はじめに
スクレイピングを習得するためにUdemyで【4つの実案件で学ぶ】Python Webスクレイピング完全パック | BeautifulSoup, Seleniumを受講し、習得した知識をアウトプットするために自分でオリジナルのスクレイピングのプログラムを作成したのでそれをアウトプットします。
本記事の概要
1. 作成した背景
2. プログラムの目的
3. 対象のサイトについて
4. 実行環境
5. 実際のプログラムについて
1. 作成した背景
実際にプログラムを作るのであれば、習得技術のアウトプットだけではなく誰かの役に立つプログラムを作成したいと思いました。
そこで、ランサーズやココナラなどの副業サイトから過去の終了済みのスクレイピング案件を選び、それに取り組むことにしました(自分が案件を受けたという想定で)。
2. プログラムの目的
選んだ案件の内容は、ワールドラグビーというサイトにある各国の世界ランキングが表示されているページからデータを記録を開始した時から現在に至るまでの日本の世界ランキングとポイント数、その時の日付を抽出し、エクセルにまとめるというものです。
データは一週間ごとに更新されているので10年間分のデータを手動で収集するのは時間がかかり過ぎてしまいます。そこでスクレイピングを使ってブラウザ操作と情報抽出を自動化します。
3. 対象のサイトについて
スクレイピング対象となるランキングのページはこちらです。
どのようなサイトになっているかを確認しておきます。
「ワールドランキング」というタイトルの下に、プルダウン形式で年月日を指定できる箇所があります。
ここで年月日を指定することでその時点でのランキングを表示させることができます。
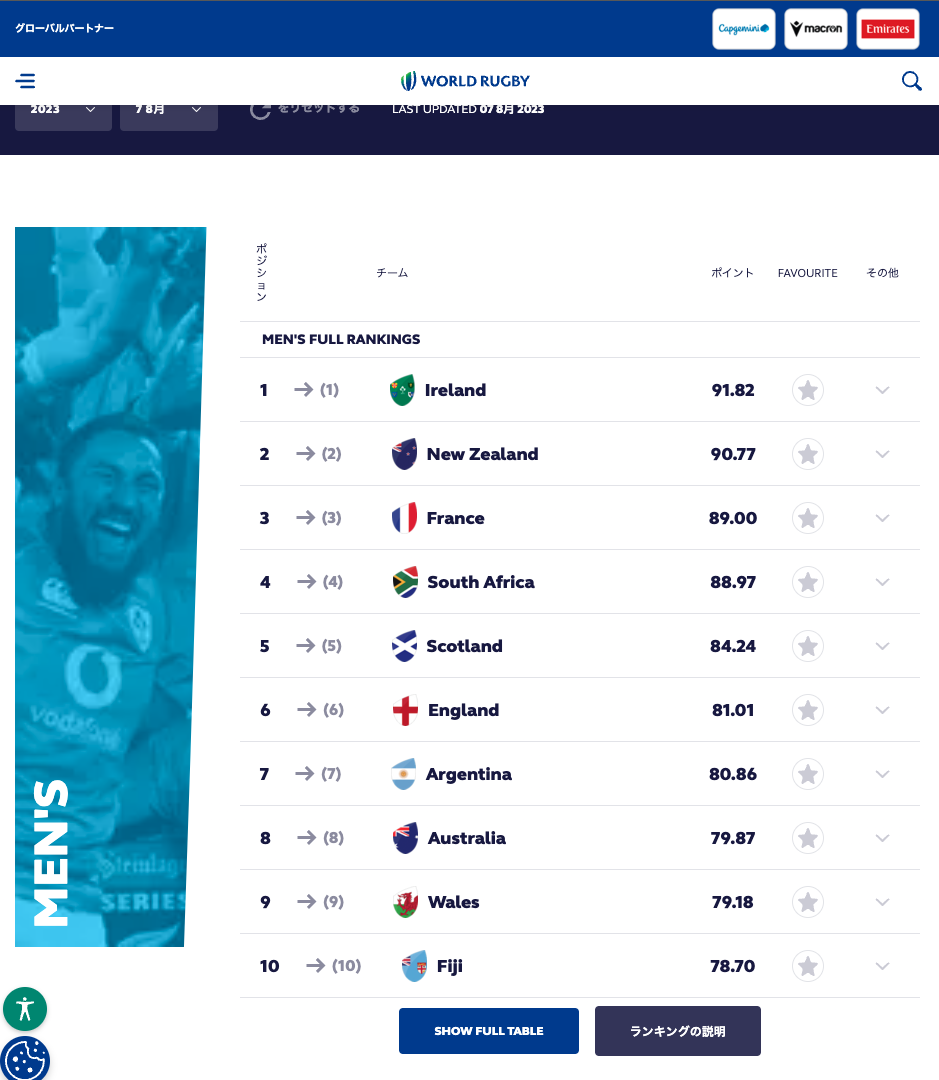
ランキングページにアクセスした時点ではランキングが上位10チームしか表示されていません。なので、スクレイピングする際に「SHOW FULL TABLE」ボタンをクリックしておく必要があります。
以上より、
対象ページにアクセス
→年月日のプルダウンで日付や年を指定
→「SHOW FULL TABLE」ボタンをクリックしてすべてのランキングを表示
→日本のランキングデータを抽出
→エクセルにまとめる
これらの操作を自動化するプログラムを作成できれば良さそうです。
4. 実行環境
Python3
MacBook Air (端末)
Visual Studio Code
5. 実際のプログラムについて
使用するライブラリについて
今回はSeleniumを使います。
スクレイピングの手法はいくつかありますが、よくある手法は大きく二つで
・Requestsライブラリを使ってクローリング(ページのHTMLを取得)を行い、Beautifulでスクレイピング(取得したHTMLから特定の情報を抽出)する
・Seleniumを使ってブラウザ操作を自動化し、クローリングとスクレイピングを行う
Seleniumを採用した理由は対象のサイトが動的なサイト(JavaScriptが使われている)だからです。
例えば、今回のような「SHOW FULL TABLE」ボタンをクリックするとランキングがすべて表示されるといったものです。
Seleniumはブラウザ操作を自動化できるためこのような動的なサイトにも対応できます。Requestsはこの逆で静的なサイトのみ対応しています。
よって、今回はランキングをすべて表示させる必要があるのと、プルダウンを操作する必要があったのでSeleniumでスクレイピングを行なっていきます。
スクレイピングの注意点
・必ずサイトの利用規約を確認し、スクレイピングが可能かどうかを確認する。
・スクレイピングが可能であれば、相手のサーバーに負荷をかけないようにsleepなどを使ってリクエストの間隔をあける
今回対象にしているサイトも利用規約が変更されている可能性があるので必ず確認をお願いします。
実際のプログラム
ポイントとして、Seleniumは動作が重く、処理に時間がかかるという性質があります。
抽出する情報量が少ない場合はSeleniumuでHTMLの取得から解析・抽出まで行えばいいのですが、今回のような10年分のデータとなるとかなり時間がかかることが予想されます。
そこで、ブラウザの操作とHTMLの取得はSeleniumで実行し、HTMLの解析はBeautifulSoupで実行するというように、二つのプログラムに分けてスクレイピングを行っていこうと思います。
※Seleniumを実行するにはChromeDriverのダウンロードが必要です。
1つ目のSeleniumでのブラウザ操作・HTML取得のプログラム
# モジュールのインポート
from time import sleep
import os
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
# driverの設定
options = webdriver.ChromeOptions()
options.add_argument('--incognito')
# options.add_argument('--headless')
driver = webdriver.Chrome(
executable_path= 'chromedriver_path',
options=options)
wait = WebDriverWait(driver, 10)
# 対象サイトにアクセス
url = 'https://www.world.rugby/tournaments/rankings/mru'
driver.get(url)
sleep(3)
# クッキーの選択(ページにアクセスした際にクッキーの選択画面が表示されるのでそれの対応)
cookie_accept_button = driver.find_element_by_css_selector('._24Il51SkQ29P1pCkJOUO-7 > button._2hTJ5th4dIYlveipSEMYHH.BfdVlAo_cgSVjDUegen0F.js-accept-all-close')
