自身の忘備録も兼ねて、今回のプロジェクトで行ったことをできる限り詳しく記述する。
また、内容が非常に長いため、必要に応じて各項目に飛んで閲覧していただきたい。
1. はじめに
1.1 背景:交通量調査における人的負荷の現状
現在、交通量計測は少なくとも日本国内においては調査員による目視観測が主流であるが、その業務は単なる通過数のカウントに留まらず、多種多様な車種の瞬時な判別も同時に求められる。また、屋外での長時間におよぶ調査は季節や天候の影響をダイレクトに受ける過酷な環境下にあり、ヒューマンエラーの発生や労働負荷の増大が課題となっている。
1.2 課題:データ取得の精度と継続性
車両の交通量は時間帯や曜日によって刻々と変化するため、本来であれば継続的なデータ収集が望ましい。しかし、人手に頼る現状では調査頻度や期間に物理的な制約があり、より詳細かつ高頻度な情報取得を自動化する仕組みが求められている。
1.3 本記事の目的
上記のような課題に対し、本記事では、最新のエッジデバイスであるRaspberry Pi 5を用いたリアルタイム車種判別システムの構築を試みる。高価な機材を必要としないエッジAIの実装により、現場の作業支援およびデータ収集の自動化に向けた技術的検証を行うことを目的とする。
また、この記事の内容を実行するにあたり、chatGPTをサポートとして使用した。
2. システム構成
本システムの構築および検証に使用した環境を、学習フェーズとリアルタイム検出(推論)フェーズに分けて記述する。
2.1 学習環境(モデル構築フェーズ)
膨大な演算を必要とする学習フェーズでは、以下のPCリソースを使用した。
ハードウェア
- CPU : Intel Core i7-13700KF
- GPU : Nvidia GeForce RTX3060 12GB
- RAM : DDR5 32GB
ソフトウエア
- OS : Windows 11 64-bit
- WSL2 : Ubuntu 24.04 LTS
- 言語 : Python 3.12.6
- アノテーションツール : CVAT 2.45.1
- 使用したPythonライブラリ
- PyTorch 2.7.0+cu126
- ultralytics 8.3.214
- CUDAバージョン : 12.8
- 使用モデル : YOLOv8s-seg
Ultratics YOLOは商用利用しようとするとAGPLライセンスの関係で非常に高いライセンス料の支払いやソースコードの公開の必要性が出てくる。そこで、実際の企業で使用することを想定してより柔軟な運用が可能なApache 2.0が適用されている、OpenMMLabが提供しているMMDetectionを使用して再実装する予定である。再実装が完了し次第この記事の一番後ろに追記をする。また、GitHub上に掲載するものは、MMDetectionによる再実装が完了し次第そちらを掲載するものとする。
2.2 推論環境(リアルタイム検出フェーズ)
現場での運用を想定した推論環境には、以下のエッジデバイス構成を採用した。
ハードウェア
- 本体: Raspberry Pi 5 (16GB)
- カメラ: Logicool C992n PRO HD STREAM WEBCAM
- 冷却: 公式Active Cooler
ソフトウェア
- OS: Raspberry Pi OS (64-bit)
3. データセットの詳細
3.1 画像の収集方法
データセットに使用した画像は以下の3種類の方法で収集した。収集した枚数が多いものから順に並べる。
- 自身でスマホ、コンデジによる撮影
- 知り合いに依頼して撮影してもらう
- O-DANで商用利用可能な画像を検索・ダウンロードして使用
様々な時間帯、天候、角度を意識して撮影および収集を行った。
収集期間:2025年5月~12月
3.2 データセットの内訳

データセットを作成するにあたり画像は4,906枚、5,816オブジェクトのアノテーションを行い作成した。
データセットの内訳は上記グラフの通りである。クラスは上記グラフの通り14種類用意して、町中を走行しているほとんどの車両に対応できるようにした。クラスは以下の通りで、この名前を英語名に直してクラス名を設定した。
- 軽自動車
- セダン
- クーペ
- SUV
- ミニバン
- 小型トラック
- 大型トラック
- バス
- スクーター(ATバイク)
- バイク(MTバイク)
- コンパクトカー
- ステーションワゴン
- 業務用バン
- ハッチバック
データセットはGitHubでの配布用に COCO 1.0 、学習用に Ultralytics YOLO Segmentation 1.0 のフォーマットでそれぞれエクスポートした。
4. 使用したツールについて
今回は走行している自動車の検出と、その後の発展性を考えYOLOv8を用いてインスタンスセグメンテーションを行う。開発にあたり、以下のツールおよび環境を使用した。
一部ツールについて導入作業が必要なものもあるが、公式サイトを含め、他のサイト等で導入についての解説がされているので割愛する。
4.1 アノテーションツール「CVAT」
CVAT.aiが提供しているアノテーションツールで、"Computer Vision Annotation Tool"の各単語の頭文字をとって名付けられている。このツールはUbuntu及びMacOS上で動作する。Windows上で動作させるにはWSL2を用いてUbuntu上で動作させる必要がある。CVATの導入には公式ドキュメントやQiitaサイトを参照してほしい。

この画像は実際のCVATのアノテーション作業画面である。
公式ドキュメント | インストールガイド
CVATのセットアップ方法 #AI - Qiita
4.2 Visual Studio Code
Microsoftが開発・提供しているソースコードエディタである。今回はモデルの学習を目的に、Jupyter Notebook形式のファイル(.ipynb)を実行するため、Raspberry Pi 5を通してRaspberry Pi AI HAT+に搭載されているHAILO-8 AIプロセッサで動作させるためにモデルを変換及び実行するためのコードを書くために使用した。
Jupyter Notebook形式のファイルを実行するために"Jupyter"及び、それに関連するすべての拡張機能を有効化して実行した。
4.3 Ultralytics YOLO
Ultralytics YOLOはUltralyticsによってリリースされているYOLOのモデルである。今回の学習時はUltralytics YOLOをpipを介してインストールし使用した。
4.4 モザイク処理に使用したAIモデル
今回学習に使用した画像は実際に路上から撮影したものを使用している。そのため、車両のナンバープレートやドライバーの顔が写ってしまっている場合が非常に多い。GitHub上にデータを公開する上でプライバシーの保護が必要なので、ナンバープレートとドライバーの顔の部分にモザイクを掛けることにした。
モザイク処理を行うためにまずはそのターゲットを検出しないといけないが、今回は各ターゲットに対して以下のリポジトリにあるモデルを使用した。
顔検出に使用したモデル
ナンバープレート検出に使用したモデル
