AI(人工知能)の進化と予想

つまり、こういうこと

フェーズ1:認識AI
画像、音声、テキストなどの感覚入力を理解し、解釈することに焦点を当てたAI
分析を行うための認識
オブジェクト、顔、声などを識別し理解するAIシステム
顔認識、音声認識、画像分類などのアプリケーションで使用されます。
フェーズ2:生成AI
テキスト、画像、音楽、コードなどの新しいコンテンツを作成するAI
壁打ち相手としての創作
テキスト、画像、音楽などのコンテンツを入力に基づいて生成するAI。GPT-4のようなモデルがエッセイを書いたり、アートを作成したり、音楽を作曲したりします。
フェーズ3:エージェントAI
自律的にタスクを実行し、目標を達成するために意思決定を行えるAIシステム。
多くの場合、計画と問題解決能力を含みます。
アシスタント的な役割の提供
コードの作成やデバッグを支援するAIツールで、プログラミングをより効率的かつアクセスしやすくします。
フェーズ4:物理AI
現実世界と相互作用できる物理的なシステムに組み込まれたAI
ソリューションの提供
センサーやカメラ、アルゴリズムを使って環境を理解し、反応することで人間の介入なしに運転するAI。
様々なタスクを実行できるロボットで、AIを使って異なる状況に適応し、経験から学ぶ。
LLMからWORLDモデルへの移行
LLM(大規模言語モデル)からWORLDモデルへの移行
LLM(Large Language Model、大規模言語モデル)は、自然言語処理(NLP)タスクにおいて非常に強力なツールです。しかし、特定のタスクやドメインにおいては、LLMの限界が存在することもあります。ここでは、LLMからWORLDモデルへの移行について考察します。
LLMの限界
LLMは、膨大な量のテキストデータを学習し、自然言語生成や理解において高い性能を発揮しますが、限界があります
ドメイン特化の知識不足
LLMは一般的な知識を持っていますが、特定のドメインに特化した知識が不足していることがあります。
文脈の理解
長い文脈や複雑な文脈を理解するのが難しい場合があります。
計算リソースの消費
LLMは大規模なモデルであるため、計算リソースを大量に消費します。
解釈性の欠如
LLMの予測結果を解釈するのが難しい場合があります。
LLMからWORLDモデルへの移行について
LLM(大規模言語モデル)からWORLDモデルへの移行は、AI分野における重要な転換点
LLMとWORLDモデルの違い
LLM(大規模言語モデル)
特定のタスク(テキスト生成、翻訳、要約など)に特化した大規模なニューラルネットワークです。大量のテキストデータを学習することで、人間が書くような自然な文章を生成できますが、現実世界との相互作用や複雑な推論能力には限界があります。
WORLDモデル
現実世界をシミュレーションする能力を持つ、より高度なAIモデルです。物理法則や物体の性質、人間行動のパターンなどを学習し、仮想空間内で様々な事象を予測・再現できます。
LLMからWORLDモデルへの移行のメリット
より高度な推論・予測能力
WORLDモデルは現実世界の複雑な状況を理解し、より高度な推論や予測を行えます。例えば、自動運転車の開発や災害シミュレーションなどに活用できます。
現実世界との相互作用
WORLDモデルは仮想空間内で現実世界を再現できるため、AIが現実世界と相互作用する能力を高められます。例えば、ロボットの制御やバーチャルリアリティ体験の向上に役立ちます。
新たな応用分野の開拓
WORLDモデルは、ゲーム、教育、医療など、様々な分野に革新的な変化をもたらす可能性があります。例えば、教育分野では、WORLDモデルを用いた没入型学習環境を構築できます。
はじめに
「時間場所を問わず意思を発信共有できる」といった点は、現代のテクノロジーが可能にした情報の拡散能力に関係しています。特にインターネットやSNSの力が強く、情報が瞬時に世界中に伝わり、それが時に誤った方向に進んでしまうこともあります。
集団心理が働き、個人の意識や意思が徐々に薄れていく様子は、ある意味で社会が直面している現代的な問題を反映していると思います。
共有化された自意識は、自由の名の下に怠惰と悪意にまみれ、道徳的に低い方向へ流れていく可能性があります。
人々が時間や場所に関わらず意思を発信・共有できるようになったことで、情報拡散の速度と伝達能力が飛躍的に向上しています。
一方で、
情報量が膨大になり、個人がその全てを精査することは不可能に近い状況となっています。
個人の自由と集団の価値観が交錯し、時としてその自由が無責任な行動や、社会的に有害な意識に変わることがあります。
煽られて、発言していないか?
芸能人の不祥事などの疑惑をネタに、過激な動画をアップして炎上系youtuberとかって、存在しますよね。
SNSなどで情報が広まるとき、特定の思想や感情が集団的に強化されていくことがしばしばあります。それが時に、感情的で偏った意見の拡散を生む原因となり、個人がその流れに乗ってしまうことがあるわけです。例えば、便利さや瞬間的な快感を追い求めるあまり、道徳的に問題のある行動が正当化されるような場面も見受けられます。
この「自由」の名の下で、道徳的に低い方向へ流れていくという現象は、社会全体に影響を及ぼす恐れがあり、個人の判断力が薄れてしまうという点でも危険を伴います。集団心理の中で、反省や自制が欠如し、単に「多数派」や「便利さ」を重視する傾向が強くなることがあるからです。
みんなが、会話しているネタだから、知っている必要があるか? というと、そんなことはないことが多い。というか、芸能人の不祥事とか、聞いてしまい、楽しかった気分が持っていかれることがある。集団の感情に飲み込まれる感じですね。つまらない情報に心を持っていかれるくらいなら、むしろ、そんな情報は、そもそも、入ってこないようにしたい。
このような問題に対して、どういったアプローチが有効だと考えますか?
情報社会における「自由」と「責任」のバランスが崩れることで、道徳的に低い方向に流れやすくなるという点は、現代社会における大きな課題ですね。
私たち一人ひとりが受け取る情報量が膨大すぎて、それを正確に精査するのは困難です。特にSNSやインターネット上では、感情的な反応や誤情報が瞬時に広がり、それが時に「多数派の意見」として強化されることがあります。これが集団心理に影響を与え、個人の意識を曖昧にさせ、無責任な行動や社会的に有害な行動が助長されることに繋がるのです。
いくつかのアプローチ
-
情報の出どころを確認する。
-
誤った情報を広めないよう対応策を講じる。
-
集団心理に流されがちな状況を避けるために、個人が自分の思考を意識的に持つ。
-
過激な意見や誤情報を助長しないよう、アルゴリズムの設計やコンテンツの管理を慎重に行う。
これは、AIを扱う時でも同じ
-
情報の出どころを確認する。
☝️正確なデータを前もって用意する。 -
誤った情報を広めないよう対応策を講じる。
☝️用意したデータの中に間違った情報が含まれているならば、前処理で加工する。 -
集団心理に流されがちな状況を避けるために、個人が自分の思考を意識的に持つ。
☝️一度作成したモデルでも、随時、精度を確認し、推論がより適切に行えるものを使うようにする。 -
過激な意見や誤情報を助長しないよう、アルゴリズムの設計やコンテンツの管理を慎重に行う。
☝️推論した結果が、もともと利用していたデータと同じようなものでしか当てはまらないような過学習になってしまったら、改めて、追加のデータを投入することで、新しい情報への推論ができるように調整する。
せっかくなので
案件に入る時に、機械学習を体系的に学べるものを探しました。その際に、最も役に立った内容を整理しました。AWSのパートナー向け研修のようなものをいくつか受講したことがあるのですが、今回、ご紹介する内容は、一日かかる研修と同等のものが得られる内容だと考えています。そのため、一回のブログ記事としては、かなり、ボリュームがあります。一回見ただけで、分からなかったとしても、自信を失わずに、良かったら、記事をストックして、継続して見直してみてください。お得な事に、Pythonも学べると思います。このチュートリアルで機械学習の基礎を固める事が出来たので、AWS Certified AI Practitioner (AIF-C01)で、スコア(1000/1000)を取得し、後輩も合格に導くことが出来ました。(社内で毎月、ご飯代を会社から支給して頂き、勉強会をしています。)
2/6 (木)に社外向け勉強会を開催するので、良かったら、来てください。(お飲み物もご用意しております。無料)
AI予備知識の確認(穴埋め問題)
AI(人工知能)とは、〇〇を模倣し、〇〇を実行するシステムや技術の総称です。
ML(機械学習)とは、〇〇から学習し、〇〇や〇〇を行うアルゴリズムやモデルの一部です。機械学習は、〇〇の一部であり、特に〇〇から学習する技術に焦点を当てています。
AI予備知識の確認(回答)
AI(人工知能)とは、人間の知能を模倣し、タスクを実行するシステムや技術の総称です。
ML(機械学習)とは、データから学習し、予測や意思決定を行うアルゴリズムやモデルの一部です。機械学習は、AI(人工知能) の一部であり、特にデータから学習する技術に焦点を当てています。
AWSの代表的なサービスについて
SageMaker Pipelines は、機械学習のために初めて作られた継続的インテグレーションおよび継続的デリバリー (CI/CD) サービスです。今回は、このパイプラインの使い方を説明します。
SageMaker Pipelines を使用すると、
データロード、データ変換、トレーニング、チューニング、評価、デプロイなど、機械学習ワークフローのさまざまなステップを自動化することができます。


SageMaker Model Registry を使用すると、
モデルのバージョン、ユースケースのグループ化などのメタデータ、モデルのパフォーマンスメトリクスベースラインを中央リポジトリで追跡でき、ビジネス要件に基づいてデプロイに適したモデルを容易に選択することができます。

