私は陸上競技の長距離を専門に取り組んでおり、5000mで15分台の目標を掲げているものの、未だ目標を達成できていません。長い間達成できていないと、もはや無理かと思ってしまいがちです。
5000mで16分切って15分台出す目標は決して高すぎる目標ではなく、やればできるはず。そう思い込むため平成国際大学長距離競技会速報サイトの記録を全部抜き出して分布を可視化しました。分布形状を見るに、15分台でなら走れそうな気がしてきました。相当な努力が必要にはなりますけど。
実行環境
前回「きかんしゃトーマス(英語版)最頻出キーワードを分析してみた」にて構築した環境を流用します。
- Mac OS X 10.13 HighSierra 10.13.8
- Scrapy
- Jupyter notebook
スクレイピング
Scrapyを使って平成国際大学長距離競技会速報ページから記録の一覧を入手し、jsonで保存します。
詳細は別記事にします。
scrapy crawl hiukirokukai -o hiukirokukai.json
2017年を除く、2015年から2018年まで16大会分の記録を入手できました。
データ整形
スクレイピングした結果を読み込んでデータフレームを作成します。詳細は別記事にします。
- スクレイピングした5000mと10000mの記録を解析用に整形する(平国大記録会)(記事作成中)
import pandas as pd
df = pd.read_json('./scrape_ld/hiukirokukai.json')
正しくスクレイピングできているかデータの個数や型を確認します。必要に応じて無効値を変更して、解析用に整形します。
確認したところ、速報ページにいくつか打ち間違いのような記録があったため修正をかけました。修正したデータフレームはcsvで保存します。
df.to_csv('hiukirokukai_49-68.csv')
タイムの可視化
事前に整形したデータフレームから、次の手順で記録分布を可視化します。
- データフレームの読み込みと確認
- timedelta型への変更
- 統計値の確認
- 軸の設定
- 各種分布のプロット
- 16大会分の男子5000m全タイム数
- 各大会の男子5000m全タイム
- 1大会分の男子5000m全タイム数
- 1大会分の男子5000m各組全タイム
データフレームの読み込みと確認
csvを読み込み、データ系列を確認します。
%matplotlib inline
import pandas as pd
df = pd.read_csv('hiukirokukai_49-68.csv', index_col=0)
df.dtypes
ath_lane float64
ath_name object
ath_reg object
ath_team object
ath_time object
cat_gen object
cat_name object
cat_num int64
meet_date object
meet_name object
meet_num int64
datetime object
timedelta object
dtype: object
df.head()
| ath_lane | ath_name | ath_reg | ath_team | ath_time | cat_gen | cat_name | cat_num | meet_date | meet_name | meet_num | datetime | timedelta | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 208 | 0.0 | 鈴木 太基 | 東京 | ラフィネグループ | 30:21.32 | 男子 | 10000m | 3 | 2018-06-23 | 平国大記録会 | 68 | 1900-01-01 00:30:21.320 | 0 days 00:30:21.320000000 |
| 209 | 0.0 | 甲斐 大貴 | 東京 | ラフィネグループ | 30:27.26 | 男子 | 10000m | 3 | 2018-06-23 | 平国大記録会 | 68 | 1900-01-01 00:30:27.260 | 0 days 00:30:27.260000000 |
| 210 | 0.0 | 熊谷 光 | 東京 | ラフィネグループ | 30:27.35 | 男子 | 10000m | 3 | 2018-06-23 | 平国大記録会 | 68 | 1900-01-01 00:30:27.350 | 0 days 00:30:27.350000000 |
| 211 | 0.0 | 小泉 雄輝 | 東京 | ラフィネグループ | 30:38.95 | 男子 | 10000m | 3 | 2018-06-23 | 平国大記録会 | 68 | 1900-01-01 00:30:38.950 | 0 days 00:30:38.950000000 |
