機械学習って、何?SageMakerで何が出来るの?ChatGPTと何が違うの?
機械学習は、コンピューターシステムがデータから パターンや知識を学習 し、それを使って タスクを実行するための技術 です。具体的には、大量のデータを用いて アルゴリズムを学習させ、未知のデータに対する予測や判断を行います。 SageMakerは、Amazon Web Services(AWS)が提供する機械学習のためのマネージドサービスで、機械学習モデルの構築、トレーニング、デプロイメントを行うことができます。 SageMakerは、データの準備からモデルのトレーニング、評価、デプロイメントまでのワークフローを効率化 し、スケーラビリティやリソースの管理をサポートします。
一方、ChatGPTは、OpenAIが開発した自然言語処理技術です。ChatGPTは大規模なデータセットを用いてトレーニングされ、テキスト生成、質問応答、文章要約などの自然言語タスクを行うことができます。ChatGPTは、対話形式での自然言語生成に特に適しており、質問応答、文章生成、対話型アプリケーションの構築などの用途で利用されます。ChatGPTは機械学習モデルの一種ですが、特定のタスクに特化したものではありません。
チュートリアルのソースコードをそのまま使えます。
細かい、ソースコードの内容は、こちらをご確認下さい。
https://aws.amazon.com/jp/getting-started/hands-on/machine-learning-tutorial-mlops-automate-ml-workflows/