SageMaker Clarify は、
トレーニングデータとモデルの可視性を高めることで、バイアスの特定と制限、予測の説明を可能にします。

機械学習パイプラインの主要なステップ
1.データ収集と前処理適切なデータセットを収集し、欠損値や異常値の処理、特徴量エンジニアリングなどの前処理を行います。
2.データ分割データセットをトレーニングデータとテストデータに分割します。これにより、モデルのトレーニングと評価を独立して行うことができます。
3.特徴量エンジニアリングデータセットから適切な特徴を選択し、変換することでモデルの性能を向上させます。
4.モデルの選択解決すべき課題に応じて、適切な機械学習アルゴリズムやモデルを選択します。
5.モデルのトレーニングトレーニングデータを使用してモデルをトレーニングします。ハイパーパラメータの調整もこの段階で行います。
6.モデルの評価テストデータを使用してモデルの性能を評価します。精度、再現率、適合率などの評価指標を考慮します。
7.モデルのデプロイメントトレーニングされたモデルを本番環境にデプロイし、実際のデータに対する予測を行えるようにします。
8.モデルのモニタリングとメンテナンスデプロイ後もモデルの性能をモニタリングし、必要に応じて再トレーニングや更新を行います。
機械学習のモデル
機械学習のモデルとは、データからパターンを学び、そのパターンを使って予測や分類などのタスクを実行できるアルゴリズムや数学的な構造のことです。具体的には、モデルは入力データを受け取り、適切な出力を生成するように「学習」します。
たとえば、あるモデルにたくさんの「犬」と「猫」の画像を与え、その特徴を学習させると、モデルは新たな画像に対して、それが犬か猫かを予測することができるようになります。
これを行う事で、獲得したい考察
モデル説明可能性レポートの確認し、次のような考察を得る事
どんな特徴があり、その特徴が予測にどのように寄与しているかを理解することができます。
予測結果を解釈し、ビジネス上の意思決定に役立てることができます。
このチュートリアルでは、リスクの高い顧客に対する対策を講じることで、保険会社のリスク管理を強化することができることを説明しています。
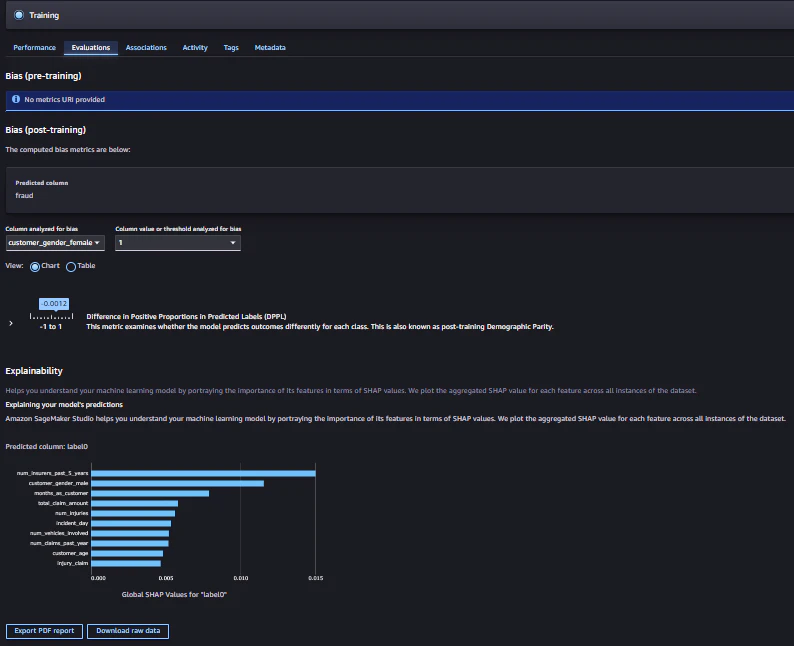
考察
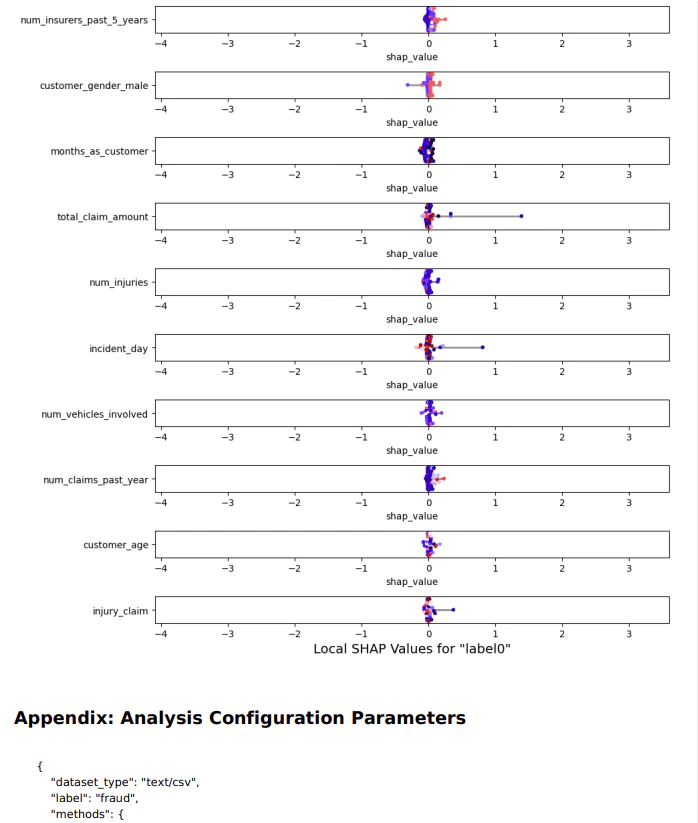
SHAP(SHapley Additive exPlanations)を用いたモデルの説明と考察
SHAP値を用いたモデルの説明により、各特徴量が予測にどのように寄与しているかを理解することができます。これにより、モデルの予測結果を解釈し、ビジネス上の意思決定に役立てることができます。上記の考察を基に、リスクの高い顧客に対する対策を講じることで、保険会社のリスク管理を強化することができます。
特徴量のリスト
-
num_insurers_past_5_years(過去5年間の保険会社数) -
customer_gender_male(顧客の性別:男性) -
months_as_customer(顧客としての月数) -
total_claim_amount(総請求額) -
num_injuries(怪我の数) -
incident_day(事故の日) -
num_vehicles_involved(関与した車両の数) -
num_claims_past_year(過去1年間の請求数) -
customer_age(顧客の年齢) -
injury_claim(怪我の請求)
考察例
1. num_insurers_past_5_years(過去5年間の保険会社数)
確認:
- 過去5年間に複数の保険会社を利用している顧客は、リスクが高いと判断される可能性があります。
考察:
- 保険会社を頻繁に変更する顧客は、保険金請求のリスクが高いと見なされることが多いです。これは、保険会社を変更する理由が、過去の請求履歴や保険料の増加に関連している可能性があるためです。
2. customer_gender_male(顧客の性別:男性)
確認:
- 性別が男性であることが、予測に影響を与えていることが確認されました。
考察:
- 一部の研究では、男性は女性よりも事故を起こすリスクが高いとされています。したがって、性別が男性であることは、保険金請求のリスクを高める要因として考慮されることがあります。
3. months_as_customer(顧客としての月数)
確認:
- 顧客としての月数が長いほど、リスクが低いと判断される可能性があります。
考察:
- 長期間にわたって同じ保険会社を利用している顧客は、信頼性が高いと見なされることが多いです。これは、保険会社との関係が長い顧客は、保険金請求のリスクが低いとされるためです。
4. total_claim_amount(総請求額)
確認:
- 総請求額が高いことが、予測に影響を与えていることが確認されました。
考察:
- 過去の総請求額が高い顧客は、将来的にも高額な請求を行うリスクが高いと見なされることがあります。これは、過去の請求履歴が将来のリスクを予測するための重要な指標となるためです。
5. num_injuries(怪我の数)
確認:
- 怪我の数が多いことが、予測に影響を与えていることが確認されました。
考察:
- 過去に怪我を伴う事故を多く経験している顧客は、リスクが高いと見なされることがあります。これは、怪我の数が多いことが、事故の頻度や重大さを示す指標となるためです。
6. incident_day(事故の日)
確認:
- 事故の日が予測に影響を与えていることが確認されました。
考察:
- 事故が発生した曜日や日付は、事故のリスクを評価するための重要な要因となることがあります。例えば、週末や特定の祝日に事故が多発する傾向がある場合、その情報はリスク評価に役立ちます。
7. num_vehicles_involved(関与した車両の数)
確認:
- 関与した車両の数が多いことが、予測に影響を与えていることが確認されました。
考察:
- 事故に関与する車両の数が多いほど、事故の重大さや複雑さが増すため、リスクが高いと見なされることがあります。これは、複数の車両が関与する事故は、単独事故よりも保険金請求の額が高くなる傾向があるためです。
8. num_claims_past_year(過去1年間の請求数)
確認:
- 過去1年間の請求数が多いことが、予測に影響を与えていることが確認されました。
考察:
- 過去1年間に多くの請求を行っている顧客は、リスクが高いと見なされることがあります。これは、頻繁に請求を行う顧客は、将来的にも請求を行う可能性が高いためです。
9. customer_age(顧客の年齢)
確認:
- 顧客の年齢が予測に影響を与えていることが確認されました。
考察:
- 年齢は、事故のリスクを評価するための重要な要因です。若年層や高齢者は、事故を起こすリスクが高いとされることが多いため、年齢が予測に影響を与えることは理にかなっています。
10. injury_claim(怪我の請求)
確認:
- 怪我の請求が予測に影響を与えていることが確認されました。
考察:
- 怪我の請求を行った顧客は、リスクが高いと見なされることがあります。これは、怪我の請求が事故の重大さを示す指標となるためです。
誰でも出来る「機械学習ワークフローを自動化する」 チュートリアルをもとに機械学習 (CI/CD)を理解する
チュートリアルのソースコードをそのまま使います。細かい、ソースコードの内容は、こちらをご確認下さい。
※現在、こちらは、lambda関数で使用するRun Timeが現在は利用できないバージョンになっています。
Cloudformationのリソースの作成に失敗します。
ステップ1のドメインなどの作成方法は、下記を参考にしてみて下さい。
SageMaker Studio ノートブックを設定し、パイプラインをパラメータ化する
必要なライブラリをインポート
Amazon SageMakerを使用して機械学習パイプラインを構築するために必要なライブラリをインポートしています。これらのライブラリを使用することで、データの前処理、モデルのトレーニング、評価、条件付きステップ、モデルの登録、デプロイメントなど、機械学習パイプラインの各ステップを定義し、実行することができます。

ライブラリ
import pandas as pd
import json
import boto3
import pathlib
import io
import sagemaker
-
pandas (
pd): データ操作と分析のためのライブラリ。データフレームを使用してデータを操作します。 - json: JSONデータのエンコードとデコードを行うためのライブラリ。
- boto3: AWS SDK for Python。AWSサービスと対話するために使用されます。
- pathlib: ファイルシステムパス操作のためのライブラリ。
- io: 入出力操作のためのライブラリ。
- sagemaker: Amazon SageMakerのPython SDK。
SageMakerのシリアライザとデシリアライザ
from sagemaker.deserializers import CSVDeserializer
from sagemaker.serializers import CSVSerializer
- CSVDeserializer: CSV形式のレスポンスをデシリアライズするためのクラス。
- CSVSerializer: データをCSV形式にシリアライズするためのクラス。
SageMakerのXGBoost推定器とSKLearnプロセッサ
from sagemaker.xgboost.estimator import XGBoost
from sagemaker.sklearn.processing import SKLearnProcessor
- XGBoost: XGBoostモデルをトレーニングするための推定器クラス。
- SKLearnProcessor: Scikit-learnを使用してデータ前処理を行うためのプロセッサクラス。
SageMakerの処理関連クラス
from sagemaker.processing import (
ProcessingInput,
ProcessingOutput,
ScriptProcessor
)
- ProcessingInput: 処理ジョブの入力データを指定するためのクラス。
- ProcessingOutput: 処理ジョブの出力データを指定するためのクラス。
- ScriptProcessor: スクリプトを実行するためのプロセッサクラス。
SageMakerのトレーニング入力
from sagemaker.inputs import TrainingInput
- TrainingInput: トレーニングジョブの入力データを指定するためのクラス。
SageMakerのパイプライン関連クラス
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.steps import (
ProcessingStep,
TrainingStep,
CreateModelStep
)
from sagemaker.workflow.check_job_config import CheckJobConfig
from sagemaker.workflow.parameters import (
ParameterInteger,
ParameterFloat,
ParameterString,
ParameterBoolean
)
from sagemaker.workflow.clarify_check_step import (
ModelBiasCheckConfig,
ClarifyCheckStep,
ModelExplainabilityCheckConfig
)
from sagemaker.workflow.step_collections import RegisterModel
from sagemaker.workflow.conditions import ConditionGreaterThanOrEqualTo
from sagemaker.workflow.properties import PropertyFile
from sagemaker.workflow.condition_step import ConditionStep
from sagemaker.workflow.functions import JsonGet
- Pipeline: パイプラインを定義するためのクラス。
- ProcessingStep: データ前処理ステップを定義するためのクラス。
- TrainingStep: モデルトレーニングステップを定義するためのクラス。
- CreateModelStep: モデル作成ステップを定義するためのクラス。
- CheckJobConfig: チェックジョブの設定を行うためのクラス。
- ParameterInteger, ParameterFloat, ParameterString, ParameterBoolean: パイプラインパラメータを定義するためのクラス。
- ModelBiasCheckConfig, ClarifyCheckStep, ModelExplainabilityCheckConfig: モデルバイアスチェックと説明可能性チェックの設定を行うためのクラス。
- RegisterModel: モデル登録ステップを定義するためのクラス。
- ConditionGreaterThanOrEqualTo: 条件付きステップの条件を定義するためのクラス。
- PropertyFile: プロパティファイルを定義するためのクラス。
- ConditionStep: 条件付きステップを定義するためのクラス。
- JsonGet: JSONデータから値を取得するための関数。
SageMakerのLambdaステップ関連クラス
from sagemaker.workflow.lambda_step import (
LambdaStep,
LambdaOutput,
LambdaOutputTypeEnum,
)
from sagemaker.lambda_helper import Lambda
- LambdaStep: Lambdaステップを定義するためのクラス。
- LambdaOutput, LambdaOutputTypeEnum: Lambdaステップの出力を定義するためのクラス。
- Lambda: Lambda関数を定義するためのヘルパークラス。
SageMakerのモデルメトリクスとドリフトチェック
from sagemaker.model_metrics import (
MetricsSource,
ModelMetrics,
FileSource
)
from sagemaker.drift_check_baselines import DriftCheckBaselines
- MetricsSource: メトリクスのソースを定義するためのクラス。
- ModelMetrics: モデルメトリクスを定義するためのクラス。
- FileSource: ファイルソースを定義するためのクラス。
- DriftCheckBaselines: ドリフトチェックのベースラインを定義するためのクラス。
SageMakerのイメージURIの取得
from sagemaker.image_uris import retrieve
- retrieve: 特定のフレームワークのイメージURIを取得するための関数。
生データセットと処理済みデータセットおよびモデルアーティファクトが保存される S3 バケットロケーションを設定
Amazon SageMakerを使用して機械学習パイプラインを構築するための準備を行います。
- AWSサービスのセッションとクライアントオブジェクトのインスタンス化
- SageMaker実行ロールの取得
- S3のパス設定
- フルS3パスの設定
- トレーニングイメージの取得

