対象読者
- Claude Code をメインで使っているが、最近 Codex も気になってきた人
- 同じプロジェクトで両ツールを行き来して、ルールや Skills を二重管理してしまっている人
- どっちかに寄せるべきか、両方使うべきか判断したい人
はじめに
私はしばらく Claude Code をメインで使ってきましたが、最近は Codex の方が高い品質のアウトプットを出すこともあり、同じプロジェクトで試す場面が増えてきました。
ただ、Claude Code の方が Codex と比較して自由度が高いと感じる場面もあります。これまで貯めてきた hooks や Skills などの資産を活かす上でも、引き続き Claude Code を使いたい場面は多いです。なので今のところ、片方に乗り換えるというより Claude Code と Codex を両方使っています。(※どちらか一方に依存しすぎるのもリスクがあるなと最近感じ始めたことも一因です。)
ただし、同じプロジェクトで両方を行き来し始めると、設定・ルール・Skills・hooks の二重管理がすぐに重くなります。あとから整理し直すのは壊しやすいので、最初に設計を決めておく 方が楽です。この記事では、そのための配置と運用ルールをまとめます。
結論
ひとことで言うと:
- 共存はできる。ただし設定ファイル形式・Skills 探索場所・hooks の書き方が全部違うので、何も考えずに両方使うと二重管理になる
- 解決策は 「共通正本 + 薄いアダプタ」。両ツールに守ってほしい情報を 1 箇所に集約し、各ツール固有の機構をその上に薄く乗せる
| 何を | 正本の置き場所 | 各ツール側 |
|---|---|---|
| プロジェクトルール | AGENTS.md |
CLAUDE.md に @AGENTS.md で import |
| Skills | ~/.agents/skills/ |
~/.claude/skills/<skill> から個別 symlink |
| Hooks | shared/hooks/<script> |
各ツールの設定からスクリプトを呼ぶ |
| Memory | 共通化しない(確定情報は AGENTS.md 側) |
ローカルリコールとしてだけ使う |
以下、それぞれの設計理由とセットアップ手順を順に説明します。
主要な違い
両ツールは「やりたいこと」は近いのに、ファイル名も置き場所も中身の形式も別々です。共存設計を考える前に、どこがどう違うかを揃えておきます。
| 観点 | Claude Code | Codex |
|---|---|---|
| プロジェクト指示 | CLAUDE.md |
AGENTS.md(階層的に読まれる) |
| ユーザー設定 | ~/.claude/settings.json |
~/.codex/config.toml |
| Skills 探索先 | ~/.claude/skills/<skill>/SKILL.md |
~/.agents/skills/<skill>/SKILL.md |
| Hooks の書き方 |
settings.json の hooks フィールド |
.codex/hooks.json |
| Memory |
~/.claude/projects/<p>/memory/(auto memory ON) |
~/.codex/memories/(デフォルト OFF) |
| ルール auto-load |
.claude/rules/ を path-match で自動ロード |
該当機構なし(明示的に読みに行く) |
ポイントは、「設定ファイルそのものは共通化できない」 ことです。形式も読み込み挙動も違うので、同じ JSON/TOML を 2 つのツールで共有することはできません。だからこそ、設定の中で 指す先のスクリプトや指示ファイル を一元化する、という戦略になります。
Memory は「便利な補助」として扱う
ここでいう Memory は、各ツールが過去の会話や作業から学習した内容を、次回以降に思い出すためのローカルな補助情報です。たとえば「このリポジトリでは pnpm を使う」「このテストは Docker が必要」といった傾向を覚えてくれるものです。
