はじめに
本記事はJDLA E資格の認定プログラム「ラビット・チャレンジ」における深層学習day4のレポート記事です。
本記事では以下の6つの項目について、要点をまとめています。
- 強化学習
- AlphaGo
- 軽量化・高速化技術
- 応用モデル
- Transformer
- 物体検知・セグメンテーション
1. 強化学習
強化学習(Reinforcement learning)は「エージェント」が「環境」の「状態」に応じてどのように「行動」すれば「報酬」が多くもらえるかを決める手法です。教師あり学習や教師なし学習と違い、学習データなしに自身の試行錯誤のみで学習するのが特徴です。

さて、いろいろな用語が出てきましたので一つずつ見ていきましょう。
ここでは「異世界転生した人(異世界で右も左も分からないけど、まずは生き延びる)」を例に、強化学習の用語について整理していきます。
強化学習の用語
-
エージェントと環境
強化学習では、行動する主体を「エージェント」、エージェントがいる世界を「環境」と呼びます。
今回の例では、異世界転生した人が「エージェント」、転生した異世界が「環境」になります。エージェントは、歩き回ったり、水を飲んだり、武器を見つけたり等、環境への働きかけを通して、探索しながら生き延びる方法を探します。 -
行動と状態
エージェントが環境に行う働きかけを「行動」と呼びます。エージェントは様々な行動をとることができますが、どの行動を採るかによって、その後の状況も変わります。
例えば、どの方向に歩くかによって、見えるものや、できることも大きく変わります。エージェントの行動によって変化する環境の要素を「状態」と呼びます。
今回の例では、移動や休むなどの人の行動が「行動」、人の現在地が「状態」になるでしょうか。 -
報酬
同じ行動でも、どの状態で実行するかによって結果は大きく変わります。例えば、水を飲むという行動でも、川に流れるきれいな水を飲めば体力を回復しますが、海で海水を飲むと脱水症状になります。強化学習では、行動の良さを示す指標として「報酬」を使います。
今回の例では、川に流れるきれいな水を飲むとプラス報酬、海水を飲むとマイナス報酬になります。 -
即時報酬と遅延報酬
エージェントは基本的に報酬がたくさんもらえる行動を選べばよいのですが、行動直後に発生する報酬にこだわると、後で発生するかもしれない大きな報酬を見逃してしまします。
例えば、周囲を探索すると体力が消耗するため、休んだ方が報酬は高いですが、探索した結果、食料を発見するという大きな報酬が発生するかもしれません。
行動直後に発生する報酬を「即時報酬」、後で遅れて発生する手法を「遅延報酬」と呼びます。 -
収益と価値
強化学習では、即時報酬だけでなく、後で発生するすべての遅延報酬を含めた報酬の合計を最大化することが求められます。これを「収益」と呼びます。
報酬が環境から与えられるものなのに対して、収益は最大化したい目標としてエージェント自身が設定するものになります。
収益はまだ発生していない未来の出来事なので不確定です。そこで、エージェントの状態と方策を固定した場合の条件付き収益を計算します。これを「価値」と呼びます。この価値が大きくなる条件を探し出せれば、学習ができていることになります。
つまり、「価値の最大化」が「収益の最大化」につながり、さらには「多くの報酬をもらえる方策」という強化学習の目的につながります。
強化学習の学習サイクル
強化学習の学習サイクルについて、マルコフ決定過程と呼ばれる手法を例に説明します。
マルコフ決定過程は、「次の状態」が「現在の状態」と採った「行動」によって確定するシステムです。
- エージェントは、最初は何をすべきか判断できないため、採れる行動の中からランダムに決定する。
- エージェントは報酬をもらえた時に、どのような状態で、どのような行動をしたら、どの程度の報酬がもらえたかという経験を記録する。
- 経験に応じて方策を求める。
- ランダムな動きはしつつ、方策を手掛かりに行動を決定する。
- 2~4を繰り返して、将来的(ゲーム終了時まで)んじ多くの報酬を得られる方策を求める。
方策を求める手法
方策を求める手法は、大きく「方策反復法」と「価値反復法」の2つがあります。
-
方策反復法
方策に従って行動し、成功時の行動は重要と考え、その行動を多く取り入れるように方策を更新する手法です。この手法を利用したアルゴリズムの一つが方策勾配法になります。
方策勾配法は以下の式で表されます。
$$
θ^{t+1} = θ^t + ε∇J(θ)
$$
ニューラルネットワークでの勾配降下法と式が似ていますね。方策勾配法の期待収益である $ε∇J(θ)$ は勾配降下法では誤差関数に該当するでしょうか。勾配降下法では誤差を小さくするためにマイナスをしていましたが、方策勾配法は期待収益を大きくしたいのでプラスされていますね。 -
価値反復法
次の状態価値と今の状態価値の差分を計算し、その差分だけ今の状態価値を増やすような手法です。この手法を利用したアルゴリズムがSarsaとQ学習になります。
2. Alpha Go
Alpha GoはGoogle傘下のDeepMind社によって開発された、強化学習の技術を利用したコンピュータ囲碁プログラムです。囲碁のプロ棋士を破った初めてのAIになります。
Alpha Goのアルゴリズムは、旧来から使われる「モンテカルロ木探索」をベースとしており、この「探索」の「先読みする力」に、「深層学習」の局面から最善手を予測する「直感」と「強化学習」の自己対戦による「経験」を組み合わせることで、人間を超える最強のAIを実現しています。
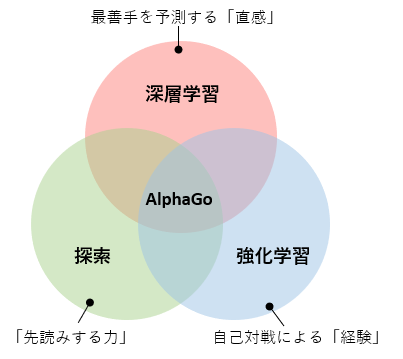
ここでは、Alpha Goの仕組みについて概要を説明します。
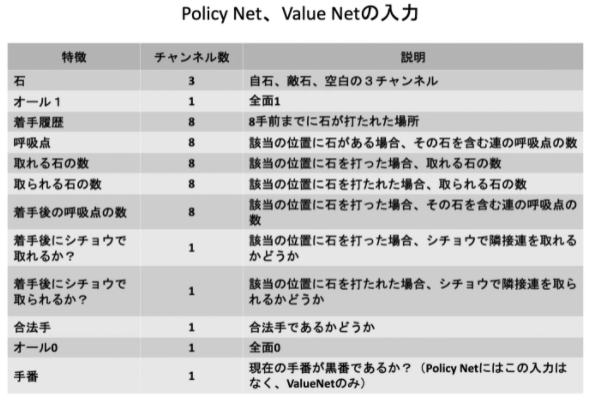
PolicyNet(方策関数)とValueNet(価値関数)について
方策と価値は関数として表すことができるので、それぞれ、方策関数、価値関数としてニューラルネットワークで学習させることができます。以下はネットワークの構造図です。

