SPSS Modelerでデータをファイル形式でエクスポートするのが、フラットファイル・エクスポートノードです。
これをPythonのpandasで書き換えてみます。
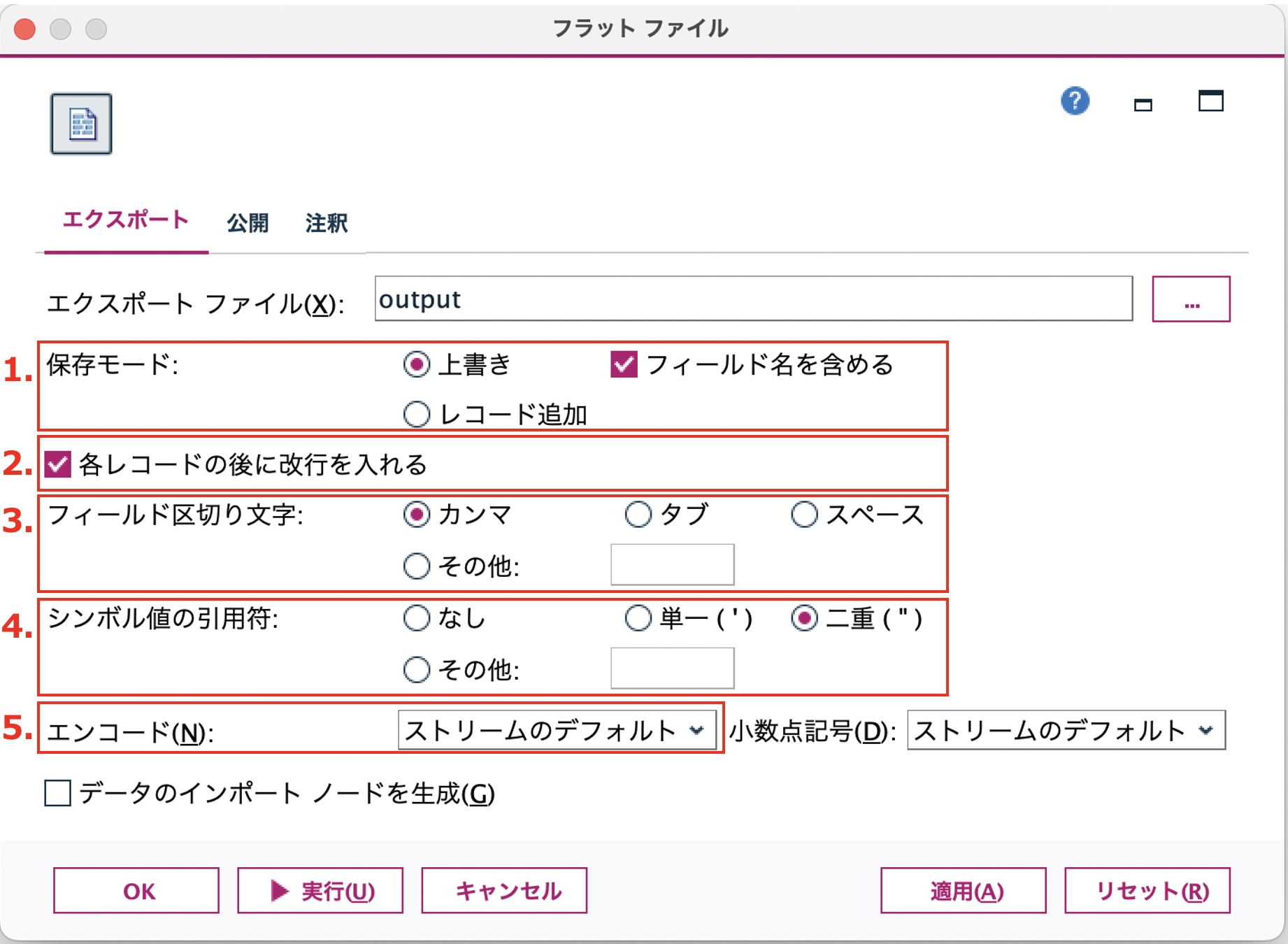
ここでは、以下の5つのオプションについてフォーカスします。
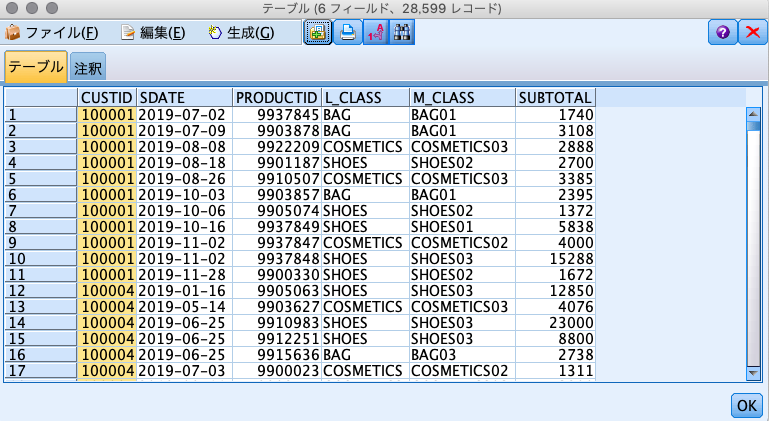
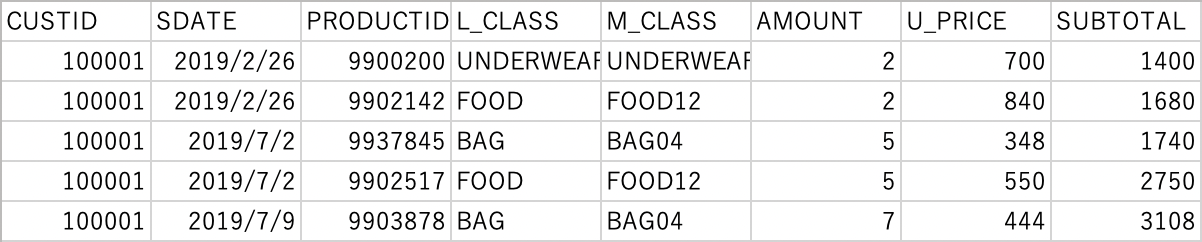
