この記事はPostgreSQL Advent Calendar 2020の20日目の記事です。
昨日はU_ikkiさんのpsqlの最新機能に関する記事でした。とてもタメになる内容でしたね!本日の記事も皆さんのお役に立てるよう頑張って書きましたので、ご査収のほどよろしくお願い申し上げます。
はじめに
今年は「Stay Home」な期間も長く家にいることが多かった1年でした。
休日暇になることも多々あり、押し入れに眠っていたJetson Nanoを目覚めさせて遊ぶことにしました!
昨年、金持ちになることを夢見てがんばってみましたが、人生そう甘くなかったので、引き続きPythonで金持ち目指します。
Jetson Nano
NVIDIA社が提供するGPU付のデバイスです。
https://www.nvidia.com/ja-jp/autonomous-machines/embedded-systems/jetson-nano/
一言で言うと、GPUラズパイ 。

Jetson Nanoのスペック概要は以下の通りです。
| モジュール | スペック | 備考 |
|---|---|---|
| GPU | 128 基の NVIDIA Maxwell™ GPU | ちょっと古い型番らしい |
| CPU | クアッドコア ARM® Cortex®-A57 MPCore プロセッサ | ラズパイ4より劣るけど、まあまあ |
| Memory | 4 GB 64 ビット LPDDR4 25.6GB/s | 最近2GBモデルも出たらしい |
Let's play!
さてPostgreSQLでGPUといえば「PG-Strom」でしょ!と言うことで早速環境構築に取りかかりました。
インストールマニュアルを読み始めます。
https://heterodb.github.io/pg-strom/ja/install/
だがしかし。
最初のチェックリストでGPUの型番をチェックできるのですが、Maxwellアーキテクチャのところに、、、
「Sorry, all the Maxwell architecture are NOT supported.」
↓
「ごめんね、全てのMaxwellアーキテクチャはサポートされないんよ。」
ΩΩΩ<な、なんだってー!?
まぁ、Jetson Nanoはエントリーモデルと言うこともあり、GPU型番が古すぎたのでしょう。
オワタ\(^o^)/
再出発
嘆いていてもしょうがないので、気持ちを切り替えてとりあえず環境構築。
OSはJetson Download Centerからダウンロードします。
ラズパイ同様、チョロチョロっと設定すれば簡単にセットアップできます(新旧いろんな情報が乱立してて、VNC接続はてこずりましたが)。
無事、起動!

Ubuntu18.04ベースのOSが入ります。
$ cat /etc/os-release
NAME="Ubuntu"
VERSION="18.04.5 LTS (Bionic Beaver)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 18.04.5 LTS"
