はじめに
Windowsで動くYoloを作っていたAlexeyABさんからYolov4が公開されました。また、ほぼ同じタイミングでUbuntu20.04がリリースされたので、この記事ではUbuntu20.04でYolov4を使ったオリジナルデータの学習を行います。自分の備忘録を兼ねて記事にしておきます。これから試される方の参考になれば嬉しいです。
今回は趣味の電子工作という観点から、下記のように電子部品を検出するモデルを作ります。
図は本記事の手順で実際に学習したモデルで推論した結果になります。

アルゴリズムの詳細についてはここでは触れませんので、ぜひ論文を読んで見ることをおすすめします。
環境構築
どこのご家庭にもある(?)下記のような構成で試しています。
- ハードウェア
- Intel Corei5 8400
- DDR4メモリ24GB
- Geforce RTX2070
- Owltech SSR-650FM(400W電源ではRTX2070を動かせなかったので。。)
- ソフトウェア
- Ubuntu20.04
- CUDA10.2
- CUDNN7.6.5
- OpenCV4.3.0
Ubuntuのインストールはさておき、それ以外のソフトウェア環境についても簡単に記載しておきます。ちなみに、Ubuntu20.04は特に難しいことをしなくてもクリーンインストール時にNVIDIAドライババージョン440.64が入りました。
CUDAとCUDNNのインストール
基本的にはNVIDIA公式にある、Ubuntu18.04向けの手順に従います(NVIDIA公式では4/30現在Ubuntu18.04までの手順のため)。ただし、apt経由でインストールする方法ではCUDA10.1が入るのでこちらのサイトのようにCUDA10.2をインストールします。
また、CUDA10.2用のCUDNN7.6.5は、NVIDIA公式の手順「2.3.2. Installing From A Debian File」に従ってインストールしました。debファイルを使ったインストール方法の他にtarファイルを使った方法も紹介されていますが、どちらかで良いと思います。
(というか、自分は両方やってしまってnvccのコンパイルで”ELF section name out of range”のエラーが出て小一時間悩みました汗)
1点、Ubuntu20.04ではgcc9.3.0がインストールされるため、nvccを用いたコンパイル時にエラーが出てしまいます。動作としては保証外ではありますが、CUDAのヘッダファイル(/usr/local/cuda/include/crt/host_config.h)を書き換え、下記部分をコメントアウトしてしまいます。
//#error -- unsupported GNU version! gcc versions later than 8 are not supported!
OpenCVのインストール
こちらのサイトに書かれている手順を参考にさせていただきました。
cmakeのコマンドは下記のように設定しています。
$ CUDA_PATH="/usr/local/cuda-10.2" CFLAGS="-I/usr/local/cuda-10.2/include" LDFLAGS="-L/usr/local/cuda-10.2/lib64" \
cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=/usr/local/opencv_contrib/modules \
-D OpenBLAS_INCLUDE_DIR=/usr/include/x86_64-linux-gnu \
-D OpenBLAS_LIB=/usr/lib/x86_64-linux-gnu/libopenblas.so \
-D INSTALL_TESTS=ON \
-D INSTALL_C_EXAMPLES=ON \
-D WITH_PYTHON=ON \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D BUILD_opencv_python2=OFF \
-D BUILD_opencv_python3=ON \
-D PYTHON_DEFAULT_EXECUTABLE=python3 \
-D WITH_MKL=ON \
-D WITH_CUDA=ON \
-D CUDA_FAST_MATH=ON \
-D WITH_CUBLAS=ON \
-D WITH_CUDNN=ON \
-D WITH_NVCUVID=OFF \
-D OPENCV_DNN_CUDA=ON \
-D BUILD_opencv_cudaimgproc=ON \
-D BUILD_EXAMPLES=ON .. \
-D WITH_GTK=ON \
-D WITH_GTK3=ON \
-D WITH_V4L=ON \
-D OPENCV_GENERATE_PKGCONFIG=ON
不要なオプションもあるかもしれませんが、下記はポイントとして入れておくべしと思います。
- BUILD_opencv_python, PYTHON_DEFAULT_EXECUTABLE=python3
- PythonからOpenCVの機能を呼び出すために必要
- WITH_CUDNN, OPENCV_DNN_CUDA, BUILD_opencv_cudaimgproc
- CUDA,CUDNNを使ってOpenCVの機能を高速化
- 特に、DNNモジュールを使う場合は必須
- WITH_V4L
- Webカメラ等の機能をフルで使う場合に必要
- OPENCV_GENERATE_PKGCONFIG
- OpenCV4台からデフォルトでOFFになるため、Yoloのコンパイル時に必要です
Yolov4のコンパイル
AlexeyABさんのYolov4はこちらからcloneできます。
基本的な使い方はv3までとほぼ変わらないと思います。
