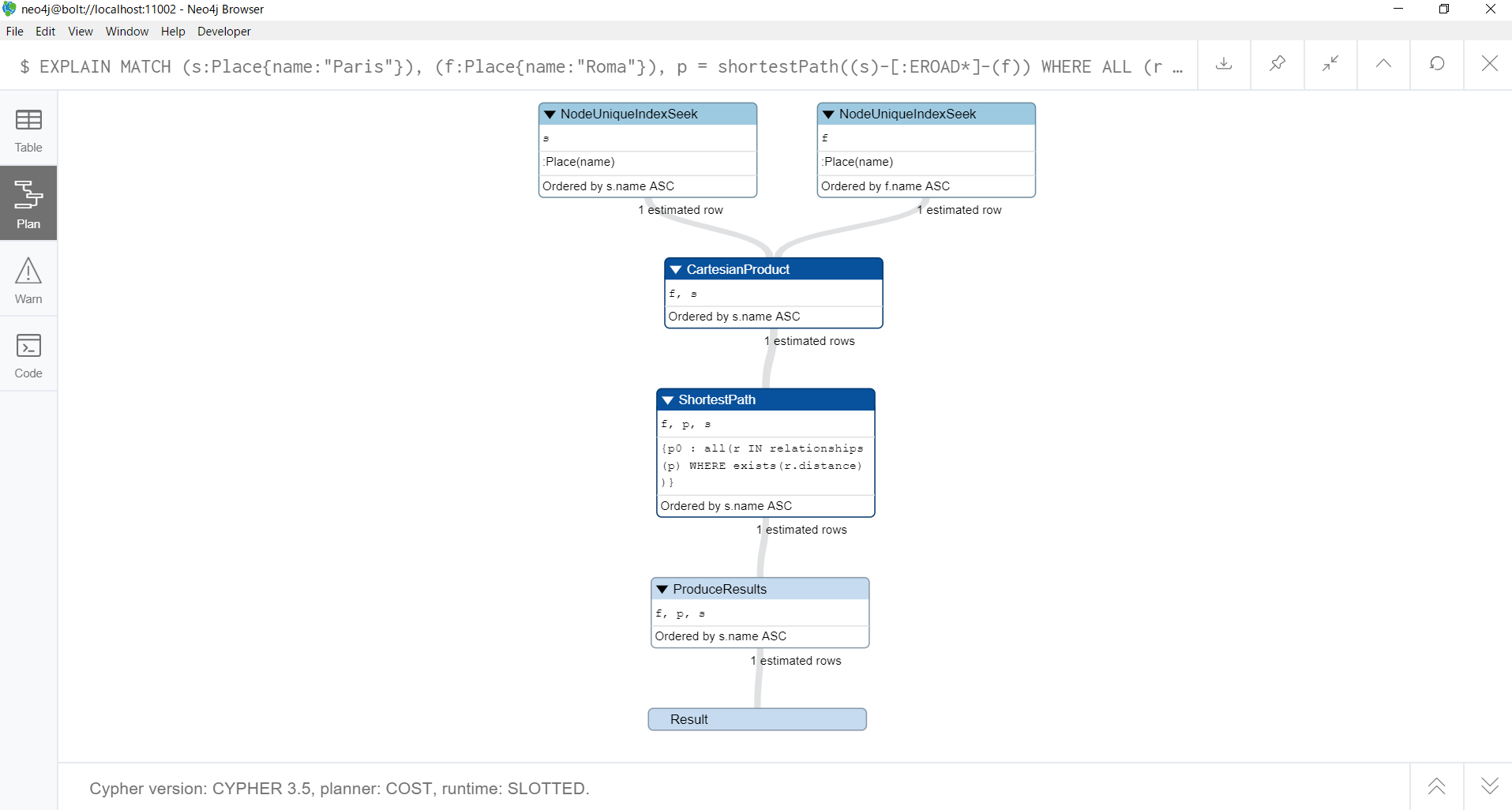
このクエリの実行計画は、以下のようになります。
EXPLAIN MATCH (s:Place{name:"Paris"}), (f:Place{name:"Roma"}), p = shortestPath((s)-[:EROAD*]-(f))
WHERE ALL (r IN relationships(p) WHERE exists(r.distance))
RETURN p
PROFILE MATCH (s:Place{name:"Paris"}), (f:Place{name:"Roma"}), p = shortestPath((s)-[:EROAD*]-(f))
WHERE ALL (r IN relationships(p) WHERE exists(r.distance))