VERSION_ID="18.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=bionic
UBUNTU_CODENAME=bionic
続けてPostgreSQLのインストール。
本家サイトを参考にapt-getでインストールしてみました。ついでに今回の主役であるPL/Pythonも(pythonのバージョンが3.6.9だったので、plpython3uを使う)。
$ sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
$ wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
$ sudo apt-get update
$ sudo apt-get -y install postgresql
$ sudo apt-get install postgresql-plpython3-13
これでOK。PostgreSQL13.1が入りました。
$ psql -c "SELECT version()"
version
----------------------------------------------------------------------------------------------------------------------------------------------
PostgreSQL 13.1 (Ubuntu 13.1-1.pgdg18.04+1) on aarch64-unknown-linux-gnu, compiled by gcc (Ubuntu/Linaro 7.5.0-3ubuntu1~18.04) 7.5.0, 64-bit
(1 行)
あとは適宜、対象データベースにCREATE LANGUAGEで登録するだけ。
testdb=# CREATE LANGUAGE plpython3u;
CREATE LANGUAGE
ほぼほぼラズパイと同様に構築できました。
GPUを効果的に使うツールインストール
JetPack SDKと言うパッケージをインストールすると、様々なライブラリやらフレームワークで効果的にGPUを使うアプリケーションを作成できるとのこと。
https://docs.nvidia.com/jetson/jetpack/install-jetpack/index.html
OSに同梱されてるのがちょっと古くなってたので、アップグレード。
$ sudo apt install nvidia-jetpack
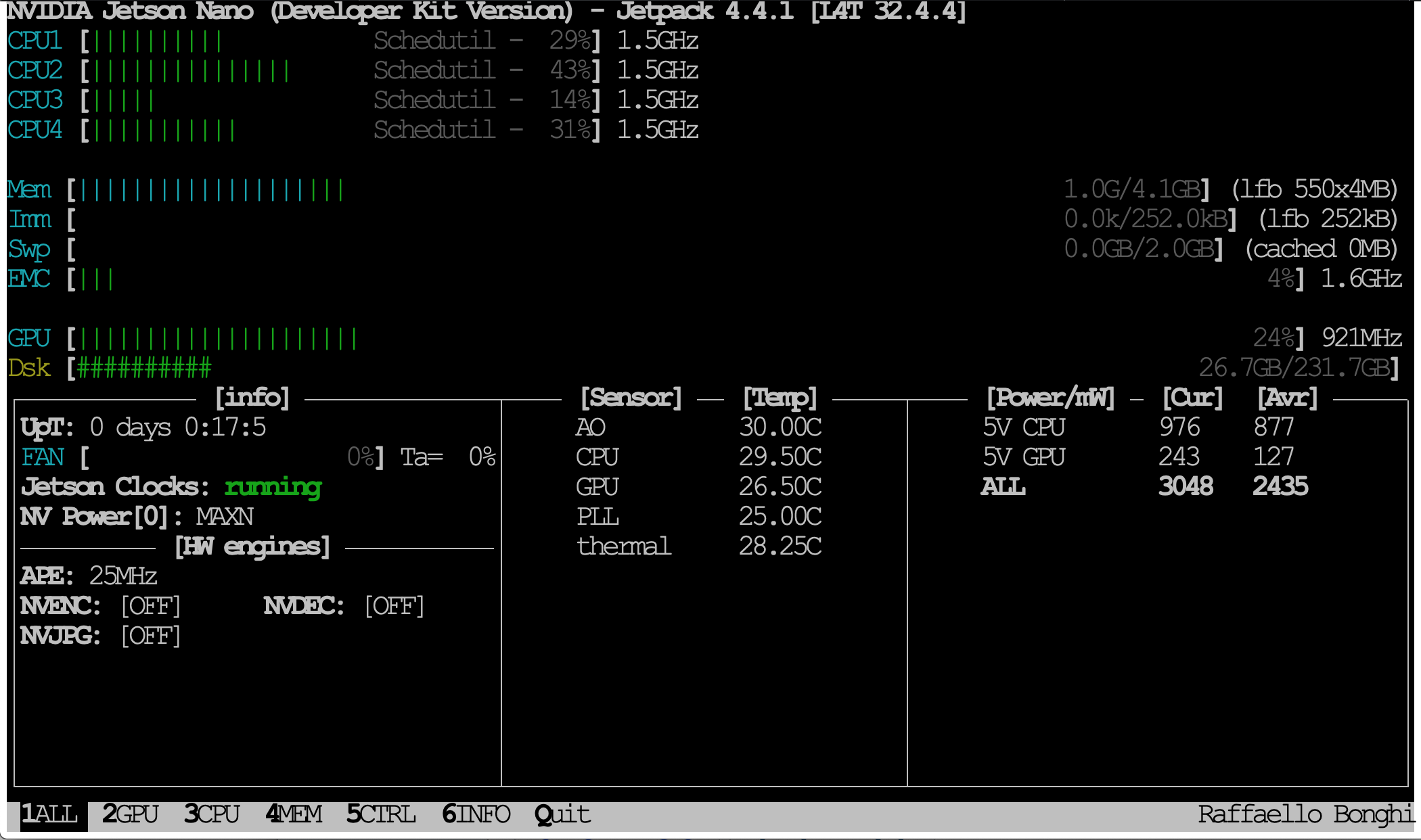
あと、GPUモニタリングツールも。
$ sudo -H pip install jetson-stats
jtopコマンド使ってGPUの使用状況など確認できるようになります。
作る
環境は整ったので、アプリケーションを作って行こうと思います。
最近、歳のせいか物忘れがひどいです。
と言うことで、我が家のNASにある写真を類似画像検索できるようにします!