ただし、Memory はチームで共有する正本には向きません。理由はシンプルで、ツールごとに保存場所も生成タイミングも違い、ユーザーごとに中身もズレるからです。Claude Code の auto memory にだけある情報は Codex から見えませんし、Codex の memory にだけある情報も Claude Code からは見えません。
そのため、必ず守ってほしいルールやプロジェクトの確定情報は AGENTS.md に書く。Memory は「前に話したことを思い出してくれる補助」として使う。この線引きをしておくと、両ツールで挙動がズレにくくなります。
推奨ディレクトリ構成
ここまでの設計をまとめると、ファイル配置はこの形に落ち着きます。
プロジェクト側:
<project>/
AGENTS.md # 共通の基本ルール(正本)
CLAUDE.md # @AGENTS.md で import + Claude Code 固有の補足
.claude/
rules/ # Claude Code 専用の path-match ルール
settings.json # hooks / permissions など
skills/ # 共有 skill への個別 symlink + Claude 専用 skill
.codex/
config.toml # Codex のメイン設定(hooks をインラインで書く場合もここ)
hooks.json # hooks を別ファイルにする場合(任意)
rules/ # Codex のコマンド承認ポリシー
shared/
hooks/ # 両ツールから呼ぶ実スクリプト
ユーザー共通側:
~/.agents/skills/ # ユーザー共通 Skills の正本(Codex が直接読む)
~/.claude/skills/ # 共有 skill への個別 symlink + Claude 専用 skill
~/.codex/skills/ # 触らない(system skills が入っている)
ポイントは 2 つです。
-
AGENTS.mdとshared/hooks/がそれぞれ 1 正本。各ツール側のファイルはそこを指すだけのアダプタになる -
~/.agents/skills/がユーザー共通 skill の正本、~/.claude/skills/は個別 symlink でそこを参照する
これだけ守れば、ルール・skill・hook を「1 箇所だけ直せば両方に効く」状態を維持できます。プロジェクト固有の共有 skill が欲しい場合は、<project>/.agents/skills/ を作って .claude/skills/ から個別 symlink を張るという同じパターンが使えます。
セットアップ手順
Step 1. AGENTS.md と CLAUDE.md を整える
Codexからの自動移行には注意が必要
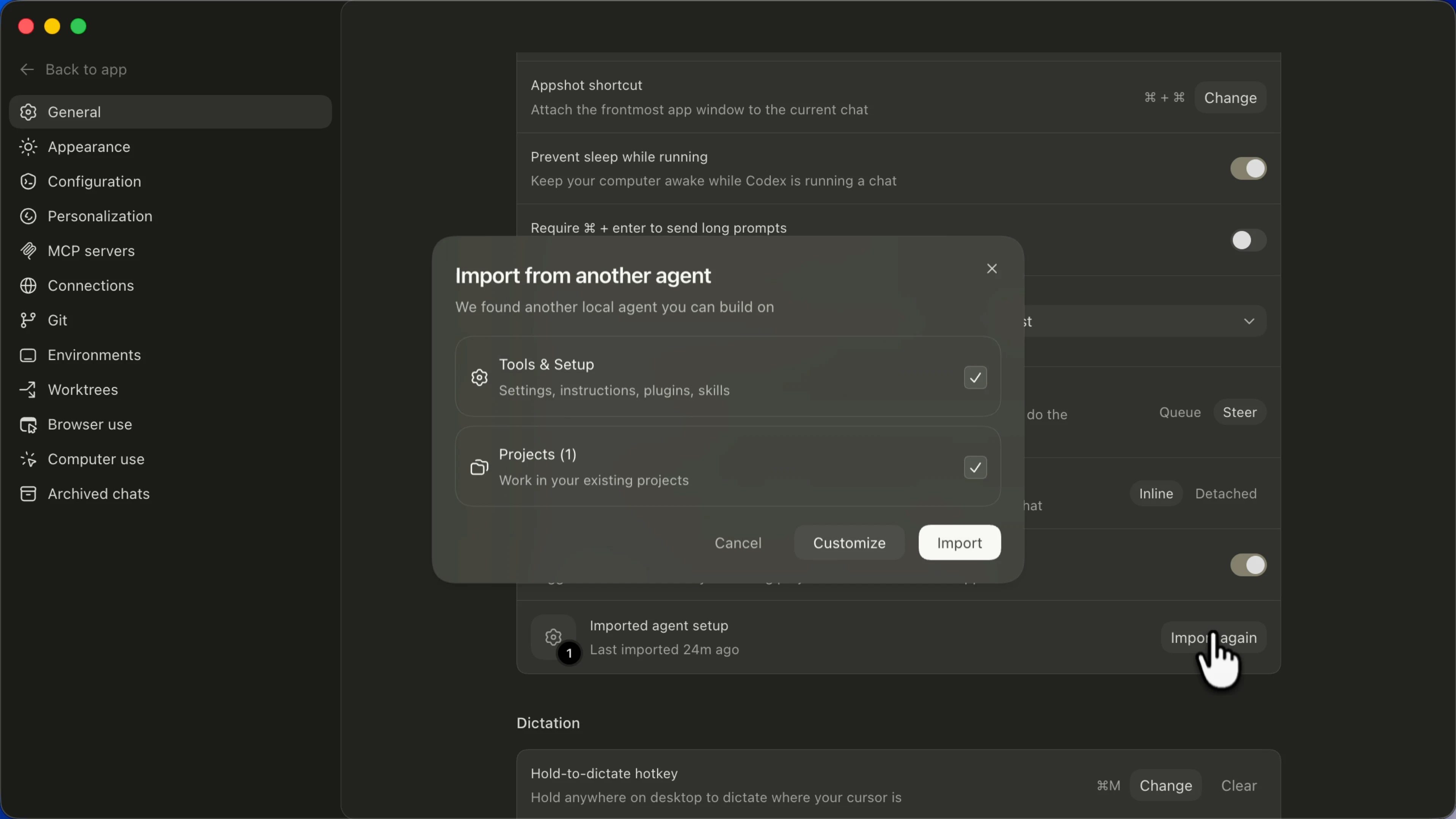
Codex App には Settings → General → Import other agent setup という機能があります。Claude Code がインストールされていると「別の local agent を見つけました」というダイアログが立ち上がり、Tools & Setup(settings / instructions / plugins / skills)と Projects を選んで Import を押すだけで、内部的に公式 skill の migrate-to-codex が走る仕組みです。
「CLI でコマンドを叩く」ではなく ダイアログ 1 クリックで自動変換が始まる ので、知らずに通すと、参照先がズレた AGENTS.md が生成されます。
自動移行は「下書き生成」。手動レビュー前提
skill の SKILL.md 自身が、変換結果を Added / Check before using / Not Added の 3 ステータスでレポートする設計です。意味が変わったもの・推測で補ったもの・未対応で落ちたものはレビュー必須と明記されています。
よくあるズレは 2 パターンあります。
-
パスの機械置換: 本文中の
