pepper君の音声認識精度がいまいちなので、クラウド音声認識サービスを使って精度向上ができないか試してみました。
NAOqiのドライバでpepperのマイク信号をネットワーク経由で取得し、音声区間のみをクラウドサービスに送ることで音声認識結果を得るという方法です。
Google Speech APIではかなり良い精度で認識できました。NICTの音声認識サービスでもまずまずの精度でした。
サンプルコードをGitHubに公開していますので、お試しください。
注意点
- NICTのAPIの利用は、学術研究目的に限られています。詳しくはrospeexのライセンスを参照してください。
- Google Speech APIには、1日50回の呼び出し回数制限があります。
動作環境
-
Ubuntu 14.04.1 LTS 64bit
- 手元の環境では、Mac OSのVMware Fusionで動かしています
- ROS Indigo
- rospeex
-
NAO Python 2.7 SDK 2.1 Linux 64
- Aldebaranのアカウントが必要
インストール手順
ROS Indigo
ROS Indigo の Ubuntu へのインストールの手順通りでインストールできます。
環境変数の変更反映のため、ターミナルの再起動が必要です。
環境変数の確認
$ export | grep ROS
ROS_ROOT とか ROS_PACKAGE_PATH の設定が表示されることを確認してください。
もし表示されない場合は、インストール手順の「環境設定」の項目をもう一度確認してください。
ROSワークスペースの作成
catkin workspaceの作成
$ mkdir -p ~/catkin_ws/src
$ cd ~/catkin_ws/src
$ catkin_init_workspace
$ cd ~/catkin_ws/
$ catkin_make
環境変数 ROS_PACKAGE_PATH に、上で作成した ~/catkin_ws/src を追加
$ echo 'source ~/catkin_ws/devel/setup.bash' >> ~/.bashrc
ターミナル再起動後、環境変数 ROS_PACKAGE_PATH の確認
$ set | grep ROS_PACKAGE_PATH
...
ROS_PACKAGE_PATH=/home/username/catkin_ws/src:/opt/ros/indigo/share:/opt/ros/indigo/stacks
rospeex
rospeexのインストール手順を参考に行います。
ROSパッケージのインストール
$ cd ~/catkin_ws/src
$ git clone https://bitbucket.org/rospeex/rospeex.git
$ rosdep update
$ rosdep install rospeex
# All required rosdeps installed successfully
ビルド
$ sudo apt-get install qtmobility-dev
$ cd ~/catkin_ws
$ catkin_make
デモを動かす
rospeexに付属しているTalking Watch サンプルで、rospeexの動作を確認します。
Ubuntuでサウンドデバイスが有効になっている必要があります。
roscore プロセスの起動
新しいターミナルを開き、roscoreを起動します。
ROS環境を動かす際には、roscoreの立ち上げが必須です。
$ roscore
デモプログラムの起動
新しいターミナルから、音声認識用の波形モニタを起動します。
$ rosrun rospeex_audiomonitor audio_monitor_epd
もう一枚新しいターミナルを開き、サンプルプログラムを開きます。
$ roslaunch rospeex_samples talking_watch_python_ja_local.launch
マイクに向かって「今何時?」と質問すると、ターミナルに現在時刻が表示されたら成功です。
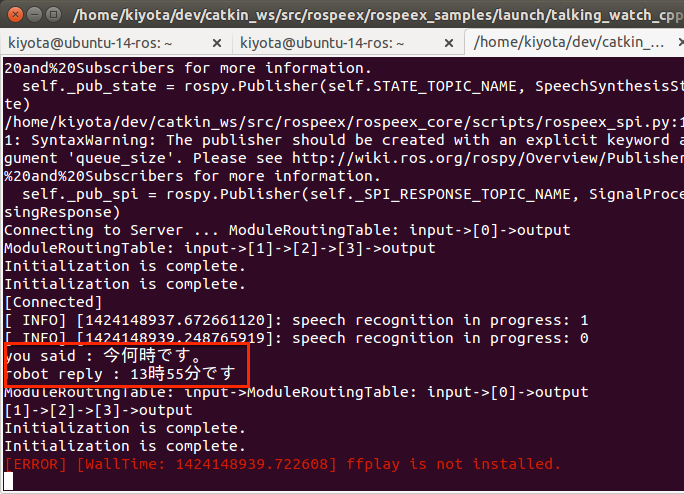
※本来このデモプログラムでは現在時刻をしゃべってくれるはずですが、Ubuntu 14.04ではffplayツールが存在しないため、しゃべってくれないようです
NAO Python SDK
Aldebaran Robotics Software Resourcesのページより、「Python 2.7 SDK 2.1 Linux 64」をダウンロードします。
※Aldebaran Roboticsのアカウントが必要です。
