ごあいさつ
AWS管理者の皆さま、こんにちは。
世の中、AWSエンジニアは数あれど、なかなかマネジメントについて書かれた記事はありません。
特にTrailに関しては集めると良いとはよく書かれていますが「それからどした?」の部分の解決が見つからないことが多いです。
** 今回最終的にやりたいことは、自社所有AWSアカウントの全てのCloudTrail証跡ログを一つのアカウントにまとめて、QuickSightで分析してしまおうというものです。**
** 代表的なところで、IAMユーザーの作成や、ポリシーアタッチが検出できるようになるのが目標になります。**
しかし、ご存知のように、TrailLogというものはJSONで記載されていますから、そのままではQuickSightに取り込めません。
そのため、実に長大な作業を踏むことになります。
今回やる作業
Trail証跡ログの集約→AWS glueでathenaが理解できる形に→QuickSight取込→分析
こうやって書くと短いですが、何もない状態から私がこれを作り上げるまで一か月くらいかかってます。
AWSサポートへの問合せ期間も含めてですが。
こんなやり方も
ちなみに下記のような公式ブログでのやり方も乗っています。
AWS Cloudtrail Logs を AWS Glue と Amazon Quicksight 使って可視化する
しかし、このブログのやり方を実装しようとすると、Trailログの発行API部分が入れ子構造になっており、glueジョブが全てのログを確認するまでDB構造を理解できず、結果タイムアウトで終了してしまいます。
ですので、今回のやり方は若干不便ですが実装が速く、確実なやり方です。
【各アカウントからCloudTrailの証跡を、一つのアカウントのS3に集約する】
作業は二つです。
・受け入れ側S3バケットの設定
・送り側Trailでの証跡作成
●受け入れ側S3バケットの設定
バケットを作成します。
バケット名は後ほどの設定で嫌というほど使いますので、使いやすい方が良いと思います。