Amazon SageMakerを使用して機械学習パイプラインを構築するための準備を行います。具体的には、AWSサービスのセッションとクライアントオブジェクトをインスタンス化し、必要なS3バケットとパスを設定します。
1. AWSサービスのセッションとクライアントオブジェクトのインスタンス化
# SageMakerセッションのインスタンス化
sess = sagemaker.Session()
# デフォルトのS3バケットを取得
write_bucket = sess.default_bucket()
write_prefix = "fraud-detect-demo"
# リージョンの取得
region = sess.boto_region_name
# S3クライアントのインスタンス化
s3_client = boto3.client("s3", region_name=region)
# SageMakerクライアントのインスタンス化
sm_client = boto3.client("sagemaker", region_name=region)
# SageMaker Runtimeクライアントのインスタンス化
sm_runtime_client = boto3.client("sagemaker-runtime")
- sess: SageMakerセッションをインスタンス化します。これにより、SageMakerの操作を行うためのセッションが作成されます。
- write_bucket: デフォルトのS3バケットを取得します。これは、SageMakerがデフォルトで使用するバケットです。
- write_prefix: S3バケット内のプレフィックスを設定します。これは、データやスクリプトを保存するためのディレクトリのようなものです。
- region: 現在のAWSリージョンを取得します。
- s3_client: S3クライアントをインスタンス化します。これにより、S3バケットやオブジェクトの操作が可能になります。
- sm_client: SageMakerクライアントをインスタンス化します。これにより、SageMakerの操作が可能になります。
- sm_runtime_client: SageMaker Runtimeクライアントをインスタンス化します。これにより、デプロイされたモデルのエンドポイントに対して予測リクエストを送信することができます。
2. SageMaker実行ロールの取得
# SageMaker実行ロールの取得
sagemaker_role = sagemaker.get_execution_role()
- sagemaker_role: SageMakerの実行ロールを取得します。このロールは、SageMakerがAWSリソースにアクセスするために使用されます。
3. S3のパス設定
# S3のパス設定
read_bucket = "sagemaker-sample-files"
read_prefix = "datasets/tabular/synthetic_automobile_claims"
# 生データのS3パス
raw_data_key = f"s3://{read_bucket}/{read_prefix}"
# 処理済みデータのS3パス
processed_data_key = f"{write_prefix}/processed"
# トレーニングデータのS3パス
train_data_key = f"{write_prefix}/train"
# 検証データのS3パス
validation_data_key = f"{write_prefix}/validation"
# テストデータのS3パス
test_data_key = f"{write_prefix}/test"
- read_bucket: 生データが保存されているS3バケットの名前を設定します。
- read_prefix: 生データが保存されているS3バケット内のプレフィックスを設定します。
- raw_data_key: 生データの完全なS3パスを設定します。
- processed_data_key: 処理済みデータのS3パスを設定します。
- train_data_key: トレーニングデータのS3パスを設定します。
- validation_data_key: 検証データのS3パスを設定します。
- test_data_key: テストデータのS3パスを設定します。
4. フルS3パスの設定
# フルS3パスの設定
claims_data_uri = f"{raw_data_key}/claims.csv"
customers_data_uri = f"{raw_data_key}/customers.csv"
output_data_uri = f"s3://{write_bucket}/{write_prefix}/"
scripts_uri = f"s3://{write_bucket}/{write_prefix}/scripts"
estimator_output_uri = f"s3://{write_bucket}/{write_prefix}/training_jobs"
processing_output_uri = f"s3://{write_bucket}/{write_prefix}/processing_jobs"
model_eval_output_uri = f"s3://{write_bucket}/{write_prefix}/model_eval"
clarify_bias_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/bias_config"
clarify_explainability_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/explainability_config"
bias_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/bias"
explainability_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/explainability"
- claims_data_uri: クレームデータのS3パスを設定します。
- customers_data_uri: 顧客データのS3パスを設定します。
- output_data_uri: 出力データのS3パスを設定します。
- scripts_uri: スクリプトのS3パスを設定します。
- estimator_output_uri: トレーニングジョブの出力データのS3パスを設定します。
- processing_output_uri: 処理ジョブの出力データのS3パスを設定します。
- model_eval_output_uri: モデル評価の出力データのS3パスを設定します。
- clarify_bias_config_output_uri: Clarifyバイアス設定のS3パスを設定します。
- clarify_explainability_config_output_uri: Clarify説明可能性設定のS3パスを設定します。
- bias_report_output_uri: バイアスレポートのS3パスを設定します。
- explainability_report_output_uri: 説明可能性レポートのS3パスを設定します。
5. トレーニングイメージの取得
# トレーニングイメージの取得
training_image = retrieve(framework="xgboost", region=region, version="1.3-1")
- training_image: XGBoostのトレーニングイメージURIを取得します。これにより、指定されたフレームワークとバージョンのトレーニングイメージが取得されます。
パイプラインコンポーネントの名前を設定し、トレーニングと推論のインスタンスタイプと数を指定
Amazon SageMakerを使用して機械学習パイプラインを構築するためのオブジェクト名やインスタンスタイプ、データパラメータなどを設定しています。
- パイプラインオブジェクトの名前設定
- データパラメータの設定
- インスタンスタイプとカウントの設定

1. パイプラインオブジェクトの名前設定
# パイプラインオブジェクトの名前設定
pipeline_name = "FraudDetectXGBPipeline"
pipeline_model_name = "fraud-detect-xgb-pipeline"
model_package_group_name = "fraud-detect-xgb-model-group"
base_job_name_prefix = "fraud-detect"
endpoint_config_name = f"{pipeline_model_name}-endpoint-config"
endpoint_name = f"{pipeline_model_name}-endpoint"
- pipeline_name: パイプラインの名前を設定します。
- pipeline_model_name: パイプラインで使用するモデルの名前を設定します。
- model_package_group_name: モデルパッケージグループの名前を設定します。これは、モデルのバージョン管理に使用されます。
- base_job_name_prefix: ジョブ名のプレフィックスを設定します。これは、各ジョブの名前の一部として使用されます。
- endpoint_config_name: エンドポイント構成の名前を設定します。
- endpoint_name: エンドポイントの名前を設定します。
2. データパラメータの設定
# データパラメータの設定
target_col = "fraud"
- target_col: ターゲット列の名前を設定します。これは、モデルが予測するラベル列です。
3. インスタンスタイプとカウントの設定
# インスタンスタイプとカウントの設定
process_instance_type = "ml.c5.xlarge"
train_instance_count = 1
train_instance_type = "ml.m4.xlarge"
predictor_instance_count = 1
predictor_instance_type = "ml.m4.xlarge"
clarify_instance_count = 1
clarify_instance_type = "ml.m4.xlarge"
- process_instance_type: データ前処理に使用するインスタンスタイプを設定します。
- train_instance_count: トレーニングに使用するインスタンスの数を設定します。
- train_instance_type: トレーニングに使用するインスタンスタイプを設定します。
- predictor_instance_count: 推論に使用するインスタンスの数を設定します。
- predictor_instance_type: 推論に使用するインスタンスタイプを設定します。
- clarify_instance_count: Clarifyジョブに使用するインスタンスの数を設定します。
- clarify_instance_type: Clarifyジョブに使用するインスタンスタイプを設定します。
パイプラインパラメータを指定
Amazon SageMakerを使用して機械学習パイプラインの入力パラメータを設定するためのものです。
- データ前処理インスタンスタイプの設定
- トレーニングインスタンスタイプとインスタンス数の設定
- デプロイメントインスタンスタイプとインスタンス数の設定
- Clarifyチェックインスタンスタイプの設定
- モデルバイアスチェックの設定
- モデル説明可能性チェックの設定
- モデル承認ステータスの設定

Amazon SageMakerを使用して機械学習パイプラインの入力パラメータを設定するためのものです。これらのパラメータは、パイプラインの各ステップで使用されるインスタンスタイプやインスタンス数、モデルバイアスチェックや説明可能性チェックの設定などを指定します。以下に、各部分の説明を行います。
1. パイプライン入力パラメータの設定
データ前処理インスタンスタイプの設定
# データ前処理インスタンスタイプの設定
process_instance_type_param = ParameterString(
name="ProcessingInstanceType",
default_value=process_instance_type,
)
- process_instance_type_param: データ前処理に使用するインスタンスタイプを指定するパラメータ。
トレーニングインスタンスタイプとインスタンス数の設定
# トレーニングインスタンスタイプの設定
train_instance_type_param = ParameterString(
name="TrainingInstanceType",
default_value=train_instance_type,
)
# トレーニングインスタンス数の設定
train_instance_count_param = ParameterInteger(
name="TrainingInstanceCount",
default_value=train_instance_count
)
- train_instance_type_param: トレーニングに使用するインスタンスタイプを指定するパラメータ。
- train_instance_count_param: トレーニングに使用するインスタンスの数を指定するパラメータ。
デプロイメントインスタンスタイプとインスタンス数の設定
# デプロイメントインスタンスタイプの設定
deploy_instance_type_param = ParameterString(
name="DeployInstanceType",
default_value=predictor_instance_type,
)
# デプロイメントインスタンス数の設定
deploy_instance_count_param = ParameterInteger(
name="DeployInstanceCount",
default_value=predictor_instance_count
)
- deploy_instance_type_param: デプロイメントに使用するインスタンスタイプを指定するパラメータ。
- deploy_instance_count_param: デプロイメントに使用するインスタンスの数を指定するパラメータ。
Clarifyチェックインスタンスタイプの設定
# Clarifyチェックインスタンスタイプの設定
clarify_instance_type_param = ParameterString(
name="ClarifyInstanceType",
default_value=clarify_instance_type,
)
- clarify_instance_type_param: Clarifyチェックに使用するインスタンスタイプを指定するパラメータ。
モデルバイアスチェックの設定
# モデルバイアスチェックの設定
skip_check_model_bias_param = ParameterBoolean(
name="SkipModelBiasCheck",
default_value=False
)
register_new_baseline_model_bias_param = ParameterBoolean(
name="RegisterNewModelBiasBaseline",
default_value=False
)
supplied_baseline_constraints_model_bias_param = ParameterString(
name="ModelBiasSuppliedBaselineConstraints",
default_value=""
)
- skip_check_model_bias_param: モデルバイアスチェックをスキップするかどうかを指定するパラメータ。
- register_new_baseline_model_bias_param: 新しいモデルバイアスベースラインを登録するかどうかを指定するパラメータ。
- supplied_baseline_constraints_model_bias_param: 提供されたモデルバイアスベースライン制約を指定するパラメータ。
モデル説明可能性チェックの設定
# モデル説明可能性チェックの設定
skip_check_model_explainability_param = ParameterBoolean(
name="SkipModelExplainabilityCheck",
default_value=False
)
register_new_baseline_model_explainability_param = ParameterBoolean(
name="RegisterNewModelExplainabilityBaseline",
default_value=False
)
supplied_baseline_constraints_model_explainability_param = ParameterString(
name="ModelExplainabilitySuppliedBaselineConstraints",
default_value=""
)
- skip_check_model_explainability_param: モデル説明可能性チェックをスキップするかどうかを指定するパラメータ。
- register_new_baseline_model_explainability_param: 新しいモデル説明可能性ベースラインを登録するかどうかを指定するパラメータ。
- supplied_baseline_constraints_model_explainability_param: 提供されたモデル説明可能性ベースライン制約を指定するパラメータ。
モデル承認ステータスの設定
# モデル承認ステータスの設定
model_approval_status_param = ParameterString(
name="ModelApprovalStatus", default_value="Approved"
)
- model_approval_status_param: モデルの承認ステータスを指定するパラメータ。
パイプラインコンポーネントの構築
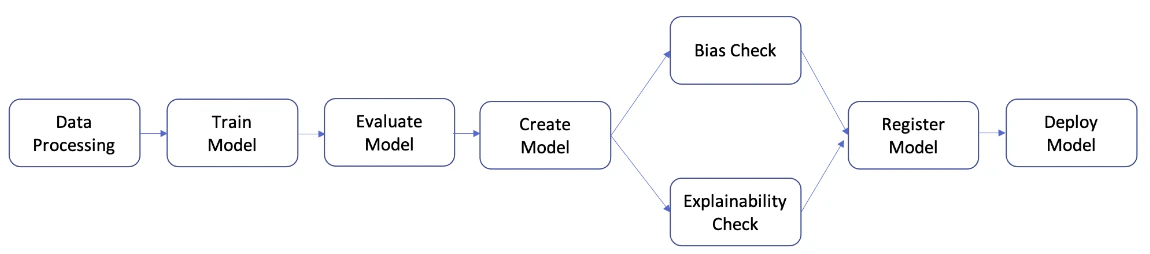
パイプラインを構築ステップ
1.データ処理ステップ: S3 にある入力生データを使用して SageMaker Processing ジョブを実行し、S3 にトレーニング、検証、およびテストの分割を出力します。
2.トレーニングステップ: S3 内のトレーニングデータと検証データを入力として、SageMaker のトレーニングジョブを使用して XGBoost モデルをトレーニングし、トレーニング済みのモデルアーティファクトを S3 に保存します。
3.評価ステップ: テストデータと S3 内のモデルアーティファクトを入力として SageMaker Processing ジョブを実行してテストデータセット上でモデルを評価し、出力されたモデルパフォーマンス評価レポートを S3 に保存します。
4.条件ステップ: テストデータセットでのモデルパフォーマンスを閾値と比較します。S3 内のモデルパフォーマンス評価レポートを入力として使用し、SageMaker Pipelines の定義済みステップを実行し、モデルパフォーマンスが許容できる場合に実行されるパイプラインステップの出力リストを保存します。
5.モデルステップを作成する: S3 にあるモデルアーティファクトを入力として使用し、SageMaker Pipelines の定義済みステップを実行し、出力された SageMaker モデルを S3 に保存します。
6.バイアスチェックのステップ: S3 にあるトレーニングデータとモデルアーティファクトを入力として SageMaker Clarify を使用してモデルのバイアスをチェックし、モデルのバイアスレポートとベースラインメトリクスを S3 に保存します。
7.モデル説明可能性ステップ: S3 内のトレーニングデータとモデルアーティファクトを入力として SageMaker Clarify を実行し、モデル説明可能性レポートとベースラインメトリクスを S3 に保存します。
8.登録ステップ: モデル、バイアス、説明可能性のベースラインメトリクスを入力として使用し、SageMaker Pipelines の定義済みステップを実行し、SageMaker Model Registry にモデルを登録します。
9.デプロイステップ: AWS Lambda ハンドラー関数、モデル、エンドポイント設定を入力として使用し、SageMaker Pipelines の定義済みステップを実行し、モデルを SageMaker Real-Time Inference のエンドポイントにデプロイします。
データ処理ステップ
データの前処理を行い、トレーニング、検証、およびテストデータセットに分割するためのものです。

