顧客離れの予測 AWS SageMaker CLI版(1/2)
https://qiita.com/kimuni-i/items/57a79ef7091702ac15c5
を補完する形で、GUI版を作成しました。
今回は、SageMaker Data Wranglerを使えば、難しい前処理を初心者でも理解しながら進める事が出来る事をご紹介致します。
機械学習で必要な前処理とは?
前処理の一般的な手順
データの理解 データの内容、データ形式、データの統計量などを理解する
データクレンジング データに含まれるノイズや不正確なデータを修正・削除する
データの標準化 異なるスケールのデータを同じスケールに変換する
エンコーディング カテゴリカルデータを数値に変換する
次元削減 データの次元数を減らす
1. データクレンジング
データクレンジングは、データに含まれるノイズや不正確なデータを修正・削除する処理です。
欠損値の処理 欠損値を補完したり、欠損値を含むデータを削除する
外れ値の処理 外れ値を修正したり、外れ値を含むデータを削除する
ノイズの除去 データに含まれるノイズを除去する
データ形式の統一 データ形式を統一する
2. データの標準化
データの標準化は、異なるスケールのデータを同じスケールに変換する処理です。
最小最大値スケーリング データの最小値と最大値を用いて、データを0から1の範囲に変換する
標準化 データの平均値と標準偏差を用いて、データを平均値0、標準偏差1に変換する
3. エンコーディング
エンコーディングは、カテゴリカルデータを数値に変換する処理です。
ラベルエンコーディング 各カテゴリにユニークな整数値を割り当てる
ワンホットエンコーディング 各カテゴリを0と1のベクトルに変換する
4. 次元削減
次元削減は、データの次元数を減らす処理です。
主成分分析 (PCA) データの主成分を抽出し、データの次元数を減らす
線形判別分析 (LDA) クラス間の識別能力を高めるように、データの次元数を減らす
