はじめに
こちらは APN Ambassador によるアドベントカレンダー「Japan APN Ambassador Advent Calendar 2020」での21日目の記事となります。
APN Ambassador の詳細については、下記の記事をご覧ください。
私は AWS re:Invent 2020 で発表された Amazon SageMaker Pipelines についてまとめてみたいと思います。
なお、こちらの投稿内容は私個人の意見であり、所属企業を代表するものではありませんので、ご了承ください。
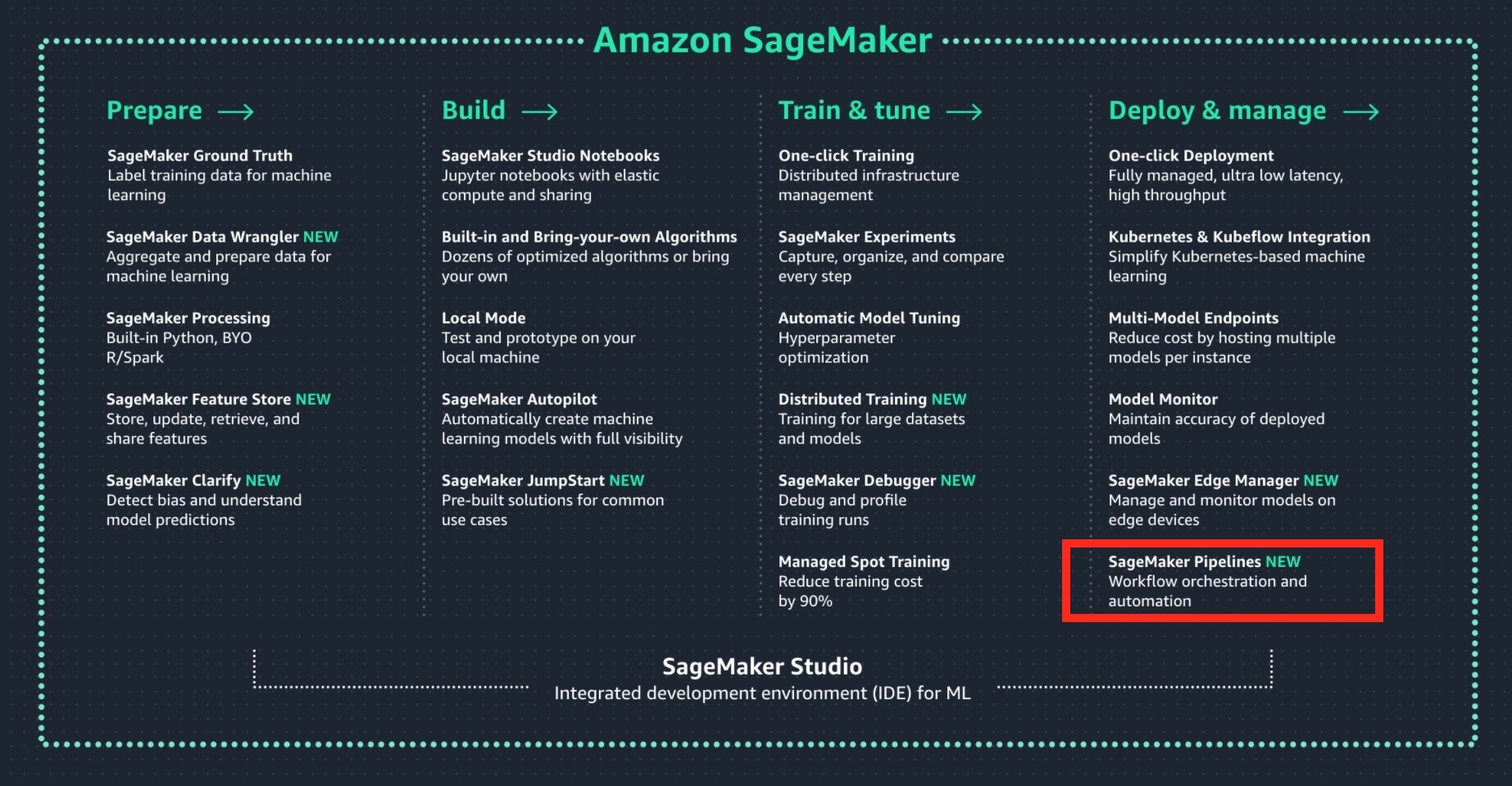
Amazon SageMaker Pipelines
Amazon SageMaker Pipelines とは、Amazon SageMaker に追加された新機能の1つであり、MLOps を簡単に実現することができる機能です。(下図の赤枠)
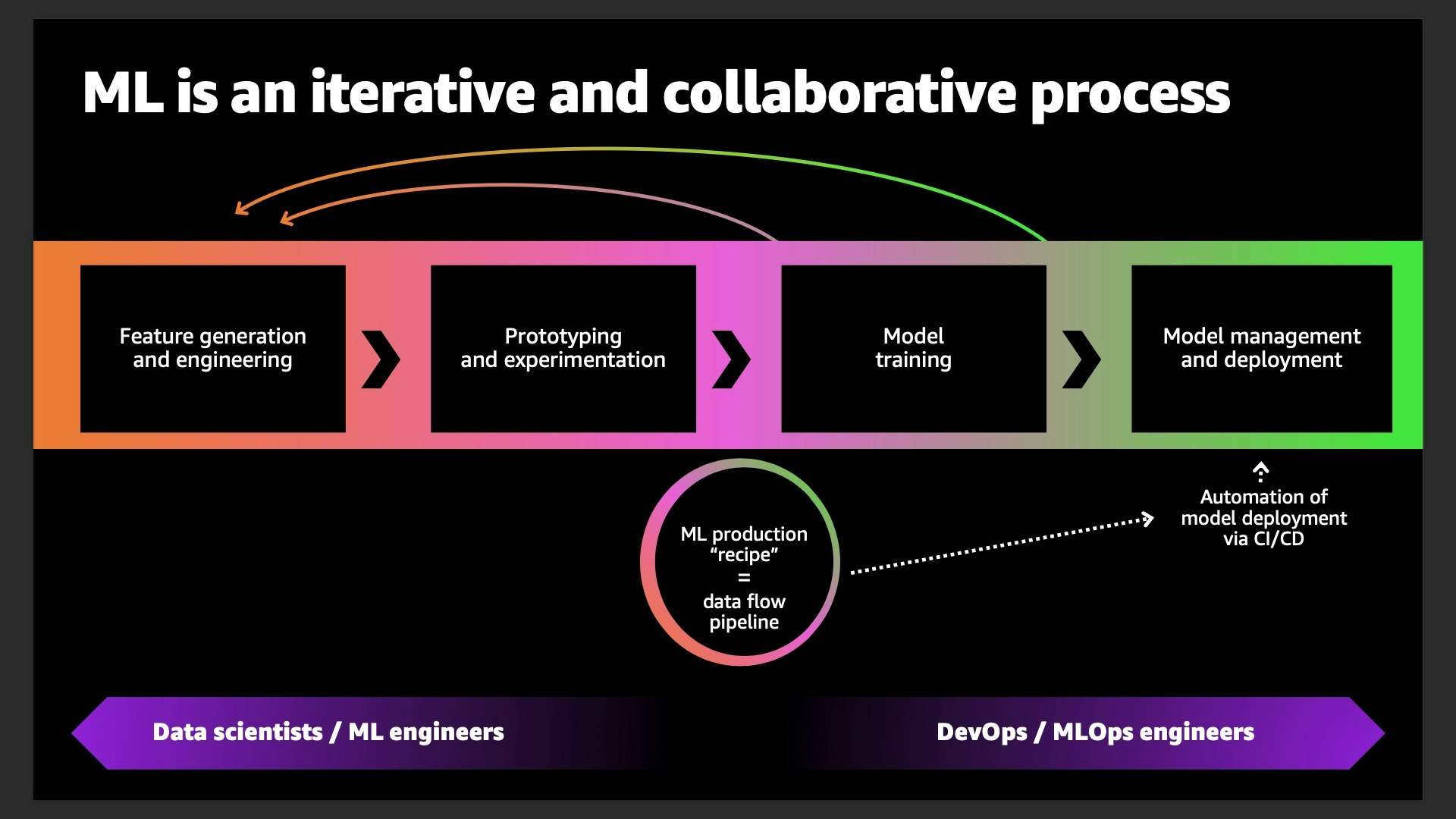
MLOps は "Machine Learning" + "DevOps" を意味し、機械学習モデルの開発に DevOps のプラクティスを適用したものです。
機械学習モデルの開発は一度作って終わりではなく、目標とする精度に到達するまで何度も試行錯誤を繰り返します。データの収集にまで戻ってやり直すこともあります。
晴れて精度の要件を満たして本番環境にデプロイ後は、精度の監視を継続的に行い、精度の維持のために必要に応じてデータの再収集や特徴量の再設計、再学習を繰り返し行います。