我が家では、「/mnt/share/Picture」配下にスマホとかで撮った写真をズコズコ突っ込んでます。
↓の感じ。
/mnt/share/Picture
├── 2002
│ ├── 2002.02.07
│ │ ├── DSCF0001.JPG
│ │ ├── DSCF0002.JPG
.......
├── 2003
│ ├── 2003.02.08
│ │ ├── DSCF0001.JPG
│ │ ├── DSCF0002.JPG
.......
├── 2019
│ └── 20190914
│ ├── P9141066.jpg
.......
たまに「XXXみたいな写真どっかにあったよなぁ〜」と探すのですが、15年以上前に撮った写真がどこにあるかなんて探せませんorz
と言うことで、ここを推論やら画像認識やらで助けてもらうようにします。
軽くググってみると、すでに開発は完了したらしいけどChainerの情報が多かったので、こいつに助けてもらいます。VGG16ってので画像認識/分類ができるって。
先人の教えに従い、なんとかChainerも動くようになりました。
システム構成
全体像は以下のようにしました。
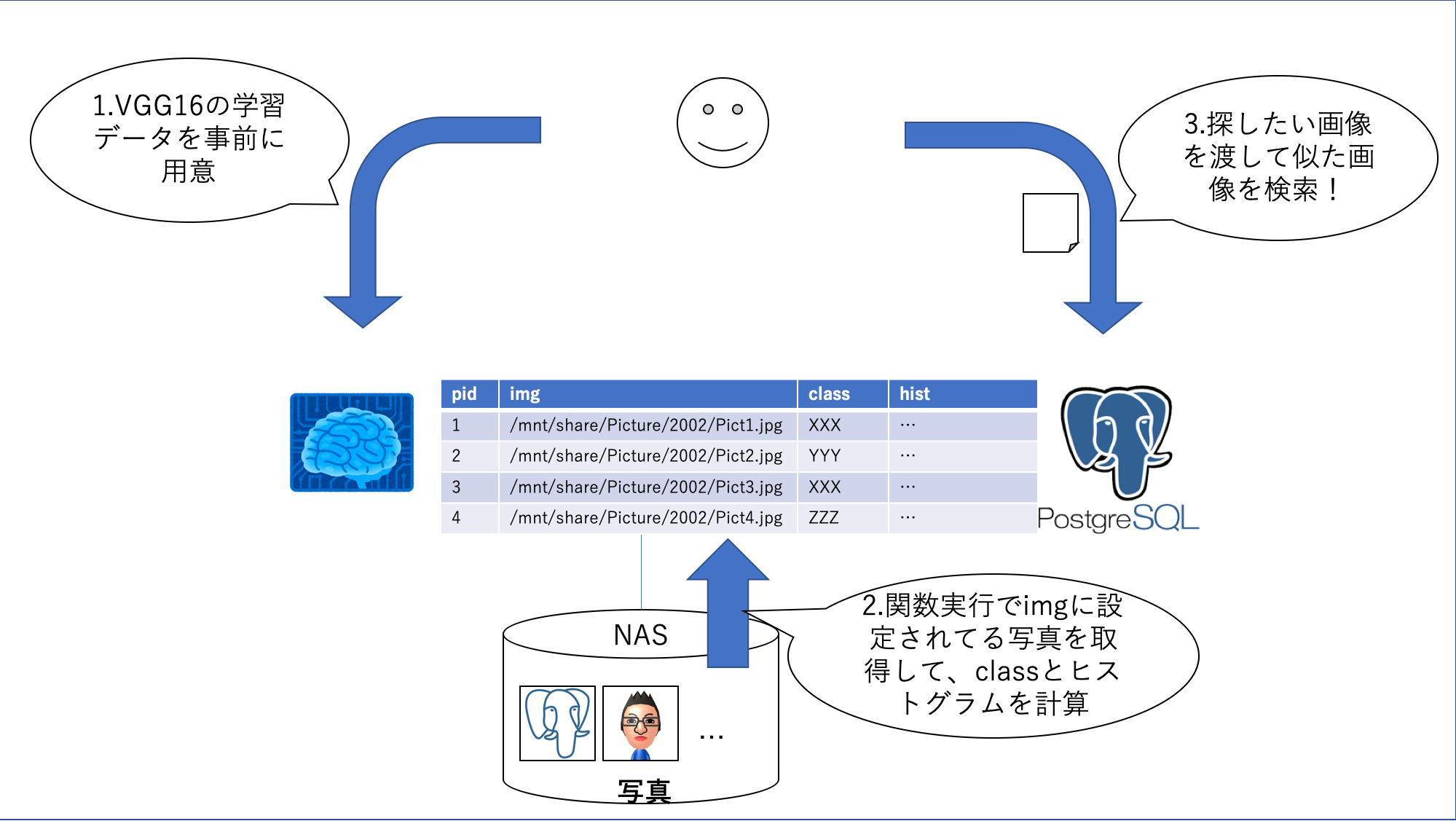
1. VGG16学習データの用意
以下のようにすると、実行したユーザの.chainer/dataset/pfnet/chainer/models配下にVGG_ILSVRC_16_layers.npzと言うファイルがダウンロードされるので、postgresユーザの~/.chainer/dataset/pfnet/chainer/modelsにコピー。
from chainer.links import VGG16Layers
vgg16 = L.VGG16Layers()
んで、PostgreSQL再起動すればOK。
(案の定、GPUを認識させるにはpostgresユーザにいろんな権限付けないとダメでした。とりあえず全部つけた)
2. 写真の分類とヒストグラム値計算
次のSQL関数を登録。
全てのレコードを実行するとメモリ不足(?)でJetson Nanoが落ちてしまうので、10件づつ処理してます。
それでも6000ファイルで7時間位かかった・・・
CREATE OR REPLACE FUNCTION pict2hist(tbl TEXT, from_idx INT, to_idx INT)
RETURNS VOID
AS $$
import cv2
import os
import cupy as cp
from chainer import functions as F
from chainer import links as L
from PIL import Image
SIZE = 256
IMG_SIZE = (224, 224)
img_gpu_src = cv2.cuda_GpuMat()
img_gpu_dst = cv2.cuda_GpuMat()
vgg16 = L.VGG16Layers()