特に設定をせずともcloneしたディレクトリでmakeを走らせればコンパイルできますが、下記のようにMakefileを書き換えてコンパイルしました(途中までの抜粋)。GPUとCUDNNの利用は必須だと思います。(CUDNNを有効化すると、学習が3−4割高速化できます。)
また、学習が遅くなるため特に必要がなければDEBUGは切っておいたほうが良いでしょう。
今回の実装では、Tensor Coreを使った高速化が有効にできます。ここではRTX2070を使うので、該当するARCHのコメントを外して有効化します。
GPU=1
CUDNN=1
CUDNN_HALF=1
OPENCV=1
AVX=0
OPENMP=0
LIBSO=0
ZED_CAMERA=0 # ZED SDK 3.0 and above
ZED_CAMERA_v2_8=0 # ZED SDK 2.X
# set GPU=1 and CUDNN=1 to speedup on GPU
# set CUDNN_HALF=1 to further speedup 3 x times (Mixed-precision on Tensor Cores) GPU: Volta, Xavier, Turing and higher
# set AVX=1 and OPENMP=1 to speedup on CPU (if error occurs then set AVX=0)
USE_CPP=0
DEBUG=0
#ARCH= -gencode arch=compute_30,code=sm_30 \
# -gencode arch=compute_35,code=sm_35 \
# -gencode arch=compute_50,code=[sm_50,compute_50] \
# -gencode arch=compute_52,code=[sm_52,compute_52] \
# -gencode arch=compute_61,code=[sm_61,compute_61]
OS := $(shell uname)
# Tesla V100
# ARCH= -gencode arch=compute_70,code=[sm_70,compute_70]
# GeForce RTX 2080 Ti, RTX 2080, RTX 2070, Quadro RTX 8000, Quadro RTX 6000, Quadro RTX 5000, Tesla T4, XNOR Tensor Cores
ARCH= -gencode arch=compute_75,code=[sm_75,compute_75]
動作テスト
公式リポジトリのHow to useに記載がありますが、
ビデオを推論させる場合は、こちら
$ ./darknet detector demo cfg/coco.data cfg/yolov4.cfg weights/yolov4.weights video.mp4
Webカメラから推論させる場合はこちらのようにコマンドを入力します。
$ ./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights -c 0
リポジトリに記載がある通り、RTX2070ではビデオ推論時に34fpsほど出ます。Webカメラからの推論の場合はYolov4による推論以外の要素で遅くなる可能性があります。ちなみに、ビデオやWebカメラからの推論を試す場合はOpenCVの有効化が必須です。
データセットの準備
何を思い立ったか電子基板のパーツを見分けるモデルを作ることにしましたので、インターネットから地道に画像を集めてアノテーションすることにしました。
アノテーション
VoTT2.1.0を使ってアノテーションしました。
抵抗やコンデンサのクラスを作っていったところ、総勢23クラス、193枚のデータセットができました。とても疲れた。。

今回はYolo以外のアルゴリズムでもデータセットを使えるよう、汎用性をもたせるためにPascal VOC形式での書き出しを行いました。
データセット内のタグ内訳について表示できたりするのもVoTTの良いところです。ご覧の通り今回はクラスごとの数に偏りがあります。(そして、学習が収束しない原因だったりもします。)
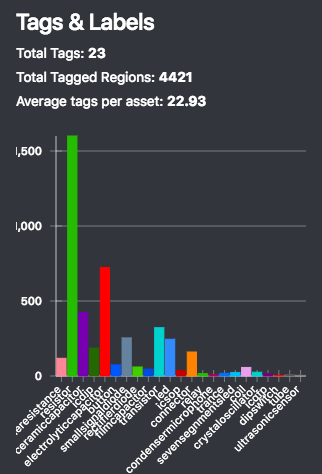
なお、今回は別途スクリプトを準備して90度・180度・270度の回転、PCA color augmentationを行って6倍に増やしています。
データセット変換
convert2Yoloのツールを利用して、Pascal VOC形式のXmlからYolo形式へ変更します。
python3 ../workspace/imagedataset-tools/convert2Yolo/example.py --datasets VOC --img_path JPEGImages/ --label Annotations/ --cls_list_file classes.name --manipast_path YoloDatasets/ --convert_output_path Labels/ --img_type ".jpg"
- --datasets
- Pascal VOCを入力するので「VOC」
- --img_path
- 画像ファイルが格納されているディレクトリ
- --label
- xml形式のアノテーションが格納されているディレクトリ
- --cls_list_file
- クラス名のリストが格納されているファイル
- --convert_output_path
- アノテーションファイルの出力先
- --img_type
- jpgファイルなので“.jpg”を指定します
オリジナルデータの学習
学習の準備
下記のようなディレクトリ構造で、先述の方法で準備したデータセットを格納します。(格納方法を変える場合は、学習実行時のコマンドで指定するディレクトリを変えます)
~/electricparts-PascalVOC-export
├── classes.name
├── YoloDatasets
│ ├── image1.jpg
│ ├── image1.txt
│ ...