RETURN p
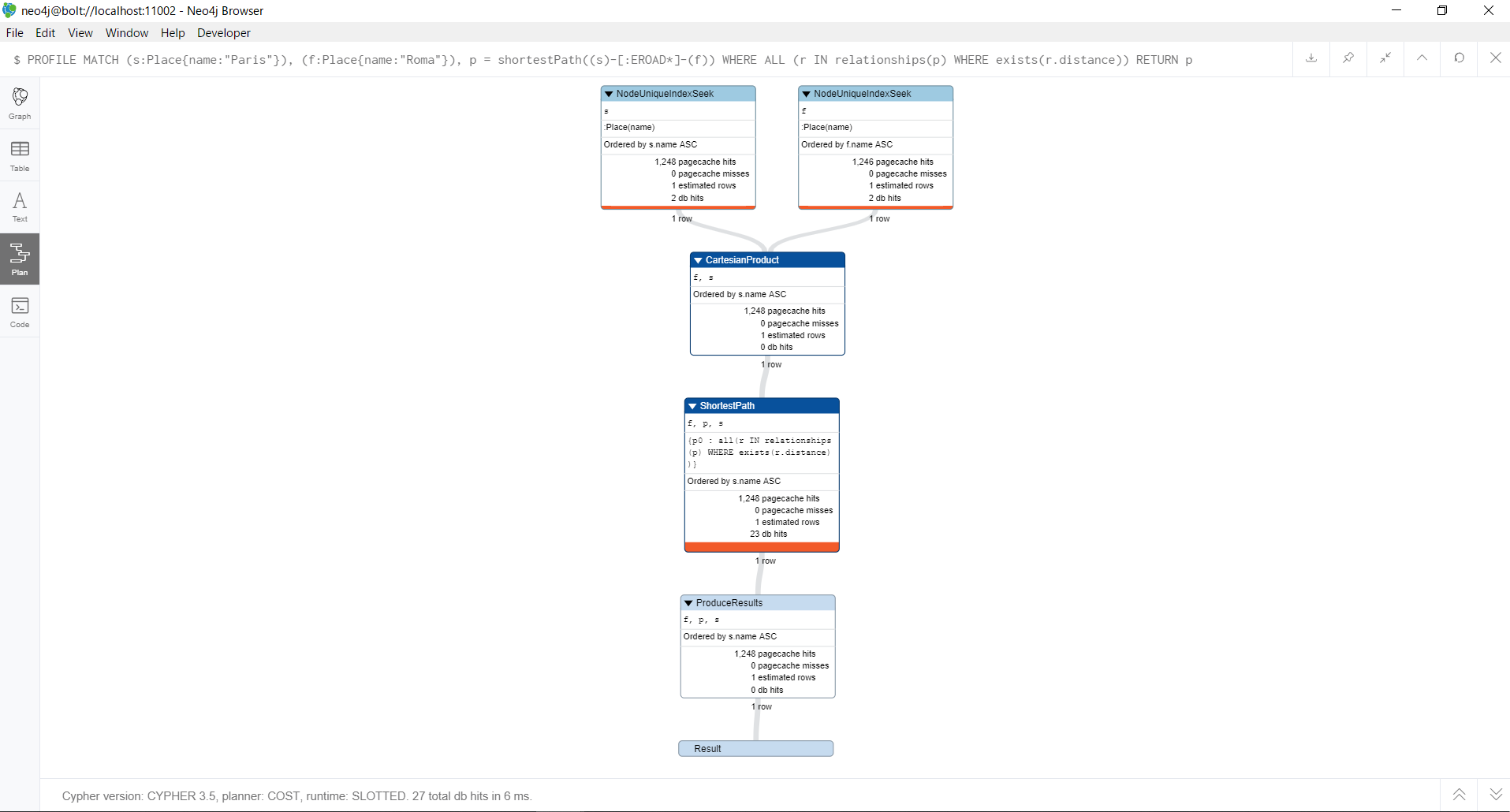
実行計画の図は、上から読んでいってください。
深さ優先探索(しらみつぶし探索)
MATCH (s:Place{name:"Paris"}), (f:Place{name:"Roma"}), p = shortestPath((s)-[:EROAD*]-(f))
WHERE length(p) > 1
RETURN p
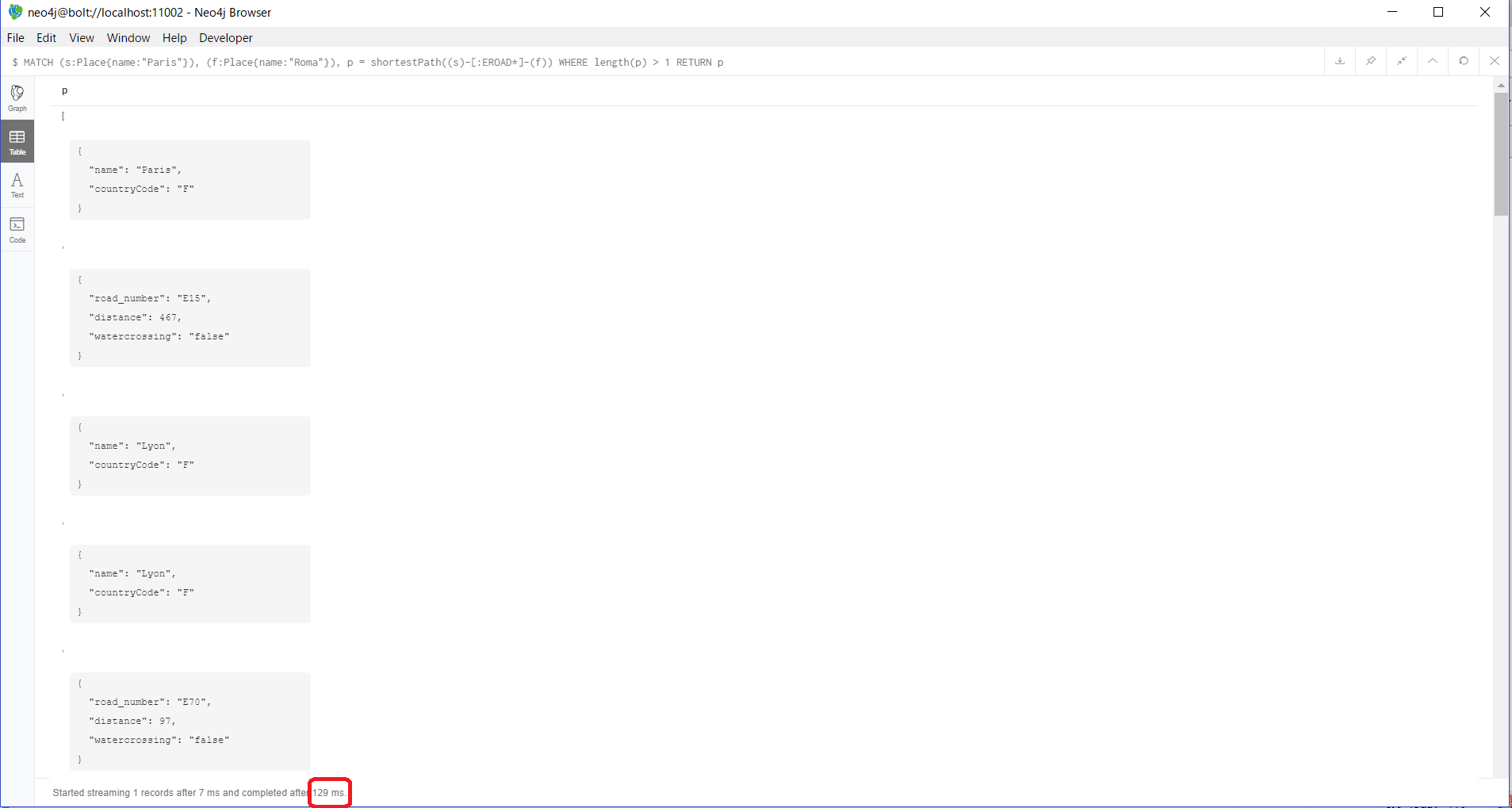
結果が返ってくるまで、129msに延びていることがわかります。
結果をグラフ形式で表示すると、以下のようになります。
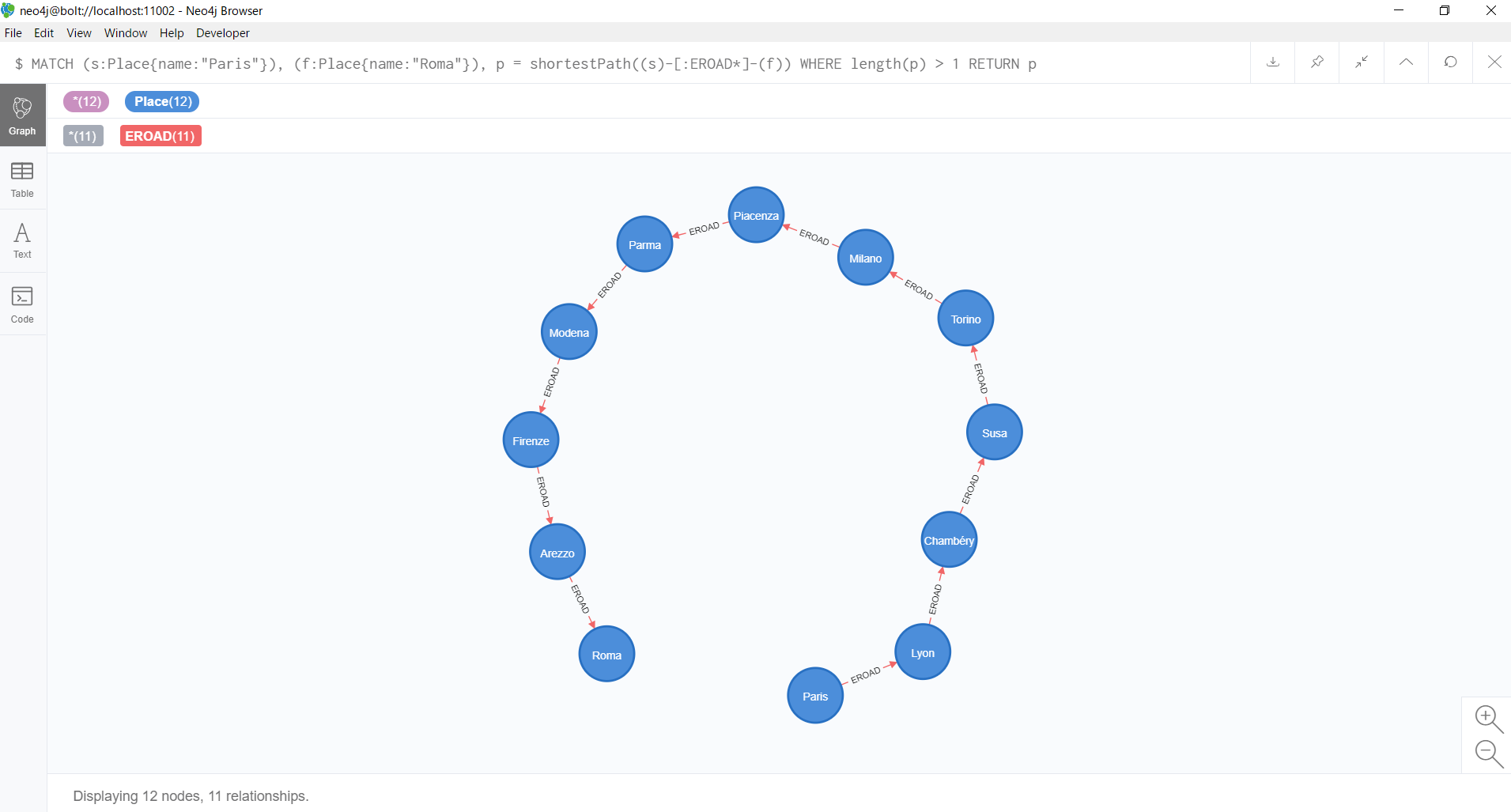
このクエリの実行計画は、以下のようになります。