.claude/rules/...のような Claude Code 固有パスが、文字列レベルで.codex/...側に書き換わる。Codex 側に同じ auto-load 機構は無いので、参照先として壊れる。 - 同名機能の非対応: MCP、hooks、subagents は名前が同じでも単位が違う。MCP の認証/環境変数、Claude 固有の hook イベント、Claude の subagent はそのまま動かないことが多い。このあたりは Zenn の Claude Code → Codex App 移行記事が具体的です。
設計方針: 「ツール非依存」と「Claude 固有」を分ける
レビューする時の判断軸は単純です。
| 内容 | 置き場所 |
|---|---|
| プロジェクト概要・フォルダ構成・両ツール共通の運用ルール | AGENTS.md |
@AGENTS.md import |
CLAUDE.md 先頭 |
.claude/rules/ の path-match auto-load 機構 |
CLAUDE.md(Claude Code 固有) |
~/.claude/projects/<p>/memory/ 経由の auto memory |
CLAUDE.md(Claude Code 固有) |
.codex/rules/ のコマンド承認ポリシー |
.codex/ 側(後の Step で扱う) |
ポイントは 「ルール」と「機構」を混ぜない こと。「画像生成は X ツールを使う」というルールは両ツール共通なので AGENTS.md に。「特定フォルダを触るとルールが自動ロードされる」という機構は Claude Code 固有なので CLAUDE.md に、という分け方です。
最小の CLAUDE.md
責務を分けると、CLAUDE.md はこの程度で済みます。
@AGENTS.md
## Claude Code 固有の補足
プロジェクトの基本ルールは `AGENTS.md` 側に集約してある。
ここには Claude Code 固有の機構だけを書く。
### path-match による rules auto-load
`.claude/rules/` 配下のルールは、対応するフォルダを操作した時に自動ロードされる。
### auto memory
`<project>/.memory/` は、Claude Code から
`~/.claude/projects/<project-slug>/memory/` 経由でアクセスする。
@AGENTS.md は Claude Code が公式サポートする import 構文で、書くだけで AGENTS.md の内容が文脈に展開されます。
AGENTS.md 先頭に「正本宣言」を入れる
将来の自分や他の AI エージェントが見たときに責務が分かるよう、AGENTS.md の先頭にこの一段落を置いておきます。
このファイル(AGENTS.md)は Claude Code・Codex など複数の AI エージェントが
共通で守るべき基本ルールを置く正本ファイル。
各ツール固有の機構(path-match auto-load、auto memory、コマンド承認ポリシー等)は、
それぞれのツール側のラッパーファイル(`CLAUDE.md`、`.codex/` 配下など)に記述する。
ダイアログには Import again ボタンが残ります。自分自身が将来また自動移行を走らせて上書きしてしまう、という事故への保険にもなります。
Step 2. ~/.agents/skills を正本にして Skills を一元化する
自動移行は skills も「コピー」で複製する
Codex App の自動移行は instruction だけでなく Skills も処理します。ただし結果は コピー で、Claude Code 側の ~/.claude/skills/<skill>/ と Codex 側の ~/.agents/skills/<skill>/ に同じ内容のディレクトリが 2 つ生まれます。
このまま運用すると、skill を 1 行直すたびに両方を編集する必要が出てきます。これを ~/.agents/skills/ を正本にして Claude Code 側は symlink にする ことで一元化します。