1. インポートとロギングの設定
import argparse
import pathlib
import boto3
import os
import pandas as pd
import logging
from sklearn.model_selection import train_test_split
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
- 必要なライブラリをインポートします。
- ロギングの設定を行い、ログレベルをINFOに設定します。
2. コマンドライン引数の解析
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--train-ratio", type=float, default=0.8)
parser.add_argument("--validation-ratio", type=float, default=0.1)
parser.add_argument("--test-ratio", type=float, default=0.1)
args, _ = parser.parse_known_args()
logger.info("Received arguments {}".format(args))
- コマンドライン引数を解析し、トレーニング、検証、およびテストデータセットの比率を設定します。
3. データの読み込み
local_dir = "/opt/ml/processing"
input_data_path_claims = os.path.join("/opt/ml/processing/claims", "claims.csv")
input_data_path_customers = os.path.join("/opt/ml/processing/customers", "customers.csv")
logger.info("Reading claims data from {}".format(input_data_path_claims))
df_claims = pd.read_csv(input_data_path_claims)
logger.info("Reading customers data from {}".format(input_data_path_customers))
df_customers = pd.read_csv(input_data_path_customers)
- データのローカルパスを設定し、
claims.csvとcustomers.csvを読み込みます。
4. データの前処理
logger.debug("Formatting column names.")
df_claims = df_claims.rename({c : c.lower().strip().replace(' ', '_') for c in df_claims.columns}, axis = 1)
df_customers = df_customers.rename({c : c.lower().strip().replace(' ', '_') for c in df_customers.columns}, axis = 1)
logger.debug("Joining datasets.")
df_data = df_claims.merge(df_customers, on = 'policy_id', how = 'left')
df_data = df_data.drop(['customer_zip'], axis = 1)
ordinal_cols = ["police_report_available", "policy_liability", "customer_education"]
cat_cols_all = list(df_data.select_dtypes('object').columns)
cat_cols = [c for c in cat_cols_all if c not in ordinal_cols]
df_data[cat_cols] = df_data[cat_cols].fillna('na')
logger.debug("One-hot encoding categorical columns.")
df_data = pd.get_dummies(df_data, columns = cat_cols)
logger.debug("Encoding ordinal columns.")
mapping = {"Yes": "1", "No": "0"}
df_data['police_report_available'] = df_data['police_report_available'].map(mapping).astype(float)
mapping = {"15/30": "0", "25/50": "1", "30/60": "2", "100/200": "3"}
df_data['policy_liability'] = df_data['policy_liability'].map(mapping).astype(float)
mapping = {"Below High School": "0", "High School": "1", "Associate": "2", "Bachelor": "3", "Advanced Degree": "4"}
df_data['customer_education'] = df_data['customer_education'].map(mapping).astype(float)
df_processed = df_data.copy()
df_processed.columns = [c.lower() for c in df_data.columns]
df_processed = df_processed.drop(["policy_id", "customer_gender_unkown"], axis=1)
- カラム名をフォーマットし、データセットを結合します。
- 不要なカラムを削除し、カテゴリカルカラムをOne-hotエンコーディングします。
- 順序付きカラムをエンコードします。
5. データの分割
train_ratio = args.train_ratio
val_ratio = args.validation_ratio
test_ratio = args.test_ratio
logger.debug("Splitting data into train, validation, and test sets")
y = df_processed['fraud']
X = df_processed.drop(['fraud'], axis = 1)
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=test_ratio, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=val_ratio, random_state=42)
train_df = pd.concat([y_train, X_train], axis = 1)
val_df = pd.concat([y_val, X_val], axis = 1)
test_df = pd.concat([y_test, X_test], axis = 1)
dataset_df = pd.concat([y, X], axis = 1)
logger.info("Train data shape after preprocessing: {}".format(train_df.shape))
logger.info("Validation data shape after preprocessing: {}".format(val_df.shape))
logger.info("Test data shape after preprocessing: {}".format(test_df.shape))
- データをトレーニング、検証、およびテストセットに分割します。
- 各データセットの形状をログに記録します。
6. データの保存
logger.debug("Writing processed datasets to container local path.")
train_output_path = os.path.join(f"{local_dir}/train", "train.csv")
validation_output_path = os.path.join(f"{local_dir}/val", "validation.csv")
test_output_path = os.path.join(f"{local_dir}/test", "test.csv")
full_processed_output_path = os.path.join(f"{local_dir}/full", "dataset.csv")
logger.info("Saving train data to {}".format(train_output_path))
train_df.to_csv(train_output_path, index=False)
logger.info("Saving validation data to {}".format(validation_output_path))
val_df.to_csv(validation_output_path, index=False)
logger.info("Saving test data to {}".format(test_output_path))
test_df.to_csv(test_output_path, index=False)
logger.info("Saving full processed data to {}".format(full_processed_output_path))
dataset_df.to_csv(full_processed_output_path, index=False)
- 前処理されたデータセットをローカルパスに保存します。
- SageMakerがこれらのパスの内容をS3バケットにアップロードします。
SageMaker Pipelines ステップをインスタンス化し、処理スクリプトを実行
Amazon SageMakerを使用してデータの前処理を行うためのパイプラインステップを定義しています。前処理スクリプトをS3にアップロードし、SKLearnProcessorを使用して前処理ジョブを設定し、ProcessingStepを使用してパイプラインの前処理ステップを定義します。これにより、データの前処理を自動化し、トレーニング、検証、およびテストデータセットを生成することができます。

1. 必要なライブラリのインポート
from sagemaker.workflow.pipeline_context import PipelineSession
from sagemaker.sklearn.processing import SKLearnProcessor
from sagemaker.processing import ProcessingInput, ProcessingOutput, ProcessingStep
import boto3
2. 前処理スクリプトのS3へのアップロード
# S3クライアントの作成
s3_client = boto3.client('s3')
# 前処理スクリプトをS3にアップロード
s3_client.upload_file(
Filename="preprocessing.py",
Bucket=write_bucket,
Key=f"{write_prefix}/scripts/preprocessing.py"
)
-
preprocessing.pyスクリプトを指定されたS3バケットにアップロードします。
3. SKLearnProcessorの設定
# SKLearnProcessorの設定
sklearn_processor = SKLearnProcessor(
framework_version="0.23-1",
role=sagemaker_role,
instance_count=1,
instance_type=process_instance_type,
base_job_name=f"{base_job_name_prefix}-processing",
)
-
SKLearnProcessorを使用して、Scikit-learnの前処理ジョブを設定します。 -
framework_version、role、instance_count、instance_type、base_job_nameを指定します。
4. パイプラインの前処理ステップの定義
# パイプラインの前処理ステップの定義
process_step = ProcessingStep(
name="DataProcessing",
processor=sklearn_processor,
inputs=[
ProcessingInput(source=claims_data_uri, destination="/opt/ml/processing/claims"),
ProcessingInput(source=customers_data_uri, destination="/opt/ml/processing/customers")
],
outputs=[
ProcessingOutput(destination=f"{processing_output_uri}/train_data", output_name="train_data", source="/opt/ml/processing/train"),
ProcessingOutput(destination=f"{processing_output_uri}/validation_data", output_name="validation_data", source="/opt/ml/processing/val"),
ProcessingOutput(destination=f"{processing_output_uri}/test_data", output_name="test_data", source="/opt/ml/processing/test"),
ProcessingOutput(destination=f"{processing_output_uri}/processed_data", output_name="processed_data", source="/opt/ml/processing/full")
],
job_arguments=[
"--train-ratio", "0.8",
"--validation-ratio", "0.1",
"--test-ratio", "0.1"
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/preprocessing.py"
)
-
ProcessingStepを使用して、前処理ステップを定義します。 -
name:ステップの名前を指定します。 -
processor:前処理ジョブを実行するためのプロセッサを指定します。 -
inputs:前処理ジョブに入力するデータのソースとデスティネーションを指定します。 -
outputs:前処理ジョブの出力データのデスティネーションを指定します。 -
job_arguments:前処理スクリプトに渡す引数を指定します。 -
code:前処理スクリプトのS3パスを指定します。
トレーニングスクリプトを準備し、XGBoost 二項分類器のトレーニングロジックをカプセル化
XGBoostを使用してモデルをトレーニングし、評価メトリクスを保存するためのものです。データの読み込み、モデルのハイパーパラメータの設定、クロスバリデーション、モデルのトレーニング、評価、保存の各ステップが含まれています。SageMaker環境で実行することを前提としており、トレーニングデータと検証データのパス、モデルの保存先などが環境変数で設定されています。

1. インポートと引数の設定
import argparse
import os
import joblib
import json
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# ハイパーパラメータとアルゴリズムパラメータの設定
parser.add_argument("--num_round", type=int, default=100)
parser.add_argument("--max_depth", type=int, default=3)
parser.add_argument("--eta", type=float, default=0.2)
parser.add_argument("--subsample", type=float, default=0.9)
parser.add_argument("--colsample_bytree", type=float, default=0.8)
parser.add_argument("--objective", type=str, default="binary:logistic")
parser.add_argument("--eval_metric", type=str, default="auc")
parser.add_argument("--nfold", type=int, default=3)
parser.add_argument("--early_stopping_rounds", type=int, default=3)
# SageMaker固有の引数。デフォルトは環境変数で設定
parser.add_argument("--train_data_dir", type=str, default=os.environ.get("SM_CHANNEL_TRAIN"))
parser.add_argument("--validation_data_dir", type=str, default=os.environ.get("SM_CHANNEL_VALIDATION"))
parser.add_argument("--model_dir", type=str, default=os.environ.get("SM_MODEL_DIR"))
parser.add_argument("--output_data_dir", type=str, default=os.environ.get("SM_OUTPUT_DATA_DIR"))
args = parser.parse_args()
- 必要なライブラリをインポートし、コマンドライン引数を設定します。
- ハイパーパラメータやSageMaker固有の引数を設定します。
2. データの読み込み
data_train = pd.read_csv(f"{args.train_data_dir}/train.csv")
train = data_train.drop("fraud", axis=1)
label_train = pd.DataFrame(data_train["fraud"])
dtrain = xgb.DMatrix(train, label=label_train)
data_validation = pd.read_csv(f"{args.validation_data_dir}/validation.csv")
validation = data_validation.drop("fraud", axis=1)
label_validation = pd.DataFrame(data_validation["fraud"])
dvalidation = xgb.DMatrix(validation, label=label_validation)
- トレーニングデータと検証データを読み込み、XGBoostのDMatrix形式に変換します。
3. モデルのハイパーパラメータの設定
params = {"max_depth": args.max_depth,
"eta": args.eta,
"objective": args.objective,
"subsample" : args.subsample,
"colsample_bytree":args.colsample_bytree
}
num_boost_round = args.num_round
nfold = args.nfold
early_stopping_rounds = args.early_stopping_rounds
- モデルのハイパーパラメータを設定します。
4. モデルのクロスバリデーションとトレーニング
cv_results = xgb.cv(
params=params,
dtrain=dtrain,
num_boost_round=num_boost_round,
nfold=nfold,
early_stopping_rounds=early_stopping_rounds,
metrics=["auc"],
seed=42,
)
model = xgb.train(params=params, dtrain=dtrain, num_boost_round=len(cv_results))
- クロスバリデーションを行い、最適なブーストラウンド数を決定します。
- モデルをトレーニングします。
5. モデルの評価
train_pred = model.predict(dtrain)
validation_pred = model.predict(dvalidation)
train_auc = roc_auc_score(label_train, train_pred)
validation_auc = roc_auc_score(label_validation, validation_pred)
print(f"[0]#011train-auc:{train_auc:.2f}")
print(f"[0]#011validation-auc:{validation_auc:.2f}")
metrics_data = {"hyperparameters" : params,
"binary_classification_metrics": {"validation:auc": {"value": validation_auc},
"train:auc": {"value": train_auc}
}
}
- トレーニングデータと検証データに対して予測を行い、AUCスコアを計算します。
- 評価メトリクスを保存します。
6. モデルとメトリクスの保存
metrics_location = args.output_data_dir + "/metrics.json"
model_location = args.model_dir + "/xgboost-model"
with open(metrics_location, "w") as f:
json.dump(metrics_data, f)
with open(model_location, "wb") as f:
joblib.dump(model, f)
- 評価メトリクスをJSONファイルとして保存します。
- トレーニング済みモデルを保存します。
SageMaker XGBoost 推定子と SageMaker Pipelines TrainingStep 関数を使用してモデルトレーニングを設定
Amazon SageMakerを使用してXGBoostモデルをトレーニングするためのパイプラインステップを定義しています。
XGBoostモデルのハイパーパラメータを設定し、推定器を定義し、トレーニングデータと検証データの入力を設定し、トレーニングステップを定義します。これにより、データの前処理からモデルのトレーニングまでの一連のプロセスを自動化することができます。

