初めに
最近少し暇になったので、研究で使っている知識で面白いことできないかな~と思い、やってみた感じです。ちなみにモデルはCNNを使っています。
前処理
本当は色々なvtuberの声を集めるべきでしたが、それは大変そうだったので今回は兎田ぺこらと雪花ラミィとさくらみこのみの音源を使いました。
手順は以下の通りです。
➀youtubeに落ちている切り抜き動画をdl
②audacityを使って声が入っていない、もしくは他の人の声が入っている区間を取り除く(正直ここはめんどくさい)
③音源を2 sごとに切り抜く
④切り抜いた音声をメル周波数スペクトログラムに変換
重要なのは④です。声の分類をするためには機械学習の入力に音に関する何らかの特徴量を与える必要があります。有名な特徴量としてはMFCCなどがありますが、今回はそういった類のものでは無く、比較的rawなデータであるスペクトルグラムを扱いました。スペクトルグラムは周波数分布の時間変化を表したものであり、これには話者の、話者らしさが反映されていると考えています。(ぺこらならツンとした感じの声色?とか)
今回使うメル周波数スペクトルグラムは短時間フーリエ変換(STFT)によって得られる一般的なスペクトルグラムを**ヒトの聴覚特性に合うように変換したものになります。**↓こんな感じです。
これはラミィの声です。
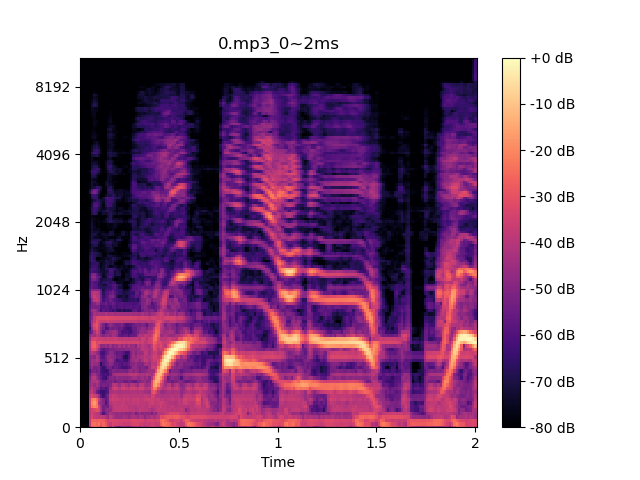
ヒトは高周波の音の変化よりも、低周波の音の変化により敏感です。これを反映するために、メル周波数スペクトルグラムでは
**低周波をより細かく、高周波を粗っぽく扱っています。**具体的には低周波には多く、高周波には少なく三角窓を掛け合わせ、複数の帯域に分けています。
今回はSTFTの時間分解能が約11.5 ms、メル周波数の帯域が128になるようにパラメータを設定し、メル周波数スペクトルグラムを作成しました。このようにして、入力に使う 2 sの音源を173×128の形状を持つ行列に変換しました。データ数は兎田ぺこらは221,雪花ラミィは191、さくらみこは160個になりました。つまり合計で572個です。
モデル構造
モデルはCNNを使いました。CNNはrawなデータから特徴量を抽出するのに長けており、画像、音声分野で近年よく使われています。
モデル構造は以下の通りです。Vgg net等を参考にフィルタ数などを決めています。ちなみに今回は3値分類なので出力ニューロンは3つになっています。
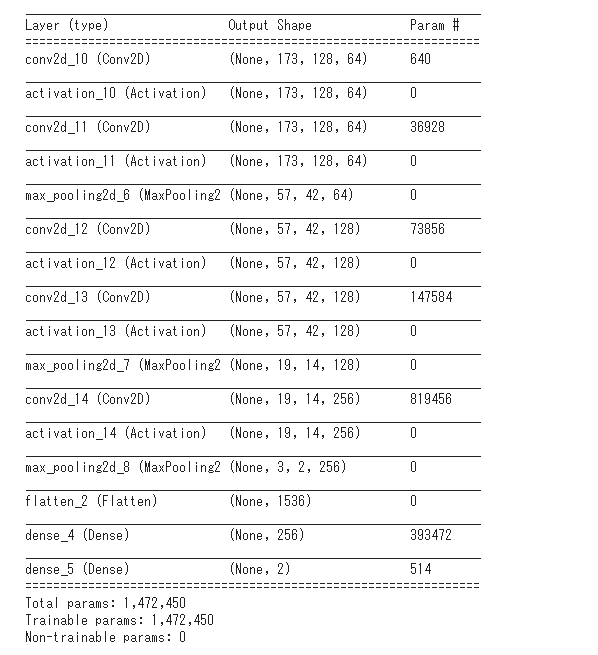
訓練データとテストデータの比率は2:1にしました。データ数が少ないので、バッチサイズは40としました。1 epochで7回分です。学習回数は60 epochとしました。
コード
コードは以下の通りです。pythonで書いています。
X=np.load("/content/drive/MyDrive/vtuber/x.npy",allow_pickle=True)
X=X.reshape(len(X),173,128,1)
Y=np.load("/content/drive/MyDrive/vtuber/y.npy",allow_pickle=True)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.33, random_state=None)
# CNNを構築
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='same',#padding=same:出力形状が変化しないようにゼロpaddingしている
