概要
キャッシュ(queryResultCache)について気になったので調べとことのメモ
検索時のキャッシュの仕組みを理解する
キャッシュアルゴリズムは?
LRUアルゴリズムを採用している
LRUなので、Least Recently Used
最も少ない利用回数のキャッシュデータから削除していく方法
LRUとは
一番古い(参照されていない)ノードを新しいノードと入れ替えるアルゴリズム
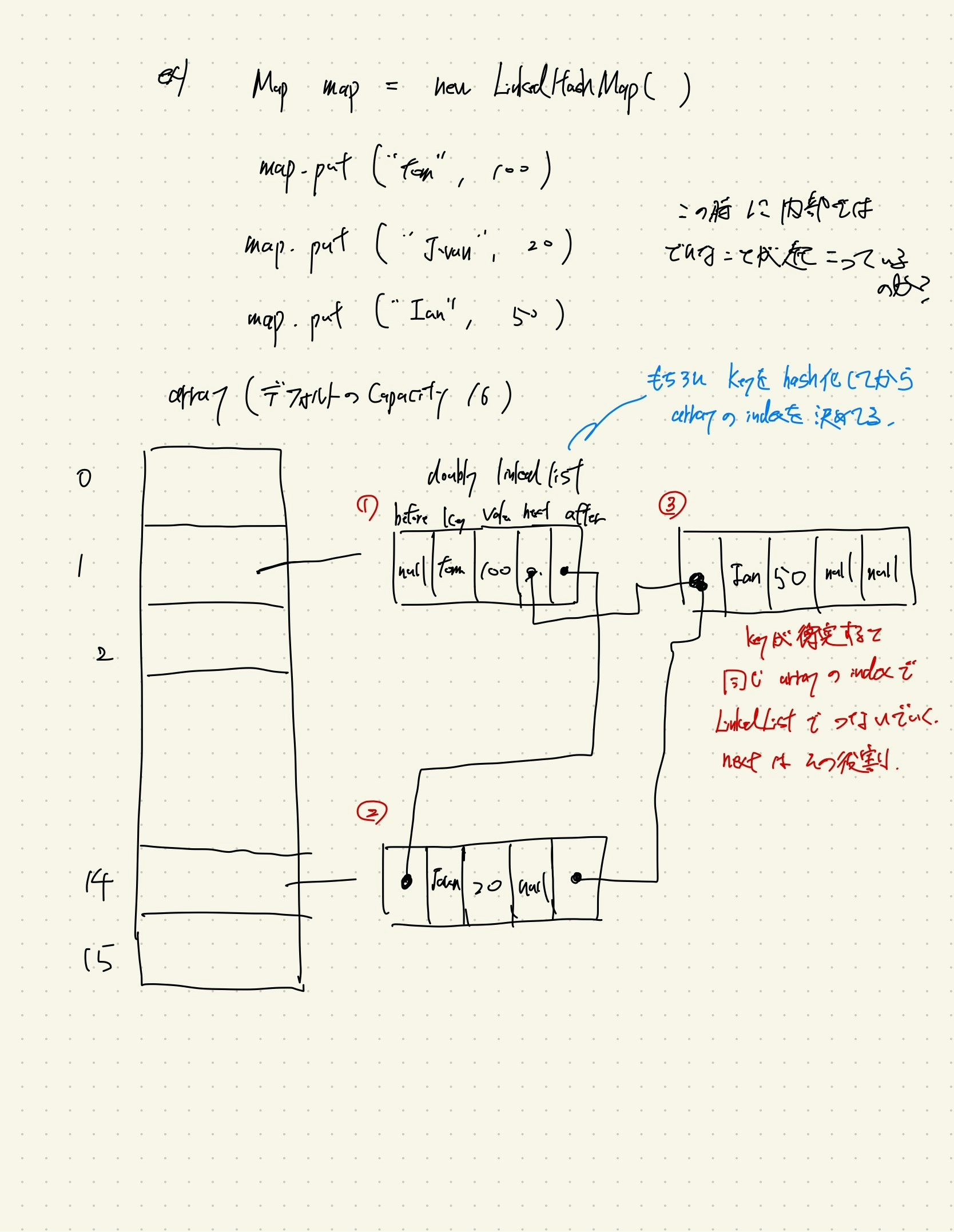
LinkedHashMapデータ構造でLRUCacheは構成されている
LinkedHaspMapとは
基本的な仕組みはHashMapと変わらないが、挿入したデータのorderを保持するHashMapである。
参照:
LRUQueryCacheクラスのコードを読む
キャッシュヒットさせるキーは?
