はじめに
本記事では、Flaggerによるプログレッシングデリバリーを活用した信頼性向上を図った際のことを書きます。
私が所属するプラットフォームSREでは、Web Gatewayと呼ばれるAPI Gatewayの前段にありWebブラウザからのみリクエストを受けるマイクロサービスを管轄しています。
主には、フロントエンドアプリケーションのセッション・UIDの初期化やAPIリクエストのメンバー認証および転送を担っています。
詳細なシステム構成に関しては、以下の資料で詳細に解説されているため、気になる方は併せてご覧ください。
このWeb Gatewayでは、マイクロサービスの性質上、定常的に400エラーが出ており、セールやピークタイム時のリクエスト増加時は比例してエラー数が増加します。
課題
ここでは詳細は書かないですが、Web Gatewayのリリース直後に400エラーが急増しておりました。
この時、起きていた事象としては、Web Gatewayに依存するサービスで5xxエラーが発生し障害が起きていました。
一方で、Web Gatewayとしては5xxエラーは出ておらず、弊チームとしては障害検知ができておりませんでした。
そのためリリース直後に400エラーの急増を検知する仕組みが必要でした。
解決策
最終的には、以下の点に着目をしましたFlaggerのプログレッシングデリバリーの実施中はk8s podのCanary podが存在します。
そのため以下の複合条件がtrueならアラートを検知するモニターを作成しました。
-
Web GatewayのCanary Podが存在する
- プログレッシングデリバリー中にzozo-web-gateway-primary(primary pod)とzozo-web-gateway(canary pod)が存在します。使用するのは、canary podの名前となります。
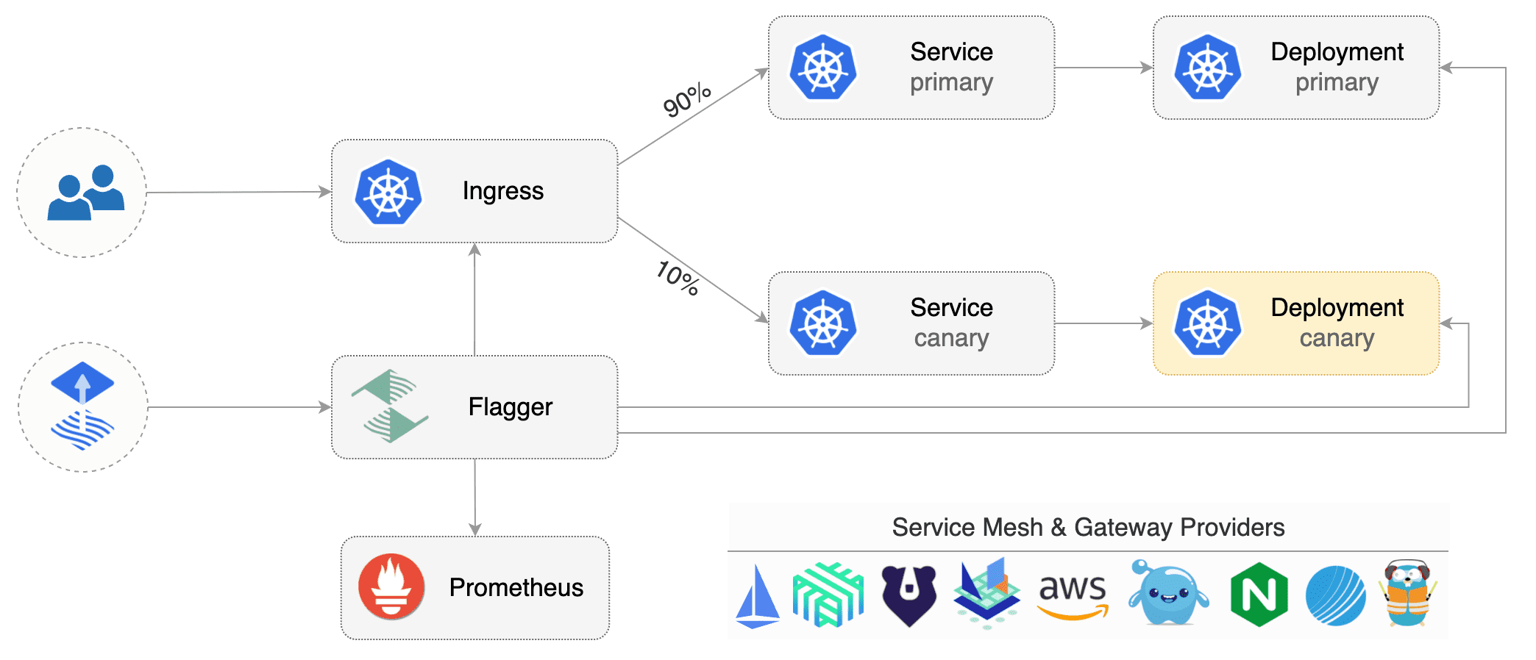
- プログレッシングデリバリー中にzozo-web-gateway-primary(primary pod)とzozo-web-gateway(canary pod)が存在します。使用するのは、canary podの名前となります。
-
400エラーが1%を超えている
# Canary pod検知
resource "datadog_monitor" "monitoring-canary-pod" {
name = "[${local.env}] ${local.service_name} Monitoring of Canary Pod"
tags = concat(local.basic_monitor_tags, ["application:${local.service_name}"])
type = "metric alert"
query = "sum(last_1m):default(sum:kubernetes.pods.running{env:${local.env},kube_namespace:${local.service_name},kube_deployment:${local.service_name}}, 0) >= 1"
message = "[${local.env}] ${local.service_name} monitoring of canary pod"
}
# 400エラー検知
resource "datadog_monitor" "monitoring-400-error-rate" {
name = "[${local.env}] ${local.service_name} Monitoring 400 Error Rate in /apis/hoge"
tags = concat(local.basic_monitor_tags, ["application:${local.service_name}"])
type = "metric alert"
query = "sum(last_1m):sum:trace.http.request.hits{http.status_code:400,resource_name:/apis/hoge,env:${local.env},service:${local.service_name}}.as_count() / sum:trace.http.request.hits{resource_name:/apis/hoge,env:${local.env},service:${local.service_name}}.as_count() * 100 >= ${local.monitor_400_error_rate_threshold}"
message = "[${local.env}] ${local.service_name} monitoring of 400 error rate"
}
# 複合モニター
resource "datadog_monitor" "monitoring-400-error-during-release" {
name = "[${local.env}] ${local.service_name} Monitoring 400 Error Rate in /apis/hoge during Release"
tags = concat(local.basic_monitor_tags, ["application:${local.service_name}"])
type = "composite"
query = "${datadog_monitor.monitoring-400-error-rate.id} && ${datadog_monitor.monitoring-canary-pod.id}"
message = <<-EOT
${local.warning_alert} {{#is_alert}}
*リリース中に400errorのエラー率が1%以上になっています。${local.oncall_guide}**
- APMトレース: ${local.service_apm_trace}
- ダッシュボード: ${local.dashboard}
1. 400エラーがリリースによる影響かを確認してください。
2. botによる影響の可能性もあるためメトリクスを確認してください。
{{/is_alert}}
EOT
}
最後に
本記事では、Flaggerのカナリアリソース×Datadogの複合モニターを活用したリリース直後の400エラー検知の仕組みを構築する際の課題と解決策を具体的に解説しました。
また、FlaggerとDatadogを組み合わせることで、リリース時のリスクを軽減することが可能となりました。
この記事が少しでも参考になればいいねの方お願いいたします!
参考