input_shape=(173,128,1)))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3),padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Conv2D(128, (3, 3),padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(128, (3, 3),padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Conv2D(256, (5, 5), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(5, 5)))
model.add(Flatten())#ベクトル化
model.add(Dense(256,activation='relu'))#中間層ニューロン256個
model.add(Dense(2,activation='softmax'))#出力ニューロン2個
# コンパイル
sgd=optimizers.SGD(lr=0.01, momentum=0.0, decay=0.0, nesterov=False)
model.compile(loss='binary_crossentropy',
optimizer='sgd',
metrics=['acc'])
model.summary()
history = model.fit(X_train, Y_train, batch_size=40, epochs=100,
validation_data=(X_test,Y_test), verbose = 1)
# acc
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['acc', 'val_acc'], loc='lower right')
plt.show()
# loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
結果
lossとaccのepochごとの推移を以下に載せます。
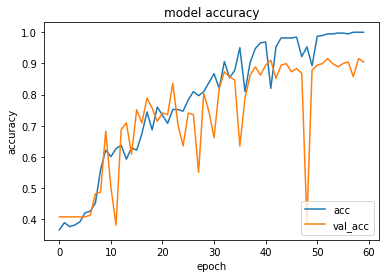
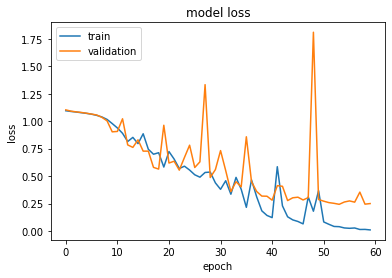
かなりギザギザしていますが、accは上昇し、lossは減少していることから学習は出来ているようです。accについてはtrainで100%、testで90%でした。3値分類では適当に答えたら33%ほどになるので、testで90%になるということは、モデルがスペクトルグラムからぺこららしさ、ラミィらしさをうまく抽出したのではないかと考えられます。しかしCNNの残念な点としてはそれがいったい何なのか、つまりぺこららしさって何?という問いに答えるのが難しい点にあります。そういった意味では伝統的に使われている決定木や重回帰等でうまく分類できるならそちらの方が良いと思います。
各ラベルごとのaccも載せてみました。
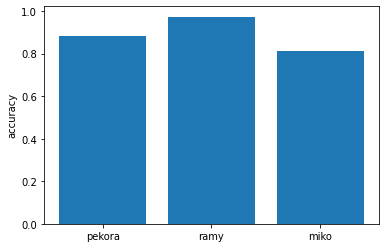
ラミィの正答率が97%でビックリしましたw分かりやすい声質なんですかね?
感想
スペクトルグラムという割と生なデータから分類できているのは**シンプルに凄いなと思います。**我々がスペクトルグラムを見てもその人らしさを見出すのは難しいと思うのですが、機械にそれが出来てしまうのは面白いですね。気になることとしては、声真似したら真似したほうに判定されるのかどうかなどですね。今後は分類する数、つまりvtuberの数を増やしていけたらなと思います。