任意のパス (ここでは /opt 直下) に展開します。
$ cd /opt
$ sudo tar zxvf /path/to/pynaoqi-python2.7-2.1.0.19-linux64.tar.gz
$ ls /opt/pynaoqi-python2.7-2.1.0.19-linux64
_allog.so libboost_math_tr1l.so
_almathswig.so libboost_prg_exec_monitor.so
_inaoqi.so libboost_program_options.so
_qi.so libboost_python.so
allog.py libboost_random.so
almath.py libboost_regex.so
almathswig.py libboost_serialization.so
engines libboost_signals.so
inaoqi.py libboost_system.so
libalbehavior.so libboost_thread.so
libalcommon.so libboost_timer.so
libalerror.so libboost_unit_test_framework.so
libalmath.so libboost_wave.so
libalproxies.so libboost_wserialization.so
libalpythontools.so libcrypto.so
libalsoap.so libcrypto.so.1.0.0
libalthread.so libgtest.so
libalvalue.so libgtest_main.so
libboost_atomic.so libqi.so
libboost_chrono.so libqic.so
libboost_context.so libqimessaging.so
libboost_coroutine.so libqipython.so
libboost_date_time.so libqitype.so
libboost_filesystem.so librttools.so
libboost_graph.so libssl.so
libboost_locale.so libssl.so.1.0.0
libboost_log.so libtinyxml.so
libboost_log_setup.so motion.py
libboost_math_c99.so naoqi.py
libboost_math_c99f.so qi
libboost_math_c99l.so share
libboost_math_tr1.so vision_definitions.py
libboost_math_tr1f.so
環境変数 PYTHONPATH に、展開した NAO Python SDKへのパスを通します。
$ echo 'export PYTHONPATH=/opt/pynaoqi-python2.7-2.1.0.19-linux64:${PYTHONPATH}' >> ~/.bashrc
ターミナル再起動後、環境変数 PYTHONPATH に SDK へのパスが通っていることを確認します。
$ set | grep PYTHONPATH
PYTHONPATH=/opt/pynaoqi-python2.7-2.1.0.19-linux64:/home/username/catkin_ws/devel/lib/python2.7/dist-packages:/opt/ros/indigo/lib/python2.7/dist-packages
サンプルコード naoqi_rospeex
ROSパッケージ
$ cd ~/catkin_ws/src
$ git clone https://github.com/kiyota-yoji/naoqi_rospeex
$ rosdep update
$ rosdep install naoqi_rospeex
依存するdebパッケージ
$ sudo apt-get install python-pyaudio
サンプルコードを動かす
ROSのlaunchファイルで起動します。
音声認識結果はターミナルに表示されます。
pepperのマイクで音声認識させる
pepperのIPアドレスを環境変数 NAO_IP に設定して起動します。
起動してから音声を受け付けるまでに10秒ほどかかります。
NICTのエンジンを使う (デフォルト)
$ NAO_IP=192.168.0.4 roslaunch naoqi_rospeex sr_nao.launch
...