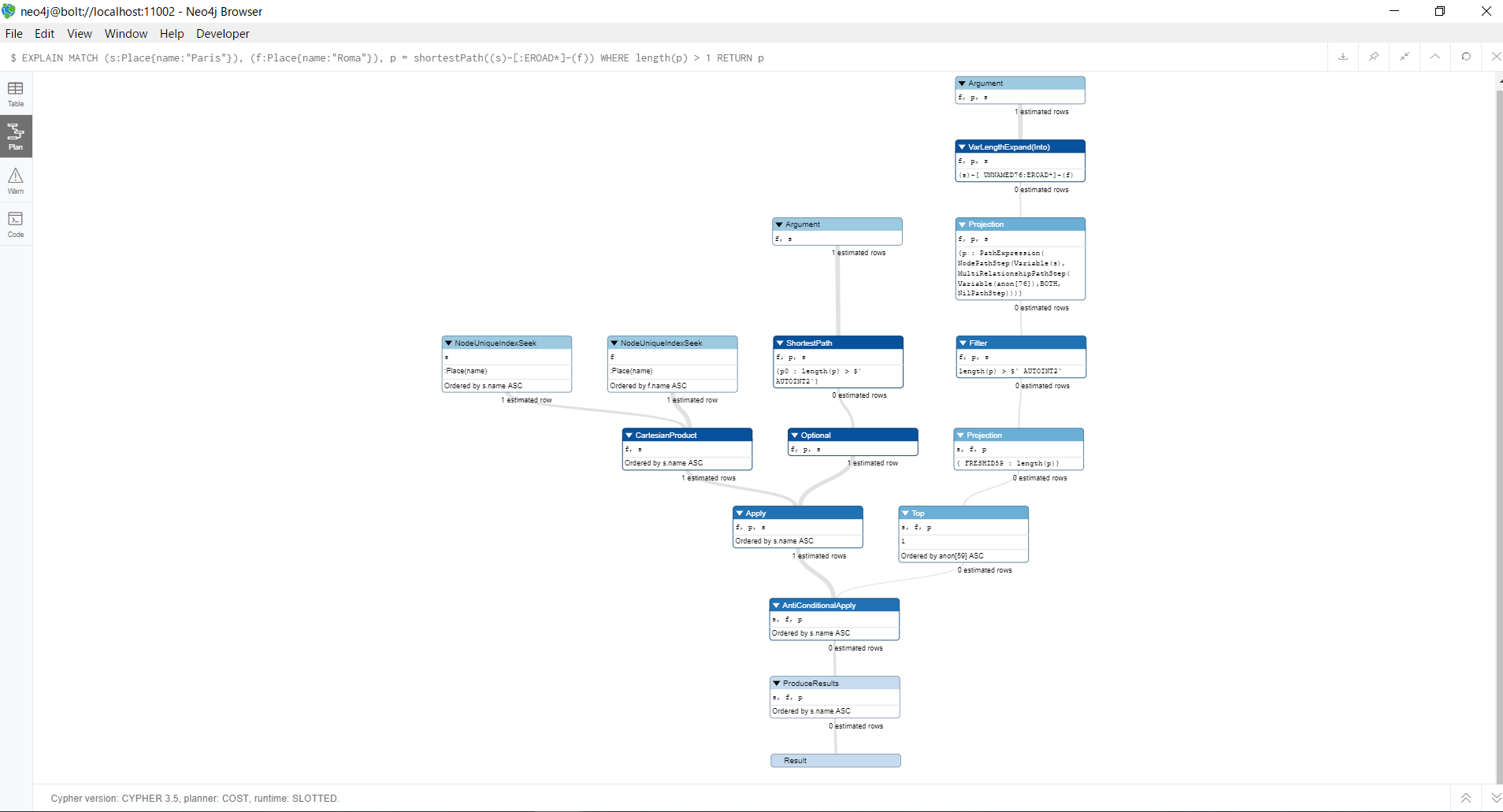
EXPLAIN MATCH (s:Place{name:"Paris"}), (f:Place{name:"Roma"}), p = shortestPath((s)-[:EROAD*]-(f))
WHERE length(p) > 1
RETURN p
PROFILE MATCH (s:Place{name:"Paris"}), (f:Place{name:"Roma"}), p = shortestPath((s)-[:EROAD*]-(f))
WHERE length(p) > 1
RETURN p
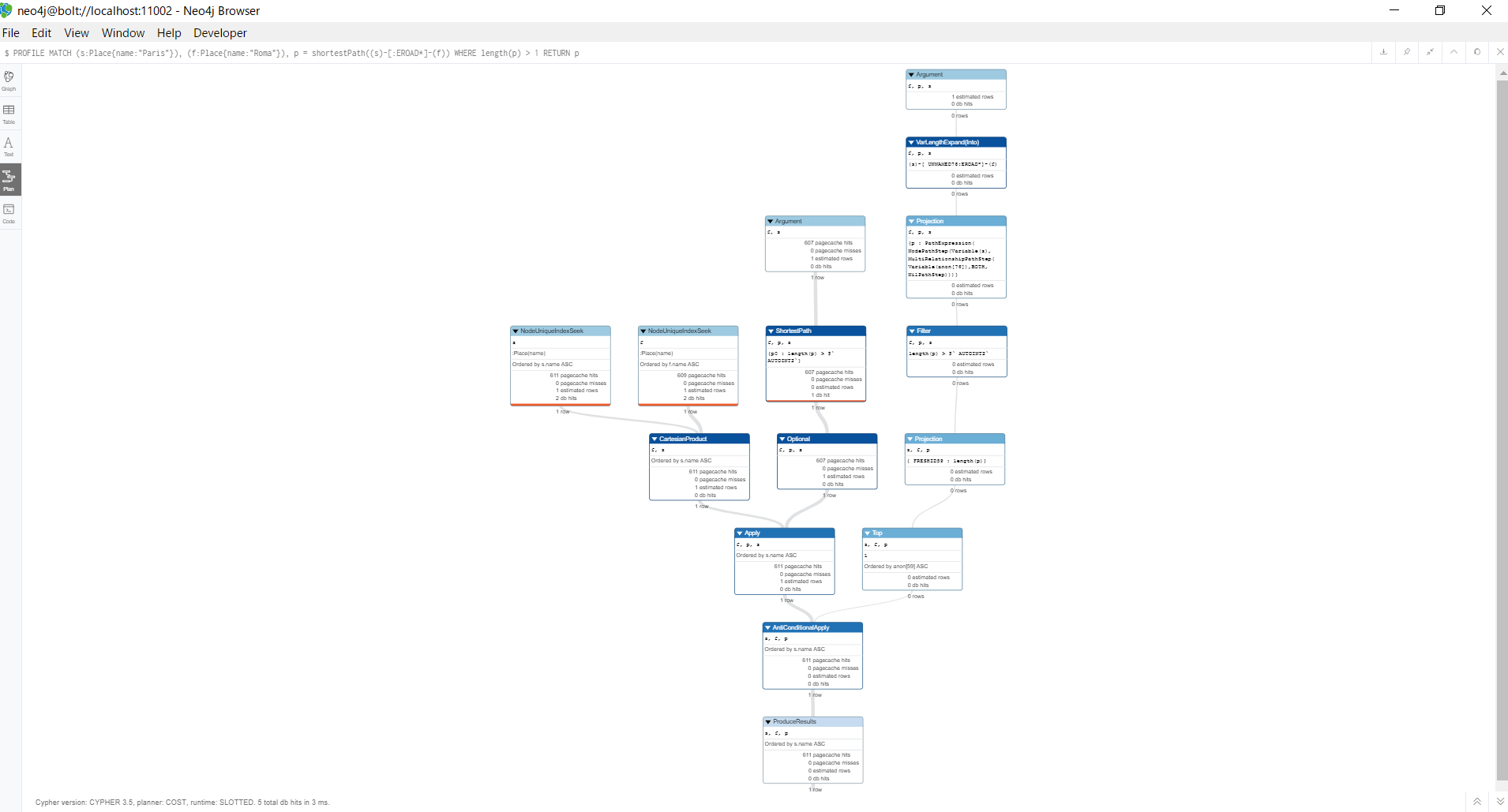
