Matplotlib と Seaborn
Matplotlibはデータの可視化によく使われるライブラリです。大小、傾向、分布、相関などを目視する時に用います。
SeabornはMatplotlibが内部で動いているのですが、特に、手軽に美しく可視化ができるライブラリです。
import方法
import matplotlib.pyplot as plt
import seaborn as sns
と書いて読み込みます。
Matplotlibで棒グラフを作ってみる
# dfを定義、列名A,B,C 行名ONE,TWO,THREE
df = pd.DataFrame({'A':[2,2,3],
'B':[4,5,6],
'C':[7,8,9]},
index=[1,2,3])
print(df)
"""
出力結果 :
A B C
1 2 4 7
2 2 5 8
3 3 6 9
"""
# value_counts()を使ったら
test = df['A'].value_counts()
print(test)
"""
出力結果 :
2 2
3 1
Name: A, dtype: int64
"""
# 横軸の値
x = df['A'].value_counts().index
# 縦軸の値
height = df['A'].value_counts().values
print(x,height)
"""
出力結果 : Int64Index([2, 3], dtype='int64'), array([2, 1])
"""
value_countsメソッドは、カテゴリ変数の各クラスがそれぞれいくつあるかを数え上げてくれます。ユニークな要素の値がindex、その出現個数がdataとなるpandas.Seriesを返すので、要素の頻度(出現回数)が必要な場合はこちらを使います。
testを出力したら、「2が2つ、3が1つですよ」と返してくれているのがわかります。
value_counts.indexでtestの中の、indexをpandas.core.indexes.numeric.Int64Indexという型で手に入れられます。
value_counts.valueでそのindexの要素の出現回数を、numpy.ndarray型で手に入れられます。
これをmatplotlibで図式化すると、
# 横軸に x , 縦軸に height の棒グラフを描画。
plt.bar(x, height)
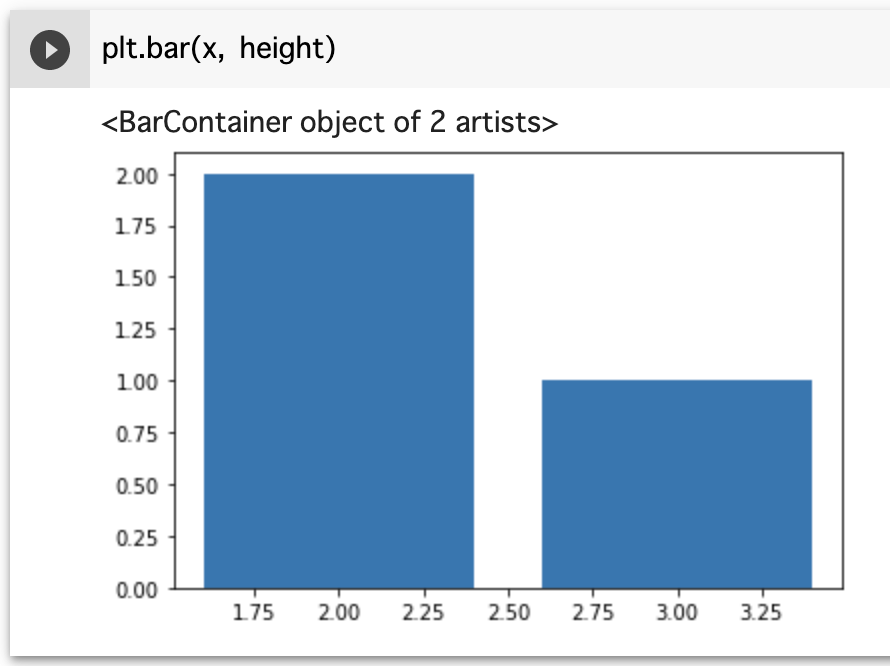
このようなグラフが出来上がります。
Seabornを使うと
# Seabornのスタイルを使う
plt.style.use('seaborn')
