はじめに
当社にアルバイトに来ていた人(来春に新卒入社の予定)に「pandasを高速化するための情報は無いですか?」と尋ねられました。
このパッケージの使い方は多数の書籍やWebで体系立った記事で書かれています。
しかし、高速化に関しては体系的な情報源が思いつかなかったので、「実際に書いてみて、1つ1つチューニングするしかないです」としか答えられませんでした。
そこで、この方を始め、来春(2019年4月)にデータアナリストまたはデータサイエンティストになる新卒へ向けて、pandasの高速化に関する私の経験をTips集にしてお伝えしたいと思います。
この記事は今後も内容を充実させるために、Tipsを追加していきます。
この記事を読んだ後にできるようになること
pandasでレコード数1000万件のデータでも1分以内で完了する前処理が書けるようになります。
その結果、1日中実行し続けなければならないような前処理を減らすことができ、分析に割く時間が増えます。
対象読者
本記事が想定している読者層は、次の3つのいずれかに該当する方々です。
- 学部生や大学院生で将来データ分析を仕事にしたい
- アルバイトやインターンとして分析案件に携わっている
- すでに企業から内定をもらっていて、アナリストまたはデータサイエンティストとして就業予定
前提にするスキル
この記事では、以下について基本的な知識があることを想定しています。
これらの使い方は本記事では説明しませんので、ご注意ください。
- python
- pandas
1. ある1つのカラムによって新しい列をDataFrameに追加したい
使用するテストデータ
テストデータはscikit-learn.datasetsのcalifornia_housingの特徴量を使います。
データの概略は以下の通りです。
データの詳細はscikit-learnのCalifornia Housing datasetを参照してください。
- サンプルサイズ:20640
- 特徴量の数:8
各特徴量の概略
| Feature | Description |
|---|---|
| MedInc | median income in block |
| HouseAge | median house age in block |
| AveRooms | average number of rooms |
| AveBedrms | average number of bedrooms |
| Population | block population |
| AveOccup | average house occupancy |
| Latitude | house block latitude |
| Longitude | house block longitude |
import pandas as pd
from sklearn.datasets import fetch_california_housing
fetched_data = fetch_california_housing()
california_housing = pd.DataFrame(
data=fetched_data['data'],
columns=fetched_data['feature_names']
)
california_housing.head(5)
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | |
|---|---|---|---|---|---|---|---|---|
| 0 | 8.3252 | 41.0 | 6.984127 | 1.023810 | 322.0 | 2.555556 | 37.88 | -122.23 |
| 1 | 8.3014 | 21.0 | 6.238137 | 0.971880 | 2401.0 | 2.109842 | 37.86 | -122.22 |
| 2 | 7.2574 | 52.0 | 8.288136 | 1.073446 | 496.0 | 2.802260 | 37.85 | -122.24 |
| 3 | 5.6431 | 52.0 | 5.817352 | 1.073059 | 558.0 | 2.547945 | 37.85 | -122.25 |
| 4 | 3.8462 | 52.0 | 6.281853 | 1.081081 | 565.0 | 2.181467 | 37.85 | -122.25 |
california_housing.describe()
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | |
|---|---|---|---|---|---|---|---|---|
| count | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 |
| mean | 3.870671 | 28.639486 | 5.429000 | 1.096675 | 1425.476744 | 3.070655 | 35.631861 | -119.569704 |
| std | 1.899822 | 12.585558 | 2.474173 | 0.473911 | 1132.462122 | 10.386050 | 2.135952 | 2.003532 |
| min | 0.499900 | 1.000000 | 0.846154 | 0.333333 | 3.000000 | 0.692308 | 32.540000 | -124.350000 |
| 25% | 2.563400 | 18.000000 | 4.440716 | 1.006079 | 787.000000 | 2.429741 | 33.930000 | -121.800000 |
| 50% | 3.534800 | 29.000000 | 5.229129 | 1.048780 | 1166.000000 | 2.818116 | 34.260000 | -118.490000 |
| 75% | 4.743250 | 37.000000 | 6.052381 | 1.099526 | 1725.000000 | 3.282261 | 37.710000 | -118.010000 |
| max | 15.000100 | 52.000000 | 141.909091 | 34.066667 | 35682.000000 | 1243.333333 | 41.950000 | -114.310000 |
ここでは、HouseAgeをyoung, middle, oldの3階級で分類した列を追加します。
youngとmiddleの分岐、middleとoldの分岐はそれぞれquantileで1/3と2/3を計算した値を使います。
california_housing.HouseAge.quantile([1/3, 2/3])
0.333333 22.0
0.666667 35.0
Name: HouseAge, dtype: float64
LOWER_SPLIT = 22.0
UPPER_SPLIT = 35.0
AGE_LABEL_YOUNG = 'young'
AGE_LABEL_MIDDLE = 'middle'
AGE_LABEL_OLD = 'old'
方法1 for文で新たな列を作る
まずはfor文で1行ずつ処理する場合を検証します。
この方法は、プログラミング初心者に多く見られる書き方です。
分かりやすいのですが、DataFrameの操作は重たいので、処理速度は遅くなります。
def method1(data):
_data = data.copy()
_data.loc[:, 'HouseAgeClass'] = None
for i in range(len(_data)):
house_age = _data.iloc[i, :]['HouseAge']
if house_age < LOWER_SPLIT:
_data.iloc[i, -1] = AGE_LABEL_YOUNG
elif LOWER_SPLIT <= house_age < UPPER_SPLIT:
_data.iloc[i, -1] = AGE_LABEL_MIDDLE
else:
_data.iloc[i, -1] = AGE_LABEL_OLD
return _data
方法2 DataFrameのスライシングで新たな列を作る
次はDataFrameのスライシングを使って新たな列を作る方法です。
Rではお馴染みな方法なので、RからPandasに乗り換えたユーザーにとっては分かりやすいのではないでしょうか?