1. XGBoostモデルのハイパーパラメータの設定
# XGBoostモデルのハイパーパラメータを設定
hyperparams = {
"eval_metric" : "auc",
"objective": "binary:logistic",
"num_round": "5",
"max_depth":"5",
"subsample":"0.75",
"colsample_bytree":"0.75",
"eta":"0.5"
}
- XGBoostモデルのハイパーパラメータを辞書形式で設定します。
-
eval_metric、objective、num_round、max_depth、subsample、colsample_bytree、etaなどのパラメータを指定します。
2. XGBoost推定器の設定
# XGBoost推定器の設定
xgb_estimator = XGBoost(
entry_point="xgboost_train.py",
output_path=estimator_output_uri,
code_location=estimator_output_uri,
hyperparameters=hyperparams,
role=sagemaker_role,
instance_count=train_instance_count,
instance_type=train_instance_type,
framework_version="1.3-1"
)
-
XGBoostクラスを使用して、XGBoost推定器を設定します。 -
entry_point:トレーニングスクリプトのパスを指定します。 -
output_path:トレーニング済みモデルの出力先を指定します。 -
code_location:トレーニングスクリプトの保存先を指定します。 -
hyperparameters:ハイパーパラメータを指定します。 -
role:SageMakerの実行ロールを指定します。 -
instance_count:トレーニングインスタンスの数を指定します。 -
instance_type:トレーニングインスタンスのタイプを指定します。 -
framework_version:XGBoostのフレームワークバージョンを指定します。
3. トレーニングデータと検証データの入力設定
# 前の処理ステップで保存されたトレーニングデータと検証データの場所にアクセス
s3_input_train = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
s3_input_validation = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["validation_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
-
TrainingInputクラスを使用して、トレーニングデータと検証データの入力設定を行います。 -
s3_data:前の処理ステップで保存されたデータのS3 URIを指定します。 -
content_type:データのコンテンツタイプを指定します(ここではcsv)。 -
s3_data_type:S3データのタイプを指定します(ここではS3Prefix)。
4. パイプラインのトレーニングステップの定義
# パイプラインのトレーニングステップの定義
train_step = TrainingStep(
name="XGBModelTraining",
estimator=xgb_estimator,
inputs={
"train": s3_input_train, # トレーニングチャネル
"validation": s3_input_validation # 検証チャネル
}
)
-
TrainingStepクラスを使用して、トレーニングステップを定義します。 -
name:ステップの名前を指定します。 -
estimator:トレーニングに使用する推定器を指定します。 -
inputs:トレーニングデータと検証データの入力を指定します。
トレーニングステップの出力を利用して、デプロイ用のモデルをパッケージ化
Amazon SageMakerを使用してトレーニング済みモデルをデプロイするためのステップを定義しています。
トレーニング済みモデルをSageMakerエンドポイントにデプロイするためのステップがパイプラインに追加されます。これにより、モデルのデプロイが自動化され、エンドポイントを通じてリアルタイムの予測が可能になります。
-
SageMakerモデルの作成
- トレーニングに使用したDockerイメージとトレーニングステップで生成されたモデルアーティファクトを使用して、SageMakerモデルを作成します。
-
モデルデプロイのインスタンスタイプの指定
- モデルデプロイに使用するインスタンスタイプを指定します。
-
CreateModelStepの定義
- モデル作成ステップを定義し、パイプラインに追加します。

1. SageMakerモデルの作成
# SageMakerモデルの作成
model = sagemaker.model.Model(
image_uri=training_image,
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
sagemaker_session=sess,
role=sagemaker_role
)
-
sagemaker.model.Modelクラスを使用して、SageMakerモデルを作成します。 -
image_uri:トレーニングに使用したDockerイメージのURIを指定します。 -
model_data:トレーニングステップで生成されたモデルアーティファクトのS3 URIを指定します。 -
sagemaker_session:SageMakerセッションを指定します。 -
role:SageMakerの実行ロールを指定します。
2. モデルデプロイのインスタンスタイプの指定
# モデルデプロイのインスタンスタイプの指定
inputs = sagemaker.inputs.CreateModelInput(instance_type=deploy_instance_type_param)
-
sagemaker.inputs.CreateModelInputクラスを使用して、モデルデプロイのインスタンスタイプを指定します。 -
instance_type:デプロイに使用するインスタンスタイプを指定します。
3. CreateModelStepの定義
create_model_step = CreateModelStep(name="FraudDetModel", model=model, inputs=inputs)
-
CreateModelStepクラスを使用して、モデル作成ステップを定義します。 -
name:ステップの名前を指定します。 -
model:作成したSageMakerモデルを指定します。 -
inputs:モデルデプロイのインスタンスタイプを指定します。
SageMaker Clarify にモデルバイアスチェックを設定
Amazon SageMaker Clarifyを使用してモデルのバイアスチェックを行うためのパイプラインステップを定義しています。モデルのバイアスチェックが自動化され、バイアスレポートが生成されます。
- 共通設定パラメータの設定:バイアスチェックジョブの共通設定パラメータを設定します。
- モデルバイアスチェック用データの設定:バイアスチェックに使用するデータの設定を行います。
- トレーニング済みモデルの設定:バイアスチェック対象のモデルの設定を行います。
- バイアスチェックの設定:バイアスチェックの設定を行います。
- モデル予測設定:モデル予測の設定を行います。
- モデルバイアスチェックの設定:モデルバイアスチェックの設定を行います。
- パイプラインのモデルバイアスチェックステップの定義:モデルバイアスチェックステップを定義し、パイプラインに追加します。

1. 共通設定パラメータの設定
# 複数のステップで使用される共通設定パラメータの設定
check_job_config = CheckJobConfig(
role=sagemaker_role,
instance_count=1,
instance_type=clarify_instance_type,
volume_size_in_gb=30,
sagemaker_session=sess,
)
-
CheckJobConfigクラスを使用して、バイアスチェックジョブの共通設定パラメータを設定します。 -
role:SageMakerの実行ロールを指定します。 -
instance_count:インスタンスの数を指定します。 -
instance_type:インスタンスタイプを指定します。 -
volume_size_in_gb:ボリュームサイズを指定します。 -
sagemaker_session:SageMakerセッションを指定します。
2. モデルバイアスチェック用データの設定
# モデルバイアスチェック用データの設定
model_bias_data_config = sagemaker.clarify.DataConfig(
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=bias_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_bias_config_output_uri
)
-
sagemaker.clarify.DataConfigクラスを使用して、バイアスチェックに使用するデータの設定を行います。 -
s3_data_input_path:トレーニングデータのS3 URIを指定します。 -
s3_output_path:バイアスレポートの出力先S3 URIを指定します。 -
label:ターゲット列を指定します。 -
dataset_type:データセットのタイプを指定します(ここではtext/csv)。 -
s3_analysis_config_output_path:分析設定の出力先S3 URIを指定します。
3. トレーニング済みモデルの設定
# トレーニング済みモデルの設定
model_config = sagemaker.clarify.ModelConfig(
model_name=create_model_step.properties.ModelName,
instance_count=train_instance_count,
instance_type=train_instance_type
)
-
sagemaker.clarify.ModelConfigクラスを使用して、バイアスチェック対象のモデルの設定を行います。 -
model_name:モデル作成ステップから取得したモデル名を指定します。 -
instance_count:インスタンスの数を指定します。 -
instance_type:インスタンスタイプを指定します。
4. バイアスチェックの設定
# バイアスチェックの設定
model_bias_config = sagemaker.clarify.BiasConfig(
label_values_or_threshold=[0],
facet_name="customer_gender_female",
facet_values_or_threshold=[1]
)
-
sagemaker.clarify.BiasConfigクラスを使用して、バイアスチェックの設定を行います。 -
label_values_or_threshold:ラベルの値または閾値を指定します。 -
facet_name:バイアスチェック対象のカラム名を指定します。 -
facet_values_or_threshold:バイアスチェック対象の値または閾値を指定します。
5. モデル予測設定
# モデル予測設定
model_predictions_config = sagemaker.clarify.ModelPredictedLabelConfig(probability_threshold=0.5)
-
sagemaker.clarify.ModelPredictedLabelConfigクラスを使用して、モデル予測の設定を行います。 -
probability_threshold:確率の閾値を指定します。
6. モデルバイアスチェックの設定
model_bias_check_config = ModelBiasCheckConfig(
data_config=model_bias_data_config,
data_bias_config=model_bias_config,
model_config=model_config,
model_predicted_label_config=model_predictions_config,
methods=["DPPL"]
)
-
ModelBiasCheckConfigクラスを使用して、モデルバイアスチェックの設定を行います。 -
data_config:データ設定を指定します。 -
data_bias_config:バイアス設定を指定します。 -
model_config:モデル設定を指定します。 -
model_predicted_label_config:モデル予測設定を指定します。 -
methods:バイアスチェックに使用するメソッドを指定します(ここではDPPL)。
7. パイプラインのモデルバイアスチェックステップの定義
# パイプラインのモデルバイアスチェックステップの定義
model_bias_check_step = ClarifyCheckStep(
name="ModelBiasCheck",
clarify_check_config=model_bias_check_config,
check_job_config=check_job_config,
skip_check=skip_check_model_bias_param,
register_new_baseline=register_new_baseline_model_bias_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_bias_param
)
-
ClarifyCheckStepクラスを使用して、モデルバイアスチェックステップを定義します。 -
name:ステップの名前を指定します。 -
clarify_check_config:バイアスチェック設定を指定します。 -
check_job_config:チェックジョブの共通設定を指定します。 -
skip_check:バイアスチェックをスキップするかどうかを指定します。 -
register_new_baseline:新しいベースラインを登録するかどうかを指定します。 -
supplied_baseline_constraints:提供されたベースライン制約を指定します。
モデル説明可能性チェックを設定
Amazon SageMaker Clarifyを使用してモデルの説明可能性チェックを行うためのパイプラインステップを定義しています。モデルの説明可能性チェックが自動化され、説明可能性レポートが生成されます。
Amazon SageMaker Clarifyを使用してモデルの説明可能性(Explainability)チェックを行うためのパイプラインステップを定義しています。
- モデル説明可能性チェック用データの設定:説明可能性チェックに使用するデータの設定を行います。
- SHAP設定の定義:SHAP(Shapley Additive Explanations)設定を定義します。
- モデル説明可能性チェックの設定:モデル説明可能性チェックの設定を行います。
- パイプラインのモデル説明可能性チェックステップの定義:モデル説明可能性チェックステップを定義し、パイプラインに追加します。

1. モデル説明可能性チェック用データの設定
# モデル説明可能性チェック用データの設定
model_explainability_data_config = sagemaker.clarify.DataConfig(
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=explainability_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_explainability_config_output_uri
)
-
sagemaker.clarify.DataConfigクラスを使用して、説明可能性チェックに使用するデータの設定を行います。 -
s3_data_input_path:トレーニングデータのS3 URIを指定します。 -
s3_output_path:説明可能性レポートの出力先S3 URIを指定します。 -
label:ターゲット列を指定します。 -
dataset_type:データセットのタイプを指定します(ここではtext/csv)。 -
s3_analysis_config_output_path:分析設定の出力先S3 URIを指定します。
2. SHAP設定の定義
# Clarifyが特徴量の重要度のためにグローバルおよびローカルSHAP値を計算するためのSHAP設定
shap_config = sagemaker.clarify.SHAPConfig(
seed=42,
num_samples=100,
agg_method="mean_abs",
save_local_shap_values=True
)
-
sagemaker.clarify.SHAPConfigクラスを使用して、SHAP(Shapley Additive Explanations)設定を定義します。 -
seed:ランダムシードを指定します。 -
num_samples:SHAP値を計算するためのサンプル数を指定します。 -
agg_method:SHAP値の集計方法を指定します(ここではmean_abs)。 -
save_local_shap_values:ローカルSHAP値を保存するかどうかを指定します。
3. モデル説明可能性チェックの設定
model_explainability_config = ModelExplainabilityCheckConfig(
data_config=model_explainability_data_config,
model_config=model_config,
explainability_config=shap_config
)
-
ModelExplainabilityCheckConfigクラスを使用して、モデル説明可能性チェックの設定を行います。 -
data_config:データ設定を指定します。 -
model_config:モデル設定を指定します。 -
explainability_config:SHAP設定を指定します。
4. パイプラインのモデル説明可能性チェックステップの定義
# パイプラインのモデル説明可能性チェックステップの定義
model_explainability_step = ClarifyCheckStep(
name="ModelExplainabilityCheck",
clarify_check_config=model_explainability_config,
check_job_config=check_job_config,
skip_check=skip_check_model_explainability_param,
register_new_baseline=register_new_baseline_model_explainability_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_explainability_param
)
-
ClarifyCheckStepクラスを使用して、モデル説明可能性チェックステップを定義します。 -
name:ステップの名前を指定します。 -
clarify_check_config:説明可能性チェック設定を指定します。 -
check_job_config:チェックジョブの共通設定を指定します。 -
skip_check:説明可能性チェックをスキップするかどうかを指定します。 -
register_new_baseline:新しいベースラインを登録するかどうかを指定します。 -
supplied_baseline_constraints:提供されたベースライン制約を指定します。
ROC-AUCメトリクスを使用して、テストセット上でモデルをスコアリングする Python スクリプトを構築
このスクリプトは、XGBoostモデルの評価を行い、評価結果をJSON形式で保存するためのものです。モデルの性能を評価し、評価結果を保存することができます。
- モデルの読み込み:保存されたモデルを読み込みます。
- テストデータの読み込み:テストデータを読み込み、ターゲットカラムと特徴量カラムを抽出します。
- 予測の生成と評価:テストデータに対して予測を生成し、ROC-AUCスコアを計算します。
- 評価結果の保存:評価結果をJSON形式で保存します。
ROC-AUC(Receiver Operating Characteristic - Area Under the Curve)は、分類モデルの性能を評価するための重要なメトリクスです。ROC曲線は、真陽性率(TPR)と偽陽性率(FPR)の関係を示し、その下の面積(AUC)はモデルの識別能力を表します。AUCが1に近いほど、モデルの性能が高いことを示します。