# 横軸に x , 縦軸に height の棒グラフを描画。
plt.bar(x, height)
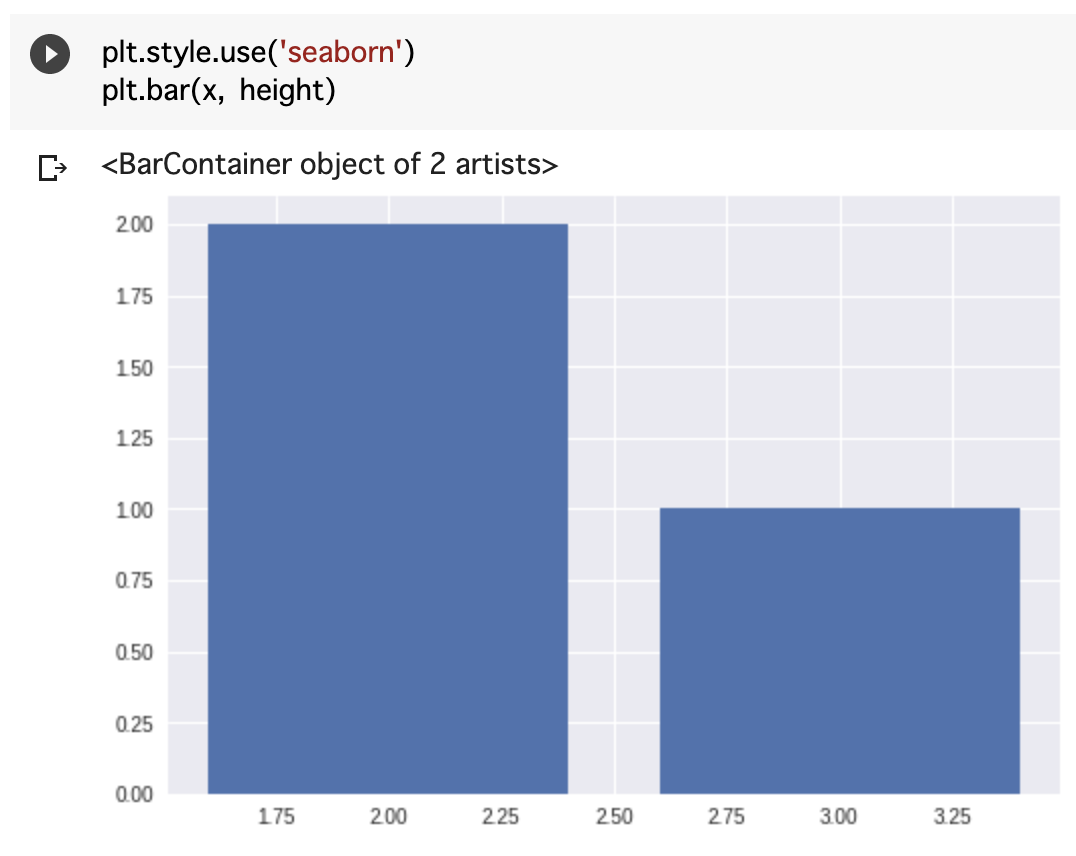
このようにちょっと見やすくなりました。
折れ線グラフ
plt.plot(x, y)で折れ線グラフが描画できます。
ヒストグラム
plt.hist(df['A'], bins=10)10分割にして分布をみるためのヒストグラムを作れます。
Seabornを使った場合
sns.distplot(df['A'], kde=False, bins=10ヒストグラムの背景に目盛りがつきます。
kde=Trueにすると、確率密度関数が表示されます。
箱ひげ図
plt.boxplot(df['A'])外れ値を検討する時に使える箱ひげ図を表示できます。
散布図
plt.scatter(df['A'], df['B'])X軸のデータをA列から、Y軸のデータをB列から取った散布図を描画できます。A列のデータとB列のデータの相関関係を可視化できます。
sns.pairplot(df)各列と各列をそれぞれX軸、Y軸に取った散布図を全て表示し、一度に確認することができます。
ヒートマップ
df_corr = df_corr()全ての組み合わせの相関係数を取得し、df_corrに代入します。
sns.heatmap(df_corr, annot=True, cmap='Blues')
annotはTrueにすることで、相関係数を表示することができます。
cmapではヒートマップの色系統を指定できます。
要約統計量の確認
df.describe()では、要素の数、平均値、中央値、最小値、最大値などを一覧でみることができます。
グループ化
任意のカテゴリカル変数についてグルーピングを行うことができます。
df.groupby('A').mean()では、A列の要素によって、グループ分けをして、それぞれのグループごとに、他の列の値の平均値を取得できます。
クロス集計
pd.crosstab(df['A'], ['B'])A列とB列のカテゴリカル変数を掛け合わせてサンプル数を集計します。データフレームが表示され、データフレームの値にはサンプル数が表示されます。
ピボットテーブル
pd.pivot_table(df, values='A', index='B', columns='C', aggfunc='mean')
データフレームの値は、A列から。agghunc='mean'によって、その平均が表示されます。
カラムはC列の要素から、インデックスは、B列の要素から表示されます。
データの中身についてよく理解した上で、こういったものを役立てるといいかもしれません。