はじめに
認証や認可について調べていると、ひとつの概念を理解しようとするたびに、また別の知らない用語が出てきて、気づけば迷子になっている、そういう人は少なくないと思います。
僕自身がそうでした。OAuth 2.0を理解しようとすればJWTが出てくる。JWTを調べれば署名検証の話になる。署名検証を追えば公開鍵暗号の前提知識が要る。ひとつ調べるたびに「先にこっちを知っておくべきだった。。。」と引き返すことの繰り返しでした。
この記事では、前提知識からひとつずつ積み上げて読めるよう構成しました。
認証・認可の基本からセッション、JWT、OAuth2.0、OpenID Connect、実装パターンまで、全体像を一本の流れで整理しています。
はじめて学ぶ方の道しるべとしても、知識の整理や振り返りにも使っていただけると思います。
この記事で学べること
- 認証と認可の違いを正確に区別できるようになる
- セッションとJWT、2つの認証方式の仕組みとトレードオフを理解する
- OAuth 2.0の認可コードフローを、登場人物・リクエスト・レスポンスのレベルで追える
- OpenID ConnectがOAuth 2.0に何を追加するのかを説明できる
- アクセストークン・IDトークン・リフレッシュトークンの3つのトークンの役割を区別できる
- PKCEやDPoPといったセキュリティ拡張が「なぜ必要なのか」を理解する
- CSRF・SOP・CORSの関係を整理し、それぞれが何を守り、何を守らないのかを正確に把握する
- SPAにおける認証パターン(BFFパターン等)を、セキュリティ上のトレードオフとともに選択できる
目次
- 第0章: 前提知識
- 第1章: 認証と認可の基本
- 第2章: セッションベース認証
- 第3章: トークンベース認証
- 第4章: JWTの仕組み
- 第5章: OAuth 2.0 — 認可のフレームワーク
- 第6章: OpenID Connect — OAuth 2.0に認証を追加する
- 第7章: 3つのトークンの役割
- 第8章: IDトークンの署名検証
- 第9章: クライアントの分類と認証方式
- 第10章: アクセストークンの利用方式
- 第11章: Webセキュリティ — CSRF対策
- 第12章: Webセキュリティ — Same-Origin PolicyとCORS
- 第13章: SPAにおける認証パターン
- 第14章: 全体のまとめ
- 参考リンク
- 用語集
第0章: 前提知識
この記事では、認可・認証の説明の中で「ハッシュ化」「署名」「Cookie」といった用語が逐一登場します。
これらの理解が曖昧なまま本編に入ると途中で詰まるので、ここでは土台になる概念を先に整理しておきます。
すでに理解している方は第1章まで読み飛ばしてください。
エンコード・暗号化・ハッシュ化・署名
まずは、これら4つの概念の意味と目的を解説します。認可・認証の文脈ではどれも頻繁に登場するので、先に違いをはっきりさせておきます。
エンコード: 形式の変換
エンコードとは、データの形式を別の形式に変換することです。秘匿の目的はなく、誰でも元に戻すことができます。
逆に、エンコードされたデータを元の形式に戻すことをデコードと呼びます。
元のデータ: {"sub":"user_123"}
↓ Base64 エンコード
結果: eyJzdWIiOiJ1c2VyXzEyMyJ9
↓ Base64 デコード
元に戻る: {"sub":"user_123"}
後の章で登場するJWT(JSON Web Token)のヘッダーやペイロードはBase64URLエンコードされているだけなので、誰でもデコードして中身を読めます。
「JWTは暗号化されているから安全」という誤解をときどき見かけますが、エンコードと暗号化は全くの別物です。
補足: Base64とBase64URL
Base64は、バイナリデータ(画像や圧縮データなど)をA-Z, a-z, 0-9, +, /の64種類の文字だけで表現するエンコード方式です。メールやJSONなど、バイナリをそのまま扱えない場面でよく使われます。
Base64URLはBase64の亜種で、+ を - に、/ を _ に置き換えたものです。URLやファイル名に含めても問題が起きないように設計されており、JWTではBase64ではなくこちらが使われています。
ハッシュ化: 一方向の変換
ハッシュ化とは、データを固定長の文字列に変換することです。
最大の特徴は、もとに戻せない不可逆性です。
ハッシュ化は、一方通行の処理であり、出力されたハッシュ値から入力データを復元する方法は原理的にありません。
また、ハッシュ化の処理を行うアルゴリズムをハッシュ関数と呼び、代表的なものにSHA-256(Secure Hash Algorithm 256-bit)があります。SHA-256は入力データの長さに関係なく、常に256ビット(64文字の16進数)のハッシュ値を出力します。
入力: "password123"
↓ SHA-256 でハッシュ化
結果: ef92b778bafe771e89245b89ecbc08a44a4e166c06659911881f383d4473e94f
↓ 元に戻す?
❌ 不可能
ハッシュ化には2つの重要な性質があります。
- 同じ入力からは常に同じハッシュ値が得られる → パスワードの照合に使えます。(平文を保存せずハッシュ値を保存する)
- 入力が1文字でも変わるとハッシュ値が全く異なる → データの改ざん検知に使えます。
後者の性質が、このあと説明する「署名」の基盤になっています。
暗号化: 秘匿が目的
暗号化とは、鍵を使ってデータを読めない形に変換し、正しい鍵を持つ人だけがもとに戻せるようにすることです。
暗号化には2つの方式があります。
共通鍵暗号方式: 鍵は1つ。送信者と受信者が同じ鍵を共有します。
送信者 ── [共通鍵で暗号化] ──→ 暗号文 ── [共通鍵で復号] ──→ 受信者
公開鍵暗号方式: 鍵は2つ(公開鍵と秘密鍵)。公開鍵は誰に見せても良いですが、秘密鍵は本人だけが持ちます。
送信者 ── [受信者の公開鍵で暗号化] ──→ 暗号文 ── [受信者の秘密鍵で復号] ──→ 受信者

もう少し詳しく説明します。
公開鍵暗号方式では、公開鍵と秘密鍵という2つの鍵がペアになって機能します。この2つの鍵は数学的に関連づけられていて、片方で処理したデータはもう片方でしかもとに戻せないという性質を持っています。
- 公開鍵は暗号化に使います。名前の通り、外部に公開して構いません。誰でも持つことができます。
- 秘密鍵は復号に使います。鍵のペアを作った本人だけが持ち、絶対に他者に渡してはいけません。
- 公開鍵で暗号化したデータは、対応する秘密鍵でしか復号できません。公開鍵自身では復号できません。
例えるなら、公開鍵は「誰でもコピーできる南京錠」、秘密鍵は「その南京錠を開けられる唯一の鍵」です。誰でも南京錠をかけて箱を閉じることはできますが、中身を取り出せるのは鍵を持っている本人だけです。
この公開鍵と秘密鍵の役割が逆転するのが、次に説明する署名の仕組みです。
署名: 改ざん検知 + 発行者の証明
署名は、ハッシュ化と秘密鍵による署名操作を組み合わせた仕組みです。
「このデータは確かに発行者が作成したもので、途中で改ざんされていない」ことを証明できます。
署名の生成(発行者が行う):
データ ──→ ハッシュ化 ──→ ハッシュ値 ──→ 秘密鍵で署名 ──→ 署名
署名の検証(検証者が行う):
データ ──→ ハッシュ化 ──→ ハッシュ値(A) ─┐
├─→ A == B ? → 改ざんなし ✅
署名 ──→ 公開鍵で検証 ──→ ハッシュ値(B) ─┘
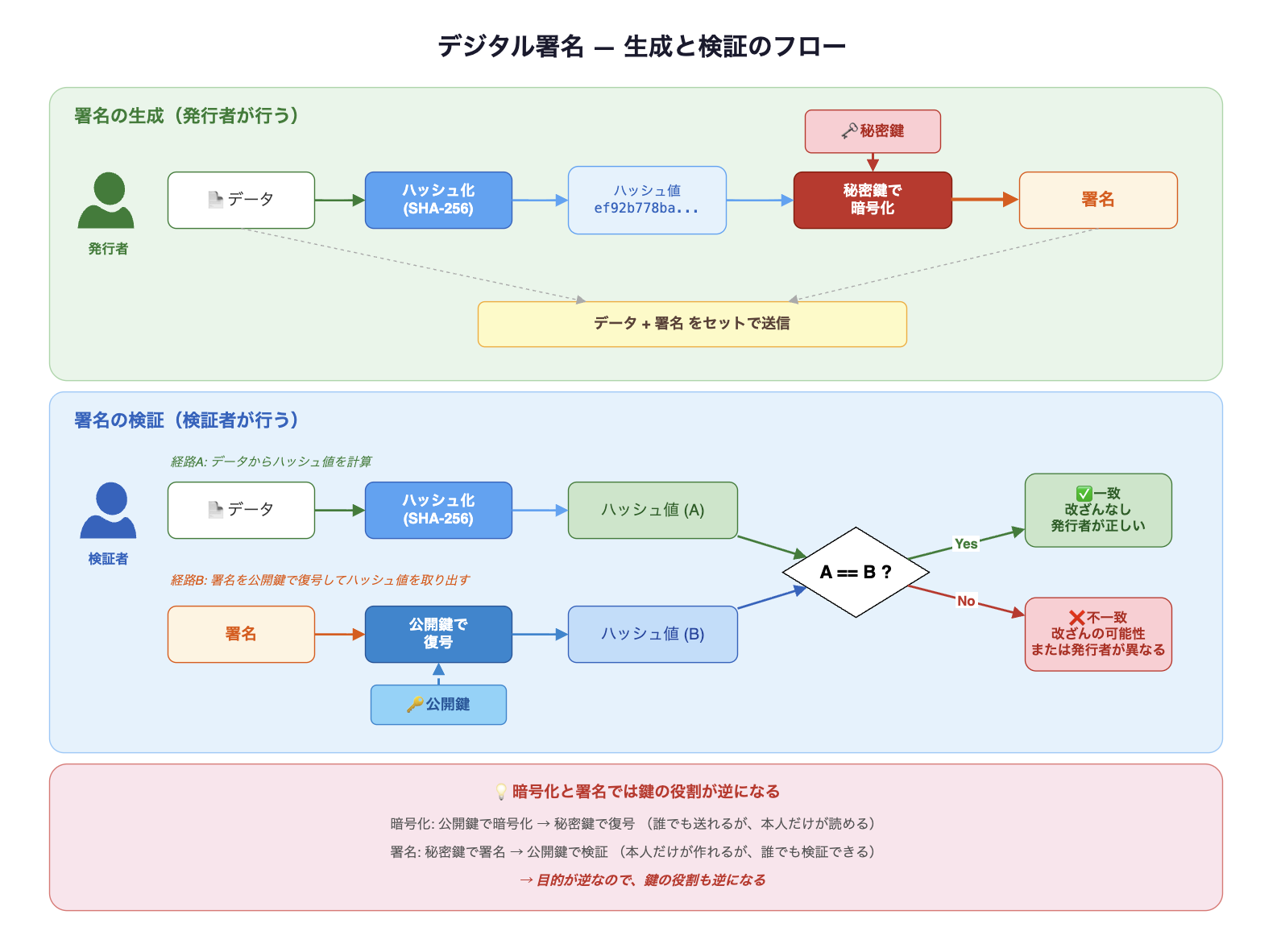
ここで注意が必要なのは、暗号化の文脈と鍵の使い方が逆になっている点です。
| 暗号化 | 署名 | |
|---|---|---|
| 公開鍵の役割 | 暗号化する | 検証する |
| 秘密鍵の役割 | 復号する | 署名する |
最初はややこしく感じますが、それぞれの目的から考えると整理できます。
- 暗号化の目的は「本人だけが読めるようにする」こと。だから、誰でも暗号化できて(公開鍵)、本人だけが復号できる(秘密鍵)
- 署名の目的は「本人が作ったことを証明する」こと。だから、本人だけが署名できて(秘密鍵)、誰でも検証できる(公開鍵)
僕自身、ここが最初なかなか腑に落ちなかったのですが、「暗号化は受け取る側を守るもの、署名は送る側を証明するもの」と考えるとスッキリしました。
この署名の仕組みは、JWTの構造(第4章)とIDトークンの署名検証(第8章)で中心的な役割を果たします。
4つの比較まとめ
| エンコード | 暗号化 | ハッシュ化 | 署名 | |
|---|---|---|---|---|
| 目的 | 形式の変換 | 秘匿 | データの検証(パスワード照合、改ざん検知など) | 改ざん検知 + 発行者の証明 |
| 元に戻せるか | 誰でも戻せる | 鍵を持つ人だけ | 戻せない | — |
| 鍵が必要か | 不要 | 必要 | 不要 | 必要(署名に秘密鍵、検証に公開鍵) |
| 例 | Base64, URL エンコード | AES, RSA | SHA-256, SHA-512 | RS256, ES256 |
補足: 表中のアルゴリズムについて
- AES(Advanced Encryption Standard): 共通鍵暗号方式の代表的なアルゴリズムです
- RSA: 公開鍵暗号方式の代表的なアルゴリズムです。暗号化にも署名にも使えます
- RS256: RSAを使った署名アルゴリズムで、ハッシュ関数にSHA-256を組み合わせたものです。JWTの署名方式として広く使われています
- ES256: 楕円曲線暗号(ECDSA)を使った署名アルゴリズムです。RS256 より鍵が短く高速なため、近年採用が増えています
後の章で登場したときに「署名のアルゴリズムのことだな」とわかれば、今の時点ではそれで十分です。
Cookieの基礎
Cookieはブラウザとサーバーの間で小さなデータをやり取りするための仕組みです。この後のセッション認証(第2章)とCSRF対策(第11章)を理解するために欠かせない前提知識になります。
Cookieのライフサイクル
Cookieの動きは3ステップで理解できます。
1. サーバーがCookieを発行する
HTTP/1.1 200 OK
Set-Cookie: session_id=abc123; HttpOnly; Secure; SameSite=Lax
2. ブラウザがCookieを保存する(ユーザーの操作なしに自動で行われる)
3. 以降のリクエストでブラウザが自動的にCookieを送信する
GET /dashboard HTTP/1.1
Cookie: session_id=abc123
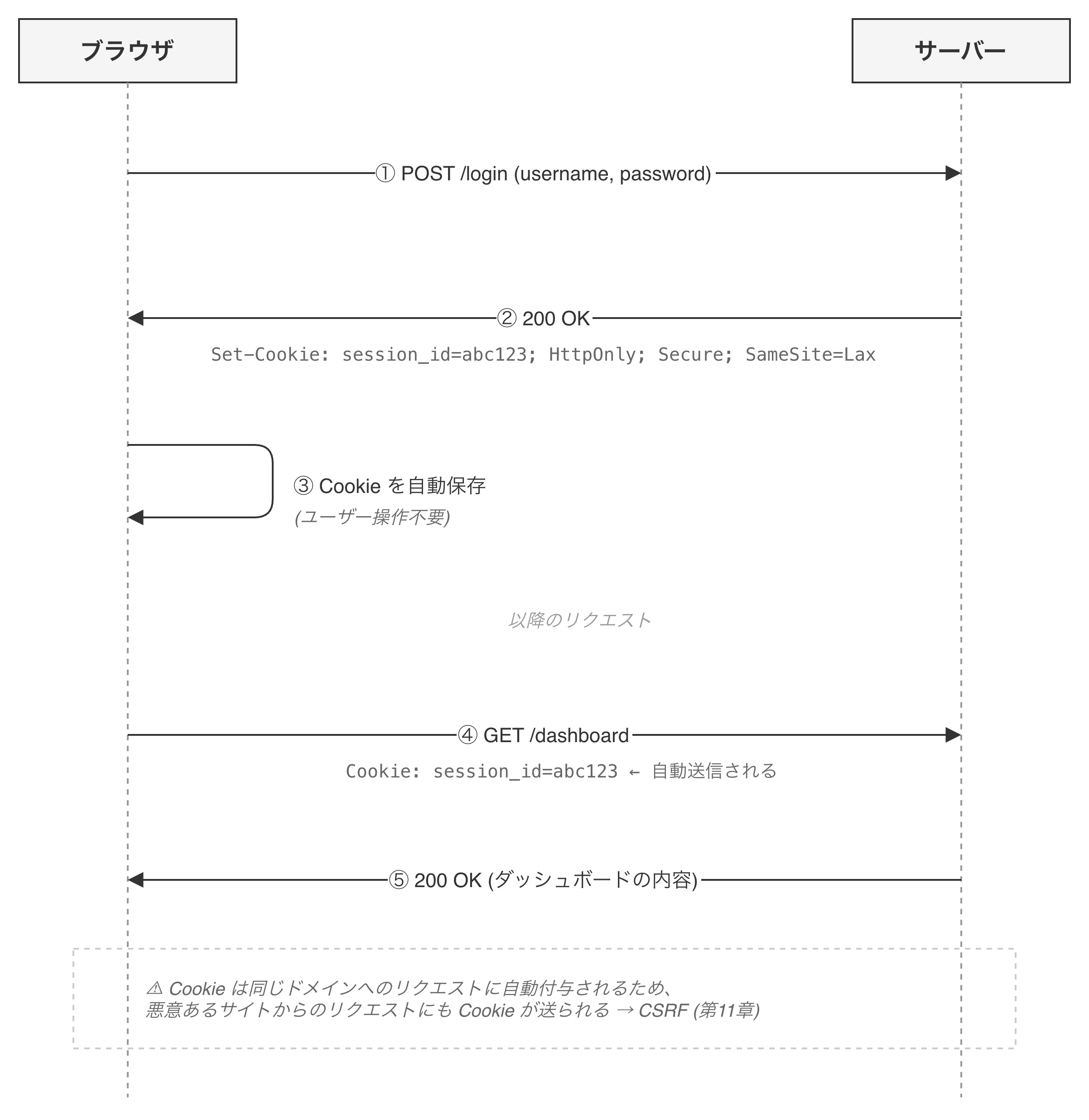
ここで押さえておきたいのは、「2. ブラウザがCookieを保存する」、「3. 以降のリクエストでブラウザが自動的にCookieを送信する」という点です。この性質がセッション認証(第2章)を便利にしている一方、CSRF攻撃(第11章)の原因にもなります。
Cookieの主要な属性
Cookieにはいくつかのセキュリティ関連の属性があります。ここでは概要だけ押さえておきます。
なお、表中に登場するXSS(Cross-Site Scripting)は、攻撃者が悪意のあるJavaScriptをWebページに埋め込み、他のユーザーのブラウザ上で実行させる攻撃手法です。ここでは「JavaScriptを使ってCookieの中身を盗み取る攻撃がある」とだけ理解しておけば大丈夫です。
| 属性 | 何を制御するか | ひとことで言うと |
|---|---|---|
| HttpOnly | JavaScript からのアクセス | XSS でトークンを盗まれるリスクを軽減する |
| Secure | 通信プロトコル | HTTPS のときだけ Cookie を送信する |
| SameSite | クロスサイトリクエスト | 別サイトからのリクエスト時に Cookie を送るかどうかを制御する(Strict / Lax / None) |
| Domain | 送信先のドメイン範囲 | どのドメインに Cookie を送るかを指定する |
| Path | 送信先のパス範囲 | どのパスに Cookie を送るかを指定する |
| Max-Age / Expires | 有効期限 | Cookie がいつまで有効かを設定する |
ステートフルとステートレス
最後に、サーバーが「クライアントの状態を覚えているか」を表す2つの概念を押さえておきます。
ステートフル: サーバーがクライアントの状態を保持する方式
サーバーは「このリクエストを送ってきたのは田中さんで、さっきカートに商品Aを入れた」という情報を自分の側で覚えています。
第2章で説明するセッション認証はこの方式にあたります。
ステートレス: サーバーがクライアントの状態を保持しない方式
サーバーは前のリクエストのことを一切覚えていません。毎回のリクエストが完全に独立しており、クライアントが必要な情報(トークンなど)をリクエストのたびに持ってきます。
第3章で説明するトークンベース認証はこの方式にあたります。

なぜ、Webの文脈でこの区別が重要かというと、スケーラビリティに直結するからです。
サーバーを1台から複数台に増やすことを想像してみてください。ステートフルな場合、ユーザーの状態をどのサーバーでも参照できるように共有する仕組みが必要になります。一方、ステートレスならクライアントが毎回すべての情報を持ってくるため、どのサーバーがリクエストを受けても独立して処理できます。
この違いが、セッション認証とトークン認証それぞれのメリット・デメリットに直結します。詳しくは第2章・第3章で説明します。
参考リンク
- RFC 7515 — JSON Web Signature (JWS) - 署名アルゴリズム(RS256, ES256等)の仕様
- MDN — HTTP Cookie の使用 - Cookieの仕組みと属性の解説
第1章: 認証と認可の基本
ここからが本編です。まずは記事全体の土台となる「認証」と「認可」の区別から。