私もPandasに乗り換えた当初はこの方法で列を作成していましたが、お世辞にも見やすいコードとは言えないので、最近はこの後で紹介するmapメソッドによる方法を使うことにしています。
def method2(data):
_data = data.copy() # 元データに影響を与えないようにする
_data.loc[(_data.HouseAge < LOWER_SPLIT), 'HouseAgeClass'] = AGE_LABEL_YOUNG
_data.loc[(_data.HouseAge >= LOWER_SPLIT) & (_data.HouseAge < UPPER_SPLIT), 'HouseAgeClass'] = AGE_LABEL_MIDDLE
_data.loc[(_data.HouseAge >= UPPER_SPLIT), 'HouseAgeClass'] = AGE_LABEL_OLD
return _data
方法3 mapメソッドを使って新たな列を作る
最後にDataFrameのmapメソッドを使って作る方法です。
ヘルパー関数(この例ではcreate_house_age_class)を定義する必要がありますが、可読性が良く、ヘルパー関数を修正するだけで分類の変更ができることが利点です。
def method3(data):
def create_house_age_class(age):
if age < LOWER_SPLIT:
return AGE_LABEL_YOUNG
elif (LOWER_SPLIT <= age) and (age < UPPER_SPLIT):
return AGE_LABEL_MIDDLE
else:
return AGE_LABEL_OLD
_data = data.copy()
_data.loc[:, 'HousingAgeClass'] = _data.HouseAge.map(create_house_age_class)
return _data
検証結果
方法1〜3を比較
方法1は2万行のデータに対して21.6秒掛かっていて、方法2と方法3はどちらも1秒未満で終わっています。
また、グラフから、方法1はサンプルサイズの増加に対して指数関数的に増加する懸念がありますので、これ以上大きなデータに対して使うことはできません。
from utilities.process_time import PandasProcessTimeMeasure
process_time_measure = PandasProcessTimeMeasure(
data=california_housing,
sample_sizes=[100, 500, 1000, 5000, 10000, 20000]
)
process_time_measure.set_method(name='method01', method=method1)
process_time_measure.set_method(name='method02', method=method2)
process_time_measure.set_method(name='method03', method=method3)
process_time_measure.measure_process_time_for_each_sample_sizes()
process_time_measure.plot_process_time()
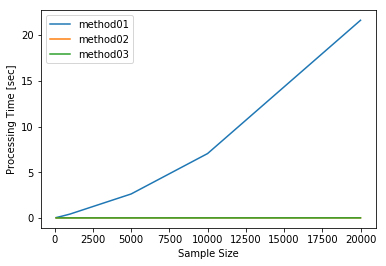
process_time_measure.process_time
| method01 | method02 | method03 | |
|---|---|---|---|
| sample_size | |||
| 100 | 0.038640 | 0.004645 | 0.000851 |
| 500 | 0.201697 | 0.004845 | 0.000944 |
| 1000 | 0.419440 | 0.004602 | 0.001031 |
| 5000 | 2.619622 | 0.005373 | 0.001831 |
| 10000 | 7.042201 | 0.006180 | 0.002811 |
| 20000 | 21.625318 | 0.008480 | 0.005633 |
方法2と方法3をより大きなデータに対して検証する
方法2と方法3について、サンプルサイズを1000万まで増やして1検証します。
大きさ1000万のデータでは、方法2は1.99秒ですが、方法3は2.31秒と方法2に対して0.31秒程度遅くなります。
一方で、サンプルサイズ1万のデータでは、逆に方法3の方が0.003秒程度速くなっているので、方法2は大きなデータを扱う場合に最適化されているようです。
data = pd.concat(objs=[california_housing]*500, axis=0)
data.reset_index(drop=True, inplace=True)
data.shape
(10320000, 8)
from utilities.process_time import PandasProcessTimeMeasure
process_time_measure = PandasProcessTimeMeasure(
data=data,
sample_sizes=[100, 500, 1000, 5000, 10000, 50000, 100000, 500000, 1000000, 5000000, 10000000]
)
process_time_measure.set_method(name='method02', method=method2)
process_time_measure.set_method(name='method03', method=method3)
process_time_measure.measure_process_time_for_each_sample_sizes()
process_time_measure.plot_process_time()
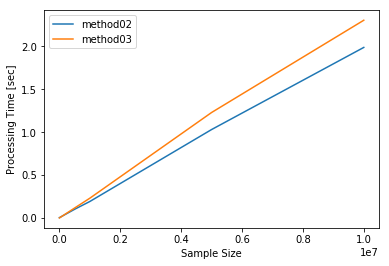
process_time_measure.process_time
| method02 | method03 | |
|---|---|---|
| sample_size | ||
| 100 | 0.004440 | 0.000823 |
| 500 | 0.004472 | 0.000891 |
| 1000 | 0.004601 | 0.000980 |