WHERE句の評価がshortestPathの決定よりも先に評価されてしまいます。この結果、最短経路だけでなく、全てのパスを評価する必要があるため、このように長い時間がかかってしまいます。
WITHを使ったクエリ
上記のクエリの実行を早めるには、WITH句を使います。MATCH句で取得した値をフィルターにかけるイメージです。
MATCH (s:Place{name:"Paris"}), (f:Place{name:"Roma"}), p = shortestPath((s)-[:EROAD*]-(f))
WITH p
WHERE length(p) > 1
RETURN p
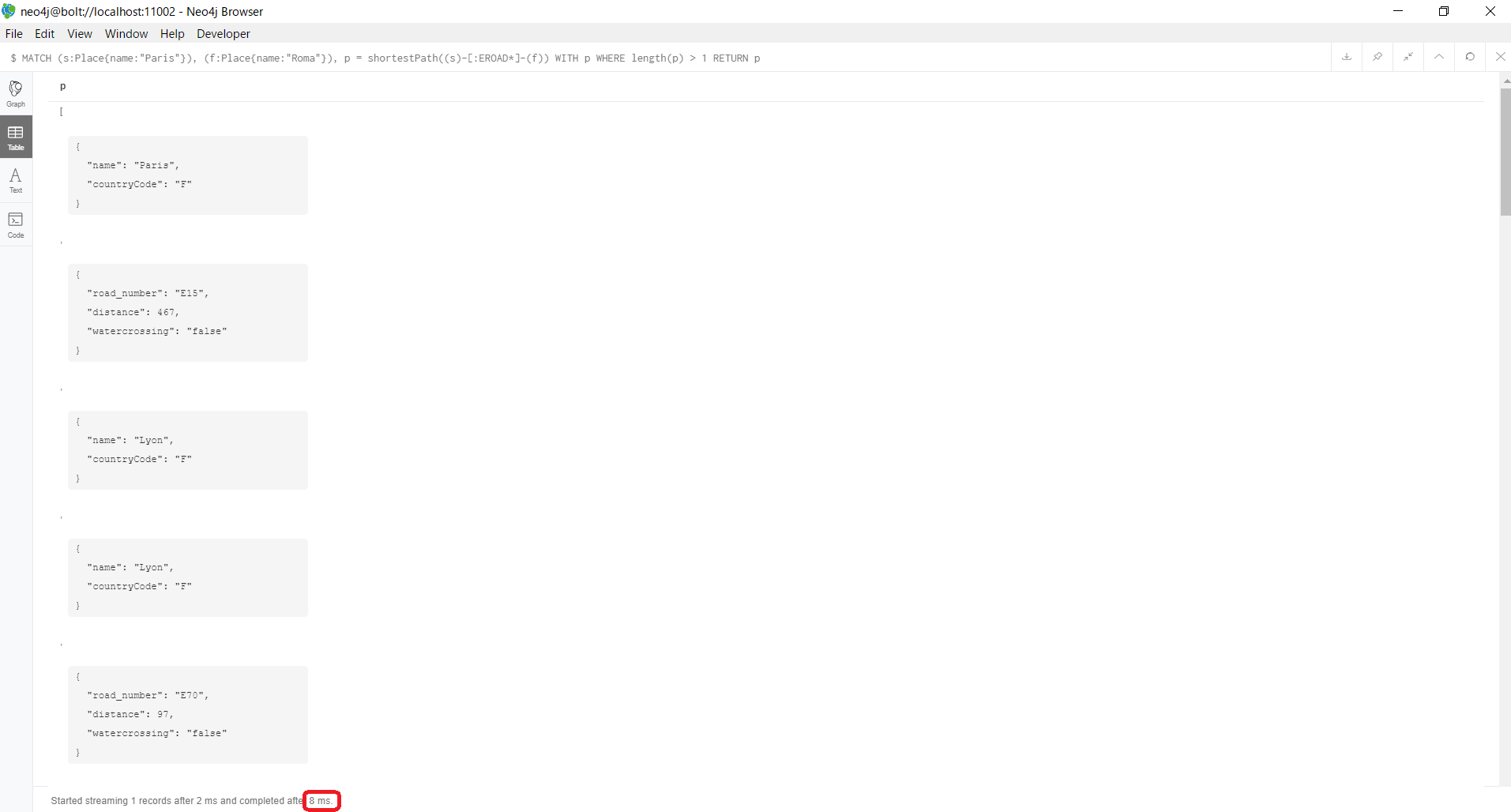
結果が返ってくるまで、たったの8msしかかっていないことがわかります。
実行計画は、以下の通りです。
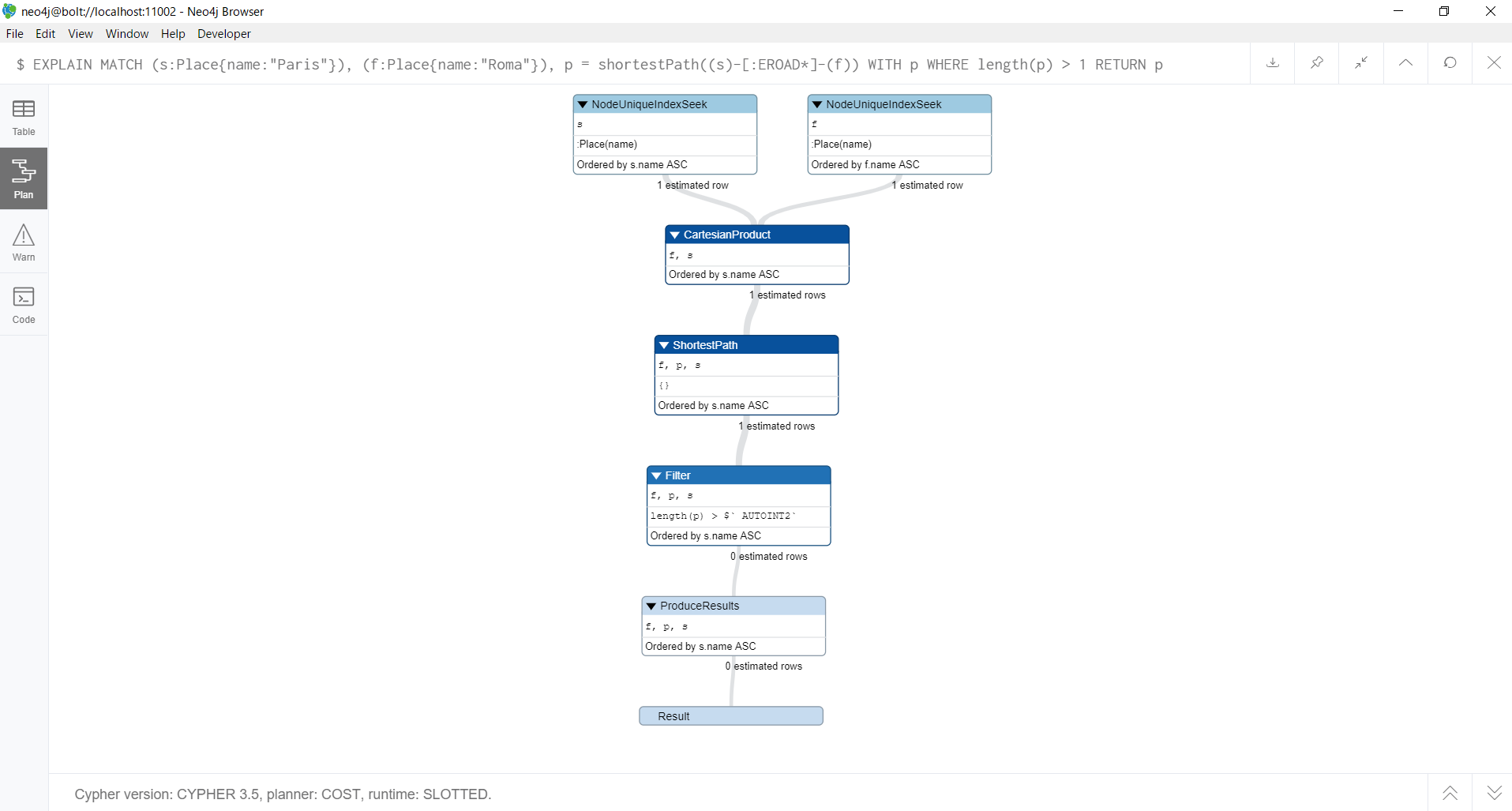