0.使用するデータ
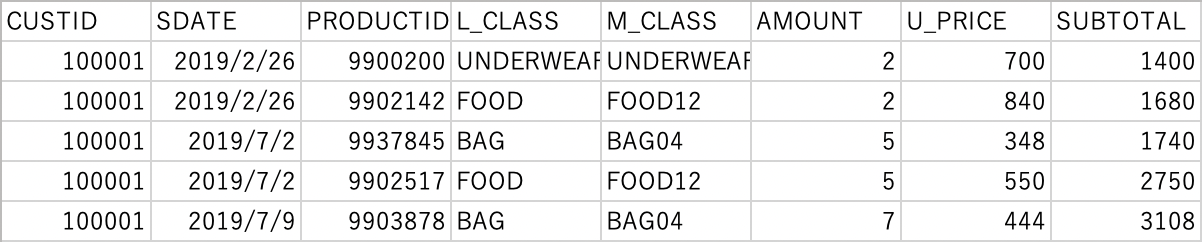
以下のID付POSデータ(■ファイル名:sampletranDEPT4en2019S.csv)を使用します。
誰(CUSTID)がいつ(SDATE)何(PRODUCTID、L_CLASS商品大分類、M_CLASS商品中分類)をいくら(SUBTOTAL)購入したかが記録されたID付POSデータです。
1.保存モード