これらを手作業で実行すると手間がかかるため、CI/CD を初めとする DevOps のプラクティスを導入して、効率化を図ろうと考えるのが MLOps のコンセプトとなります。
しかし、MLOps を導入するにあたって、下記のような悩みが生じます。
- データサイエンティストや機械学習エンジニアにとって、DevOps やそのプラクティスは必ずしも馴染みがあるものではない。DevOps に詳しいエンジニアを雇う必要がある。(コスト増やリードタイムの発生)
- 反対に、DevOps エンジニアは必ずしも機械学習に詳しいわけではない。機械学習の理解に学習コストがかかる他、要件の把握や調整等に苦労して MLOps のシステム化までに長い時間を要する可能性がある。
- MLOps 自体はビジネス上の利益を生まないので、仕組みの導入にかける労力は最小化したい。
SageMaker Pipelines は、上記のような悩みに対処すべく、MLOps の仕組みをマネージドサービスとして提供してくれます。東京リージョンを初めとする SageMaker の利用が可能な全てのリージョンで利用することができます。
SageMaker Pipelines の全体像を下図に示します。
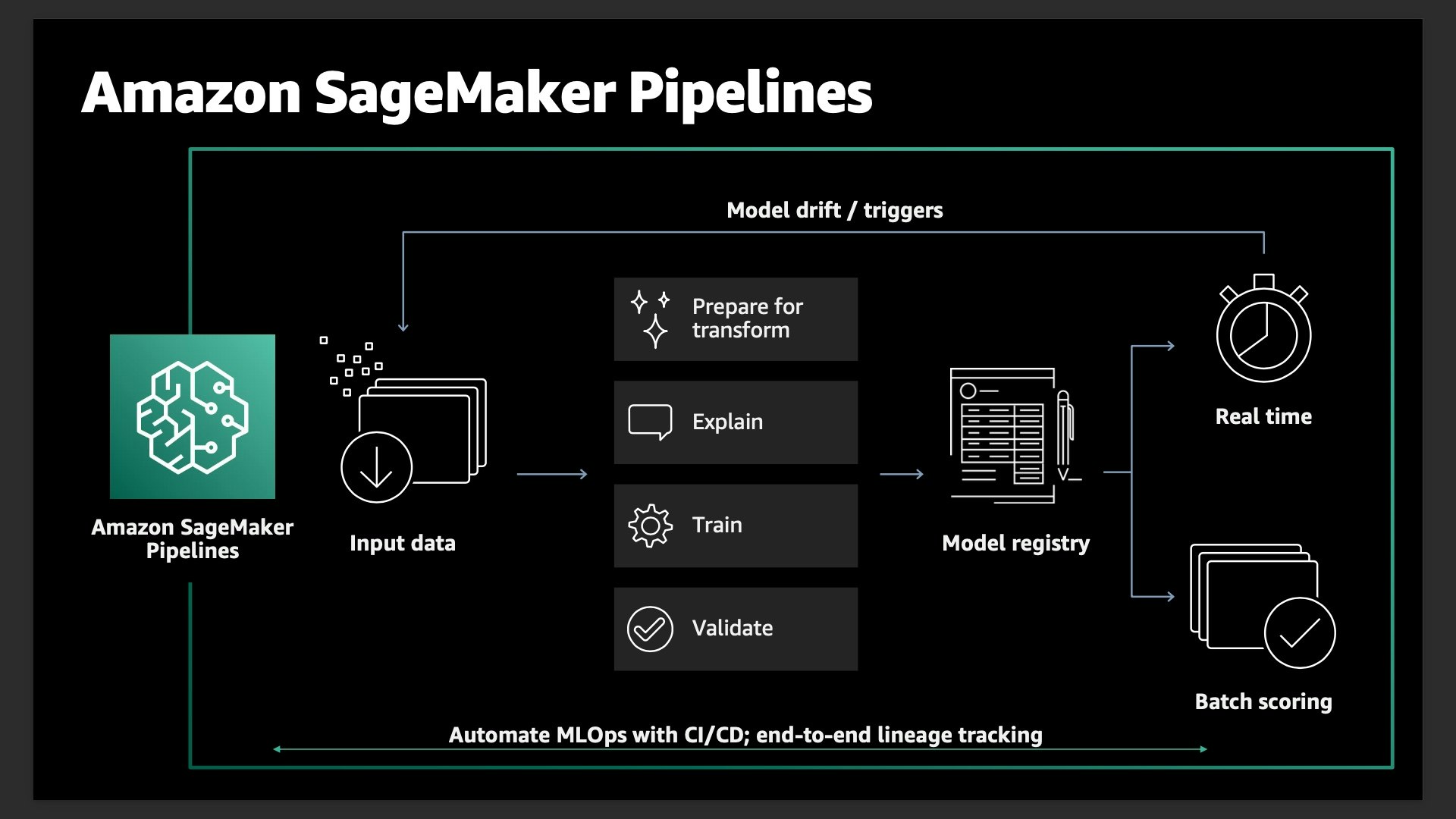
SageMaker Pipelines は、SageMaker に加えて、下記に示すようなサービスが背後で連携して MLOps を実現する機械学習ワークフローのパイプラインが構成されます。
- CloudFormation