| 5000 | 0.005166 | 0.001705 |
| 10000 | 0.005774 | 0.002586 |
| 50000 | 0.013529 | 0.012015 |
| 100000 | 0.023419 | 0.023697 |
| 500000 | 0.101577 | 0.116434 |
| 1000000 | 0.192417 | 0.230766 |
| 5000000 | 1.030966 | 1.229623 |
| 10000000 | 1.988032 | 2.304879 |
まとめ
ある1つのカラムを使って新たなカラムを追加する場合の方法について検証しました。
- 方法1 for文で新たな列を作る
- 方法2 DataFrameのスライシングで新たな列を作る
- 方法3 mapメソッドを使って新たな列を作る
その結果、次の3つについて分かりました。
- 方法1は一番遅く、サンプルサイズの増加に対して、処理時間の増加幅が大きいので、大きなデータに対して使えない。
- 方法2は、3つの中で最も速かった。
- 方法3は、サンプルサイズ1000万のデータに対して、方法2より0.31秒程遅かった。
実際に使う場合は、方法3をおすすめします。
理由は、方法2とほぼ遜色ない速さで処理できて、可読性とメンテナンス性が方法2よりも高いからです。
方法2はどうしても処理能力を高めたい場合にのみ使うべきでしょう。
2. 複数のカラムで全ての組み合わせを持ったマスタを作成したい
すべての組み合わせを持ったマスタを作成する場合を検証します。
これが必要になるのは、例えば、ゲーム内のユーザー毎に各アイテムの所持数の推移を日次で見たい場合です。
ユーザーのアイテム購入数の擬似データを例にして考えていきます。
擬似データは作成スクリプトで生成し、csvファイルにgame_user_item.csvで保存しています。
スクリプトは https://github.com/Katsuya-Ishiyama/pandas_tips/blob/master/generate_data_game_user_item.py にあります。
- user_id ユーザーID
- date 日付
- item_id アイテムID
- item_name アイテム名
- item_purchase_count 該当日に該当するアイテムを購入した個数
- payment 該当日に該当するアイテムに課金した金額
from itertools import product
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
from utilities.process_time import PandasProcessTimeMeasure
plt.rcParams['font.size'] = 12
plt.rcParams['figure.figsize'] = (10, 6)
item_data = pd.read_csv('./data/game_user_item.csv')
item_data.head(5)
| user_id | date | item_id | item_name | item_purchase_count | payment | |
|---|---|---|---|---|---|---|
| 0 | 2855 | 2018-04-14 | 5 | item005 | 0 | 0 |
| 1 | 9634 | 2018-05-23 | 4 | item004 | 4 | 6000 |
| 2 | 5936 | 2018-05-28 | 10 | item010 | 0 | 0 |
| 3 | 6635 | 2018-03-08 | 9 | item009 | 2 | 3000 |
| 4 | 8864 | 2018-05-27 | 9 | item009 | 1 | 1500 |
各ユーザーともに日付が1日も欠けないように集計するためには、item_dataからユーザー、日付、アイテムの全ての組み合わせを持ったマスター(ここではmasterと呼ぶ)を作り、それにitem_dataを結合して、各ユーザー毎にアイテム獲得数の累積を計算していきます。
コードを例示すると、以下のようになります。
master = some_method(...) # 何らかの方法でマスター作成
tmp = master.merge(
right=item_get,
how='left',
on=['user_id', 'data', 'item_id', 'item_name']
)
tmp.sort_values(['user_id', 'item_id', 'data'], inplace=True)
item_owned = tmp.groupby(['user_id', 'item_id']).item_purchase_count.rolling_sum(window=2)
masterを作る処理は、全組み合わせを作成する必要があるため、かなり重たい処理になります。
ここを速度を気にせずに書いてしまうと、かなり遅い処理が出来上がってしまうので、どのような方法が良いのかを検討していきます。
def create_values(sample_size):
user_id_list = sorted(item_data.user_id.unique().tolist())
date_list = sorted(item_data.date.unique().tolist())
item_id_list = sorted(item_data.item_id.unique().tolist())
item_name_list = sorted(item_data.item_name.unique().tolist())
return user_id_list[:sample_size], date_list, item_id_list, item_name_list
方法1 1行毎にDataFrame化して.append()で積み上げる
まずは、作成した行を1回ずつDataFrameにしていく方法です。
初心者が書いてしまいがちなコードです。
def method1(sample_size):
user_id_list, date_list, item_id_list, item_name_list = create_values(sample_size)
master = pd.DataFrame()
for user_id in user_id_list:
for date in date_list:
for item_id, item_name in zip(item_id_list, item_name_list):