この2つは日常会話では特に区別なく使われがちですし、英語でもAuthenticationとAuthorizationで綴りが似ています。僕自身、最初は大体同じようなものだと思ってしまっていましたが、この区別が曖昧なまま進むと、OAuth2.0やOpenID Connectの役割分担が理解できなくなります。
この章で区別をつけます。
認証(Authentication)とは
認証とは、「あなたは誰ですか?」を確認するプロセスです。
日常生活でいえば、空港でパスポートを見せて「私は田中です」と身元を証明する行為が認証にあたります。Webアプリケーションにおいては、メールアドレスとパスワードを入力してログインすることがもっとも身近な認証の例です。
では、「あなたは確かに本人です」と判断するために、何を根拠にしているのでしょうか。認証の根拠は大きく3つの要素に分類されます。
| 要素 | 説明 | 例 |
|---|---|---|
| 知識要素 | 本人だけが知っていること | パスワード、PINコード、秘密の質問 |
| 所持要素 | 本人だけが持っているもの | スマホ(SMS認証)、秘密鍵、ハードウェアキー |
| 生体要素 | 本人の身体的特徴 | 指紋、顔認証、虹彩 |
パスワードだけのログインは「知識要素」の1つだけに頼っています。もしパスワードが漏洩すれば、それだけで突破されてしまいます。
そこで、2つ以上の要素を組み合わせることで安全性を高める方法があります。これを多要素認証(MFA: Multi-Factor Authentication)と呼びます。例えば、パスワード(知識要素)を入力した後に、スマートフォンに届いた確認コード(所持要素)を入力する、といった方式です。
認可(Authorization)とは
認可とは、「あなたは何ができますか?」を決めるプロセスです。
日常生活でいえば、社員証でオフィスに入れるけど、サーバールームには入れない、というアクセス制御が認可にあたります。Webアプリケーションでは、一般ユーザーは自分のデータだけ閲覧でき、管理者は全ユーザーのデータを閲覧・編集できる、といったルールが認可です。
認証が「あなたは誰か」を確認するのに対し、認可は「その人に何を許可するか」を決めるものです。似ているようで、扱っている問題が全く異なります。
認証と認可の関係
この2つには明確な順序があります。認証が先で、認可はその後です。
「誰なのか」がわからなければ、「何ができるか」を判断しようがありません。例えば、社員証を見せずにオフィスに入ろうとしても、そもそも「あなたは社員ですか?」が確認できないので、サーバールームに入れるかどうか以前の問題です。
| 認証(Authentication) | 認可(Authorization) | |
|---|---|---|
| 問い | あなたは誰か? | あなたは何ができるか? |
| タイミング | 先に行う | 認証の後に行う |
| 例 | ログイン画面で ID/パスワードを入力 | 管理者だけが設定画面にアクセス可能 |
| 失敗時 | 401 Unauthorized | 403 Forbidden |
補足: HTTPステータスコードの紛らわしい命名
認証に失敗すると401 Unauthorized、認可に失敗すると403 Forbiddenが返されます。
ここで、「あれ?」と思う方もいるかもしれません。401の名前がUnauthorized(未認可)なので、認可の失敗と混同しそうになります。しかし実際には、401は「認証されていない(=ログインしていない)」ことを意味します。
HTTPの仕様が策定された際の命名が紛らわしいだけなので401は「未認証」、403は「未認可」と覚えてしまいましょう。
この区別が、第5章のOAuth 2.0と第6章のOpenID Connectで効いてきます。
次は、Webでもっとも古くから使われてきた認証方式、セッションベース認証に入ります。
参考リンク
- RFC 7235 — HTTP Authentication - 401/403ステータスコードの定義
第2章: セッションベース認証
認証は「あなたは誰ですか?」を確認するプロセスでした。では、確認した結果をどう覚えておくのか。ページ遷移のたびにパスワードを入力するわけにはいきません。
ここでは、Webでもっとも古くから使われてきた「ログイン状態を維持する仕組み」、セッションベース認証を取り上げます。
HTTPはステートレス
まず前提として、HTTPは本来ステートレスなプロトコルです。第0章で触れた通り、リクエストごとに独立しており、サーバーは前のリクエストの情報を覚えていません。
リクエスト1: ログインに成功した
リクエスト2: ← この人はさっきログインした人?新しい人?というようにサーバーは区別がつきません。
しかし実際のWebアプリケーションでは、「ログイン状態を維持する」「カートの中身を覚えている」など、複数のリクエストを跨いで状態を保持する必要があります。
ステートレスなHTTPの上で、どうやって状態を維持するのか。その答えの一つが「セッション」です。
セッションとは
セッションとは、ステートレスなHTTPの上に、状態を持った一連のやり取りを作り出す仕組みのことです。
ただし、「セッション」という言葉は文脈によって2つの異なる意味で使われるので注意が必要です。
| 概念としてのセッション | 実装としてのセッション | |
|---|---|---|
| 意味 | ユーザーとサーバーの一連のやり取りの期間 | その期間中に維持したい状態データのこと |
| たとえるなら | 「ログインからログアウトまで」というはじめから終わりまでの期間そのもの | その期間中にサーバーが覚えておく中身 |
| 例 | - | user_id, role, カートの中身、CSRFトークンなど |
| 保存場所 | - | Redis, データベース, メモリ, ファイルなど |
「セッションが切れた」と言うときは前者の意味で、「セッションにuser_idを保存する」と言うときは、後者の意味です。どちらの意味で使われているかは文脈から判断する必要がありますが、混同しやすいポイントなので意識しておくとよいでしょう。
セッションベース認証の流れ
セッションを使った認証の具体的な流れを追ってみます。登場人物は3つです。
- ブラウザ: ユーザーが操作する側
- サーバー: リクエストを処理するアプリケーション
- セッションストア: セッションデータを保存する場所(Redisやデータベース、メモリ、ファイルなど)
ログイン時の流れ

- ユーザーがメールアドレスとパスワードを送信
- サーバーが資格情報を確認(メールアドレスとパスワードの組み合わせが正しいか確認)し、認証OKであれば、セッションID(推測困難なランダム文字列)を生成する
- セッションIDをキーにして、ユーザー情報(user_idやroleなど)をセッションストアに保存する
- セッションIDを
Set-Cookieヘッダーでブラウザに返す
ログイン後の流れ
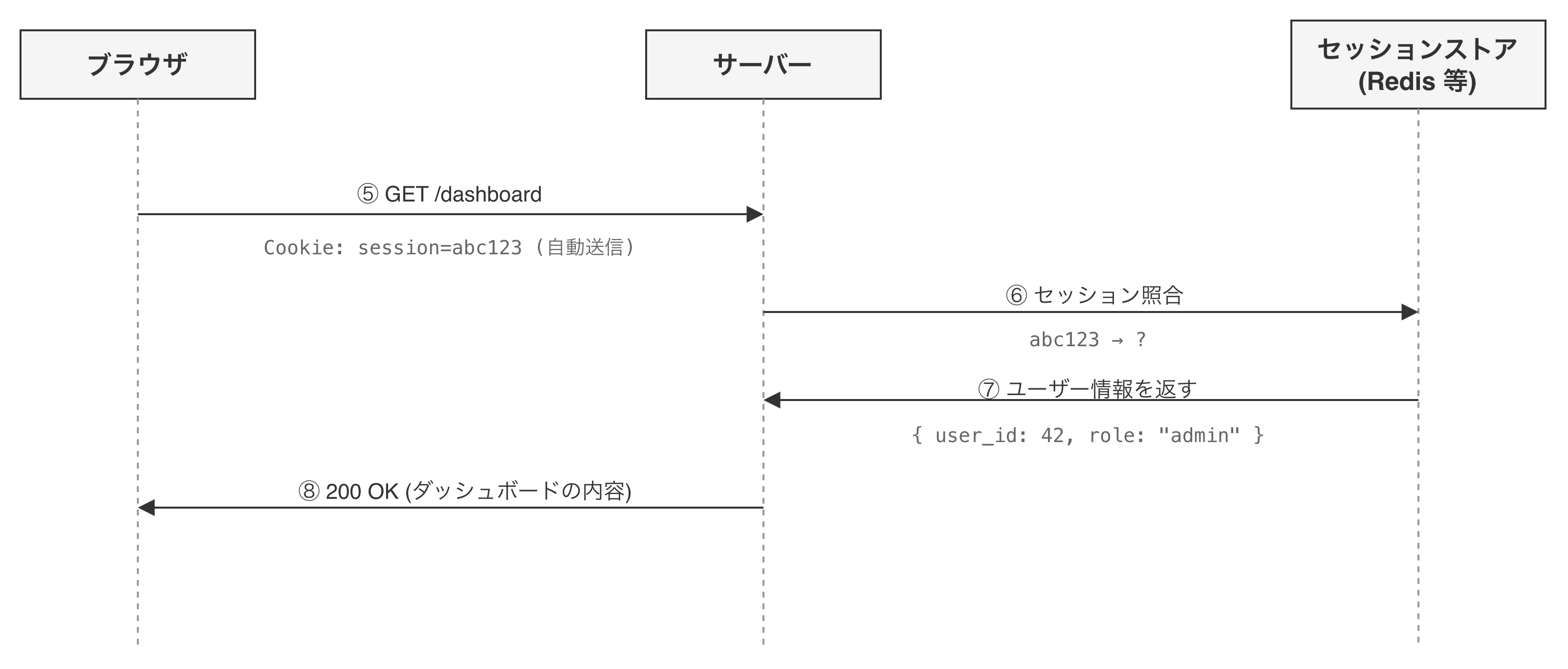
- ブラウザは以降のリクエストでCookieを自動的に送信する
- サーバーは受け取ったセッションIDでセッションストアを照合し、ユーザーを特定する
ここで重要なのは、ブラウザが持っているのはセッションIDだけという点です。ユーザー情報そのものはサーバー側のセッションストアに保存されており、ブラウザには渡されていません。セッションIDは、「ロッカーの鍵」のようなもので、鍵自体には中身の情報は含まれていませんが、正しいロッカーを開けるための手掛かりとなります。
メリットとデメリット
セッションベース認証には以下のメリットとデメリットがあります。
メリット
- 即座に無効化できる: サーバー側でセッションを管理しているため、ログアウト時やアカウント停止時にセッションストアからデータを削除すれば、その時点でセッションは無効になります。
- ブラウザ側に機密情報を持たない: ユーザー情報はサーバー側に保存されており、ブラウザが持つのはセッションIDだけです。
-
Cookieのセキュリティ属性が使える:
HttpOnly属性をつければ、JavaScriptからCookieの内容をアクセスできなくなるので、XSS(クロスサイトスクリプティング)によるセッションIDの窃取リスクを軽減できます。
デメリット
- ステートフルである: サーバーがセッションストアに状態を保持するため、サーバーを複数台に増やす(スケールアウト)する場合、すべてのサーバーからアクセスできる共有のセッションストア(Redisなど)が必要になります。
- モバイルアプリやSPAとの相性: Cookieはブラウザの仕組みに依存しているため、モバイルアプリのようなブラウザ以外のクライアントでは扱いにくい場面があります
- マイクロサービスとの相性: 複数のサービスが連携するアーキテクチャでは、サービス間でセッションストアを共有する必要が出てきますが、これはサービスの独立性を損なう原因になります。
これらの課題を解決するアプローチとなるのが、次の章で説明する「トークンベース認証」です。
参考リンク
- RFC 6265 — HTTP State Management Mechanism - Cookieの仕様
- Redis — Session Store - Redisをセッションストアとして使う例
第3章: トークンベース認証
セッションベース認証には、サーバーが状態を保つ(ステートフル)ことに起因する課題がありました。スケールアウト時のセッション共有や、モバイルアプリとの相性の問題です。
この章では、その課題へのアプローチとなる「トークンベース認証」を扱います。
基本的な考え方
トークン認証の発想はシンプルです。
セッション認証では、サーバーがユーザー情報をセッションストアに保存し、ブラウザには「ロッカーの鍵」であるセッションIDだけを渡していました。リクエストのたびにサーバーがセッションストアを参照して、「この鍵はどのロッカーのものか」を確認する必要がありました。
トークンベース認証では、ユーザー情報そのものを署名付きのトークンに含めてクライアントに渡し、サーバーは何も保存しません。リクエストを受けたサーバーは、トークンの署名を検証するだけでユーザーを特定できます。
トークンベース認証の流れ
ログイン時の流れ
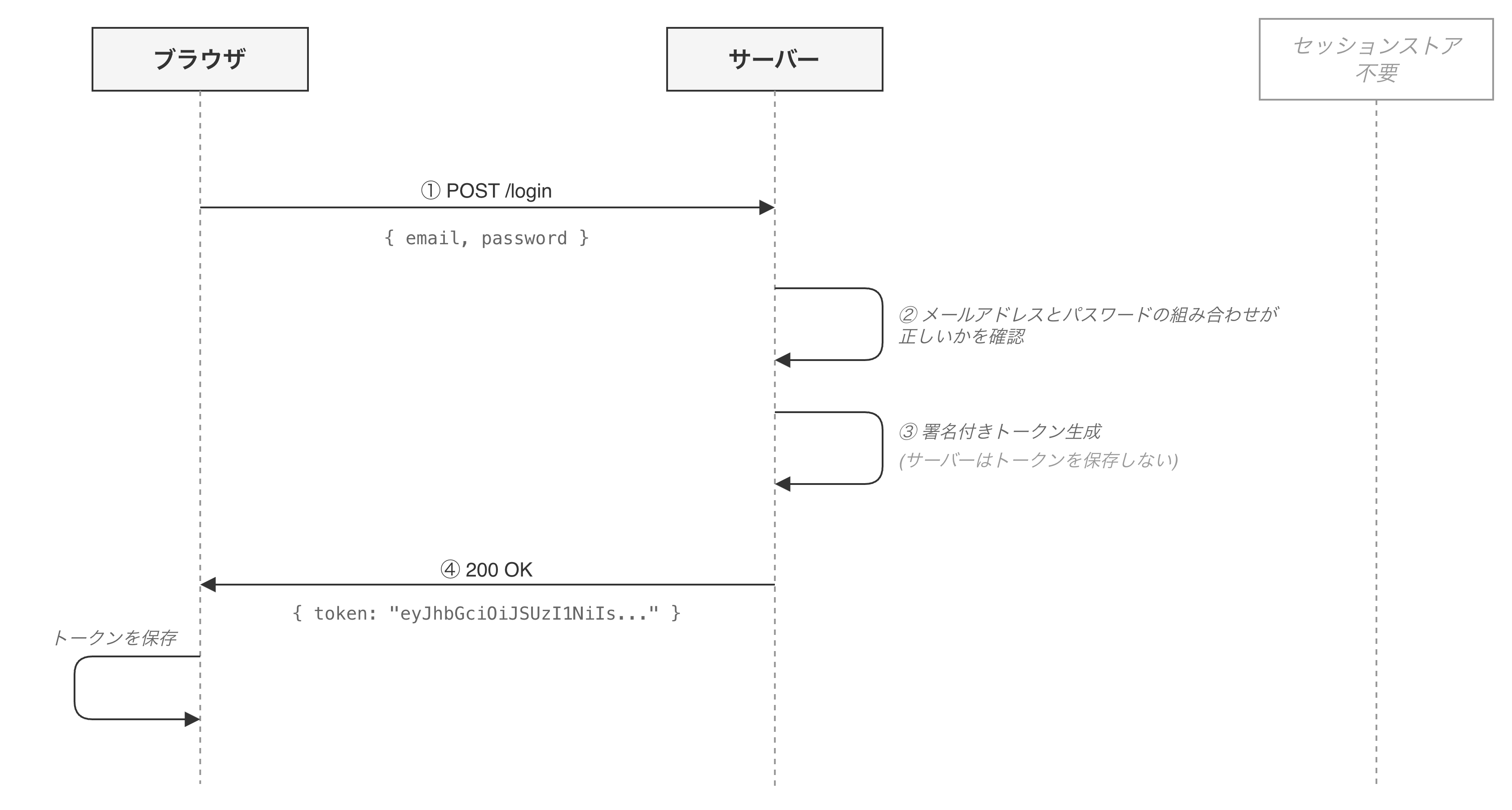
- ユーザーがメールアドレスとパスワードを送信
- サーバーが資格情報を確認(メールアドレスとパスワードの組み合わせが正しいか確認)し、認証OKであれば、署名付きトークンを生成する
- 生成したトークンをレスポンスとしてクライアントに返す
セッション認証との最大の違いは、サーバーがトークンをどこにも保存していない点です。セッションストアのような仕組みは不要です。
ログイン後のリクエスト
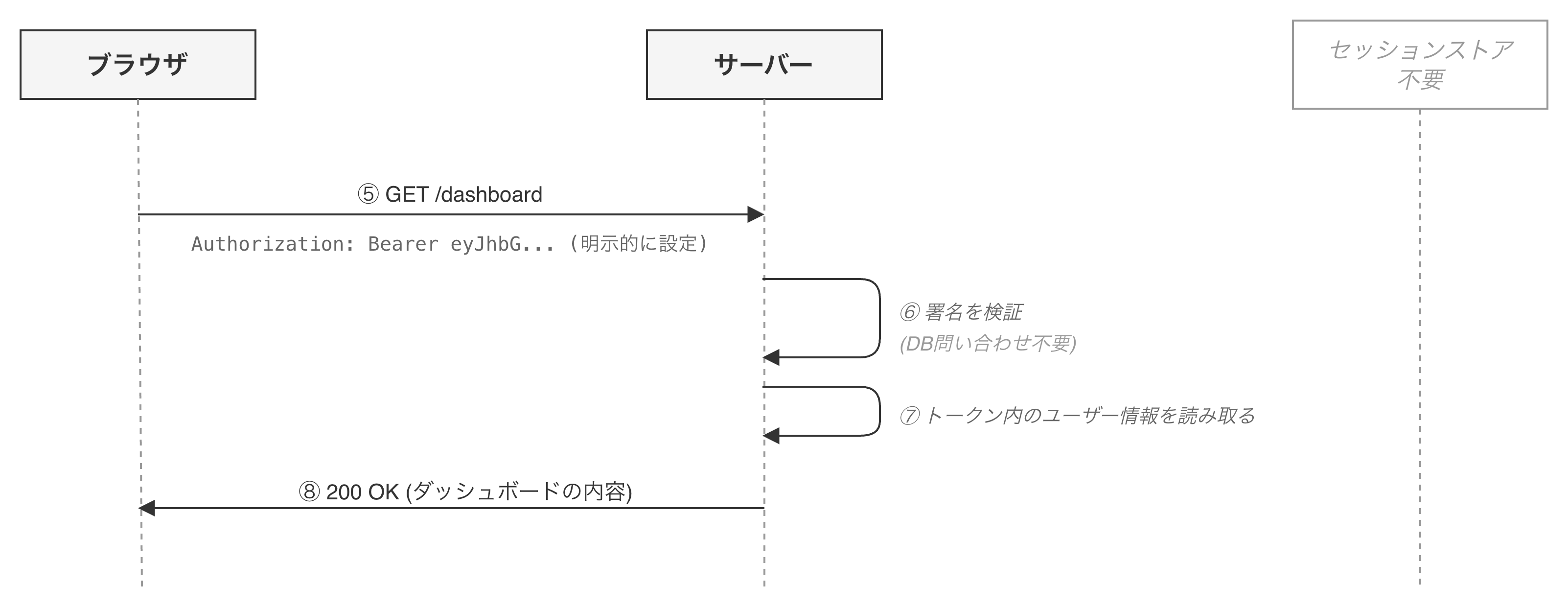
- クライアントはリクエストの
Authorizationヘッダーにトークンを添付して送信する - サーバーはトークンの署名を検証し、改ざんされていないことを確認する(第0章で解説した署名の仕組み)
- 署名が正しければ、トークンに含まれるユーザー情報をそのまま信頼して処理を行う
補足: AuthorizationヘッダーとBearerスキーム
トークンベース認証では、Authorization: Bearer <トークン>という形式のHTTPヘッダーでトークンを送信します。Bearer(ベアラー)は「持参人」という意味で「このトークンを持っている人にアクセスを許可する」という意味合いです。
Cookieがブラウザによって自動的に送信されるのとは異なり、AuthorizationヘッダーはJavaScriptで明示的に設定する必要があります。この違いが、後の章で触れるCSRF対策やSPAの認証に関わってきます。
セッション認証との比較
ここまでの内容を、セッション認証と比べて整理します。

| セッション認証 | トークンベース認証 | |
|---|---|---|
| サーバーの状態 | ステートフル(状態を保持) | ステートレス(状態を保持しない) |
| 認証情報の保存場所 | サーバー側(Redis/DB) | クライアント側(トークン内) |
| リクエストごとの処理 | セッションストアへの問い合わせ | トークンの署名検証 |
| スケーラビリティ | セッションストアの共有が必要 | サーバーを自由に増減可能 |
| ログアウト | サーバー側でセッション破棄→即座に無効化 | トークンの有効期限まで有効(即時無効化が難しい) |
多くの項目で、トークンベース認証に利点がありますが、ログアウト(即時無効化)はセッション認証の方が優れています。トークンベース認証ではサーバーが状態を持たないため、「このトークンは無効です」とサーバー側から宣言する手段がありません。トークンは有効期限が切れるまで有効であり続けます。
この即時無効化の課題に対処するために、実際のアプリケーションではリフレッシュトークンという仕組みを組み合わせて使います。これについては第7章で詳しく説明します。
ステートレスだとなぜスケールしやすいのか
第0章でステートフルとステートレスの違いに触れましたが、ここでもう少し具体的に見てみます。
ステートフル(セッション認証)の場合
サーバーA ──→ 共有セッションストア(Redis) ←── サーバーB
↑ ↑
リクエスト1 リクエスト2
→ どのサーバーにリクエストが来ても、同じセッションストアを参照する必要がある
セッション認証では、どのサーバーにリクエストが振り分けられても同じセッション情報を読めるように、共有のセッションストアが必要です。このセッションストア自体がボトルネックや単一障害点(SPOF: Single Point Of Failure)になる可能性があります。
ステートレス(トークンベース認証)の場合
サーバーA(署名を検証) サーバーB(署名を検証)
↑ ↑
リクエスト1 リクエスト2
→ 各サーバーが独立してトークンを検証できる。共有するものがない
トークンベース認証では、各サーバーが署名検証用の鍵さえ持っていれば、独立してリクエストを処理できます。サーバー間で共有するものがないため、サーバーの台数を自由に増減できます。
トークンの正体は?