[INFO] [WallTime: 1424159368.607674] reconfigure changed
[INFO] [WallTime: 1424159368.608243] subscribed to audio proxy, since this is the first listener
frame_data: 19110, energy = 171
lang=ja, engine=nict
[INFO] [WallTime: 1424159381.798684] speech recognition in progress: 1
こんにちは。
Googleのエンジンを使う
Google Speech APIを使うには、あらかじめAPI keyの設定が必要です。
末尾のメモを参照の上、取得したAPIキーを~/catkin_ws/src/naoqi_rospeex/config/sr_config.yaml に書いてください。
# This file is rospeex sr config file.
# These parameters mesans,
# google_api_key: if you want to use google speech api in rospeex,
# you MUST get google api key from following site.
# https://console.developers.google.com
google_api_key: (ここにAPIキーを書く)
$ NAO_IP=192.168.0.4 roslaunch naoqi_rospeex sr_nao.launch engine:=google
...
[INFO] [WallTime: 1424159852.998351] reconfigure changed
[INFO] [WallTime: 1424159852.998967] subscribed to audio proxy, since this is the first listener
frame_data: 177450, energy = 252
lang=ja, engine=google
[INFO] [WallTime: 1424159960.504821] speech recognition in progress: 1
池袋駅から徒歩10分圏内のマンションをさがしたいんですけど
他の言語を指定する
NICTのエンジンでは日本語(ja)、英語(en)、中国語(zh)、韓国語(ko)、
Googleのエンジンでは日本語(ja)、英語(en)が指定できます。
$ NAO_IP=192.168.0.4 roslaunch naoqi_rospeex sr_nao.launch lang:=en engine:=google
...
[INFO] [WallTime: 1424160599.257334] reconfigure changed
[INFO] [WallTime: 1424160599.258082] subscribed to audio proxy, since this is the first listener
frame_data: 35490, energy = 185
lang=en, engine=google
Hello.
$ NAO_IP=192.168.0.4 roslaunch naoqi_rospeex sr_nao.launch lang:=ko
...