このPythonスクリプトは、XGBoostモデルの評価を行い、評価結果をJSON形式で保存するためのものです。以下に、スクリプトの各部分を詳しく説明します。
1. インポートとロギングの設定
import json
import logging
import pathlib
import pickle
import tarfile
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
- 必要なライブラリをインポートします。
- ロギングの設定を行い、ログレベルをINFOに設定します。
2. モデルの読み込み
if __name__ == "__main__":
model_path = "/opt/ml/processing/model/model.tar.gz"
with tarfile.open(model_path) as tar:
tar.extractall(path=".")
logger.debug("Loading xgboost model.")
# トレーニングスクリプトで保存されたモデルファイル名に一致させる必要があります
model = pickle.load(open("xgboost-model", "rb"))
- モデルが保存されているtarファイルを解凍し、モデルを読み込みます。
-
model_path:モデルが保存されているパスを指定します。 -
pickle.loadを使用して、モデルを読み込みます。
3. テストデータの読み込み
logger.debug("Reading test data.")
test_local_path = "/opt/ml/processing/test/test.csv"
df_test = pd.read_csv(test_local_path)
# テストデータのターゲットカラムを抽出
y_test = df_test.iloc[:, 0].values
cols_when_train = model.feature_names
# テストデータの特徴量カラムを抽出
X = df_test[cols_when_train].copy()
X_test = xgb.DMatrix(X)
- テストデータを読み込み、ターゲットカラムと特徴量カラムを抽出します。
-
test_local_path:テストデータのパスを指定します。 -
xgb.DMatrixを使用して、特徴量データをXGBoostのDMatrix形式に変換します。
4. 予測の生成と評価
logger.info("Generating predictions for test data.")
pred = model.predict(X_test)
# モデル評価スコアの計算
logger.debug("Calculating ROC-AUC score.")
auc = roc_auc_score(y_test, pred)
metric_dict = {
"classification_metrics": {"roc_auc": {"value": auc}}
}
- テストデータに対して予測を生成します。
-
roc_auc_scoreを使用して、ROC-AUCスコアを計算します。 - 評価結果を辞書形式で保存します。
5. 評価結果の保存
# モデル評価メトリクスの保存
output_dir = "/opt/ml/processing/evaluation"
pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True)
logger.info("Writing evaluation report with ROC-AUC: %f", auc)
evaluation_path = f"{output_dir}/evaluation.json"
with open(evaluation_path, "w") as f:
f.write(json.dumps(metric_dict))
- 評価結果を保存するディレクトリを作成します。
- 評価結果をJSON形式で保存します。
-
evaluation_path:評価結果を保存するパスを指定します。
プロセッサと SageMaker Pipelines ステップをインスタンス化し、評価スクリプトを実行
Amazon SageMakerを使用してモデルの評価を行うためのパイプラインステップを定義しています。モデルの評価が自動化され、評価結果が保存されます。
- モデル評価スクリプトのS3へのアップロード:評価スクリプトをS3にアップロードします。
- ScriptProcessorの設定:評価ジョブを実行するためのプロセッサを設定します。
- PropertyFileの設定:評価結果を保存するファイルの設定を行います。
- モデル評価ステップの定義:モデル評価ステップを定義し、パイプラインに追加します。

1. モデル評価スクリプトのS3へのアップロード
# モデル評価スクリプトをS3にアップロード
s3_client.upload_file(
Filename="evaluate.py",
Bucket=write_bucket,
Key=f"{write_prefix}/scripts/evaluate.py"
)
-
evaluate.pyスクリプトを指定されたS3バケットにアップロードします。
2. ScriptProcessorの設定
eval_processor = ScriptProcessor(
image_uri=training_image,
command=["python3"],
instance_type=predictor_instance_type,
instance_count=predictor_instance_count,
base_job_name=f"{base_job_name_prefix}-model-eval",
sagemaker_session=sess,
role=sagemaker_role,
)
-
ScriptProcessorクラスを使用して、評価ジョブを実行するためのプロセッサを設定します。 -
image_uri:トレーニングに使用したDockerイメージのURIを指定します。 -
command:スクリプトを実行するコマンドを指定します(ここではpython3)。 -
instance_type:インスタンスタイプを指定します。 -
instance_count:インスタンスの数を指定します。 -
base_job_name:ジョブのベース名を指定します。 -
sagemaker_session:SageMakerセッションを指定します。 -
role:SageMakerの実行ロールを指定します。
3. PropertyFileの設定
evaluation_report = PropertyFile(
name="FraudDetEvaluationReport",
output_name="evaluation",
path="evaluation.json",
)
-
PropertyFileクラスを使用して、評価結果を保存するファイルの設定を行います。 -
name:プロパティファイルの名前を指定します。 -
output_name:出力名を指定します。 -
path:評価結果を保存するファイルのパスを指定します。
4. モデル評価ステップの定義
evaluation_step = ProcessingStep(
name="XGBModelEvaluate",
processor=eval_processor,
inputs=[
ProcessingInput(
source=train_step.properties.ModelArtifacts.S3ModelArtifacts,
destination="/opt/ml/processing/model",
),
ProcessingInput(
source=process_step.properties.ProcessingOutputConfig.Outputs["test_data"].S3Output.S3Uri,
destination="/opt/ml/processing/test",
),
],
outputs=[
ProcessingOutput(destination=f"{model_eval_output_uri}", output_name="evaluation", source="/opt/ml/processing/evaluation"),
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/evaluate.py",
property_files=[evaluation_report],
)
-
ProcessingStepクラスを使用して、モデル評価ステップを定義します。 -
name:ステップの名前を指定します。 -
processor:評価ジョブを実行するプロセッサを指定します。 -
inputs:評価ジョブに入力するデータのソースとデスティネーションを指定します。- トレーニングステップで保存されたモデルアーティファクトのS3 URIを指定します。
- 処理ステップで保存されたテストデータのS3 URIを指定します。
-
outputs:評価ジョブの出力データのデスティネーションを指定します。 -
code:評価スクリプトのS3パスを指定します。 -
property_files:評価結果を保存するプロパティファイルを指定します。
モデルステップを作成する
S3 にあるモデルアーティファクトを入力として使用し、SageMaker Pipelines の定義済みステップを実行し、出力された SageMaker モデルを S3 に保存します。
モデル登録のステップを設定
Amazon SageMakerを使用してモデルをレジストリに登録し、バイアスチェックや説明可能性チェックの結果を記録するためのステップを定義しています。モデルのバイアスチェックや説明可能性チェックの結果を記録し、モデルの品質を監視することができます。
- モデルメトリクスの設定:バイアスチェックや説明可能性チェックの結果を設定します。
- ドリフトチェックのベースライン設定:ドリフトチェックのベースラインを設定します。
- モデル登録ステップの定義:モデル登録ステップを定義し、パイプラインに追加します。

1. モデルメトリクスの設定
# モデルレジストリに記録するベースライン制約を取得
model_metrics = ModelMetrics(
bias_post_training=MetricsSource(
s3_uri=model_bias_check_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
explainability=MetricsSource(
s3_uri=model_explainability_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
)
-
ModelMetricsクラスを使用して、モデルメトリクスを設定します。 -
bias_post_training:バイアスチェックの結果を指定します。 -
explainability:説明可能性チェックの結果を指定します。 -
MetricsSourceクラスを使用して、メトリクスのS3 URIとコンテンツタイプを指定します。
2. ドリフトチェックのベースライン設定
# ドリフトチェックのためにモデルレジストリに記録するベースラインを取得
drift_check_baselines = DriftCheckBaselines(
bias_post_training_constraints=MetricsSource(
s3_uri=model_bias_check_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_constraints=MetricsSource(
s3_uri=model_explainability_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_config_file=FileSource(
s3_uri=model_explainability_config.monitoring_analysis_config_uri,
content_type="application/json",
),
)
-
DriftCheckBaselinesクラスを使用して、ドリフトチェックのベースラインを設定します。 -
bias_post_training_constraints:バイアスチェックのベースライン制約を指定します。 -
explainability_constraints:説明可能性チェックのベースライン制約を指定します。 -
explainability_config_file:説明可能性チェックの設定ファイルを指定します。 -
MetricsSourceおよびFileSourceクラスを使用して、ベースラインのS3 URIとコンテンツタイプを指定します。
3. モデル登録ステップの定義
# モデル登録ステップの定義
register_step = RegisterModel(
name="XGBRegisterModel",
estimator=xgb_estimator,
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
content_types=["text/csv"],
response_types=["text/csv"],
inference_instances=[predictor_instance_type],
transform_instances=[predictor_instance_type],
model_package_group_name=model_package_group_name,
approval_status=model_approval_status_param,
model_metrics=model_metrics,
drift_check_baselines=drift_check_baselines
)
-
RegisterModelクラスを使用して、モデル登録ステップを定義します。 -
name:ステップの名前を指定します。 -
estimator:トレーニングに使用した推定器を指定します。 -
model_data:トレーニングステップで生成されたモデルアーティファクトのS3 URIを指定します。 -
content_types:モデルが受け入れるコンテンツタイプを指定します。 -
response_types:モデルが返すレスポンスタイプを指定します。 -
inference_instances:推論に使用するインスタンスタイプを指定します。 -
transform_instances:バッチ変換に使用するインスタンスタイプを指定します。 -
model_package_group_name:モデルパッケージグループの名前を指定します。 -
approval_status:モデルの承認ステータスを指定します。 -
model_metrics:モデルメトリクスを指定します。 -
drift_check_baselines:ドリフトチェックのベースラインを指定します。
LambdaStep 関数を使用してモデルをデプロイ
このLambda関数は、Amazon SageMakerを使用してモデルをリアルタイムエンドポイントにデプロイするためのものです。指定されたパラメータに基づいてモデルがデプロイされ、リアルタイムエンドポイントが作成されます。
- モデルの作成:SageMakerモデルを作成します。
- エンドポイント構成の作成:エンドポイント構成を作成します。
- エンドポイントの作成:エンドポイントを作成します。

このPythonスクリプトは、AWS Lambda関数として実行され、Amazon SageMakerを使用してモデルをリアルタイムエンドポイントにデプロイするためのものです。
1. インポートとLambdaハンドラーの定義
%%writefile lambda_deployer.py
"""
Lambda function creates an endpoint configuration and deploys a model to real-time endpoint.
Required parameters for deployment are retrieved from the event object
"""
import json
import boto3
- 必要なライブラリをインポートします。
-
boto3はAWS SDK for Pythonで、AWSサービスと対話するために使用されます。
2. Lambdaハンドラー関数
def lambda_handler(event, context):
sm_client = boto3.client("sagemaker")
# Details of the model created in the Pipeline CreateModelStep
model_name = event["model_name"]
model_package_arn = event["model_package_arn"]
endpoint_config_name = event["endpoint_config_name"]
endpoint_name = event["endpoint_name"]
role = event["role"]
instance_type = event["instance_type"]
instance_count = event["instance_count"]
primary_container = {"ModelPackageName": model_package_arn}
-
lambda_handler関数は、Lambda関数のエントリーポイントです。 -
boto3.client("sagemaker")を使用して、SageMakerクライアントを作成します。 -
eventオブジェクトから必要なパラメータを取得します。
3. モデルの作成
# Create model
model = sm_client.create_model(
ModelName=model_name,
PrimaryContainer=primary_container,
ExecutionRoleArn=role
)
-
create_modelメソッドを使用して、SageMakerモデルを作成します。 -
ModelName:モデルの名前を指定します。 -
PrimaryContainer:モデルパッケージのARNを指定します。 -
ExecutionRoleArn:モデルの実行ロールを指定します。
4. エンドポイント構成の作成
# Create endpoint configuration
create_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"VariantName": "Alltraffic",
"ModelName": model_name,
"InitialInstanceCount": instance_count,
"InstanceType": instance_type,
"InitialVariantWeight": 1
}
]
)
-
create_endpoint_configメソッドを使用して、エンドポイント構成を作成します。 -
EndpointConfigName:エンドポイント構成の名前を指定します。 -
ProductionVariants:エンドポイントで使用するモデルのバリアントを指定します。-
VariantName:バリアントの名前を指定します。 -
ModelName:モデルの名前を指定します。 -
InitialInstanceCount:初期インスタンス数を指定します。 -
InstanceType:インスタンスタイプを指定します。 -
InitialVariantWeight:初期バリアントの重みを指定します。
-
5. エンドポイントの作成
# Create endpoint
create_endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)
-
create_endpointメソッドを使用して、エンドポイントを作成します。 -
EndpointName:エンドポイントの名前を指定します。 -
EndpointConfigName:エンドポイント構成の名前を指定します。
LambdaStep を作成
Amazon SageMakerを使用してLambda関数を作成し、その関数を使用してモデルをリアルタイムエンドポイントにデプロイするためのパイプラインステップを定義しています。指定されたパラメータに基づいてモデルがデプロイされ、リアルタイムエンドポイントが作成されます。
- Lambda関数の作成:Lambda関数を作成し、デプロイに必要なスクリプトと設定を指定します。
- Lambdaステップの定義:Lambdaステップを定義し、デプロイに必要なパラメータを指定します。