SPSS Modeler
「上書き」を選択、「フィールド名を含める」にチェックを入れる場合
ローカル環境の指定したディレクトリにフラットファイルをエクスポートします。
※もし指定したディレクトリに同名のファイルが既に存在した場合、上書きを行うため、元のデータは削除されます。
「上書き」を選択、「フィールド名を含める」にチェックを入れない場合
同様に、ローカル環境の指定したディレクトリにフラットファイルをエクスポートします。
ただし、1行目(フィールド)を含めないため、2行目以降のデータのみがエクスポートされることになります。

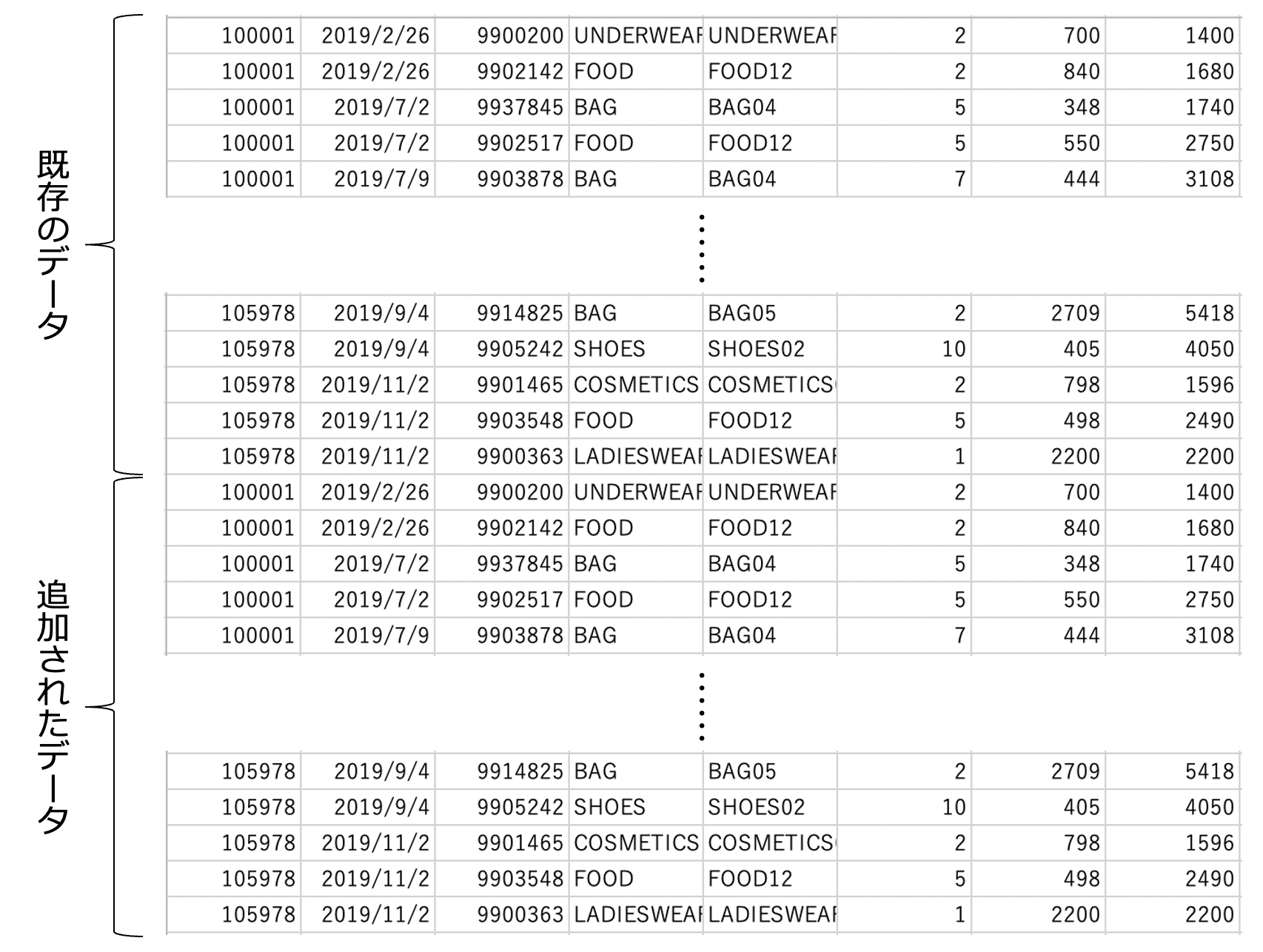
「レコード追加」を選択する場合
指定したディレクトリに同名のファイルが既に存在する場合のみ実行可能で、元のデータの下にデータを追加するようにエクスポートします。
Python
SPSS Modelerの各チェック項目に対応するように、Pythonで書き換えました。
# 保存モード: 上書き、フィールド名を含める: チェックあり
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False)
# 保存モード: 上書き、フィールド名を含める: チェックなし
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, header=None)
# 保存モード: レコード追加
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, header=None, mode='a')
2.各レコードの後に改行を入れる

SPSS Modeler
「各レコードの後に改行を入れる」にチェックを入れる場合
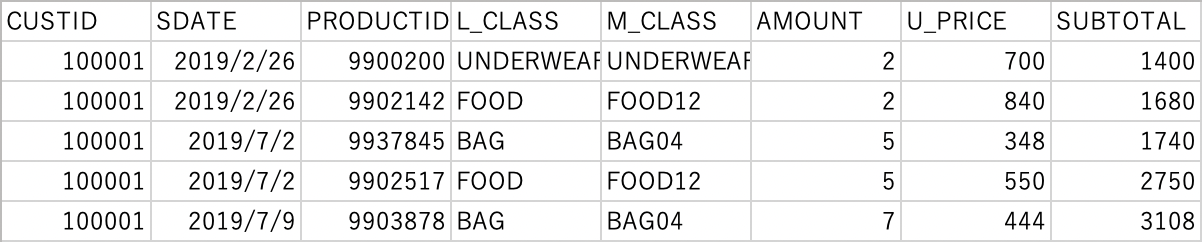
「各レコードの後に改行を入れる」にチェックを入れない場合
各レコードの後に改行を入れないため、同一の行にデータがエクスポートされます。