※現在、こちらは、lambda関数で使用するRun Timeが現在は利用できないバージョンになっています。Cloudformationのリソースの作成に失敗します。しかしながら、一部修正を行うことで実行が可能です。修正方法は、最後にご説明致します。
SageMaker Pipelines は、
機械学習のために作られた継続的インテグレーションおよび継続的デリバリー (CI/CD) サービスです。
機械学習パイプラインは、機械学習モデルの構築、トレーニング、評価、デプロイメントなどの一連のプロセスを組み合わせた フレームワーク です。これは、データの収集からモデルの運用までの全体的な流れを体系的に組織し、自動化することを目的としています。
一般的な機械学習パイプラインの主要なステップ
1.データ収集と前処理
適切なデータセットを収集し、欠損値や異常値の処理、特徴量エンジニアリングなどの前処理を行います。
2.データ分割
データセットをトレーニングデータとテストデータに分割します。これにより、モデルのトレーニングと評価を独立して行うことができます。
3.特徴量エンジニアリング
データセットから適切な特徴を選択し、変換することでモデルの性能を向上させます。
4.モデルの選択
解決すべき課題に応じて、適切な機械学習アルゴリズムやモデルを選択します。
5.モデルのトレーニング
トレーニングデータを使用してモデルをトレーニングします。ハイパーパラメータの調整もこの段階で行います。
6.モデルの評価
テストデータを使用してモデルの性能を評価します。精度、再現率、適合率などの評価指標を考慮します。
7.モデルのデプロイメント
トレーニングされたモデルを本番環境にデプロイし、実際のデータに対する予測を行えるようにします。
8.モデルのモニタリングとメンテナンス
デプロイ後もモデルの性能をモニタリングし、必要に応じて再トレーニングや更新を行います。