これらの前処理を行うことで、機械学習モデルの精度を向上させることができます。
前処理の重要性
前処理は、機械学習モデルの精度を向上させるために非常に重要なステップです。データにノイズや不正確なデータが含まれている場合、機械学習モデルは誤った学習をしてしまう可能性があります。
前処理を行うことで、データの品質を向上させ、機械学習モデルが正確な学習を行うことができるようにすることができます。
前処理は、機械学習モデルの精度を向上させるために非常に重要なステップです。データの種類や機械学習モデルによって、必要な前処理は異なりますが、一般的にはデータクレンジング、データの標準化、エンコーディング、次元削減などの処理を行います。
前処理を効率的に行うために、AWSマネージドツールを使用することができます。
SageMaker Data Wranglerを使うと、GUIで前処理を行う事が出来ます
大まかな手順
1.データセットchurn.csvをダウンロードします。
2.データセットを S3 にロードします。
3.Data Wrangler を起動します。
4.データセットを Amazon S3 から Data Wrangler フローにインポートします。
5.レポートを作成し、必要な特徴エンジニアリングに関する結論を導き出します。
6.Data Wrangler で必要なデータ変換を実行します。
7.データ品質および分析レポートと変換されたデータセットをダウンロードします。
8.モデルのトレーニングのためにデータを Studio Lab プロジェクトにアップロードします。
Data Wranglerを起動します
前処理を行いたいデータを用意します
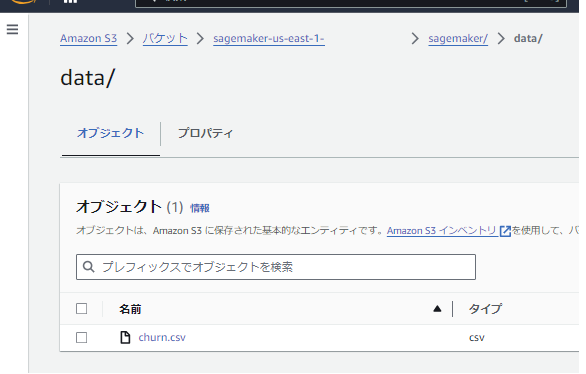
S3からデータを読み込みます
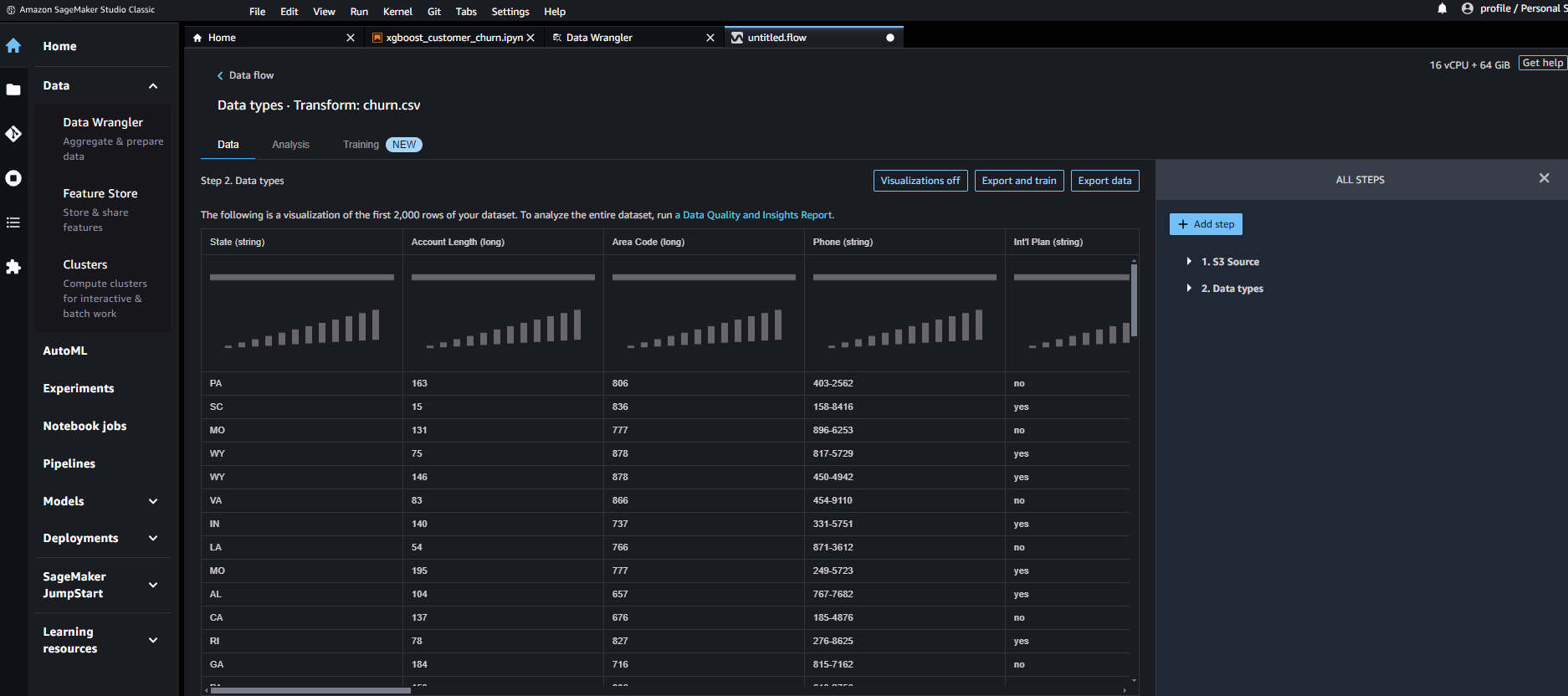
データの読み込み