Python
SPSS Modelerのチェック項目に対応するように、Pythonで書き換えました。
# 各レコードの後に改行を入れる: チェックあり
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, line_terminator=None)
# line_terminator='\n'と、改行を指定してもよい
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, line_terminator='\n')
# to_csvはデフォルトでline_terminator=Noneを選択するため、指定しなくてもよい
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False)
# 各レコードの後に改行を入れる: チェックなし
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, line_terminator=',')
3.フィールド区切り文字

SPSS Modeler
「カンマ」にチェックを入れる場合
カンマ区切りのデータ(.csv)としてエクスポートされます。

「タブ」にチェックを入れる場合
タブ区切りのデータ(.tsv)としてエクスポートされます。
※エクスポート先のディレクトリを指定する際に、ファイル名の拡張子を.tsvとする必要があります。

「スペース」にチェックを入れる場合
スペース区切りのデータとしてエクスポートされます。

「その他」にチェックを入れる場合
空欄の箇所があり、区切り文字として選択したい任意の文字を指定可能です。
ここでは例として、ハイフン(-)を区切り文字として指定しております。

Python
SPSS Modelerの各チェック項目に対応するように、Pythonで書き換えました。
# フィールド区切り文字: カンマ
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, sep=',')
# to_csvはデフォルトでsep=','を選択するため、指定しなくてもよい
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False)
# フィールド区切り文字: タブ
# この場合ファイルの拡張子がtsvとなることに注意されたい
df.to_csv('./output/sampletranDEPT4en2019S.tsv', index=False, sep='\t')
# フィールド区切り文字: スペース
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, sep=' ')
# フィールド区切り文字: その他
# to_csvのsep引数に任意の文字を指定すればよい
# ここでは例として改行(\n)を指定する
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, sep='\n')
4.シンボル値の引用符
この機能は文字列型のデータのみを対象としたものであり、文字列の前後を囲むシンボル値を指定することが可能です。

SPSS Modeler
「なし」にチェックを入れる場合

「単一(')」にチェックを入れる場合
文字列の項目にシングルクォーテーションが付けられます。

「二重(")」にチェックを入れる場合

「その他」にチェックを入れる場合
空欄の箇所があり、引用符として選択したい任意の文字を指定可能です。
ここでは例として、#を引用符として指定しております。

Python
SPSS Modelerの各チェック項目に対応するように、Pythonで書き換えました。
# シンボル値の引用符: なし
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False)
# シンボル値の引用符: 単一(')
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, quoting=csv.QUOTE_NONNUMERIC, quotechar="'")
# 注意事項: quoting=csv.QUOTE_NONNUMERICを指定することで、非数値の列に対しシンボル値を適用可能。quotingのデフォルト設定はquoting=csv.QUOTE_MINIMAL
# また、quoting=csv.QUOTE_ALLを指定した場合は、非数値だけでなく、全ての列に対しシンボル値を適用
# quoting=csv.QUOTE_NONNUMERICの定義を詳細に知りたい場合は、ページ最下部の参考情報よりご覧ください
# シンボル値の引用符: 二重(")
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, quoting=csv.QUOTE_NONNUMERIC, quotechar='"')
# シンボル値の引用符: その他
# ここでは例としてハイフン(-)を指定する
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, quoting=csv.QUOTE_NONNUMERIC, quotechar='-')
5.エンコード