ここまで「署名付きトークン」と言ってきましたが、具体的にトークンの中身がどのような構造になっているかを説明していませんでした。
Webの世界でトークンベース認証に使われるトークンの事実上の標準がJWT(JSON Web Token)です。次の章で、このJWTの仕組みについて説明します。
参考リンク
- RFC 7519 — JSON Web Token (JWT) - JWTの仕様(次章で詳述)
- RFC 6750 — Bearer Token Usage - Bearerトークンの仕様
第4章: JWTの仕組み
トークンベース認証の考え方はわかりました。サーバーは状態を持たず、署名付きトークンをクライアントに渡し、リクエストのたびに署名を検証する。
ただ、「署名付きトークン」の具体的な中身にはまだ触れていませんでした。この章では、その正体であるJWT(JSON Web Token)の構造と、署名による改ざん検知の仕組みを掘り下げます。
JWTの構造
JWTは、ドット(.)で区切られた3つのパートで構成された文字列です。
eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjo0Mn0.SflKxwRJSMeKKF2QT4fwpM
├────────────── ヘッダー ────────────┤├──── ペイロード ────┤├─────── 署名 ────────┤
それぞれの役割はこうです。
ヘッダー(Header)
ヘッダーには、署名アルゴリズムなどのメタ情報が含まれます。
{
"alg": "RS256",
"typ": "JWT"
}
-
alg: 署名に使用するアルゴリズム(この例ではRS256) -
typ: トークンの種類(JWT)
ペイロード(Payload)
ペイロードには、ユーザー情報などの実際のデータが含まれます。ペイロードに含まれる個々のデータ項目をクレーム(claim)と呼びます。
{
"user_id": 42,
"role": "admin",
"exp": 1708340400
}
expは有効期限(Expiration Time)を表す標準クレームで、UNIXタイムスタンプで指定します。サーバーはこの値を確認し、期限切れのトークンを拒否します。
署名(Signature)
署名は、ヘッダーとペイロードから計算される改ざん検知のためのデータです。詳しい仕組みは、この章の後半で説明します。
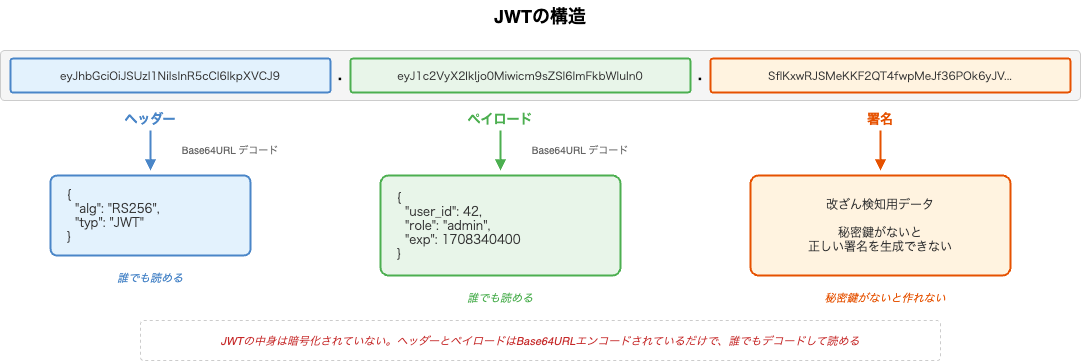
JWTの中身は暗号化されていない
ここで1つ、非常に重要な点を押さえておきます。
3つのパートはそれぞれBase64URLエンコードされているだけです。第0章で説明した通り、エンコードは暗号化ではありません。つまり、JWTの中身は誰でもデコードして読むことができます。
「JWTは暗号化されているから安全」という誤解をときどき見かけますが、JWTの署名の目的は秘匿ではなく、改ざん検知と発行者の証明です。
したがって、ペイロードにはユーザーを特定するための最小限の情報だけを含めるべきです。
// ✅ OK: 最小限の識別情報
{
"user_id": 42,
"role": "admin",
"exp": 1708340400
}
// ❌ NG: 個人情報を入れてしまっている
{
"user_id": 42,
"email": "tanaka@example.com",
"password": "hashed_password",
"address": "東京都..."
}
補足: JWTの仕様上の扱い
RFC 7519では、機微な情報の意図しない開示を防ぐ措置がMUSTとされており、JWE(JSON Web Encryption)による暗号化やTLSの使用がその手段として挙げられています。しかし実務上は、ペイロードに機微な情報をそもそも含めないのがもっともシンプルで確実な対策です。
署名アルゴリズム: 共通鍵方式と公開鍵方式
JWTの署名に使えるアルゴリズムは複数ありますが、大きく共通鍵方式と公開鍵方式の2つに分かれます。
| 共通鍵方式(HS256) | 公開鍵方式(RS256 / PS256 / ES256) | |
|---|---|---|
| 署名する鍵 | 共通鍵 | 秘密鍵 |
| 検証する鍵 | 同じ共通鍵 | 公開鍵 |
| 向いている場面 | 発行と検証が同じサーバー | 発行と検証が別のサーバー |
この違いが重要になるのは、システムの構成によってどちらを選ぶべきかが変わるからです。
発行と検証が同じサーバーの場合
自分のアプリケーションがトークンを発行し、同じアプリケーションが検証する構成では、共通鍵方式(HS256)で十分です。鍵は1つだけなので管理もシンプルです。
アプリケーションサーバー(秘密鍵を持つ)
→ トークンを発行する
→ トークンを検証する
発行と検証が別のサーバーの場合
認証サーバーがトークンを発行し、複数のサービスがそれぞれ検証するような構成では、公開鍵方式が適しています。
認証サーバー(秘密鍵を持つ)
→ トークンを発行する(ここだけ)
注文サービス(公開鍵を持つ)→ トークンを検証するだけ
決済サービス(公開鍵を持つ)→ トークンを検証するだけ
在庫サービス(公開鍵を持つ)→ トークンを検証するだけ
もし共通鍵方式を使い、複数のサービスに同じ秘密鍵を配るとどうなるでしょうか。2つの問題が生じます。
- 漏洩リスクの増大: 秘密鍵を持つサービスが増えるほど、漏洩する可能性が高くなります
- 権限の分離ができない: 秘密鍵を持つサービスはどこでもトークンを「発行」できてしまいます。検証だけさせたいのに、偽のトークンを作る能力まで与えてしまうことになります
公開鍵方式なら、トークンを発行できるのは秘密鍵を持つ認証サーバーだけです。各サービスが持つ公開鍵ではトークンの検証しかできないため、権限の分離が自然に実現できます。

補足: 主な署名アルゴリズムの比較
| アルゴリズム | 方式 | 特徴 |
|---|---|---|
| HS256 | 共通鍵(HMAC-SHA256) | シンプルで高速。発行・検証が同一サーバー向き |
| RS256 | 公開鍵(RSA, PKCS#1 v1.5) | 広く普及。多くのライブラリでサポート |
| PS256 | 公開鍵(RSA, PSS) | RS256より頑健なパディング方式。RFC 8017で新規アプリケーションに推奨 |
| ES256 | 公開鍵(楕円曲線, ECDSA) | 鍵が短く高速(256bit ECキー ≈ 3072bit RSAキーと同等の安全性) |
新規にシステムを設計する場合、公開鍵方式であればPS256またはES256が選択肢になります。RS256は現在も広く使われていますが、RFC 8017ではPSSパディング(PS256が使用)の方が頑健性が高いとされ、新規アプリケーションではPSSがREQUIREDとされています。
署名による改ざん検知の仕組み
ここまでJWTの構造と署名アルゴリズムの使い分けを見てきました。では、署名が具体的にどうやって改ざんを検知するのか。
共通鍵方式(HS256)の場合
共通鍵方式では、HMAC(Hash-based Message Authentication Code)を使います。
署名の生成:
HMAC-SHA256( ヘッダー + "." + ペイロード, 秘密鍵 ) → 署名
署名の検証:
サーバーが受け取ったトークンに対して:
1. ヘッダー + "." + ペイロード を取り出す
2. 自分の秘密鍵で HMAC-SHA256 を再計算する
3. 再計算した値 == 受け取った署名 → ✅ 改ざんなし
4. 再計算した値 ≠ 受け取った署名 → ❌ 改ざんされている
もし攻撃者がペイロードの"role": "user"を"role": "admin"に書き換えたとします。
サーバーの検証:
1. 改ざんされたペイロードで HMAC-SHA256 を再計算する
2. 再計算した値 ≠ 受け取った署名
→ ❌ 不一致!改ざん検知!
ペイロードが1文字でも変わると、再計算される値がまったく異なるものになります(第0章で説明したハッシュ化の性質です)。そして攻撃者は秘密鍵を知らないので、改ざん後のペイロードに対応する正しい署名を作ることができません。

公開鍵方式(RS256)の場合
公開鍵方式では、第0章で説明した署名の仕組みがそのまま使われます。
署名の生成(秘密鍵を持つ認証サーバー):
ヘッダー + "." + ペイロード
→ ハッシュ化 → ハッシュ値
→ 秘密鍵で署名操作 → 署名
署名の検証(公開鍵を持つ各サービス):
受け取った署名 → 公開鍵で検証操作 → ハッシュ値(A)
受け取ったデータ本体 → ハッシュ化 → ハッシュ値(B)
ハッシュ値(A) == ハッシュ値(B)
→ ✅ 改ざんなし & 認証サーバーが発行したことの証明
共通鍵方式と比べた公開鍵方式の特徴は、改ざん検知に加えて「誰が発行したか」も証明できる点です。公開鍵で検証が成功するということは、対応する秘密鍵で署名されたことの証明になります。
第3章まではトークンベース認証の「考え方」でしたが、この章でその中核を担うJWTの「仕組み」が見えてきました。
- JWTはヘッダー・ペイロード・署名の3パートで構成され、中身は暗号化されていない
- 署名アルゴリズムはシステム構成に応じて共通鍵方式と公開鍵方式を選ぶ
- 署名により改ざん検知と発行者の証明ができる
ここまでで、認証の基本(第1章)、セッション認証(第2章)、トークン認証(第3章)、JWT(第4章)と、認証にまつわる技術要素をひととおり見てきました。
次は視点を変えて、OAuth 2.0という「認可」のフレームワークに進みます。認証の話の流れでなぜ認可なのか。その理由から始めます。
参考リンク
- RFC 7519 — JSON Web Token (JWT) - JWTの仕様
- RFC 7518 — JSON Web Algorithms (JWA) - 署名アルゴリズムの仕様と実装要求レベル
- RFC 8017 — PKCS #1 v2.2 - RSA署名仕様、PSSの推奨
第5章: OAuth 2.0 - 認可のフレームワーク
第1章〜第4章では、「ログインしたユーザーをどう覚えておくか」という認証の仕組みを扱ってきました。セッション認証、トークン認証、JWT。いずれも「あなたは誰ですか?」を確認・維持するための技術です。
ここからは、認証とは別の課題に目を向けます。
たとえば、写真プリントサービスを想像してください。このサービスは、ユーザーのGoogleフォトにある写真を読み取ってプリントしたいと考えています。しかし、ユーザーのGoogleアカウントのパスワードを預かるわけにはいきません。
これは「写真プリントサービスに対して、Googleフォトの写真を読み取る権限を与える」という話であり、第1章で整理した認可の問題です。
この章では、この問題を解決するためのフレームワークであるOAuth 2.0について解説します。
なぜOAuth 2.0が必要なのか
OAuth 2.0がない世界で、写真プリントサービスがユーザーのGoogleフォトにアクセスしようとすると、ユーザーのGoogleのID・パスワードを直接受け取るしかありません。
この「パスワードを直接渡す」方式には、RFC 6749のSection 1で指摘されている深刻な問題があります。

問題1: 情報漏洩リスク
写真プリントサービスがパスワードを保存する必要があります。このサービスから情報が漏洩すると、Googleアカウント全体が危険にさらされます。
問題2: 権限が広すぎる
パスワードを渡すということは、そのアカウントの全権限を渡すことと同じです。写真だけ見せたいのに、Gmail・ドライブ・YouTubeなど何でもアクセスできてしまいます。
問題3: 個別に取り消せない
複数のサービスにパスワードを渡している場合、特定のサービスだけアクセスを取り消す手段がありません。パスワードを変更すると、すべてのサービスに影響が出ます。
OAuth 2.0は、パスワードを渡す代わりに、限定された権限を持つトークンを発行することでこれらの問題を解決します。この権限の範囲をスコープ(Scope)と呼びます。
登場人物(4つのロール)
OAuth 2.0のフローには4つのロールが登場します(RFC 6749 Section 1.1)。
| ロール | 役割 | 例(Googleフォトの場合) |
|---|---|---|
| リソースオーナー | リソースの持ち主 | ユーザー(Googleアカウントの持ち主) |
| クライアント | リソースにアクセスしたいアプリ | 写真プリントサービス |
| 認可サーバー | トークンを発行するサーバー | Google(accounts.google.com) |
| リソースサーバー | リソースを持つサーバー | Googleフォト(photos.googleapis.com) |
補足: 「クライアント」の意味に注意
ここでの「クライアント」は、ブラウザやスマホのことではありません。ユーザーのリソースにアクセスしたいアプリケーション(この例では写真プリントサービス)を指します。OAuth 2.0の文脈では、このアプリケーションが認可サーバーに対して「クライアント」の立場になるため、こう呼ばれています。
認可コードフロー(Authorization Code Flow)
OAuth 2.0にはいくつかのフロー(グラントタイプ)がありますが、もっとも一般的で安全なのが認可コードフローです(RFC 6749 Section 4.1)。
全体の流れを先に示し、その後で各ステップを掘り下げます。
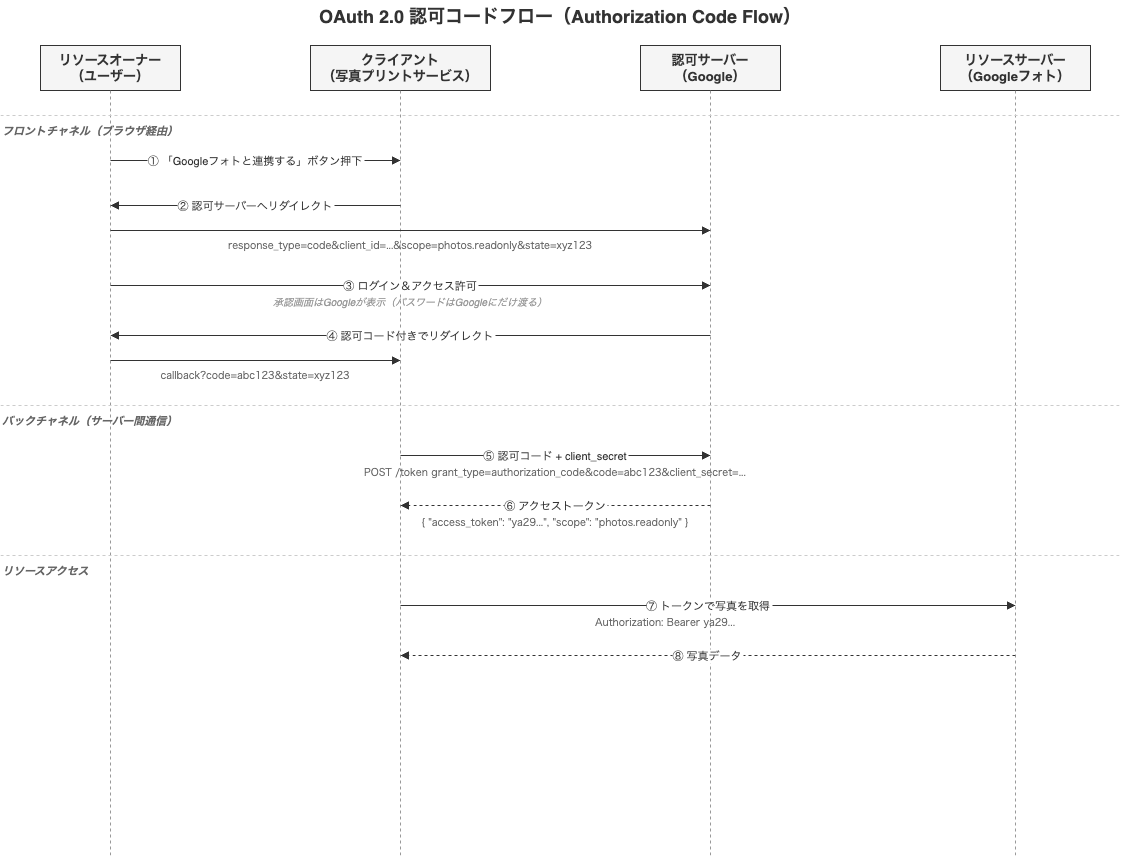
ステップ①②: ユーザーが「Googleフォトと連携する」ボタンを押す
写真プリントサービスは、ユーザーのブラウザをGoogleの認可サーバーにリダイレクトさせます。
https://accounts.google.com/authorize?
response_type=code
&client_id=写真プリントサービスのID
&scope=photos.readonly
&redirect_uri=https://print-service.com/callback
&state=xyz123
各パラメーターの意味は以下の通りです。
| パラメーター | 意味 | 補足 |
|---|---|---|
response_type=code |
認可コードを要求する | REQUIRED |
client_id |
クライアントの識別子 | REQUIRED。事前にGoogleに登録して取得する |
scope |
要求する権限の範囲 | この例では「写真の読み取りだけ」 |
redirect_uri |
認可後の戻り先URL | |
state |
CSRF対策のランダム文字列 | RECOMMENDED |
stateパラメーターについては、CSRF対策(第11章)で改めて扱います。ここでは「セキュリティのためのパラメーター」とだけ理解しておけば十分です。
ステップ③: ユーザーがGoogleにログインし、アクセスを許可する
Googleの認可サーバーが承認画面を表示します。
「写真プリントサービスがあなたのGoogleフォトの写真を
読み取ることを許可しますか?」
[許可する] [拒否する]
ここで重要なのは、この画面はGoogleが表示しているという点です。ユーザーのパスワードは写真プリントサービスには一切渡りません。パスワードはGoogleに直接入力しています。
ステップ④: 認可コードがクライアントに返される
ユーザーが許可すると、Googleはブラウザを写真プリントサービスのredirect_uriにリダイレクトさせます。このとき、URLのクエリパラメーターに認可コードが付与されます。
https://print-service.com/callback?code=abc123&state=xyz123
ステップ⑤⑥: 認可コードをアクセストークンと交換する
写真プリントサービスのサーバーが、受け取った認可コードをGoogleの認可サーバーに送り、アクセストークンと交換します。
POST https://oauth2.googleapis.com/token
Content-Type: application/x-www-form-urlencoded
grant_type=authorization_code
&code=abc123
&client_id=写真プリントサービスのID
&client_secret=サービスの秘密鍵
&redirect_uri=https://print-service.com/callback
認可サーバーはリクエストを検証し、問題なければアクセストークンを返します。
{
"access_token": "ya29.a0AfH6SM...",
"token_type": "Bearer",
"expires_in": 3600,
"scope": "photos.readonly"
}
補足: クライアント認証について
ステップ⑤のリクエストに含まれるclient_secretは、クライアント(写真プリントサービス)を認可サーバーに対して認証するためのものです。クライアントの認証方法にはclient_secretをPOSTボディに含める方式のほかに、HTTP Basic認証を使う方式などがあります。クライアントの種類と認証方式については第9章で詳しく解説します。
ステップ⑦⑧: アクセストークンでリソースにアクセスする
写真プリントサービスは、取得したアクセストークンを使ってGoogleフォトのAPIにリクエストします。
GET https://photoslibrary.googleapis.com/v1/mediaItems
Authorization: Bearer ya29.a0AfH6SM...