s_query = "SELECT pid, img FROM " + tbl \
+ " WHERE hist IS NULL AND pid >= " + str(from_idx) + " AND pid <= " + str(to_idx)
plpy.log(s_query)
u_query_a = "UPDATE " + tbl
plan = plpy.prepare(u_query_a + " SET class = $1, hist = $2 WHERE pid = $3", ["int", "bytea", "int"])
rv = plpy.execute(s_query)
cnt = rv.nrows()
for i in range(cnt):
idx = rv[i]["pid"]
plpy.log(idx)
# Read Image
comparing_img_path = rv[i]["img"]
comparing_img = cv2.imread(comparing_img_path, 0)
img_gpu_src.upload(comparing_img)
img_gpu_dst = cv2.cuda.resize(img_gpu_src, IMG_SIZE)
img_dst = img_gpu_dst.download()
# Class
vgg16.to_gpu()
img = L.model.vision.vgg.prepare(img_dst)
img = img[cp.newaxis]
img = cp.array(img, dtype=cp.float32)
result = vgg16(img)
val = F.argmax(result['prob'], axis=1)
#print(val)
this_class = val.item()
# Histgram
hist_tmp = cv2.calcHist([img_dst],[0],None,[SIZE],[0,SIZE])
hist_bytes = hist_tmp.tobytes()
tmp_rv = plpy.execute(plan, [this_class, hist_bytes, idx])
$$ LANGUAGE plpython3u;
VGG16の画像は224x224らしいので、写真も同じサイズに変換して分類(class列)。
あと類似画像検索で使うので、ヒストグラムを算出(hist列)。今回はグレースケール画像として扱ったので濃淡のヒストグラムになります。
ちなみに、hist列はbytea型にしたので、tobytesメソッドで変換して突っ込んでます。
VGG16の分類
VGG16のモデルファイルを使うと画像を1000個に分類できます。分類される項目は↓とか参考にしました。分類コードだけだとワケワカメなので、こいつも別テーブルに突っ込んでおきました。
https://github.com/davidgengenbach/vgg-caffe/blob/master/data/labels.txt
途中jtopで様子見すると、きちんとGPUも使われてる。
3. 検索!