Codex は ~/.agents/skills/ を公式に探索パスとして読みます。Claude Code は ~/.claude/skills/ 配下の symlink を辿って skill を認識するため、symlink で繋いでも問題ありません。npx skills(skills.sh の CLI)のようなマルチエージェント前提のインストーラも、共有 skill は ~/.agents/skills/ に置く前提で動きます。
共有する skill / しない skill を選別する
すべての skill を symlink にしてはいけません。判断基準はシンプルです。
| skill の中身 | 運用 |
|---|---|
| 両ツールで同じ手順・同じツール呼び出しで完結する |
symlink で共有(~/.agents/skills/<skill> を正本) |
SKILL.md 本文に Claude Code 専用機能(allowed-tools、subagent 呼び出し等)や Codex 専用機能の記述が混ざる |
個別ファイル(両側に別実体で置く) |
| 一部の reference や script だけツール固有 | 共通部分を symlink、固有部分を個別配置(分割が手間なら個別ファイル) |
「無理して symlink にして条件分岐を増やす」より「割り切って個別ファイル」の方が、後で読みやすく壊しにくくなります。
個別 symlink の張り方
ディレクトリ全体(~/.claude/skills -> ~/.agents/skills)を symlink にする方式もありますが、Claude Code 専用の skill や追加ファイルと共存しづらいので、skill ごとに個別 symlink を推奨します。
mkdir -p ~/.agents/skills
# 共有したい skill を正本側に移動
mv ~/.claude/skills/<shared-skill> ~/.agents/skills/<shared-skill>
# Claude Code 側に symlink を張る
ln -s ~/.agents/skills/<shared-skill> ~/.claude/skills/<shared-skill>
すでに Codex 自動移行でコピーが両方にできてしまっている場合は、片方を消してから symlink を張ります。
# 中身が完全同期なら片方を削除して symlink に置き換える
diff -r ~/.claude/skills/<skill> ~/.agents/skills/<skill> && \
rm -rf ~/.claude/skills/<skill> && \
ln -s ~/.agents/skills/<skill> ~/.claude/skills/<skill>
検証
symlink が解決されているかと、Claude Code が skill を認識しているかを確認します。
# symlink が正しく張られているか
ls -la ~/.claude/skills/ | grep ^l
Claude Code 側はセッションを開いて / メニューから skill が見えるか、Codex 側は skill 一覧コマンドで見えるかで確認します。両方に同じ skill が出ていれば成功です。
Step 3. hooks を共通スクリプト化する
設定ファイルそのものは共有できない
Claude Code は .claude/settings.json の hooks フィールド、Codex は .codex/hooks.json という独立ファイルで hook を定義します。JSON 構造(PostToolUse などのイベント、matcher、command の並び)はかなり似ていますが、
- 置き場所もキー構造も別もの
- イベント名・実行タイミングは厳密には 1:1 対応しない(Claude 固有の
Notificationなど、片側にしか無いイベントもある)
ので、1 つの設定ファイルを共有することはできません。
共有するのは「スクリプト本体」だけ
実体のスクリプトを shared/hooks/<script>.sh に置き、両ツールの設定からそれを呼ぶだけにします。これでフォーマッタや lint を直すときに 1 箇所触れば済むようになります。