モザイクについては以下のコードをChatGPTに生成させて、実行した。
ファイルパスの表記がWindows環境での書き方になっているので、適宜環境に応じてパスの書き方を変更していただきたい。
モザイク処理に使用したコード
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
auto_mask_yolov8_face_plate.py
- YOLOv8-Face (large) と YOLOv8 Plate (任意) を使い、顔 + ナンバープレート領域を自動マスク
- 顔モデルはユーザー指定の large 重みを想定
- プレートモデルが未指定なら簡易輪郭検出でフォールバック
- マスク結果は出力フォルダに images/ として別名保存(元画像は上書きしません)
- 設定はこのファイルの上部だけ編集してください
"""
from pathlib import Path
import cv2
import numpy as np
import sys
# ========== 設定(ここだけ編集) ==========
SRC_DIR = Path(r"Path\to\your\Folder") # 入力画像フォルダ
DST_DIR = Path(r"Path\to\your\Folder") # 出力フォルダ
YOLO_FACE_MODEL_PATH = Path(r"Path\to\your\Folder\yolov8l_100e_face.pt") # YOLOv8-Face large の重みパス(必ず指定)
YOLO_PLATE_MODEL_PATH = Path(r"Path\to\your\Folder\license_plate_detector(v8).pt") # ナンバープレート用YOLOv8重み(持っていればPath(...)で指定)、なければ None
MASK_TYPE = "blur" # "blur" or "black"
BLUR_KERNEL = (201,201) # odd x odd
CONF_FACE = 0.35 # 顔検出の confidence 閾値(必要なら調整)
CONF_PLATE = 0.25 # プレート検出の confidence 閾値
IMG_SIZE = 1280 # 推論時リサイズ (モデルに合わせる)
MIN_PLATE_AREA = 1750 # 簡易検出フォールバックの最小面積
IOU_MERGE_THRESH = 0.4 # 重複ボックスをマージする閾値
# ========================================
# 準備
DST_IMAGES = DST_DIR / "images"
DST_IMAGES.mkdir(parents=True, exist_ok=True)
# ultralytics (YOLOv8) をロードする (顔モデルは必須扱い)
USE_YOLO_FACE = False
USE_YOLO_PLATE = False
face_model = None
plate_model = None
try:
from ultralytics import YOLO
except Exception as e:
print("ERROR: ultralytics が import できません。`pip install ultralytics` を実行してください。")
print("詳細:", e)
sys.exit(1)
# 顔モデルロード (必須)
if YOLO_FACE_MODEL_PATH is None or not YOLO_FACE_MODEL_PATH.exists():
print("ERROR: YOLO_FACE_MODEL_PATH を指定して存在するファイルパスにしてください。")
sys.exit(1)
print("YOLOv8-Face (large) をロードしています:", YOLO_FACE_MODEL_PATH)
face_model = YOLO(str(YOLO_FACE_MODEL_PATH))
USE_YOLO_FACE = True
print("Face model loaded. classes:", face_model.names)
# プレートモデルは任意
if YOLO_PLATE_MODEL_PATH:
if not YOLO_PLATE_MODEL_PATH.exists():
print("WARNING: 指定した YOLO_PLATE_MODEL_PATH が存在しません。フォールバックで簡易検出を使います。")
YOLO_PLATE_MODEL_PATH = None
else:
print("YOLOv8 Plate model をロードしています:", YOLO_PLATE_MODEL_PATH)
plate_model = YOLO(str(YOLO_PLATE_MODEL_PATH))
USE_YOLO_PLATE = True
print("Plate model loaded. classes:", plate_model.names)
else:
print("Plate model 未指定。簡易輪郭検出にフォールバックします。")
# 画像読み込みユーティリティ(Unicode対応)
def imread_unicode(path: Path):
try:
arr = np.fromfile(str(path), dtype=np.uint8)
img = cv2.imdecode(arr, cv2.IMREAD_COLOR)
return img
except Exception:
return None
# bbox形式変換ユーティリティ: ultralytics result -> (x,y,w,h)
def extract_boxes_from_yolo_result(res, conf_thresh):
boxes = []
try:
r = res[0]
if hasattr(r, "boxes") and len(r.boxes) > 0:
xyxy = r.boxes.xyxy.cpu().numpy() # (N,4)
confs = r.boxes.conf.cpu().numpy() if hasattr(r.boxes, "conf") else None
for i, box in enumerate(xyxy):
conf = confs[i] if confs is not None else 1.0
if conf < conf_thresh:
continue
x1, y1, x2, y2 = map(int, box[:4])
boxes.append((x1, y1, x2 - x1, y2 - y1))
except Exception:
# defensive fallback
try:
for pred in res:
if hasattr(pred, "boxes"):
for b in pred.boxes:
conf = float(b.conf) if hasattr(b, "conf") else 1.0
if conf < conf_thresh:
continue
xyxy = b.xyxy