- Service Catalog
- CodeCommit
- CodeBuild
- CodePipeline
- S3
- ECR
- CloudWatch/CloudWatch Logs
- CloudTrail
SageMaker Pipelines の特徴
SageMaker Pipelines は、下図に示す5つの特徴を備えています。
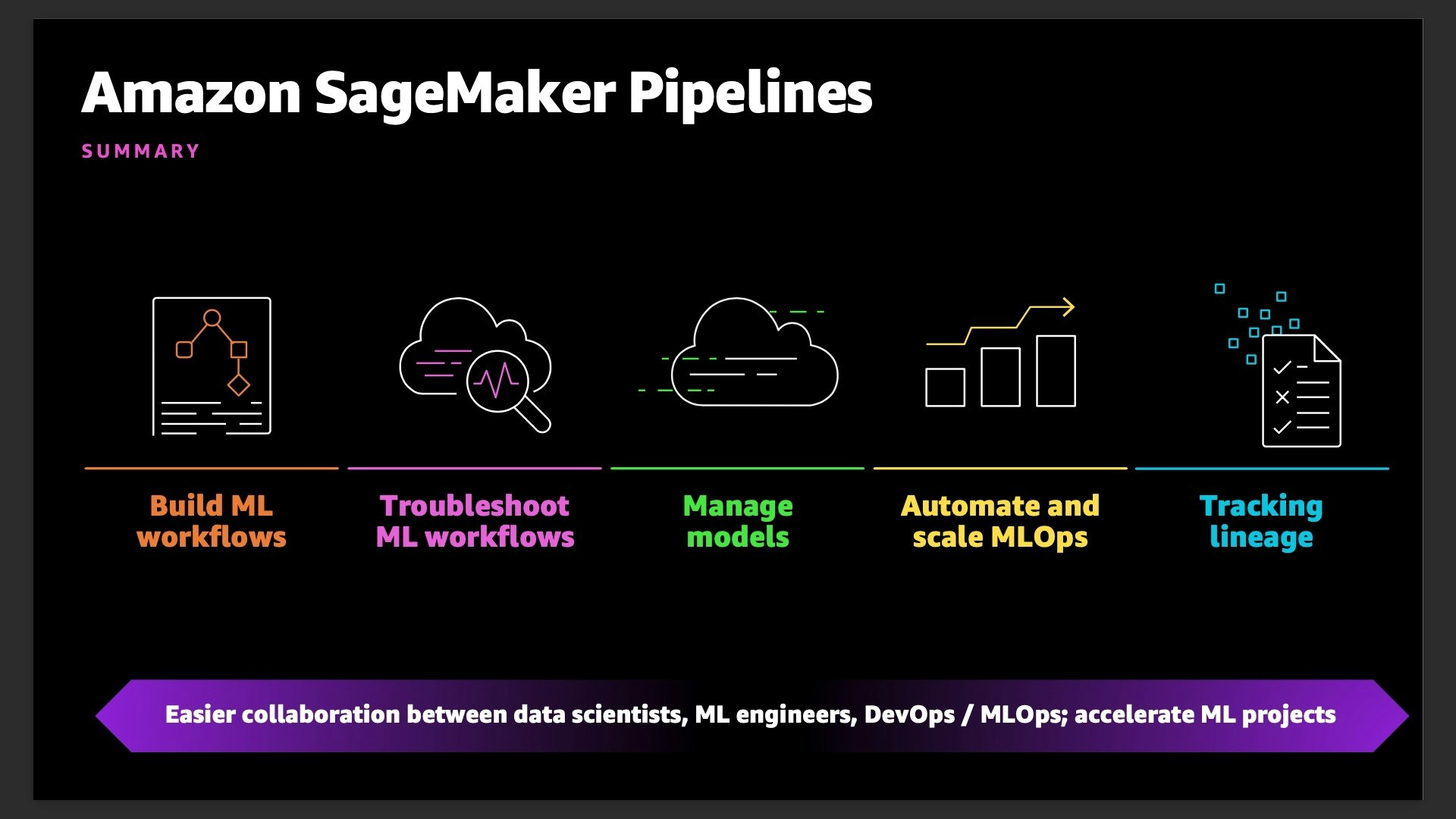
これらの特徴について詳細を見ていきたいと思います。
Build ML workflows
SageMaker Pipelines は、SageMaker Studio (機械学習の開発用 IDE) と Amazon SageMaker Python SDK に統合されており、これらを利用して機械学習ワークフローのパイプラインを定義することができます。
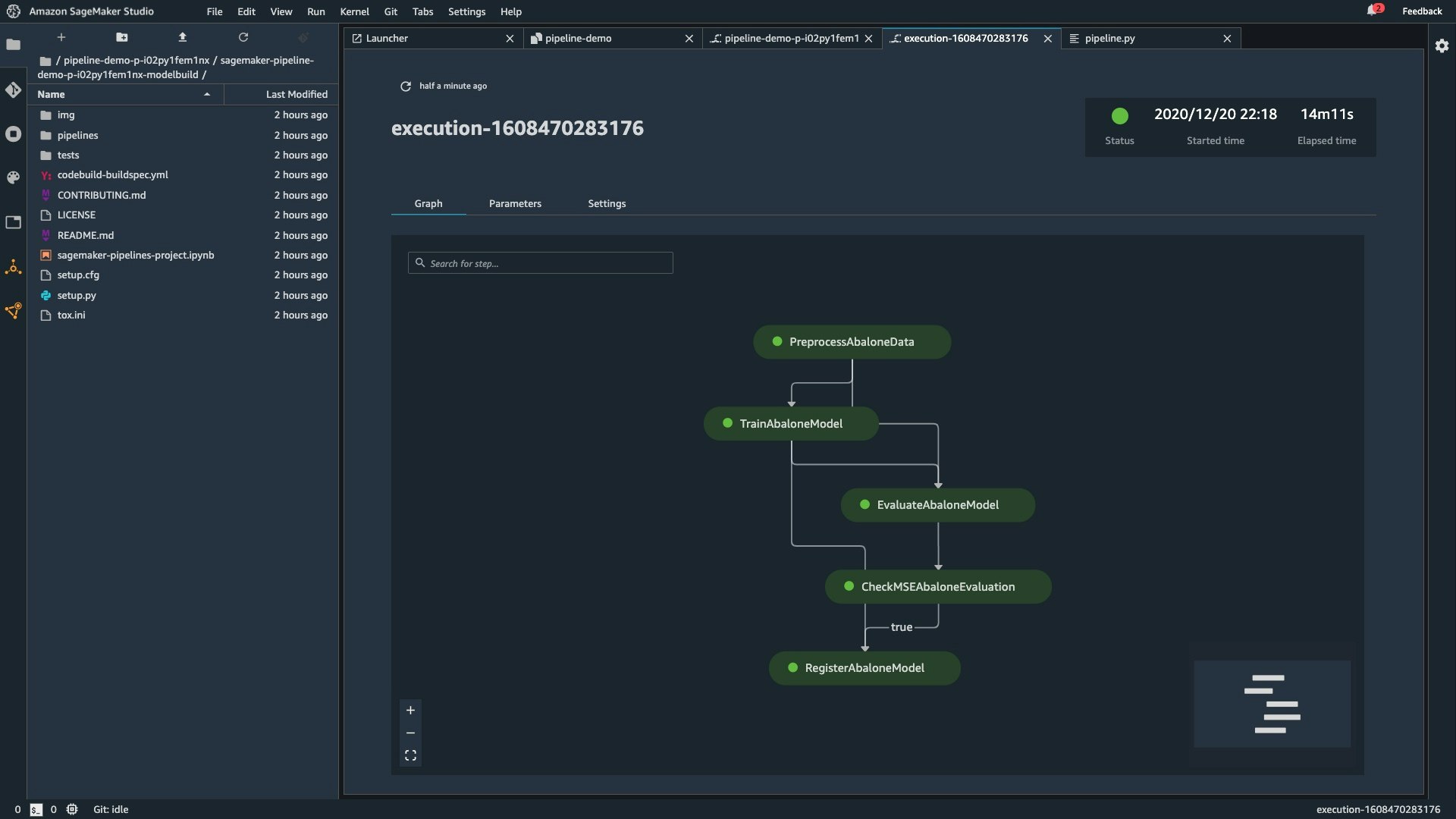
例えば、上記の機械学習ワークフローのパイプラインは、pipeline.py に下記のように定義します。(パイプラインの定義部分のみを記載)
from sagemaker.workflow.pipeline import Pipeline
pipeline_name = f"AbalonePipeline"
pipeline = Pipeline(
name=pipeline_name,
parameters=[
processing_instance_type,
processing_instance_count,