例として、変更された Python ファイルを ruff format で整形する hook を考えます。Claude Code の PostToolUse では Edit / Write の対象ファイルが tool_input.file_path に入るので、そのままファイルパスを取り出せます。
# shared/hooks/ruff-format-claude.sh
#!/usr/bin/env bash
set -euo pipefail
file_path="$(jq -r '.tool_input.file_path // empty')"
[[ "$file_path" == *.py ]] && ruff format "$file_path"
.claude/settings.json:
{
"hooks": {
"PostToolUse": [
{
"matcher": "Edit|Write",
"hooks": [
{ "type": "command", "command": "bash $(git rev-parse --show-toplevel)/shared/hooks/ruff-format-claude.sh" }
]
}
]
}
}
一方、Codex の file edit は apply_patch として hook に渡るため、Claude Code と同じ tool_input.file_path 前提のスクリプトにはできません。Codex 側では Stop hook で最後に差分を見て、変更済みの Python ファイルだけ整形する方が単純です。
# shared/hooks/ruff-format-changed-py.sh
#!/usr/bin/env bash
set -euo pipefail
while IFS= read -r file_path; do
[[ "$file_path" == *.py ]] && ruff format "$file_path"
done < <(git diff --name-only --diff-filter=ACMRTUXB)
.codex/hooks.json:
{
"hooks": {
"Stop": [
{
"hooks": [
{ "type": "command", "command": "bash $(git rev-parse --show-toplevel)/shared/hooks/ruff-format-changed-py.sh" }
]
}
]
}
}
設定ファイルは別物として保持し、処理の本体だけを shared/hooks/ に寄せるのがポイントです。今回の例のように、イベントや payload の差が大きい場合は、無理に 1 つの shell script にまとめず、同じ shared/hooks/ 配下でツール別に分ける方が読みやすくなります。スクリプトのパス解決は各ツールの作業ディレクトリ次第なので、git rev-parse で repo root を引くか、絶対パスを書くのが安全です。
補足: Codex は config.toml インラインでも書ける
Codex の hooks は .codex/hooks.json のほか、.codex/config.toml の [hooks] テーブルにインラインで書く方法も公式にサポートされています。同じ hook を TOML で書くとこうなります。
[features]
codex_hooks = true
[[hooks.Stop]]
[[hooks.Stop.hooks]]
type = "command"
command = 'bash "$(git rev-parse --show-toplevel)/shared/hooks/ruff-format-changed-py.sh"'
両者は機能的に等価です。公式 docs では「同じレイヤーで両方書くと Codex は merge して警告を出すので、レイヤーごとに片方に統一せよ」と明記されています。
"If a single layer contains both
hooks.jsonand inline[hooks], Codex merges them and warns at startup. Prefer one representation per layer."