類似画像検索は、2つの画像のヒストグラムからコサイン類似度を求めます。
cos(\overrightarrow{p},\overrightarrow{q}) = \frac{\overrightarrow{p}・\overrightarrow{q}}{|\overrightarrow{p}||\overrightarrow{q}|}
結果は-1から1までの値となり、1に近いほど類似度が高いと判断します。
CREATE OR REPLACE FUNCTION extract_cpu(tbl TEXT, qry TEXT, OUT INTEGER, OUT TEXT, OUT INTEGER, OUT REAL)
RETURNS SETOF record
AS $$
import sys
import cv2
import numpy as np
### VALUES
IMG_SIZE = (224, 224)
SIZE = 256
### Read source image
img_qry = cv2.imread(qry, 0)
### Run with CPU
img_dst = cv2.resize(img_qry, IMG_SIZE)
qry_hist = cv2.calcHist([img_dst],[0],None,[SIZE],[0,SIZE])
qry_hist = qry_hist.reshape([1,SIZE])
def cos_sim(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
s_query = "SELECT pid, img, class, hist FROM " + tbl
rv = plpy.execute(s_query)
cnt = rv.nrows()
ret = []
for i in range(cnt):
pid = rv[i]["pid"]
img = rv[i]["img"]
cls = rv[i]["class"]
target_hist = rv[i]["hist"]
target_hist = np.frombuffer(target_hist, dtype=np.float32)
score = cos_sim(qry_hist, target_hist)[0]
ret.append([pid, img, cls, score])
return ret
$$ LANGUAGE plpython3u;
bytea型(hist列)を読み込むときはNumpyのfrombufferが使えました。
Let's Try!
クエリ画像1:
手書きのtest_slonik_01.png。

検索結果1:
testdb=# SELECT * FROM extract_cpu('pict','/var/lib/postgresql/work/2020AdventCalendar/image/test_slonik_01.png'), classes WHERE column3 = cid ORDER BY column4 DESC LIMIT 3;
column1 | column2 | column3 | column4 | cid | no | class
---------+-------------------------------------------------------+---------+-----------+-----+-----------+----------------
1152 | /mnt/share/Pictures/wine/100002.jpg | 512 | 0.9983001 | 512 | n03100240 | convertible
327 | /mnt/share/Pictures/2008/2008.05.11/tomo-taichi13.jpg | 681 | 0.9981289 | 681 | n03825788 | nipple
1157 | /mnt/share/Pictures/wine/100007.jpg | 551 | 0.9979377 | 551 | n03297495 | espresso maker
(3 行)
pid=1152、類似度0.9983001の10002.jpg。

ワインw
うーん、画像の濃淡だけでヒストグラム作ってるので、全く違う画像がヒットしてしまう・・・
だめだこりゃ\(^o^)/
気を取り直して、超うまく書いたクエリ画像でトライ!
クエリ画像2:
トレースして書いたtest_slonik_02.png。

検索結果2:
testdb=# SELECT * FROM extract_cpu('pict','/var/lib/postgresql/work/2020AdventCalendar/image/test_slonik_02.png'), classes WHERE column3 = cid ORDER BY column4 DESC LIMIT 3;
column1 | column2 | column3 | column4 | cid | no | class
---------+-----------------------------------------------------------+---------+------------+-----+-----------+--------------------------
6773 | /mnt/share/Pictures/PostgreSQL_logo.3colors.120x120.png | 512 | 0.93299615 | 512 | n03100240 | convertible
3472 | /mnt/share/Pictures/2005/20051102-ishikawa/DSCF1276.JPG | 896 | 0.87577224 | 896 | n04552348 | warplane, military plane
2344 | /mnt/share/Pictures/2002/2002.02.07/MobilePhone_Jacky.JPG | 285 | 0.8745841 | 285 | n02123597 | Siamese cat, Siamese
(3 行)
pid=6773、類似度0.93299615のPostgreSQL_logo.3colors.120x120.png。

めちゃくちゃ丁寧にクエリ画像を用意できれば、きちんと結果を返してくれそうです。ただ、分類はまだまだ伸びしろがアリそうです(convertibleはオープンカーのことみたい)。
現場からは以上です。
まとめ
当初想定した操作をするには、絵画の力を伸ばす必要がありそうですが、まぁ下地はできたと言うことでよしとしましょう。(金持ちへの道は険しい・・・)
明日はtom-satoさんのPgpool-II 4.2のお話です!