training_instance_type,
model_approval_status,
input_data,
batch_data,
],
steps=[step_process, step_train, step_eval, step_cond],
)
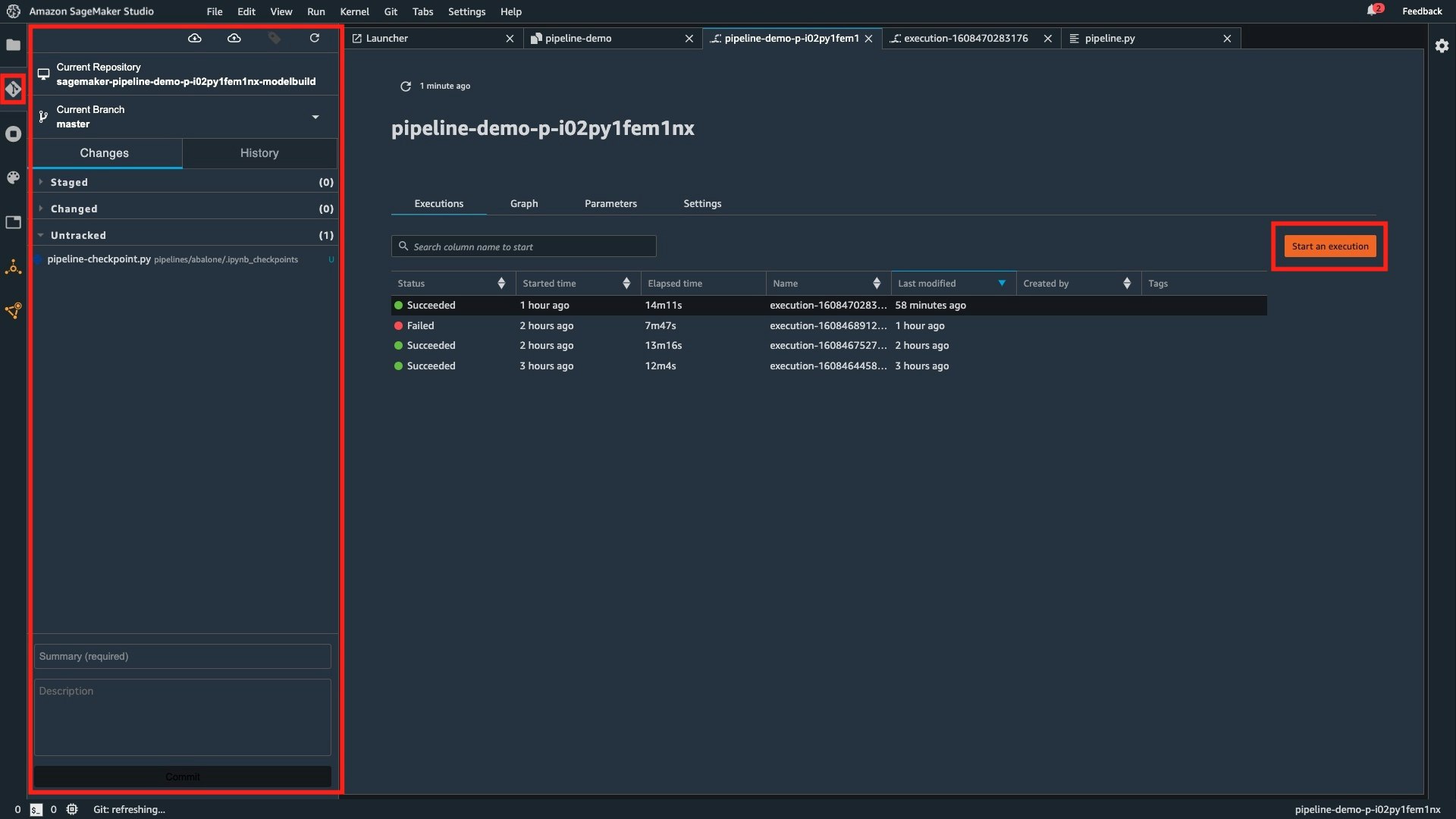
機械学習ワークフローのパイプラインは、CodeCommit リポジトリへの Push をトリガーに自動で実行させることができます。SageMaker Studio には実行ボタン (下図の "Start an execution") が用意されているので手動での実行や SDK によるプログラムからの実行も可能です。
Automate and scale MLOps
前述の通りで、SageMaker Pipelines は AWS Code シリーズを初めとする様々なサービスの組み合わせで CI/CD が実現されており、Service Catalog や CloudFormation を利用して MLOps の仕組みを自動構築することができます。
開発者ガイドでは、サンプルテンプレートを用いた簡単なデモの手順が公開されています。
このデモでは、アワビ (abalone) の物理的な特徴から年齢の予測を行う機械学習モデルの構築が題材となっています。(参考:UCI Machine Learning Repository Abalone Data Sets)
機械学習ワークフローのパイプラインの構築から Staging & Production への推論エンドポイントのデプロイまで 5 ステップで実行することができます。