[INFO] [WallTime: 1424160827.972297] reconfigure changed
[INFO] [WallTime: 1424160827.973224] subscribed to audio proxy, since this is the first listener
frame_data: 46410, energy = 212
lang=ko, engine=nict
안녕하세요.
Ubuntuサーバーのマイクで音声認識させる
サーバーに接続したマイクを使って認識させることも可能です。
$ roslaunch naoqi_rospeex sr_dummy.launch engine:=google
...
frame_data: 114660, energy = 64
lang=ja, engine=google
羽田空港から池袋まで行く方法 教えて
$ roslaunch naoqi_rospeex sr_dummy.launch lang:=en
...
frame_data: 43680, energy = 89
lang=en, engine=nict
Hello.
ちなみに、この例では、 ~/catkin_ws/src/naoqi_rospeex/scripts/dummy_microphone.py を使って、NAOqiによって取得されるのと同一形式の音声データをローカルのマイクで生成しています。
メモ: Google Speech APIのキーを取得する
Googleのクラウド音声認識API (Speech API)を使うためのAPIキー取得手順をまとめておきます。
無料アカウントでは、1日50回の呼び出し回数制限があります。
※ 参考
Chromium-dev グループへの参加
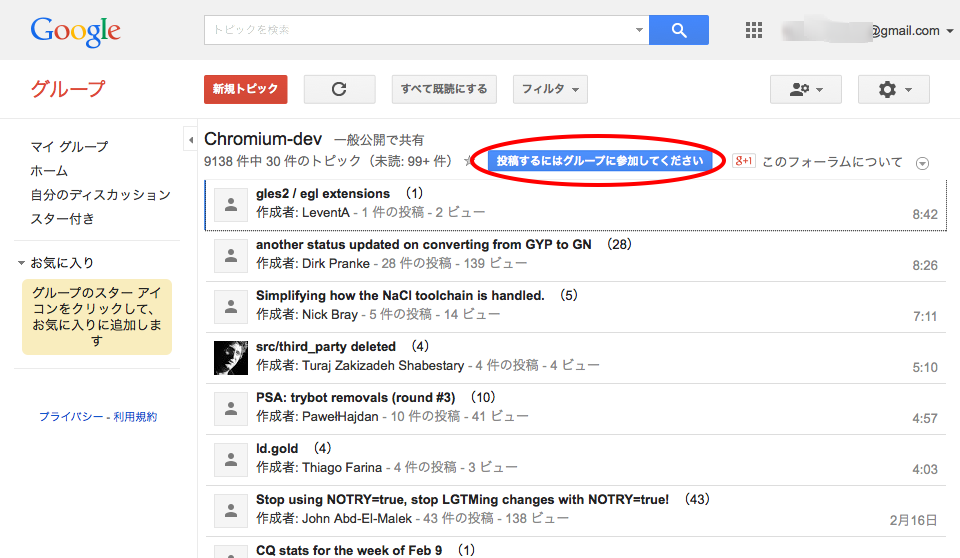
