こんなデータがあるとします。
カラムxには1~5のいずれか、yにはデータ、keyには系列ラベル、ですね。
set.seed(71)
N <- 100
dat <- data.frame(x = sample(1:5, 2 * N, replace = TRUE),
y = c(rnorm(N, 1, 3), rnorm(N, 3, 3)),
key = c(rep("A", N), rep("B", N)))
Fig.1 平均値の折れ線グラフ+標準偏差
 Fig.1
Fig.1
こんなグラフを書いたりします。
往々にして、こんなグラフが出てくるのは横軸が時間軸で、タイムポイント1~5までの系列A, Bそれぞれの値の推移をまとめました、という内容です。横軸の取り方に問題がある場合もありますが、とりあえずそこはセーフとしておきましょう。
dat_g <- dat %>%
group_by(key, x) %>%
summarise(mean = mean(y), sd = sd(y))
ggplot(dat_g, aes(x, mean, color = key))+
geom_errorbar(aes(ymin = mean - sd, ymax = mean + sd, color = key),
width = 0.2, size = 1.5, alpha = 0.5)+
geom_line(size = 2)+
geom_point(size = 5)+
theme_classic()+
theme(axis.title.x = element_blank())
Fig.2 問題アリのグラフ
 Fig.2
Fig.2
これはダメです。
