はじめに
最近、お客さんからもらったデータを Bigquery など Embulk を使い始めました。
今回はその際に特に困った2つの問題の解決方法のお話を書こうかなと思います。
Embuk ってなに?
公式によると Embulk とは
Embulk is a open-source bulk data loader that helps data transfer between various databases, storages, file formats, and cloud services.
だそうです。
簡単に言うと、INPUT元からデータを取り込み、OUTPUT先へデータを転送するデータローダーです。
Fluentd をご存知の人はイメージしやすいと思いますが、 Fluentd と同じく 取り込み元や転送先に合わせた plugin が各種用意されていて、そのプラグインを使用することでいろんなデータの保存先から別のデータ保存先へデータを転送することができます。
Fluentd がストリーム転送なのに対して、Embulk はバッチ形式でデータを転送します。
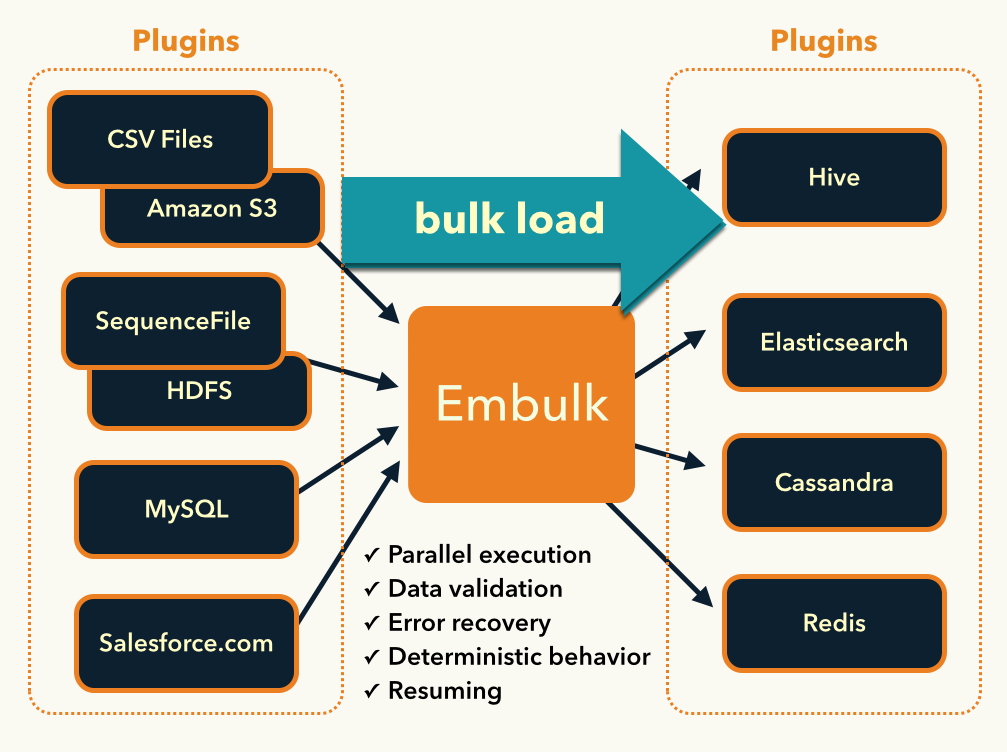
Embulk を使ったメリット
今回、なぜ Embulk を導入したのかというと、あらゆるデータ形式への柔軟な対応と今後のメンテナンス性の担保を可能にするために Embulk を導入しました。
データ形式への柔軟な対応
AI を運用する上で、お客さんからもらうデータは命のようなものですが、そのデータの形式や連携先のサービスなどは様々です。
お客さんは必ずしも ITリテラシーの高い会社ばかりではないため、いろんな場面に対応する必要があります。
CSV や TSV だけでなく、エクセルやその他いろんなデータの連携が考えられます。
これらのいろんなデータ連携元に対しても plugin を使うことで、簡単に対応可能です。
現にEmbulk導入前は、連携されたエクセルファイルをCSVに変換して取り込むスクリプトを用意していましたが、Embulk を使用することでそういった手間が省けます。
メンテナンス性の担保
上記で説明しましたが、エクセルファイルが連携された時に、「エクセルが生データでCSVはエクセル内の複数のシートをこちらで変換したものだよ」という説明分も一緒に残しつつ、取り込み手順も別途資料に残していました。
これらの手順は、別の人間に継承されるにつれて、データの変更や追加の際のメンテナンスコストが膨れ上がることが考えられます。
しかし、Embulk を使用することで、 yaml 形式で config を管理できるため、データを取り込む際に必要な情報の可読性も高まります。
また、処理の実行も Embulk コマンドを一発叩くだけで良いので、誰でも簡単に実行できます。
Embulk の導入
導入も簡単で公式に沿って以下のコマンドを実行するだけです。[公式]
$ curl --create-dirs -o ~/.embulk/bin/embulk -L "https://dl.embulk.org/embulk-latest.jar"
$ chmod +x ~/.embulk/bin/embulk
$ echo 'export PATH="$HOME/.embulk/bin:$PATH"' >> ~/.bashrc
$ source ~/.bashrc
ASCII 0 encountered エラーの回避方法
では、まず1つめ。
背景
お客さんから頂いたCSVをBigQueryに取り込もうとした際に Error: Bad character (ASCII 0) encountered. が起きてしまいました。
このときは百以上あるCSV ファイルの中のいくつかのファイルで問題が起きていました。
(通常は圧縮ファイルを取り込む際によく起きるエラーなのですが、今回は CSV ファイルで起きていました。)
以前 (Embulk 導入前) にもこの問題にぶつかったことがあったのですが、その際は数ファイルだけだったので、以下のように、ASCII 文字を消しながら解凍ファイルを作成し、それをBigQueryに取り込む事で対処していました。
