概要
Luceneのインデックスの構成などを理解を深めるためにLuceneのコードを読んだのでそのメモ
アジェンダ
- インデックス作成されるまで
- Luceneの転置インデックスとは ←次回
- タームリストとポスティングリストの実現方法(コード) ←次回
インデックス作成までの順番として
インメモリバッファ
ドキュメントデータセグメント単位でインメモリバッファに保持
マージ
設定されたポリシーに沿ってセグメント同士を結合する
フラッシュ
フラッシュによってインメモリバッファのデータをdiskにセグメントとして永続化する
セグメントファイルとして永続化されるが、次のコミットされるまでは検索では使えない
コミット
これによって強制的にデータがフラッシュされる
これによってdiskに永続化されたセグメントファイルが検索可能になる
だたdisk同期が発生するのでコストがかかる処理になっている
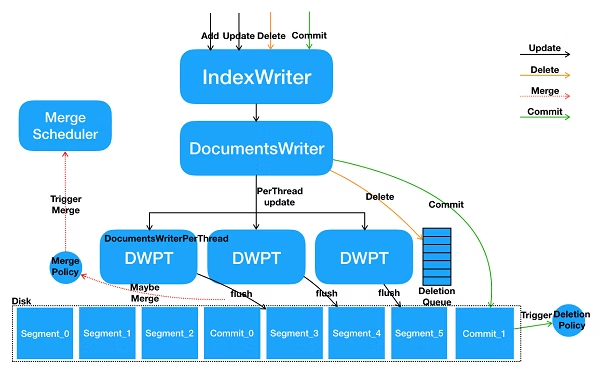
参考:https://qiita.com/KentOhwada_AlibabaCloudJapan/items/b165c4cb9bab06a84479
フラッシュ・コミットの挙動を試してみた
.flush()だけの場合
import Main.{args, runMain}
import org.apache.lucene.analysis.standard.StandardAnalyzer
import org.apache.lucene.document.{Document, Field, TextField}
import org.apache.lucene.index.{IndexWriter, IndexWriterConfig}
import org.apache.lucene.store.FSDirectory
import java.nio.file.Paths
object TermPosting extends App {
def runMain(args: List[String]): Unit = {
val directory = FSDirectory.open(Paths.get("./data/index"))
val analyzer = new StandardAnalyzer()
val indexConfig = new IndexWriterConfig(analyzer)
val conf = indexConfig.setMaxFullFlushMergeWaitMillis(10)
val writer = new IndexWriter(directory, indexConfig)
val document = new Document()
val field = new TextField("title", "load of the ring", Field.Store.YES)
document.add(field)
writer.addDocument(document)
writer.flush()
}
runMain(args.toList)
}
出来上がるファイル
セグメントファイルは作成されていない
_0.cfe
_0.cfs
_0.si
write.lock
.commit()を設定した場合
import Main.{args, runMain}
import org.apache.lucene.analysis.standard.StandardAnalyzer
import org.apache.lucene.document.{Document, Field, TextField}
import org.apache.lucene.index.{IndexWriter, IndexWriterConfig}
import org.apache.lucene.store.FSDirectory
import java.nio.file.Paths
object TermPosting extends App {
def runMain(args: List[String]): Unit = {
val directory = FSDirectory.open(Paths.get("./data/index"))
val analyzer = new StandardAnalyzer()
val indexConfig = new IndexWriterConfig(analyzer)
val conf = indexConfig.setMaxFullFlushMergeWaitMillis(10)
val writer = new IndexWriter(directory, indexConfig)
val document = new Document()
val field = new TextField("title", "load of the ring", Field.Store.YES)
document.add(field)
writer.addDocument(document)
writer.flush()
}
runMain(args.toList)
}
セグメントファイルが作成される
_0.cfe
_0.cfs
_0.si
segments_1
write.lock
segment、mergeの挙動
何も設定してなければいくつかのセグメントが切られる
例えば以下のようにMergePolicyでNoMergePolicyを定義し、セグメントをマージしないようにするといくつかのセグメントに分かれてdiskに保存される
flushPolicyでセグメントの数が決定される
flushPolicy:ramのサイズやドキュメント数が定義されておりメモリ内のバッファをどのタイミングでdiskにフラッシュするのかを定義している