選び方の目安:
-
hooks.json派: hook の数が増えた時に見通しが良い。Claude Code 側のsettings.jsonhooksフィールドとも形が揃って読み比べやすい -
config.tomlインライン派: Codex の設定をすべて 1 ファイルに集約できる。[features].codex_hooks = trueの有効化フラグと隣り合うので、有効/無効の状態を把握しやすい
なお Codex の hooks は現状 feature flag 配下([features].codex_hooks = true を入れないと動かない)です。仕様が更新される可能性は念頭に置いておくと安全です。
スクリプト側で「呼ばれ方の差」を吸収する
両ツールから同じスクリプトを呼ぶときの注意点が 2 つあります。
-
ペイロード差: stdin で渡される JSON のキー名は近いが完全一致ではない。特に Codex の file edit は
apply_patchとして渡るため、Claude Code のtool_input.file_path前提では動かない -
イベント差: Claude 固有の
Notificationのように片側にしか無いイベントは共通化せず、その hook はそのツール側に閉じておく
「全 hook を必ず 1 ファイルに共通化する」ではなく、処理の置き場所だけ shared に寄せ、ツール差がある部分は分ける という割り切りで運用すると素直に回ります。
Step 4. 動作確認
それぞれの Step が機能しているかを、雑なスモークテストで確認します。
AGENTS.md / CLAUDE.md(Step 1)
両ツールで新しいセッションを開き、AGENTS.md にしか書いていない特徴的な指示 を聞いて、同じ答えが返るか比較します。
たとえば AGENTS.md に「画像生成は X ツールを使う」と書いておき、両ツールに「画像を生成したい時、何を使う?」と質問して同じ回答が返れば、CLAUDE.md 側の @AGENTS.md import も Codex 側の AGENTS.md 読み込みも効いている、と判断できます。
Skills(Step 2)
symlink がちゃんと解決されているかをまず ls で確認。
ls -la ~/.claude/skills/ | grep '^l'
# 共有 skill の行に <skill> -> .../.agents/skills/<skill> が出ていれば OK
そのうえで、Claude Code 側で / メニュー、Codex 側で skill 一覧コマンドから、同じ skill が両方に見えているか確認します。
Hooks(Step 3)
設定が反映されているかをまずチェック。
- Codex 側:
.codex/config.tomlに[features].codex_hooks = trueが入っているか - Claude Code 側:
.claude/settings.jsonのhooksフィールドが構文的に正しく、起動時ログで認識されているか
そのうえで、共有スクリプトの先頭に動作ログを一時的に仕込みます。
# shared/hooks/<script>.sh の先頭に追加
echo "$(date '+%Y-%m-%d %H:%M:%S') hook fired" >> /tmp/hook-trace.log
両ツールから Python ファイルを 1 回ずつ編集し、/tmp/hook-trace.log に 2 行記録されればスクリプトが両方から叩かれた証拠です。確認したら echo 行は削除します。
使い分けの暫定基準
両方使えるようになると、次は「いつどっちを使うか」が課題になります。私は、モデル性能そのものよりも 既存資産・コンテキストウィンドウ・実行環境・作業の並列性 で分けています。
判断軸はこの 4 つです。
- 既存資産を使うか: Claude Code 向けに作った hooks、rules、subagent、運用手順をそのまま使いたいなら Claude Code
- 一度に読ませたい量が多いか: 大量のファイル、長いログ、複数ドキュメントをまとめて読ませる調査は、実効コンテキストウィンドウの大きい環境が有利
- 外部連携や自動実行が主役か: GitHub PR、CI/CD、定期実行、background task のように、作業の入口がチャット以外にあるなら Codex
- 同時に複数視点を走らせたいか: 別 worktree や subagent でレビュー・実装・調査を並列に進めたいなら Codex
その前提で、2026 年 5 月時点の暫定的な切り分けはこうです。
| 作業 | 優先 | 理由 |
|---|---|---|
| 既存ルールに沿った日常的な修正 | Claude Code | 既存の CLAUDE.md、.claude/rules/、hooks をそのまま活かしやすい |
