ここ数年、Qiita やnote に記事を書いてました。
気づけば、Qiita、X、Facebook など、さまざまなプラットフォームにもアウトプットが点在し、どこに何を書いたのか把握しづらい状況になっていました。
さらに、外部サービスに依存する以上、
- プラットフォームの仕様変更
- サービスの衰退
- UI更新による記事の埋もれ
といった理由で、せっかく積み上げた記事が “資産” として活用できなくなるリスクもあります。
実際に、
「Facebook に書いた昔の記事が取り出しづらくなり、振り返れない」
「SNS が乱立していて、どこを “ホーム” にすればいいのかわからない」
といった悩みはよく耳にします。
大前提として、Qiita は素晴らしいプラットフォームで、感謝しています。
ただ、自分の手元で管理しておく仕組みも重要だと考えるようになりました。
そこで今回、Qiita API → Markdown → Eleventy → 自作ホームページで統合管理 をしてみました。
この記事では、その中でも Qiita 記事の Markdown 化 に絞ってまとめます。
(note 記事の Markdown 化については別記事で紹介しています。)
全体構成
最終的には、以下のようなディレクトリ構造を目指しました。
HomePage/
posts/
qiita/ ← ここに Qiita 変換後の .md
tech/
reading/
community/
note/
images/
posts/ ← ここに Qiita から取得した画像
qiita/
scripts/
qiita2md/qiita_export.py ← Qiita記事をMarkdown化するスクリプト
Eleventy は posts/** を横断して扱えるため、カテゴリ別に整理しても問題ありません。
Qiita API を使った Markdown 化の流れ
QiitaAPI を活用させていただきました。使い方はこちらに詳細が記載されています。
Qiita の記事は API 経由で JSON 取得できるため、変換処理は非常にシンプルです。
今回のスクリプトでは、Qiita API から自分の記事を取得し、次の流れで Markdown 化しています。
実際に行ったことは次のとおり。
- Qiita API Token を発行
-
.envに書いたQIITA_TOKENとUSER_IDを読み込む -
GET /api/v2/authenticated_user/itemsで自分の記事一覧を取得 -
rendered_bodyから画像 URL を抽出し、ローカルへ保存 - 画像の URL を
/images/qiita/xxxx.pngに置き換える -
body(元 Markdown)をそのまま本文として利用 - タイトル・日付・Qiita URL・タグ一覧を YAML Frontmatter として整形
- ファイル名を安全化して
posts/qiita/に保存
Qiita API の使用例
使用した API は以下。
GET https://qiita.com/api/v2/users/{USER_ID}/items?page={page}&per_page=100
-
body→ 元の Markdown -
rendered_body→ HTML(ここから画像 URL を抽出) -
tags→ タグ配列({"name": "AWS"}の形式) -
created_at,url,id,titleなどのメタ情報
これらを組み合わせて Markdown ファイルを生成しています。
実際の変換ポイント
1. 本文(Markdown)は body をそのまま使う
Qiita の記事はもともと Markdown で投稿されているため、
HTML 変換は不要で、JSON の body をそのまま本文として利用しています。
2. 画像は rendered_body から抽出してローカル保存
見た目用 HTML(rendered_body)には <img> タグが含まれます。
BeautifulSoup で <img src="..."> を拾い、ローカル保存します。
保存先は:
images/qiita/{item_id}_{index}.{ext}
Markdown 内の画像パスは自動で書き換えています。
3. タグは Qiita 由来+自作ブログ用を統合
Qiita のタグ配列からタグ名を取り出しつつ、
- tech
- qiita
を必ず付与しています。
YAML には次のように出力されます。
tags: ["tech", "qiita", "AWS", "Python"]
4. ファイル名は安全な文字だけに整形
日本語タイトルでも保存できるように、以下の処理をしています。
- 禁止文字(/ : * ? " < > |)を
_に置換 - 制御文字を削除
- 長すぎる場合は 100 文字に切る
例:
「AWS認定 試験の勉強方法」→ AWS認定_試験の勉強方法.md
ポイント
- Qiita API は情報が充実しており、自動化が容易
- body(Markdown)をそのまま使え、変換ロスがない
- rendered_body を併用して画像だけ別処理
- タグを Qiitaタグ+ブログ側タグの両方で管理
- ファイル名の安全化で、Windows/Mac/Linux 全環境に対応
- Eleventy と組み合わせて「自前の Qiita」環境が構築できる
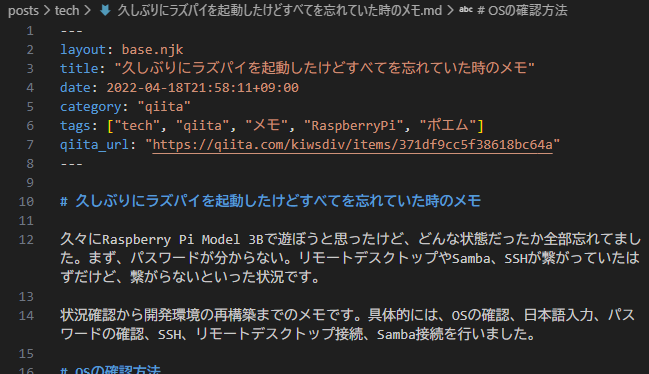
変換後の Markdown(例)
---
layout: base.njk
title: "9軸IMUモジュールHWT901B-TTLをROS1で使用するメモ"
date: 2023-12-30T07:51:59+09:00
category: "qiita"
tags: ["tech", "qiita", "メモ", "ROS", "IMU"]
qiita_url: "https://qiita.com/kiwsdiv/items/f44afb7291227494c4f0"
---
本文は純粋な Markdown として保存され、
元記事の URL も失わずに保持できます。
Before / After(実例)
元の Qiita 記事