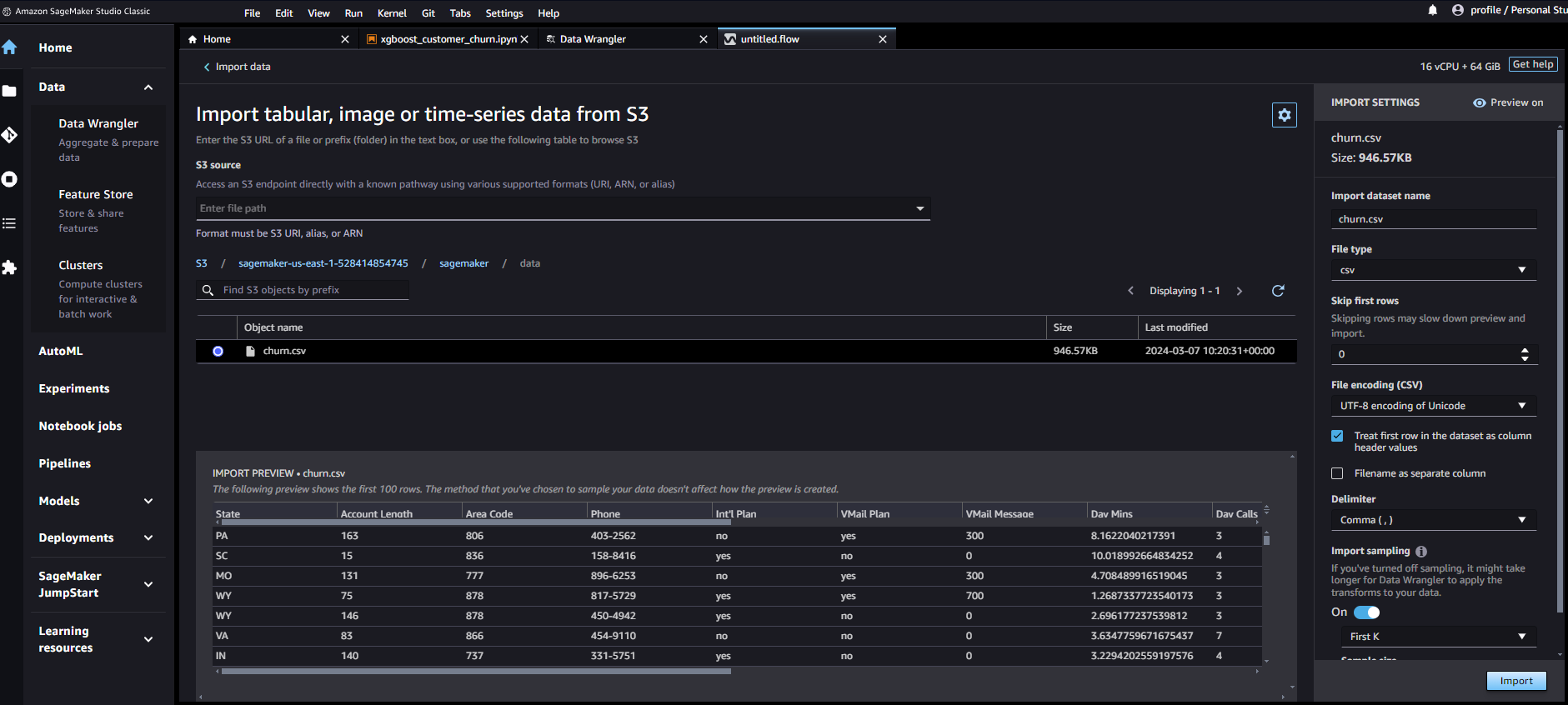
インポート後
Get Data inshitsで、確認します
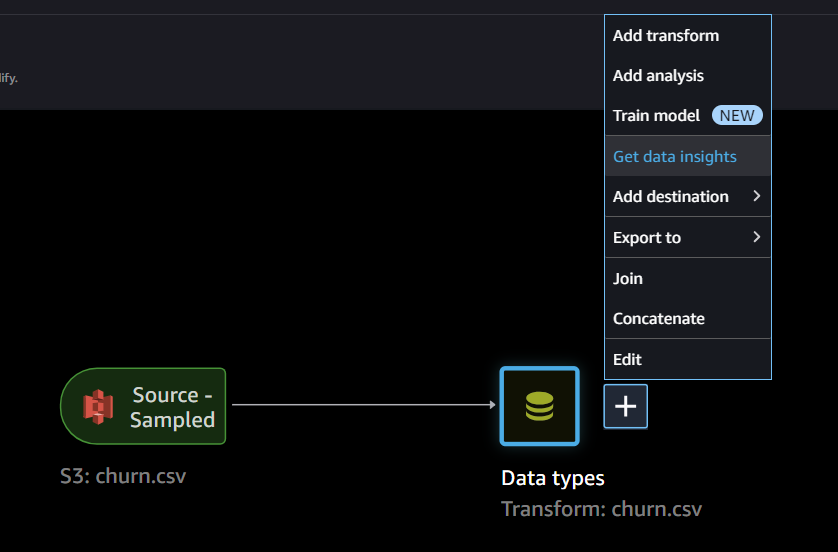
インサイトの作成
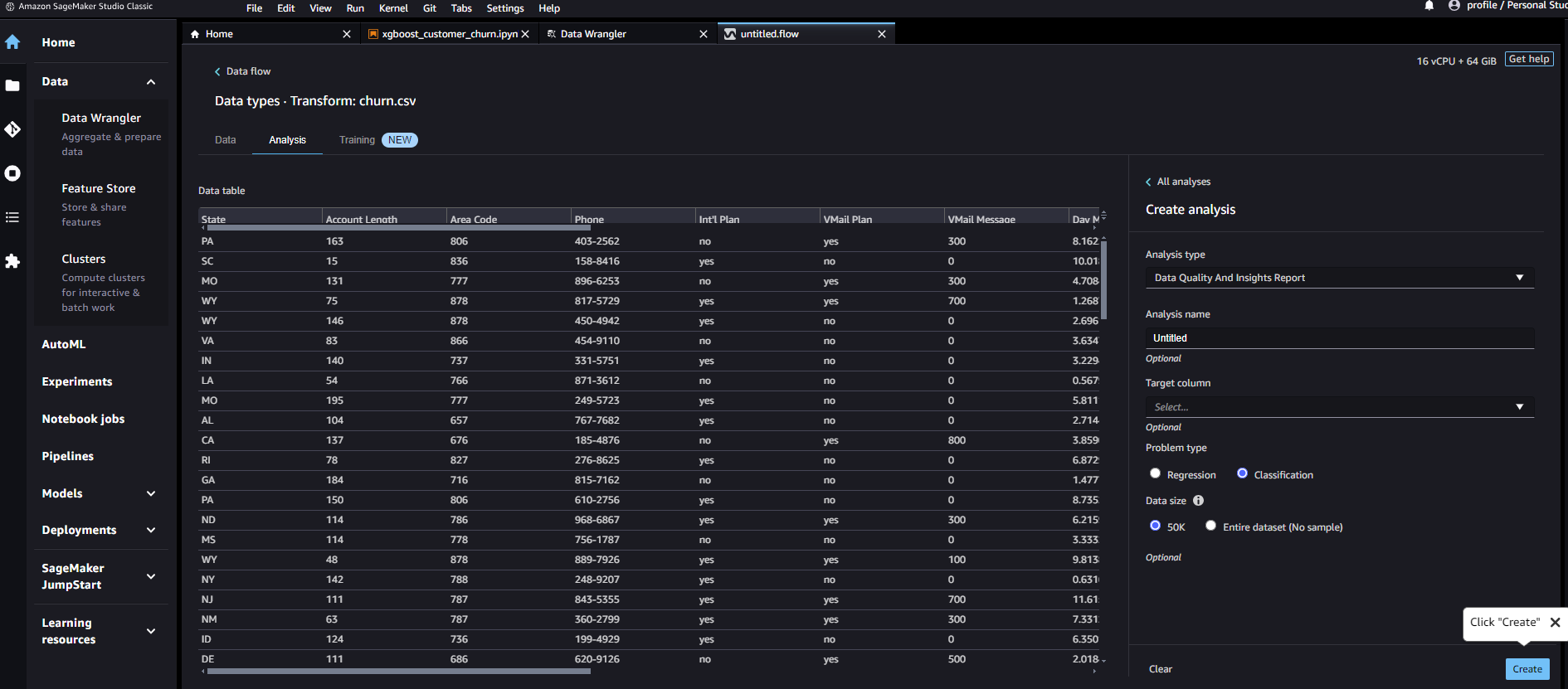
レポート作成
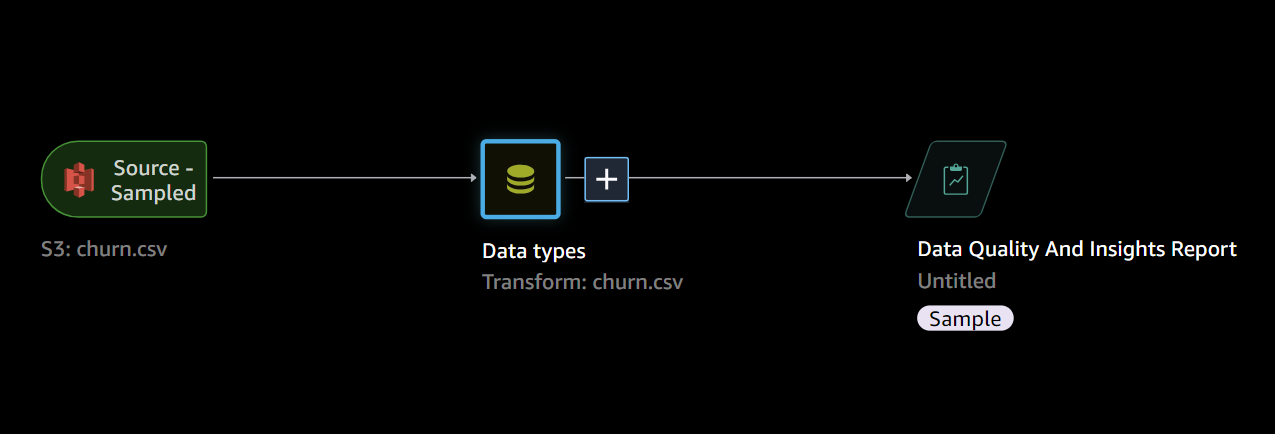
作成されたレポート
このレポートを使用すると、データをクリーンアップして処理するために何をする必要があるかを理解できます。欠損値の数や外れ値の数などの情報を確認出来ます。ターゲットの漏洩や不均衡などの問題を確認する事が出来ます。
このレポートから、次のことがわかります
・重複する行は見つかりませんでした。
・このState列は非常に均等に分布しているように見えるため、州の人口に関してデータのバランスが取れています。