SPSS Modeler
エンコードとしてUTF-8を指定することが可能です。
Python
SPSS Modelerのチェック項目に対応するように、Pythonで書き換えました。
# エンコード: UTF-8
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, encoding='utf-8')
# to_csvはデフォルトでencoding='utf-8'を選択するため、指定しなくてもよい
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False)
# 他にもshift-jisやcp932など、encodingの引数に指定すればよい
# エンコード: SHIFT-JIS
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, encoding='shift-jis')
# Pythonで指定可能なSHIFT-JISは'shift-jis'だけでなく、複数種類あります。詳細を知りたい場合は、ページ最下部の参考情報を参照ください。
# エンコード: CP932
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, encoding='cp932')
# エンコード: EUC-JP
df.to_csv('./output/sampletranDEPT4en2019S.csv', index=False, encoding='euc-jp')
総括
これまで言及した5点のフラットファイル・エクスポートノードの機能を網羅したPython関数を定義しました。
# 1.保存モード - 変数save_modeとinclude_fieldで設定
# save_mode: 'overwrite', 'add': 上書きするか、レコード追加するか
# include_field: 'yes', 'no': フィールド名を含めるかどうか
save_mode = 'overwrite'
include_field = 'yes'
# 2.各レコードの後に改行を入れる - 変数new_lineで設定
# new_line: 'yes' or 'no': 各レコードの後に改行を入れるかどうか
new_line = 'yes'
# 3.フィールド区切り文字 - 変数separatorで設定
# separator: 'comma', 'tab', 'space', 'other': カンマ区切りか、タブ区切りか、スペース区切りか、その他で区切るか
# separator_character: その他で区切る場合、任意の文字を指定する
separator = 'comma'
separator_character = ''
# 4.シンボル値の引用符 - 変数quotationで設定
# quotation: 'not used', 'single', 'double', 'other': 引用符を使用しないか、シングルクォーテーションを使用するか、ダブルクォーテーションを使用するか、その他を使用するか
# quotation_character: その他の文字を引用符に使用する場合、任意の文字を指定する
quotation = 'not used'
quotation_character = ''
# 5.エンコード - 変数encodingで設定
# encoding: 'utf-8', 'other': エンコーディングにUTF-8、その他のいずれを使用するか
# encoding_character: エンコーディングにその他を使用する場合、任意のものを指定する(Ex. 'shift-jis', 'cp932', 'euc-jp', etc.)
encoding = 'utf-8'
encoding_character = ''
# SPSS Modelerのフラットファイルのエクスポート機能を総括したPython関数を定義
def flat_file_export(df, output_file, save_mode, include_field, new_line, separator, separator_character, quotation, quotation_character, encoding, encoding_character):
# ライブラリの準備
import pandas as pd
import csv
# 拡張子の設定
extension = '.csv'
# 1.保存モード
if save_mode == 'overwrite':
mode = 'w'
if include_field == 'yes':
header = True
elif include_field == 'no':
header = None
elif save_mode == 'add':
header = None
mode = 'a'
# 2.各レコードの後に改行を入れる
if new_line == 'yes':
line_terminator = None
elif new_line == 'no':
if separator == 'comma':
line_terminator = ','
elif separator == 'tab':
line_terminator = '\t'
elif separator == 'space':
line_terminator = ' '
elif separator == 'other':
line_terminator = separator_character
# 3.フィールド区切り文字
if separator == 'comma':
sep = ','
elif separator == 'tab':
sep = '\t'
extension = '.tsv'
elif separator == 'space':
sep = ' '
elif separator == 'other':
sep = separator_character
# 4.シンボル値の引用符
if quotation == 'not used':
quotechar = '"'
elif quotation == 'single':
quotechar = "'"
elif quotation == 'double':
quotechar = '"'
elif quotation == 'other':
quotechar = quotation_character
# 5.エンコード
if encoding == 'utf-8':
encoding = 'utf-8'
elif encoding == 'other':
encoding = encoding_character
# 拡張子の調整
if extension == '.tsv':
output_file = output_file.replace('.csv', '.tsv')
# フラットファイルをエクスポート
df.to_csv(
output_file,
header=header,
mode=mode,
line_terminator=line_terminator,
sep=sep,
quoting=csv.QUOTE_NONNUMERIC,
quotechar=quotechar,
encoding=encoding,
index=False
)
print('フラットファイルのエクスポートを完了しました。')
サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/kitroc7134/Modeler2Python_FlatFileExport/blob/main/FlatFileExport_Validation_v0.1.str
notebook
https://github.com/kitroc7134/Modeler2Python_FlatFileExport/blob/main/FlatFileExport_Validation_v0.1.ipynb
データ
https://github.com/kitroc7134/Modeler2Python_FlatFileExport/blob/main/sampletranDEPT4en2019S.csv
■テスト環境
Modeler 18.3
Mac OS Monterey 12.4
Python 3.8.13
pandas 1.4.2
csv 1.0
参考情報
記事を書く際に、参考にしたサイトを以下に提示します。必要に応じ参照ください。
csv --- CSV ファイルの読み書き
Python♪Windowsの「Shift JIS」の落とし穴