sleep(3)
cookie_accept_button.click() # 選択ボタンをクリック
# ここでランキングのページが表示される
# yearのbuttonタグをすべて取得
year_dropdown = driver.find_elements_by_css_selector('.wr-datepicker__button.js-year-button > div.wr-datepicker__select.js-date-select > div.wr-datepicker__dropdown-list.js-dropdown-list > button.wr-datepicker__option.js-date-option')
sleep(3)
# dateのbuttonタグをすべて取得
# 最新年のdateのbuttonタグだと一年分のタグが表示されないので昨年を指定し、すべてのbuttonタグを取得できるようにする
# まず昨年のタグをクリックできるようにyearのdropdownを表示させる
driver.find_element_by_css_selector('.wr-datepicker__button.js-year-button').click()
sleep(3)
# 昨年のタブをクリック
year_dropdown[1].click()
# ここでdateのbuttonタグをすべて取得
date_dropdown = driver.find_elements_by_css_selector('.wr-datepicker__button.js-week-button > .wr-datepicker__select.js-date-select > .wr-datepicker__dropdown-list.js-dropdown-list > button.wr-datepicker__option.js-date-option')
sleep(3)
# ランキング全てを表示させるための設定
# 表示ボタンが画面上に来るように下へスクロール
driver.execute_script('window.scrollTo(0, 1000);')
sleep(3)
# 表示ボタン取得
btn = driver.find_element_by_css_selector('.world-rankings__row.world-rankings__row--lower.widget > div > div > div > div.wr-table__rankings > div.wr-table__button-container > button.wr-table__button.wr-table__button--toggle.js-toggle-table')
sleep(3)
# 表示ボタンクリック
btn.click()
sleep(1)
# 画面の位置を元に戻す(戻さないと年月日の部分が画面外になっているので操作ができなくなる)
driver.execute_script('window.scrollTo(0, 0);')
sleep(3)
# pathの設定
dir_name = os.path.dirname(os.path.abspath(__file__))
for i in range(len(year_dropdown))[2:]:
print('='*30, i, '='*30)
# yearのdropdownを表示
driver.find_element_by_css_selector('.wr-datepicker__button.js-year-button').click()
sleep(3)
# yearを指定
year_dropdown = driver.find_elements_by_css_selector('.wr-datepicker__button.js-year-button > div.wr-datepicker__select.js-date-select > div.wr-datepicker__dropdown-list.js-dropdown-list > button.wr-datepicker__option.js-date-option')
sleep(3)
year_dropdown[len(year_dropdown) - 1 - i].click()
for j in range(len(date_dropdown)):
sleep(3)
# dateのdropdownを表示
driver.find_element_by_css_selector('.wr-datepicker__button.js-week-button').click()
sleep(3)
# dateを指定
date_dropdown = driver.find_elements_by_css_selector('.wr-datepicker__button.js-week-button > .wr-datepicker__select.js-date-select > .wr-datepicker__dropdown-list.js-dropdown-list > button.wr-datepicker__option.js-date-option')
sleep(3)
# 日付のdropdownの数で条件分岐(年によってdate_dropdownの数が異なる)
if date_dropdown[j] is None: # リストが範囲外になればループを抜ける
break
else: # リストが範囲内であれば操作を続行
date_dropdown[j].click()
sleep(3)
# htmlを取得
html = driver.page_source
sleep(3)