_master = pd.DataFrame(
data={
'user_id': [user_id],
'date': [date],
'item_id': [item_id],
'item_name': [item_name]
},
columns=['user_id', 'date', 'item_id', 'item_name']
)
master = master.append(_master)
master.reset_index(drop=True, inplace=True)
return master
method1(10).head(10)
| user_id | date | item_id | item_name | |
|---|---|---|---|---|
| 0 | 1 | 2018-01-01 | 1 | item001 |
| 1 | 1 | 2018-01-01 | 2 | item002 |
| 2 | 1 | 2018-01-01 | 3 | item003 |
| 3 | 1 | 2018-01-01 | 4 | item004 |
| 4 | 1 | 2018-01-01 | 5 | item005 |
| 5 | 1 | 2018-01-01 | 6 | item006 |
| 6 | 1 | 2018-01-01 | 7 | item007 |
| 7 | 1 | 2018-01-01 | 8 | item008 |
| 8 | 1 | 2018-01-01 | 9 | item009 |
| 9 | 1 | 2018-01-01 | 10 | item010 |
方法2 listで全組み合わせ作成後にDataFrame化する .append()バージョン
listにデータを吐き出しておいて、すべての組み合わせを作成後に一括してDataFrame化する方法です。
for文をいくつか重ねる必要がありますが、重たいDataFrameの操作を回避できるので、その分高速化が見込める方法です。
def method2(sample_size):
user_id_list, date_list, item_id_list, item_name_list = create_values(sample_size)
master_user = []
master_date = []
master_item_id = []
master_item_name = []
for user_id in user_id_list:
for date in date_list:
for item_id, item_name in zip(item_id_list, item_name_list):
master_user.append(user_id)
master_date.append(date)
master_item_id.append(item_id)
master_item_name.append(item_name)
master = pd.DataFrame(
data={
'user_id': master_user,
'date': master_date,
'item_id': master_item_id,
'item_name': master_item_name
},
columns=['user_id', 'date', 'item_id', 'item_name']
)
return master
method2(10).head(10)
| user_id | date | item_id | item_name | |
|---|---|---|---|---|
| 0 | 1 | 2018-01-01 | 1 | item001 |
| 1 | 1 | 2018-01-01 | 2 | item002 |
| 2 | 1 | 2018-01-01 | 3 | item003 |
| 3 | 1 | 2018-01-01 | 4 | item004 |
| 4 | 1 | 2018-01-01 | 5 | item005 |
| 5 | 1 | 2018-01-01 | 6 | item006 |
| 6 | 1 | 2018-01-01 | 7 | item007 |
| 7 | 1 | 2018-01-01 | 8 | item008 |
| 8 | 1 | 2018-01-01 | 9 | item009 |
| 9 | 1 | 2018-01-01 | 10 | item010 |
方法3 listで全組み合わせ作成後にDataFrame化する .extend()バージョン
こちらも方法2と同じようにすべての組み合わせを作成した後に、一括してDataFrame化する方法です。
方法2と異なる点は、appendメソッドではなくextendメソッドを使っていることです。
このようにすることでfor文を1つ減らすことができ、その分、方法2よりも高速化が見込めます。
難点としては、方法2よりも分かりづらいコードになるため、間違いを起こしやすいです。
def method3(sample_size):
user_id_list, date_list, item_id_list, item_name_list = create_values(sample_size)
master_user = []
master_date = []
master_item_id = []
master_item_name = []
n_item = len(item_id_list)
for user_id in user_id_list:
for date in date_list:
master_user.extend([user_id] * n_item)
master_date.extend([date] * n_item)
master_item_id.extend(item_id_list)
master_item_name.extend(item_name_list)
master = pd.DataFrame(
data={
'user_id': master_user,
'date': master_date,
'item_id': master_item_id,
'item_name': master_item_name
},
columns=['user_id', 'date', 'item_id', 'item_name']
)
return master
method3(10).head(10)
| user_id | date | item_id | item_name | |
|---|---|---|---|---|