また、証跡を集めるのですから、削除ができる環境は避けたいところです。
バージョニングを有効化し、オブジェクトのロックも完全に有効化しておきましょう。
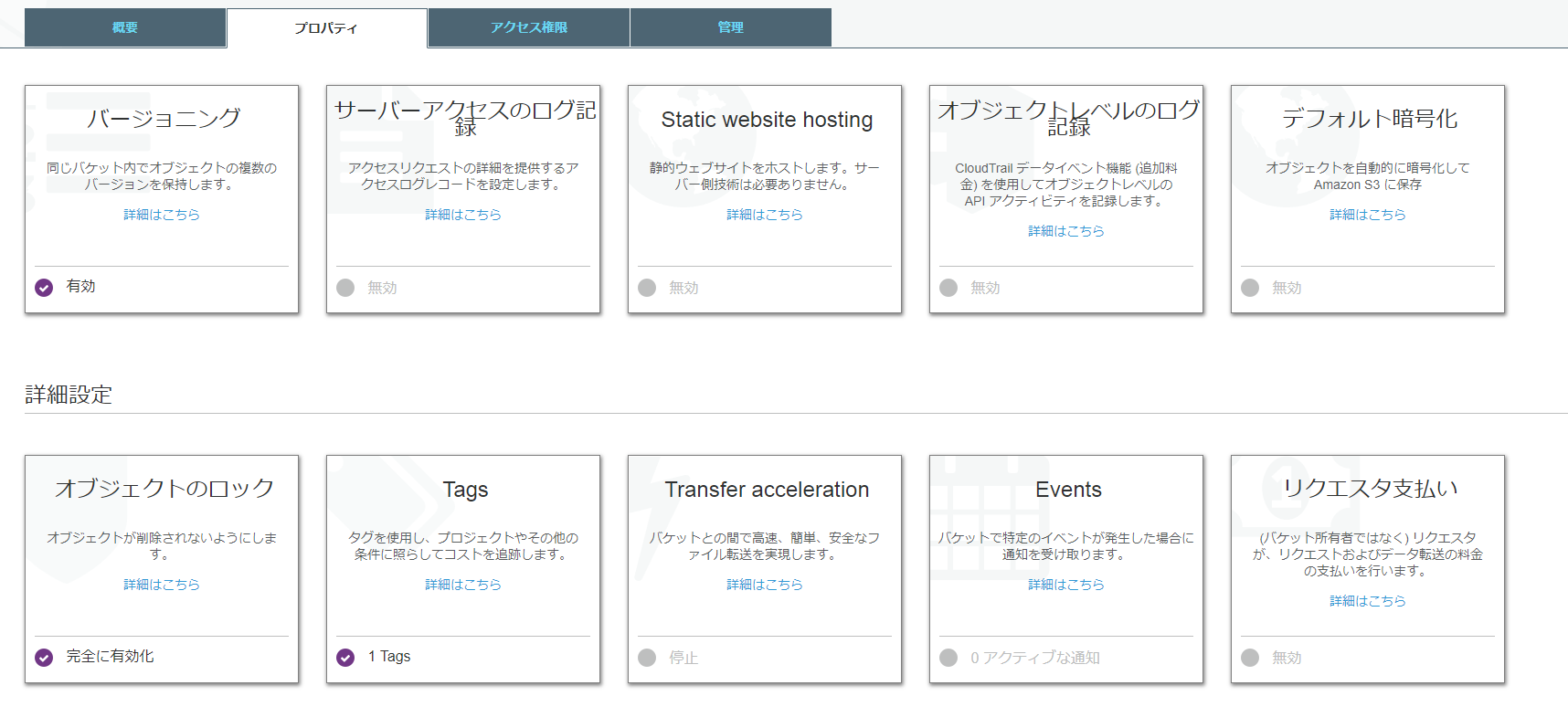
パブリックアクセスコントロールについても全てオンにしておいて問題ありません。

最後にバケットポリシーです。
下記のようなものを用意しましょう。
※注:xxx部分には自分のアカウントIDやバケット名を入れてください。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AWSCloudTrailAclCheck20150319",
"Effect": "Allow",
"Principal": {
"Service": "cloudtrail.amazonaws.com"
},
"Action": "s3:GetBucketAcl",
"Resource": "arn:aws:s3:::xx-xx-account-traillog-xxx"
},
{
"Sid": "AWSCloudTrailAclCheck20150222",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::xxxxxxxxxxx:root"
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::xx-xx-account-traillog-xxx",
"arn:aws:s3:::xx-xx-account-traillog-xxx/*"
]
},
{
"Sid": "AWSCloudTrailWrite20150319",
"Effect": "Allow",
"Principal": {
"Service": "cloudtrail.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": [
"arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/76xxxxxxxxxx/*",
"arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/77xxxxxxxxxx/*",
"arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/22xxxxxxxxxx/*",
"arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/24xxxxxxxxxx/*",
"arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/06xxxxxxxxxx/*",
"arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/62xxxxxxxxxx/*",
"arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/08xxxxxxxxxx/*",
"arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/66xxxxxxxxxx/*",
"arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/68xxxxxxxxxx/*",
"arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/01xxxxxxxxxx/*",
"arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/06xxxxxxxxxx/*",
"arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/55xxxxxxxxxx/*"
],
"Condition": {
"StringEquals": {
"s3:x-amz-acl": "bucket-owner-full-control"
}
}
}
]
}
●送り側Trailでの証跡作成
各アカウントで、Trailを開きます。
「証跡情報」から「証跡の作成」をクリックします。
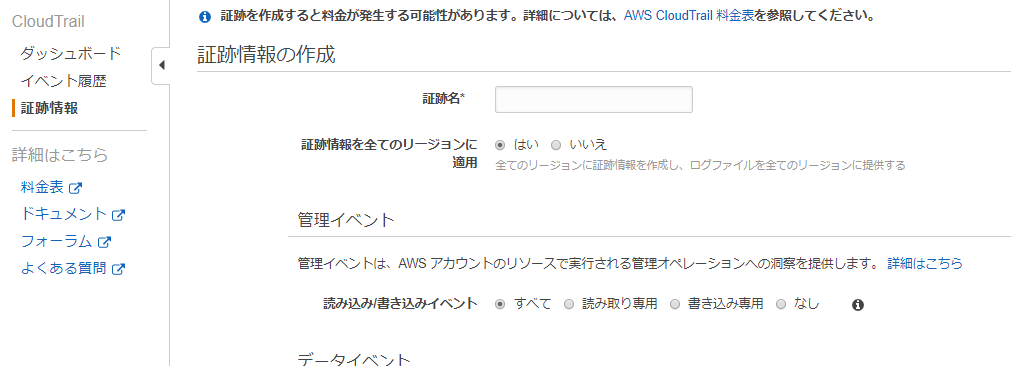
上部の必須項目を埋めた後に、「ストレージの場所」を埋めていきます。
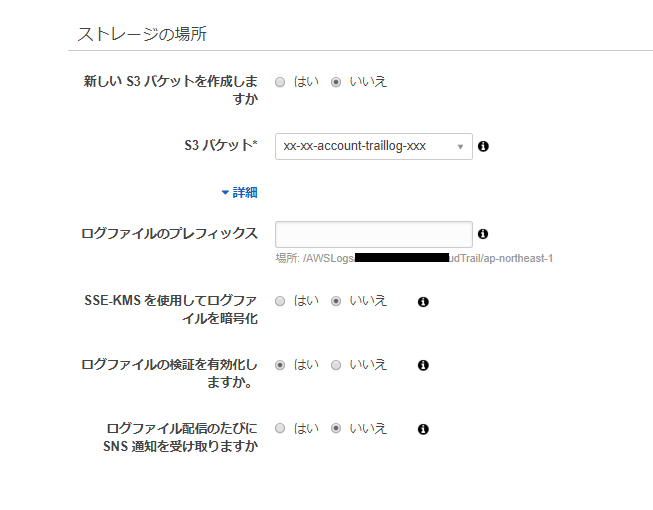
新しいS3バケットを作成しますか? → いいえ
S3バケット → 先ほど作成したバケット名を直接入力※
詳細から「ログのプレフィックス」 → 何でもよいですが、「/AWSLogs/AccountID/CloudTrail/ap-northeast-1」の部分は変えられません。
※AWSでは、S3のみアカウントの壁に守られていません。
バケット名を指定することで、相手が公開状態であればアクセス可能になります。
S3のバケット名がリージョン、アカウントを越えて一意でなくてはならない理由はここにあります。
この部分が、後ほどの作業の煩雑さに影響してきます。
その下の詳細項目についてはお好きな設定でどうぞ。
上記二つの設定を行うことで、しばらくしたらS3バケットにログが集まり始めます。
もし集まらないログがあれば、バケットポリシーか証跡のバケット指定が怪しいところです。
【集約したTrailログをAWS glue ETLジョブを使ってathenaでクエリ発行できるようにする】
公開されている、glueジョブからathenaDBを作成するスクリプトを実行します。
AWSログ解析Git
$ git clone https://github.com/awslabs/athena-glue-service-logs
今回利用するのは
./scripts/example_glue_jobs.json
./scripts/sample_cloudtrail_job.py