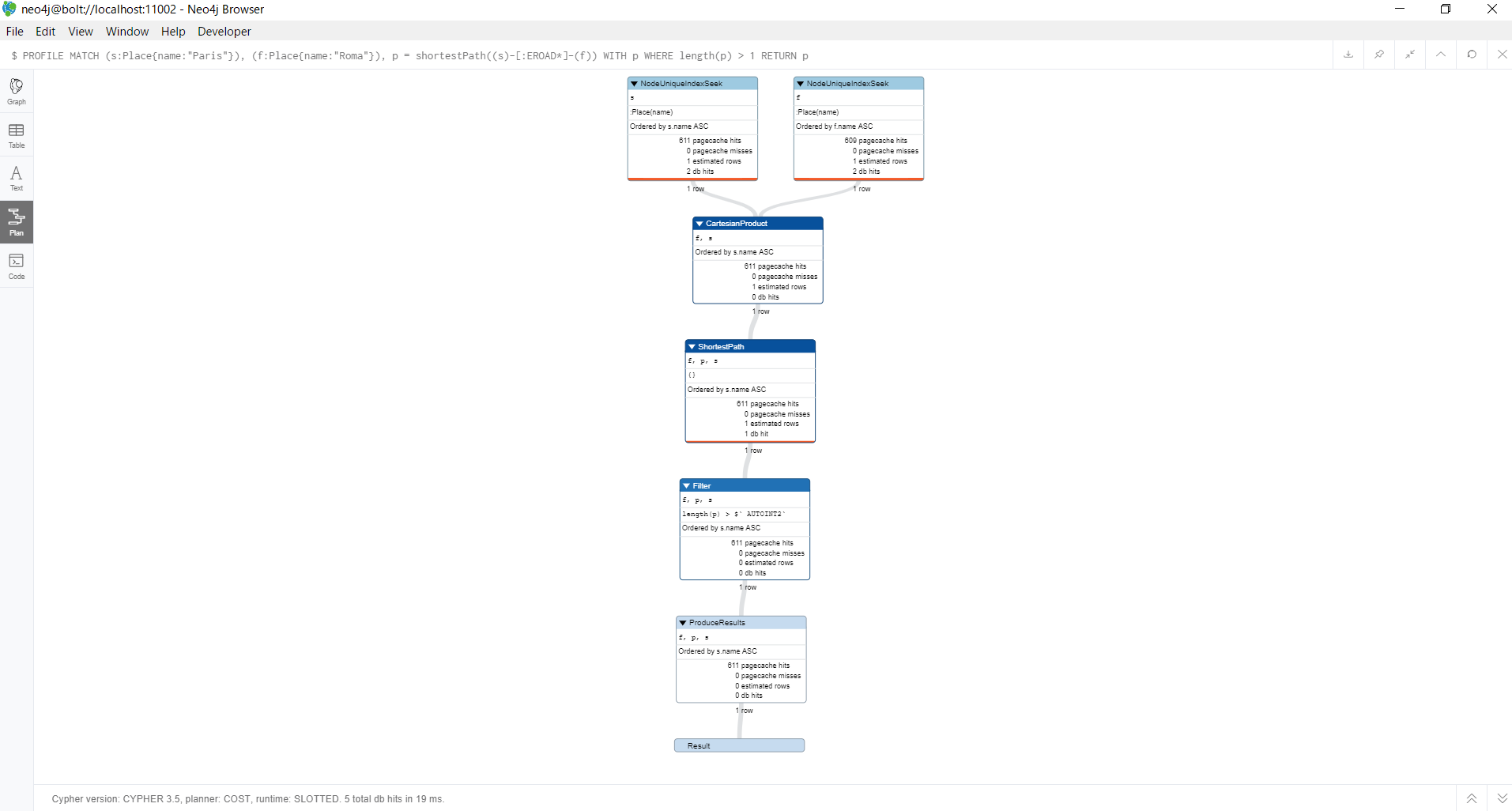
WITH句を使ったクエリでは、WHERE句ではMATCH句で取得した最短経路のみを評価すればよいので、結果を返すまでにかかる時間が大幅に減少します。
まとめ
WHERE句のPredicateはshortestPathの決定より先に評価されてしまうため、条件付きの最短経路探索を行う場合は、WITH句を使ったほうが処理が速くなることを念頭に入れておいたほうが良いです。
追記(2019/06/12)
WHERE句があるからといって、必ず深さ優先探索(しらみつぶし探索)が動くというわけではないようでした。上記のlength(p)>1という条件をかけると、最短経路以外のパスの長さを調べる必要があるため、深さ優先探索(しらみつぶし探索)が動いてしまうということがわかりました。