# 取得したhtmlをファイルに保存
p = os.path.join(dir_name, 'html', f'ranking_{i*len(date_dropdown)+j}.html') # 保存先のパスの設定
# 取得したHTMLを保存
with open(p, 'w') as f:
f.write(html)
# ドライバーの停止
driver.quit()
これを実行するとhtmlが保存されるファイルが作成され、そこに取得したHTMLが保存されていきます。
2つ目のBeautifulSoupでのHTML解析のプログラム
# モジュールのインポート
import os
from time import sleep
from bs4 import BeautifulSoup
from glob import glob
import pandas as pd
# pathの設定
dir_name = os.path.dirname(os.path.abspath(__file__))
html_path = os.path.join(dir_name, 'html', '*')
# 取得したHTMLファイルの解析
d_list = []
for i in range(1040):
path = f'./html/ranking_{i}.html'
is_file = os.path.isfile(path)
if is_file: # ファイルが存在する場合
# ファイルの読み込み
with open(f'./html/ranking_{i}.html', 'r') as f:
html = f.read()
# htmlの解析
soup = BeautifulSoup(html, 'lxml')
year = soup.select_one('.wr-datepicker__wrapper.widget > div.wr-datepicker__filters-container > div.wr-datepicker__button.js-year-button > div.wr-datepicker__select.js-date-select > span').text
date = soup.select_one('.wr-datepicker__wrapper.widget > div.wr-datepicker__filters-container > div.wr-datepicker__button.js-week-button > div.wr-datepicker__select.js-date-select > span').text
table_num = soup.select('.world-rankings__row.world-rankings__row--lower.widget > div > div > div > div.wr-table__rankings > div.wr-table__content.js-table-content > table > tbody > tr')
if len(table_num) == 1:
pass
else:
table = soup.select_one('.world-rankings__row.world-rankings__row--lower.widget > div > div > div > div.wr-table__rankings > div.wr-table__content.js-table-content > table > tbody')
pts = table.select_one('tr:-soup-contains("日本") > td.wr-table__cell.wr-table__cell--points').text
ranking = table.select_one('tr:-soup-contains("日本") > td.wr-table__cell.wr-table__cell--position > div').text
d_list.append({
'year': year,
'date': date,
'pts': pts,
'ranking': ranking
})
else: # ファイルが存在しない場合
pass
# 取得したデータのリストをデータフレームに格納
df = pd.DataFrame(d_list)
# データフレームをエクセルに変換して保存
df.to_excel('ranking-data_japan.xlsx', index=None, encoding='utf-8-sig')
これを実行するとエクセルに年(year)、日付(date)、勝ち点(pts)、ランキング(ranking)が以下のようにまとまるようになっています。
データがあるのは2003年10月19日からなので正しく出力できていることがわかります。また、日付順に綺麗に並べることができています。
まとめ
スクレイピングを実践するために、実際のスクレイピング案件に取り組んでみました。
ボタンのクリックの操作とプルダウンの操作が特に難しかったです。
ページにアクセスすればボタンのクリックは簡単にできると思っていましたが、パソコンの画面上にそのボタンが表示されていないとクリックできないということを知らなかったので苦労しました。
今回クリックする箇所はランキングを表示する「SHOW FULL TABLE」ボタンと、年月日を指定するプルダウンがありました。この二つは離れており画面上に両方が入りきらないので、Seleniumでページを上下に動かすという機能を細かく組み込んでいくことで解消することができました。
プルダウンに関しては年によって日付のプルダウンの数がバラバラだったのでループの処理が難しかったです。条件分岐で処理を分けることで解決しました。
案件は3日ほどで完成してもらえると嬉しいと書いてありましたが、私は1週間もかかってしまいました。素早くできるように引き続き自分の知識を高めていこうと思います。