・Phone 列には、実際には使用できないほど多くの一意の値が表示されます。一意の値が多すぎると、この列は役に立たなくなります。変換では Phone 列を削除できます。
・レポートの機能相関セクションに基づくと、MinsとChargeは高度に相関しています。そのうちの 1 つを削除できます。

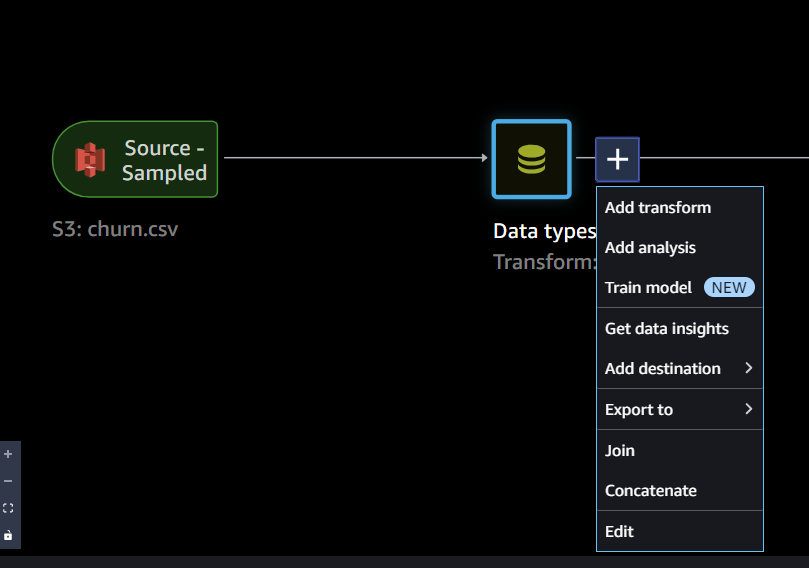
レポート結果をもとに、GUIで前処理を行うことができます
Add transformでデータ加工を選択します
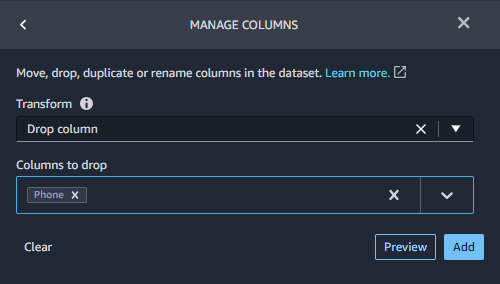
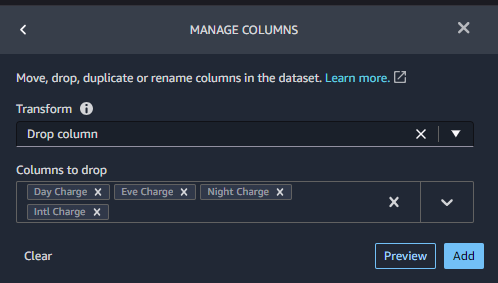
MANAGE COLUMNSで列の削除 Drop columnを行います
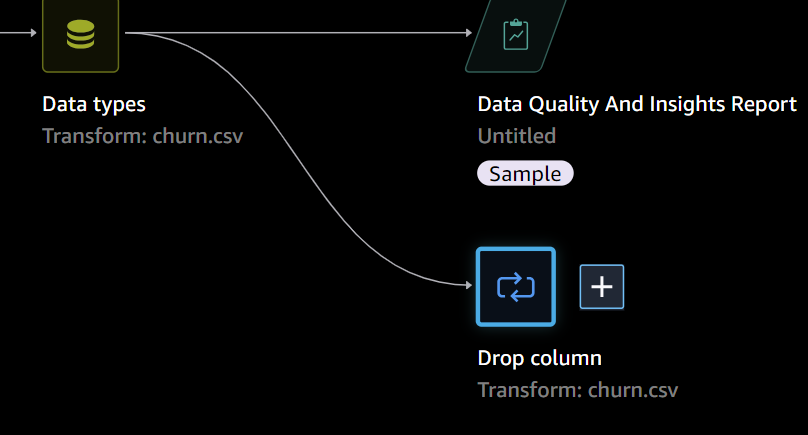