| Claude Code 側に作り込んだ hooks / subagent を使う作業 | Claude Code | 移行すると hook event や payload の差で意味が変わることがある |
| 大量のファイルやドキュメントを一度に読ませる調査 | Claude Code | Opus / Sonnet の 1M context が効く場面では、長い前提を保持したまま考えさせやすい |
| GitHub PR レビュー、CI/CD からの自動実行、定期 background タスク | Codex | Codex 側に GitHub 連携・background 実行・automation まわりの導線がある |
| 別 worktree での並列実装、subagent で複数視点を当てたい時 | Codex | Codex の subagent workflow は並列調査やレビューに向いている |
| どちらでもできる小さな修正 | その時品質が良い方 | モデルやプランの状態で体感が変わるので固定しない |
コンテキストウィンドウは「モデル上限」と「実効上限」を分けて見る
コンテキストウィンドウは使い分けにかなり影響します。ここで注意したいのは、公式のモデルスペック上の上限と、実際に Claude Code / Codex CLI で使う時の上限が必ずしも同じとは限らないことです。
OpenAI の公式モデルページを見ると、2026 年 5 月時点では gpt-5.5 が 1,050,000 context window、gpt-5.3-codex などの Codex 系モデルが 400,000 context window、旧 codex-mini-latest が 200,000 context window とされています。
ただし、Codex CLI / App 経由で使う場合は、モデルの理論上限とは別に、プラン・利用モデル・セッション管理・UI 側の制約がかかる可能性があります。私の手元の Codex CLI では context window が 256K と表示されることがありました。なのでこの記事では、API モデルの公称値ではなく、実際のツール上で見えている context window を使い分けの基準にする 方針にしています。
実務上は単純で、長いログや大量のドキュメントを 1 セッションに載せたい時は、まず Claude Code / Codex のステータス表示や /model 相当の画面で実効ウィンドウを確認します。そこで Claude Code 側が 1M、Codex 側が 256K のように差があるなら、大きな読み込み調査は Claude Code に寄せる、という判断になります。
併用パターン
両方を並走させるときの定石は 3 つです。
-
確定情報は
AGENTS.mdに書く。会話の暗黙文脈に頼らない - 並列で走らせるときは
git worktreeで物理ディレクトリを分ける -
片方の調査結果をもう片方に引き継ぐときは Markdown ファイルで明示的に渡す。
/clear後でも残るし、両ツールから読める
まとめ
Claude Code と Codex は 同じプロジェクトで共存できる。ただし何も決めずに両方使うと、設定・ルール・Skills・hooks の二重管理に陥ります。最初に正本とアダプタの責務を分けておくのが大事です。
押さえるべきは 4 点:
-
ルール:
AGENTS.mdを正本に、CLAUDE.mdから@AGENTS.mdで import。Claude Code 固有の機構(path-match auto-load、auto memory)はCLAUDE.md側に逃がす -
Skills:
~/.agents/skills/を正本に、~/.claude/skills/<skill>から個別 symlink。ツール固有の記述が混ざる skill だけは symlink せず個別ファイルで持つ -
Hooks: 設定ファイルは別物のまま、
shared/hooks/<script>を両ツールから呼ぶ -
Memory: ローカルな補助記憶として割り切る。確定情報は memory ではなく
AGENTS.mdに書く
両ツールにはまだまだ機能・性能の差があります。「片方に寄せる」より「両方の強みを使い分ける」設計を入れておくと、モデルやプランが変わったときに乗り換えやすく、片方が一時的に不調でも作業が止まらない構造になります。
参考
公式 docs
Codex
- Custom instructions with AGENTS.md
- Hooks
- Advanced Configuration
- Migrate
- migrate-to-codex skill (openai/skills リポジトリ)
- GPT-5.5 model
- GPT-5.3-Codex model
- codex-mini-latest model
Claude Code