ValueNetでは、盤面からの情報を$19×19×48$として入力します。画像を扱うのでCNNですね。
出力では、どこに打てばよいのかの予想確率を出したいので、出力前の活性化関数はSoftMaxを使用しています。
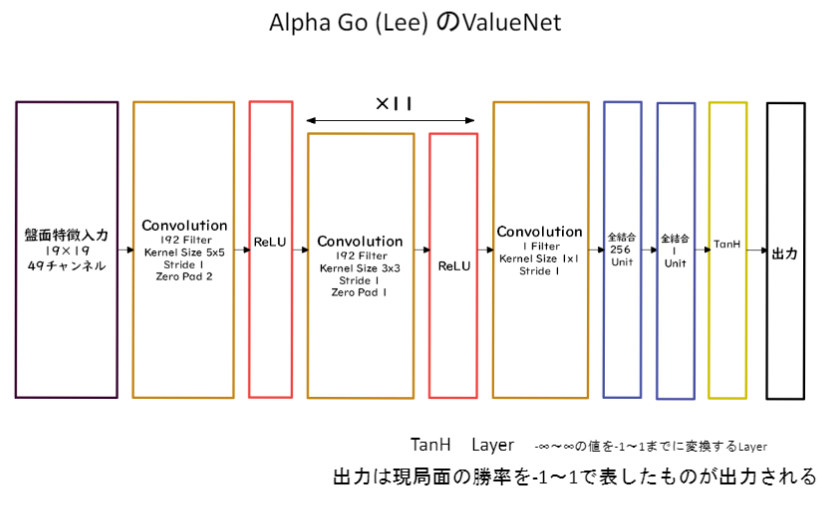
ValueNetはPolicyNetと大きく構造は変わりません。しかし、入力が1チャンネルふえて49となっています。また、出力は現局面の勝率を-1~1で表したいので、全結合層を用いて単一の値を出力するようにして、活性化関数としてtanhを用いています。
PolicyNetとValueNetの入力は次のようになっています。違いは、手番の有無のみです。
RollOutPolicy
ニューラルネットワーク(NN)ではなく、線形の方策関数です。
NNを用いたPolicyNetでは学習に時間が掛かかります。RollOutPolicyは探索中に高速に着手確率を出すために使用されます。PolicyNetと比較して計算速度は速いものの精度は落ちます。

モンテカルロ木探索
コンピュータ囲碁ソフトで現在もっとも有効とされている探索法です。
モンテカルロ木探索は、盤面の価値や勝率予想値が必要となるminmax探索やαβ探索とは違い、盤面評価値に頼らず末端評価値、つまり勝敗のみを使って探索を行うことができないかという発想で生まれた探索法です。
探索の流れは次のようになります。
- 現局面から末端局面までPlayOutと呼ばれるランダムシミュレーションを多数回行い、その勝敗を集計して着手の優劣を決定する。
- 該当手のシミュレーション回数が一定数を超えたら、その手を着手したあとの局面をシミュレーション開始局面とするよう、探索木を成長させる。
この探索木の成長を行うというのがモンテカルロ木探索の優れているところです。
モンテカルロ木探索はこの木の成長を行うことによって、一定条件下において探索結果は、最善手を返すということが理論的に証明されています。
Alpha Goのモンテカルロ木探索は、選択、評価、バックアップ、成長という4つのステップで構成されます。