x1, y1, x2, y2 = map(int, xyxy[:4])
boxes.append((x1, y1, x2 - x1, y2 - y1))
except Exception:
pass
return boxes
# 簡易プレート検出フォールバック(輪郭ベース)
def simple_plate_detector_gray(gray):
blurred = cv2.bilateralFilter(gray, 9, 75, 75)
edged = cv2.Canny(blurred, 50, 200)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5,5))
closed = cv2.morphologyEx(edged, cv2.MORPH_CLOSE, kernel)
cnts, _ = cv2.findContours(closed, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
boxes = []
for c in cnts:
area = cv2.contourArea(c)
if area < MIN_PLATE_AREA:
continue
rect = cv2.minAreaRect(c)
(cx,cy),(w,h),ang = rect
if w == 0 or h == 0:
continue
ratio = max(w,h) / min(w,h)
if ratio > 2.0 and ratio < 7.0 and area > MIN_PLATE_AREA:
box = cv2.boundingRect(c)
boxes.append(box)
return boxes
# IoU と簡易マージ(重なりが高ければ一つの大きな矩形に統合)
def iou_xywh(b1, b2):
x1, y1, w1, h1 = b1
x2, y2, w2, h2 = b2
xa = max(x1, x2)
ya = max(y1, y2)
xb = min(x1 + w1, x2 + w2)
yb = min(y1 + h1, y2 + h2)
inter_w = max(0, xb - xa)
inter_h = max(0, yb - ya)
inter = inter_w * inter_h
area1 = w1 * h1
area2 = w2 * h2
union = area1 + area2 - inter
if union == 0:
return 0.0
return inter / union
def merge_boxes(boxes, iou_thresh=IOU_MERGE_THRESH):
"""
boxes: list of (x,y,w,h)
単純なグリーディマージ:重複する箱をまとめる
"""
if not boxes:
return []
boxes = boxes.copy()
merged = []
while boxes:
base = boxes.pop(0)
bx, by, bw, bh = base
changed = True
while changed:
changed = False
new_boxes = []
for other in boxes:
if iou_xywh(base, other) >= iou_thresh:
# merge into base -> expand to bounding rect
ox, oy, ow, oh = other
x_min = min(base[0], ox)
y_min = min(base[1], oy)
x_max = max(base[0] + base[2], ox + ow)
y_max = max(base[1] + base[3], oy + oh)
base = (x_min, y_min, x_max - x_min, y_max - y_min)
changed = True
else:
new_boxes.append(other)
boxes = new_boxes
merged.append(base)
return merged
# マスク適用
def apply_mask(img, box, mask_type=MASK_TYPE):
x, y, w, h = box
x1, y1 = max(0, int(x)), max(0, int(y))
x2, y2 = min(img.shape[1], int(x + w)), min(img.shape[0], int(y + h))
if x1 >= x2 or y1 >= y2:
return img
roi = img[y1:y2, x1:x2]
if mask_type == "blur":
kx, ky = BLUR_KERNEL
kx = kx if kx % 2 == 1 else kx + 1
ky = ky if ky % 2 == 1 else ky + 1
blurred = cv2.GaussianBlur(roi, (kx, ky), 0)
img[y1:y2, x1:x2] = blurred
else:
img[y1:y2, x1:x2] = 0
return img
# メイン処理ループ
image_paths = sorted([p for p in SRC_DIR.iterdir() if p.is_file() and p.suffix.lower() in {".jpg",".jpeg",".png"}])
print(f"処理対象画像数: {len(image_paths)}")
total = 0
masked_count = 0
notread = []
for p in image_paths:
total += 1
img = imread_unicode(p)
if img is None:
print("読み込み失敗:", p.name)
notread.append(p.name)
continue
h, w = img.shape[:2]
boxes = []
# 1) 顔検出 (YOLOv8-Face)
try:
res_face = face_model.predict(source=str(p), imgsz=IMG_SIZE, conf=CONF_FACE, verbose=False)
face_boxes = extract_boxes_from_yolo_result(res_face, CONF_FACE)
boxes.extend(face_boxes)
except Exception as e:
print("WARNING: Face model inference failed for", p.name, ":", e)
# 2) ナンバープレート検出 (YOLOv8 Plate or fallback)
plate_boxes = []
if USE_YOLO_PLATE and plate_model is not None:
try:
res_plate = plate_model.predict(source=str(p), imgsz=IMG_SIZE, conf=CONF_PLATE, verbose=False)