試しに始点ノード、終点ノードにのみ条件をかけるWHERE句を使ったクエリを投げてみます。
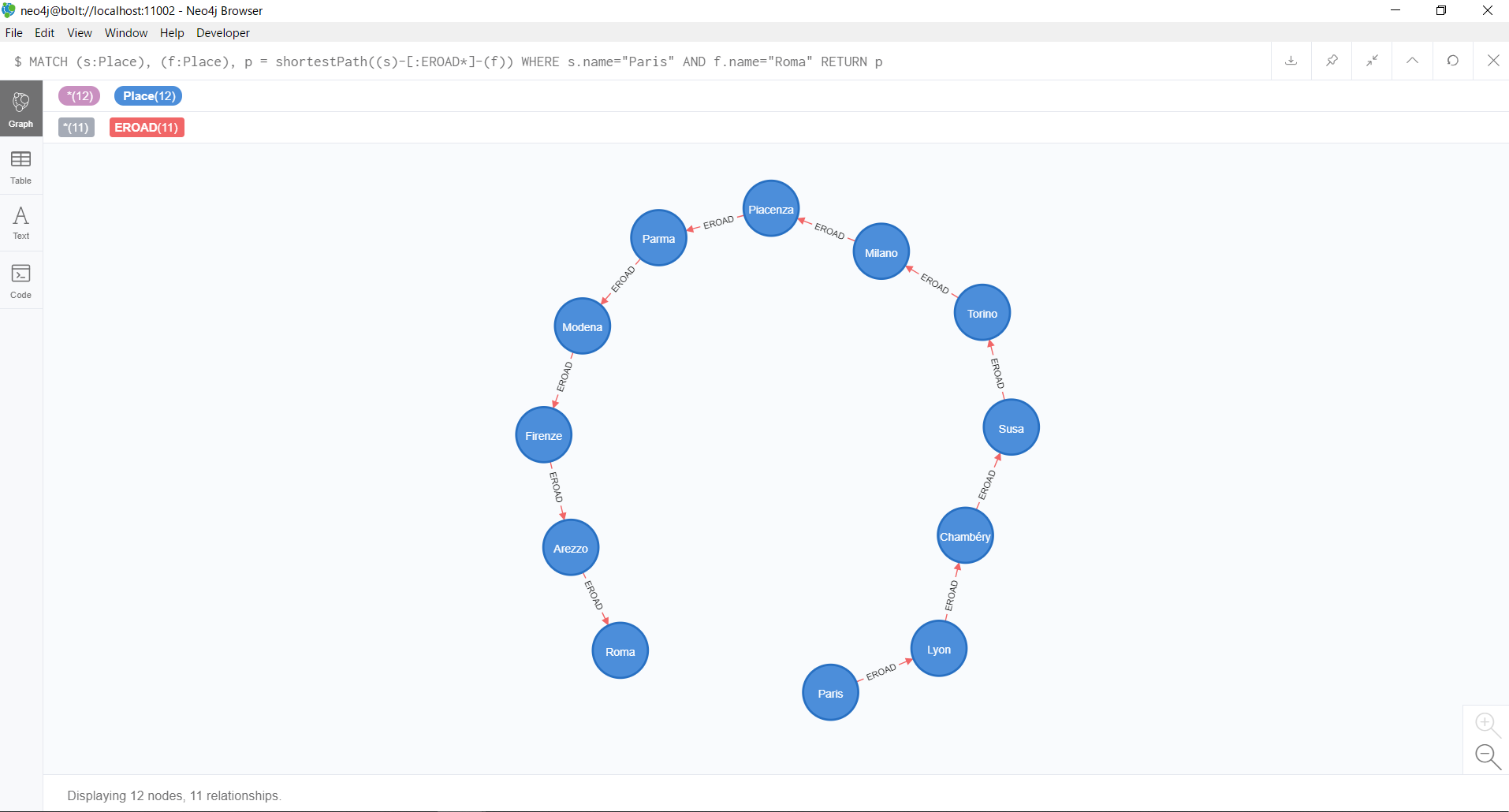
MATCH (s:Place), (f:Place), p = shortestPath((s)-[:EROAD*]-(f))
WHERE s.name="Paris" AND f.name="Roma"
RETURN p
結果はこのようになります。
それでは、実行計画はどのようになっているでしょうか。
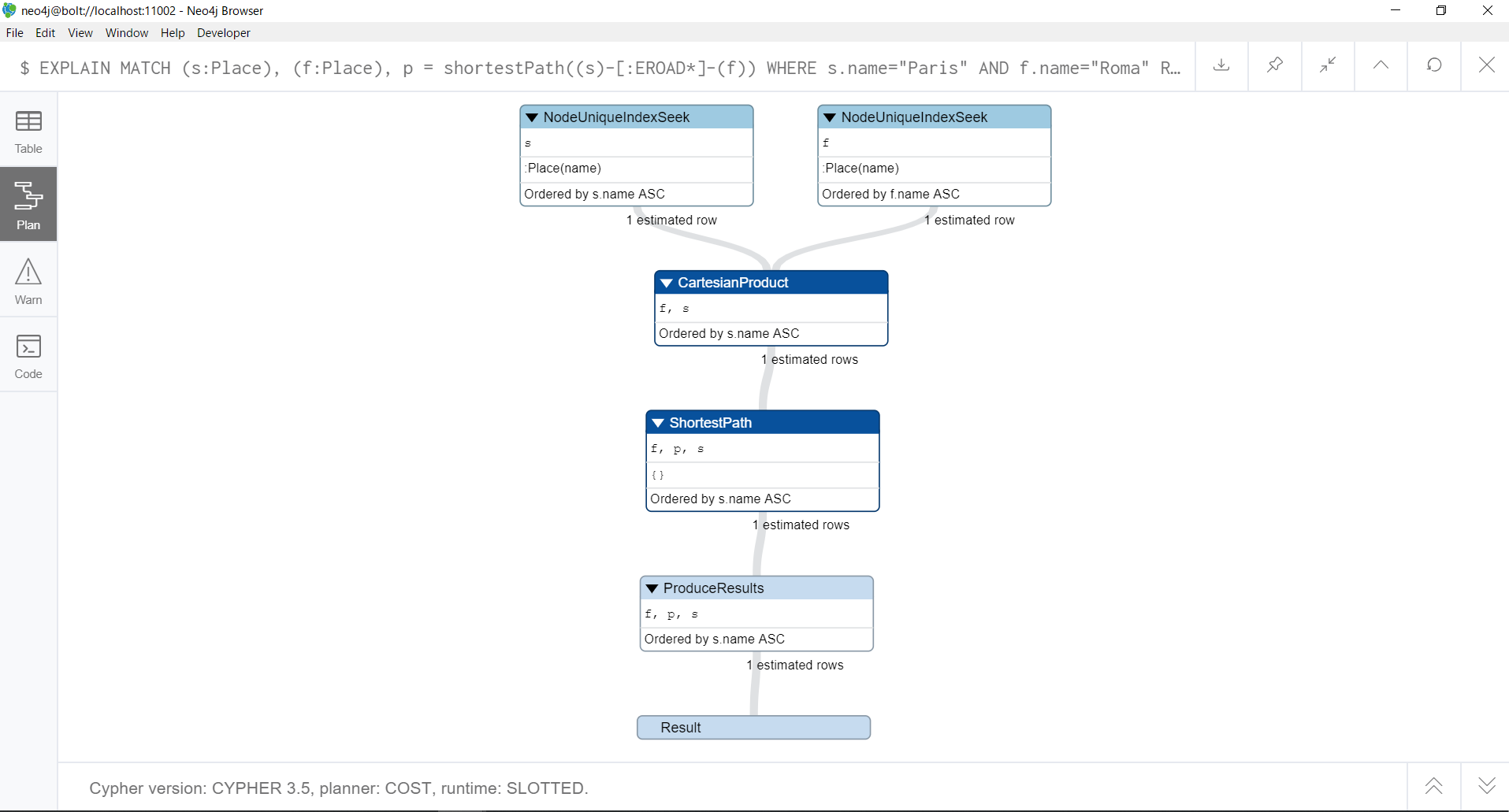
EXPLAIN MATCH (s:Place), (f:Place), p = shortestPath((s)-[:EROAD*]-(f))
WHERE s.name="Paris" AND f.name="Roma"