Googleフォトはアクセストークンを検証し、スコープの範囲内であれば写真データを返します。
なぜ認可コードを経由するのか: 2段階にする理由
フローを見て、「なぜ最初から直接アクセストークンを返さないのか?」と疑問に思うかもしれません。
ステップ④の認可コードはブラウザのリダイレクト(URLパラメーター)で運ばれます。URLに含まれるデータには以下のリスクがあります。
- ブラウザの履歴に残る
- ブラウザのログに残る
- ネットワーク経路上で見られる可能性がある
【もしアクセストークンを直接URLで返していたら】
URLからアクセストークンが盗まれたら、即座にGoogleフォトにアクセスされてしまう
【認可コードを経由する場合】
URLから認可コードが盗まれても、client_secretがないとトークンに交換できない
トークン交換(ステップ⑤⑥)はサーバー間通信なので、ブラウザを経由しない
つまり、漏洩リスクのある経路(ブラウザ)には使い捨ての認可コードだけを流し、重要なアクセストークンは安全なサーバー間通信でやり取りするという設計です。

補足: フロントチャネルとバックチャネル
ブラウザを経由する通信をフロントチャネル、サーバー間の直接通信をバックチャネルと呼びます。認可コードはフロントチャネルで、アクセストークンの交換はバックチャネルで行われます。この区別は、OAuth 2.0のセキュリティモデルを理解する上で重要な概念です。
OAuth 2.0は「認可」のフレームワークである
最後に、この章の核心を改めて確認しておきます。
OAuth 2.0の正式名称は「The OAuth 2.0 Authorization Framework」です。名前の通り、これは認可(Authorization)の仕組みです。
OAuth 2.0が解決するのは、「写真プリントサービスにGoogleフォトへのアクセス権限を与える」という問題です。「このユーザーは田中さんである」という本人確認(認証)の標準的な方法は定義していません。
冒頭で述べた3つの問題がどう解決されたかを確認しておきます。
| 問題 | OAuth 2.0による解決 |
|---|---|
| 情報漏洩リスク | パスワードはGoogleの認可サーバーにしか渡らない |
| 権限が広すぎる | スコープで「写真の読み取りだけ」に絞れる |
| 個別に取り消せない | アクセストークンを個別に無効化できる |
では、OAuth 2.0が認可のフレームワークであるならば、「Googleでログイン」のような認証はどう実現するのでしょうか?
次の章では、OAuth 2.0の上に認証の仕組みを追加したOpenID Connectについて解説します。
参考リンク
- RFC 6749 — The OAuth 2.0 Authorization Framework - OAuth 2.0の仕様
- RFC 6749 Section 1 - 従来モデルの問題点
- RFC 6749 Section 4.1 - Authorization Code Grant
第6章: OpenID Connect - OAuth 2.0に認証を追加する
第5章では、OAuth 2.0が「パスワードを渡さずに権限を委譲する」という認可の問題を解決することを見ました。写真プリントサービスは、ユーザーのGoogleフォトにアクセスする権限をアクセストークンとして受け取ることができました。
しかし、アクセストークンだけでは「このユーザーは誰なのか」はわかりません。
「Googleでログイン」ボタンを想像してください。ユーザーがこのボタンを押したとき、アプリケーションが知りたいのは「Googleフォトにアクセスする権限」ではなく、「このユーザーは田中太郎さんである」という本人確認、つまり認証の情報です。
OAuth 2.0は認可のフレームワークであり、認証の標準的な方法は定義していません。では、認証はどう実現するのか。その答えがOpenID Connectです。
OpenID Connectとは
OpenID Connect(以下OIDC)は、その仕様の冒頭で次のように定義されています。
OpenID Connect 1.0 is a simple identity layer on top of the OAuth 2.0 protocol.
— OpenID Connect Core 1.0 Abstract
「OAuth 2.0プロトコルの上のシンプルなアイデンティティレイヤー」。この一文がOIDCの本質を正確に表しています。
OIDCはOAuth 2.0を置き換えるものではありません。第5章で見た認可コードフローをほぼそのまま使いながら、そこに「ユーザーが誰か」を伝える仕組みを追加したものです。
OAuth 2.0からの変更点はわずか2箇所
OIDCがOAuth 2.0の認可コードフローに追加するのは、わずか2箇所です。
変更点1: 認可リクエストにscope=openidを追加する
第5章のステップ②で見た認可リクエストに、openidスコープを加えます。
第5章(OAuth 2.0のみ):
https://accounts.google.com/authorize?
response_type=code
&client_id=写真プリントサービスのID
&scope=photos.readonly
&redirect_uri=https://print-service.com/callback
OpenID Connectの場合:
https://accounts.google.com/authorize?
response_type=code
&client_id=写真プリントサービスのID
&scope=openid photos.readonly ← openid を追加
&redirect_uri=https://print-service.com/callback
scopeにopenidが含まれていることで、認可サーバーは「このリクエストはOIDCとして処理すべきだ」と判断します。
変更点2: トークンエンドポイントの応答にIDトークンが追加される
第5章のステップ⑥で見たトークンエンドポイントの応答に、IDトークンが追加されます。
// OAuth 2.0だけの場合(第5章のステップ⑥)
{
"access_token": "ya29.a0AfH6SM...",
"token_type": "Bearer",
"expires_in": 3600
}
// OpenID Connectの場合
{
"access_token": "ya29.a0AfH6SM...",
"token_type": "Bearer",
"expires_in": 3600,
"id_token": "eyJhbGciOiJSUzI1Ni..." // ← IDトークンが追加される
}
これだけです。 認可コードフロー自体のステップ(①〜⑧)は変わりません。既存のOAuth 2.0のフローに最小限の追加で認証を実現している。これがOIDCが「シンプルなアイデンティティレイヤー」と呼ばれる理由です。
IDトークン: 「あなたは誰か」の答え
IDトークンは、認可サーバーが「このユーザーはこの人物です」と証明するためのトークンです。
OIDCの仕様により、IDトークンは必ずJWT形式で発行されます。第4章で学んだJWTの構造(ヘッダー・ペイロード・署名の3パート)がそのまま使われています。
必須クレーム
OIDCの仕様(Section 2)では、IDトークンに含めるべき5つの必須クレームが定義されています。
| クレーム | 説明 | 例 |
|---|---|---|
iss |
発行者のURL | "https://accounts.google.com" |
sub |
ユーザーの一意な識別子 | "1234567890" |
aud |
このトークンの対象者(client_id) | "写真プリントサービスのID" |
exp |
有効期限(UNIXタイムスタンプ) | 1708340400 |
iat |
発行日時(UNIXタイムスタンプ) | 1708336800 |
ペイロードの具体例を見てみましょう。
{
"iss": "https://accounts.google.com",
"sub": "1234567890",
"aud": "写真プリントサービスのID",
"exp": 1708340400,
"iat": 1708336800,
"email": "tanaka@gmail.com",
"name": "田中太郎"
}
iss、sub、aud、exp、iatの5つが必須クレームです。emailとnameは次に説明する任意の標準クレームで、IDトークンに含まれるかは認可サーバーの設定やスコープ次第です。
任意の標準クレーム
OIDCの仕様(Section 5.1)では、email、name、pictureなどの標準クレームも定義されています。ただし、これらはIDトークンに含めることが可能というだけで必須ではありません。
実際にどのクレームが含まれるかは、認可リクエストで要求したスコープによって変わります。
| スコープ | 取得できるクレーム |
|---|---|
openid |
sub(必須) |
profile |
name, picture, gender など |
email |
email, email_verified
|
たとえば、scope=openid email profileと指定すれば、IDトークンにメールアドレスや名前が含まれる可能性があります。
OAuth 2.0とOpenID Connectの関係
ここまでの内容を整理します。
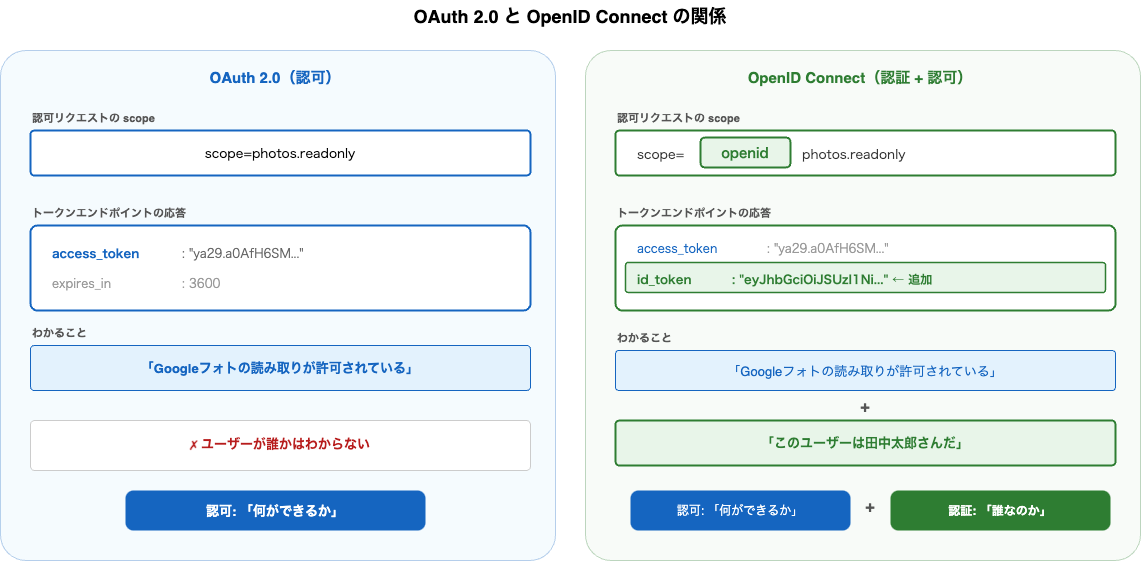
| OAuth 2.0 | OpenID Connect | |
|---|---|---|
| 目的 | 認可(リソースへのアクセス権限を委譲) | 認証(ユーザーが誰かを特定)+ 認可 |
| 返すもの | アクセストークン | アクセストークン + IDトークン |
| わかること | 「Googleフォトの読み取りが許可されている」 | 左記 +「このユーザーは田中太郎さんだ」 |
OIDCはOAuth 2.0を拡張したものであり、OAuth 2.0の認可の仕組みはそのまま活かしつつ、IDトークンによって「認証」の能力を追加しています。
「Googleでログイン」の裏側
ここまでの知識で、「Googleでログイン」ボタンの裏側で何が起きているかを説明できます。
- ユーザーが「Googleでログイン」ボタンを押す
- アプリケーションが
scope=openid email profileで認可リクエストを送る - ユーザーがGoogleにログインし、情報の提供を許可する
- アプリケーションがIDトークンを受け取る
- IDトークンの署名を検証し、クレーム(
sub、email、nameなど)を読み取る - そのユーザー情報をもとに、自分のサービスのアカウントと紐づける(または新規作成する)
ユーザーのパスワードはGoogleにしか渡らず、アプリケーションはIDトークンから必要な情報だけを受け取ります。
補足: OpenID Certified
GoogleをはじめとするOIDCプロバイダーの多くは、OpenID Foundationの認定プログラム(OpenID Certified)を取得しています。これは、そのプロバイダーのOIDC実装が仕様に準拠していることを第三者が確認したものです。
第5章のOAuth 2.0と、この章のOpenID Connectを通して、「認可」と「認証」の仕組みがそれぞれ明らかになりました。
ここで少し立ち止まります。ここまででアクセストークンとIDトークンの2種類が登場しました。実は、OAuth 2.0 / OIDCの世界にはもう1つ、リフレッシュトークンがあります。
次の章で、この3つのトークンの役割と使い分けを整理します。
参考リンク
- OpenID Connect Core 1.0 - OIDCの仕様
- OpenID Connect Core 1.0 Section 2 — ID Token - IDトークンの必須クレーム
- OpenID Connect Core 1.0 Section 5.1 — Standard Claims - 標準クレーム一覧
- Google OpenID Connect Documentation - GoogleのOIDC実装
第7章: 3つのトークンの役割
第5章と第6章で、アクセストークンとIDトークンが出てきました。ここに3つ目のリフレッシュトークンを加えて、それぞれの役割を整理します。
3つのトークンの比較
まず全体像から。
| アクセストークン | IDトークン | リフレッシュトークン | |
|---|---|---|---|
| 役割 | リソースにアクセスするための「鍵」 | ユーザーが誰かを伝える「身分証」 | アクセストークンを更新するためのトークン |
| 送信先 | リソースサーバー | クライアントが自分で検証 | 認可サーバーのみ |
| フォーマット | 仕様上の規定なし | 必ずJWT(OIDC仕様で規定) | 仕様上の規定なし |
| 有効期限 | 短い(数分〜1時間) | 短い | 長い(数日〜数週間) |
| 定義元 | RFC 6749 | OpenID Connect Core 1.0 | RFC 6749 |
※ 有効期限の具体的な数値はRFCの規定ではなく、一般的な実装慣行です。
IDトークンの有効期限も「短い」とありますが、アクセストークンのようにリフレッシュトークンで再発行する必要は通常ありません。アクセストークンはAPIリクエストのたびに繰り返し使うため期限切れへの対処が必要ですが、IDトークンはログイン時にユーザーを特定し、自サービスのアカウントと紐づけたら役目を終えます。expはセキュリティ上の保険で、漏洩したIDトークンの使い回しを防ぐためのものです。
ここで注目したいのは、アクセストークンのフォーマットが仕様上規定されていないという点です。
アクセストークンのフォーマット: JWT vs ランダム文字列
IDトークンはOIDCの仕様でJWT形式が必須ですが、アクセストークンのフォーマットはOAuth 2.0の仕様では規定されていません。実装上は大きく2つのパターンがあります。
パターン1: JWT形式
アクセストークン: eyJhbGciOiJSUzI1NiJ9.eyJ1c2VyX2lkIjo0Mn0.SflKx...
→ トークン自体に情報が埋め込まれている
→ デコード+署名検証だけでユーザーを特定できる
→ 認可サーバーへの問い合わせ不要
- メリット: 高速。リソースサーバーが単独で検証できる
- デメリット: トークンの即時無効化が困難(第3章で触れたトークンベース認証の課題と同じ)
パターン2: ランダム文字列(Opaque Token)
アクセストークン: dGhpcyBpcyBhIHJhbmRvbQ...
→ トークン自体には情報がない(ただの引換券)
→ 認可サーバーのイントロスペクションエンドポイント(RFC 7662)に問い合わせる
- メリット: 認可サーバー側で
active: falseにすれば即時無効化できる - デメリット: 毎回認可サーバーへの問い合わせが必要
これは、第2章・第3章で学んだ「セッションベース vs トークンベース」のトレードオフと同じ構造です。引換券を渡してサーバーに問い合わせるか、情報を直接持たせるか。即時無効化の必要性とパフォーマンスのバランスで選択します。
リフレッシュトークン: なぜ必要か
第3章で、トークンベース認証のデメリットとして「即時無効化が困難」という課題を挙げました。その対策としてアクセストークンの有効期限を短くするのが一般的ですが、そのままではユーザーが頻繁に再ログインを求められてしまいます。
リフレッシュトークンは、アクセストークンの有効期限を短く保ちつつ、ユーザー体験を損なわないための仕組みです。
トークン更新の流れ
ログイン成功時に、アクセストークンとリフレッシュトークンの2つが発行されます。
{
"access_token": "eyJhbG...",
"refresh_token": "dGhpcyBpcw..."