gsutil cp gs://xxxxxxxxxx/input/file.tsv.gz - | gzip -d | tr -d '\000' | gsutil cp - gs://xxxxxxxxxx/input/unzip/file.tsv
今回は、ファイル数も多いことと、データの取り込み処理を全て Embulk に統一したいという考えもあったため、結構ハマってしまいました。
解決策
解決策として、CSV を 一回 jsonl に変換し、その jsonl を BigQuery に取り込むことで大抵の事が回避できるというすてきなアドバイスを受けて、 jsonl に変換することにしました。
必要なもの
使用する plugin は以下の2つ。
embulk config の例
以下のように取り込み対象のCSVを、一度 jsonl に変換します。
この例では gcs の sample-bucket のファイルを jsonl へ変換し、sample-bucket-tmp へ保存しています。
in:
type: gcs
bucket: sample-bucket
path_prefix: input/
auth_method: compute_engine
parser:
charset: UTF-8
newline: LF
type: csv
delimiter: ','
quote: '"'
escape: '"'
trim_if_not_quoted: false
skip_header_lines: 0
columns:
- {name: 'user_id', type: string}
- {name: 'date', type: string}
out:
type: gcs
formatter:
type: jsonl
encoding: UTF-8
auth_method: compute_engine
file_ext: .jsonl
bucket: sample-bucket-tmp
path_prefix: jsonl/
次に jsonl を Bigquery に取り込みます。
in:
type: gcs
bucket: sample-bucket-tmp
path_prefix: jsonl/
auth_method: compute_engine
parser:
charset: UTF-8
newline: LF
type: jsonl
columns:
- {name: 'user_id', type: string}
- {name: 'date', type: string}
out:
type: bigquery
mode: replace
project: sample
dataset: dataset
table: table
allow_quoted_newlines: true
auth_method: compute_engine
schema_file: schema.json
gcs_bucket: sample-bucket-tmp
現状、これらの処理を1つのyamlに統一することはできませんでしたが、config 名に step_1、 step_2 という名前をつけるなどをして、だれが見ても順序を間違えずに実行できるようにしていました。
(後述しますが、今は digdag でまとめています。)
実行結果
上記の方法で見事に問題を回避することができました。
jsonl に変換する際に、よしなにパースしてくれているそうです。
アドバイスをくれた人曰く、エスケープの問題など、大抵の問題はこの方法で幅広く対応可能だとか。
ぜひ、同じような問題で困っている人は試してみてください。
ファイル名を取得する方法
では、2つめ。
背景
こちらは CSV データを BigQuery に取り込むさいに、データの期間の情報がデータ内には無く、ファイル名に記載されていました。
そのCSVファイル内のデータがいつのものなのかを、データを取り込む際にファイル名に沿った期間情報をカラムとして追加してあげないと、最新のレコードが判断できない状態でした。
解決策
今回は、pyton でファイル名から期間情報を抜き出し、変数として Embulk に渡す事ことにしました。
そこで、冒頭で上げた Embulk の導入理由であるメンテナンス性などを極力損なわないために、 Digdag を使用し、Digdag から Embulk を実行することにしました。
Digdag ってなに?