- Step 1: Create the Project
- Step 2: Clone the Code Repository
- Step 3: Make a Change in the Code
- Step 4: Approve the Model
- (Optional) Step 5: Deploy the Model Version to Production
これと同等の仕組みをゼロから構築すると、数日〜数週間程度はかかりそうですが、SageMaker Pipelines を利用すると、わずか 5 ステップ、時間にして数時間程度で構成することができます。
SageMaker Pipelines では、サンプルテンプレートが3つ提供されています。
- MLOps template for model building and training:
機械学習モデルの構築 (学習) とレジストリの登録までのパイプラインを構築 - MLOps template for model deployment:
レジストリに登録した機械学習モデルを推論エンドポイントとしてデプロイするためのパイプラインを構築 - MLOps template for model building, training and deployment:
1 と 2 の組み合わせで End-to-End のパイプラインを構築
上記の 1〜3 の中からテンプレートを選び、プロジェクト名を入力してクリックするだけで MLOps を実現する機械学習ワークフローのパイプラインを構築することができます。
利用者の要件に合わせて独自のプロジェクトテンプレートを作成することも可能です。Service Catalog を利用して組織のテンプレートとして公開して共有することができます。
Manage models
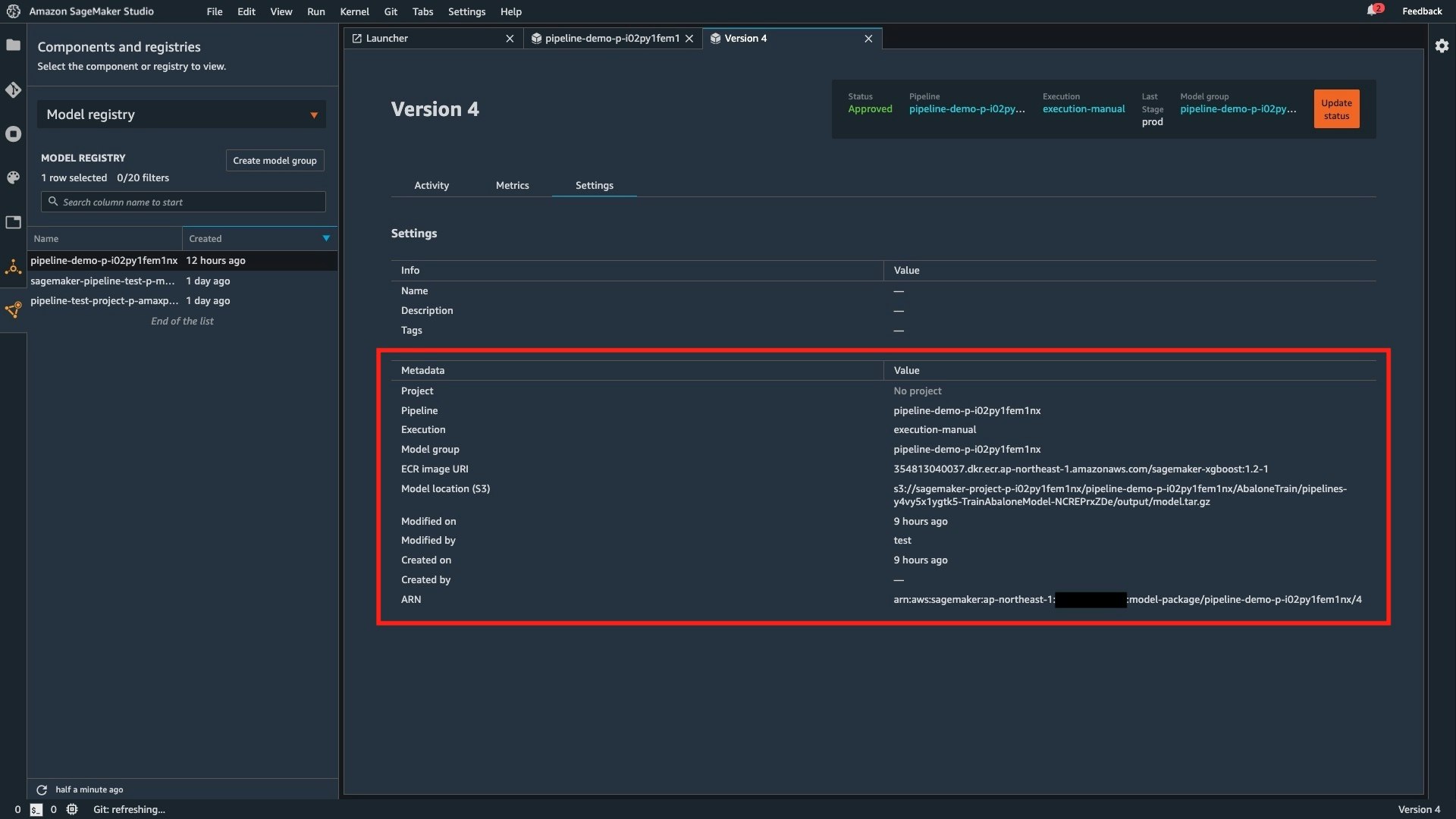
機械学習モデル用のレジストリを構成して、バージョン管理などを行うことができます。
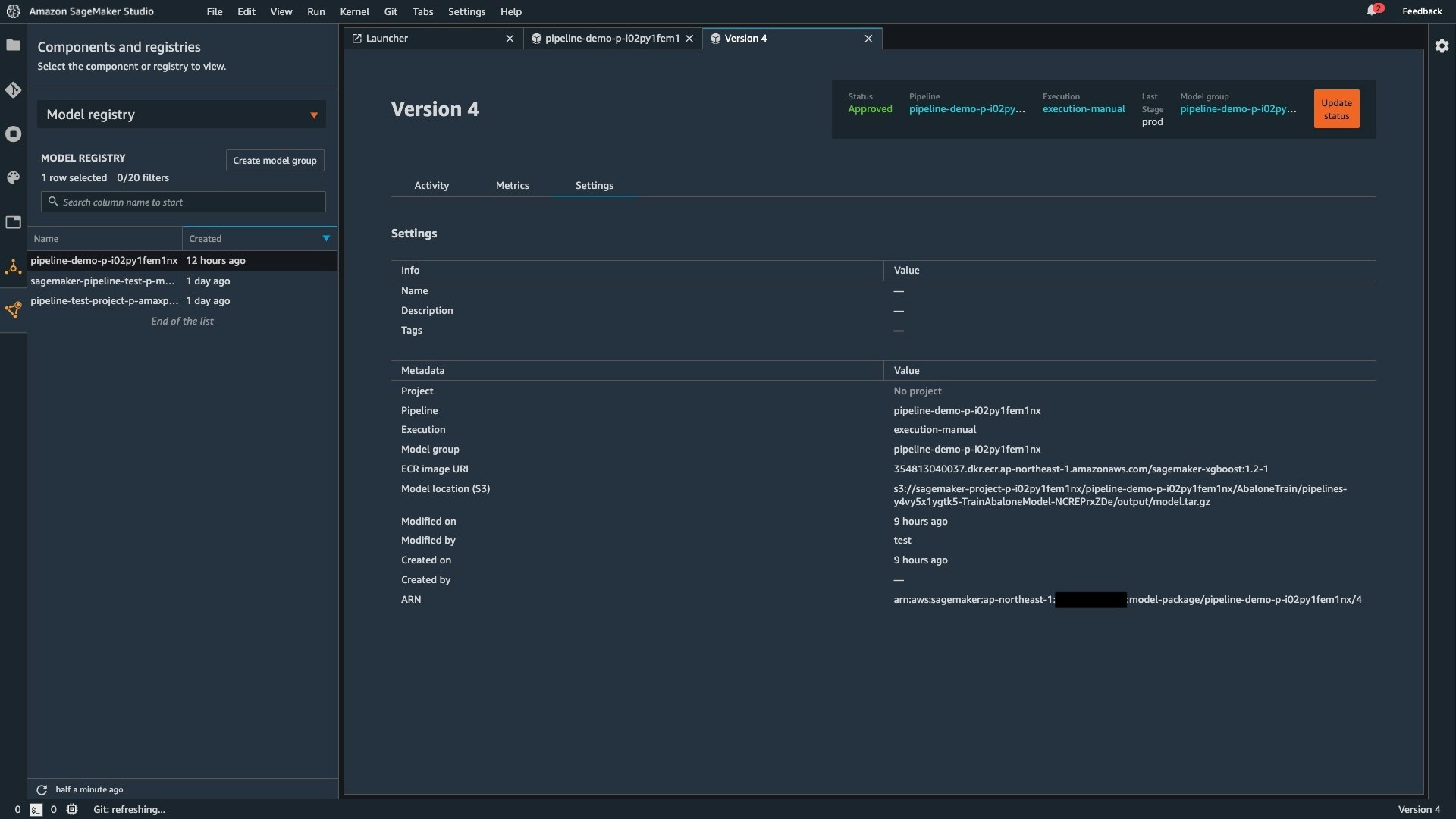
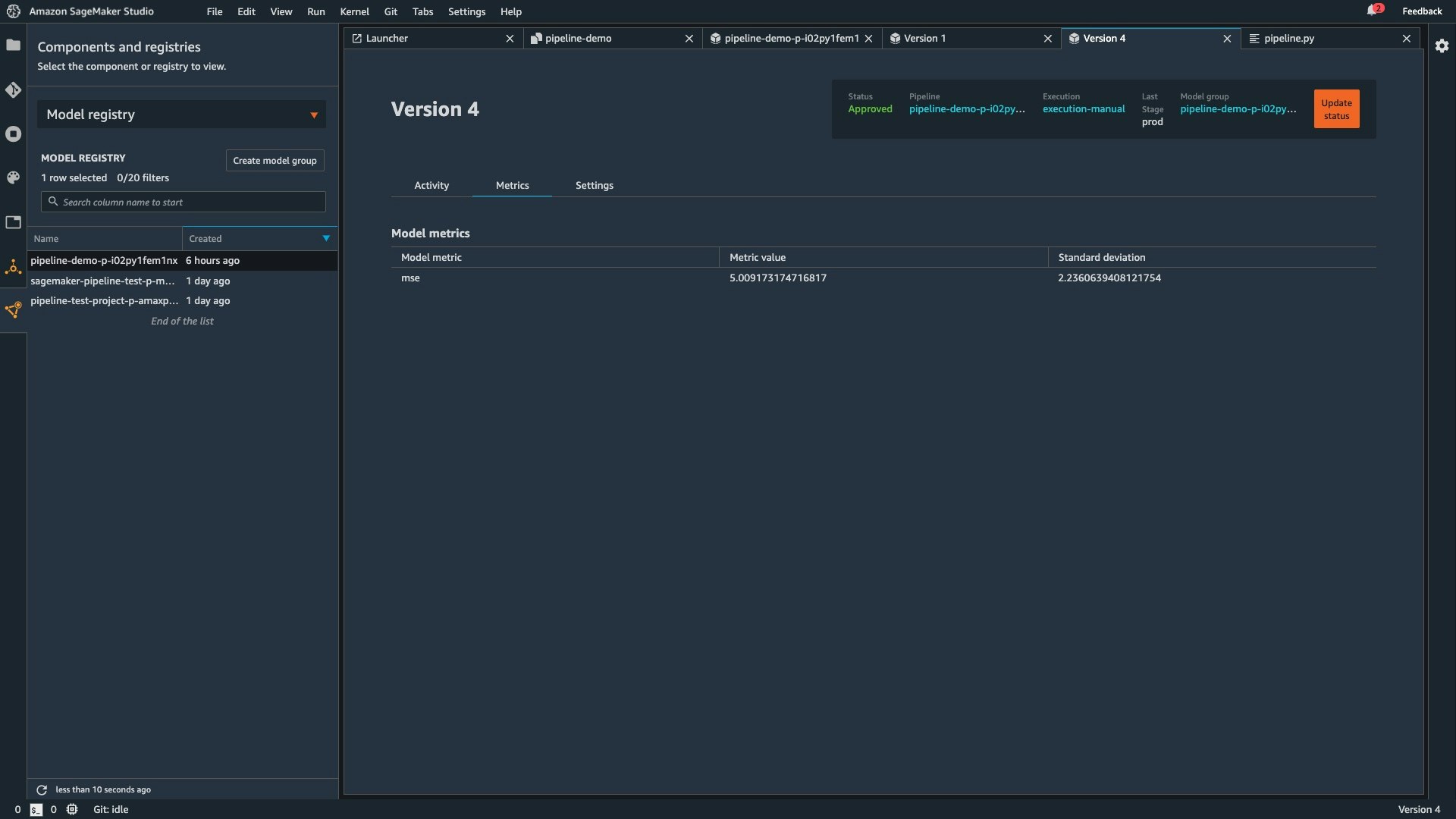
機械学習モデルの精度などの各種メトリクスも確認することができるため、これらを管理するための Excel 管理なども不要です。下図は機械学習モデルの精度を評価するメトリクスとして MSE (平均二乗誤差) と標準偏差が記録されています。
また、SageMaker Pipelines では、デプロイ前の承認の要否を定義することができます。
デフォルトはデプロイ前に承認を行う継続的デリバリーであり、下記を "Approved" に変更することで承認を行わずにデプロイを行う継続的デプロイを実現することができます。
model_approval_status = ParameterString(
name="ModelApprovalStatus", default_value="PendingManualApproval"
)
Staging へのデプロイ前のレビューと承認は SageMaker Studio から行うことができます。