plate_boxes = extract_boxes_from_yolo_result(res_plate, CONF_PLATE)
except Exception as e:
print("WARNING: Plate model inference failed for", p.name, ":", e)
plate_boxes = []
if not plate_boxes:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plate_boxes = simple_plate_detector_gray(gray)
boxes.extend(plate_boxes)
# 3) マージして被覆範囲を整理
boxes_merged = merge_boxes(boxes, iou_thresh=IOU_MERGE_THRESH)
# 4) マスク適用
for b in boxes_merged:
img = apply_mask(img, b, mask_type=MASK_TYPE)
# 5) 保存(Unicode対応)
outp = DST_IMAGES / p.name
ext = p.suffix.lower()
success, encimg = cv2.imencode(ext, img)
if success:
encimg.tofile(str(outp))
masked_count += 1
else:
print("出力失敗:", p.name)
print("==== 完了 ====")
print(f"総画像: {total}, マスク済み: {masked_count}, 読み込み失敗: {len(notread)}")
if notread:
print("読み込み失敗例:", notread[:20])
このコードを使用しても画像全体に対してモザイクを掛けてしまったり、反対にナンバープレート全体がはっきりわかる状態なのにモザイクがかかっていないという状況も発生した。それに対して今回はGIMPを使用して不適切なモザイク処理が行われている画像に対して、手作業でモザイク処理または塗りつぶしの処理を行った。
ナンバープレートに関しては以下の部分の内、どちらかが隠れていれば合格とした。
- 地域名および分類番号
- ひらがな部およびナンバー
下のサンプル画像を例にすると
- 横浜 34
- ん 11-11
これのどちらかが隠れていることが合格の条件として設定した。

このナンバープレートサンプルは以下のサイトを使用して作成した。
5. 最適化アルゴリズム(Optimizer)の選択について
世の中で使用されている最適化アルゴリズムは多々あり、有名なものであれば最急降下法(GD)、確率的勾配降下法(SGD)、RMSProp、Adamなどがあるが、今回はAdamを使用することとした。その上で、なぜAdamを使うに至ったかを説明する。
5.1 確率的勾配降下法(SGD)とAdamの比較
今回検討した最適化アルゴリズムは確率的勾配降下法とAdamの2つの選択肢があった。その中で確率的勾配降下法を選択しなかった理由として、数万枚単位のデータセットを使用するときにこの方法を使用すること、epoch数が進んでいくにあたって最終的な学習率の調整が大変そうだという理由から今回は選択をしませんでした。それに対しAdamは、多くても数万枚単位くらいまでを目安に使われるということと、学習率の調整を勝手にしてくれるということでAdamを選択した。
以下に自身の理解における各最適化アルゴリズムの特徴を記述する。
| SGD | Adam | |
|---|---|---|
| 使用される規模 | 中~大規模 | 小~中規模 |
| 扱いやすさ | 難しい | 簡単 |
5.2 AdamWの存在について
Ultralytics YOLOの最適化アルゴリズムは確率的勾配降下法とAdam以外にもAdamの改良版であるAdamW (Adam with Decoupled Weight Decay) の選択が可能であった。しかし、当初アルゴリズムを選択するときにAdamWの技術的な理解が十分ではなかったため、不確実な要素を排除するという意味で採用を見送った。しかし、Adamで学習を続けていくにつれて、Weight Decay(重み減衰)を用いて調整する部分の扱いについて、より効率的に改善されている点がAdamWの大きな改善点なのではないかと気づいた。今回はAdamのままで学習を行ったが今後、重みの調整が自動で最適化されるAdamWを使用するとさらなる制度の向上が見込めるのではないかと考えたため、今後の課題とすることにした。
6. モデルの学習
モデルのが学習は学習済みのモデルに対して学習を行うタイプではなく、まっさらな状態のモデルに対して学習を行うようにした。理由としては、学習済みのモデルに記録されているクラスの情報を無効化するのが手間だと感じたというのが大きな理由である。そのため、Ultralytics のサイトからyolov8-seg.yamlというファイルをダウンロードしてきてyolov8s-seg.yamlとすることでYOLOv8sのセグメンテーション用モデルとして設定し、学習を進めた。
6.1 学習用スクリプトの実装
学習にはUltralytics YOLOのAPIを用いた。再現性を確保するため、コマンドライン引数ではなく、以下のようなPythonスクリプトをJupyter Notebook形式のファイルに書き込んで学習を実行した。
import torch
from ultralytics import YOLO
# setting model
model = YOLO(r"yolov8s-seg.yaml")
#Train
results = model.train(data=r"dataset.yaml",
epochs=100,
imgsz=800,
batch = 16,
plots = True,
optimizer = "Adam",
lr0=0.0005, # Initial
cos_lr=False, # Cos scesuler
cls = 0.3, # default:0.5
workers = 8, # Use CPU's
nbs = 128, # default 64
label_smoothing = 0.05,
weight_decay = 0.005
)
今回学習を行い、Valitationの結果から実用的な性能を出せそうなものは上記のハイパーパラメーターを設定して学習を行ったものである。
epoch数に関しては100のものと125のものを用意し、人間の目で見たのと同じ感覚で検出できるもの、より小さいものまで検出できるようになったものとして2つ用意した。
6.2 主要なハイパーパラメーターの設定根拠
本検証では、リアルタイム性を重視し、モデルの軽量化と精度のバランスを考慮して以下の設定を採用した。
- モデルサイズ
YOLOv8s: 当初はRaspberry Pi AI HAT+に搭載されているHAILO-8でもほぼ確実に動くであろうYOLOv8n (Nano) を選択する予定だった。しかし、精度面で不安が残ったため、リアルタイム動作において15FPSくらいで動いてなおかつ高い精度を維持できれば実用的なのではないかと考え、できる限り高い精度を維持しつつリアルタイムでも動きそうなYOLOv8s (Small) を選択 - 入力画像サイズ