| 0 | 1 | 2018-01-01 | 1 | item001 |
| 1 | 1 | 2018-01-01 | 2 | item002 |
| 2 | 1 | 2018-01-01 | 3 | item003 |
| 3 | 1 | 2018-01-01 | 4 | item004 |
| 4 | 1 | 2018-01-01 | 5 | item005 |
| 5 | 1 | 2018-01-01 | 6 | item006 |
| 6 | 1 | 2018-01-01 | 7 | item007 |
| 7 | 1 | 2018-01-01 | 8 | item008 |
| 8 | 1 | 2018-01-01 | 9 | item009 |
| 9 | 1 | 2018-01-01 | 10 | item010 |
検証結果
今回はユーザー数を変えることで総レコード数を変化させていきます。
ユーザー数と総レコード数の関係は下表の通りです。
| ユーザー数 | 日数 | アイテム数 | 総レコード数 |
|---|---|---|---|
| 10 | 365 | 10 | 36,500 |
| 20 | 365 | 10 | 73,000 |
| 30 | 365 | 10 | 109,500 |
| 50 | 365 | 10 | 182,500 |
| 100 | 365 | 10 | 365,000 |
| 500 | 365 | 10 | 1,825,000 |
| 1,000 | 365 | 10 | 3,650,000 |
| 5,000 | 365 | 10 | 18,250,000 |
| 10,000 | 365 | 10 | 36,500,000 |
ユーザー数を10, 20, 30と変化させて方法1〜3を比較
まずはユーザー数を10, 20, 30と変化させて方法1〜3を試します。
総レコード数はそれぞれ36,500、73,000、109,500となっています。
方法1は他の2つに比べてかなり遅く、ユーザー数30人で592秒(約10分)掛かっていることが分かります。
機械学習や統計を使った分析を行うサービスでユーザー数が30人しかいないことは、例え、アクティブユーザーのみに絞ったとしてもありえないでしょう。
どんなビジネスモデルなのかにも依ってユーザー数は変わりますが、それでも方法1を安易に使うことはできません。
process_time_measure = PandasProcessTimeMeasure(
sample_sizes=[10, 20, 30]
)
process_time_measure.set_method(name='method01', method=method1)
process_time_measure.set_method(name='method02', method=method2)
process_time_measure.set_method(name='method03', method=method3)
process_time_measure.measure_process_time_for_each_sample_sizes()
process_time_measure.plot_process_time()
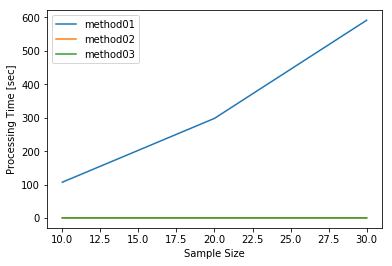
process_time_measure.process_time
| method01 | method02 | method03 | |
|---|---|---|---|
| sample_size | |||
| 10 | 107.301365 | 0.529076 | 0.516198 |
| 20 | 298.265140 | 0.532413 | 0.549056 |
| 30 | 591.759437 | 0.546038 | 0.545157 |
方法2と方法3をユーザー数を10,000まで変化させて比較
次に方法2と方法3に絞って、ユーザー数を10、50、100、500、1,000、5,000、10,000と変化させて比較検証します。
ユーザー数10,000人(レコード数36,500,000)では、方法2は15.7秒に対し方法3は11.3秒と方法3が4.4秒程速くなっています。
逆に言えば、for文を1つ減らした結果、36,500,000行の処理時間の違いはわずか4.4秒しかなかった、とも言えます。
落としたforが処理していたデータ数に依るところが大きいので、例えばアイテム数が50, 100とある場合には、方法3の有効性が増します。
アイテムのような項目はその時々によって数が増減するものなので、数が増えても処理時間の増加が小さい方法を選ぶべきでしょう。
process_time_measure = PandasProcessTimeMeasure(
sample_sizes=[10, 50, 100, 500, 1000, 5000, 10000]
)
process_time_measure.set_method(name='method02', method=method2)
process_time_measure.set_method(name='method03', method=method3)
process_time_measure.measure_process_time_for_each_sample_sizes()
process_time_measure.plot_process_time()
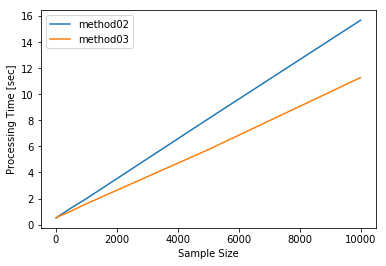
process_time_measure.process_time
| method02 | method03 | |
|---|---|---|
| sample_size | ||
| 10 | 0.519822 | 0.512880 |
| 50 | 0.572985 | 0.549018 |
| 100 | 0.664457 | 0.629464 |
| 500 | 1.275971 | 1.038292 |
| 1000 | 1.991046 | 1.598195 |
| 5000 | 8.112805 | 5.750179 |
| 10000 | 15.682714 | 11.285188 |
まとめ
ゲーム内のアイテム所持数を例に、マスターテーブルを作る方法について3パターンを検証しました。
その結果
- 方法1は他の2つの方法に比べて比較にならないほど遅く、実用的ではない
- 方法2は2番目に速く、3650万行を処理した時でも方法3に比べて4.4秒しか遅くならない
- 方法3はこの中では1番速いが、