Alpha Goの学習
- 教師あり学習によるRollOutPolicyとPolicyNetの学習
- 強化学習によるPolicyNetの学習
- 強化学習によるValueNetの学習
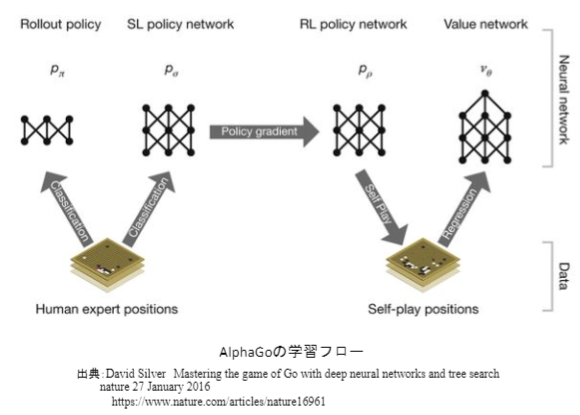
PolicyNetの教師あり学習
KGS Go Server(ネット囲碁対局サイト)の棋譜データから3000万局面分の教師を用意し、教師と同じ着手を予測できるよう学習を行います。
教師が着手した手を1、残りを0とした19×19次元の配列を教師とし、それを分類問題として学習させます。
この学習で作成したPolicyNetは57%ほどの精度となりました。
PolicyNetの強化学習
現状のPolicyNetとPolicyPoolからランダムに選択されたPolicyNetと対局シミュレーションを行い、その結果を用いて方策勾配法で学習を行います。PolicyPoolとは、PolicyNetの強化学習の過程を500Iteraionごとに記録し保存しておいたものです。現状のPolicyNet同士の対局ではなく、PolicyPoolに保存されているものとの対局を使用する理由は、対局に幅を持たせて過学習を防ごうという目的があります。
この学習をminibatch size 128で1万回行いました。
ValueNetの強化学習
PolicyNetを使用して対局シミュレーションを行い、その結果の勝敗を教師として学習させます。
教師データの作成手順は以下の通りです。
- SL PolicyNet(教師あり学習で作成したPolicyNet)でN手まで打つ。
- N+1手目の手をランダムに選択し、その手で進めた局面をS(N+1)とする。
- S(N+1)からRL PolicyNet(強化学習で作成したPolicyNet)で終局まで打ち、その勝敗報酬をRとする。
S(N+1)とRを教師データ対として、回帰問題として学習させます。この学習をminibatch size 32で5000万回行います。
N手までとN+1手からのPolicyNetを別々にしてある理由は、過学習を防ぐためであると論文では説明されています。
AlphaGo Zero
AlphaGo(Lee)とAlphaGo Zeroの違い
以下に違いをまとめました。
- 棋譜データを用いた教師あり学習を行わず、強化学習のみで作成。
- 特徴量として有効と思われる入力データ(PolicyNetなら48チャンネル)を人が用意せず、石のみの配置にした。
- PolicyNetとValueNetを1つのネットワークに統合。
- Residual Net(残差ブロック)を導入。
- モンテカルロ木探索からRollOutシミュレーションをなくした。
AlphaGo ZeroのNetwork
ネットワークの構造は次のようになっています。
Residual Block以降、PolicyNetとValueNetが分かれる構造になっていますね。
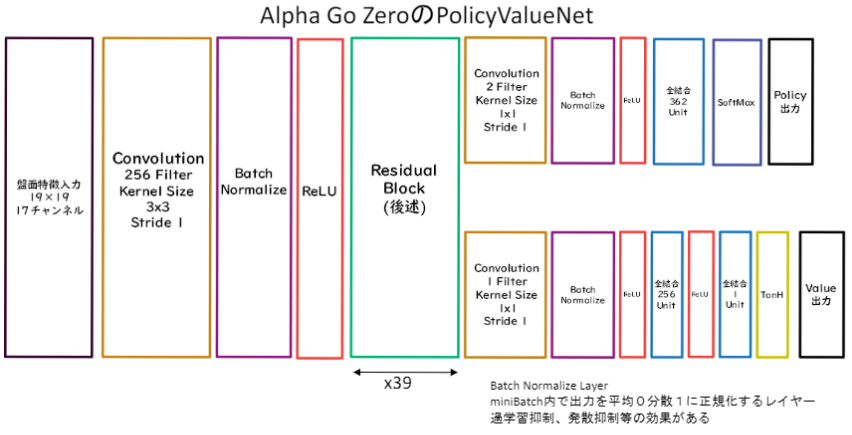
Residual Block
Residual Blockの中身についてみていきます。
Residual Blockは、ネットワークにショートカット構造を追加して、勾配の爆発、消失を抑える効果を狙ったものです。この構造を用いることで、100層を超えるネットワークでの安定した学習が可能になりました。
基本構造は次のようになっています。
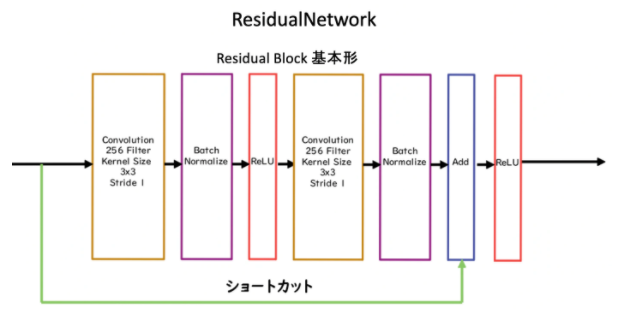
Convolution → BatchNorm → ReLU → Convolution → BatchNorm → Add → ReLU
のBlockを1単位にして積み重ねる形となっています。入力からAddにショートカットがありますね。
Residual Networkを使うことにより層数の違うNetworkのアンサンブル効果が期待されるとのことです。
AlphaGo Zeroでは、このResidual Blockが39個並んでいる構造になっています。
Alpha Go Zeroの学習法
Alpha Goの学習は、①自己対局による教師データの作成 ②学習 ③ネットワークの更新
の3ステップで構成されます。
① 自己対局による教師データの作成
現状のネットワークでモンテカルロ木探索を用いて自己対局を行う。まず30手までランダムで打ち、そこから探索を行い勝敗を決定する。自己対局中の各局面での着手選択確率分布と勝敗を記録する。教師データの形は(局面、着手選択確率分布、勝敗)が1セットとなる。