800px: 当初はYOLOやそれ以外のMask R-CNN等でも使用される640pxで学習を行っていた。しかし、ハイパーパラメーターを少し調整してみても物体の検出精度やクラス割り当ての精度がなかなか改善しなかったため、細部の特徴を学習させるために入力画像サイズを800pxに設定 - コサイン学習率スケジューラ
cos_lr=False: デフォルトの設定ではTrueになっていたが、最適化アルゴリズムのAdamとの相性が悪く、後半の学習が抑制され細かいディテールなどの学習が進まなかったため無効化した - ラベル平滑化
label_smoothing = 0.05: 学習を行っているときに過学習の兆候が見え隠れしていたのでラベル平滑化の効果を追加するためにデフォルトでは0になっていたところ、0.05の数値に設定することで効果をわずかながら追加し、過学習を抑制した
7. 学習したモデルの性能について
モデルのテストには学習用・検証用とは別に撮影した214枚の画像を使用して学習済みモデルの性能をテストした。撮影した車種はランダムである。前述したとおりモデルはepoch数で区別し、100epochのものと125epochの2つを用意している。各数値については、マスクを行った時の精度を表記する。
結果は以下のとおりである。
| mAP50 | mAP50-95 | |
|---|---|---|
| (val)100epoch | 32.8 | 32.2 |
| (val)125epoch | 29.2 | 28.6 |
| (test)100epoch | 87.0 | 85.1 |
| (test)125epoch | 90.1 | 87.9 |
誤検出・誤分類の内訳(Confusion Matrix)
Valitation
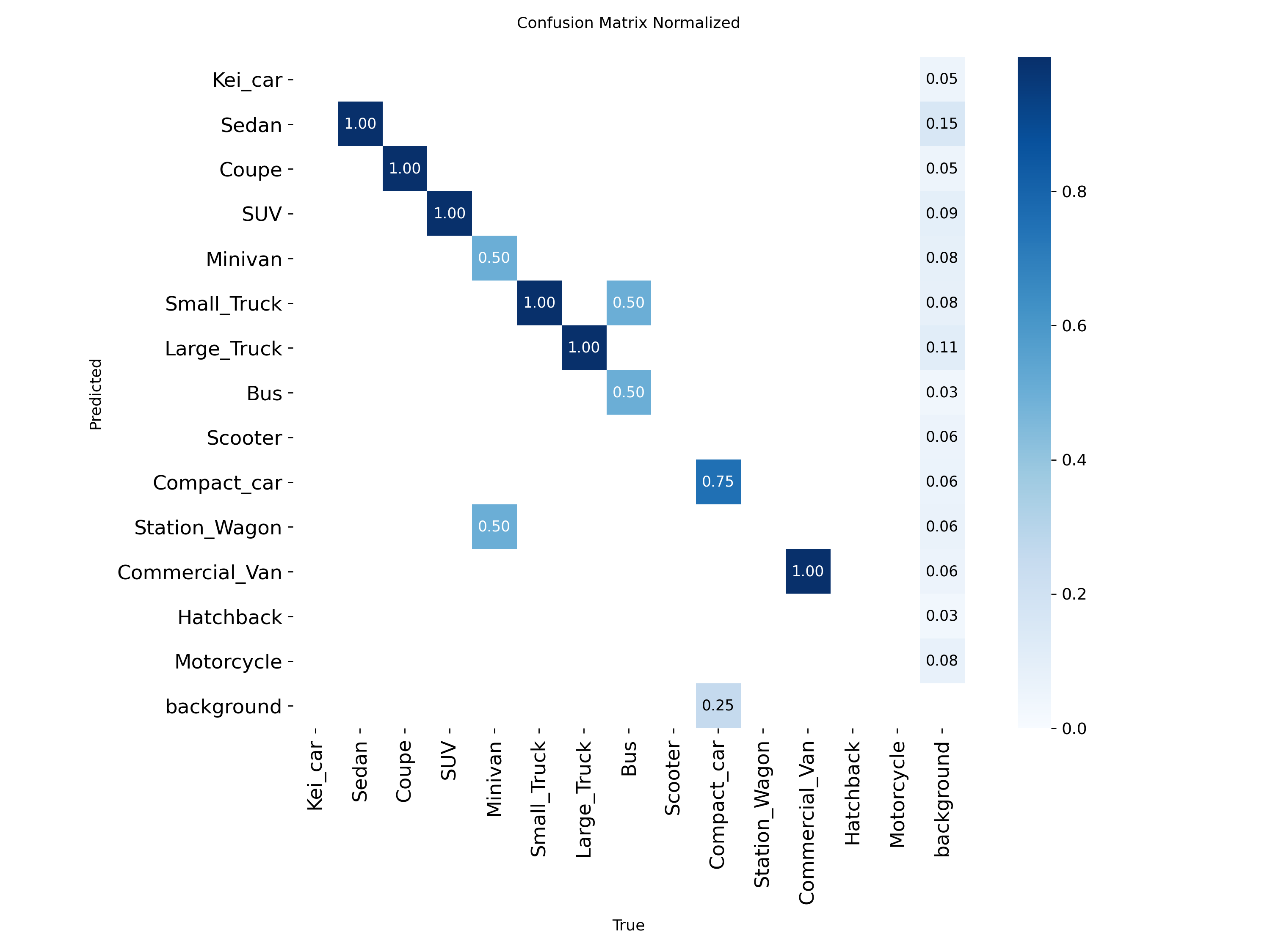 (val)100epoch の結果
(val)100epoch の結果
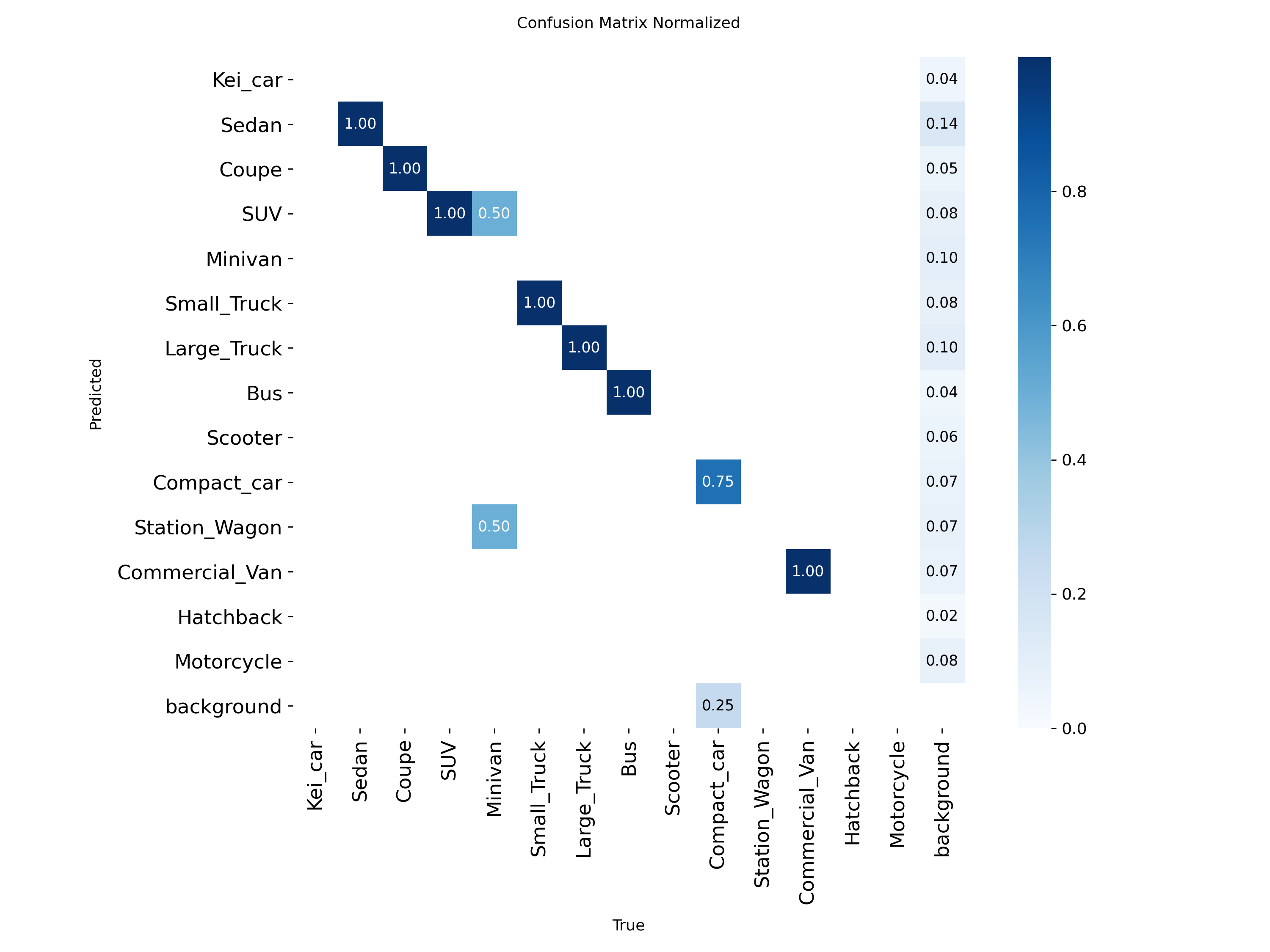 (val)125epoch の結果
(val)125epoch の結果
Test
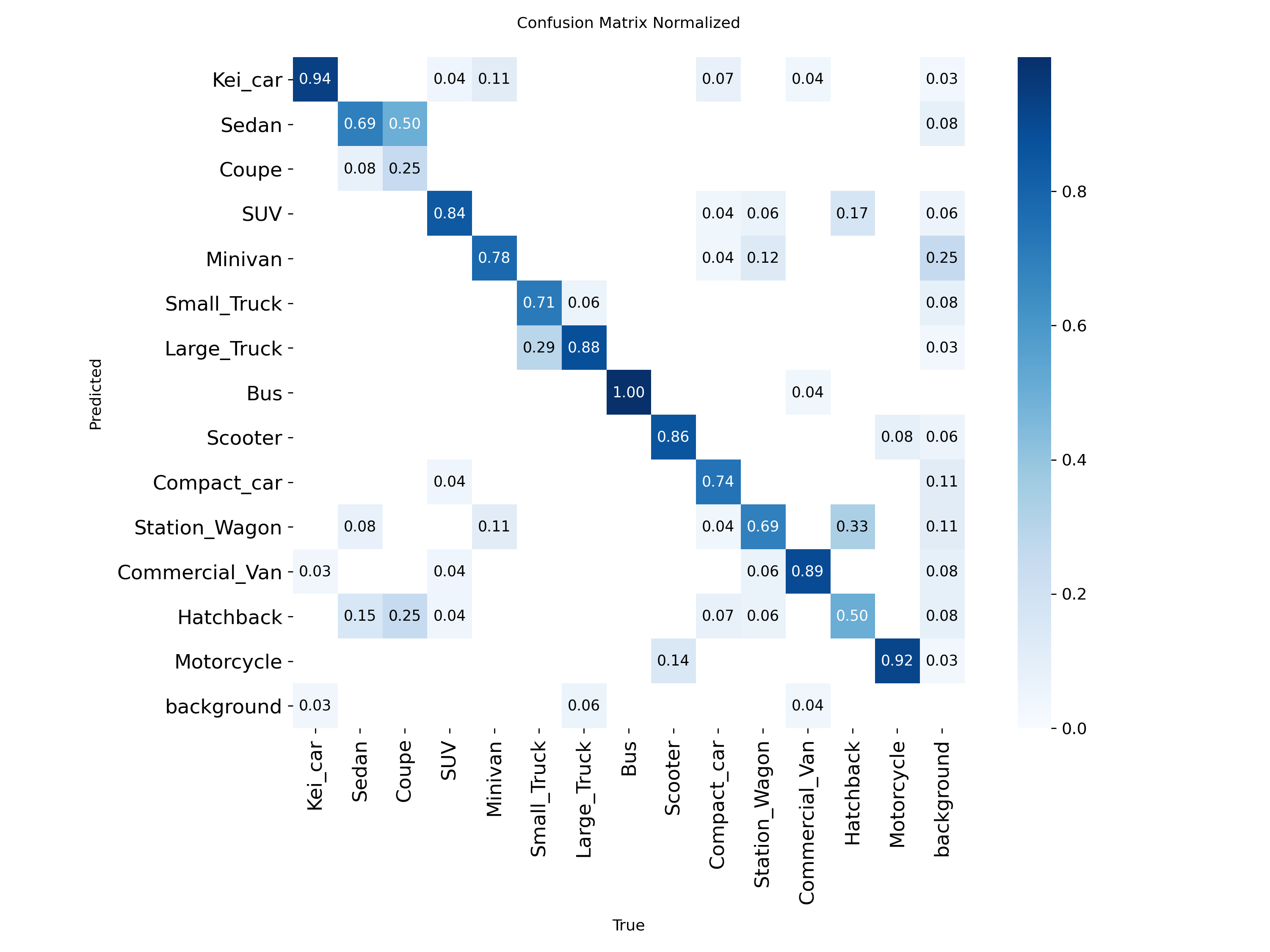
(test)100epoch の結果

(test)125epoch の結果
今回の結果から、125epochのものについてはvalの結果から100epochのものと比較して数値の低下がみられることから、過学習の傾向が見受けられると判断した。そのため、実際に使用する場合には100epochのものを使用することが妥当であると考えた。
また、本テストデータセットでは比較的大きな物体が多く含まれているため、実運用環境においては物体サイズの縮小や撮影条件の変動により、本テスト結果よりも低い検出精度となる可能性がある。
8. リアルタイム実装と動作検証
次に、学習済みのUltratics YOLOv8-seg のモデルを Raspberry Pi5 で動作できるようにし、どのくらいの精度を保つことができるのかを検証する。Raspberry Pi5 の拡張モジュールとして、AI HAT+ が存在するが今回は使用することができなかった。できなかった理由については以下の折り畳み部に詳細を記述する。
AI HAT+(Hailo-8)を使用しなかった理由
Hailo-8でつかえるようにするためには以下の画像のような段階を踏む必要がある。この画像はSky株式会社のTech Blogから引用した。

問題が発生したのは、上記画像の「ONNXからHARへの変換」の部分で発生した。内容としては、hailo parser を使用して変換を行うが以下の通り後処理の部分を含めたモデル全体の変換を行おうとしたときにエラーが発生した。
(hailo_virtualenv) hailo@machineName:~/models/yolov8_seg$ hailo parser onnx train48_best_epc125.onnx \
--end-node-names \
"/model.22/Concat_1" \
"/model.22/Concat_2" \
"/model.22/Concat_3" \
"/model.22/Concat_4" \
"/model.22/proto/cv3/act/Mul"
[info] No GPU chosen and no suitable GPU found, falling back to CPU.
[info] Current Time: 23:13:05, 01/25/26
[info] CPU: Architecture: x86_64, Model: 13th Gen Intel(R) Core(TM) i7-13700KF, Number Of Cores: 24, Utilization: 0.2%
[info] Memory: Total: 15GB, Available: 9GB
[info] System info: OS: Linux, Kernel: 6.6.87.2-microsoft-standard-WSL2
[info] Hailo DFC Version: 3.33.0
[info] HailoRT Version: 4.23.0
[info] PCIe: No Hailo PCIe device was found
[info] Running `hailo parser onnx train48_best_epc125.onnx --end-node-names /model.22/Concat_1 /model.22/Concat_2 /model.22/Concat_3 /model.22/Concat_4 /model.22/proto/cv3/act/Mul`
[info] Translation started on ONNX model train48_best_epc125
[info] Restored ONNX model train48_best_epc125 (completion time: 00:00:00.37)
[info] Extracted ONNXRuntime meta-data for Hailo model (completion time: 00:00:01.14)
[info] NMS structure of yolov8 (or equivalent architecture) was detected.
[info] In order to use HailoRT post-processing capabilities, these end node names should be used: /model.22/cv2.0/cv2.0.2/Conv /model.22/cv3.0/cv3.0.2/Conv /model.22/cv2.1/cv2.1.2/Conv /model.22/cv3.1/cv3.1.2/Conv /model.22/cv2.2/cv2.2.2/Conv /model.22/cv3.2/cv3.2.2/Conv.