.extend()の部分が分かりづらく、ミスしやすい
ことが分かりました。
extendメソッドの部分が分かりづらいものの、データがスケールした場合のことを考えると方法3を採用することをオススメします。
3. 複数の列を元に列を修正したい(新しい列を作りたい)
ゲーム内アイテム購入データでアイテムの単価が間違っていたので、課金額を修正したいとします。
from itertools import product
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
from utilities.process_time import PandasProcessTimeMeasure
plt.rcParams['font.size'] = 12
plt.rcParams['figure.figsize'] = (10, 6)
item_data = pd.read_csv('./data/game_user_item.csv')
item_data.head(5)
| user_id | date | item_id | item_name | item_purchase_count | payment | |
|---|---|---|---|---|---|---|
| 0 | 2855 | 2018-04-14 | 5 | item005 | 0 | 0 |
| 1 | 9634 | 2018-05-23 | 4 | item004 | 4 | 6000 |
| 2 | 5936 | 2018-05-28 | 10 | item010 | 0 | 0 |
| 3 | 6635 | 2018-03-08 | 9 | item009 | 2 | 3000 |
| 4 | 8864 | 2018-05-27 | 9 | item009 | 1 | 1500 |
間違っていたアイテムのIDと正しい単価は下記の通りです。
| 間違っていたアイテムID | 正しい単価 |
|---|---|
| 4 | 360 |
| 6 | 1000 |
| 7 | 680 |
この情報を元にitem_dataのpaymentを修正する方法について検証します。
なお、新しい列を追加する場合でも、同じ方法で処理できます。
CORRECT_PRICE_MASTER = {
4: 360,
6: 1000,
7: 680
}
def calculate_correct_payment(item_id, purchase_count, old_payment):
correct_price = CORRECT_PRICE_MASTER.get(item_id)
if correct_price is None:
return old_payment
new_payment = correct_price * purchase_count
return new_payment
方法1 for文とiterrowsメソッドで値を修正していく
def method1(data):
_data = data.copy()
new_payment_list = []
for i, row in _data.iterrows():
new_payment = calculate_correct_payment(
item_id=row.item_id,
purchase_count=row.item_purchase_count,
old_payment=row.payment
)
new_payment_list.append(new_payment)
_data.loc[:, 'payment'] = new_payment_list
return _data
method1(item_data.iloc[:100, :]).head()
| user_id | date | item_id | item_name | item_purchase_count | payment | |
|---|---|---|---|---|---|---|
| 0 | 2855 | 2018-04-14 | 5 | item005 | 0 | 0 |
| 1 | 9634 | 2018-05-23 | 4 | item004 | 4 | 1440 |
| 2 | 5936 | 2018-05-28 | 10 | item010 | 0 | 0 |
| 3 | 6635 | 2018-03-08 | 9 | item009 | 2 | 3000 |
| 4 | 8864 | 2018-05-27 | 9 | item009 | 1 | 1500 |
方法2 applyメソッドを使う
def method2(data):
_data = data.copy()
new_payment = _data.apply(
func=lambda row: calculate_correct_payment(row.item_id, row.item_purchase_count, row.payment),
axis=1
)
_data.loc[:, 'payment'] = new_payment
return _data
method2(item_data.iloc[:100, :]).head()
| user_id | date | item_id | item_name | item_purchase_count | payment | |
|---|---|---|---|---|---|---|
| 0 | 2855 | 2018-04-14 | 5 | item005 | 0 | 0 |
| 1 | 9634 | 2018-05-23 | 4 | item004 | 4 | 1440 |
| 2 | 5936 | 2018-05-28 | 10 | item010 | 0 | 0 |
| 3 | 6635 | 2018-03-08 | 9 | item009 | 2 | 3000 |
| 4 | 8864 | 2018-05-27 | 9 | item009 | 1 | 1500 |
方法3 必要な列をlistで取り出してfor文で計算する
def method3(data):
_data = data.copy()
item_id_list = _data.item_id.tolist()
item_purchase_count_list = _data.item_purchase_count.tolist()
payment_list = _data.payment.tolist()
new_payment_list = []
for item_id, purchase_count, old_payment in zip(item_id_list, item_purchase_count_list, payment_list):