↓の場合は10セグメント切られていた
import Main.{args, runMain}
import org.apache.lucene.analysis.standard.StandardAnalyzer
import org.apache.lucene.document.{Document, Field, TextField}
import org.apache.lucene.index.{IndexReader, IndexWriter, IndexWriterConfig, NoMergePolicy, SegmentReader, TieredMergePolicy}
import org.apache.lucene.store.FSDirectory
import java.nio.file.Paths
object TermPosting extends App {
def runMain(args: List[String]): Unit = {
val directory = FSDirectory.open(Paths.get("./data/index"))
val analyzer = new StandardAnalyzer()
val indexConfig = new IndexWriterConfig(analyzer)
val conf = indexConfig.setMaxFullFlushMergeWaitMillis(10)
val mergePolicy = NoMergePolicy.INSTANCE // <- ここ
val conf2 = conf.setMergePolicy(mergePolicy)
val writer = new IndexWriter(directory, conf2)
for(index <- 1 to 1000000) {
val document = new Document()
document.add(new TextField("title", s"load${index} of the ring-${index}", Field.Store.YES))
document.add(new TextField("content", s"ロードオブザリングです。面白いですね。", Field.Store.YES))
writer.addDocument(document)
}
writer.flush()
writer.commit()
}
runMain(args.toList)
}
例えば以下のようにMergePolicyを設定するとセグメントの数を調整できると思いきや、これはマージの設定なのでこれだけではセグメントサイズは変更できていない
引き続き10セグメント切られていた
import Main.{args, runMain}
import org.apache.lucene.analysis.standard.StandardAnalyzer
import org.apache.lucene.document.{Document, Field, TextField}
import org.apache.lucene.index.{IndexReader, IndexWriter, IndexWriterConfig, NoMergePolicy, SegmentReader, TieredMergePolicy}
import org.apache.lucene.store.FSDirectory
import java.nio.file.Paths
object TermPosting extends App {
def runMain(args: List[String]): Unit = {
val directory = FSDirectory.open(Paths.get("./data/index"))
val analyzer = new StandardAnalyzer()
val indexConfig = new IndexWriterConfig(analyzer)
val conf = indexConfig.setMaxFullFlushMergeWaitMillis(10)
val mergePolicy = new TieredMergePolicy() // <- ここ
val conf2 = conf.setMergePolicy(mergePolicy)
val writer = new IndexWriter(directory, conf2)
for(index <- 1 to 1000000) {
val document = new Document()
document.add(new TextField("title", s"load${index} of the ring-${index}", Field.Store.YES))
document.add(new TextField("content", s"ロードオブザリングです。面白いですね。", Field.Store.YES))
writer.addDocument(document)
}
writer.flush()
writer.commit()
}
runMain(args.toList)
}
indexWriterConfig自体にインメモリのバッファに格納しておくサイズを設定できるのでそこでセグメント数を調整できる
デフォルトのバッファサイズは16MBで設定されている
バッファサイズがここの設定値を超えるとdiskにフラッシュされる
/**
* Default value is 16 MB (which means flush when buffered docs consume approximately 16 MB RAM).