RETURN p
PROFILE MATCH (s:Place), (f:Place), p = shortestPath((s)-[:EROAD*]-(f))
WHERE s.name="Paris" AND f.name="Roma"
RETURN p
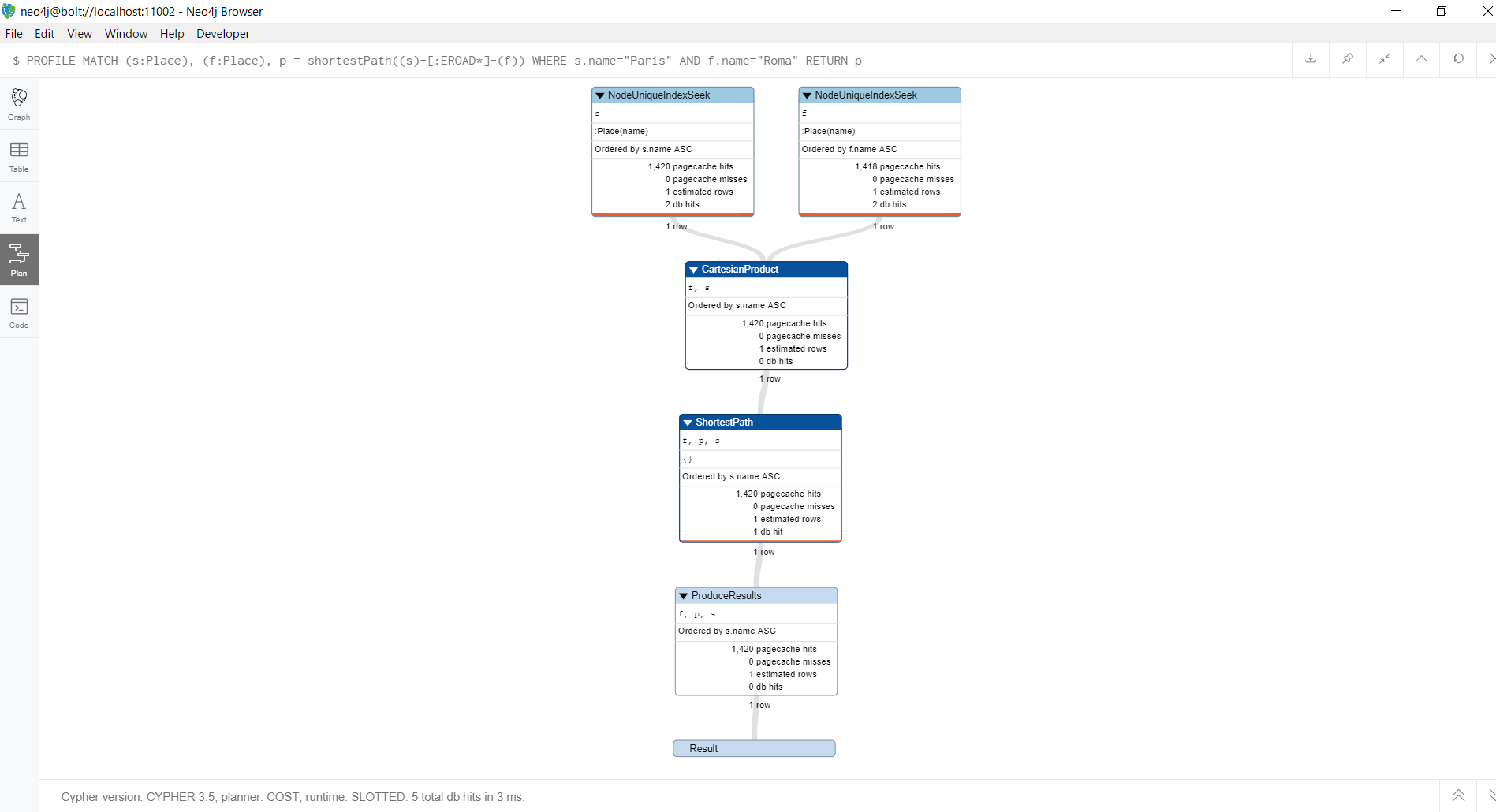
このように、始点ノード・終点ノードだけに条件をかけた場合は、WHERE句を使っても、幅優先探索が動いていることがわかります。
よって、最短経路以外の経路も取得する条件をかけるクエリを実行する場合は、WITH句を使うことを考慮する必要があるという結論に至りました。
参考
https://neo4j.com/docs/cypher-manual/current/execution-plans/shortestpath-planning/
https://neo4j.com/docs/cypher-manual/current/clauses/with/
https://books.google.co.jp/books?id=RSTLCgAAQBAJ&pg=PT27&lpg=PT27&dq=neo4j+%E5%AE%9F%E8%A1%8C%E8%A8%88%E7%94%BB&source=bl&ots=rU-r8PFYQa&sig=ACfU3U1JbZbf0l31GQ3r2i7LUQ9b6n5ZZg&hl=ja&sa=X&ved=2ahUKEwjRstrxgtTiAhUGEbwKHSr-AOwQ6AEwCXoECAkQAQ#v=onepage&q=neo4j%20%E5%AE%9F%E8%A1%8C%E8%A8%88%E7%94%BB&f=false