./athena_glue_service_logs/cloudtrail.py
./Makefile
で、これらの全てに手を加える必要があります。
●ファイルコピー
$ cp ./scripts/example_glue_jobs.json ./scripts/glue_jobs.json
サンプルファイルから実行ファイルを作成するためにコピーします。
●./scripts/glue_jobs.jsonを修正
修正箇所は下記の通りです。
・defaultsセクション
glueジョブで作成されるathenaデータベースの名称を決めます。
こだわりが無ければそのままで問題なしです。
・cloudtrail
ジョブ名とバケット名を修正します。
ジョブ名は複数アカウントのtrailを解析するのであれば、各アカウントごとに名称を分ける必要があります。
S3_SOURCE_LOCATIONについてはパスを省略させることはできず(glueジョブのパラメーターが正規表現に対応していないため)、Trailファイルのprefixまで指定する必要があります。
「S3_CONVERTED_TARGET」については、Trailを集約するバケットを指定して問題ないです。
●./scripts/sample_cloudtrail_job.pyは特に修正箇所無し
glueジョブのスクリプト実行部分。sampleというファイル名のままで問題ありません(MakeFile内で指定してあるため)。
●./athena_glue_service_logs/cloudtrail.pyを必要があれば修正
glueジョブからathenaDBを作成する際のテーブル構造を決定します。
必要があればTypeを修正します。修正しなくてもジョブは問題なく動きます。
json部分(json_requestparametersなど)についてはTrailのAPI内容によって入れ子構造が異なっており、ここを修正するとジョブが完了しなくなります。
●./Makefileの修正
RELEASE_BUCKETにスクリプトなどをアップするためのバケット名を記載します。
