初めに
レガシーシステムのOracleDBデータをBigQueryへETLする必要があり、GCPのDataflowでETLをしましたが、
日本語のデータが文字化けしていたので、その回避した経験を記述します。
簡単に言えば
- 文字列byte化してクエリ、BigQueryへBYTES型で格納
- BigqueryのUDFを設定してBYTEからcp932形式の文字変換
処理順番
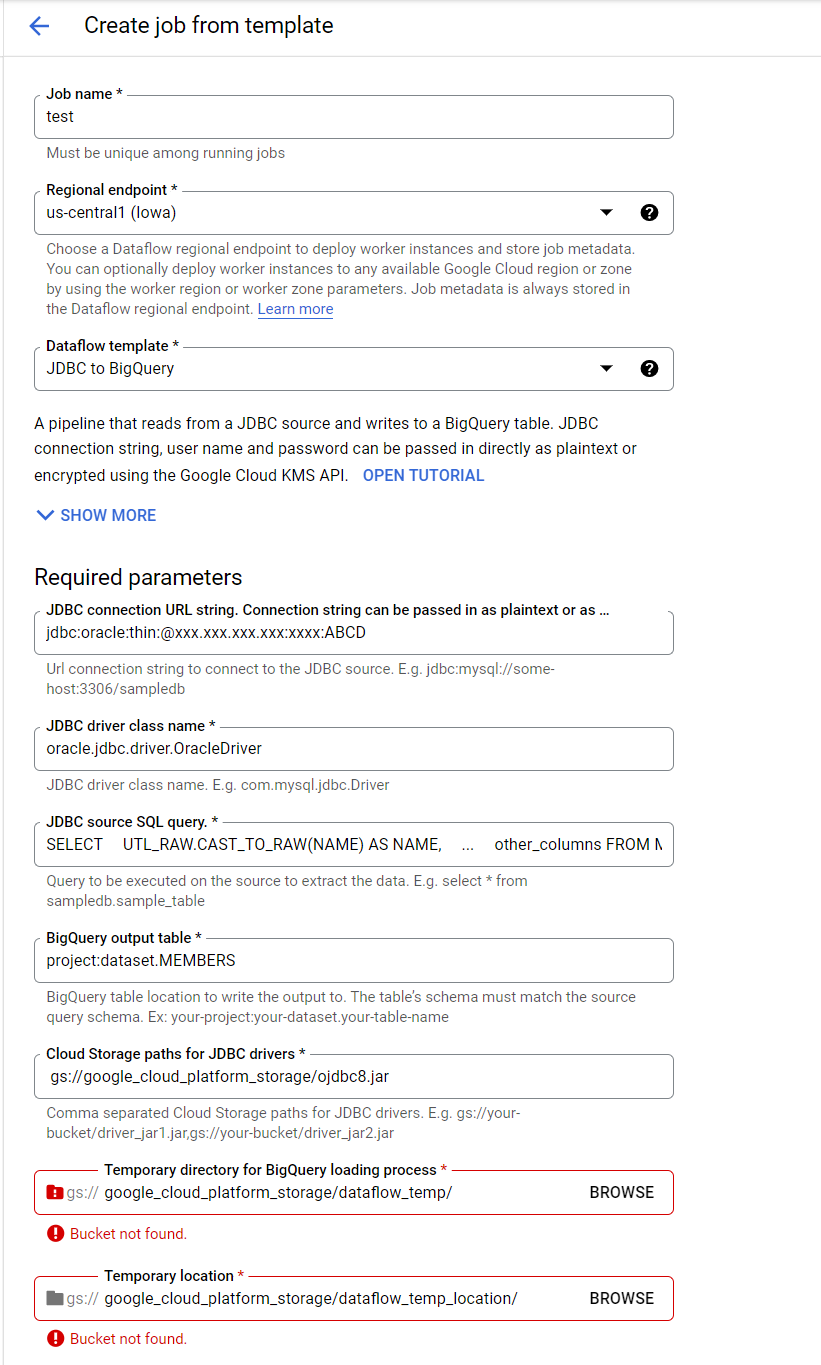
Oracle クエリ
SELECT
UTL_RAW.CAST_TO_RAW(NAME) AS NAME,
...
other_columns
FROM MEMBERS
WHERE condition
Dataflowの設定
Dataflow 提供テンプレートの JDBC to BigQueryで簡単にETLの設定ができる
※ 各設定値はサンプルです。
UDF(user defined function)の設定とクエリ
BigQueryでは、SQL式またはJavaScriptコードを使ってクエリで利用する関数を作成できる。
文字変換ライブラリ iconv-lite
こちらのライブラリはこれは jsファイルを提供してないので webpack でパッケージングする必要がありました。
※ webpackでパッケージングするとき参考にした記事:https://dev.classmethod.jp/articles/bigquery-javascript-udf/
パッケージングしたjsファイルはGCPプロジェクトのクラウドストレージにアップロードします。
UDF定義とクエリ実行
CREATE TEMP FUNCTION conv_test(x ARRAY<INTEGER>)
RETURNS STRING
LANGUAGE js AS """
return iconv_for_udf.decode(x, "CP932")
"""
OPTIONS (
library = ["gs://project_gcp_storage/iconv-lite_bq-udf.js"]
)
;
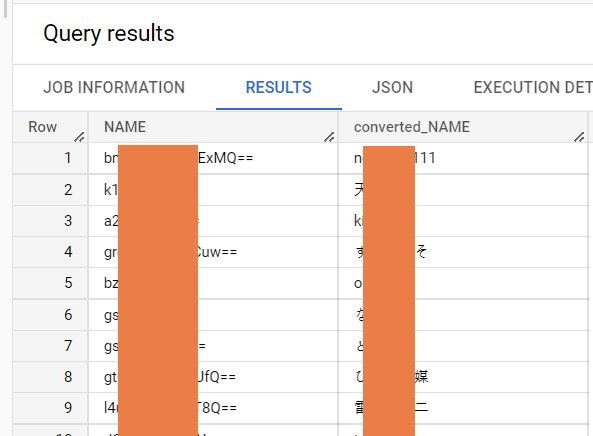
select
NAME,
conv_test(TO_CODE_POINTS(MEMBERID)) as converted_name
FROM `project.dataset.MEMBERS`
※ iconv-liteのdecode関数は buffer を引数として扱うのでクエリでBuffer Arrayに変換してUDFを呼び出す必要があった
iconv-liteの例(from iconv-lite github)
var iconv = require('iconv-lite');
// Convert from an encoded buffer to a js string.
str = iconv.decode(Buffer.from([0x68, 0x65, 0x6c, 0x6c, 0x6f]), 'win1251');
// Convert from a js string to an encoded buffer.
buf = iconv.encode("Sample input string", 'win1251');
// Check if encoding is supported
iconv.encodingExists("us-ascii")
結果
まとめ
やり方、色々あると思いますが、チーム内のシステムに適用するための方法を探す中で一番簡単にできそうなやり方でした。
辿り着くまでは大変だったが、完成した流れは簡単でシンプルでした。
レガシーシステムのETLがまた今後あるかは別にして、なかなか良い勉強でした。