1. Lambda関数の作成
# Lambda関数の名前を定義
function_name = "sagemaker-fraud-det-demo-lambda-step"
# Lambdaヘルパークラスを使用して、Lambda関数を作成
func = Lambda(
function_name=function_name,
execution_role_arn=sagemaker_role,
script="lambda_deployer.py",
handler="lambda_deployer.lambda_handler",
timeout=600,
memory_size=10240,
)
-
function_name:Lambda関数の名前を指定します。 -
Lambdaクラスを使用して、Lambda関数を作成します。-
function_name:Lambda関数の名前を指定します。 -
execution_role_arn:Lambda関数の実行ロールを指定します。 -
script:Lambda関数のスクリプトファイルを指定します。 -
handler:Lambda関数のハンドラを指定します。 -
timeout:Lambda関数のタイムアウトを指定します(秒単位)。 -
memory_size:Lambda関数のメモリサイズを指定します(MB単位)。
-
2. Lambdaステップの定義
# Lambdaハンドラで使用される入力は、LambdaStepのinputs引数を通じて渡され、
# `lambda_handler`関数内の`event`オブジェクトを介して取得されます
lambda_deploy_step = LambdaStep(
name="LambdaStepRealTimeDeploy",
lambda_func=func,
inputs={
"model_name": pipeline_model_name,
"endpoint_config_name": endpoint_config_name,
"endpoint_name": endpoint_name,
"model_package_arn": register_step.steps[0].properties.ModelPackageArn,
"role": sagemaker_role,
"instance_type": deploy_instance_type_param,
"instance_count": deploy_instance_count_param
}
)
-
LambdaStepクラスを使用して、Lambdaステップを定義します。-
name:ステップの名前を指定します。 -
lambda_func:作成したLambda関数を指定します。 -
inputs:Lambdaハンドラで使用される入力パラメータを指定します。-
model_name:モデルの名前を指定します。 -
endpoint_config_name:エンドポイント構成の名前を指定します。 -
endpoint_name:エンドポイントのめいSを指定します。 -
model_package_arn:モデルパッケージのARNを指定します。 -
role:SageMakerの実行ロールを指定します。 -
instance_type:デプロイに使用するインスタンスタイプを指定します。 -
instance_count:デプロイに使用するインスタンスの数を指定します。
-
-
ConditionStep を使用して、曲線の下の面積 (AUC) メトリクスに基づく現在のモデルのパフォーマンスを比較
Amazon SageMakerを使用してモデルの評価結果に基づいて条件付きステップを定義しています。モデルの評価結果に基づいて次のステップを実行するかどうかを決定することができます。条件を満たす場合、モデル作成、バイアスチェック、説明可能性チェック、モデル登録、Lambdaデプロイの各ステップが実行されます。
- 条件の定義:評価ステップの結果からROC-AUCスコアを取得し、指定された閾値と比較する条件を定義します。
- 条件付きステップの定義:条件を満たす場合に実行するステップを指定します。

1. 条件の定義
# テストセットでのモデル性能を評価
cond_gte = ConditionGreaterThanOrEqualTo(
left=JsonGet(
step_name=evaluation_step.name,
property_file=evaluation_report,
json_path="classification_metrics.roc_auc.value",
),
right=0.7, # モデル性能を比較する閾値
)
-
ConditionGreaterThanOrEqualToクラスを使用して、条件を定義します。 -
left:評価ステップの結果からROC-AUCスコアを取得します。-
JsonGetクラスを使用して、評価ステップの結果から特定のプロパティを取得します。 -
step_name:評価ステップの名前を指定します。 -
property_file:評価結果を保存したプロパティファイルを指定します。 -
json_path:評価結果のJSONパスを指定します。
-
-
right:比較する閾値を指定します(ここでは0.7)。
2. 条件付きステップの定義
condition_step = ConditionStep(
name="CheckFraudDetXGBEvaluation",
conditions=[cond_gte],
if_steps=[create_model_step, model_bias_check_step, model_explainability_step, register_step, lambda_deploy_step],
else_steps=[]
)
-
ConditionStepクラスを使用して、条件付きステップを定義します。 -
name:ステップの名前を指定します。 -
conditions:評価する条件をリストで指定します。 -
if_steps:条件を満たす場合に実行するステップをリストで指定します。-
create_model_step:モデル作成ステップ。 -
model_bias_check_step:モデルバイアスチェックステップ。 -
model_explainability_step:モデル説明可能性チェックステップ。 -
register_step:モデル登録ステップ。 -
lambda_deploy_step:Lambdaデプロイステップ。
-
-
else_steps:条件を満たさない場合に実行するステップをリストで指定します(ここでは空のリスト)。
パイプラインを設定
Amazon SageMakerを使用してパイプラインを作成するためのものです。データの前処理、モデルのトレーニング、評価、条件付きステップなど、複数のステップで構成されたパイプラインが作成されます。パイプラインを実行することで、これらのステップが順次実行され、モデルのトレーニングとデプロイが自動化されます。
パイプラインは、データの前処理、モデルのトレーニング、評価、条件付きステップなど、複数のステップで構成されています。
- パラメータの設定:パイプラインで使用するパラメータをリストで指定します。
- ステップの設定:パイプラインの各ステップをリストで指定します。
-
パイプラインの作成:
Pipelineクラスを使用して、パイプラインを作成します。

1. パイプラインの作成
# すべてのコンポーネントステップとパラメータを含むパイプラインの作成
pipeline = Pipeline(
name=pipeline_name,
parameters=[
process_instance_type_param,
train_instance_type_param,
train_instance_count_param,
deploy_instance_type_param,
deploy_instance_count_param,
clarify_instance_type_param,
skip_check_model_bias_param,
register_new_baseline_model_bias_param,
supplied_baseline_constraints_model_bias_param,
skip_check_model_explainability_param,
register_new_baseline_model_explainability_param,
supplied_baseline_constraints_model_explainability_param,
model_approval_status_param
],
steps=[
process_step,
train_step,
evaluation_step,
condition_step
],
sagemaker_session=sess
)
-
Pipelineクラスを使用して、パイプラインを作成します。 -
name:パイプラインの名前を指定します。 -
parameters:パイプラインで使用するパラメータをリストで指定します。-
process_instance_type_param:データ前処理に使用するインスタンスタイプのパラメータ。 -
train_instance_type_param:トレーニングに使用するインスタンスタイプのパラメータ。 -
train_instance_count_param:トレーニングに使用するインスタンスの数のパラメータ。 -
deploy_instance_type_param:デプロイに使用するインスタンスタイプのパラメータ。 -
deploy_instance_count_param:デプロイに使用するインスタンスの数のパラメータ。 -
clarify_instance_type_param:Clarifyジョブに使用するインスタンスタイプのパラメータ。 -
skip_check_model_bias_param:モデルバイアスチェックをスキップするかどうかのパラメータ。 -
register_new_baseline_model_bias_param:新しいベースラインを登録するかどうかのパラメータ。 -
supplied_baseline_constraints_model_bias_param:提供されたベースライン制約のパラメータ。 -
skip_check_model_explainability_param:モデル説明可能性チェックをスキップするかどうかのパラメータ。 -
register_new_baseline_model_explainability_param:新しいベースラインを登録するかどうかのパラメータ。 -
supplied_baseline_constraints_model_explainability_param:提供されたベースライン制約のパラメータ。 -
model_approval_status_param:モデルの承認ステータスのパラメータ。
-
-
steps:パイプラインのステップをリストで指定します。-
process_step:データ前処理ステップ。 -
train_step:モデルトレーニングステップ。 -
evaluation_step:モデル評価ステップ。 -
condition_step:条件付きステップ。
-
-
sagemaker_session:SageMakerセッションを指定します。
パイプライン作成
Amazon SageMakerを使用してパイプラインを作成または更新し、その詳細を取得するためのものです。パイプラインの定義を確認し、必要に応じてパイプラインを更新することができます。
-
パイプラインの作成または更新:
pipeline.upsertメソッドを使用して、パイプラインを作成または更新します。 -
パイプラインの詳細を取得:
pipeline.describeメソッドを使用して、パイプラインの詳細を取得し、JSON形式に変換します。
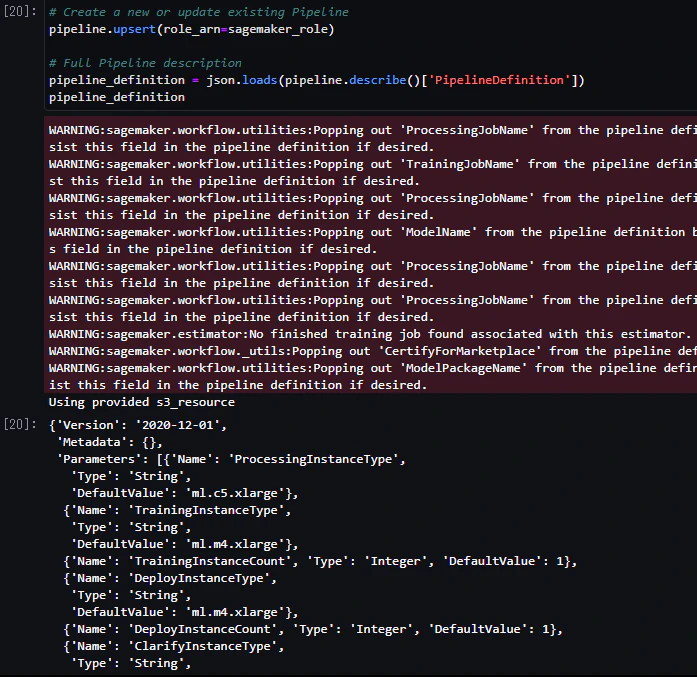
1. パイプラインの作成または更新
# 新しいパイプラインを作成するか、既存のパイプラインを更新
pipeline.upsert(role_arn=sagemaker_role)
-
pipeline.upsertメソッドを使用して、パイプラインを作成または更新します。 -
role_arn:SageMakerの実行ロールを指定します。
2. パイプラインの詳細を取得
# パイプラインの完全な説明を取得
pipeline_definition = json.loads(pipeline.describe()['PipelineDefinition'])
pipeline_definition
-
pipeline.describeメソッドを使用して、パイプラインの詳細を取得します。 -
json.loadsを使用して、取得したパイプラインの定義をJSON形式に変換します。
パイプラインメニューを表示
作成したパイプラインステップを表示
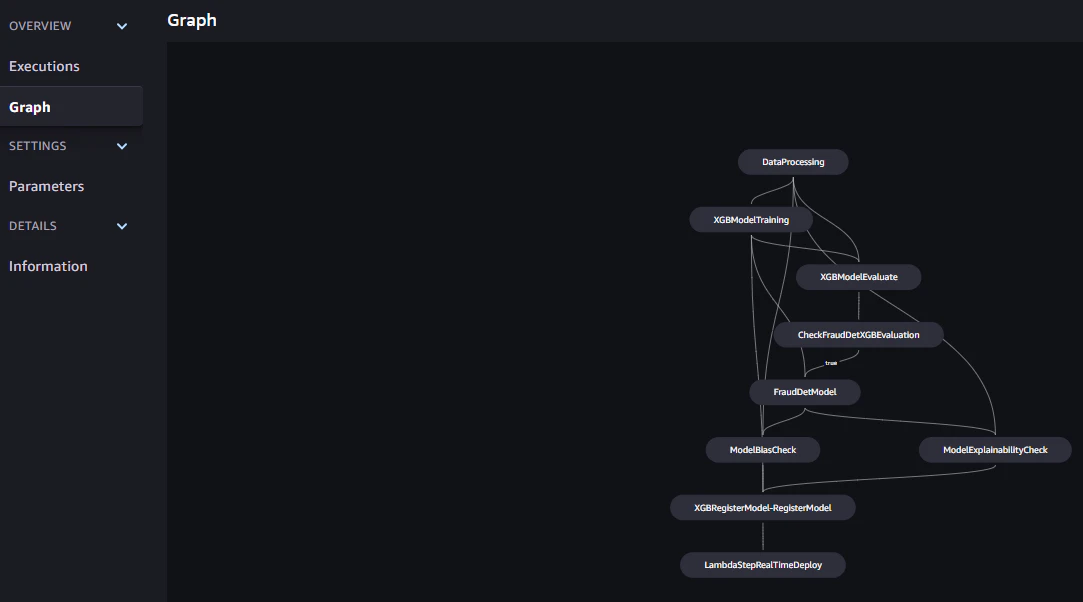
パイプラインを実行
Amazon SageMakerを使用してパイプラインを実行するためのものです。パイプラインの実行時に特定のチェックをスキップしたり、新しいベースラインを登録したり、動作を制御します。
-
パイプラインの実行:
pipeline.startメソッドを使用して、パイプラインを実行します。 - パラメータの指定:パイプラインの実行時に特定のパラメータを指定して、パイプラインの動作を制御します。
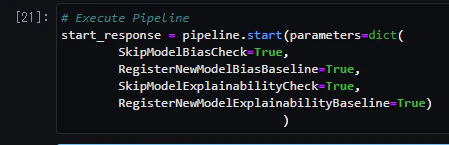
1. パイプラインの実行
# パイプラインの実行
start_response = pipeline.start(parameters=dict(
SkipModelBiasCheck=True,
RegisterNewModelBiasBaseline=True,
SkipModelExplainabilityCheck=True,
RegisterNewModelExplainabilityBaseline=True)
)
-
pipeline.startメソッドを使用して、パイプラインを実行します。 -
parameters引数を使用して、パイプラインの実行時に特定のパラメータを指定します。-
SkipModelBiasCheck:モデルバイアスチェックをスキップするかどうかを指定します。 -
RegisterNewModelBiasBaseline:新しいモデルバイアスベースラインを登録するかどうかを指定します。 -
SkipModelExplainabilityCheck:モデル説明可能性チェックをスキップするかどうかを指定します。 -
RegisterNewModelExplainabilityBaseline:新しいモデル説明可能性ベースラインを登録するかどうかを指定します。
-
パイプラインの実行を表示
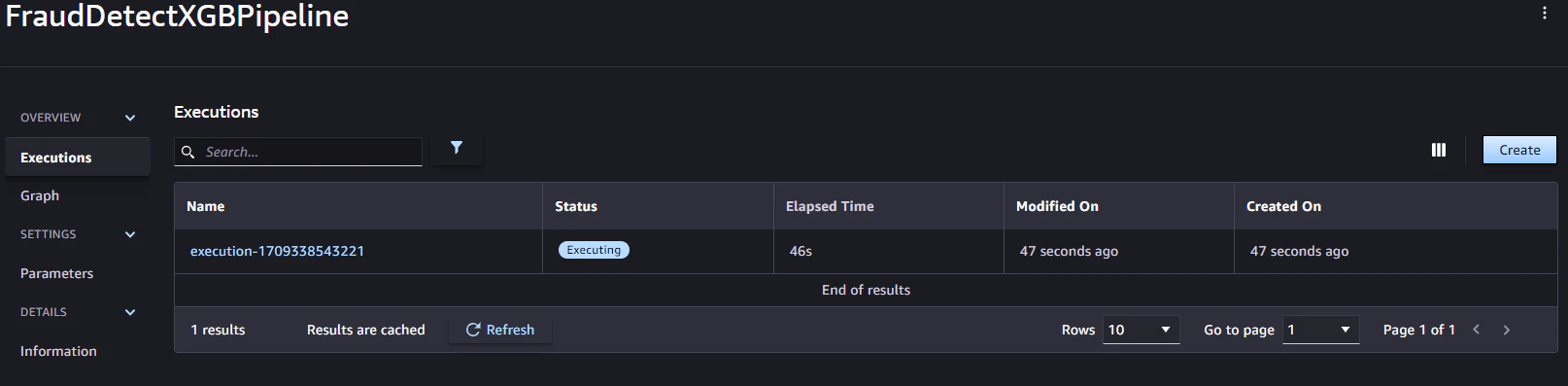
すべてのステップが正常に実行される