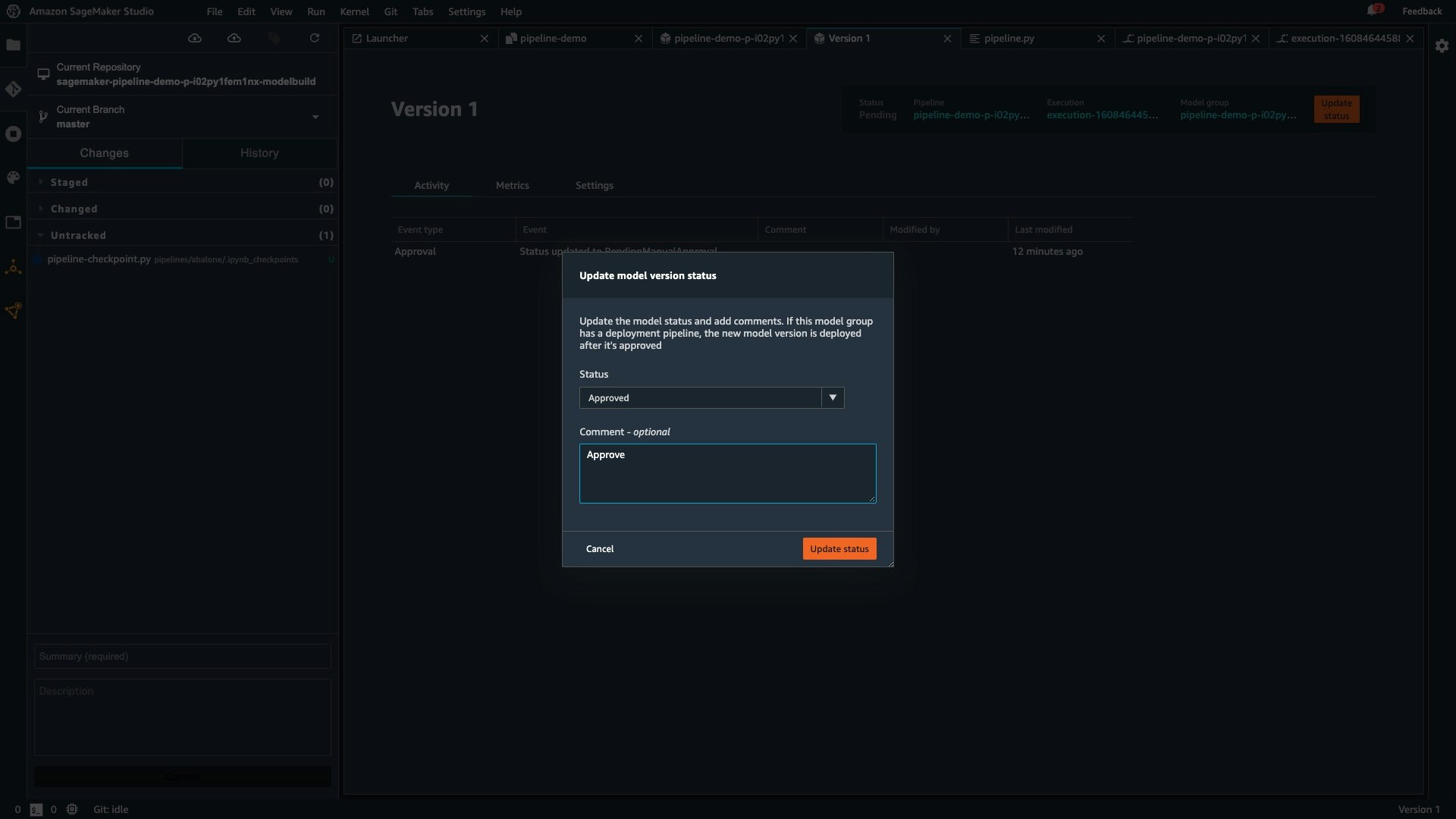
Production へのデプロイ前のレビューと承認は CodePipeline のコンソール画面から行うことができます。例えば、プロダクトの責任者に限定してデプロイの権限を与えることで、プロダクトのデプロイに牽制をかけることができます。
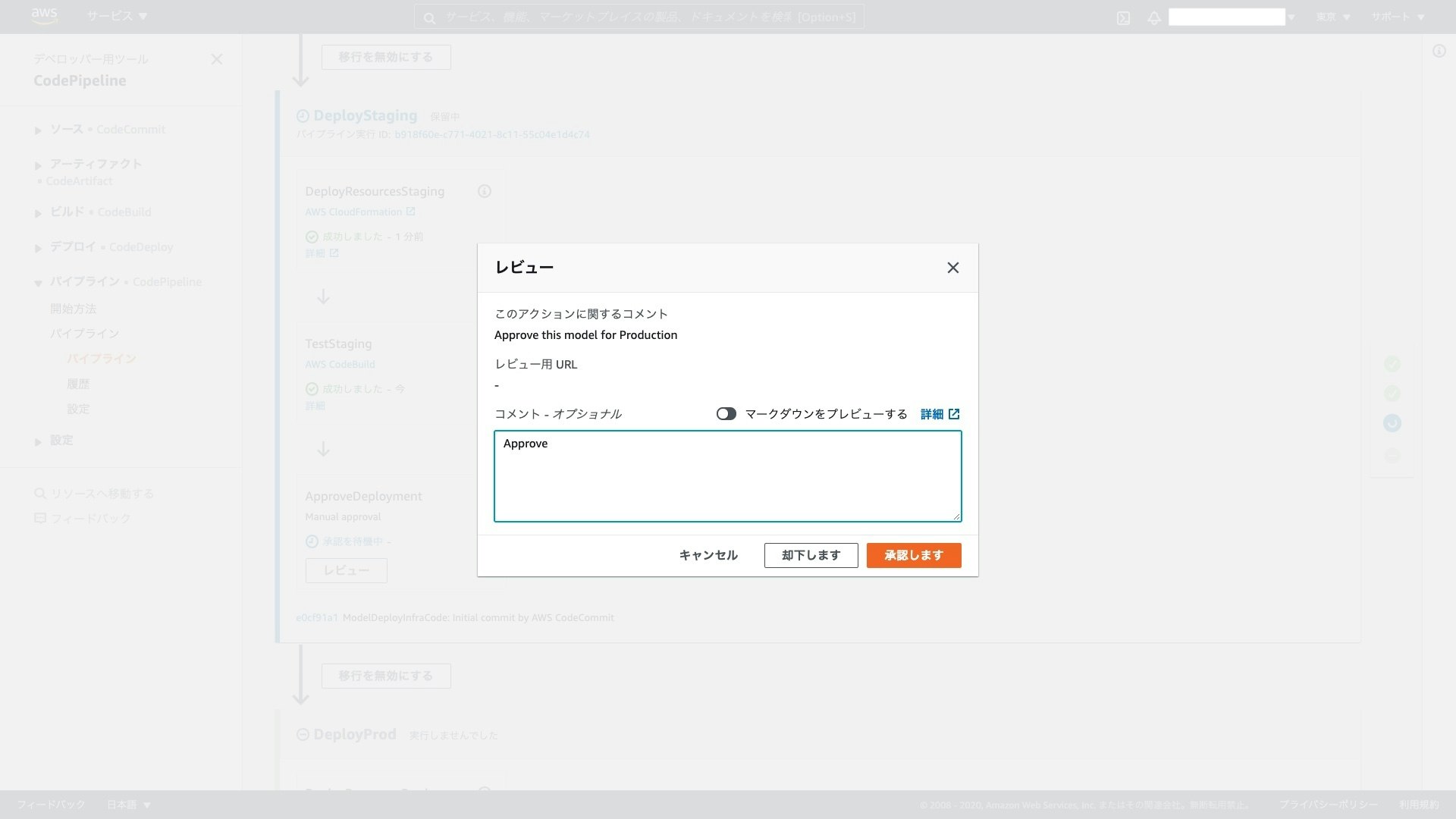
サンプルテンプレートでは単一アカウントに推論エンドポイントをデプロイして Staging および Production 環境を構成しますが、これらを個別のアカウントに切り出して、マルチアカウントに MLOps を実現することも可能です。
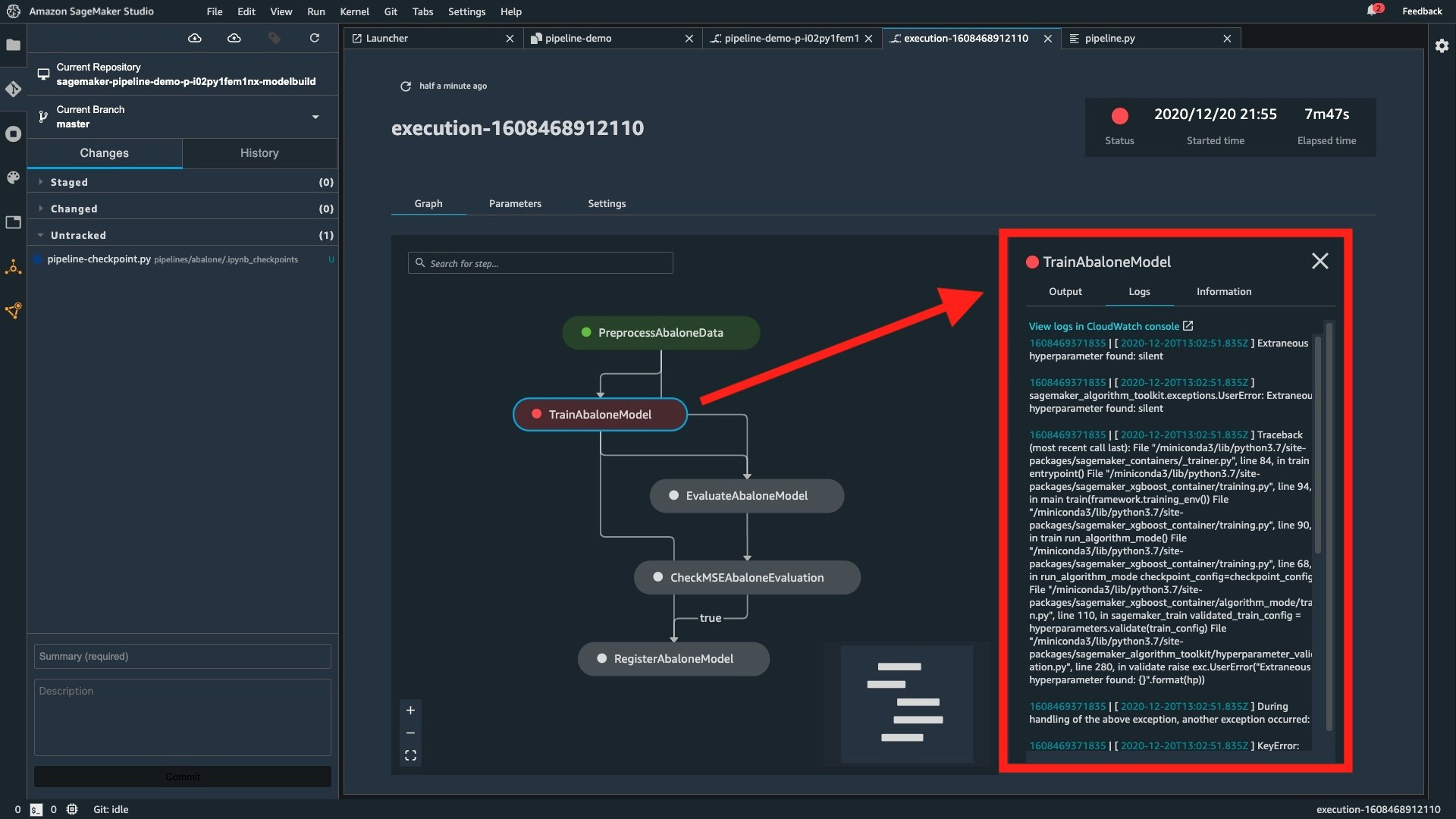
Troubleshoot ML workflows
SageMaker Pipeline では、下図のようにパイプラインの各ステップのステータスが可視化されます。CloudWatch Logs や各種メトリクスを SageMaker Studio 内で確認することができるため、トラブルシューティングを迅速かつ効率的に行うことができます。
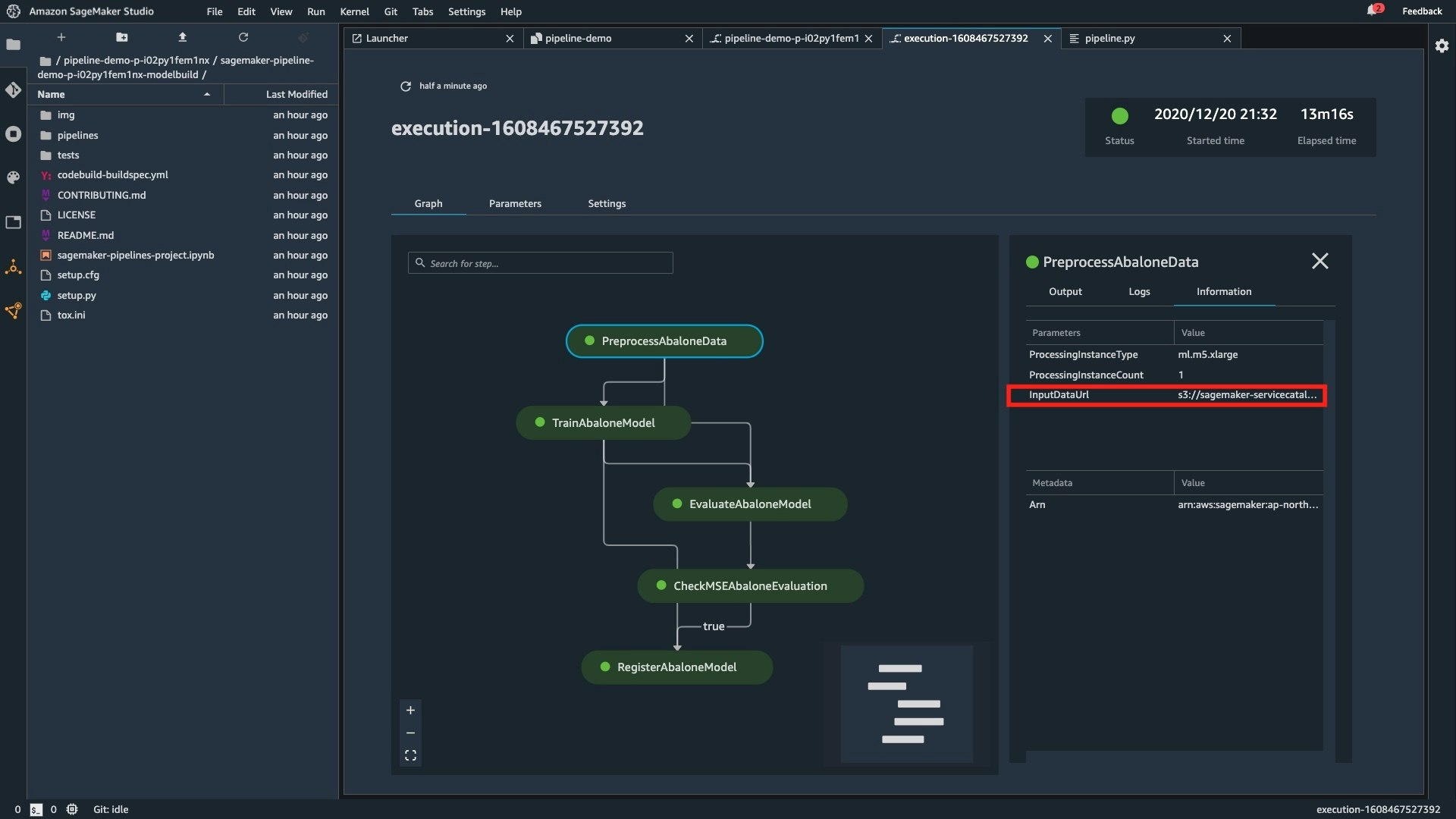
Track lineage
「データがどこから来て、どこへ行くのか?」というデータのライフサイクルを追跡することを「データリネージ」といいます。機械学習では、エンドユーザの行動履歴や購買履歴のような機微なデータを扱うことが多いため、データリネージの管理は非常に重要であると考えられます。
SageMaker Pipelines を利用すると、パイプライン内のリネージを追跡することができます。
学習ジョブなどの SageMaker が扱う基本的なコンポーネントのリネージは自動で取得されますが、独自に定義することも可能です。
まとめ
本稿では SageMaker Pipelines について、サンプルテンプレートを利用しながら概要をまとめました。カスタムテンプレートを用いるパターンなどの実践的な使い方は別途扱いたいと思います。
Advent Calendar も佳境ですが、興味深い記事がたくさん投稿されていますので、是非お読みいただければと思います。
最後までお読みいただきありがとうございました。
参考文献
本稿の執筆にあたり、下記を参考にさせていただきました。
- Amazon SageMaker Model Building Pipelines
- [NEW LAUNCH!] How to create fully automated ML workflows with Amazon SageMaker Pipelines (EMB025) ※ AWS re:Invent 2020 のセッション
- Introducing Amazon SageMaker Pipelines - AWS re:Invent 2020
- Using the Git workflow in Amazon SageMaker Pipelines - AWS re:Invent 2020