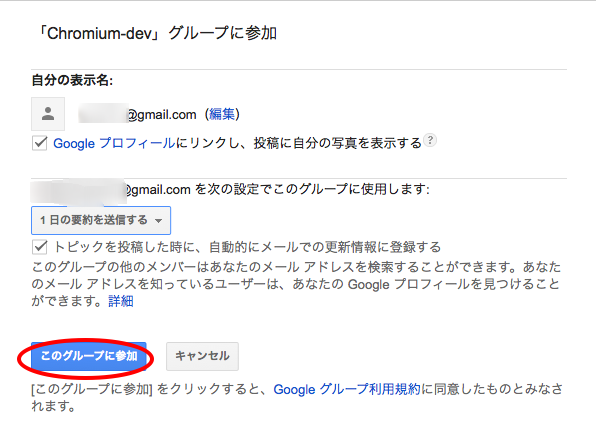
Speech APIを有効にするためには、Googleグループ Chromium-dev への参加が必要です。
Chromium-devのページにて、「グループに参加」をクリックしてください。
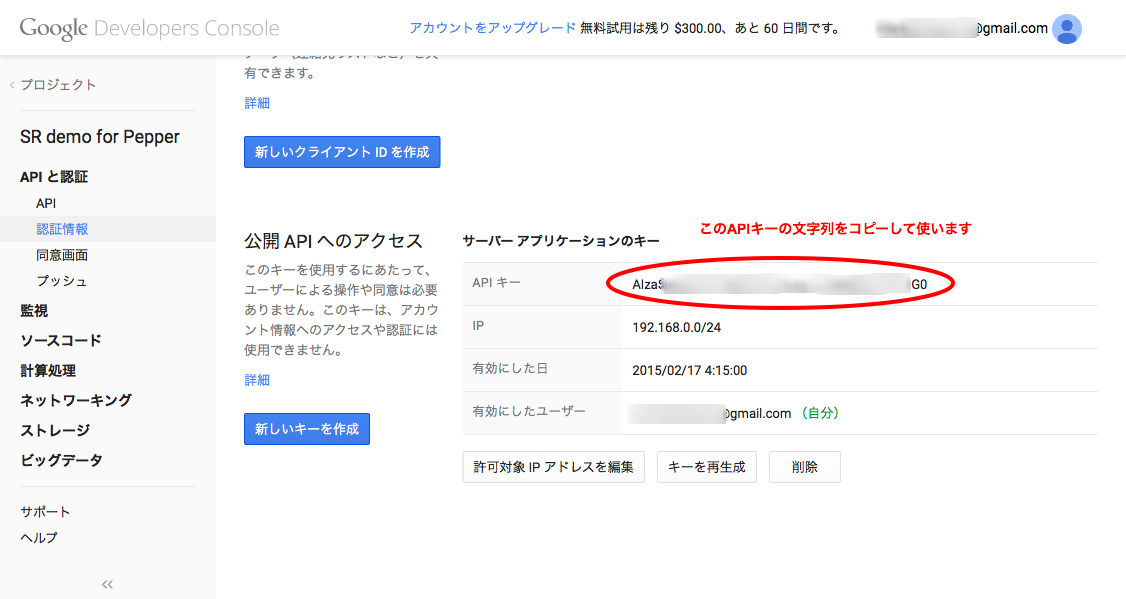
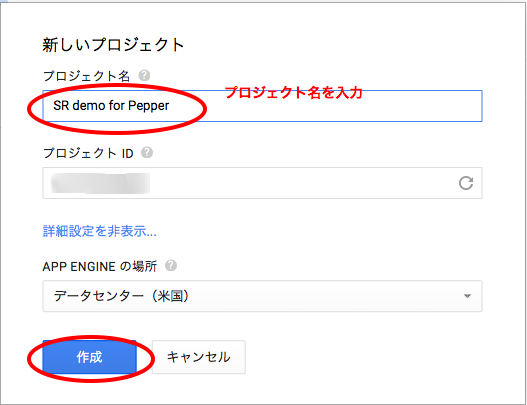
Google Developer Consoleでの操作
Google Developer Consoleにアクセスし、「プロジェクトを作成」します。
![Google Developers Console 2015-02-17 11-52-46.png]
(https://qiita-image-store.s3.amazonaws.com/0/69546/97dcf055-c8c0-4cdc-3a51-09d1c861dbf2.png)
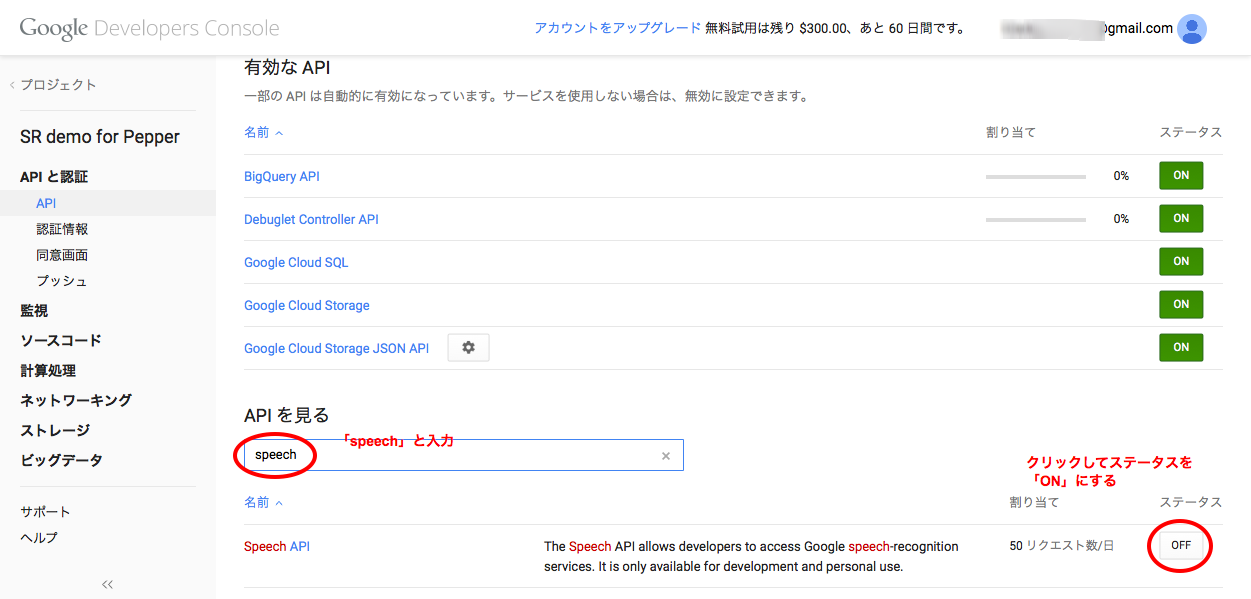
作成したプロジェクトのページにアクセスし、「APIと認証」→「API」を開いて、「Speech API」を有効(ON)にします。
「APIと認証」→「認証情報」を開いて、サーバー用のAPIアクセスキーを作成します。
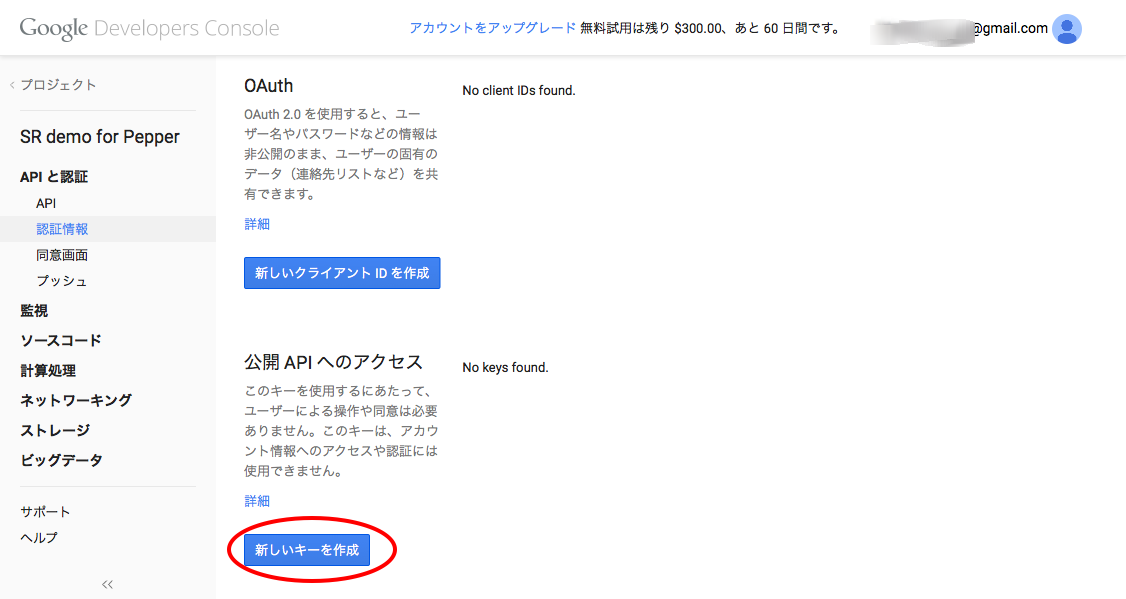
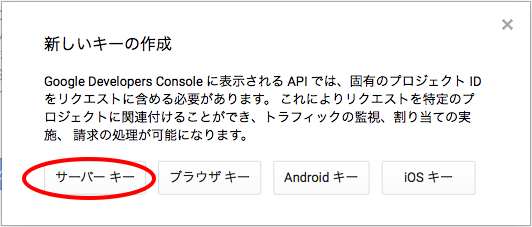
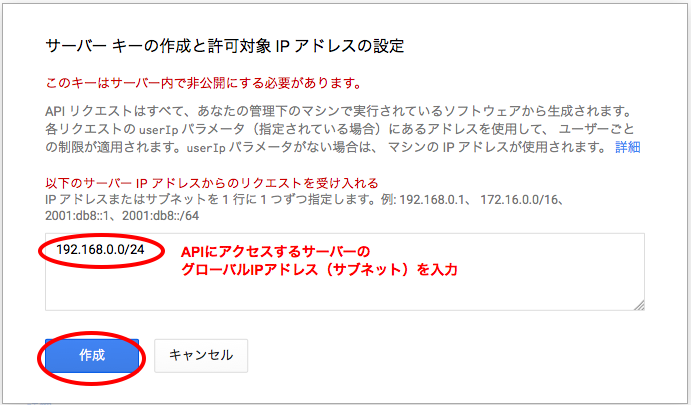
※自分のPCのグローバルIPアドレスを調べるには、IPアドレス確認サービスなどを利用してください。