これらのステップは、機械学習プロジェクトを効果的に進めるために重要です。機械学習パイプラインの自動化は、実験の再現性、生産性の向上、モデルの効果的な管理を可能にし、効率的かつ信頼性の高い機械学習モデルの開発を支援します。
今回は、このパイプラインの使い方を説明します。
SageMaker Pipelines を使用すると、
データロード、データ変換、トレーニング、チューニング、評価、デプロイなど、機械学習ワークフローのさまざまなステップを自動化することができます。
SageMaker Model Registry を使用すると、
モデルのバージョン、ユースケースのグループ化などのメタデータ、モデルのパフォーマンスメトリクスベースラインを中央リポジトリで追跡でき、ビジネス要件に基づいてデプロイに適したモデルを容易に選択することができます。
SageMaker Clarify は、
トレーニングデータとモデルの可視性を高めることで、バイアスの特定と制限、予測の説明を可能にします。
ステップ 1: Amazon SageMaker Studio ドメインを設定する
ドメインの設定方法は、下記にまとめました。
https://qiita.com/kimuni-i/items/d822973ac825cdfbaa6c
※実行ロールの修正箇所は、最後の項目で整理しているので、ご確認下さい。
ステップ 2: SageMaker Studio ノートブックを設定し、パイプラインをパラメータ化する
1.必要なライブラリをインポート
2.生データセットと処理済みデータセットおよびモデルアーティファクトが保存される S3 バケットロケーションを設定