}
アクセストークンが切れたとき、クライアントはリフレッシュトークンを使って新しいアクセストークンを取得します。
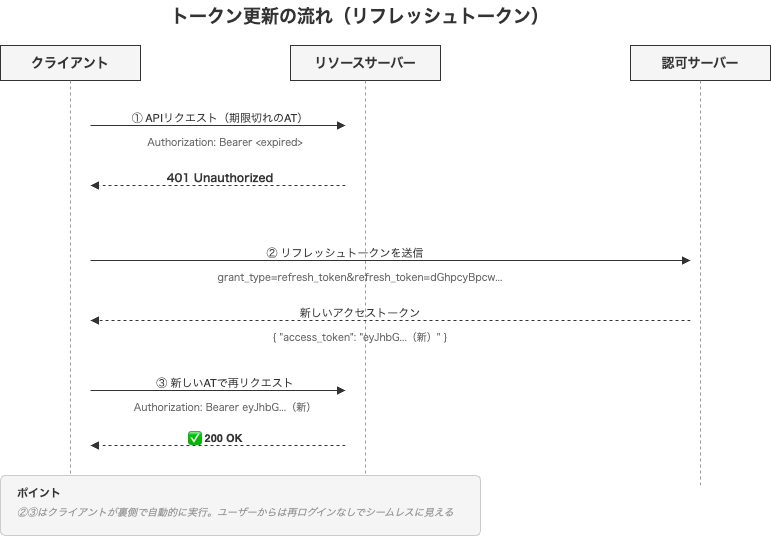
②③はクライアントが裏側で自動的に行うのが一般的な実装パターンです。ユーザーから見れば、再ログインなしでシームレスに使い続けられます。
補足: リフレッシュトークンの発行は任意
リフレッシュトークンの発行は認可サーバーの裁量であり、必ず発行されるわけではありません(RFC 6749 Section 1.5では「MAY」と規定)。
なぜアクセストークンとリフレッシュトークンを分けるのか
「アクセストークンの有効期限を長くすればリフレッシュトークンは不要では?」と思うかもしれません。しかし、2つのトークンは使われ方が根本的に違います。
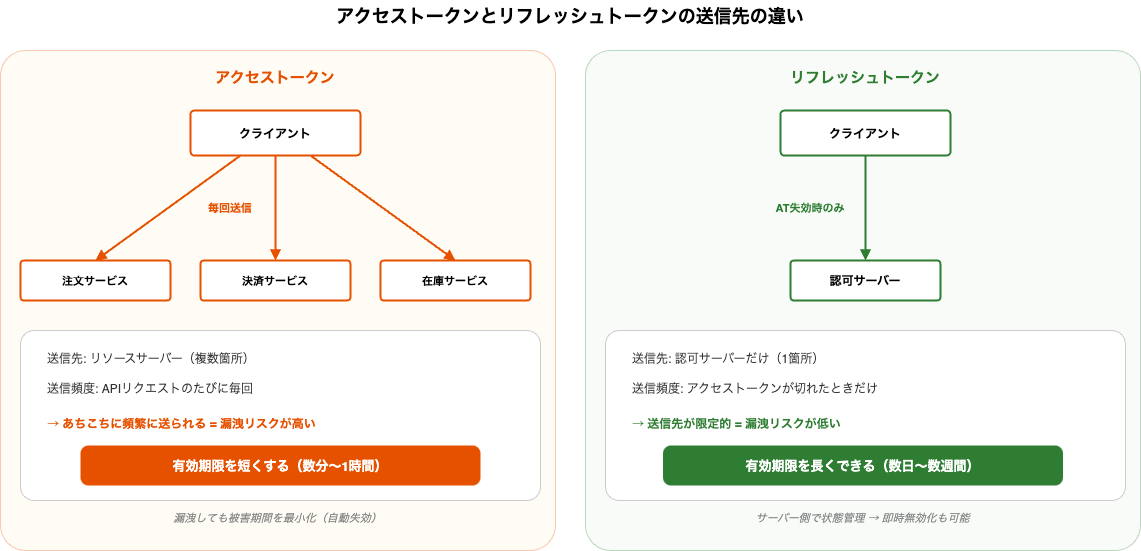
【アクセストークン】
送信先: リソースサーバー(複数箇所)
送信頻度: APIリクエストのたびに毎回送る
→ あちこちに頻繁に送られる = 漏洩する機会が多い
→ だから有効期限を短くする(漏洩しても被害期間を最小化)
【リフレッシュトークン】
送信先: 認可サーバーだけ(1箇所)
送信頻度: アクセストークンが切れたときだけ
→ 送信先が限定的 = 漏洩リスクが低い
→ だから有効期限を長くできる
→ サーバー側で状態管理され、即時無効化も可能
つまり、アクセストークンの「短い有効期限による自動失効」とリフレッシュトークンの「サーバー側での即時無効化」を組み合わせることで、セキュリティとユーザー体験の両立を実現しています。
補足: リフレッシュトークンの無効化
リフレッシュトークンは一般にサーバー側でopaque token(ランダム文字列)として状態管理されており、RFC 7009で定義されたrevocationエンドポイントを通じて即時無効化できます(リフレッシュトークンのrevocationサポートはMUST)。
リフレッシュトークンローテーション
リフレッシュトークンにはもう1つ重要な仕組みがあります。リフレッシュトークンローテーションです(RFC 9700 Section 4.14.2でSHOULDとして推奨)。
これは、リフレッシュトークンを使って新しいアクセストークンを取得するとき、新しいリフレッシュトークンも同時に発行し、古いリフレッシュトークンを無効化する仕組みです。
// リフレッシュリクエスト
{
"grant_type": "refresh_token",
"refresh_token": "old_refresh_token"
}
// 応答
{
"access_token": "new_access_token",
"refresh_token": "new_refresh_token" // ← 新しいリフレッシュトークン
}
// → old_refresh_token は無効化される
ローテーションの2つのメリット
メリット1: 有効期限の自動延長
使い続けている限りリフレッシュトークンの期限が更新されるため、アクティブなユーザーが再ログインを求められることがありません。
メリット2: 盗難の検知(最大のメリット)
ローテーションにより、1つのリフレッシュトークンは1回しか使えなくなります。もし攻撃者がトークンを盗んだ場合、どちらが先に使っても不正が検知できます。
【攻撃者が先に使った場合】
1. 攻撃者がリフレッシュトークンAを盗む
2. 攻撃者がAを使用 → 新しいトークンCが発行される(Aは無効化)
3. 正規ユーザーがAを使おうとする → ❌ 無効化済み!
→ 「使用済みトークンが再利用された」= 不正アクセスのシグナル
→ そのユーザーの全リフレッシュトークンを無効化 → 攻撃者のCも無効に
【正規ユーザーが先に使った場合】
1. 攻撃者がリフレッシュトークンAを盗む
2. 正規ユーザーがAを使用 → 新しいトークンBが発行される(Aは無効化)
3. 攻撃者がAを使おうとする → ❌ 無効化済み!
どちらが先に使っても検知でき、全トークンの無効化で被害を食い止められます。
まとめると、3つのトークンの役割はこうです。
- アクセストークン: リソースにアクセスするための鍵。短い有効期限で漏洩リスクを軽減
- IDトークン: ユーザーが誰かを証明する身分証。必ずJWT形式
- リフレッシュトークン: アクセストークンを再発行するためのトークン。認可サーバーにのみ送信
第6章の「Googleでログイン」の流れでは、アプリケーションがIDトークンの「署名を検証」するステップがありました。この署名検証は具体的にどう行われるのか。次の章で掘り下げます。
参考リンク
- RFC 6749 Section 1.5 — Refresh Token - リフレッシュトークンの定義
- RFC 6749 Section 10.4 — Refresh Tokens - リフレッシュトークンのセキュリティ考慮事項
- RFC 7662 — OAuth 2.0 Token Introspection - イントロスペクションエンドポイント
- RFC 7009 — OAuth 2.0 Token Revocation - トークン無効化エンドポイント
- RFC 9700 Section 4.14 — Refresh Tokens - リフレッシュトークンローテーションの推奨
第8章: IDトークンの署名検証
第6章の「Googleでログイン」の流れでは、ステップ5で「IDトークンの署名を検証し、クレームを読み取る」と説明しました。第4章で署名検証の原理(公開鍵でハッシュ値を照合する)は学びましたが、実際の検証ではその公開鍵をどうやって手に入れるかという問題が残っています。
この章では、その手順を追います。
IDトークンのヘッダーの中身
第4章で、JWTのヘッダーには署名アルゴリズム(alg)が含まれると説明しました。IDトークンのヘッダーには、もう1つ重要なフィールドがあります。
{
"kid": "SD-2021-10",
"alg": "RS256"
}
kid(Key ID)は、署名検証に使うべき公開鍵を特定するためのIDです(RFC 7515 Section 4.1.4)。
なぜこれが必要なのでしょうか。認可サーバー(IdP)はセキュリティ上の理由から、署名に使う鍵を定期的に入れ替えます(鍵のローテーション)。ローテーション中は新旧の鍵が同時に存在するため、「このトークンはどの鍵で検証すべきか」を示す手がかりが必要になります。それがkidです。
ディスカバリエンドポイント: IdPの設定を自動取得する
署名検証には公開鍵が必要ですが、その公開鍵はどこにあるのでしょうか。
「Googleでログイン」を実装するとき、開発者は認可エンドポイントのURL、トークンエンドポイントのURL、署名検証用の公開鍵の場所、サポートされているスコープなど、多くの情報を知る必要があります。これらを手動で設定するのは面倒ですし、IdPが設定を変更するたびに追従しなければなりません。
ディスカバリエンドポイントは、これらの情報を1つのURLから機械的に取得できるようにした仕組みです(OpenID Connect Discovery 1.0で定義)。
URLの形式は {Issuer識別子}/.well-known/openid-configuration です。
https://accounts.google.com/.well-known/openid-configuration
このURLにアクセスすると、IdPの設定情報がJSONで返ってきます。
{
"issuer": "https://accounts.google.com",
"authorization_endpoint": "https://accounts.google.com/o/oauth2/v2/auth",
"token_endpoint": "https://oauth2.googleapis.com/token",
"jwks_uri": "https://www.googleapis.com/oauth2/v3/certs",
"scopes_supported": ["openid", "email", "profile"],
"id_token_signing_alg_values_supported": ["RS256"]
}
| フィールド | 説明 | 必須/推奨 |
|---|---|---|
authorization_endpoint |
認可コードフローのリダイレクト先 | REQUIRED |
token_endpoint |
トークン交換先 | REQUIRED |
jwks_uri |
公開鍵が置いてある場所 | REQUIRED |
scopes_supported |
使えるスコープの一覧 | RECOMMENDED |
ここで注目すべきはjwks_uriです。公開鍵そのものがディスカバリエンドポイントに含まれるのではなく、公開鍵の置き場所を指すURLが返ってきます。
JWKセットドキュメント: 公開鍵の一覧
jwks_uriにアクセスすると、JWKセットドキュメント(RFC 7517で定義)が返ってきます。これは公開鍵の一覧です。
{
"keys": [
{
"kid": "SD-2021-10",
"alg": "RS256",
"kty": "RSA",
"n": "0vx7agoebGcQ...",
"e": "AQAB"
},
{
"kid": "SD-2023-03",
"alg": "RS256",
"kty": "RSA",
"n": "4f3YcZ8zulE...",
"e": "AQAB"
}
]
}
複数の鍵が含まれているのは、先ほど説明した鍵のローテーションのためです。古い鍵で署名されたトークンも検証できるよう、新旧の鍵が同時に公開されています。
IDトークンのヘッダーのkidと一致する鍵を選び、その公開鍵で署名を検証します。
署名検証フロー全体
ここまでの内容をつなげると、署名検証の全体像が見えてきます。Issuer識別子さえ知っていれば、あとは全部自動で辿れる設計です。

① Issuer識別子がわかる
例: https://accounts.google.com
② ディスカバリエンドポイントにアクセス
https://accounts.google.com/.well-known/openid-configuration
→ jwks_uri を取得
③ jwks_uri にアクセス
https://www.googleapis.com/oauth2/v3/certs
→ 公開鍵の一覧を取得
④ IDトークンのヘッダーの kid と一致する公開鍵を選ぶ
⑤ その公開鍵で署名を検証(第4章で学んだ仕組み)
→ ✅ 改ざんなし & このIdPが発行したことの証明
実際のアプリケーション開発では、OIDCライブラリがこのフロー(ディスカバリ → JWKS取得 → 鍵選択 → 検証)を自動で行います。公開鍵のキャッシュも含めてライブラリが処理するため、開発者がIssuer識別子を設定するだけで署名検証が機能します。
補足: JWKSのキャッシュ
JWKセットドキュメントのレスポンスは通常キャッシュされ、リクエストのたびに取得するわけではありません。鍵ローテーション時など、kidが一致する鍵が見つからない場合にJWKSを再取得するのが一般的な実装パターンです。
IDトークンの署名検証は「Issuer識別子 → ディスカバリ → JWKS → 鍵選択 → 検証」という自動化された流れで行われます。
第5章〜第8章で、OAuth 2.0とOpenID Connectの核心部分はひととおりカバーしました。ここからは実装に近い視点に移ります。
第5章の認可コードフローでは、クライアントがclient_secretで認可サーバーに自分を証明していました。しかし、すべてのアプリケーションがclient_secretを安全に保持できるわけではありません。次の章ではクライアントの分類と認証方式を扱います。
参考リンク
- OpenID Connect Discovery 1.0 - ディスカバリエンドポイントの仕様
- RFC 7517 — JSON Web Key (JWK) - JWKセットドキュメントの仕様
- RFC 7515 Section 4.1.4 — "kid" Header Parameter - Key IDの定義
第9章: クライアントの分類と認証方式
第5章の認可コードフローでは、ステップ⑤でクライアント(写真プリントサービス)がclient_secretを送ることで、認可サーバーに対して「自分は正規のクライアントです」と証明していました。
POST https://oauth2.googleapis.com/token
grant_type=authorization_code
&code=abc123
&client_id=写真プリントサービスのID
&client_secret=サービスの秘密鍵 ← これ
&redirect_uri=https://print-service.com/callback
しかし、すべてのアプリケーションがclient_secretを安全に保持できるわけではありません。SPAやモバイルアプリでは、コードがユーザーの手元で動くため、client_secretを埋め込んでも隠しきれないのです。
この章では、クライアントの種類による違いと、それぞれに適した認証方法を整理します。
クライアントタイプ: コンフィデンシャルとパブリック
OAuth 2.0の仕様(RFC 6749 Section 2.1)では、クライアントをクレデンシャルの機密性を維持できるかどうかで2つに分類しています。
【コンフィデンシャルクライアント(Confidential)】
= クレデンシャルの機密性を維持できるクライアント
例: サーバーサイドアプリ(Laravel、Rails、Djangoなど)
→ トークンエンドポイントへのリクエスト時に「クライアント認証」を行う
【パブリッククライアント(Public)】
= クレデンシャルの機密性を維持できないクライアント
例: SPA、モバイルアプリ
→ クライアント認証ができない
この分類の核心は、コードがどこで実行されるかにあります。
【サーバーサイドアプリ(Laravelなど)】
コードの実行場所: 開発者が管理するサーバー
client_secret: サーバー上に安全に保管(環境変数、Secrets Manager等)
トークンリクエストの送信元: サーバー(ユーザーには見えない)
→ client_secretを安全に保持できる = コンフィデンシャルクライアント
【SPA】
コードの実行場所: ユーザーのブラウザ
client_secret: 埋め込む場所がない(JavaScriptはすべて閲覧可能)
トークンリクエストの送信元: ブラウザ(開発者ツールで丸見え)
→ client_secretを安全に保持できない = パブリッククライアント
【モバイルアプリ】
コードの実行場所: ユーザーのデバイス
client_secret: バイナリに埋め込んでもリバースエンジニアリングで解析可能
→ client_secretを安全に保持できない = パブリッククライアント
SPAのJavaScriptは、ブラウザの開発者ツールのSourcesタブでソースコードが読め、Networkタブでリクエストの中身が見えます。環境変数に入れようがビルド時に埋め込もうが、最終的にブラウザに届くJavaScriptの中に含まれてしまいます。
つまり、ユーザーが管理するデバイス上で動くアプリには、真の秘密を持たせることができないのです。
PKCE: client_secretを使えないクライアントのための仕組み
パブリッククライアントはclient_secretを使えません。しかし、認可コードが漏洩したときに第三者がトークンに交換できてしまっては困ります。
PKCE(Proof Key for Code Exchange、ピクシーと読む)は、client_secretの代わりとなる仕組みです(RFC 7636)。
PKCEの仕組み
PKCEは、第4章で触れたハッシュ化の性質(不可逆、元に戻せない)を活用しています。
事前準備(認可リクエストの前):
1. クライアントがランダムな文字列を生成する
→ これを code_verifier と呼ぶ(43〜128文字、暗号学的にランダム)
2. code_verifier をSHA-256でハッシュ化する
→ これを code_challenge と呼ぶ
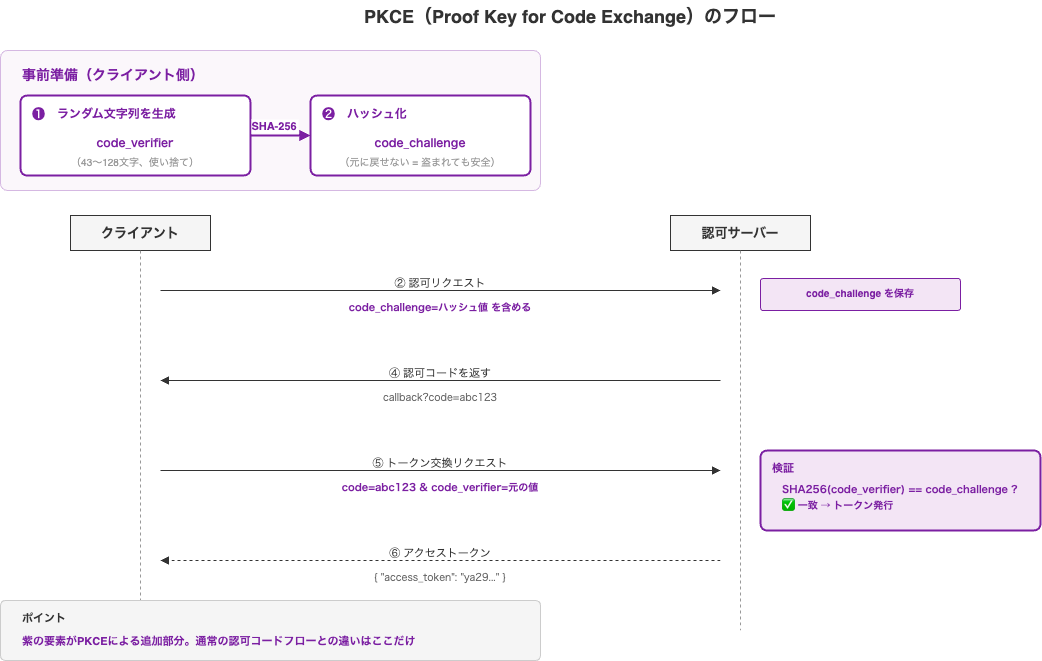
認可コードフロー + PKCE:
【ステップ②】認可リクエスト時に code_challenge を送る
https://accounts.google.com/authorize?
client_id=アプリのID
&scope=photos.readonly
&redirect_uri=https://app.example.com/callback
&response_type=code
&code_challenge=ハッシュ化された値 ← 追加
&code_challenge_method=S256 ← 追加
【ステップ④】認可コードが返ってくる(変更なし)
【ステップ⑤】トークン交換時に code_verifier を送る
POST https://oauth2.googleapis.com/token
grant_type=authorization_code
&code=abc123
&client_id=アプリのID
&code_verifier=元のランダム文字列 ← client_secretの代わり
認可サーバーでの検証:
SHA256(受け取った code_verifier) == 最初に受け取った code_challenge ?