② 学習
自己対局で作成した教師データを使い学習を行う。NetworkのPolicy部分の教師として着手選択確率分布を用い、Value部分の教師に勝敗を用いる。
損失関数はPolicy部分はCrossEntropy、Value部分は平均二乗誤差。
③ ネットワークの更新
学習後、現状のネットワークと学習後のネットワークとで対局テストを行い、学習後のネットワークの勝率が高かった場合、学習後のネットワークを現状のネットワークとする。
参考
参考書籍
強化学習の勉強をするにあたり、以下の書籍がとても参考になりました。
[AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 ]
(https://www.amazon.co.jp/AlphaZero-%E6%B7%B1%E5%B1%A4%E5%AD%A6%E7%BF%92%E3%83%BB%E5%BC%B7%E5%8C%96%E5%AD%A6%E7%BF%92%E3%83%BB%E6%8E%A2%E7%B4%A2-%E4%BA%BA%E5%B7%A5%E7%9F%A5%E8%83%BD%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0%E5%AE%9F%E8%B7%B5%E5%85%A5%E9%96%80-%E5%B8%83%E7%95%99%E5%B7%9D-%E8%8B%B1%E4%B8%80/dp/4862464505)
AlphaZeroと機械学習の概要を解説後、深層学習、強化学習、探索について解説があり、最終的にAlphaZeroベースのゲームAIの作成をします。開発環境の準備やPythonの文法についても序盤で解説されています。
AlphaZeroはAlpha Go Zeroの進化版です。囲碁だけでなくチェスや将棋も学習できるようにしたバージョンで、当時の囲碁とチェスと将棋のゲームAI世界チャンピオンに勝利しています。
原著論文
今回ご紹介したAlphaGo Zeroの論文は以下です。
Mastering the game of Go without human knowledge
https://www.nature.com/nature/journal/v550/n7676/pdf/nature24270.pdf
最新の強化学習AI
AlphaZero以降にDeepmind社から発表されたAIとして「AlphaFold」と「AlphaStar」があります。
AlphaFoldは遺伝子配列情報からタンパク質の立体構造を予測する技術、
AlphaStarは「スタークラフト2」を攻略するAIです。囲碁は「完全情報ゲーム」で「ターン制」のため、行動数は$361$であるのに対して、スタークラフトは「不完全情報ゲーム」で「リアルタイム」のため、行動数は$10^{26}$と、はるかに複雑性の高いゲームらしいです。
以下、参考のURLです。
AlphaFold: Using AI for scientific discovery
https://deepmind.com/blog/article/AlphaFold-Using-AI-for-scientific-discovery
AlphaStar: Mastering the Real-Time Strategy Game StarCraft II
https://deepmind.com/blog/article/alphastar-mastering-real-time-strategy-game-starcraft-ii
他にも、DeepMind社の技術ブログには興味深い内容がたくさんありました。
強化学習すごいですね!
3. 軽量化・高速技術
分散深層学習
深層学習は多くのデータを使用したり、パラメータ調整のために多くの時間を使用したりするため、高速な計算が求められます。
複数の計算資源(ワーカー)を使用し、並列的にニューラルネットを構成することで、効率の良い学習を行いたい。そのために、データ並列化、モデル並列化、GPUによる高速技術は不可欠です。
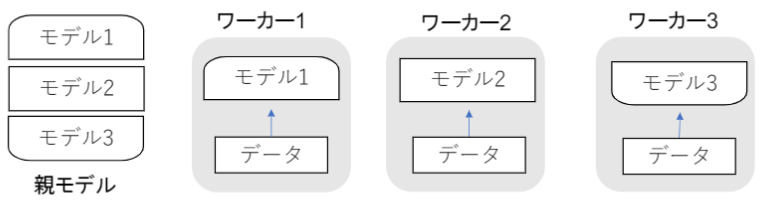
データ並列化
親モデルを各ワーカーに子モデルとしてコピーし、データを分割させ各ワーカーごとに計算させます。
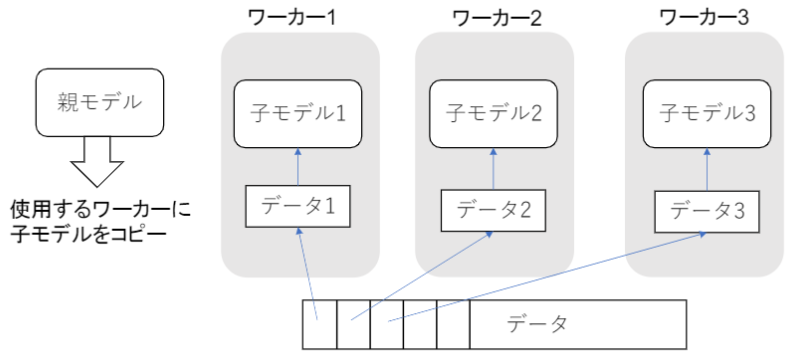
同期型
各ワーカーの計算が終わるのを待ち、全ワーカーの勾配が出たところで勾配の平均を計算し、親モデルのパラメータを更新する手法です。