ここはTrailを集約したバケットで無く、別途専用のバケットを作った方が良いです。
このファイルのcreate_job部分がそのままでは上手く動きません。
--default-arguments部分の改行を無くし、ワンラインにすると手っ取り早く実行が可能になります。
--default-arguments '{ \
"--extra-py-files":"$(RELEASE_LATEST_PATH)", \
"--TempDir":"$(GLUE_TEMP_S3_LOCATION)", \
"--job-bookmark-option":"job-bookmark-enable", \
"--raw_database_name":"$(RAW_DATABASE_NAME)", \
"--raw_table_name":"$(RAW_TABLE_NAME)", \
"--converted_database_name":"$(CONVERTED_DATABASE_NAME)", \
"--converted_table_name":"$(CONVERTED_TABLE_NAME)", \
"--s3_converted_target":"$(S3_CONVERTED_TARGET)", \
"--s3_source_location":"$(S3_SOURCE_LOCATION)" \
}'
上記を下記のように変更します。
--default-arguments '{ "--extra-py-files":"$(RELEASE_LATEST_PATH)", "--TempDir":"$(GLUE_TEMP_S3_LOCATION)", "--job-bookmark-option":"job-bookmark-enable", "--raw_database_name":"$(RAW_DATABASE_NAME)","--raw_table_name":"$(RAW_TABLE_NAME)", "--converted_database_name":"$(