| 212 | 0.0 | 海老澤 太 | 東京 | ラフィネグループ | 30:46.97 | 男子 | 10000m | 3 | 2018-06-23 | 平国大記録会 | 68 | 1900-01-01 00:30:46.970 | 0 days 00:30:46.970000000 |
ath_laneからmeet_numはスクレイピングしたデータで、最後のdatetimeとtimedeltaは次のように加工したデータです。
-
datetime- 文字列の
ath_timeを書式指定してdatetime型に変換したもの
- 文字列の
-
timedelta-
datetimeから年の部分を引いたもの
-
timedeltaがプロットすべきタイムの系列です。
timedelta型への変更
統計値計算や数値プロットのため、タイムの系列timedeltaをtimedelta型に変更します。
df['datetime']=pd.to_datetime(df['datetime'])
df['timedelta']=pd.to_timedelta(df['timedelta'])
df['timedelta'].head()
208 00:30:21.320000
209 00:30:27.260000
210 00:30:27.350000
211 00:30:38.950000
212 00:30:46.970000
Name: timedelta, dtype: timedelta64[ns]
df.dtypes
ath_lane float64
ath_name object
ath_reg object
ath_team object
ath_time object
cat_gen object
cat_name object
cat_num int64
meet_date object
meet_name object
meet_num int64
datetime datetime64[ns]
timedelta timedelta64[ns]
dtype: object
統計値の確認
次の項目を簡単に確認します。
- 種目ごと全体の人数
- 男子5000mの統計値一式
種目ごと全体の人数を確認します。
df.groupby(['cat_gen']).cat_name.value_counts()
cat_gen cat_name
女子 5000m 84
5000mW 8
男女混合 5000m 284
10000mW 16
男子 5000m 5349
10000m 1419
5000mW 25
Name: cat_name, dtype: int64
男子5000mは延べ5349人分ありました。
男子5000mのデータフレームを作成し、統計値一式を確認します。
dfM = df[df['cat_gen']=='男子']
x = dfM[dfM['cat_name']=='5000m']['timedelta']
x.describe(include='all')
count 5349
mean 0 days 00:15:48.598708
std 0 days 00:00:55.947584
min 0 days 00:13:22.420000
25% 0 days 00:15:08.830000
50% 0 days 00:15:40.430000
75% 0 days 00:16:20.170000
max 0 days 00:22:30.560000
Name: timedelta, dtype: object
5000mのタイムは平均値で15分48秒、中央値だと15分40秒でした。15分台は決して速い方ではなさそうです。また、標準偏差は1分程度あるので、ほとんどの人は17分切って16分台以内に収まっていそうです。
軸の設定
描画用のライブラリをインポートします。
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="darkgrid", font='Meiryo')
datetime型をそのままプロットするとどうなるか、簡単に確認します。
x.plot()
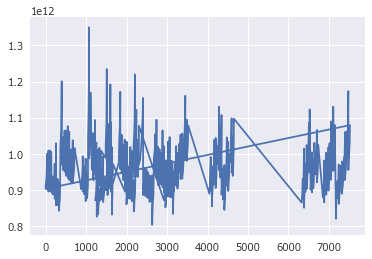
y軸はナノ秒になりました。比較のため、datetime型をプロットした場合も確認します。
xd = dfM[dfM['cat_name']=='5000m']['datetime']
xd.plot()
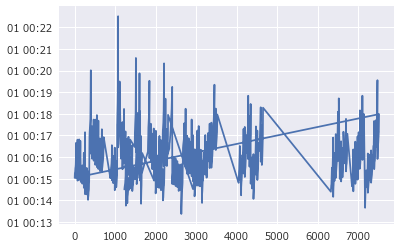
y軸は日 時間:分の書式になりました。datetime型なら軸の書式設定がサポートされており、書式を変えられそうです。
一方、datetime型はヒストグラムを作成するsns.distplotに対応していないので、timedelta型を使うことにします。