→ ✅ 一致!このクライアントが認可リクエストを開始した本人であると確認できた
→ トークンを発行
なぜPKCEは安全か
-
認可コードが盗まれても →
code_verifierがないとトークンに交換できない -
code_challengeが盗まれても → ハッシュ化されているのでcode_verifierを逆算できない -
code_verifierは毎回使い捨て → 認可フローのたびにランダムに生成するので、コードに埋め込む必要がない
client_secretがアプリに恒久的に埋め込む「パスワード」だとすれば、PKCEのcode_verifierはリクエストのたびに生成する「ワンタイムパスワード」のようなものです。だからこそ、パブリッククライアントでも安全に使えます。
補足: PKCEの適用範囲の拡大
PKCEは当初SPA・モバイルアプリ向けに設計されましたが、現在ではサーバーサイドアプリでもPKCEの併用が推奨されています(RFC 9700)。さらにOAuth 2.1(現在ドラフト段階)では、全クライアントでPKCEが必須になる予定です。
クライアント認証の方式
パブリッククライアントがPKCEを使う一方で、コンフィデンシャルクライアントは「自分は正規のクライアントです」と認可サーバーに証明するクライアント認証を行います。その方式には複数の種類があります。
方式1: client_secretを送る
もっともシンプルな方法です。第5章で見たように、client_secretをリクエストボディに含める方式と、HTTP Basic認証としてヘッダーに含める方式があります。
POST https://as.example.com/token
Authorization: Basic dGVzdF9jbGllbnQ6dGVzdF9zZWNyZXQ=
Basic認証ヘッダーの値はclient_id:client_secretをBase64エンコードしたものです。リクエストボディに含める方式と本質的には同じで、秘密の値を直接送っていることに変わりはありません。
方式2: クライアントアサーション(private_key_jwt)
client_secretを直接送る代わりに、秘密鍵で署名したJWTを認可サーバーに送る方式です(RFC 7523)。
POST https://as.example.com/token
grant_type=authorization_code
&code=abc123
&client_assertion_type=urn:ietf:params:oauth:client-assertion-type:jwt-bearer
&client_assertion=eyJ0eXAi...(秘密鍵で署名したJWT)
認可サーバーは、クライアント登録時に受け取った公開鍵でJWTの署名を検証します。
この方式の最大の利点は、秘密鍵そのものがネットワーク上を流れないことです。client_secretを直接送る方式では、万が一通信が傍受された場合に秘密が漏洩しますが、クライアントアサーションでは署名済みのJWTだけが流れます。
注意: client_secretと秘密鍵は別物
混同しやすいですが、この2つはまったくの別物です。
client_secret = ただの文字列(パスワードのようなもの)
→ client_secretを送る方式で使う
秘密鍵 = 暗号学的な鍵ペアの一方(RSA等)
→ クライアントアサーションでJWTに署名するのに使う
クライアントアサーションと第8章の署名検証: 方向が逆
ここで、第8章のIDトークンの署名検証と見比べてみると、鍵の使い方は同じで方向が逆であることに気づきます。
【第8章: IDトークンの署名検証】
認可サーバー(IdP)が秘密鍵で署名 → クライアントが公開鍵で検証
「このトークンは本当にGoogleが発行したものか?」
【第9章: クライアントアサーション】
クライアントが秘密鍵で署名 → 認可サーバーが公開鍵で検証
「このリクエストは本当に正規のクライアントからか?」
どちらも「署名する側が秘密鍵を持ち、検証する側が公開鍵を持つ」という公開鍵暗号の原則(第0章・第4章)に従っています。同じ仕組みを、立場を入れ替えて使っているだけです。
セキュリティレベルの全体像
ここまでの内容を整理して、クライアントの種類と認証方式の関係をまとめます。
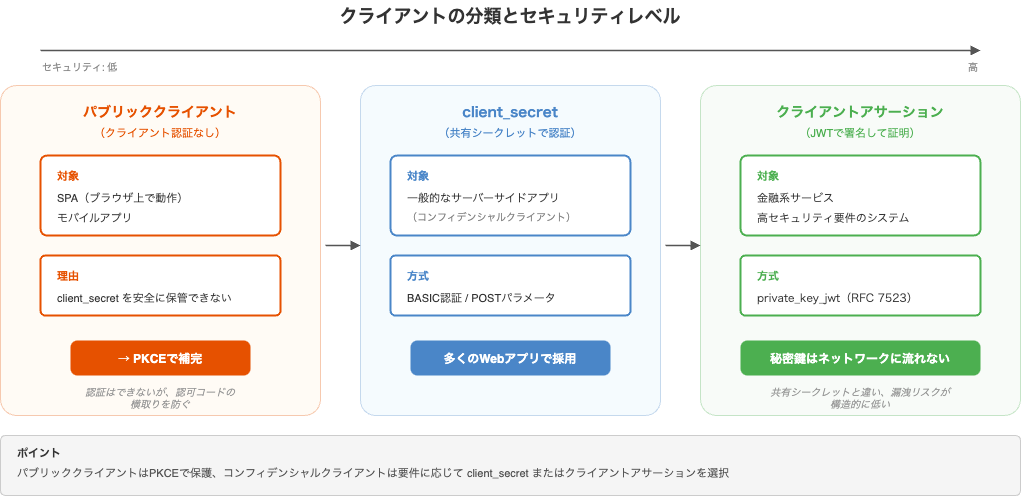
パブリッククライアントはクライアント認証ができない代わりにPKCEで安全性を確保し、コンフィデンシャルクライアントは要件に応じてclient_secretまたはクライアントアサーションを選択します。
この章のポイントを振り返ると、クライアントは「クレデンシャルの機密性を維持できるか」で2つに分かれます。
- パブリッククライアント(SPA、モバイルアプリ)→ PKCEで保護
- コンフィデンシャルクライアント(サーバーサイドアプリ)→ client_secretまたはクライアントアサーションで認証
次は視点を変えて、認可コードフローで取得したアクセストークンを実際にどう使うか——リソースサーバーへの送信方法と、検証の仕組みに入ります。
参考リンク
- RFC 6749 Section 2.1 — Client Types - クライアントタイプの定義
- RFC 7636 — Proof Key for Code Exchange (PKCE) - PKCEの仕様
- RFC 7523 — JWT Profile for Client Authentication - クライアントアサーション
- RFC 9700 — OAuth 2.0 Security Best Current Practice - 全クライアントでのPKCE推奨
- OAuth 2.1 Draft - PKCE必須化の予定
第10章: アクセストークンの利用方式
第9章では、クライアントが認可サーバーに対して自分を証明する方法を見ました。コンフィデンシャルクライアントはclient_secretやクライアントアサーションで認証し、パブリッククライアントはPKCEで保護します。
ここでは、認可コードフローで取得したアクセストークンをどうリソースサーバーに送るかを扱います。送り方は1つではなく、セキュリティ要件に応じた選択肢があります。
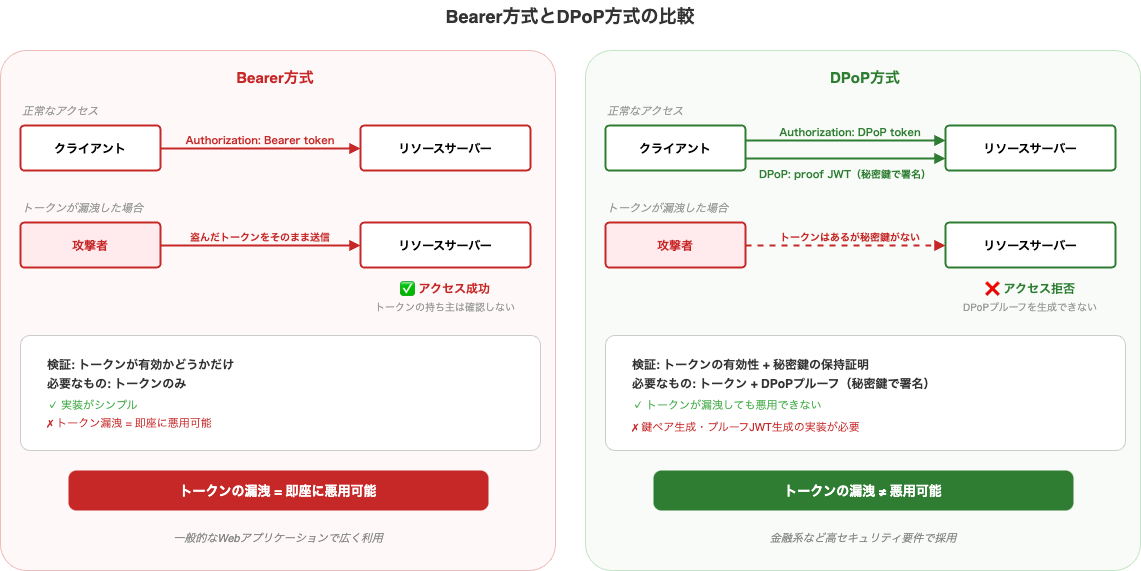
Bearer方式: トークンを持っている人がアクセスできる
もっとも広く使われているのがBearer方式です(RFC 6750)。
GET https://photoslibrary.googleapis.com/v1/mediaItems
Authorization: Bearer ya29.a0AfH6SM...
第5章のステップ⑦で、写真プリントサービスがアクセストークンを使ってGoogleフォトにリクエストする場面がありました。あのとき使っていたのがまさにBearer方式です。
Bearerは「持参人」という意味です。Bearer方式のアクセストークンは、映画のチケットに例えるとわかりやすいでしょう。チケットを持っていれば誰でも映画を観られる — 購入者本人かどうかは問われません。
RFC 6750は、この特性を次のように説明しています。
Any party in possession of a bearer token (a "bearer") can use it to get access to the associated resources (without demonstrating possession of a cryptographic key).
Bearer方式では、トークンを持っているという事実だけでアクセスが許可されます。暗号学的な鍵の保持を証明する必要はありません。
これはシンプルで実装しやすい反面、明確な弱点があります。トークンが漏洩したら、盗んだ人がそのまま使えてしまうのです。
【Bearer方式の弱点】
1. 正規ユーザーがアクセストークンを取得
2. 何らかの理由でトークンが漏洩(ログに残る、通信傍受、XSSなど)
3. 攻撃者がそのトークンをそのまま使う
4. リソースサーバーはトークンが有効かだけを確認 → ✅ アクセス許可
(トークンの「持ち主」が正当かどうかは確認しない)
第7章で学んだ「アクセストークンの有効期限を短くする」対策は、漏洩時の被害期間を限定するものでした。しかし、有効期限内であれば攻撃者のリクエストは通ってしまいます。
DPoP方式: トークンの正当な持ち主であることを証明する
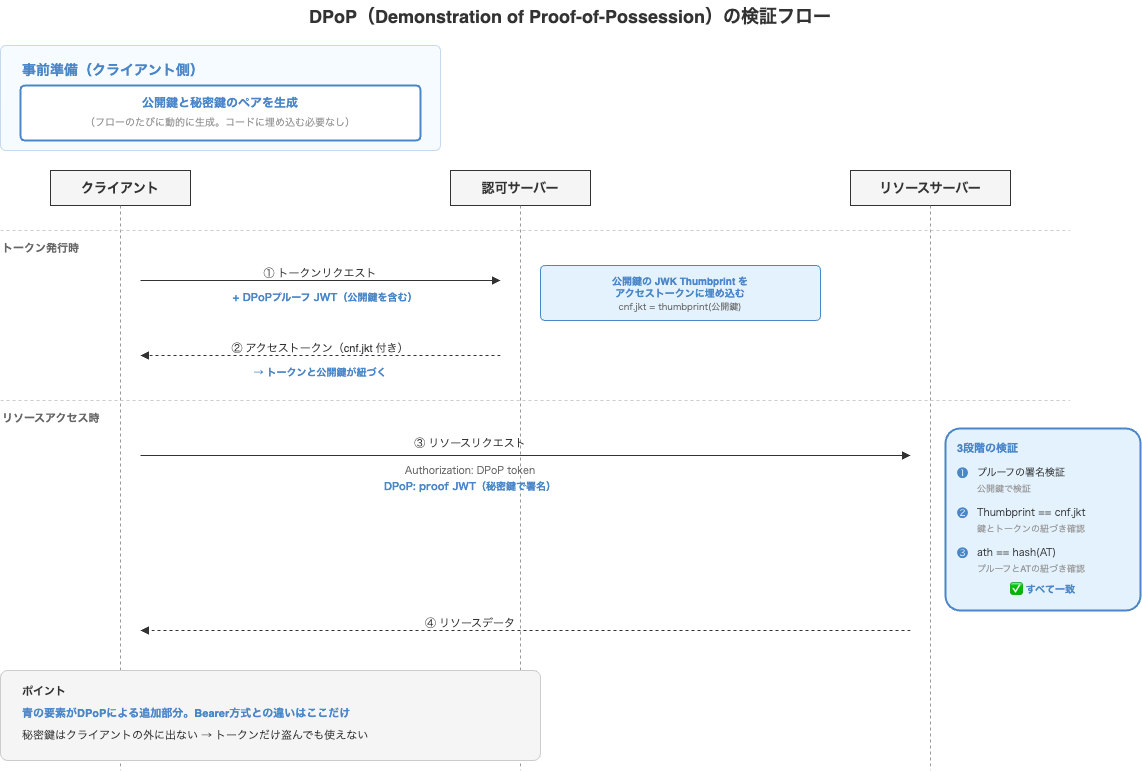
Bearer方式の弱点を克服するために考えられたのがDPoP(Demonstration of Proof-of-Possession、ディーポップ)方式です(RFC 9449)。
DPoP方式では、アクセストークンを持っているだけでは不十分です。そのトークンが自分に発行されたものであることを、秘密鍵で証明する必要があります。
GET https://photoslibrary.googleapis.com/v1/mediaItems
Authorization: DPoP ya29.a0AfH6SM...
DPoP: eyJ0eXAi...(DPoPプルーフJWT)
Bearerの代わりにDPoPスキームを使い、さらにDPoPヘッダーにDPoPプルーフと呼ばれるJWTを添付します。
DPoPの仕組み
DPoPは、第4章で学んだJWTの署名と、第0章で学んだ公開鍵暗号の原理を組み合わせた仕組みです。
事前準備: クライアントが公開鍵と秘密鍵のペアを生成します。PKCEのcode_verifierと同様に、クライアント側で動的に生成するため、コードに埋め込む必要はありません。
トークン発行時(認可サーバーとのやり取り):
1. クライアントが秘密鍵で署名したDPoPプルーフJWTを認可サーバーに送る
(プルーフ内に公開鍵が含まれる)
2. 認可サーバーが公開鍵のフィンガープリント(JWK Thumbprint)を
アクセストークンに埋め込む(cnfクレームのjktフィールド)
→ アクセストークンと公開鍵が紐づく
リソースアクセス時(リソースサーバーでの検証):
1. DPoPプルーフJWT内の公開鍵で署名を検証
→ 「この人は対応する秘密鍵を持っている」
2. その公開鍵のフィンガープリントが、
アクセストークン内のcnf.jktと一致するか確認
→ 「この秘密鍵はこのトークンに紐づいている」
3. DPoPプルーフ内のath(access token hash)が、
提示されたアクセストークンのハッシュと一致するか確認
→ 「このプルーフはこのトークンのために作られた」
3段階の検証をすべてパスしてはじめて、アクセスが許可されます。
なぜDPoPは安全か
【Bearer方式でトークンが盗まれた場合】
攻撃者: トークンを持っている → ✅ アクセスできる
【DPoP方式でトークンが盗まれた場合】
攻撃者: トークンを持っている。しかし秘密鍵を持っていない
→ DPoPプルーフを生成できない → ❌ アクセスできない
DPoPプルーフはリクエストのたびに生成される使い捨てのJWTです。仮にプルーフが盗まれても、秘密鍵がなければ新しいプルーフを作れません。
BearerとDPoPの比較
| Bearer | DPoP | |
|---|---|---|
| 仕組み | トークンを持っていればアクセスできる | トークン + 秘密鍵の保持証明が必要 |
| トークン漏洩時 | 攻撃者がそのまま使える | 秘密鍵がないと使えない |
| 実装の複雑さ | シンプル | 鍵ペア生成・プルーフJWT生成が必要 |
| 利用状況 | 広く普及(ほとんどのAPIがこちら) | 高セキュリティ要件向け(金融系など) |
| RFC | RFC 6750 | RFC 9449 |
一般的なWebアプリケーションではBearer方式で十分なケースがほとんどです。DPoPは、金融系APIなどトークン漏洩のリスクを最小化したい場面で採用されます。
補足: DPoPはクライアント認証ではない
DPoPは「このトークンの正当な持ち主であること」を証明する仕組みであり、第9章で扱った「このクライアントは正規のクライアントであること」を証明するクライアント認証とは別の概念です。RFC 9449でも「The DPoP mechanism presented herein is not a client authentication method.」と明記されています。
| クライアント認証(第9章) | DPoP | |
|---|---|---|
| 目的 | 「私はこのクライアントです」 | 「このトークンは私に発行されたものです」 |
| 証明する相手 | 認可サーバー | 認可サーバー + リソースサーバー |
| RFC | RFC 7523 | RFC 9449 |
ただし、どちらも「秘密鍵で署名し、公開鍵で検証する」という公開鍵暗号の原理は共通しています。第8章のIDトークン署名検証、第9章のクライアントアサーション、そしてDPoP — 同じ仕組みが場面に応じて使い分けられています。
BearerとDPoPをまとめます。
- Bearer方式: トークンを持っている人がアクセスできる。シンプルだが漏洩に弱い
- DPoP方式: トークンに加えて秘密鍵の保持を証明する。漏洩に強いが実装が複雑
OAuth 2.0 / OpenID Connectの仕組みとトークンの扱い方は、ここまででひととおりカバーしました。
さて、第5章の認可コードフローで登場したstateパラメーターを覚えているでしょうか。「CSRF対策のランダム文字列」とだけ説明して先送りにしていました。次の章では、CSRF(Cross-Site Request Forgery)とは何か、なぜstateパラメーターが必要なのかを扱います。
参考リンク
- RFC 6750 — OAuth 2.0 Bearer Token Usage - Bearer方式の仕様
- RFC 9449 — OAuth 2.0 Demonstrating Proof of Possession (DPoP) - DPoP方式の仕様
第11章: Webセキュリティ - CSRF対策
第5章の認可コードフローで、認可リクエストにstateパラメーターを含めていました。「CSRF対策のランダム文字列」とだけ書いて先送りにしていた部分です。ここでは、CSRF(Cross-Site Request Forgery)の仕組みと、stateパラメーターの役割、そして主要な対策手法を扱います。
CSRFとは: ブラウザのCookie自動送信を悪用する攻撃
まず、CSRFの仕組みを具体例で見てみます。

正常なリクエスト:
ユーザー → 銀行サイト(bank.example.com)にログイン
ユーザー → 送金フォームから送信
ブラウザ → セッションCookieを自動付与 → bank.example.comに送信
→ ✅ ユーザーの意図どおりの送金
CSRF攻撃:
ユーザー → 銀行サイトにログイン済み(セッションCookieがブラウザに残っている)
ユーザー → 攻撃者のサイト(evil.example.com)にアクセス
攻撃者のサイト → 銀行サイトへの送金リクエストを自動で送信
ブラウザ → セッションCookieを自動付与 → bank.example.comに送信
→ ❌ ユーザーの意図しない送金が実行される
攻撃者のサイトに以下のような隠しフォームが仕込まれていると想像してください。
<!-- evil.example.com のページに埋め込まれた隠しフォーム -->
<form action="https://bank.example.com/transfer" method="POST">
<input type="hidden" name="to" value="attacker_account">
<input type="hidden" name="amount" value="1000000">
</form>
<script>document.forms[0].submit();</script>
ユーザーがこのページを開いた瞬間、JavaScriptがフォームを自動送信します。ブラウザは送信先がbank.example.comであることを見て、そのドメインに紐づくセッションCookieを自動的に付与します。銀行サーバーから見ると、正規のユーザーからの正規のリクエストと区別がつきません。
CSRFの根本原因は、ブラウザがCookieをリクエスト先のドメインに自動で付与する仕組みにあります。第2章でセッションベース認証を学んだとき、「ブラウザは、該当ドメインのCookieを自動で付与してくれる」と説明しました。この便利な仕組みが、CSRFでは攻撃ベクトルになってしまうのです。
OAuthにおけるCSRF: stateパラメーターの役割
CSRFは銀行の送金だけの話ではありません。第5章で見たOAuth 2.0の認可コードフローにもCSRFのリスクがあります。
攻撃シナリオ: ログインCSRF
1. 攻撃者が自分のGoogleアカウントで認可フローを開始する
2. 認可コードを含むコールバックURLを取得する
https://print-service.com/callback?code=攻撃者の認可コード
3. このURLをユーザーに踏ませる(メール、チャットなど)
4. ユーザーのブラウザが写真プリントサービスにリクエストを送信
→ ブラウザはユーザーのセッションCookieを自動付与
→ 写真プリントサービスは攻撃者の認可コードをトークンに交換
→ ユーザーのアカウントに攻撃者のGoogleアカウントが紐づく
5. 攻撃者は自分のGoogleアカウントでログインすれば、
ユーザーのアカウントにアクセスできてしまう
stateパラメーターはこの攻撃を防ぎます。
【stateパラメーターによる防御】
① 認可リクエスト時:
クライアントがランダムな state を生成し、セッションに保存
→ state=xyz123 を認可リクエストに含める
② コールバック受信時:
受け取った state と、セッションに保存した state を照合
→ 攻撃者のURLには攻撃者のstateが含まれるが、
ユーザーのセッションに保存されたstateとは一致しない
→ ❌ 不一致 → リクエストを拒否
仕組みとしては、このあとで紹介するCSRFトークンと同じ原理です。サーバーが発行した秘密の値をセッションに紐づけ、リクエスト時に照合することで「このリクエストは正規のフローで開始されたものか」を検証します。
対策手法
CSRFの対策にはいくつかの手法があり、それぞれ異なるレイヤーで防御します。ここでは主要な3つを紹介します。
対策1: SameSite Cookie
CookieにSameSite属性を付けることで、クロスサイトリクエスト時にCookieを送るかどうかを制御できます(RFC 6265bis)。
Set-Cookie: session_id=abc123; SameSite=Lax; Secure; HttpOnly
| 値 | 動作 | ユースケース |
|---|---|---|
Strict |
外部サイトからのリクエストには一切Cookieを送らない | 銀行・金融系 |
Lax |
外部サイトからのPOST等にはCookieを送らない | 一般的なWebアプリ |
None |
常にCookieを送る(Secure必須) |
サードパーティ連携 |
Laxをもう少し詳しく見てみましょう。
【SameSite=Lax の動作】
Cookieが送られる:
✅ 同一サイトからのリクエスト(全メソッド)
✅ 外部サイトからの GET による画面遷移(リンクのクリックなど)