バッチの実行順序を管理するワークフローエンジンです。[公式]
digdag run xxxx.dig のように実行することで実行順序に沿ってバッチの実行が可能になります。
また、サードパーティプラグインなどもあり、応用をきかせる幅も広がります。
導入も簡単で、記述方法も ShellScript を書くよりも簡単だなって思ったのと、Embulkの実行もサポートしていたため、今回は導入することにしました。
Digdag の導入方法
導入は簡単で、公式に沿って以下のように実行するだけです。
$ curl -o ~/bin/digdag --create-dirs -L "https://dl.digdag.io/digdag-latest"
$ chmod +x ~/bin/digdag
$ echo 'export PATH="$HOME/bin:$PATH"' >> ~/.bashrc
$ source ~/.bashrc
config の例
では、以下に各ファイルの例を記述します。
- sample.dig : これが Digdag の実行ファイルとなります。
- setting.py で代入した変数を for_each でイテレートして embulk を実行しています。
- setting.py : Python を利用して変数を代入します。
- INPUT_ARGS dict に INPUTファイルのpath とそれに伴った変数をもたせています。
- ファイル名を取得する python 処理を実装することで、動的な取得も可能です。
- embulk_config.yaml : Embulk の config ファイルになります。
- カラム追加を行うために embulk-filter-column plugin を使用しています。
- Digdag から受け取った dict 形式の変数を
${args.xxxxx}で展開しています。
timezone: Asia/Tokyo
+start:
echo>: start ${session_time}
+setup:
py>: setting.SampleClass.set_arg
+RawDataInsert:
for_each>:
args: ${args}
_do:
embulk>: embulk_config.yaml
+end:
sh>: echo "---------- successful ----------"
# -*- coding: utf-8 -*-
import digdag
INPUT_ARGS = [
{"path": "input/2017/sample_08.csv", "year": "2017", "month": "8"},
{"path": "input/2018/sample_12.csv", "year": "2018", "month": "12"},
]
class SampleClass(object):
def set_arg(self):
digdag.env.store({'args': INPUT_ARGS})
in:
type: gcs
bucket: sample-bucket-tmp
path_prefix: ${args.path}
auth_method: compute_engine
parser:
charset: UTF-8
newline: LF
type: csv
columns:
- {name: 'user_id', type: string}
- {name: 'date', type: string}
filters:
- type: column
add_columns:
- {name: year, type: string, default: ${args.year} }
- {name: month, type: string, default: ${args.month} }
out:
type: bigquery
mode: replace
project: sample
dataset: dataset
table: table
auth_method: compute_engine
schema_file: schema.json
gcs_bucket: sample-bucket-tmp
実行結果
これで digdag run sample.dig を実行すると Embulk が実行され、yearカラム と monthカラム が追加されたテーブルが BigQuery に作成されます。
また、「ASCII 0 encountered エラーの回避方法」で紹介したみたいな embulk config が複数に分かれてしまった場合でも、Digdag を使えば STEP実行 の管理が可能です。
さいごに
今まで自社開発していた時は「データが汚い!」なんてことをそこまで気にする機会がなかったのですが、AI開発はお客さんのデータに依存するため、データ取り込みで疲弊してしまうことが結構あります。。。
そういった作業は Embulk や Digdag などを使用して、少しでも楽するべきだなと実感させられます。^^;
その中でも特に今回紹介した2つは解決方法に悩んだものなので、他に同じことで悩んでいる人がいたらぜひ参考にしてみてください。