*/
public static final double DEFAULT_RAM_BUFFER_SIZE_MB = 16.0;
とりあえず10 -> 1セグメントに変更したいので以下のようにバッファサイズを非常に大きいサイズに変更
こうすると1セグメントしか作成されないようになった
import Main.{args, runMain}
import org.apache.lucene.analysis.standard.StandardAnalyzer
import org.apache.lucene.document.{Document, Field, TextField}
import org.apache.lucene.index.{IndexReader, IndexWriter, IndexWriterConfig, NoMergePolicy, SegmentReader, TieredMergePolicy}
import org.apache.lucene.store.FSDirectory
import java.nio.file.Paths
object TermPosting extends App {
def runMain(args: List[String]): Unit = {
val directory = FSDirectory.open(Paths.get("./data/index"))
val analyzer = new StandardAnalyzer()
val indexConfig = new IndexWriterConfig(analyzer)
val conf1 = indexConfig.setMaxFullFlushMergeWaitMillis(10)
val conf2 = conf1.setRAMBufferSizeMB(10000) // <-ここ
val mergePolicy = new TieredMergePolicy()
val conf3 = conf2.setMergePolicy(mergePolicy)
val writer = new IndexWriter(directory, conf3)
for(index <- 1 to 1000000) {
val document = new Document()
document.add(new TextField("title", s"load${index} of the ring-${index}", Field.Store.YES))
document.add(new TextField("content", s"ロードオブザリングです。面白いですね。", Field.Store.YES))
writer.addDocument(document)
}
writer.flush()
writer.commit()
}
runMain(args.toList)
}
マージポリシーでマージされるセグメントの調整
デフォルトのマージポリシーでは、マージ後に作成されるセグメントサイズは5GBがデフォルト値になっている
/**
* Maximum sized segment to produce during normal merging. This setting is approximate: the
* estimate of the merged segment size is made by summing sizes of to-be-merged segments
* (compensating for percent deleted docs). Default is 5 GB.
*/
public TieredMergePolicy setMaxMergedSegmentMB(double v) {
if (v < 0.0) {
throw new IllegalArgumentException("maxMergedSegmentMB must be >=0 (got " + v + ")");
}
v *= 1024 * 1024;
maxMergedSegmentBytes = v > Long.MAX_VALUE ? Long.MAX_VALUE : (long) v;
return this;
}
なので試験的にマージ後にさらに多くのセグメントを生成する
setMaxMergedSegmentMB = 5 に設定することで、5MBが1つのセグメントの最大サイズになる
こうすると21セグメント切られるようになった
import Main.{args, runMain}
import org.apache.lucene.analysis.standard.StandardAnalyzer
import org.apache.lucene.document.{Document, Field, TextField}
import org.apache.lucene.index.{IndexReader, IndexWriter, IndexWriterConfig, NoMergePolicy, SegmentReader, TieredMergePolicy}
import org.apache.lucene.store.FSDirectory
import java.nio.file.Paths
object TermPosting extends App {
def runMain(args: List[String]): Unit = {
val directory = FSDirectory.open(Paths.get("./data/index"))
val analyzer = new StandardAnalyzer()
val indexConfig = new IndexWriterConfig(analyzer)
val conf1 = indexConfig.setMaxFullFlushMergeWaitMillis(10)
val conf2 = conf1.setRAMBufferSizeMB(1)
val mergePolicy = new TieredMergePolicy()
val p2 = mergePolicy.setMaxMergedSegmentMB(5) // <- ここ
val conf3 = conf2.setMergePolicy(p2)
val writer = new IndexWriter(directory, conf3)
for(index <- 1 to 1000000) {
val document = new Document()
document.add(new TextField("title", s"load${index} of the ring-${index}", Field.Store.YES))
document.add(new TextField("content", s"ロードオブザリングです。面白いですね。", Field.Store.YES))
writer.addDocument(document)
}
writer.flush()
writer.commit()
}
runMain(args.toList)
}
closeメソッド
単発でインデックスファイルを作成する場合は、write.close()を実行すればよい
デフォルトの設定ではindexWrite.close()した時点でコミット走るようになっている
public static final boolean DEFAULT_COMMIT_ON_CLOSE = true;
@Override
public void close() throws IOException {
if (config.getCommitOnClose()) {
shutdown();
} else {
rollback();
}
}
shutdown()メソッドの中身
private void shutdown() throws IOException {
if (pendingCommit != null) {
throw new IllegalStateException(
"cannot close: prepareCommit was already called with no corresponding call to commit");
}
// Ensure that only one thread actually gets to do the
// closing
if (shouldClose(true)) {
try {
if (infoStream.isEnabled("IW")) {
infoStream.message("IW", "now flush at close");
}
flush(true, true);
waitForMerges();
commitInternal(config.getMergePolicy());
} catch (Throwable t) {
// Be certain to close the index on any exception
try {
rollbackInternal();
} catch (Throwable t1) {
t.addSuppressed(t1);
}
throw t;
}
rollbackInternal(); // if we got that far lets rollback and close
}
}