3.パイプラインコンポーネントの名前を設定し、トレーニングと推論のインスタンスタイプと数を指定
4.パイプラインパラメータを指定
ステップ 3: パイプラインコンポーネントの構築
データ処理、トレーニング、評価、条件、モデル作成、バイアスチェック、説明可能性、登録、デプロイの各ステップを組み合わせたSageMakerパイプラインがあり、S3からのデータ取得やモデル評価などのタスクを実施し、最終的にSageMaker Model Registryにモデルを登録し、AWS Lambdaを用いてSageMaker Real-Time Inferenceエンドポイントにデプロイします。
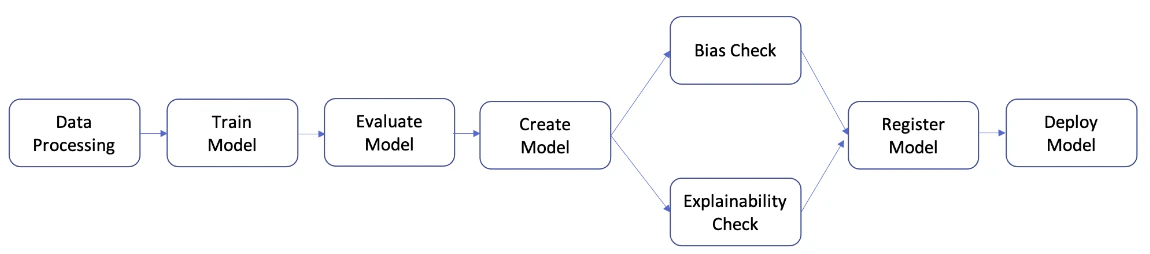
1.データ処理ステップ: S3 にある入力生データを使用して SageMaker Processing ジョブを実行し、S3 にトレーニング、検証、およびテストの分割を出力します。
2.トレーニングステップ: S3 内のトレーニングデータと検証データを入力として、SageMaker のトレーニングジョブを使用して XGBoost モデルをトレーニングし、トレーニング済みのモデルアーティファクトを S3 に保存します。
3.評価ステップ: テストデータと S3 内のモデルアーティファクトを入力として SageMaker Processing ジョブを実行してテストデータセット上でモデルを評価し、出力されたモデルパフォーマンス評価レポートを S3 に保存します。
4.条件ステップ: テストデータセットでのモデルパフォーマンスを閾値と比較します。S3 内のモデルパフォーマンス評価レポートを入力として使用し、SageMaker Pipelines の定義済みステップを実行し、モデルパフォーマンスが許容できる場合に実行されるパイプラインステップの出力リストを保存します。