モデルの登録確認
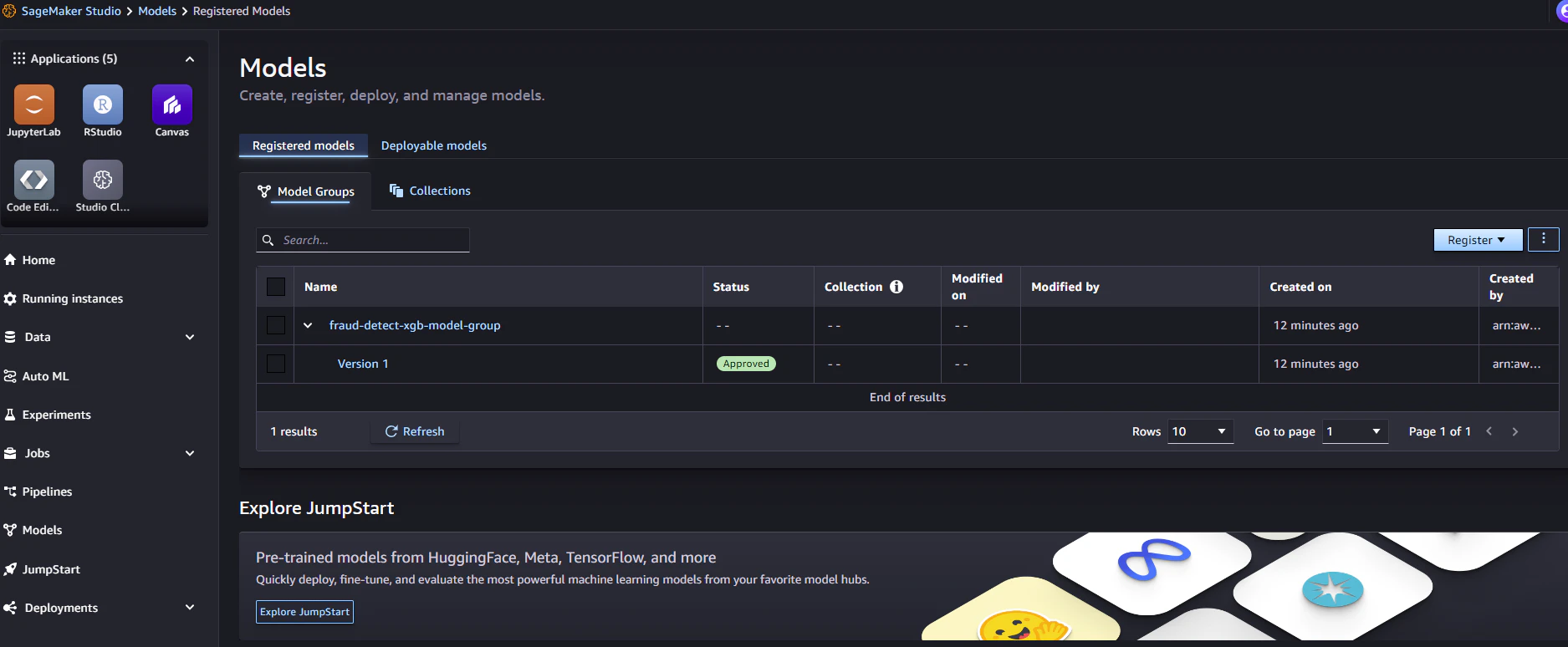
モデル説明可能性レポートの確認
レポートをダウンロードする事も出来る1/2

レポートをダウンロードする事も出来る2/2
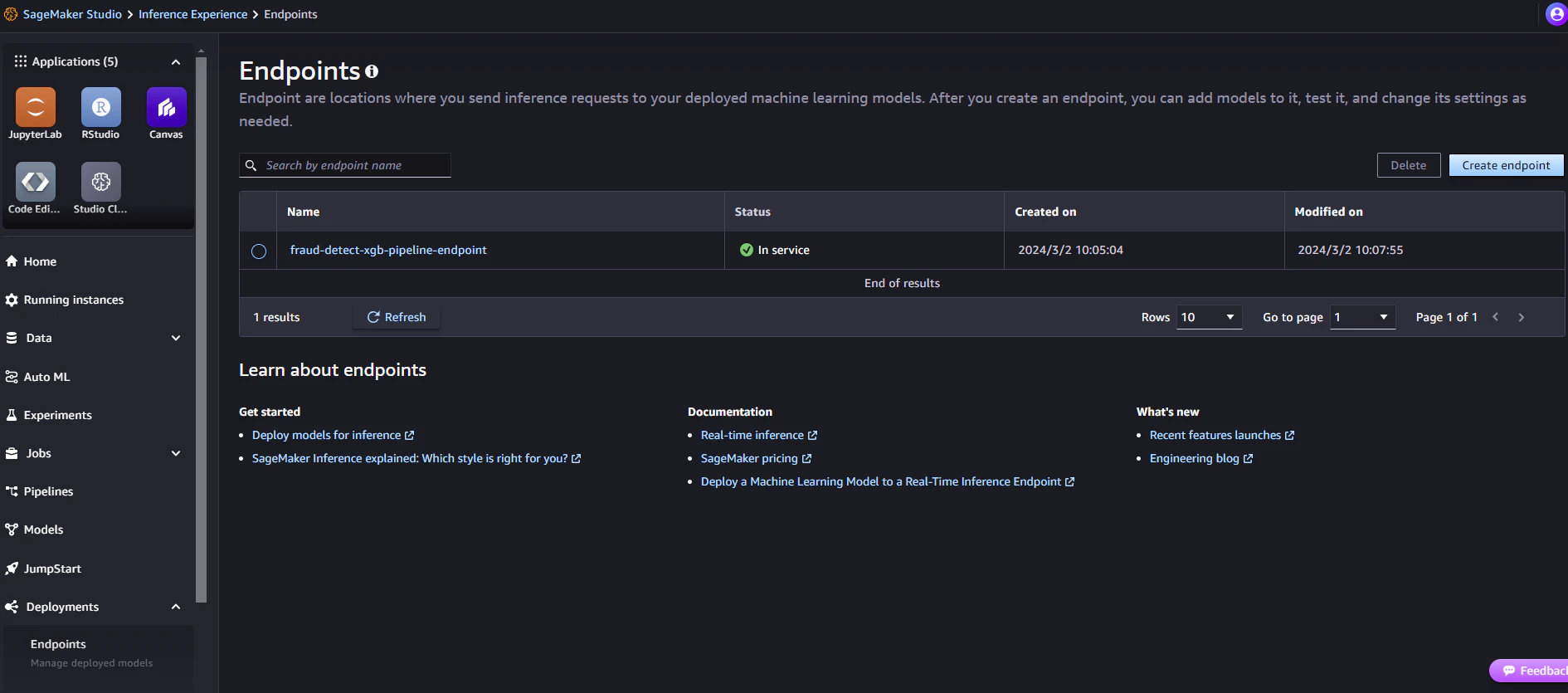
fraud-detect-xgb-pipeline-endpoint のステータスを確認する
推論を実行し、モデル予測値を確認する
Amazon SageMakerを使用してデプロイされたエンドポイントに対して予測を行うためのものです。デプロイされたモデルの予測結果を確認し、モデルの性能を評価することができます。
- テストデータの読み込み:テストデータをCSVファイルから読み込みます。
- SageMaker Predictorの作成:デプロイされたエンドポイントからSageMaker Predictorを作成します。
- エンドポイントへのリクエストと予測結果の取得:エンドポイントにリクエストを送り、予測結果を取得します。
- 予測結果の表示:予測結果をデータフレームに変換し、実際のラベルとともに表示します。
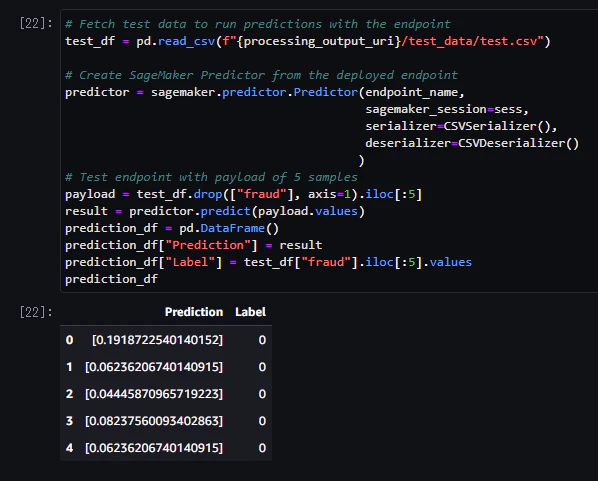
1. テストデータの読み込み
# 予測を実行するためのテストデータを取得
test_df = pd.read_csv(f"{processing_output_uri}/test_data/test.csv")
-
pd.read_csvを使用して、テストデータをCSVファイルから読み込みます。 -
processing_output_uri:テストデータが保存されているS3 URIを指定します。
2. SageMaker Predictorの作成
# デプロイされたエンドポイントからSageMaker Predictorを作成
predictor = sagemaker.predictor.Predictor(
endpoint_name,
sagemaker_session=sess,
serializer=CSVSerializer(),
deserializer=CSVDeserializer()
)
-
sagemaker.predictor.Predictorクラスを使用して、SageMaker Predictorを作成します。 -
endpoint_name:デプロイされたエンドポイントの名前を指定します。 -
sagemaker_session:SageMakerセッションを指定します。 -
serializer:リクエストデータをシリアライズするためのシリアライザを指定します(ここではCSVSerializer)。 -
deserializer:レスポンスデータをデシリアライズするためのデシリアライザを指定します(ここではCSVDeserializer)。
3. エンドポイントへのリクエストと予測結果の取得
# 5つのサンプルのペイロードでエンドポイントをテスト
payload = test_df.drop(["fraud"], axis=1).iloc[:5]
result = predictor.predict(payload.values)
-
test_dfからターゲット列(fraud)を削除し、最初の5つのサンプルを取得してペイロードを作成します。 -
predictor.predictメソッドを使用して、エンドポイントにリクエストを送り、予測結果を取得します。
4. 予測結果の表示
# 予測結果を表示
prediction_df = pd.DataFrame()
prediction_df["Prediction"] = result
prediction_df["Label"] = test_df["fraud"].iloc[:5].values
prediction_df
-
pd.DataFrameを使用して、予測結果をデータフレームに変換します。 -
Prediction列に予測結果を、Label列に実際のラベルを追加します。 -
prediction_dfを表示します。
補足
クイックセットアップで、実行ロール作成後、下記の修正が必要です。
信頼関係の修正
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "sagemaker.amazonaws.com"
},
"Action": "sts:AssumeRole"
},
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
ポリシーの修正
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket",
"iam:PassRole",
"lambda:CreateFunction"
],
"Resource": [
"arn:aws:s3:::*",
"arn:aws:iam::アカウント ID:role/*",
"arn:aws:lambda:us-east-1:アカウント ID:*"
]
}
]
}
リソースを削除する場合は、こちらの修正も必要
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"lambda:DeleteFunction"
],
"Resource": "arn:aws:lambda:us-east-1:アカウント ID:*"
}
]
}
仲間を募集しています!
ARIではエンジニア・ITコンサルタント・PM職全方位で仲間を募集しております。
カジュアル面談、随時受付中です!
ご興味ある方はこちらをご覧ください。