CONVERTED_DATABASE_NAME)", "--converted_table_name":"$(CONVERTED_TABLE_NAME)","--s3_converted_target":"$(S3_CONVERTED_TARGET)","--s3_source_location":"$(S3_SOURCE_LOCATION)" }'
また、roleが必要になりますが、記述箇所は「create_job」の項目の--roleです。
--role AWSGlueServiceRoleDefault \
と、さもデフォルトでありますよ、的な雰囲気を出していますが、このロールは存在しません。
ロールを作成するときは、
・AWS管理ポリシーである「AWSGlueServiceRole」をアタッチ
・Trailログとglueジョブ作成ツールの両方で使用するバケットへのアクセス権限
s3:ListBucket
s3:GetObject
s3:PutObject
s3:DeleteObject
・ロールの信頼関係は「glue.amazonaws.com」に与えましょう
●ジョブ作成ツールの実行
ジョブの作成は、下記のコマンドを実行することで行われます。
必ずMakeFileのある場所で実行しましょう。
$ RELEASE_BUCKET=<YOUR_BUCKET_NAME> make private_release
$ RELEASE_BUCKET=<YOUR_BUCKET_NAME> make create_job service=<SERVICE_NAME>
ちなみに今回の場合、SERVICE_NAMEは「cloudtrail」になります。
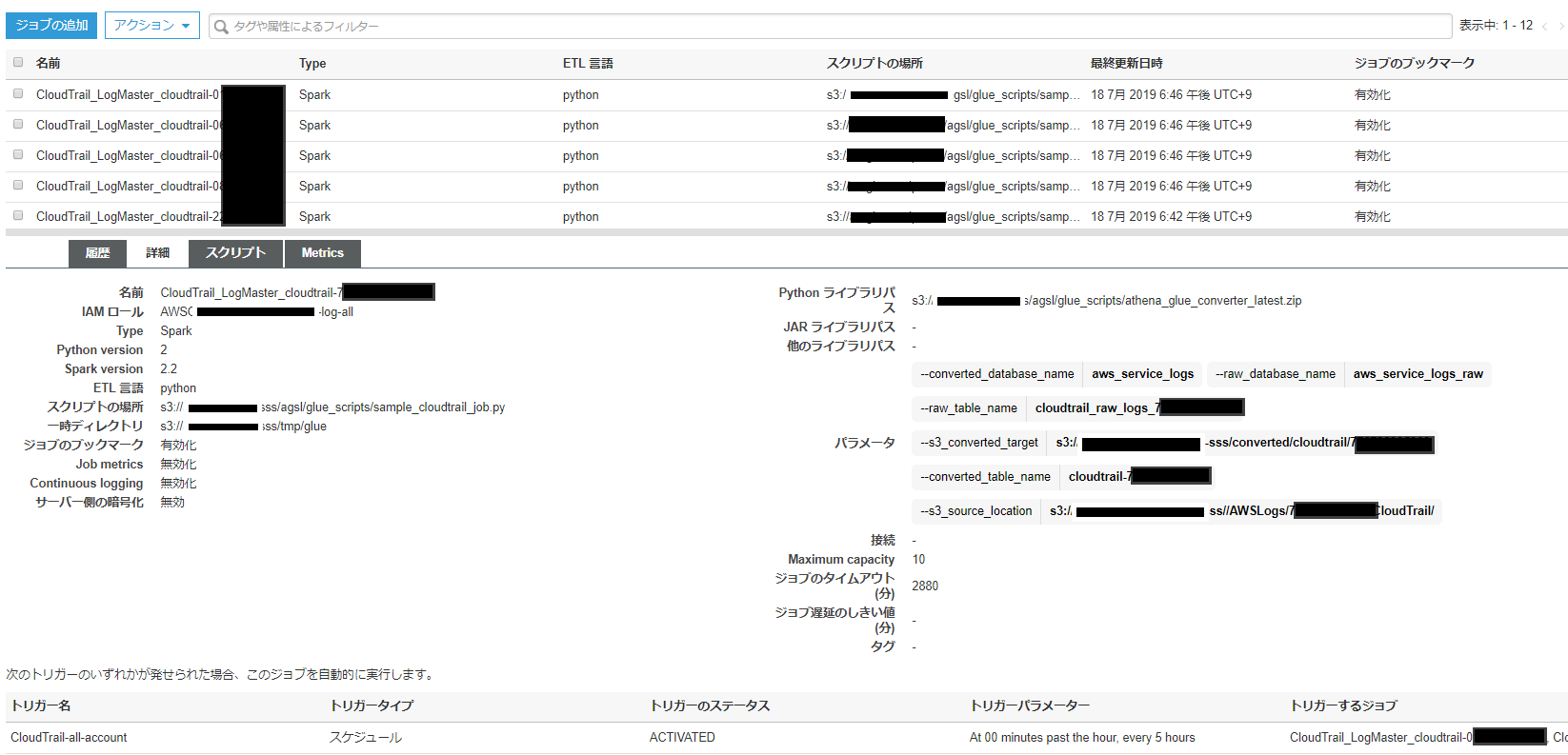
実行したら、ジョブができているか確認し、実行してみましょう。
上手くいっていれば数分でジョブが完了し、カタログデータが出来上がっているはずです。
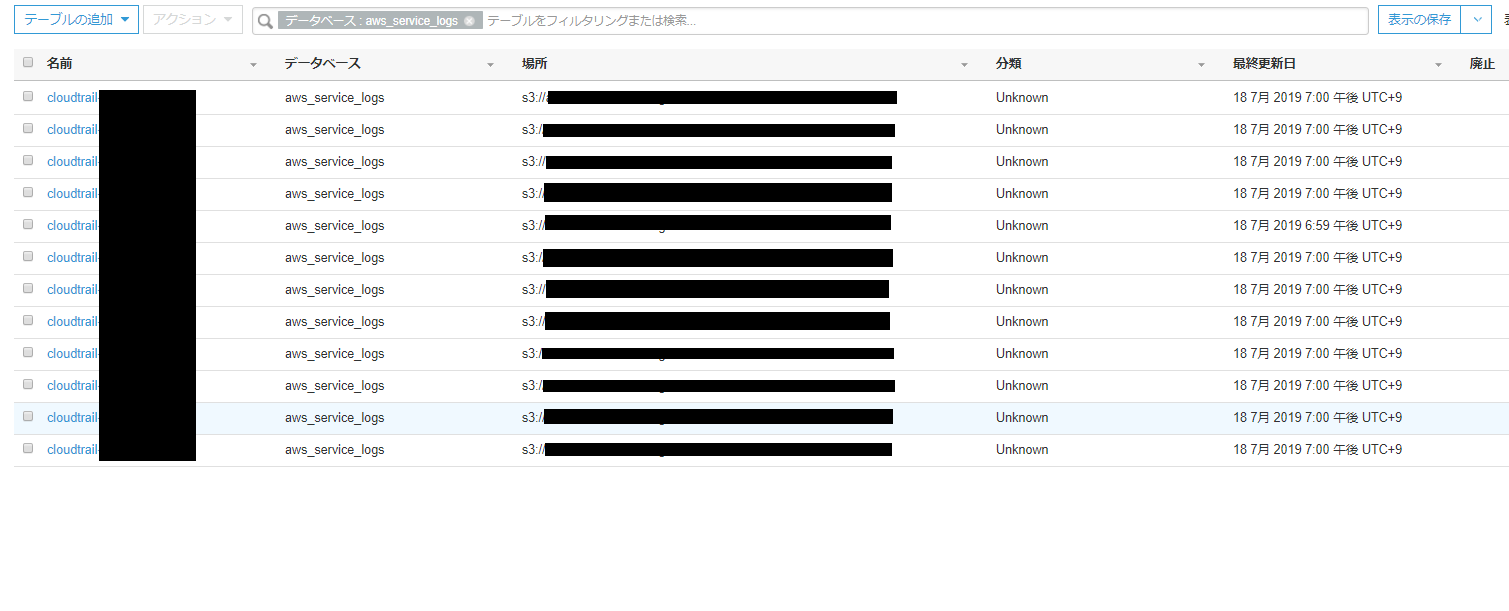