Cookieが送られない:
❌ 外部サイトからのPOSTリクエスト ← CSRF攻撃の主要パターン
❌ 外部サイトからの img, iframe 等のサブリソースリクエスト
先ほどの銀行の例では、攻撃者のサイトからPOSTで送金リクエストが送られます。SameSite=Laxであれば、この外部サイトからのPOSTにはCookieが付与されないため、攻撃は成立しません。
Chrome 80以降、SameSiteを指定していないCookieはLaxとして扱われるようになりました(Firefox、Edgeも同様)。つまり、とくに何も設定しなくても、モダンブラウザではCSRFの主要な攻撃パターンが自動的にブロックされています。
補足: Strictのデメリット
Strictはもっとも安全ですが、外部サイトのリンクからアクセスした場合にもCookieが送られません。たとえばメールに貼られたリンクをクリックして自社サービスにアクセスしたとき、ログイン状態が維持されず再ログインを求められます。このため、ユーザー体験を重視する一般的なWebアプリではLaxが現実的な選択肢です。
対策2: CSRFトークン(Synchronizer Token Pattern)
伝統的かつ確実な対策です。サーバーがフォーム表示時にランダムなトークンを埋め込み、送信時に照合します。
<!-- サーバーがフォームにトークンを埋め込む -->
<form action="/transfer" method="POST">
<input type="hidden" name="_token" value="ランダムな値">
<input type="text" name="amount" value="10000">
<button type="submit">送金</button>
</form>
サーバー: フォーム表示時にランダムなトークンを生成し、セッションに保存
→ フォームの hidden フィールドにもトークンを埋め込む
ユーザー: フォームを送信
→ トークンがリクエストに含まれる
サーバー: リクエスト内のトークンとセッション内のトークンを照合
→ ✅ 一致 → 正規のリクエスト
→ ❌ 不一致 → 拒否
なぜ攻撃者はトークンを知ることができないのでしょうか。攻撃者が銀行サイトのフォームを取得しようとしても、Same-Origin Policy(次章で解説)がクロスオリジンのレスポンスの読み取りをブロックするため、フォームに埋め込まれたトークンの値を知ることができないのです。
対策3: カスタムヘッダーによるプリフライト保護(SPA向け)
SPAがAPIにリクエストを送る際、カスタムヘッダーやContent-Type: application/jsonを使うと、ブラウザがCORSプリフライト(OPTIONSリクエスト)を送信します。
【HTMLフォーム(simple request)】
Content-Type: application/x-www-form-urlencoded
→ プリフライトなし → リクエストがそのまま送られる
【SPAのAPIリクエスト(non-simple request)】
Content-Type: application/json
→ プリフライト発動 → サーバーが許可しなければリクエストは送られない
攻撃者のサイトからは通常のHTMLフォームでしかリクエストを送れません(フォームではContent-Type: application/jsonを指定できない)。JavaScriptでfetchを使おうとしても、CORSの仕組みがクロスオリジンのリクエストを制限します。
ただし、この防御はサーバーのCORS設定が適切であることが前提です。Access-Control-Allow-Origin: *のような緩い設定では無効になります。CORSの仕組みは次章で詳しく解説します。
補足: CORSプリフライトとは何か
ブラウザは、クロスオリジンのリクエストが「単純リクエスト(simple request)」の条件を満たさない場合、実際のリクエストを送る前にOPTIONSメソッドで「このリクエストを送ってもいいですか?」とサーバーに問い合わせます。これがプリフライトリクエストです。
【プリフライトの流れ】
① ブラウザ → サーバー(OPTIONSリクエスト)
Origin: https://evil.example.com
Access-Control-Request-Method: POST
Access-Control-Request-Headers: Content-Type
② サーバー → ブラウザ(プリフライトへの応答)
Access-Control-Allow-Origin: https://myapp.example.com ← 許可するオリジン
Access-Control-Allow-Methods: POST
Access-Control-Allow-Headers: Content-Type
③ ブラウザがOriginと許可リストを照合
→ evil.example.com は許可されていない
→ ❌ 実際のPOSTリクエストは送信されない
「単純リクエスト」とみなされるのは、メソッドがGET/HEAD/POSTで、かつヘッダーがAccept、Content-Type(ただしapplication/x-www-form-urlencoded、multipart/form-data、text/plainのみ)などに限られる場合です。Content-Type: application/jsonやカスタムヘッダー(X-Requested-Withなど)を付けると単純リクエストの条件を満たさなくなり、プリフライトが発動します。
つまり、SPAがContent-Type: application/jsonでAPIを呼ぶだけで、攻撃者のサイトからの不正なリクエストはプリフライトの段階でブロックされるのです。
多層防御(Defense in Depth)
CSRFの対策手法を見てきましたが、どれか1つで万全というわけではありません。OWASPは多層防御のアプローチを推奨しています。
【推奨される組み合わせ】
SameSite Cookie → ブラウザレベルでのCSRF自動ブロック(ベースライン)
+ CSRFトークン → アプリケーションレベルでの確実な検証
+ Originヘッダー検証 → リクエスト元の追加チェック
複数のレイヤーで防御することで、1つの対策に穴があっても別のレイヤーが攻撃を防ぎます。
この章の要点をまとめます。
- CSRFの本質: ブラウザがCookieを自動送信する仕組みの悪用
- OAuthのstateパラメーター: ログインCSRFを防ぐCSRFトークンの一種
- 主要な対策: SameSite Cookie、CSRFトークン、カスタムヘッダーによるプリフライト保護
- 多層防御: 複数の対策を組み合わせる
対策の中で「Same-Origin Policy」「CORS」「プリフライト」という言葉が繰り返し出てきました。次の章でこれらを正面から扱います。
参考リンク
- OWASP CSRF Prevention Cheat Sheet - CSRF対策の網羅的ガイド
- RFC 6265bis — Cookies: HTTP State Management Mechanism - SameSite Cookieの仕様
- MDN — CSRF - CSRFの概要と対策
第12章: Webセキュリティ — Same-Origin PolicyとCORS
前章のCSRF対策で、「Same-Origin Policy」「CORS」「プリフライト」が繰り返し出てきました。改めて整理します。
Same-Origin Policy(SOP)はブラウザのセキュリティの土台であり、CORSはその制限を選択的に緩和する仕組みです。これらが何を守り、何を守らないのかを正確に理解することで、前章のCSRF対策やこのあとのSPAの認証パターンの話がすっきりつながります。
Originの定義
まず「Origin(オリジン)」の定義を押さえます。OriginはRFC 6454で定義されており、スキーム + ホスト + ポートの3つの組み合わせです。
https://example.com:443/path?q=1
└scheme┘└──host───┘└port┘
Origin = (https, example.com, 443)
パスやクエリパラメータ-はOriginに含まれません。URLが異なっていても、この3つが一致すれば「同一オリジン」です。
| URL A | URL B | 同一? | 理由 |
|---|---|---|---|
https://example.com/a |
https://example.com/b |
✅ | パスは関係ない |
https://example.com |
http://example.com |
❌ | スキームが異なる |
https://example.com |
https://api.example.com |
❌ | ホストが異なる |
https://example.com:443 |
https://example.com |
✅ | 443はHTTPSのデフォルト |
https://example.com:8080 |
https://example.com |
❌ | ポートが異なる |
Same-Origin Policy: 何をブロックし、何をブロックしないのか
Same-Origin Policy(SOP)はブラウザに組み込まれたセキュリティ機構です。核心をひと言でいうと、クロスオリジンのレスポンス読み取りをブロックするものです。
ここで重要なのは、SOPはリクエストの送信を止めるわけではないという点です。
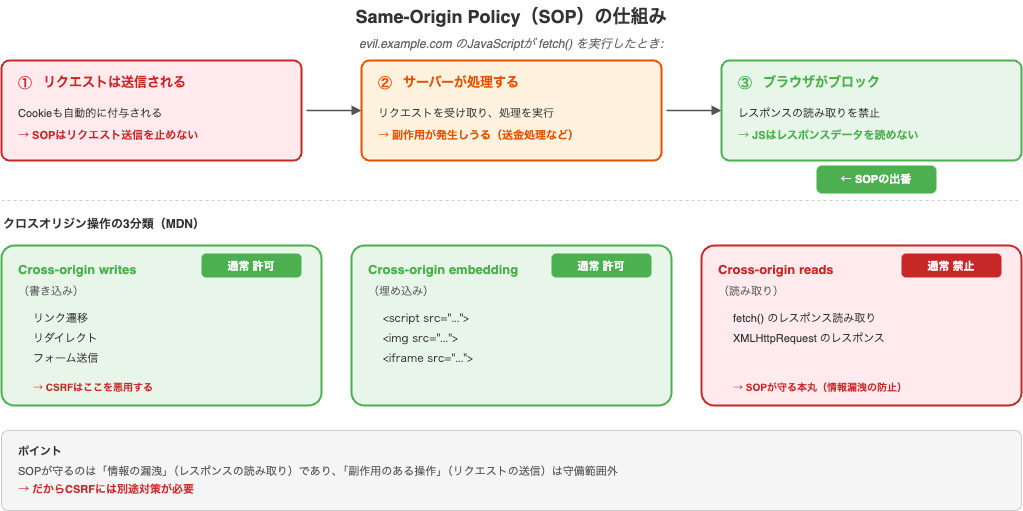
前章でCSRF攻撃が成立する理由を思い出してください。HTMLフォームによる送金リクエストは「cross-origin write」にあたるため、SOPでは許可されます。SOPが守るのは情報の漏洩(レスポンスの読み取り)であり、副作用のある操作(状態変更リクエストの送信)は守備範囲外なのです。だからこそ、CSRFには別途対策が必要でした。
CORS: SOPの制限を選択的に緩和する
SOPのおかげで、クロスオリジンのレスポンス読み取りはブロックされます。しかし、正当な理由でクロスオリジン通信が必要な場面は多くあります。たとえば、app.example.comのSPAがapi.example.comのAPIを呼び出す場合です。
そこで使われるのがCORS(Cross-Origin Resource Sharing)です。サーバー側が「このオリジンからのリクエストは許可する」と明示する仕組みです。
① ブラウザ → サーバーにリクエスト送信
Origin: https://app.example.com
② サーバー → レスポンスに許可ヘッダーを付与
Access-Control-Allow-Origin: https://app.example.com
③ ブラウザ → Originが許可リストに含まれているか確認
→ ✅ 含まれている → レスポンスをJavaScriptに渡す
→ ❌ 含まれていない → レスポンスをブロック
見落としやすいポイントがあります。CORSはセキュリティを追加するものではなく、SOPの制限を緩和するものです。サーバーにAccess-Control-Allow-Originを設定するということは、「このオリジンからのクロスオリジンアクセスを許可します」という制限の解除を意味します。
Simple RequestとPreflight Request
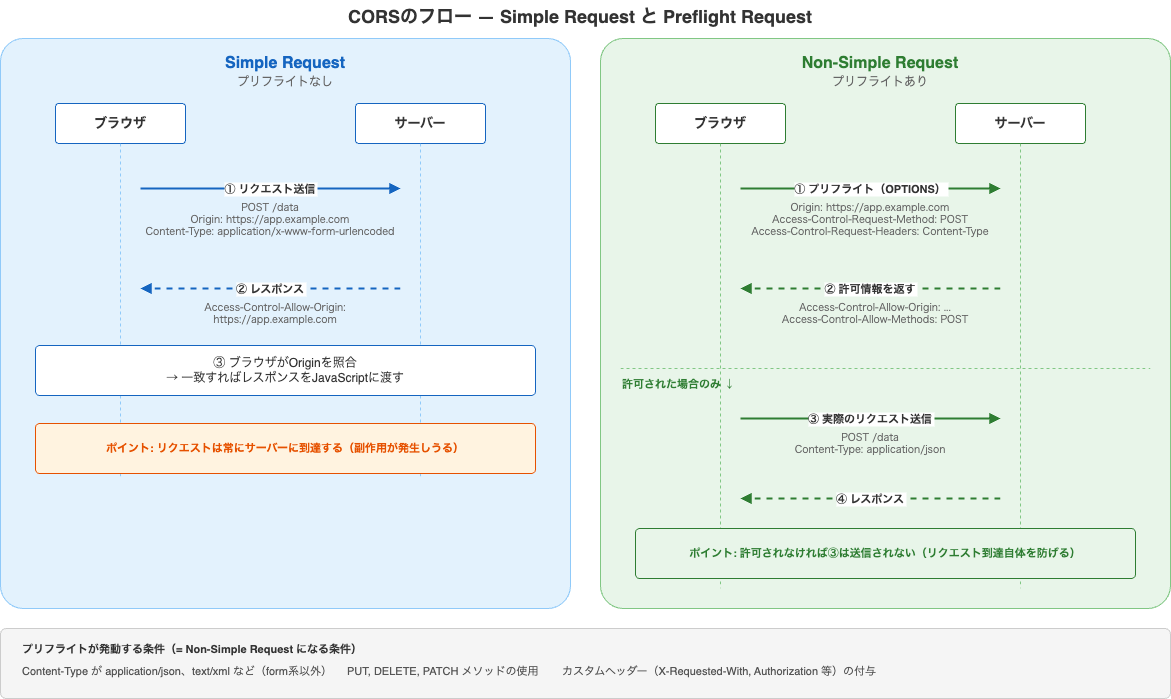
前章でプリフライトの概念を紹介しましたが、ここではCORSの文脈でもう少し体系的に整理します。
ブラウザはクロスオリジンリクエストをSimple RequestとNon-Simple Requestに分類し、後者にはプリフライトを送信します。
Simple Requestの条件(すべてを満たす場合):
① メソッド: GET, HEAD, POST のいずれか
② ヘッダー: CORS-safelisted request-headerのみ
- Accept, Accept-Language, Content-Language
- Content-Type(値が以下のいずれか):
application/x-www-form-urlencoded
multipart/form-data
text/plain
③ ReadableStreamがリクエストボディに使われていない
この条件をひとつでも満たさないと、ブラウザはプリフライト(OPTIONSリクエスト)を送信します。
【Simple Request — プリフライトなし】
ブラウザ サーバー
│ │
│─── POST /data ───────────────────→ │
│ Origin: https://app.example.com │
│ Content-Type: application/ │
│ x-www-form-urlencoded │
│ │
│ ←── 200 OK ──────────────────── │
│ Access-Control-Allow-Origin: │
│ https://app.example.com │
│ │
ブラウザ: Originが許可されている → レスポンスをJSに渡す
【Non-Simple Request — プリフライトあり】
ブラウザ サーバー
│ │
│─── OPTIONS /data(プリフライト)──→ │
│ Origin: https://app.example.com │
│ Access-Control-Request-Method: │
│ POST │
│ Access-Control-Request-Headers: │
│ Content-Type │
│ │
│ ←── 204 ─────────────────────── │
│ Access-Control-Allow-Origin: │
│ https://app.example.com │
│ Access-Control-Allow-Methods: │
│ POST │
│ Access-Control-Allow-Headers: │
│ Content-Type │
│ │
ブラウザ: 許可を確認 → 実際のリクエストを送信
│ │
│─── POST /data(実際のリクエスト)──→ │
│ Content-Type: application/json │
│ │
│ ←── 200 OK ──────────────────── │
プリフライトの重要な特性は、サーバーが許可しなければ実際のリクエスト自体が送信されないことです。Simple Requestでは「リクエストは送信され、レスポンスの読み取りだけがブロックされる」のに対し、プリフライトではリクエストの送信自体を止められます。
補足: なぜSimple Requestにはプリフライトがないのか
HTMLフォームで送信できるリクエスト(GET/POST、application/x-www-form-urlencodedなど)は、CORSという仕組みが生まれる前からクロスオリジンで送信できていました。もともと送信できていたものに対して、いまさらプリフライトを追加しても新たな保護にはなりません。そのため、互換性を維持してそのままにしています。
逆にいえば、Content-Type: application/jsonやカスタムヘッダーを使ったリクエストは、従来のHTMLフォームでは送信できなかったものです。こうした「新しい種類」のクロスオリジンリクエストに対してのみ、プリフライトで事前確認を行うという設計です。
CORSとCredentials(Cookie)
クロスオリジンリクエストでCookieを送る場合、クライアント側とサーバー側の両方で明示的な設定が必要です。
// クライアント側: credentials オプションを指定
fetch('https://api.example.com/data', {
credentials: 'include' // デフォルトは 'same-origin'
})
// サーバー側: 以下のヘッダーを返す
Access-Control-Allow-Origin: https://app.example.com ← ワイルドカード不可
Access-Control-Allow-Credentials: true
ここで注意すべきは、Credentialsリクエストではワイルドカード(*)が使えないという制約です。
| ヘッダー |
* 使用可? |
|---|---|
Access-Control-Allow-Origin |
❌ 明示的なオリジン指定が必要 |
Access-Control-Allow-Headers |
❌ |
Access-Control-Allow-Methods |
❌ |
Access-Control-Expose-Headers |
❌ |
この制約は、Cookieを含むリクエストに対して「どのオリジンでもOK」という緩い許可を出せないようにするためのものです。Access-Control-Allow-Origin: *とAccess-Control-Allow-Credentials: trueを同時に指定すると、ブラウザはリクエストをブロックします。
SOP・CORS・CSRFの関係を整理する
SOP・CORS・CSRFの関係をまとめます。
【SOP(Same-Origin Policy)】
役割: クロスオリジンのレスポンス読み取りをブロック
限界: リクエストの送信自体は止めない → CSRFは防げない
【CORS(Cross-Origin Resource Sharing)】
役割: SOPの制限を選択的に緩和する
注意: セキュリティを「追加」するのではなく「緩和」する仕組み
間接効果: プリフライトにより、non-simple requestの送信自体を止められる
【CSRF対策】
SOPだけでは不十分 → 別途対策が必要:
→ SameSite Cookie(ブラウザレベル)
→ CSRFトークン(アプリケーションレベル)
→ カスタムヘッダー + プリフライト(SPA向け)
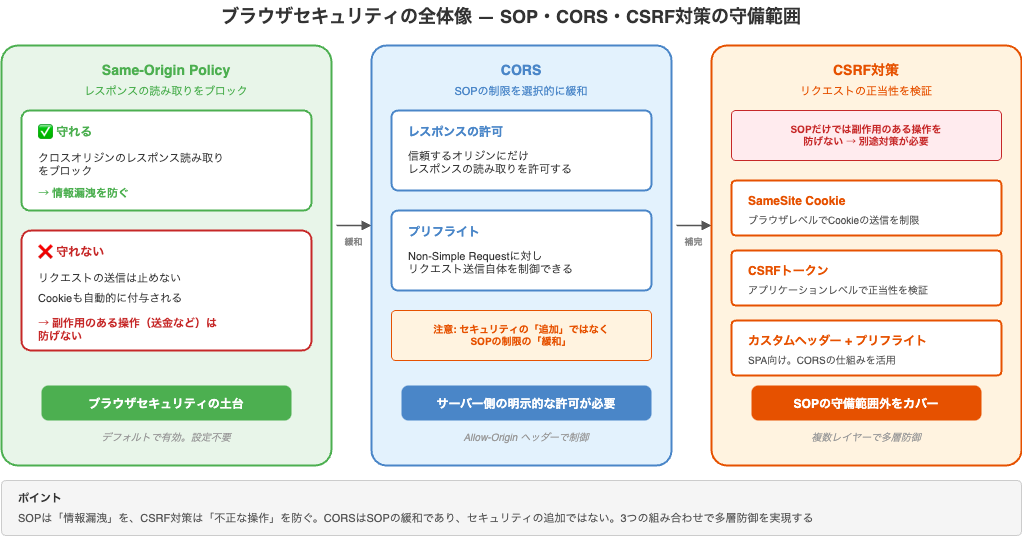
よくある誤解:
- ❌「SOPがあるからクロスオリジンのリクエストは送れない」→ 送れる。止めるのはレスポンスの読み取り
- ❌「CORSを設定するとセキュリティが強化される」→ CORSはSOPの制限を緩めるもの。設定するほどオープンになる
- ❌「SOPがあればCSRFは防げる」→ SOPはレスポンスの読み取りを守る。CSRFが悪用するのは副作用のある操作の送信
この章で扱った内容をまとめます。
- Origin: スキーム + ホスト + ポートの3つ組
- SOP: クロスオリジンのレスポンス読み取りをブロック(リクエスト送信は止めない)
- CORS: サーバーがクロスオリジンアクセスを選択的に許可する仕組み(SOPの緩和)
- プリフライト: Non-Simple Requestに対して事前確認を行い、許可されなければリクエスト自体を送信しない
- Credentials: Cookieを送るにはクライアント・サーバー双方の明示的な設定が必要
第11〜12章でWebセキュリティの基盤が揃いました。次の章では、これらの知識を総合して、SPAにおける認証パターンに入ります。「トークンをどこに保存するか」「BFFとは何か」など実践に近いテーマです。
参考リンク
- RFC 6454 — The Web Origin Concept - Originの定義