timedelta型をプロットするには、.astypeを指定して変換します。
xs=x.astype('timedelta64[s]')
x軸の書式設定のため、Formatterを工夫します。
import datetime
import matplotlib.ticker as mticker
def timeTicks(x, pos):
d = datetime.timedelta(seconds=x)
return str(d)
formatter = mticker.FuncFormatter(timeTicks)
軸範囲を設定します。5000mはこの範囲で統一します。
xmin = datetime.timedelta(minutes=13,seconds=0).seconds
xmax = datetime.timedelta(minutes=21,seconds=0).seconds
xint = 60
これで各種設定が完了しました。次は各種分布をプロットします。
16大会分の男子5000m全タイム数
ax=sns.distplot(xs,kde=False,bins=20,)
ax.xaxis.set_major_formatter(formatter)
ax.xaxis.set_major_locator(mticker.MultipleLocator(xint))
plt.gcf().autofmt_xdate()
plt.xlim(xmin,xmax)
plt.title("Male 5000m all results")
plt.xlabel("Time")
plt.ylabel("Count")
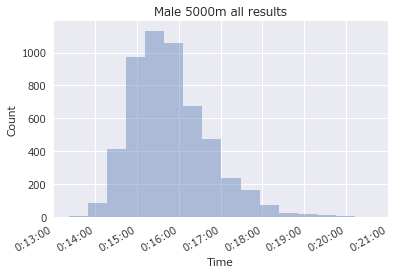
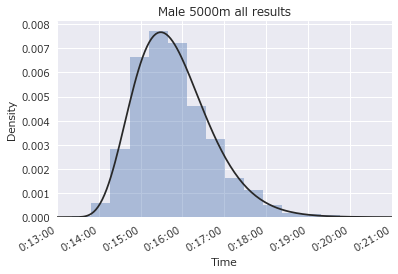
統計値で確認した中央値の15分40秒よりも最頻値は速そうで、15分30秒前後が最も多そうです。
from scipy import stats
ax=sns.distplot(xs,kde=False,bins=20,fit=stats.gamma)
ax.xaxis.set_major_formatter(formatter)
ax.xaxis.set_major_locator(mticker.MultipleLocator(xint))
plt.gcf().autofmt_xdate()
plt.xlim(xmin,xmax)
plt.title("Male 5000m all results")
plt.xlabel("Time")
plt.ylabel("Density")
男子5000m5349人全員の記録を集計すると、記録分布はほぼガンマ分布でフィッティングできました。
記録分布が一般的な形で分かると、予測や目標設定に使えそうです。たとえば、駅伝チームを作って上位を選抜するとして、チーム人数を何人くらい集めれば上位メンバーのタイムを目標に入れられるか見当がつきそうです。
各大会の男子5000m全タイム
各大会ごとのばらつきを確認します。特に、中央値が15分40秒からどれほどばらつくかに注目します。
rec = dfM[(dfM['cat_name']=='5000m')]
rec = rec.assign(timedelta=rec['timedelta'].astype('timedelta64[s]'))
rec = rec.sort_values('meet_date')
ax = sns.boxplot(x="meet_date", y="timedelta", data=rec)
ax.yaxis.set_major_formatter(formatter)
ax.yaxis.set_major_locator(mticker.MultipleLocator(xint))
plt.gcf().autofmt_xdate()
plt.ylim(xmin,xmax)
plt.title("Male 5000m")
plt.xlabel("date")
plt.ylabel("Time")
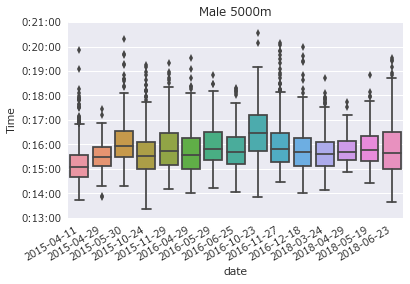
箱の下端が25%、中央が50%、上端が25%に相当します。線は最大で箱の大きさの1.5倍まで伸ばされていて、この中に入らない点は個別にプロットされます。
次のことがグラフより読み取れます。
- 中央値はほぼ15分30秒から16分00秒までの間にばらつく
- 中央値含む50%の区間はおおよそ1分から1分30秒程度
- 全体的に2015-4-11が最も速く、2016-10-23が最も遅い
1大会分の男子5000m全タイム
比較的最近の2018年5月19日の結果を確認します。
x = dfM[(dfM['cat_name']=='5000m')&
(dfM['meet_date']=='2018-05-19')]['timedelta']
xs=x.astype('timedelta64[s]')