●全てのアカウントでジョブが成功したら、トリガーで定期実行する
ジョブは一度回しただけでは追加されていくTrailデータに対応できないため、トリガーを定期実行して常にカタログデータを更新する必要があります。
更新頻度はTrailログがどの程度最新でない状態を許容するかによります。
例えば、定期実行を5時間ごとにすれば、最大で5時間前までのデータしか見れないことになります。
一方でglueジョブを実行するにはそれなりの費用がかかるため、コストとセキュリティポリシーの兼ね合いで実行間隔を決めてください。
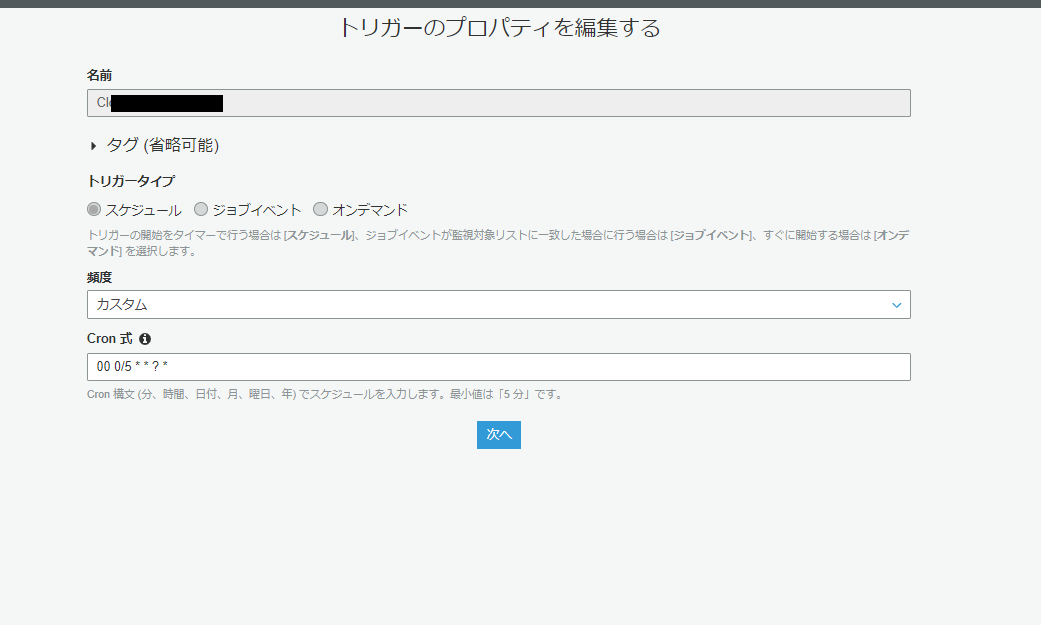
タイプはスケジュールタイプが良いと思います。定期実行ですね。クーロン式では、曜日に指定が無い場合は「?」にする必要があります。
linux形式ではなく、CloudWatchEventと同じ形式です。
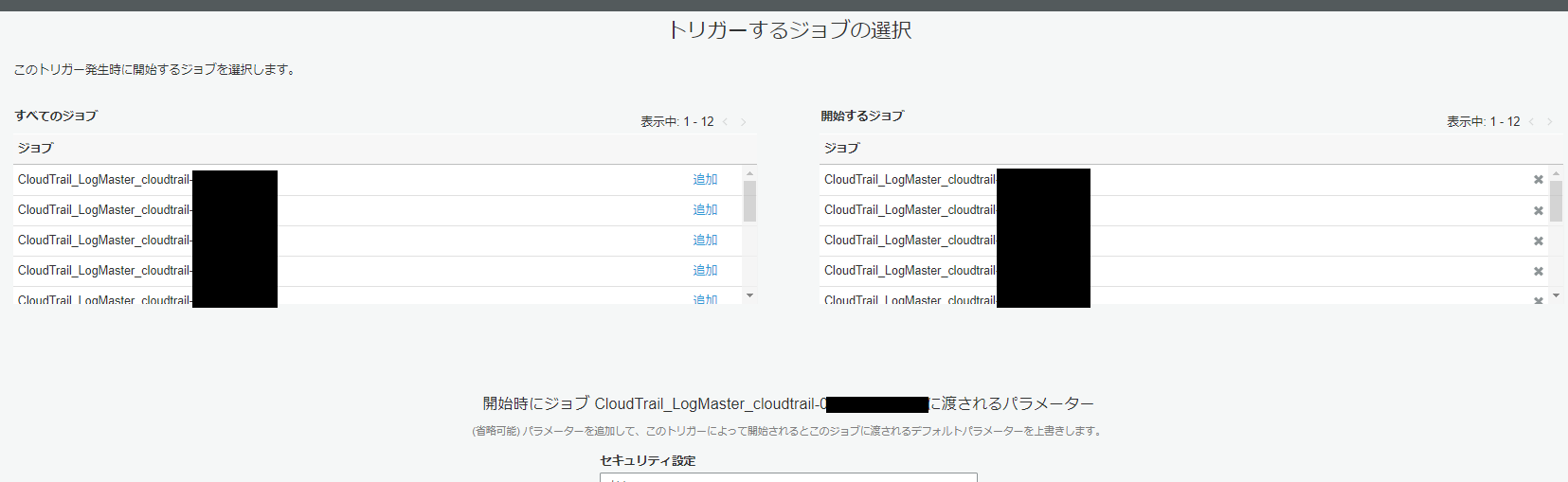
一つのトリガーで複数のジョブが実行できますので、この際、まとめて実行してしまいます。
それぞれのジョブに対するカスタマイズ実行が可能ですが、数分で終わってしまうジョブなので、変更の必要性はそれほどありません。
最安値を目指すのであればチューニングしてみるのも良いかもしれませんね。
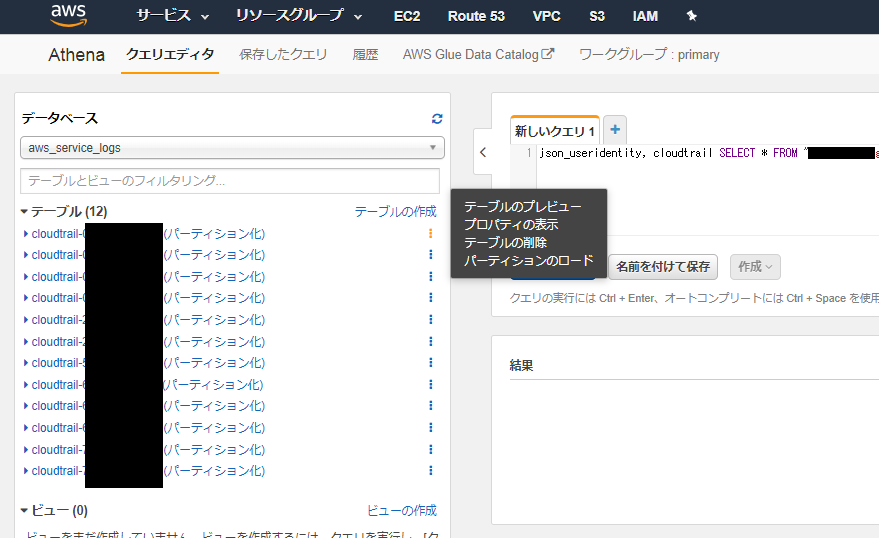
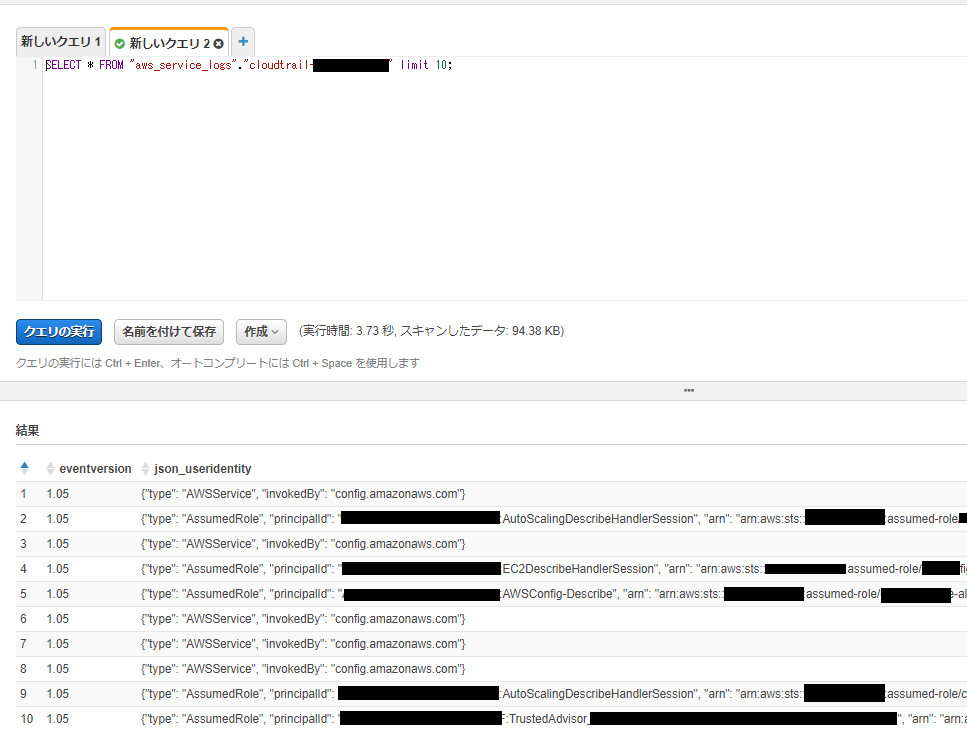
そして、データカタログができた時点で、Athenaによるクエリ投入が可能になっています。
Athenaに移動して、クエリを投入すると、データを引けることが分かります。
もうちょっとだけ続くんじゃ
ここから先はQuickSightにデータを投入して、解析する部分になります、が。
まあこれがまた少々長くなります。
単純なやり方だけならすぐに終わるんですが、QuickSightの癖がある部分までお伝えしようと思うと微妙に大変な感じです。
ということで、もうちょっとだけ続くんじゃ。