非同期型
各ワーカーはお互いの計算を待たず、各子モデルごとに更新を行います。

同期型と非同期型の比較
同期型と非同期型には次のような特徴があります。
- 処理のスピードは、お互いのワーカーの計算を待たない非同期型の方が早い。
- 非同期型は最新のモデルのパラメータを利用できないので、学習が不安定になりやすい。
- 現在は同期型の方が精度が良いことが多いので、主流となっている。
モデル並列化
親モデルを各ワーカーに分割し、それぞれのモデルを学習させます。全てのデータで学習が終わった後で、一つのモデルに復元します。
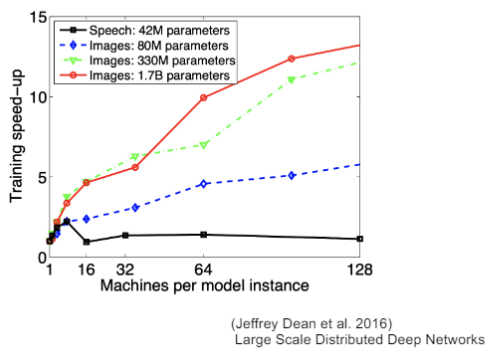
モデルが大きい時はモデル並列化を、データが大きい時はデータ並列化をすると良いとされています。
モデルのパラメータ数が多いほど、スピードアップの効率も向上します。
GPUによる高速化
- GPGPU (General-purpose on GPU)
元々の使用目的であるグラフィック以外の用途で使用されるGPUの総称 - CPU
高性能なコアが少数。複雑で連続的な処理が得意 - GPU
比較的低性能なコアが多数。簡単な並列処理が得意。
ニューラルネットの学習は単純な行列演算が多いので、高速化が可能になる。
軽量化の手法
代表的な手法として、量子化・蒸留・プルーニングの3つがあります。ひとつずつ見ていきましょう。
量子化(Quantization)
ネットワークが大きくなると大量のパラメータが必要となり、学習や推論に多くのメモリと演算処理が必要になります。そこで、通常のパラメータの64bit浮動小数点を、32bitなど下位の精度に落とすことでメモリと演算処理の削減を行います。
計算の高速化、省メモリ化の一方で、精度は低下します。
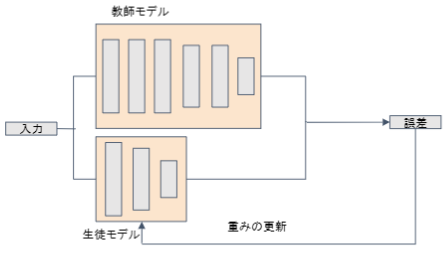
蒸留
規模の大きなモデルの知識を用いて、軽量なモデルの作成を行う手法です。
学習済みの精度の高いモデルの知識を軽量なモデルへ継承させます。知識の継承により、軽量でありながら複雑なモデルに匹敵する制度のモデルを得ることが期待できます。

蒸留は教師モデルと生徒モデルの2つで構成されます。
教師モデルは、予測精度の高い複雑なモデルやアンサンブルされたモデルです。
生徒モデルは、教師モデルを元に作られる軽量なモデルです。
プルーニング
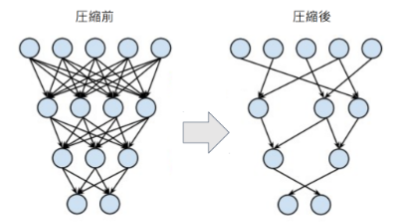
ネットワークが大きくなると大量のパラメータが生成されますが、すべてのニューロンの計算が精度に寄与しているわけではありません。プルーニングでは、モデルの精度に寄与が少ないニューロンを削減することでモデルの軽量化や高速化を見込みます。
ニューロンの削減手法は、重みが閾値以下の場合にニューロンを削減し再学習を行います。
4. 応用モデル
ここでは応用モデルとして、Wavenetの紹介をします。
概要
時系列データに対してDilated Convolution(畳み込み)を適用します。
Dilated Convolution は「層が深くなるにつれて畳み込むリンクを離す」「受容野を簡単に増やすことができる」という利点があります。
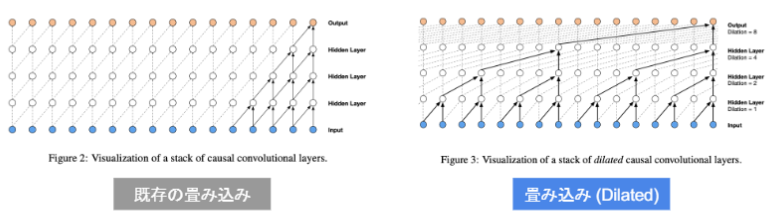
確認テスト
確認テスト1
深層学習を用いて結合確率を学習する際に、効率的に学習が行えるアーキテクチャを提案したことがWaveNetの大きな貢献の1つである。提案された新しいConvolution 型アーキテクチャは(あ)と呼ばれ、結合確率を効率的に学習できるようになっている。(あ)に入るものを選べ。
- Dilated causal convolution
- Depthwise separable convolution
- Pointwise convolution
- Deconvolution
解答: 1) Dilated causal convolution
確認テスト2
Dilated causal convolutionを用いた際の大きな利点は、単純なConvolution layer と比べて(い)ことである。
1) パラメータ数に対する受容野が広い
2) 受容野あたりのパラメータ数が多い
3) 学習時に並列計算が行える
4) 推論時に並列計算が行える
解答: 1) パラメータ数に対する受容野が広い
5. Transformer
ニューラル機械翻訳には、長文に対して精度が高くないことが課題として挙げられていました。
次の図のように、文章が長くなるにつれてBLEU score(翻訳に用いられる精度)が悪くなっていくことが分かります。