- key: 検索クエリ
- value: 検索ヒットしたdocumentIdのハッシュセット
キャッシュにsetするメソッド
Queryがkey
CacheAndCountがvalueになっている
private void putIfAbsent(Query query, CacheAndCount cached, IndexReader.CacheHelper cacheHelper) {
assert query instanceof BoostQuery == false;
assert query instanceof ConstantScoreQuery == false;
// under a lock to make sure that mostRecentlyUsedQueries and cache remain sync'ed
lock.lock();
try {
Query singleton = uniqueQueries.putIfAbsent(query, query);
if (singleton == null) {
if (query instanceof Accountable) {
onQueryCache(
query, LINKED_HASHTABLE_RAM_BYTES_PER_ENTRY + ((Accountable) query).ramBytesUsed());
} else {
onQueryCache(query, LINKED_HASHTABLE_RAM_BYTES_PER_ENTRY + QUERY_DEFAULT_RAM_BYTES_USED);
}
} else {
query = singleton;
}
final IndexReader.CacheKey key = cacheHelper.getKey();
LeafCache leafCache = cache.get(key);
if (leafCache == null) {
leafCache = new LeafCache(key);
final LeafCache previous = cache.put(key, leafCache);
ramBytesUsed += HASHTABLE_RAM_BYTES_PER_ENTRY;
assert previous == null;
// we just created a new leaf cache, need to register a close listener
cacheHelper.addClosedListener(this::clearCoreCacheKey);
}
leafCache.putIfAbsent(query, cached);
evictIfNecessary();
} finally {
lock.unlock();
}
}
CacheAndCountは、DocIdSetとcountを持つオブジェクト
public CacheAndCount(DocIdSet cache, int count) {
this.cache = cache;
this.count = count;
}
キャッシュのttlはどれくらいの期間なのか?
LRUQueryCacheインスタンスを生成している
LRUなので、時間ではなくキャッシュサイズの閾値を設定し、最も少ない利用回数のキャッシュデータから削除していく方法
デフォルト設定は以下2点
クエリのサイズ
maxQueryCacheは1000
final int maxCachedQueries = 1000;
DEFAULT_QUERY_CACHE = new LRUQueryCache(maxCachedQueries, maxRamBytesUsed);
メモリのサイズ
maxRamBytesUsed
32MB
もしくは
jvmのヒープサイズの5%
// min of 32MB or 5% of the heap size
final long maxRamBytesUsed = Math.min(1L << 25, Runtime.getRuntime().maxMemory() / 20);
DEFAULT_QUERY_CACHE = new LRUQueryCache(maxCachedQueries, maxRamBytesUsed);
キャッシュに格納するための条件
LuceneのLRUQueryCacheでは全てのクエリがキャッシュされるわけではない
以下条件を満たすことでLRUQueryCacheされる
- そのクエリが10000件以上のドキュメントが検索ヒット対象
- そのクエリがインデックス内のドキュメント総数の3%が検索対象
/**
* Create a new instance that will cache at most <code>maxSize</code> queries with at most <code>
* maxRamBytesUsed</code> bytes of memory. Queries will only be cached on leaves that have more
* than 10k documents and have more than 3% of the total number of documents in the index. This
* should guarantee that all leaves from the upper {@link TieredMergePolicy tier} will be cached
* while ensuring that at most <code>33</code> leaves can make it to the cache (very likely less
* than 10 in practice), which is useful for this implementation since some operations perform in
* linear time with the number of cached leaves. Only clauses whose cost is at most 100x the cost
* of the top-level query will be cached in order to not hurt latency too much because of caching.
*/
public LRUQueryCache(int maxSize, long maxRamBytesUsed) {
this(maxSize, maxRamBytesUsed, new MinSegmentSizePredicate(10000, .03f), 10);
}
最大 maxSize のクエリを、最大 maxRamBytesUsed バイトのメモリでキャッシュする新しいインスタンスを作成します。クエリは、10k文書以上かつインデックス内の文書総数の3%以上を持つリーフにのみキャッシュされます。これは、上位層のすべてのリーフがキャッシュされることを保証すると同時に、最大33のリーフがキャッシュされることを保証します(実際には10以下である可能性が非常に高いです)。キャッシュのために待ち時間があまり長くならないように、コストがトップレベルクエリのコストの最大100倍である節のみがキャッシュされます。
ただこれはLRUQueryCacheデフォルトの設定でありカスタムでLRUQueryCacheを定義するとこの値も変更することができる
自前でクエリキャッシュを設定する方法
LRUQueryCacheクラスに書いている
↓こんな感じでカスタムできる
import org.apache.lucene.search.{IndexSearcher, LRUQueryCache}
val cache = new LRUQueryCache(
10,
Math.min(1L << 25, Runtime.getRuntime.maxMemory / 20),
MinSegmentSizePredicate(0, .0f),
1
)
IndexSearcher.setDefaultQueryCache(cache)
ただ、↑の設定でどんなクエリでもキャッシュに格納されるように設定したのだが、
searcher.getQueryCache match {
case c: LRUQueryCache => {
println(c.hashCode())
println(s"cache ram byte: ${c.ramBytesUsed()}")
println(s"cache miss count: ${c.getMissCount}")
println(s"cache hits count: ${c.getHitCount}")
println(s"cache size: ${c.getCacheSize}")
println(s"cache count: ${c.getCacheCount}")
}
case _ => println("not LRUQueryCache")
}
キャッシュヒット数など全部0になりキャッシュに格納されているのか怪しい、、、
hashCodeはカスタムで定義したLRUQueryCacheオブジェクトと同じコードになっているので定義したキャッシュが設定されていることは設定されていそう、、
cache ram byte: 0
cache miss count: 0
cache hits count: 0
cache size: 0
cache count: 0
[option] javaのシフト演算に関して
2進数で指定した数だけビットを左にシフトする演算方法
例1)
1L << 2
2進数 10進数
0001 1
0010 2
例2)
1L << 3
2進数 10進数
0001 1
1000 8
つまり、2^nの演算になる