│ ├── imagex.jpg
│ └── imagex.txt
├── yolo_cfg
│ ├── electricparts.data
│ └── yolov4-custom.cfg
├── backup
└── ImageSet
└── Main
├── train.txt
└── test.txt
YoloDatasetsディレクトリには、jpegファイルとそれに対応するYoloアノテーションファイル(同じファイル名)を格納します。
electricparts.dataは下記のような感じ。
classes= 23
train = /home/takuya/electricparts-PascalVOC-export/ImageSets/Main/train.txt
valid = /home/takuya/electricparts-PascalVOC-export/ImageSets/Main/test.txt
names = /home/takuya/electricparts-PascalVOC-export/classes.name
backup = /home/takuya/electricparts-PascalVOC-export/backup/
クラス数や学習時に使うデータセットリストを指定するファイル、クラス名一覧namesが記載されたファイル、学習の結果できたweightファイルを格納するbackupディレクトリを指定します。
各種パスは絶対パスで書いておきます。
train.txtは学習に用いる画像リスト、test.txtはValidationに使う画像リストです。このファイルも下記のように絶対パスで記載します。(抜粋)
/home/takuya/electricparts-PascalVOC-export/YoloDatasets/image1.jpg
/home/takuya/electricparts-PascalVOC-export/YoloDatasets/image2.jpg
configファイル
記載の方法はGithubに記載がありますが、ここではyolov4-custom.cfgをベースに実際に書き換えた項目を記載します。
- batch=64
- subdivisions=64
- batchとsubdivisionの組み合わせは学習時のGPUメモリ消費量に影響します
- 公式では16となっていましたが、RTX2070(8GB)では64まで落とす必要がありました
- subdivisionsを大きくすると消費メモリが減りますが、収束までにかかる時間が長くなります
- width=608
- height=608
- 今回は変更しませんでしたが、GPUメモリが足りない場合は縮小します
- ネットワークサイズは32の倍数で指定します
- max_batches = 46000
- 4000以上で、クラス数×2000
- steps=36800,41400
- max_batchesの80%,90%
- classes=23
- filters=84
学習の実行
下記のコマンドで学習を実行します。
darknet$ ./darknet detector train ~/electricparts-PascalVOC-export/yolo_cfg/electricparts.data ~/electricparts-PascalVOC-export/yolo_cfg/yolov4-custom.cfg weights/yolov4.conv.137
Lossのグラフが表示されるかと思います。(画像は学習途中)
きれいなLossカーブを描くことを期待していましたが5.0付近を推移しています。。Subdivisionsが大きいのと、データセットの偏りが問題なのかもしれません。
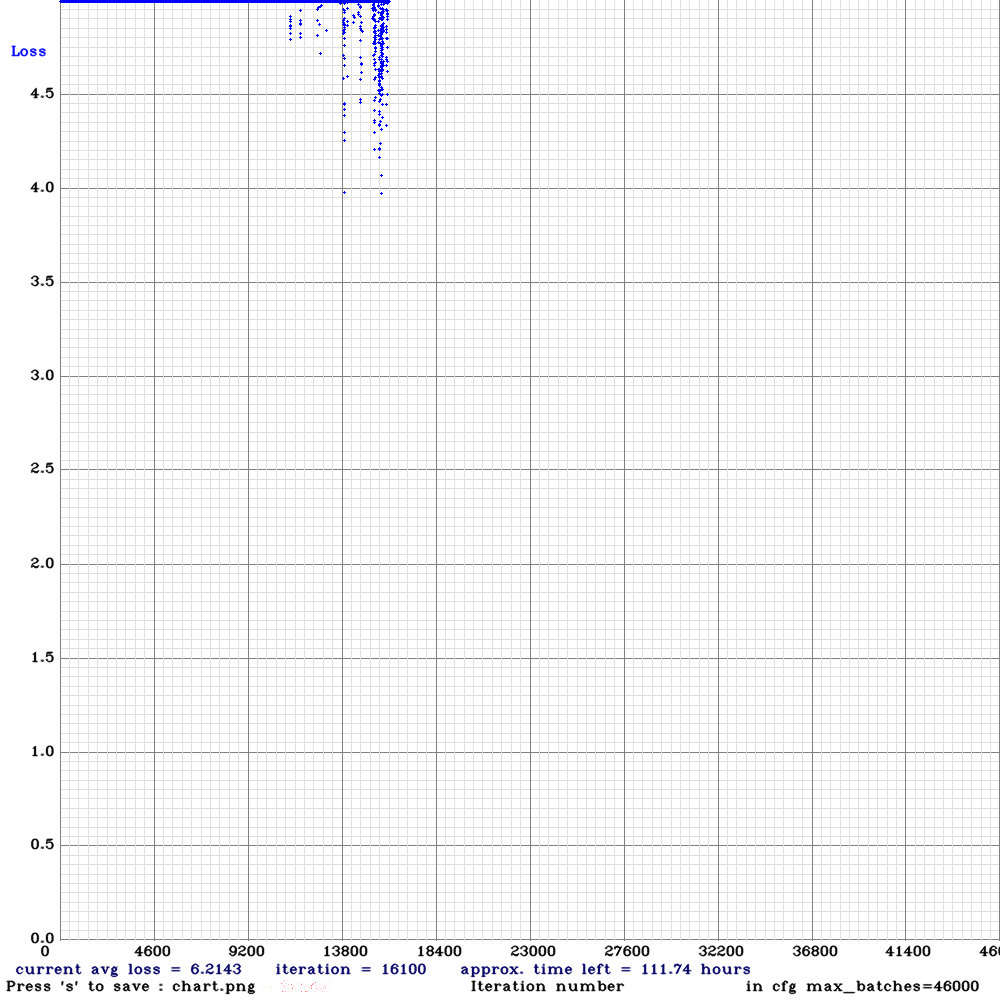
ちなみに、3000イテレーションまではTensorCoreは有効化されずに進みます。