TransformaerはRNNを使用せずAttention機構のみで、この課題を解決した手法になります。
文章が長くなっても精度が落ちないことが確認できますね。

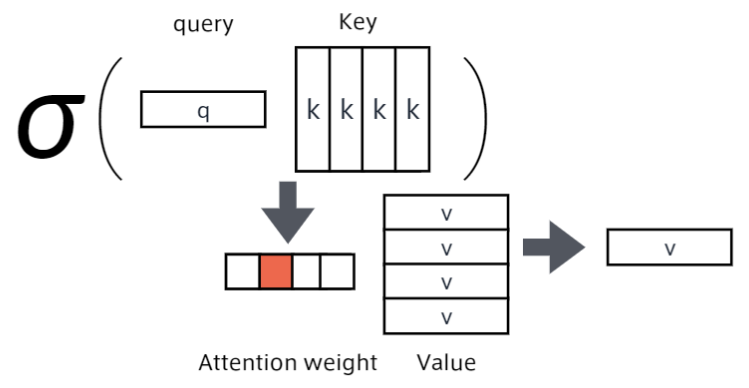
Attention
翻訳先の各単語を選択する際に、翻訳元の文中の各単語の隠れ状態を利用する手法のことです。
query(検索クエリ)に一致するkeyを索引し、対応するvalueを取り出す操作であると見做すことができるため、
辞書オブジェクトの機能と言えます。
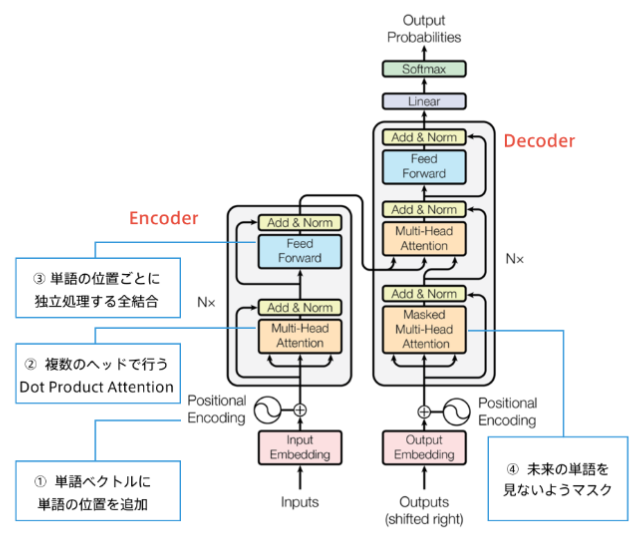
Transformerの主要モジュールは以下のようになります。
6. 物体検知・セグメンテーション
物体認識タスク
物体認識について説明をしていきます。
下図は広義の意味における物体認識タスクについてまとめたものです。一つずつ見ていきましょう。

-
分類(Classification)
入力画像が犬なのか、猫なのか、風船なのか?、どのラベルに属するものなのかを分類します。分類においては、画像のどの位置に物体があるのかについては興味がありません。ラベルに分類することがタスクになります。 -
物体検知(Object Detection)
物体検出では、画像分類と同じく画像内に写っている物体が属するラベルに加えて、その物体が写っている位置も明らかにする必要があります。この位置については、図に示すように物体を矩形で囲うことで表現します。物体を囲うこの矩形のことをバウンディングボックスと呼びます。 -
意味領域分割(Semantic Segmentation)
意味領域分割では、各ピクセルに対してラベルが割り当てられています。図の例でいうと、風船というクラスラベルが割り当てられたピクセルを青色として出力しています。バウンディングボックスに対象物が収まらなければならない物体検知とは対照的に、不規則な形状の対象物を明瞭に検出することができます。 -
個体領域分割(Instance Segmentation)
各ピクセルにラベルが与えられ、さらにインスタンス(風船ごと)の区別も付けられるようになります。意味領域分割では風船は全部同じ(青色)とみなしていました。一方で個体領域分割では、物体個々の区別に興味があり、風船はそれぞれに色がついています。
タスクの難易度は、個体領域分割が一番難しくなります。
代表的データセット
物体検出コンペティションで用いられたデータセットについて下図にまとめました。

物体検知においてはBox/画像、つまり一枚の画像にいくつ物体が写っているかの平均は重要な指標になります。
Box/画像 が少ないもの、例えば一枚の画像に人の顔だけが写っているものがあるとしましょう。このような画像ばかりを学習した自動運転サービスがあったとしたら、実際の道路で、信号機や人、自転車、建物など複数の物体検出を一度に行うようなタスクの精度は低いように思います。
一方でアイコン的な映りをするような何かサービスを作りたいときは、Box/画像 が小さいデータセットを使用した方が良いかもしれません。
このように、タスクの目的に応じたBox/画像 の選択が大切です。
クラス数についても同様にタスクの目的に応じた選択が必要です。
たとえばImageNetでは、画像に写っているパソコンが、あるものではLaptop、あるものではNotebooktとしてラベル付けされています。つまり、同じものなのに違う名づけがされている。そのせいでクラス数が増えているというものもあります。
評価指標
復習
物体検知の評価指標についてみていきます。
まずは復習として、分類問題についての評価指標を以下にまとめました。