書く側の頭の中で、X軸を連続量として扱うのか、離散量として扱うのかがとっ散らかっています。読む側は大変混乱します。
そもそも論として、折れ線グラフの X軸は連続量を取るのが大原則です。
読む側としては、謎の要因でAのタイムポイントがそれぞれ微妙に遅れて測定された、と読むのが自然です。
常識で察しろ?うーん、
 Fig.2-2
Fig.2-2
これなら完全にXのポイントがズレていますよね。
Fig.2とFig.2-2で読み方を変えなければならない理由は、読み手にはありません。
Fig.3 離散化されているならboxplotはいかがでしょう?

Fig.3
X軸が厳密に離散化されているのならば、boxplotにしてデータをjitterで示すというのが筋が良さそうです。この場合、横軸のAとBは離散量として明記されているのでjitterでバラつかせるのは読み手にとって親切です(データの重なりが見えるので)。
ggplot(dat, aes(key, y, color = key))+
geom_boxplot(outlier.colour = NA)+
geom_jitter(width = 0.1, alpha = 0.7)+
facet_wrap(~x, nrow = 1)+
theme(axis.title.x = element_blank())
これぐらいのデータ数ならjitterではなくpointでもOKですが、データ数が5倍ぐらいになると、jitterにした方が親切だと思います。
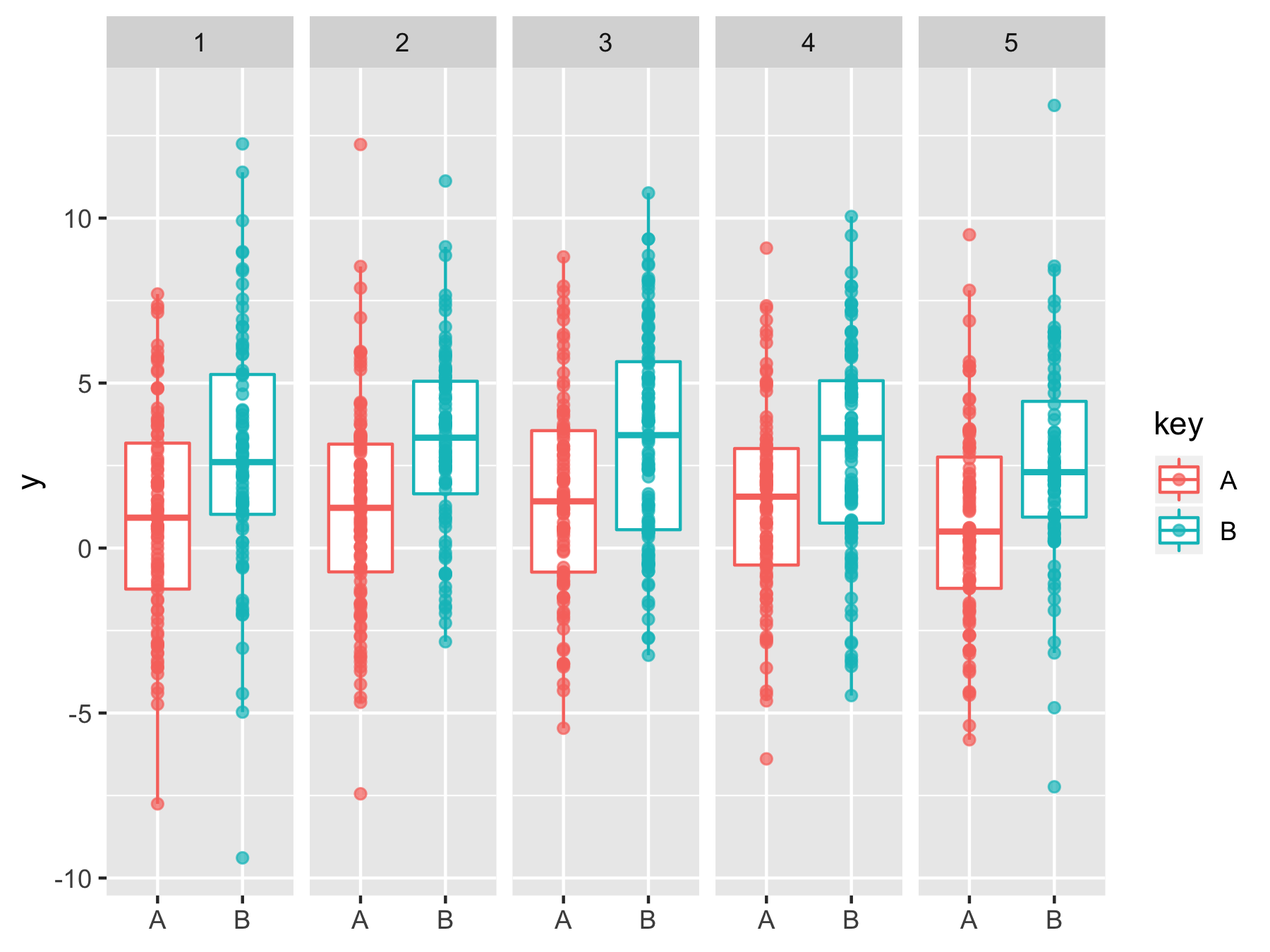
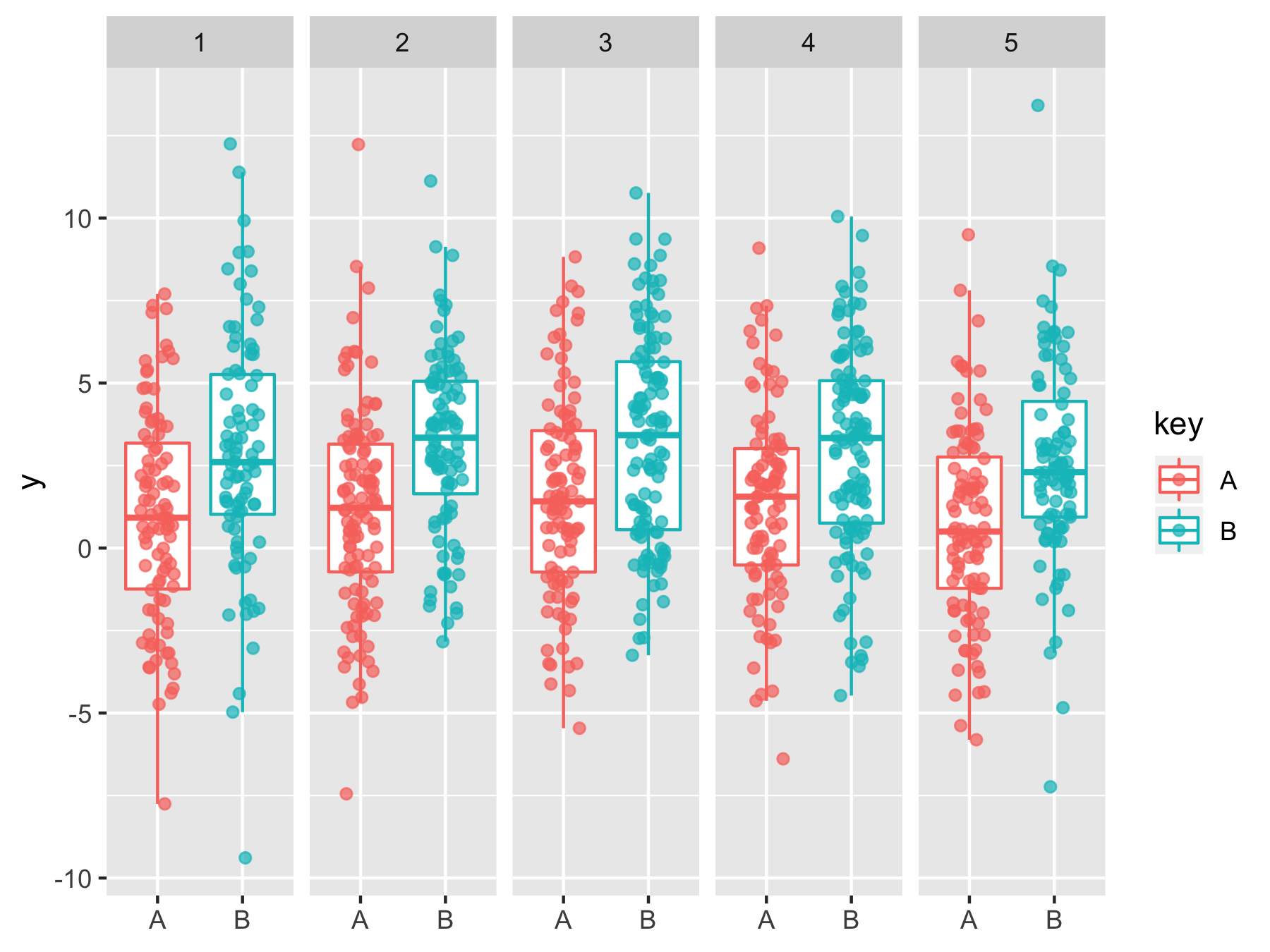
Fig.4 連続量なら回帰線を引いてみるなど
本当はX軸にも広がりがあり、それを丸めてstageを作っていたならば回帰曲線を引いた方がFig.1よりも素直だと思います。ただし、この編みかけ部分がデータの分散範囲と誤解する方もいらっしゃるのでそこは注意が必要です。
 Fig.4
Fig.4
ここでは手順が逆ですが、後付けでx2を作って書きました。
dat2 <- dat %>%
mutate(x2 = x + rnorm(2 * N, 0, 0.15))
ggplot(dat2, aes(x2, y, color = key))+
geom_smooth(aes(fill = key))+
geom_point()+
theme_classic()+
theme(axis.title.x = element_blank())
Fig.5 線でつながないというやつ。

線でつながなければ、X軸に離散量を取って同一グラフに入れてもOKです。
dat <- iris %>% gather(key, val, -Species)
dat_g <- dat %>%
group_by(key, Species) %>%
summarise(mean = mean(val), sd = sd(val))
ggplot(dat, aes(key, val, color = Species))+
geom_jitter(width = 0.2, alpha = 0.2)+
geom_point(data = dat_g, aes(key, mean, color = Species),
size = 5)+
theme_classic()+
theme(axis.title.x = element_blank())