new_payment = calculate_correct_payment(item_id, purchase_count, old_payment)
new_payment_list.append(new_payment)
_data.loc[:, 'payment'] = new_payment_list
return _data
method3(item_data.iloc[:100, :]).head()
| user_id | date | item_id | item_name | item_purchase_count | payment | |
|---|---|---|---|---|---|---|
| 0 | 2855 | 2018-04-14 | 5 | item005 | 0 | 0 |
| 1 | 9634 | 2018-05-23 | 4 | item004 | 4 | 1440 |
| 2 | 5936 | 2018-05-28 | 10 | item010 | 0 | 0 |
| 3 | 6635 | 2018-03-08 | 9 | item009 | 2 | 3000 |
| 4 | 8864 | 2018-05-27 | 9 | item009 | 1 | 1500 |
検証結果
方法1〜3を10万件までのデータで比較
まずは10万件までのデータで比較します。
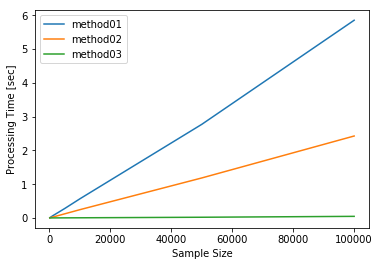
方法1は5.9秒、方法2は2.4秒掛かっていますが、方法3は0.1秒未満で終わっています。
方法1と方法2が遅いのはどちらも内部でDataFrameの操作を行なっているためですが、処理時間に2倍程度の開きが出ている原因については、今後の課題にさせてください。
process_time_measure = PandasProcessTimeMeasure(
data=item_data,
sample_sizes=[100, 500, 1000, 5000, 10000, 50000, 100000]
)
process_time_measure.set_method(name='method01', method=method1)
process_time_measure.set_method(name='method02', method=method2)
process_time_measure.set_method(name='method03', method=method3)
process_time_measure.measure_process_time_for_each_sample_sizes()
process_time_measure.plot_process_time()
process_time_measure.process_time
| method01 | method02 | method03 | |
|---|---|---|---|
| sample_size | |||
| 100 | 0.006275 | 0.002978 | 0.000399 |
| 500 | 0.029832 | 0.012977 | 0.000561 |
| 1000 | 0.060400 | 0.023462 | 0.000726 |
| 5000 | 0.279075 | 0.121582 | 0.002264 |
| 10000 | 0.567415 | 0.245067 | 0.004303 |
| 50000 | 2.773393 | 1.184637 | 0.020269 |
| 100000 | 5.856177 | 2.426971 | 0.046708 |
方法3を1000万件のデータで検証する
方法3のみ1000万件のデータに適用して、実際の処理時間を検証します。
結果は4.1秒で完了することができました。
面倒でもlistに取り出しておくと、すぐに結果を得ることができ、無駄なアイドリングタイムを減らせます。
process_time_measure = PandasProcessTimeMeasure(
data=item_data,
sample_sizes=[100, 500, 1000, 5000, 10000, 50000, 100000, 1000000, 10000000]
)
process_time_measure.set_method(name='method03', method=method3)
process_time_measure.measure_process_time_for_each_sample_sizes()
process_time_measure.plot_process_time()
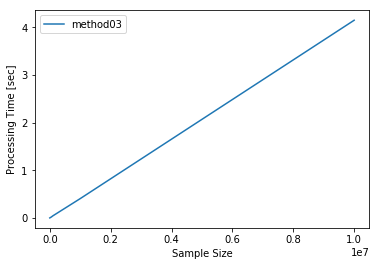
process_time_measure.process_time
| method03 | |
|---|---|
| sample_size | |
| 100 | 0.000415 |
| 500 | 0.000577 |
| 1000 | 0.000769 |
| 5000 | 0.002512 |
| 10000 | 0.004136 |
| 50000 | 0.019558 |
| 100000 | 0.043555 |
| 1000000 | 0.405703 |
| 10000000 | 4.149219 |
まとめ
ゲーム内アイテム購入データで誤った単価で課金額が計算されている場合を例にして、複数の列を元に既存の列を修正する方法について検証しました。
その結果、
- 方法1は3つの方法の中で1番遅い
- 方法2は2番目に速く、1番シンプルなコードで記述できる
- 方法3は1番速いが、必要な列をすべてlistに変換する手間が掛かる
が分かりました。
手間は掛かるものの、方法3は1,000万件のデータでも4.1秒で完了するため、繰り返し実行する可能性があるものは、この方法で実装すべきです。
Appendix
パフォーマンス計測に使ったクラスPandasProcessTimeMeasureは、この記事のシミュレーションが簡単にできるように、私が実装したものです。
コードを下に示します。
また、このコードはGitHubで随時更新する予定です。
https://github.com/Katsuya-Ishiyama/pandas_tips/blob/master/utilities/process_time.py
# -*- coding: utf-8 -*-
import logging
import sys