適合率(Precision)はPositive と分類されたデータ(TP + FP)の中で実際にPositiveだったデータ(TP)数の割合でした。この値が高いほど性能が良く、間違った分類が少ないということを意味します。
再現率(Recall)は実際にPositiveであるデータ(TP + FN)の中で、正しくPositiveと予測された(TP)数の割合でした。この値が高いほど性能がよく、間違ったPositiveの判断が少ないという事を意味します。
PR曲線(Precison Recall curve)はPrecisonを縦軸、Recallを横軸に取ります。
Positiveに予測されるかNegativeに予測されるかは、予測値と閾値の値によって決まります。たとえば、予測値0.7という値が得られたとき、閾値が0.5だとしたら予測結果はPositiveになります。一方で閾値が0.8だった場合、予測結果はNegativeとなります。このように、閾値が変わればPositive、Negativeの予測結果が変わり混同行列の結果も変わってきます。そうすると、PrecisonやRecallの値も変わりますよね。閾値を0~1と変化させたときのPrecisonとRecallの関係がPR曲線です。
PrecisionとRecallの両方が高い状態が望ましいです。
IoU(Intersection over Union)
物体検出においてはクラスラベルだけでなく、物体位置の予測精度も評価を行いたいです。
IoUとは予測領域がどれだけ正解領域と重なっているのかを示す指標になり、IoUの値が大きい(Max:1)と良い位置予測であるといえます。
Ground-Truth BBは真のバウンディングボックス、Predicted BBは予測したバウンディングボックスのことです。

Precision/Recall
物体検知において、入力画像1枚を見たときのPrecision/Recall指標について説明します。
以下に指標の見方、計算をまとめました。

物体検出ではconfidenceの他にIoUについても閾値を用意する必要があります。
今回はconfidenceの閾値を0.5としているので、まず「conf.> 0.5」となるクラスラベルの予測が表にピックアップされています。
そしてIoUの閾値0.5より大きいものについては、物体位置の予測精度も良いとしてTPとなります。注意としては、既に検出済みの対象については「IoU > 0.5」であってもFPとなることです。同じ物体に対して複数のPredicted BBが出てきてしまったときは、最もconfidenceが高く、かつIoUの閾値を超えているものだけをTPとします。
TPとFPの数が分かるので、PrecisionとRecallの計算ができますね。
続いて、クラス単位でかつ、画像が複数ある場合のPrecision/Recall指標についてみていきます。
ここでは、まず「人」のクラスラベルだけに着目していきます。
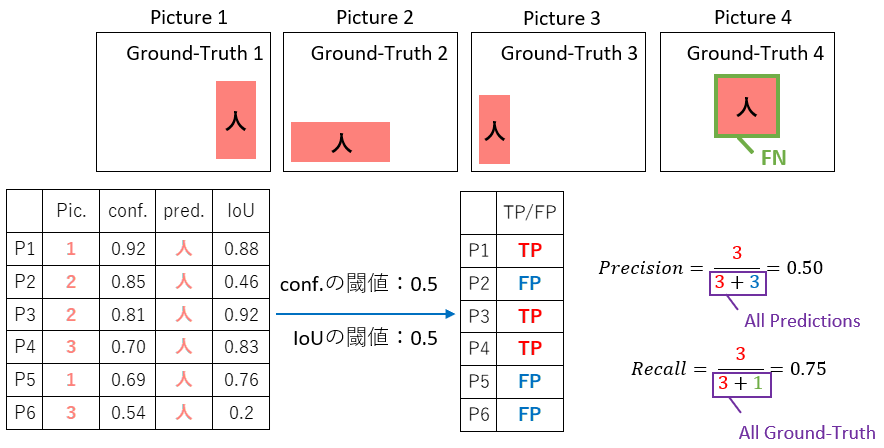
confidenceの閾値を0.5、IoUの閾値を0.5としています。
表のP1は、picture1について「confidence 0.92」で人を検出していて「IoU 0.88」の精度で位置を検出していることを表します。
同じく、表のP4はpicture3について「confidence 0.70」で人を検出していて「IoU 0.83」の精度で位置を検出していることを表しています。
それぞれについて、入力画像1枚の時と同じくTPであるかFPであるかの判断をしていき、PrecisionとRecallを求めます。
Recallの計算では分母に+1がありますね。Recallの分母は、すべてのGround-Truth数を表します。
今回、P1~P6までpicture4の「人」は一度も検出されませんでした。すなわち、本来は検出すべき対象であるにもかかわらず検出できなかったもの(FN)が1つ存在するという事です。これが+1に該当します。
ここでは、人のクラスラベルを用いて説明しましたが、同様に車と犬についても算出する必要があります。
Average Precision (AP)
画像が複数ある場合のPrecision/Recallの算出では、confidenceの閾値は0.5で計算をしていました。
confidenceの閾値を変えれば、Precision/Recallの値も変わるはずですよね。confidenceの閾値ごとにPrecision/Recallを算出しPR曲線を作成。PR曲線の下側面積が、物体検知で用いられる指標Average Precisionになります。
ここでもクラスラベルは一度「人」に固定して説明をします。