5.モデルステップを作成する: S3 にあるモデルアーティファクトを入力として使用し、SageMaker Pipelines の定義済みステップを実行し、出力された SageMaker モデルを S3 に保存します。
6.バイアスチェックのステップ: S3 にあるトレーニングデータとモデルアーティファクトを入力として SageMaker Clarify を使用してモデルのバイアスをチェックし、モデルのバイアスレポートとベースラインメトリクスを S3 に保存します。
7.モデル説明可能性ステップ: S3 内のトレーニングデータとモデルアーティファクトを入力として SageMaker Clarify を実行し、モデル説明可能性レポートとベースラインメトリクスを S3 に保存します。
8.登録ステップ: モデル、バイアス、説明可能性のベースラインメトリクスを入力として使用し、SageMaker Pipelines の定義済みステップを実行し、SageMaker Model Registry にモデルを登録します。
9.デプロイステップ: AWS Lambda ハンドラー関数、モデル、エンドポイント設定を入力として使用し、SageMaker Pipelines の定義済みステップを実行し、モデルを SageMaker Real-Time Inference のエンドポイントにデプロイします。
ステップ 4: パイプラインの構築と実行
機械学習パイプラインは、機械学習モデルの構築、トレーニング、評価、デプロイメントなどの一連のプロセスを組み合わせたフレームワークです。これは、データの収集からモデルの運用までの全体的な流れを体系的に組織し、自動化することを目的としています。