[info] Start nodes mapped from original model: 'images': 'train48_best_epc125/input_layer1'.
[info] End nodes mapped from original model: '/model.22/Concat_1', '/model.22/Concat_2', '/model.22/Concat_3', '/model.22/Concat_4', '/model.22/proto/cv3/act/Mul'.
[info] Translation completed on ONNX model train48_best_epc125 (completion time: 00:00:02.42)
[warning] hw_arch parameter not given, using the default hw_arch hailo8.
If another device is the target, please run again using one of hailo8, hailo8r, hailo8l
Traceback (most recent call last):
File "/local/workspace/hailo_virtualenv/bin/hailo", line 8, in <module>
sys.exit(main())
File "/local/workspace/hailo_virtualenv/lib/python3.10/site-packages/hailo_sdk_client/tools/cmd_utils/main.py", line 111, in main
ret_val = client_command_runner.run()
File "/local/workspace/hailo_virtualenv/lib/python3.10/site-packages/hailo_platform/tools/hailocli/main.py", line 64, in run
return self._run(argv)
File "/local/workspace/hailo_virtualenv/lib/python3.10/site-packages/hailo_platform/tools/hailocli/main.py", line 104, in _run
return args.func(args)
File "/local/workspace/hailo_virtualenv/lib/python3.10/site-packages/hailo_sdk_client/tools/parser_cli.py", line 212, in run
self._parse(net_name, args, tensor_shapes)
File "/local/workspace/hailo_virtualenv/lib/python3.10/site-packages/hailo_sdk_client/tools/parser_cli.py", line 298, in _parse
self.runner.translate_onnx_model(
File "/local/workspace/hailo_virtualenv/lib/python3.10/site-packages/hailo_sdk_common/states/states.py", line 16, in wrapped_func
return func(self, *args, **kwargs)
File "/local/workspace/hailo_virtualenv/lib/python3.10/site-packages/hailo_sdk_client/runner/client_runner.py", line 1204, in translate_onnx_model
return self._finalize_parsing(parser.return_data)
File "/local/workspace/hailo_virtualenv/lib/python3.10/site-packages/hailo_sdk_client/runner/client_runner.py", line 1278, in _finalize_parsing
full_config = self._get_nms_full_config(meta_arch)
File "/local/workspace/hailo_virtualenv/lib/python3.10/site-packages/hailo_sdk_client/runner/client_runner.py", line 2330, in _get_nms_full_config
classes = self._detect_num_of_classes(meta_arch, detected_nms_layers)
File "/local/workspace/hailo_virtualenv/lib/python3.10/site-packages/hailo_sdk_client/runner/client_runner.py", line 2368, in _detect_num_of_classes
reg_length = self.original_model_meta["detected_anchors"]["config_values"]["regression_length"]
KeyError: 'config_values'
このログの中の[info] NMS structure of yolov8 (or equivalent architecture) was detected.が主な原因なのではないかと考えた。ptからONNXへの変換時にNMSの処理を無効化して出力していたはずだが、ログを見るとNMSの構造を見つけた旨が書かれている。これは完全にHailo側のプログラムの勘違いなのではないかと推測した。そこで、明示的にNMSの処理を無効化できるか試してみることにした。
エラーログのNMSについて書かれている[info]の次の行に以下のように書かれていた。
[info] In order to use HailoRT post-processing capabilities, these end node names should be used: /model.22/cv2.0/cv2.0.2/Conv /model.22/cv3.0/cv3.0.2/Conv /model.22/cv2.1/cv2.1.2/Conv /model.22/cv3.1/cv3.1.2/Conv /model.22/cv2.2/cv2.2.2/Conv /model.22/cv3.2/cv3.2.2/Conv.
上記のコマンドを使用すればConvのところで変換の処理が止まりエラーを回避できるのではないかと考えたため、これを実行して、後処理を自分で実装しようと考えた。そこで、コマンドを以下の記述に変更して実行した。
hailo parser onnx train48_best_epc125.onnx \
--end-node-names \
"/model.22/cv2.0/cv2.0.2/Conv" \
"/model.22/cv2.1/cv2.1.2/Conv" \
"/model.22/cv2.2/cv2.2.2/Conv" \
"/model.22/cv3.0/cv3.0.2/Conv" \
"/model.22/cv3.1/cv3.1.2/Conv" \
"/model.22/cv3.2/cv3.2.2/Conv"
しかし、ここが大きな罠でよくよく考えてみると、最終のConvの部分で処理を止めるということはニューラルネットワークをそこでぶった切っていることに気づいた。そうすると全く異なるニューラルネットワークモデルに作り変えてしまっていることを理解したため、今回は AI HAT+ に搭載されている Hailo-8 は使用できないと判断し、Ultratics のドキュメントにある方法でモデルを変換し、Raspberry Pi5 の CPU で推論を実行し、今後の改善内容で Hailo-8 を活用することを目指すことにした。
Hailo-8についてはこちら
実装については下記の Ultratics のドキュメントに基本的には則って行う。
8.1 モデルの変換
モデルの変換は Windows PC 上で行う。モデルは学習済みの pt ファイルを使用して変換し、変換されたものは学習済みモデルの重みが保存されているフォルダの中に保存される。
from ultralytics import YOLO
from pathlib import Path
# ===== パス設定 =====
MODEL_PATH = Path("best.pt")
# ===== モデル読み込み =====
model = YOLO(MODEL_PATH)
# ===== NCNN へ変換 =====
model.export(
format="ncnn",
name="ncnn",
imgsz=800, # 基本的に学習時と同じ
half=False # 半精度を有効化するか否か
)
これを実行した結果、以下のような出力が得られればモデルの変換は完了している。
ここの出力に保存先のディレクトリが書かれているから、そこを参照すると変換後の NCNN モデルのフォルダを見つけることができる。
NCNN: export success 5.8s, saved as 'D:\projectName\yolo\weight\best' (45.2 MB)
今回指定した引数として、imgsz は 800 に指定した。これは、学習時に使用した画像の解像度を 800 に指定したため、それを引き継ぐ形で設定した。
8.2 Raspberry Pi 側の環境設定
Raspberry Pi で推論を行う前に環境設定を行う。
今回私はこれの作業用に Ultratics というフォルダを作成した。場所は ~/Ultratics にした。
次に仮想環境を立ち上げる。仮想環境を立ち上げる前に cd ~/Ultratics で、作業用のフォルダに移動する。この仮想環境はシステム側のPythonライブラリも参照させるようにしたいため、以下のコマンドで実行した。
python -m venv --system-site-packages ultratics
この仮想環境を有効化するために、source ultratics/bin/activate を実行し、以下のようなコマンド入力画面になっていれば問題ない。
(ultratics) userName@macineName:~/Ultratics $
次に、必要なライブラリをインストールする。今回は以下のコマンドを使用してインストールする。
pip install -U pip
pip install ultralytics
pip install ncnn
構築にはおおよそ15~30分程度かかった。
この構築が終了次第、sudo reboot で再起動をする。
8.3 NCNNモデルを使用した推論テスト
次に、構築した環境下で正しく推論が実行できそうかを検証する。まずは、変換したモデルのフォルダを ~/Ultratics/Model の中に配置する。その上で、以下のコードを実行した。
from ultralytics import YOLO
from pathlib import Path
model_path = Path("/home/useName/Ultratics/Model/best_model")
image_path = Path("~/Ultratics/test_images").expanduser()
output_path = Path("~/Ultratics/output").expanduser()
ncnn_model = YOLO(str(model_path), task='segment')
results = ncnn_model(image_path)
# results Visualized
# Single Only (For File)
# results[0].show()
# Save all result (For folder directory)
for r in results:
original = Path(r.path).name
save_path = output_path / original
r.save(filename=str(save_path))
print(f"Saved: {save_path}")