IoUの閾値は0.5に固定して、confidenceの閾値を0.05~0.95まで0.05ずつ変化させていきながらPrecision/Recallを算出していきます。そうすると、求められたPrecision/RecallのペアからPR曲線を描くことができます。(この考え方は一般的なクラス分類でPR曲線を描くときと一緒ですね。)
confidenceの閾値をβとすると、βの関数としてprecisionとRecallが記述できます。
Recall=R(\beta)
Precision=P(\beta)
これらを一つにまとめ、Recallの関数としてprecisionを記述することができます。
これがPR曲線の式になります。
P=f(R)
APはPR曲線の下側面積となるので、次の式で表すことができます。
AP=\int_0^1 P(R) dR
以上、物体検知における評価指標であるAPの導出になります。
今回は「人」のクラスラベルに着目してAPを求めましたが、車や犬についても同様にAPを求めます。
mean Average Precision (mAP)
各クラスごとにAPを求め、算術平均したものがmAPです。
今回の例では、人・車・犬のAPをそれぞれ算出し、それらの平均を求めたものになりますね。
mAP=\frac{1}{C}\sum_{i=1}^{C}AP_{i}
mAP COCO
mAP COCOはMS COCOで導入された物体検知の評価指標です。
これまで、mAPの導出はIoUの閾値を0.5に固定していました。
mAP COCOはIoUの閾値を0.5~0.95まで0.05刻みで変化させたときの各AP、mAPを計算します。
IoUの閾値毎のmAPを算術平均したものがmAP COCOです。
mAP_{COCO}=\frac{mAP_{0.5}+mAP_{0.55}+...+mAP_{0.95}}{10}
この指標はIoUの閾値を0.5より大きいものにしてmAPを求めていきます。つまり、しっかりとGround-Truth BBに被ったようなPredicted BBを評価したい。位置について厳しく見ていくという指標になります。
Flames per Second (FPS)
物体検知では、検出精度に加えて検出速度も重要である。
横軸はFrame Pre Secondであり、1秒あたりに何フレーム処理できるかという処理速度を測る指標です。大きいほど処理速度が速いという事になります。

下図のように、inference timeが用いられることもあります。これは、1フレームあたり何秒処理に時間が掛かったかという推論の時間を表します。小さいほど処理速度が速いという事になります。
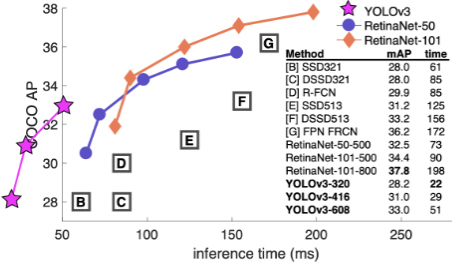
物体検知のフレームワーク
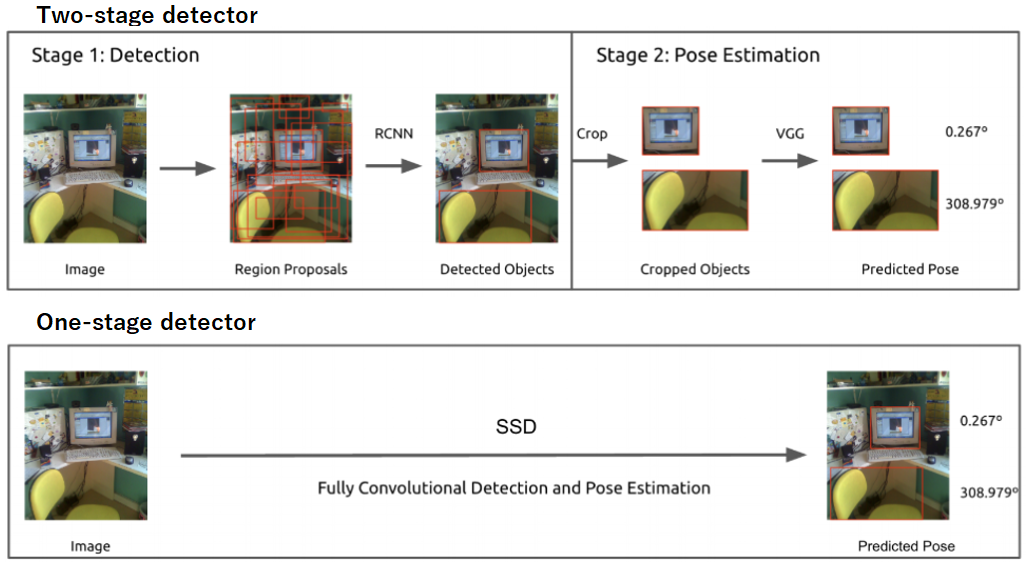
物体検知のフレームワークは大きく分けて2種類あります。
- 2段階検出器(Two-stage detector)
- 候補領域の検出とクラス推定を別々に行う。
- 相対的に精度が高い傾向。
- 相対的に計算量が大きく推論も遅い傾向
- 例)RCNN、SPPNet、Fast RCNN、Faster RCNN、RFCN、FPN、Mask RCNN
- 1段検出器(One-stage detector)。
- 候補領域の検出とクラス推定を同時に行う。
- 相対的に精度が低い傾向。
- 相対的に計算量が小さく推論も早い傾向。
- 例)DetectorNet、YOLO、SSD、YOLO9000、RetinaNet、CornerNet