1.パイプラインを設定
2.パイプライン作成
3.パイプラインメニューを表示
4.作成したパイプラインステップを表示
5.パイプラインを実行
6.パイプラインの実行を表示
7.すべてのステップが正常に実行される
8.モデルの登録確認
9.モデル説明可能性レポートの確認
1.パイプラインを設定

2.パイプライン作成
3.パイプラインメニューを表示
4.作成したパイプラインステップを表示
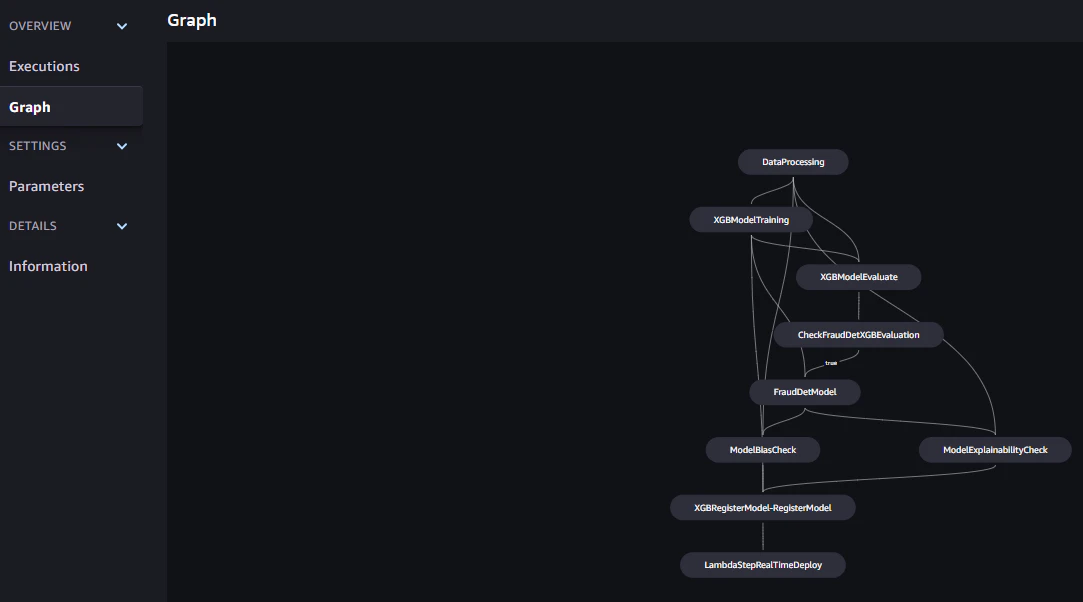
5.パイプラインを実行
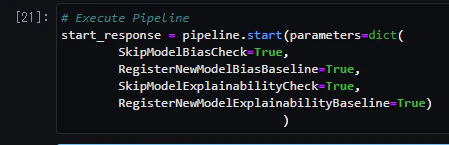
6.パイプラインの実行を表示
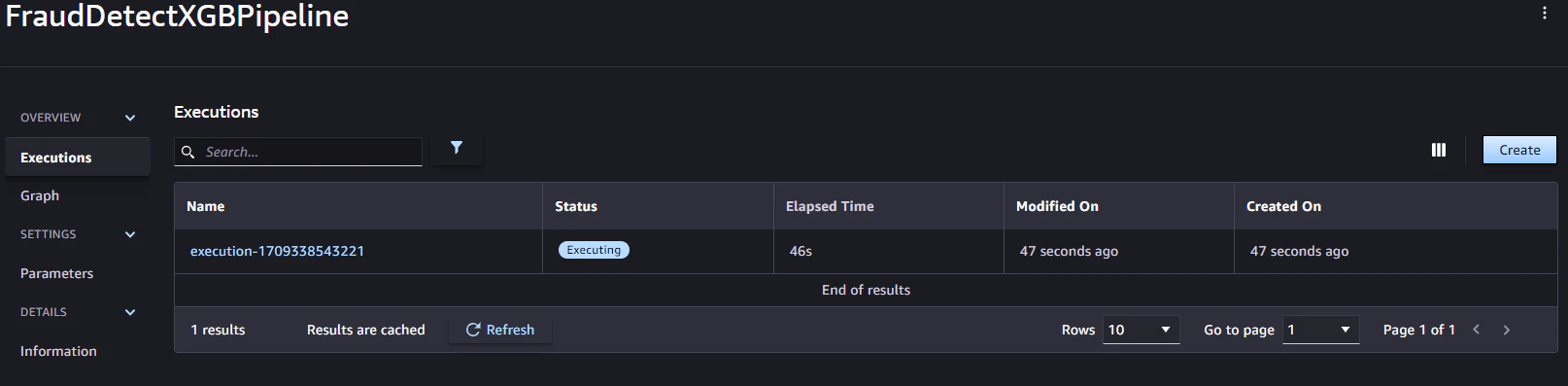
7.すべてのステップが正常に実行される
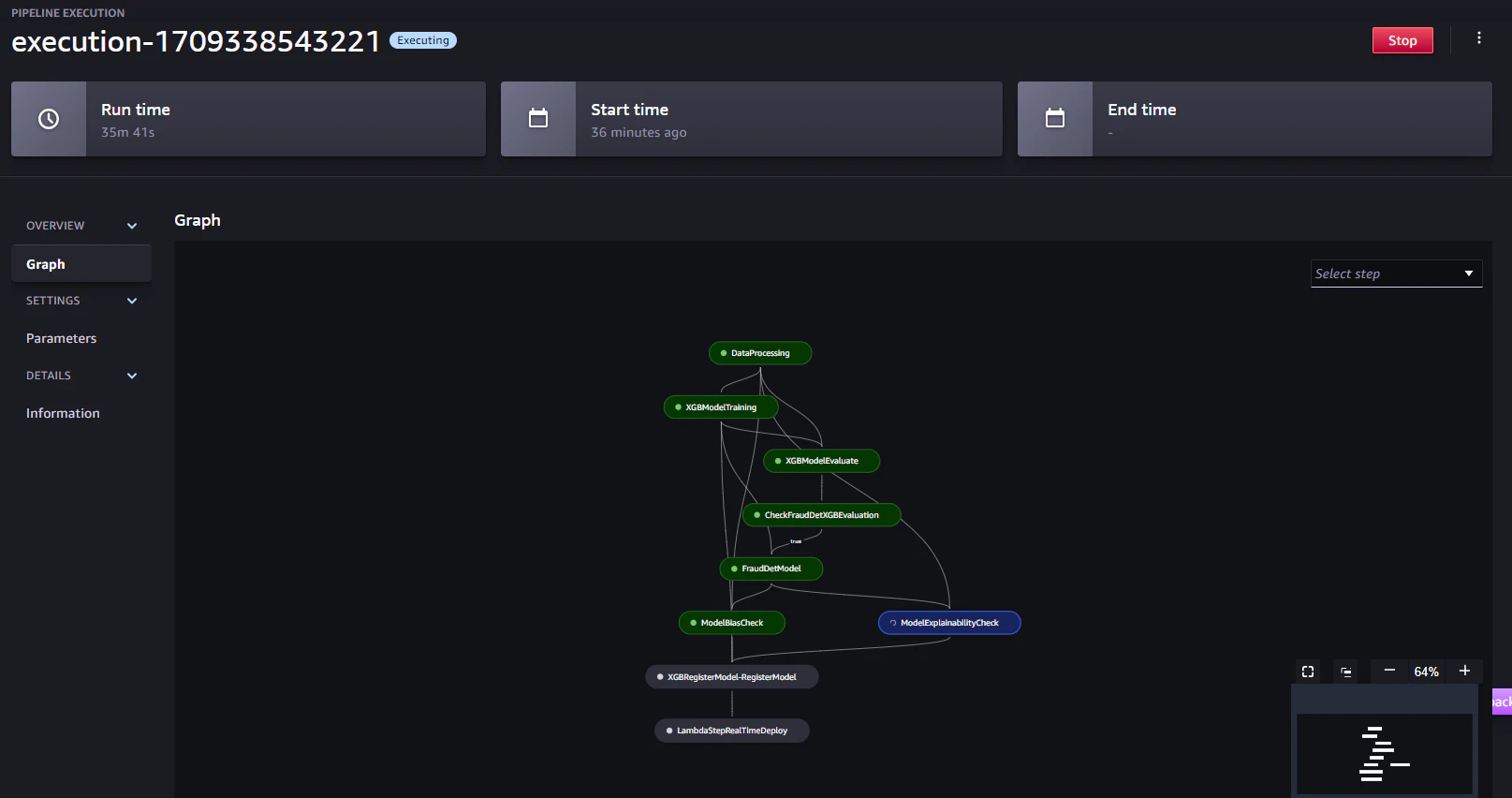

8.モデルの登録確認
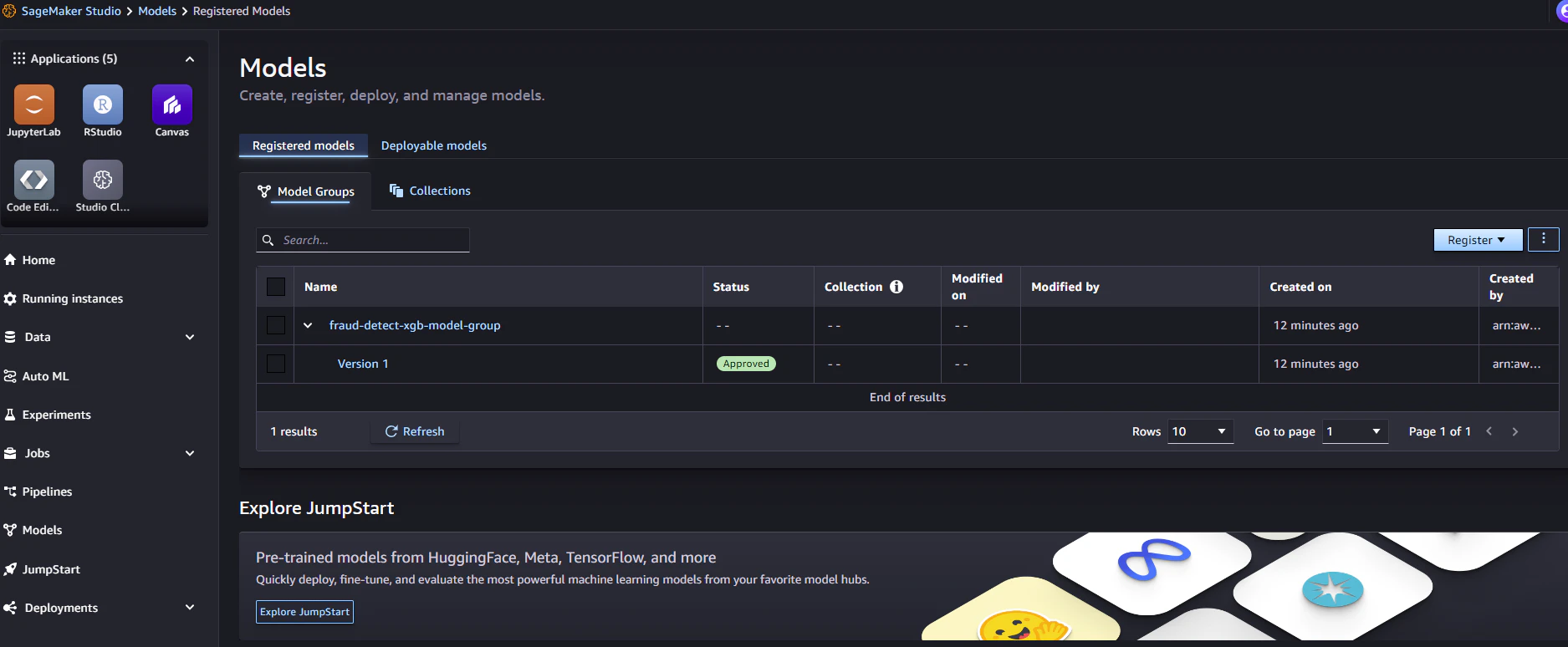
9.モデル説明可能性レポートの確認
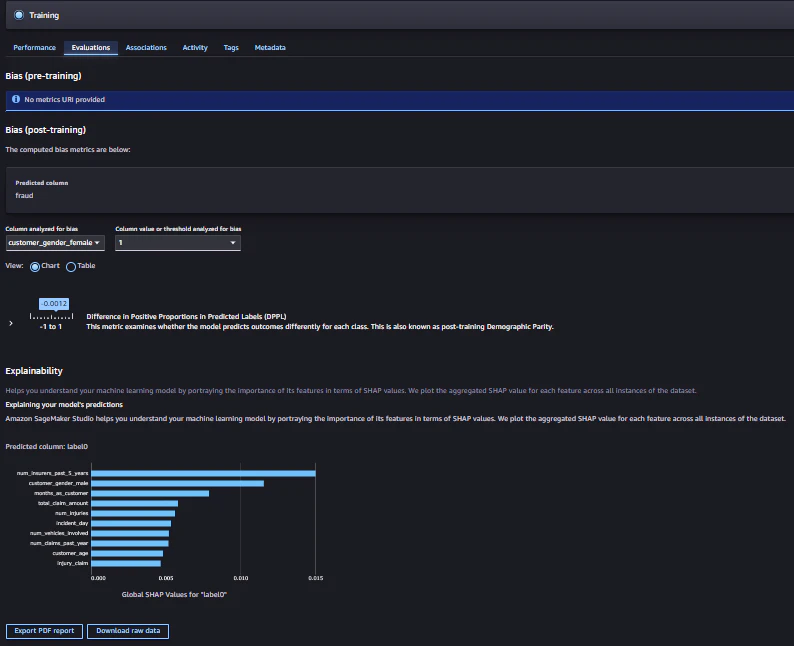
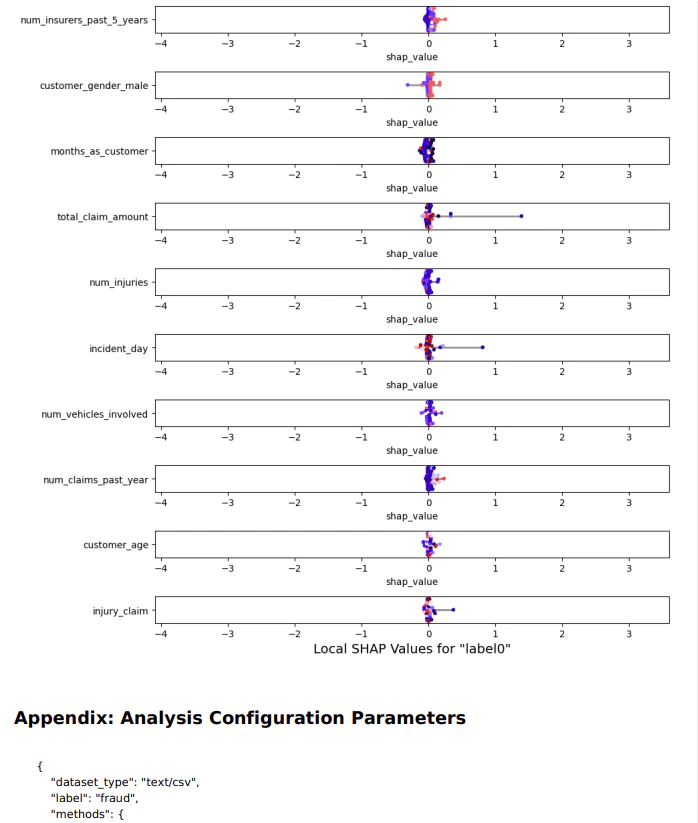
レポートをダウンロードする事も出来る1/2

レポートをダウンロードする事も出来る2/2
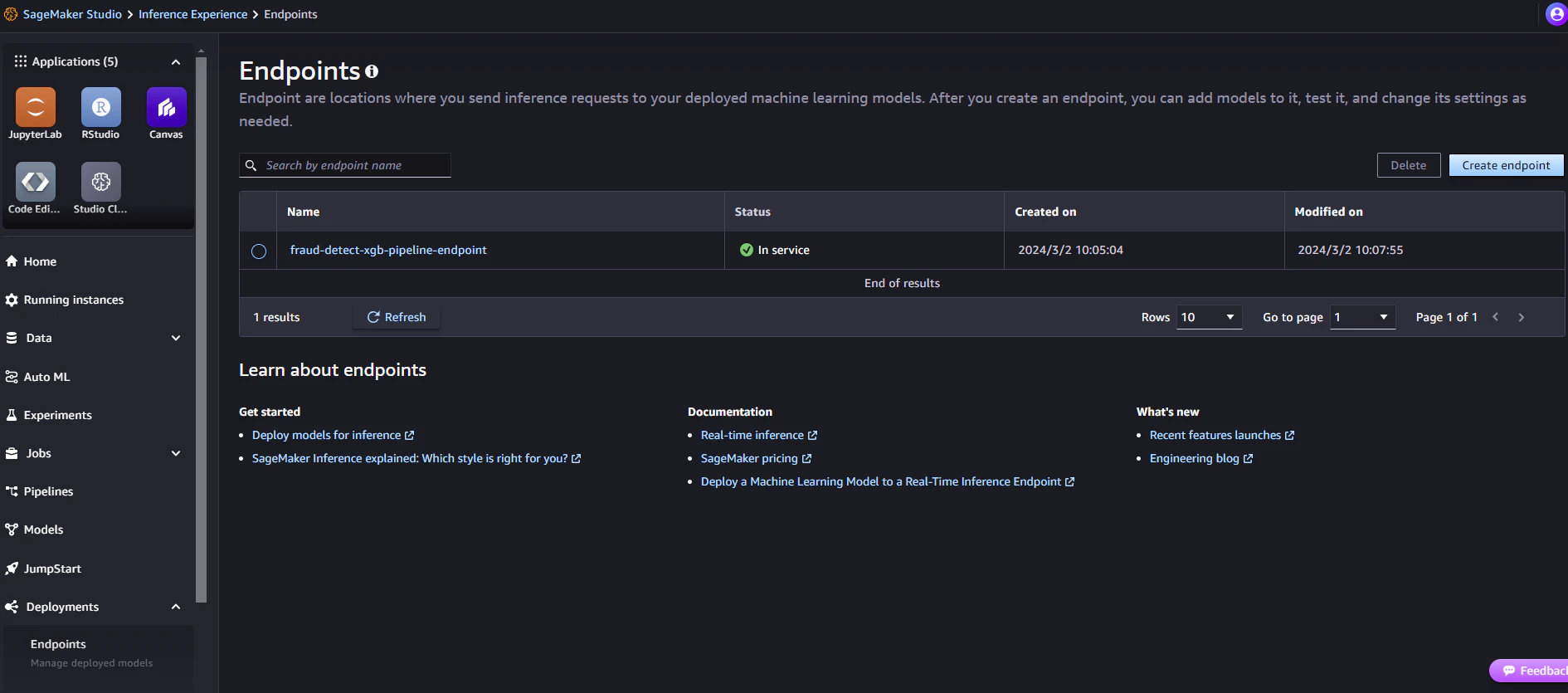
ステップ 5: エンドポイントを呼び出してパイプラインをテストする
1.エンドポイントのステータスを確認する
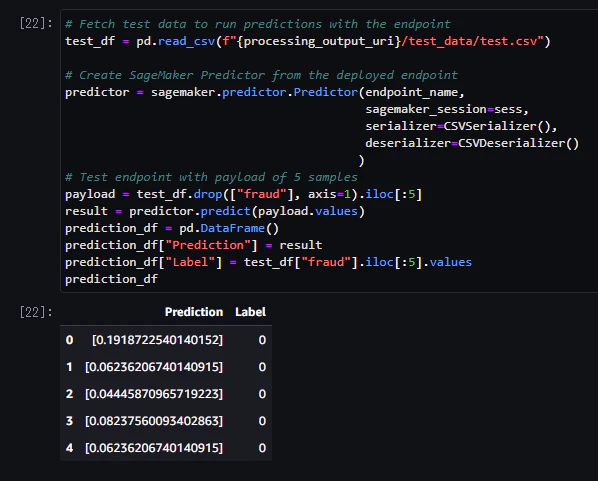
2.推論を実行し、モデル予測値を確認する
1.エンドポイントのステータスを確認する
2.推論を実行し、モデル予測値を確認する
・・・という流れをなぞれば、「機械学習ワークフローを自動化する」 チュートリアルをもとに機械学習 (CI/CD)を誰でも出来ますので、試してみて下さい。
一部修正のポイント
※実行ロール作成後、下記の修正が必要です。
信頼関係の修正
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "sagemaker.amazonaws.com"
},
"Action": "sts:AssumeRole"
},
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
ポリシーの修正
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket",
"iam:PassRole",
"lambda:CreateFunction"
],
"Resource": [
"arn:aws:s3:::*",
"arn:aws:iam::アカウント ID:role/*",
"arn:aws:lambda:us-east-1:アカウント ID:*"
]
}
]
}
リソースを削除する場合は、こちらの修正も必要
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"lambda:DeleteFunction"
],
"Resource": "arn:aws:lambda:us-east-1:アカウント ID:*"
}
]
}
以上、読んでいただいてありがとうございました。