分析を継続し、他に削除する列があれば、MANAGE COLUMNSで列の削除 Drop columnを行います
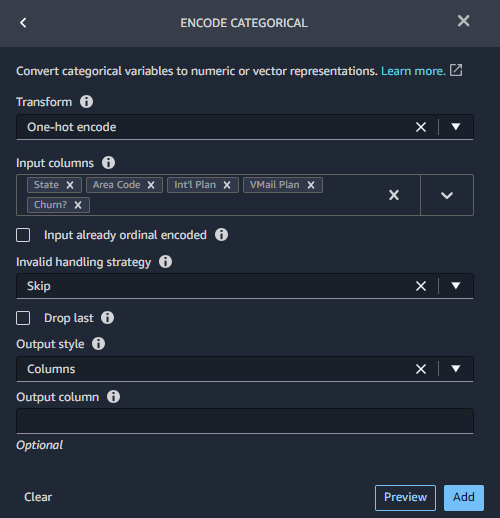
カテゴリ列をエンコードするため、ENCODE CATEGORICALで、One-hot encode
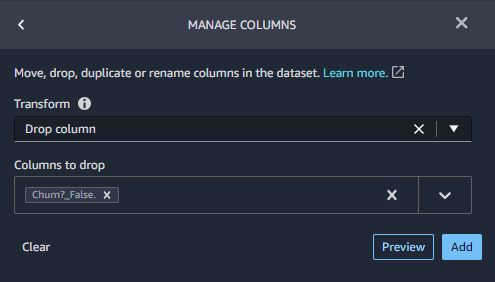
MANAGE COLUMNSで列の削除 Drop columnを行います
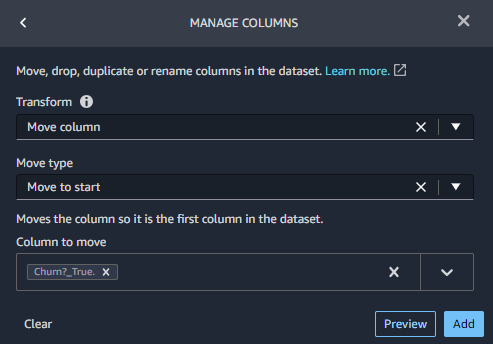
MANAGE COLUMNSで移動したい列として、最初の列を選択し、Move columnを行います
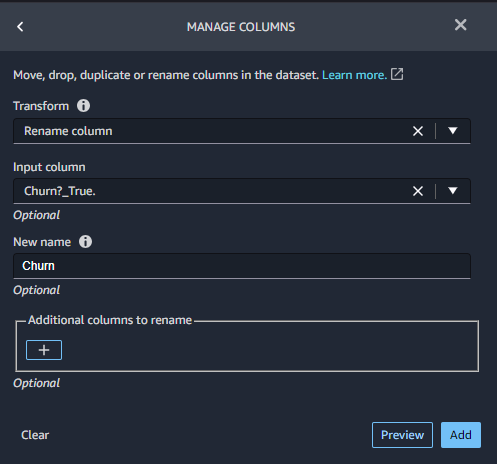
MANAGE COLUMNSで変形したい型として、Rename columnを選択し、変更したい列を選び列名の変更を行います
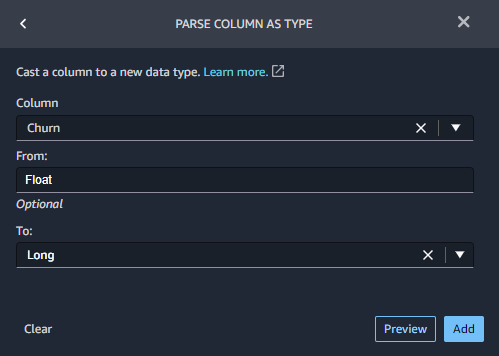