- WHATWG Fetch Standard - CORSとプリフライトの仕様
- MDN — Same-origin policy - SOPの動作と例外
- MDN — Cross-Origin Resource Sharing (CORS) - CORSの解説
第13章: SPAにおける認証パターン
OAuth 2.0のフロー、トークンの種類と使い方、CSRFやSOP/CORS。ここまでの知識を総合して、この章ではSPAにおける認証・認可の実装パターンを扱います。
第9章で触れたとおり、SPAはパブリッククライアントです。ソースコードがブラウザ上で丸見えであり、client_secretを安全に保持できません。ではSPAでOAuth 2.0を使うとき、トークンはどこに保管すればよいのでしょうか。この問いに対して、OAuth WGは「OAuth 2.0 for Browser-Based Applications」(draft-ietf-oauth-browser-based-apps)で具体的なアーキテクチャパターンを示しています。
SPAの課題を整理する
まず、SPAが認証・認可を実装する際に直面する課題を整理します。
【SPAの制約】
① client_secretを保持できない
→ JavaScriptのソースコードはブラウザで読める
→ コンフィデンシャルクライアントにはなれない
② トークンの保管場所が限られる
→ ブラウザ環境にはサーバーのような安全なストレージがない
③ XSS脆弱性のリスク
→ XSSが成功すると、ブラウザ内のトークンが盗まれうる
これらの制約をどう扱うかによって、アーキテクチャの選択が変わります。
3つのアーキテクチャパターン
draft-ietf-oauth-browser-based-appsは、セキュリティの高い順に3つのパターンを定義しています。
| パターン | 概要 | トークンの所在 |
|---|---|---|
| BFF(Backend for Frontend) | SPAの裏にバックエンドを置く | サーバー側 |
| Token-Mediating Backend | バックエンドがトークンの保管・中継を担当 | サーバー側 |
| 直接OAuthフロー | SPAがパブリッククライアントとして直接処理 | ブラウザ内 |
この記事ではもっとも推奨されるBFFパターンを中心に解説し、直接OAuthフローについても触れます。
BFFパターン: もっとも推奨されるアプローチ
BFF(Backend for Frontend)パターンは、SPAの背後にバックエンドサーバーを配置し、OAuthのフローとトークン管理をすべてサーバー側に閉じ込めるアーキテクチャです。draft-ietf-oauth-browser-based-appsでstrongly recommendedとされています。
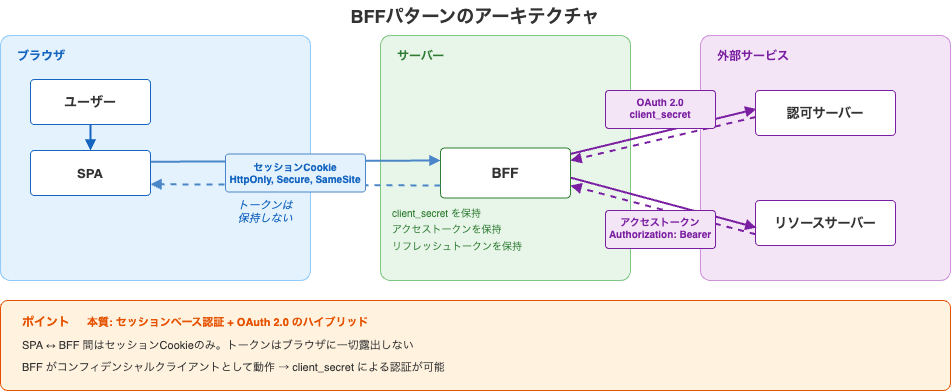
ユーザー ←→ SPA ←→ BFF ←→ 認可サーバー / リソースサーバー
│ │
│ ├─ コンフィデンシャルクライアントとして動作
│ ├─ client_secretを安全に保持
│ ├─ アクセストークン・リフレッシュトークンを保持
│ └─ リソースサーバーへのAPIリクエストを代行
│
└─ BFFとの間はセッションCookie(HttpOnly, Secure, SameSite)
この構成のポイントは、BFFがSPA ↔ 外部サービスの間に立って、2つの異なる認証方式を橋渡しすることです。
SPA ↔ BFF間: セッションベース認証(HttpOnly Cookie)
BFF ↔ 認可サーバー間: OAuth 2.0(コンフィデンシャルクライアント)
BFF ↔ リソースサーバー間: アクセストークンによるAPIアクセス
第2章で学んだセッションベース認証と、第5章以降で学んだOAuth 2.0が、ここでひとつに合流します。BFFパターンの本質は「セッションベース認証 + OAuth 2.0のハイブリッド」なのです。
メリット:
- トークンがブラウザに一切露出しない → XSSでトークンが盗まれるリスクがない
- BFFはサーバー上で動作するため、
client_secretを安全に保持できる - セッションCookieのセキュリティ属性(
HttpOnly,Secure,SameSite)を活用できる
デメリット:
- バックエンドサーバーの構築・運用が必要
- SPAの「バックエンドが不要」というシンプルさが薄れる
補足: 「BFFを新たに立てる必要があるのか?」
SPA + バックエンドAPI(DB操作用)という構成ですでに開発しているなら、そのバックエンドAPIにOAuthフローの責務を追加すれば、それがBFFになります。
【既存構成】
SPA ←Cookie→ バックエンドAPI ←→ DB
【OAuth追加後(バックエンドAPIがBFFを兼ねる)】
SPA ←Cookie→ バックエンドAPI ←→ DB
│
├←→ 認可サーバー(トークン交換)
└──→ リソースサーバー(外部API呼び出し)
バックエンドAPIはもともとサーバー上で動作しており、client_secretを安全に保持できます。SPA ↔ バックエンドAPI間は既存のセッションCookieをそのまま使えます。「BFFパターンの採用」というと大がかりに聞こえますが、この構成であれば自然な拡張です。
また、Next.jsやNuxt.jsなどのフルスタックフレームワークを使っている場合、そのサーバー機能をBFFとして活用できます。
直接OAuthフロー: トークンはどこに保管するか
BFFを使わず、SPAが直接パブリッククライアントとしてOAuthフローを行う場合、トークンをブラウザ内に保管する必要があります。保管場所にはそれぞれトレードオフがあります。
| 保管場所 | XSS耐性 | 永続性 | 補足 |
|---|---|---|---|
| メモリ(JavaScript変数) | 高(ただし完全ではない) | なし(リロードで消失) | ドラフトでもっともセキュアとされる |
| HttpOnly Cookie | 高(JSからアクセス不可) | あり | CSRF対策が別途必要 |
| localStorage | 低(XSSで読み取り可能) | あり | ドラフトSection 8で非推奨の傾向 |
| sessionStorage | 低(XSSで読み取り可能) | タブ内のみ | localStorageと同様の問題 |
メモリ内保管がもっともセキュアですが、ページリロードのたびにトークンが消失するため、再認証が必要になるトレードオフがあります。
ここで注意すべきは、メモリ保管も完全な防御ではないという点です。XSSが成功した場合、攻撃者のJavaScriptはアプリケーションと同じコンテキストで実行されるため、実行中のメモリ内トークンも抽出される可能性があります。
つまり、保管場所の選択でリスクを低減することはできますが、根本的な対策はXSS脆弱性自体を作らないことです。
SPAにおけるOAuth 2.0の必須要件
パブリッククライアントとしてSPAが直接OAuthフローを行う場合、以下が必須です。
PKCE(必須):
第9章で解説したPKCEは、SPAでは必須です(RFC 9700 Section 2.1.1)。認可コードフローのたびにcode_verifierとcode_challengeを生成し、認可コードの横取りを防ぎます。
リフレッシュトークンの保護(必須):
パブリッククライアントのリフレッシュトークンには、以下のいずれかが必須です(RFC 9700 Section 2.2.2)。
① リフレッシュトークンローテーション
→ トークンを使うたびに新しいトークンを発行
→ 盗まれたトークンの再利用を検知できる
② sender-constrained refresh tokens
→ DPoP等で送信者を制約
→ 盗まれても別の送信者からは使えない
実務上はローテーションのほうが広くサポートされています。
パターンの選び方
【BFFパターンを選ぶべきケース】
- ビジネスアプリケーション、個人データを扱うアプリ
- 金融系など高セキュリティ要件
- バックエンドサーバーを構築・運用できるリソースがある
→ ドラフトで "strongly recommended"
【直接OAuthフローを選ぶケース】
- 静的サイトホスティングのみ(バックエンド構築のリソースがない)
- 扱うデータの機密性が比較的低い
→ PKCE必須、リフレッシュトークンのrotation or sender-constrained必須
→ トークンがブラウザ内に存在するリスクを受け入れる
迷ったらBFFパターンを選ぶのが安全です。とくにSPA + バックエンドAPIという構成であれば、BFFは自然な拡張として導入できます。
SPAにおける認証パターンの要点です。
-
SPAの課題:
client_secretを保持できない、トークンの保管場所が限られる、XSSリスク - BFFパターン: サーバー側にトークン管理を閉じ込める。セッションベース認証 + OAuth 2.0のハイブリッド
- 直接OAuthフロー: トークンがブラウザ内に存在する。メモリ保管がもっともセキュアだが完全ではない
- 根本対策: どのパターンでもXSS脆弱性を作らないことが最重要
最後に、これまでの全体像をまとめます。
参考リンク
- OAuth 2.0 for Browser-Based Applications (draft-ietf-oauth-browser-based-apps) - SPAにおけるOAuth実装の公式ガイド
- RFC 9700 — OAuth 2.0 Security Best Current Practice - パブリッククライアントのPKCE必須化、リフレッシュトークン要件
第14章: 全体のまとめ
第0章から第13章まで、認証・認可の基礎から実装パターンまでを一本の流れで追ってきました。全体像を俯瞰して整理します。
全体マップ
この記事で扱った技術要素は、以下のようなレイヤー構造で整理できます。

下のレイヤーが上のレイヤーの土台になっています。第0章の前提知識がないとJWTの署名検証が理解できず、セッションベース認証を知らないとBFFパターンの本質が見えない、というように、各章が積み重なって全体像を構成しています。
各レイヤーの要点
基礎概念(第0〜1章)
認証(あなたは誰か)と認可(あなたに何が許されているか)の区別が出発点でした。ここが曖昧だと、OAuth 2.0が「認可」のフレームワークであること、OpenID Connectが「認証」を追加するものであることの意味が見えてきません。
Web認証方式(第2〜4章)
セッションベース認証は「サーバーが状態を持つ」方式、トークンベース認証は「クライアントが状態を持つ」方式でした。JWTはトークンの代表的な形式であり、ヘッダー・ペイロード・署名の3パートで構成されます。
OAuth 2.0 / OpenID Connect(第5〜10章)
記事の中核です。OAuth 2.0の認可コードフロー、OpenID Connectによる認証の追加、3つのトークンの役割、署名検証、クライアントの分類と認証方式、アクセストークンの利用方式(Bearer vs DPoP)——ここまでを段階的に積み上げてきました。
Webセキュリティ(第11〜12章)
CSRFの本質は「ブラウザのCookie自動送信」にある。SOPは「レスポンスの読み取り」をブロックするがリクエストの送信は止めない。CORSはSOPの「緩和」であり「強化」ではない。いずれもよく誤解されるポイントですが、ここを正確に押さえておくと、セキュリティ対策の選択に根拠が持てます。
実装パターン(第13章)
最終的に、これらの知識はSPAの認証パターンに合流しました。BFFパターンは第2章のセッションベース認証と第5章のOAuth 2.0を組み合わせたハイブリッドであり、ここまでの学習が実践的な設計判断につながります。
実務での選択指針
| ケース | 推奨構成 |
|---|---|
| 従来型Webアプリ(サーバーレンダリング) | セッションベース認証 + SameSite Cookie + CSRF対策 |
| SPA + バックエンドAPI | BFFパターン。トークンはサーバー側で管理 |
| SPA(バックエンドなし) | PKCE + リフレッシュトークンローテーション + メモリ内トークン保管 |
| 高セキュリティ要件(金融系等) | BFF + クライアントアサーション(private_key_jwt) + DPoP |
どの構成でも、XSS対策が最重要です。トークンの安全な保管は、XSS脆弱性がないことを前提としています。
学習を通じた主な気づき
この記事を書く過程で修正された誤解や、見落としていたポイントをまとめます。
| 章 | 修正された理解 |
|---|---|
| 第0章 | RSAの署名は「秘密鍵で暗号化」ではない。署名と暗号化は別の操作 |
| 第4章 | PS256はRS256より「安全」ではなく「頑健(robust)」 |
| 第5章 | OAuth 2.0のアクセストークンにユーザー情報が含まれうる(RFC 9068) |
| 第6章 | IDトークンのemailやnameは必須クレームではなく任意の標準クレーム |
| 第10章 | DPoPは「認証方式」ではなく「sender-constrainingメカニズム」 |
| 第11章 | CSRFの根本原因は「Cookieの自動送信」であり、「出所の区別不能」はその結果 |
| 第12章 | CORSはセキュリティを「追加」するのではなく、SOPの制限を「緩和」する仕組み |
| 第13章 | SPAのリフレッシュトークンはrotation「必須」ではなく、rotation or sender-constrainedのいずれか |
以上で、認証・認可の全体像の整理でした。
前提知識から実装パターンまでを一本の流れで書きました。「ひとつ調べるたびに別の知識が要る」という堂々巡りを避けるために、土台から順に積み上げる構成にしています。
認証・認可の世界は広く、この記事で触れられなかったトピック(SAML、WebAuthn/Passkeys、ゼロトラストなど)もあります。ただ、ここで整理した基礎があれば、新しいトピックに出会ったときに「どのレイヤーの話か」「既知の概念とどう関係するか」を見通せるはずです。
参考リンク
RFC・標準仕様
- RFC 6749 — The OAuth 2.0 Authorization Framework - OAuth 2.0の基本仕様
- RFC 6750 — The OAuth 2.0 Authorization Framework: Bearer Token Usage - Bearerトークンの利用方式
- RFC 7519 — JSON Web Token (JWT) - JWTの仕様
- RFC 7636 — Proof Key for Code Exchange (PKCE) - PKCEの仕様
- RFC 9449 — OAuth 2.0 Demonstrating Proof of Possession (DPoP) - DPoPの仕様
- RFC 9700 — OAuth 2.0 Security Best Current Practice - OAuth 2.0のセキュリティベストプラクティス
- RFC 6454 — The Web Origin Concept - Originの定義
- RFC 6265bis — Cookies: HTTP State Management Mechanism - SameSite Cookieの仕様
- OpenID Connect Core 1.0 - OpenID Connectの基本仕様
- OpenID Connect Discovery 1.0 - IdPのメタデータ取得仕様
ドラフト・ガイド
- OAuth 2.0 for Browser-Based Applications (draft-ietf-oauth-browser-based-apps) - SPAにおけるOAuth実装の公式ガイド
- OWASP CSRF Prevention Cheat Sheet - CSRF対策の網羅的ガイド
Web標準・リファレンス
- WHATWG Fetch Standard - SOP, CORS, Fetch Metadataの仕様
- W3C Fetch Metadata Request Headers - Sec-Fetch-Siteヘッダーの仕様
- MDN — Same-origin policy - SOPの動作と例外
- MDN — Cross-Origin Resource Sharing (CORS) - CORSの解説
用語集
| 用語 | 説明 | 関連章 |
|---|---|---|
| 認証(Authentication) | 「あなたは誰か」を確認すること | 第1章 |
| 認可(Authorization) | 「あなたに何が許されているか」を制御すること | 第1章 |
| セッション | サーバーが保持するクライアントの状態情報。セッションIDで識別する | 第2章 |
| JWT(JSON Web Token) | ヘッダー・ペイロード・署名の3パートで構成されるトークン形式 | 第4章 |
| OAuth 2.0 | リソースへのアクセス権限を第三者に委譲するための認可フレームワーク | 第5章 |
| 認可コードフロー | OAuth 2.0のもっとも基本的なフロー。認可コードを経由してトークンを取得する | 第5章 |
| OpenID Connect(OIDC) | OAuth 2.0に認証機能を追加するプロトコル。scope=openidで動作する |
第6章 |
| アクセストークン | リソースサーバーへのアクセスに使う短寿命のトークン | 第7章 |
| IDトークン | ユーザーの身元情報を含むJWT。クライアントが検証して使う | 第7章 |
| リフレッシュトークン | アクセストークンの再発行に使う長寿命のトークン。認可サーバーにのみ送信する | 第7章 |
| PKCE | 認可コードの横取りを防ぐ拡張。パブリッククライアントでは必須 | 第9章 |
| コンフィデンシャルクライアント |
client_secretを安全に保持できるクライアント(サーバーサイドアプリ等) |
第9章 |
| パブリッククライアント |
client_secretを保持できないクライアント(SPA、モバイルアプリ等) |
第9章 |
| Bearer | トークンを持っていれば誰でもアクセスできる利用方式 | 第10章 |
| DPoP | トークンの送信者が正当な保持者であることを証明する仕組み | 第10章 |
| CSRF | ブラウザのCookie自動送信を悪用し、ユーザーの意図しないリクエストを送信させる攻撃 | 第11章 |
| SameSite Cookie | クロスサイトリクエスト時のCookie送信を制御するCookie属性 | 第11章 |
| Same-Origin Policy(SOP) | ブラウザがクロスオリジンのレスポンス読み取りをブロックするセキュリティ機構 | 第12章 |
| CORS | サーバーがクロスオリジンリクエストを選択的に許可する仕組み。SOPの緩和 | 第12章 |
| プリフライト | ブラウザがNon-Simple Requestの前にOPTIONSメソッドで送信許可を確認するリクエスト | 第12章 |
| BFF(Backend for Frontend) | SPAの裏にバックエンドを置き、トークン管理をサーバー側に閉じ込めるパターン | 第13章 |