学習がうまくいかないときは
設定ファイルなどの問題で学習が始まらなかったり、Segmentation faultで落ちてしまう事象に遭遇しました。ノウハウとして記載しておきます。
configファイル
class数やfiltersの設定はもちろんなのですが、行の途中でコメントをするとうまくいきません。例えば、下記のようなコメント記載はネットワークの読み込みすら始まらずにSegmentation faultで終了します。
max_batches = 46000 #hogehoge
CUDA Error
学習が始まると、下記のような表示がコンソールに大量に出力されるはずです。
v3 (iou loss, Normalizer: (iou: 0.07, cls: 1.00) Region 139 Avg (IOU: 0.887837, GIOU: 0.887717), Class: 0.997238, Obj: 0.987031, No Obj: 0.001221, .5R: 1.000000, .75R: 1.000000, count: 4, class_loss = 0.557072, iou_loss = 38.477901, total_loss = 39.034973
CUDA Errorが発生して学習が始まらない場合はGPUメモリ不足であることがほとんどなので、batch・subdivisionsのサイズ、ネットワークサイズを調節する必要があります。
パスの指定方法
実行ユーザやシステムの挙動のよって、~/などの指定がうまく働かない場合があります。絶対パスで指定するのが間違いないでしょう。例えば.dataやtrain.txt,test.txtなどが該当します。
bad.list
train.txtやtest.txtに指定したデータセットが読み込めない場合、実行ディレクトリ配下にbad.listとして列挙されます。このファイルにエラーが吐き出されないようにしてあげる必要があります。ちなみに、ファイル名に.が含まれていると大抵うまくいきません。
bad_label.txt
ラベル(アノテーション)ファイルに不具合があると、bad.list同様bad_label.txtに列挙されますので、エラーが吐き出されないようにする必要があります。アノテーションで指定するBoundingBoxの座標が0から1の間に収まっていない場合がほとんどです。
出来上がったモデルで推論してみる
まる2日学習を回してなお15000イテレーションくらいなのですが、ここまでで得られたweightファイルを使って推論を試してみます。weightファイルのサイズは245MBです。かなりデカイですね。
configファイルは基本的には学習時と同じものを使いますが、batch・subdivisionsは1にします。
この画像が、

こんな感じで推論されます。推論は、darknet detector demoコマンドで行います。
LED、IC、トランジスタ、電解コンデンサはバッチリ認識されています。
一方で、VRやセラコン、抵抗には精度向上の余地がありそうです。
最後に、実行時のメモリについてです。
weightファイルは245MBでしたが、推論時のGPUメモリは2.3GBでした。RTX2070で推論時間は1枚およそ30msくらいですが、GPUメモリは結構消費するのでJetsonなどの小型ボードで推論させるのはちょっと厳しいかもしれません。tinyモデルができればよいのですが。
ちなみに、推論テストに使った電子工作キットの基板は、自分が小学生のときに作ったものです。裏のはんだ付けクオリティはちょっと見せられません笑
終わりに
Ubuntu20.04のマシンにてYolov4を使って電子部品を認識させる画像認識モデルを作る方法を整理しました。どなたかの参考になれば。
今後時間が許せば、下記試してみたいと思っています。
- モデルのダウンサイジング
- 抵抗やコンデンサ容量の画像認識