PARSE COLUMN AS TYPEで、Float型からLong型に変更します
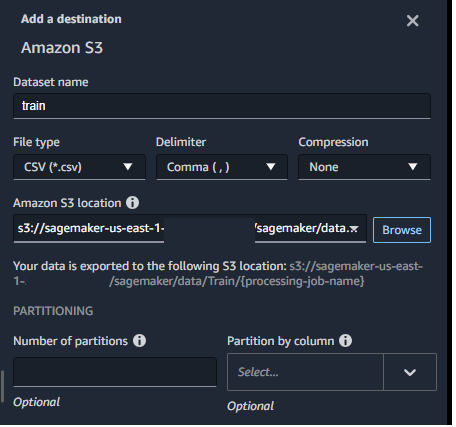
S3を指定します
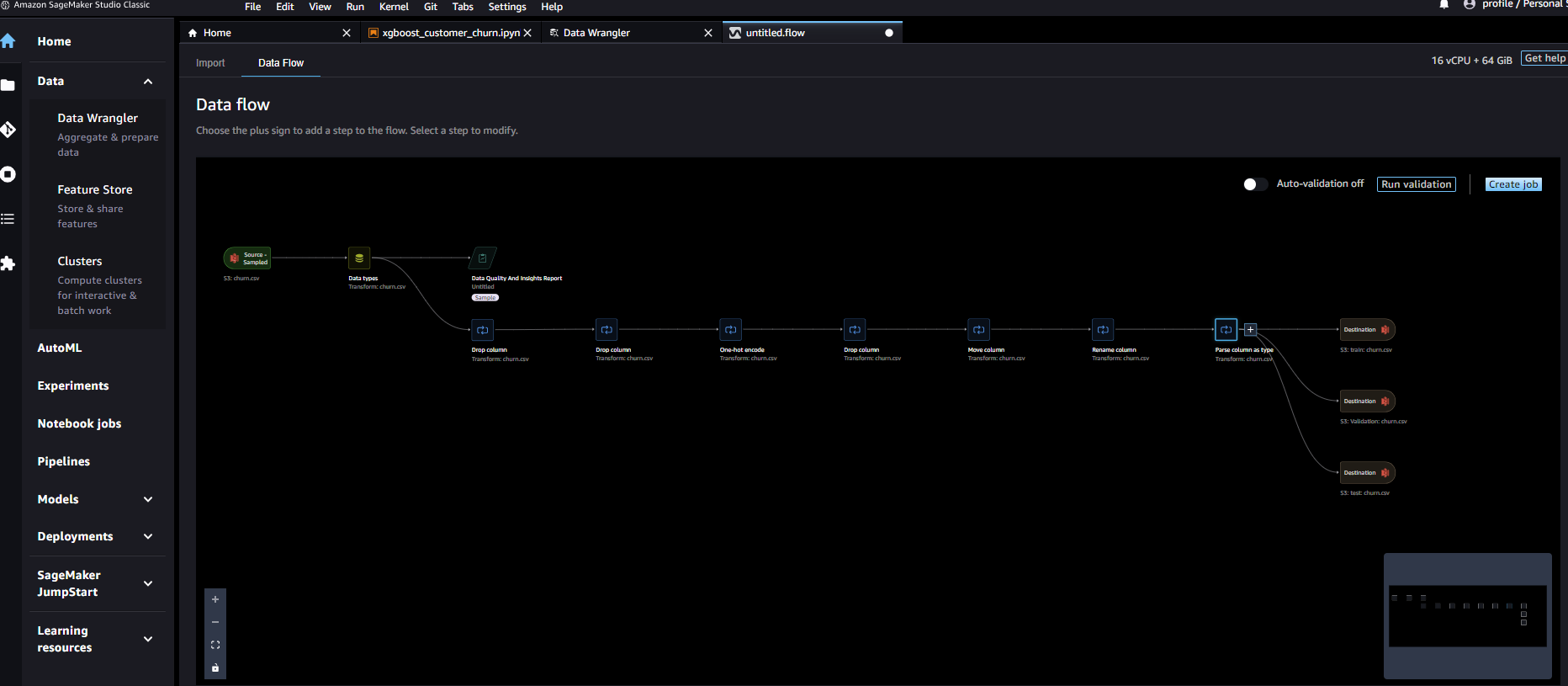
一通り作成が終わるとこのようになります
ジョブを実行します
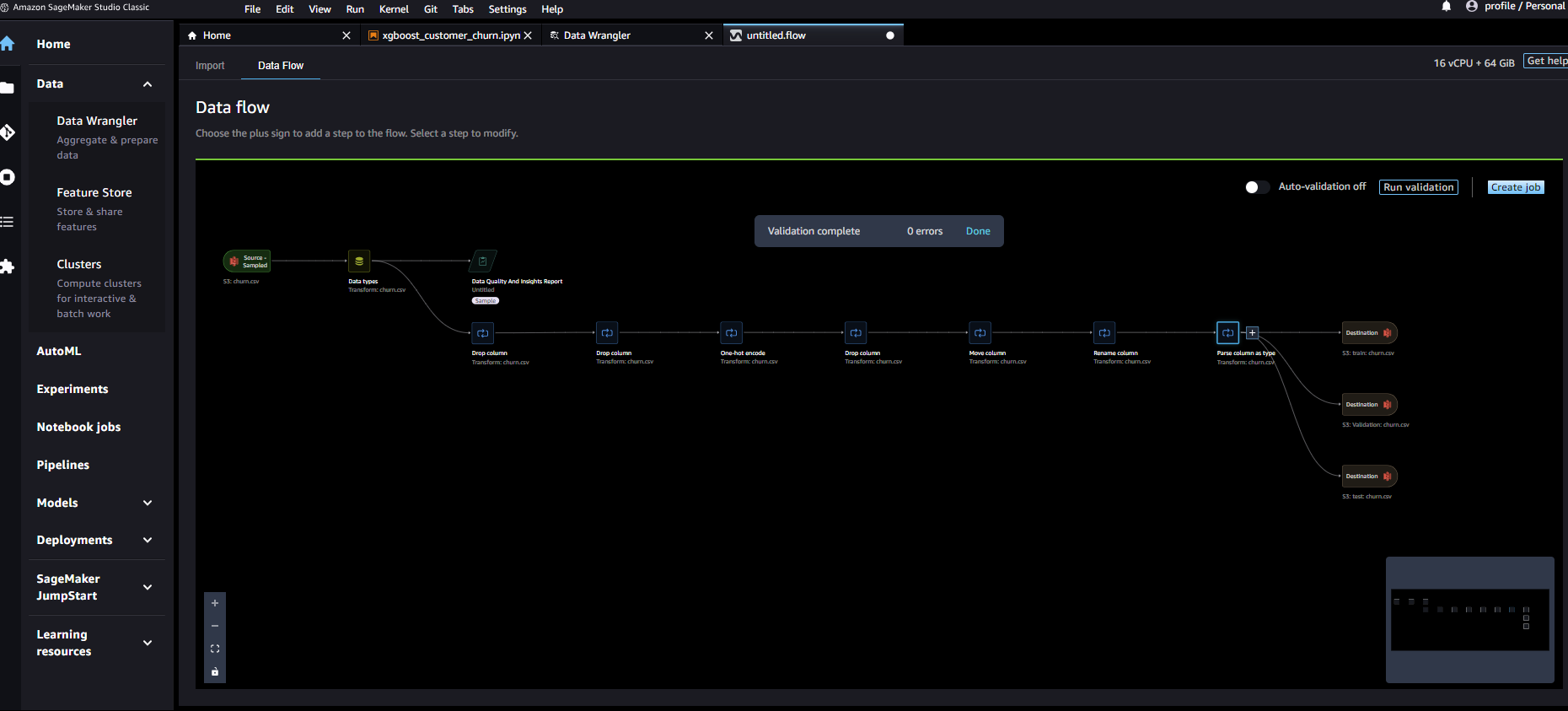
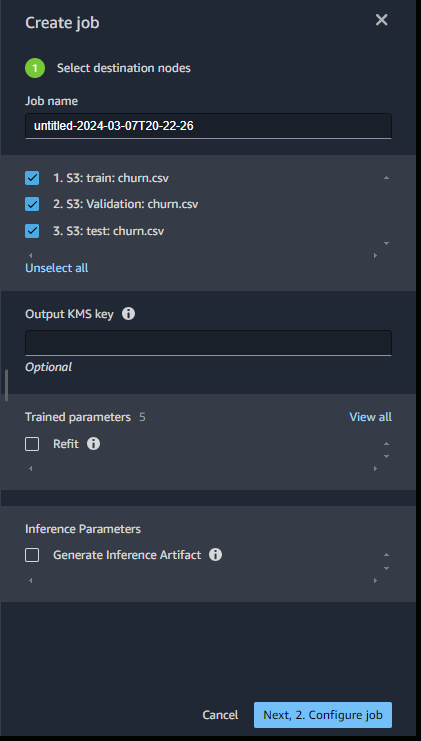
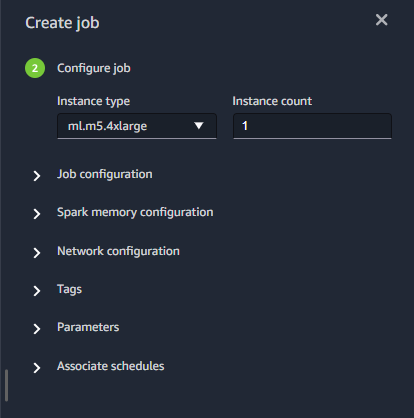
ジョブが成功した事を確認します
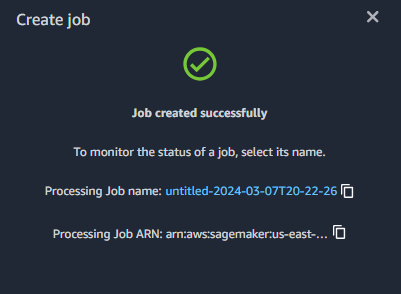
最後に、変換されたデータセットをダウンロードし、モデルのトレーニングのためにデータを Studio Lab プロジェクトにアップロードします。