ax=sns.distplot(xs,kde=False,bins=20,rug=True)
ax.xaxis.set_major_formatter(formatter)
ax.xaxis.set_major_locator(mticker.MultipleLocator(xint))
plt.gcf().autofmt_xdate()
plt.xlim(xmin,xmax)
plt.title("Male 5000m 2018-05-19")
plt.xlabel("Time")
plt.ylabel("Count")
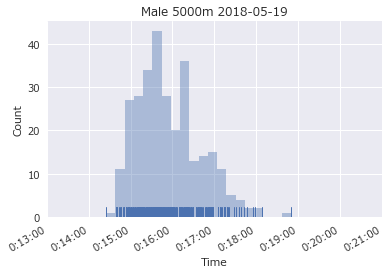
15分30秒と16分手前、17分ちょうどの3つの場所に山がありました。なんだかんだで、16分切れなくて苦労している人たちのグループがありそうです。
xs=x.astype('timedelta64[s]')
ax=sns.distplot(xs,kde=False,bins=20,rug=True,fit=stats.gamma)
ax.xaxis.set_major_formatter(formatter)
ax.xaxis.set_major_locator(mticker.MultipleLocator(xint))
plt.gcf().autofmt_xdate()
plt.xlim(xmin,xmax)
plt.title("Male 5000m 2018-05-19")
plt.xlabel("Time")
plt.ylabel("Density")
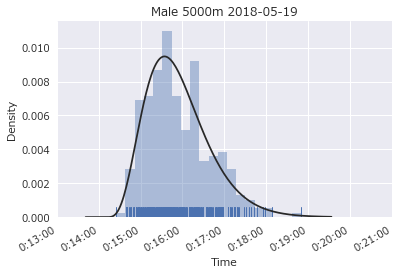
全体で見たのと同様に、分布形状はガンマ分布に近いです。
1大会分の男子5000m各組全タイム
各組ごとのタイム分布を確認します。今度は1組目の男女混合の組も合わせてプロットします。
rec = df[(df['cat_name']=='5000m')&
(df['meet_date']=='2018-05-19')]
rec = rec.assign(timedelta=rec['timedelta'].astype('timedelta64[s]'))
ax = sns.swarmplot(x="cat_num", y="timedelta", data=rec, size=3)
ax.yaxis.set_major_formatter(formatter)
ax.yaxis.set_major_locator(mticker.MultipleLocator(xint))
plt.ylim(xmin,xmax)
plt.title("Male 5000m 2018-05-19")
plt.xlabel("group")
plt.ylabel("Time")
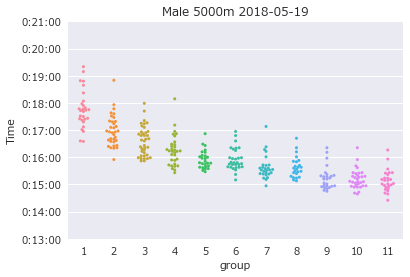
記録を重ねず並べてみると、それぞれの組の集団から狙えそうな記録が分かります。
- 2組目は16分30秒切り狙い
- 3組目から6組目では16分切り狙い
- 7組目から8組目では15分30秒切り狙い
- 9組目以降で15分切り狙い
組の中でほぼ同時にゴールしているのは最大でも5名程度で、人数は30秒から1分以内におおよそ平均的に分布しています。先頭の集団から30秒程度離されても心配なさそうです。
1組目から速い組になるほどタイムのばらつきは小さくなり、15分30秒の7組目を境にそれ以降は少しづつばらつきが大きくなるようです。各組の人数は同程度で、タイム分布はガンマ分布であることから妥当な結果です。
まとめ
平成国際大長距離競技会の男子5000mの全記録分布を可視化して、次のことがよく分かりました。
- 15分台は決して珍しくなく多数派を占め、15分30秒前後が最も多い
- 記録分布はガンマ分布になっており、予測や目標設定に使える可能性がある
- 中央値は15分30秒から16分の間にばらつき、半分くらいの人は中央値を挟む1分から1分30秒の中にいる
- 組の中のタイム分布からすると、先頭の集団から30秒程度離されても単独走になる心配はない
- 15分30秒前後の組が最もタイムのばらつきが小さく、そのタイムから離れた組であるほどタイムのばらつきは大きくなる
5000m15分台のタイムは決して珍しくなく多数派であることがよく分かりました。また、15分台出せれば15分30秒くらいまでなら一気に伸びそうです。15分台ならどうにかすれば走れるはずと自分に言い聞かせ、今後も競技に取り組みます。
まだまだやり残していることあるので、続きができたらまた共有します。
- 記録分布の可視化
- 日体大長距離競技会
- 福岡国際マラソン
- 箱根駅伝予選会
- 5000mと10000mの目標タイムの設定
- 福岡国際マラソンをA標準で走る
- 箱根駅伝予選会通過に必要な部員数とタイム構成
- 5000mと10000mのシーズン記録から箱根駅伝予選会通過校を予測する