import timeit
from typing import Callable, List, Any
from matplotlib import pyplot as plt
from pandas import DataFrame
logger = logging.getLogger()
stdout_handler = logging.StreamHandler(sys.stdout)
logging.basicConfig(
level=logging.INFO,
handlers=[stdout_handler],
format='[%(asctime)s] %(levelname)s %(filename)s:%(funcName)s:L%(lineno)d - %(message)s'
)
class PandasProcessTimeMeasure(object):
def __init__(self, sample_sizes: List[int], data: DataFrame=None, number: int=10):
self.data = data
self.sample_sizes = sample_sizes
self.number = number
self.methods = {}
self.process_time = None
def set_method(self, name: str, method: Callable[[Any], DataFrame]):
self.methods.setdefault(name, method)
def measure_average_process_time(self, method: Callable[[Any], DataFrame], args: tuple=None, kwargs: dict=None) -> float:
if (args is None) and (kwargs is None):
def test_func():
method()
elif (args is not None) and (kwargs is None):
def test_func():
method(*args)
elif (args is None) and (kwargs is not None):
def test_func():
method(**kwargs)
else:
def test_func():
method(*args, **kwargs)
_number = self.number
logger.debug('number of iterations at timeit: {}'.format(_number))
logger.debug('start timeit')
total_process_time_sec = timeit.timeit('test_func()', globals=locals(), number=_number)
logger.debug('end timeit')
average_process_time_sec = total_process_time_sec / float(_number)
logger.debug('average process time: {} [sec]'.format(average_process_time_sec))
return average_process_time_sec
def create_sample_data(self, n: int) -> DataFrame:
return self.data.sample(n)
def measure_process_time_for_each_sample_sizes(self) -> DataFrame:
_measurement_time = {'sample_size': self.sample_sizes}
logger.debug('sample sizes: {}'.format(self.sample_sizes))
for method_name, method in self.methods.items():
logger.debug('processing method: {}'.format(method_name))
average_process_times = []
for n in self.sample_sizes:
logger.debug('loop method_name = {}, sample_size = {}'.format(method_name, n))
if self.data is not None:
logger.debug('data is supplied')
data = self.create_sample_data(n=n)
logger.debug('shape of data: {}, {}'.format(*data.shape))
_time = self.measure_average_process_time(method=method, args=(data,))
else:
logger.debug('data is not supplied')
_time = self.measure_average_process_time(method=method, args=(n,))
logger.debug('processing time: {} [sec]'.format(_time))
average_process_times.append(_time)
_measurement_time.setdefault(method_name, average_process_times)
logger.debug('_measurement_time: {}'.format(_measurement_time))
process_time = DataFrame(data=_measurement_time)
process_time.set_index('sample_size', inplace=True)
process_time.sort_index(axis=1, inplace=True)
self.process_time = process_time
def plot_process_time(self):
self.process_time.plot()
plt.xlabel('Sample Size')
plt.ylabel('Processing Time [sec]')
plt.show()
-
無理やりデータをかさ増ししています。。。後日、ゲームの例で出した疑似データに変更します。 ↩