変換後(Markdown)
自作ホームページ上での表示
ページ一覧

自作ホームページ上の記事の見出し

画像も表示されている

ホームページの作成については、別途記事にするかもしれません。
マークダウンで手元にあれば、いかようにでも修正・編集することができます。
おわりに
Qiita は素晴らしいプラットフォームですが、自分の記録を「自分の手元」に置く安心感は大きいです。
Qiita API Token を用意するだけで始められます。
Python スクリプト(折りたたみ)
参考まで。仕様を生成AIに伝えれば簡単に作成できると思います。
アクセストークンは .env に記載しておきます。
QIITA_TOKEN=[token]
USER_ID=[user]
クリックして展開
{% raw %}
import os
import requests
from datetime import datetime
from pathlib import Path
from bs4 import BeautifulSoup
import re
from dotenv import load_dotenv
# -------------------------------------------------------------
# .env 読み込み
# -------------------------------------------------------------
load_dotenv()
QIITA_TOKEN = os.getenv("QIITA_TOKEN")
USER_ID = os.getenv("USER_ID")
# -------------------------------------------------------------
# 設定
# -------------------------------------------------------------
BASE_DIR = Path("posts/tech")
IMAGES_DIR = Path("images/qiita")
IMAGES_DIR.mkdir(parents=True, exist_ok=True)
HEADERS = {
"Authorization": f"Bearer {QIITA_TOKEN}"
}
# -------------------------------------------------------------
# 画像をローカルに保存
# -------------------------------------------------------------
def download_image(url, item_id, index):
try:
ext = url.split("?")[0].split(".")[-1]
filename = f"{item_id}_{index}.{ext}"
save_path = IMAGES_DIR / filename
resp = requests.get(url, stream=True)
if resp.status_code == 200:
with open(save_path, "wb") as f:
for chunk in resp.iter_content(1024):
f.write(chunk)
return f"/images/qiita/{filename}"
else:
return url
except Exception:
return url
# -------------------------------------------------------------
# HTML に埋め込まれた画像をローカル画像に差し替え
# -------------------------------------------------------------
def replace_images_in_html(html, item_id):
soup = BeautifulSoup(html, "html.parser")
images = soup.find_all("img")
for i, img in enumerate(images):
src = img.get("src")
if not src:
continue
new_src = download_image(src, item_id, i)
img["src"] = new_src
return str(soup)
# -------------------------------------------------------------
# Qiita API で全記事を取得(ページネーション)
# -------------------------------------------------------------
def fetch_all_qiita_items():
items = []
page = 1
while True:
url = f"https://qiita.com/api/v2/users/{USER_ID}/items?page={page}&per_page=100"
resp = requests.get(url, headers=HEADERS)
if resp.status_code != 200:
break
data = resp.json()
if not data:
break
items.extend(data)
page += 1
return items
# 安全なファイル名を生成する関数
def slugify_filename(title: str) -> str:
"""
タイトルから安全なファイル名を生成
日本語は残しつつ、禁止文字を全て _ に置換
"""
# 禁止文字 → _
cleaned = re.sub(r'[\\/:*?"<>|]', '_', title)
cleaned = cleaned.replace(" ", "_")
# 制御文字削除
cleaned = re.sub(r'[\x00-\x1f\x7f]', '', cleaned)
# 長すぎる場合は切る
return cleaned[:100]
# -------------------------------------------------------------
# Markdown に変換して保存
# -------------------------------------------------------------
def save_as_markdown(item):
title = item["title"]
created_at = item["created_at"]
qiita_url = item["url"]
item_id = item["id"]
qiita_tags = [t["name"] for t in item.get("tags", [])]
tags = ["tech", "qiita"] + qiita_tags
tags = list(dict.fromkeys(tags)) # 重複削除
# HTML を Markdown 化せず、本文(body) をそのまま使う(Qiita は元が Markdown)
body_md = item["body"]
# HTML の rendered_body 内の画像 URL をローカルに置換
rendered = item["rendered_body"]
rendered = replace_images_in_html(rendered, item_id)
# YAML front matter
tag_str = ", ".join(f'"{t}"' for t in tags)
md_content = f"""---
layout: base.njk
title: "{title}"
date: {created_at}
category: "qiita"
tags: [{tag_str}]
qiita_url: "{qiita_url}"
---
# {title}
{body_md}
"""
# 保存パス
safe_title = slugify_filename(title)
md_path = BASE_DIR / f"{safe_title}.md"
with open(md_path, "w", encoding="utf-8") as f:
f.write(md_content)
print(f"Saved: {md_path}")
# -------------------------------------------------------------
# メイン処理
# -------------------------------------------------------------
def main():
BASE_DIR.mkdir(parents=True, exist_ok=True)
print("Fetching Qiita articles...")
items = fetch_all_qiita_items()
print(f"Found {len(items)} articles")
for item in items:
save_as_markdown(item)
print("\nDone.")
if __name__ == "__main__":
main()
{% endraw %}