これを実行するにあたり、Windowsユーザーが気をつけないといけない点がある。1つ目はパスの指定方法が異なるということである。パスの指定方法についてだが、model_path は問題なかったが、同じように指定した image_path で KeyError が発生したため、.expanduser() を後ろに追加して解決した。
推論を行った画像は6枚で、1枚は 3916x2204 解像度だが、それ以外は 5184x3888 の解像度の画像を使用した。その結果、推論時間の平均は477.85ms、最大 519.1ms、最小 423.3ms の所要時間だった。
推論結果画像






小さいものだったり、間違えやすそうなディテールの車種はミスが発生しているように感じるが、全体的にはそこまで大きな問題は無いように見える。
8.4 カメラの動作検証
OpenCVを使用して、カメラの動作確認を行う。Windows PC → Raspberry Pi 5 の順に行う。
カメラの仕様として、フルHD(1920x1080)だと30FPSまでしか出ないが、HD(1280x720)だと60FPSのスピードが出る。そこで、推論時の入力である 800x800 に近い 16:9 の解像度である 1440x810 の解像度に設定した。その実行コードは以下の通りである。
import cv2 as cv
import time
cap = cv.VideoCapture(0)
# cam setting : 1440x810
cap.set(cv.CAP_PROP_FRAME_WIDTH, 1440)
cap.set(cv.CAP_PROP_FRAME_HEIGHT, 810)
cap.set(cv.CAP_PROP_FOURCC, cv.VideoWriter_fourcc(*'mp4v'))
cap.set(cv.CAP_PROP_FPS, 60)
# cam warmup
for _ in range(10):
cap.read()
cv.namedWindow("Webcam Live", cv.WINDOW_NORMAL)
cv.resizeWindow("Webcam Live", 960, 540)
prev_time = time.time()
max_fps = 0.0
fps_sum = 0.0
frame_count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
current_time = time.time()
fps = 1 / (current_time - prev_time)
prev_time = current_time
# getting fps data
max_fps = max(max_fps, fps)
fps_sum += fps
frame_count += 1
cv.putText(frame, f"FPS: {fps:.2f}", (20, 40),
cv.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv.imshow("Webcam Live", frame)
if cv.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv.destroyAllWindows()
# ===== print end time =====
if frame_count > 0:
avg_fps = fps_sum / frame_count
print("===== FPS Statistics =====")
print(f"Max FPS : {max_fps:.2f}")
print(f"Average FPS : {avg_fps:.2f}")
else:
print("No frames captured.")
実際にどのくらいのFPS値が出るのかを検証するために、ディスプレイに映っているYouTubeの動画をカメラで読み込ませてベンチマークの代わりとして検証した。動画を流した時間は20分で以下のような結果を得ることができた。
===== FPS Statistics =====
Max FPS : 162.46
Average FPS : 42.44
真正面から撮らずに雑な設置で撮影をしているから、参考値程度に捉えていただけるとありがたい。
次に、これを Raspberry Pi 5 でも同じように動くのか、どのくらいのFPS値が出るのかというのを検証する。 Raspberry Pi 5 においては、以下のコードを実行して同じ条件でベンチマークを行った。
import cv2 as cv
import time
cap = cv.VideoCapture(0)
# cam setting : 1440x810
cap.set(cv.CAP_PROP_FRAME_WIDTH, 1440)
cap.set(cv.CAP_PROP_FRAME_HEIGHT, 810)
cap.set(cv.CAP_PROP_FOURCC, cv.VideoWriter_fourcc(*'MJPG'))
cap.set(cv.CAP_PROP_FPS, 60)
# cam warmup
for _ in range(10):
cap.read()
cv.namedWindow("Webcam Live", cv.WINDOW_NORMAL)
cv.resizeWindow("Webcam Live", 960, 540)
prev_time = time.time()
max_fps = 0.0
fps_sum = 0.0
frame_count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
current_time = time.time()
fps = 1 / (current_time - prev_time)
prev_time = current_time
# getting fps data
max_fps = max(max_fps, fps)
fps_sum += fps
frame_count += 1
cv.putText(frame, f"FPS: {fps:.2f}", (20, 40),
cv.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv.imshow("Webcam Live", frame)
if cv.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv.destroyAllWindows()
# ===== print end time =====
if frame_count > 0:
avg_fps = fps_sum / frame_count
print("===== FPS Statistics =====")
print(f"Max FPS : {max_fps:.2f}")
print(f"Average FPS : {avg_fps:.2f}")
else:
print("No frames captured.")
ベンチマーク結果としては以下のような結果を得ることができた。
===== FPS Statistics =====
Max FPS : 133.82
Average FPS : 28.54
Windows PC ではビデオコーデックを mp4v に設定すると高いFPS値を得ることができたが、MJPG ではおおよそ10FPSほどしか得ることができなかった。逆に、Raspberry Pi 5 では正反対の結果になった。この現象の考えられる理由はドライバーが原因なのではないかと思っている。
このベンチマークの比較は Average FPS を見て比較した。
また、デフォルトでの露光調整等でどのように制御しているのか不明だったため、カメラのウオームアップとカメラのFPS上限値設定の間に以下のコードを追加して強制的に自動調整するようにした。これが正解なのかは見当がつかないが明示的に指示しておこうと思う。
# cam exposure setting
cap.set(cv.CAP_PROP_AUTO_EXPOSURE, 0)
因みに、これについては 0 が完全自動、1 がマニュアル、2 がシャッター優先、3 が露光時間優先らしいから、それに基づき設定した。
また、オートフォーカスも初期値は有効になっているかと思うがこれも不安だったから、露光調整等の設定コードの下に、以下のコードを追加してオートフォーカスも明示的に設定した。
# autofocus 1 = ON / 0 = OFF
cap.set(cv.CAP_PROP_AUTOFOCUS, 1)
8.5 リアルタイム検出コードの構築
次に、リアルタイム検出をするためのコードを構築する。ベースは前章 8.4 にある Raspberry Pi 用のカメラ動作のコードでそれに 8.3章で作成した推論用のコードを組み合わせる形を取る。
Hailo-8がこの章の最初の方に書いたとおり、諸事情により使用できないことから、CPU を使用して推論を行う。動くとは思うが動作時のFPS値は期待していない。
コードは以下のように記述した。
import cv2 as cv
import time
from pathlib import Path
from ultralytics import YOLO
cap = cv.VideoCapture(0)
# cam setting : 1440x810
cap.set(cv.CAP_PROP_FRAME_WIDTH, 1440)
cap.set(cv.CAP_PROP_FRAME_HEIGHT, 810)
cap.set(cv.CAP_PROP_FOURCC, cv.VideoWriter_fourcc(*'MJPG'))
cap.set(cv.CAP_PROP_FPS, 60)
# cam exposure setting
cap.set(cv.CAP_PROP_AUTO_EXPOSURE, 0)
# autofocus 1 = ON / 0 = OFF
cap.set(cv.CAP_PROP_AUTOFOCUS, 1)
# model loading
model_path = Path("/home/userName/Ultratics/Model/best_model")
ncnn_model = YOLO(str(model_path), task='segment')
# cam warmup
for _ in range(10):
cap.read()
cv.namedWindow("Webcam Live", cv.WINDOW_NORMAL)
cv.resizeWindow("Webcam Live", 960, 540)
prev_time = time.time()
max_fps = 0.0
fps_sum = 0.0
frame_count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# Inference
results = ncnn_model(frame, imgsz=800, verbose=False)
annotated_frame = results[0].plot()
current_time = time.time()
fps = 1 / (current_time - prev_time)
prev_time = current_time
# getting fps data
max_fps = max(max_fps, fps)
fps_sum += fps
frame_count += 1
cv.putText(annotated_frame, f"FPS: {fps:.2f}", (20, 40),
cv.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv.imshow("Webcam Live", annotated_frame)
if cv.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv.destroyAllWindows()
# ===== print end time =====
if frame_count > 0:
avg_fps = fps_sum / frame_count
print("===== FPS Statistics =====")
print(f"Max FPS : {max_fps:.2f}")
print(f"Average FPS : {avg_fps:.2f}")
else:
print("No frames captured.")
これを動作させたときのベンチマーク結果としては、以下のとおりである。
===== FPS Statistics =====
Max FPS : 2.38
Average FPS : 2.10
期待していなかった通りの結果を得ることができた。
9. Raspberry Pi 5 を用いたリアルタイム車種判別
今回はepoch100とepoch125の2種類のファイルを用意して実験を行う。事前に変換時に herf = True にしたものも動かしてみてどのような動作をするのかを確認したが、False のものと比較しても特に変化がなかったため、今回は使用しない。
9.1 実験条件と機器の環境
実験条件としては、各モデルにつき5分間のリアルタイム推論を行い、どのような動作をするのかというのを確認する。画面をキャプチャーしてどのように動いていたかを記録して、この場で共有をする。機器の接続は以下のように行った。
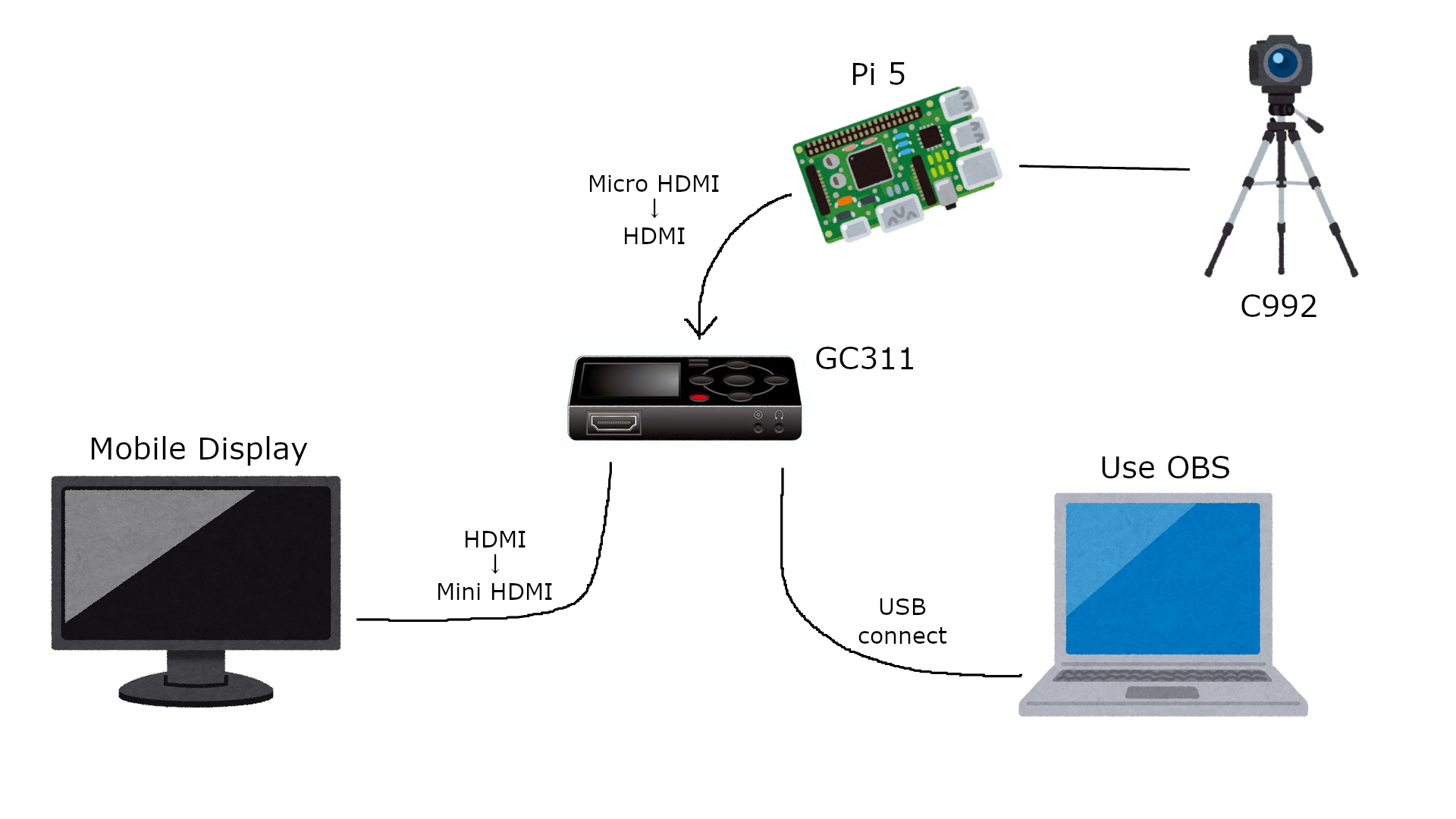
実行時の様子は GC311 というキャプチャーボードから出力された映像を取り込み、ノートパソコン上で動いている OBS Studio を使用して録画することにした。
キャプチャーボードからモバイルディスプレイに接続するのは必須ではないが、使い込んでいるノートパソコンのバッテリーが劣化している関係で駆動時間が短くなってしまっているため、できる限り負荷を掛けないようにすることを考え、画面確認用で接続している。
今回は千葉市役所付近の交差点で実施した。当時それらしき人物を見かけたと思うかもしれないが、個人の特定等を行う行為は控えていただけると非常にありがたい。
9.2 実験結果
実験結果は可もなく不可もなくといった感覚ではある。駐車場の入り口に設置してどのような車種がよく利用するのかというデータを取るのであれば、十分なのではないかと思う精度ではあった。
実際に動作している様子は以下の通りである。
epoch 100 のモデル
epoch 125 のモデル
10. ここまでの所感と今後の改善点
Ultralytics YOLO を使用して学習から推論を行った所感として、まず学習は思っていたよりも簡単に行えたが、調整できるパラメータが少なかったり説明されていないものも多々あったため痒いところに手が届かなそうだという感想を抱いた。
推論については、epoch数が100のもので十分だと思っていたが実際には、車両が思っていたよりも小さく映っていたため125でも性能が少し足りないと感じた。そこで、同じサイズのモデルを使用するとするならば、学習に使用する画像枚数を現在の2倍以上に増やし尚且つ、もっと小さく映っているもののデータも増やす方向で行えば同じepoch数でも性能が上がるのではないかと考えた。
次に、今後の改善点として以下のものが挙げられる。
- 商用利用時にライセンス料が発生してしまう点
- Hailo-8 のような推論用プロセッサに対応していなかった / できなかった点
これらを解決するために、今後の改善として OpenMMLab が提供している MMDetection が対応している RTMDet を使用してライセンス料の回避と、そのモデルを変換して Hailo-8 を活用した高速なリアルタイムの推論実現を目指す。