アプリケーションやサービスプロトタイプを作り、サーバ上に環境構築し動かし始めると、「今、このサーバ・ミドルウェア・アプリケーションはどんな状況にあるのだろう」と全体を俯瞰したくなる時がある。
もちろん、top したり dstat したり cat /proc/~ したり、もしくは journalctl ~ してログから見てみたり。
何かもっと手軽に全体のメトリクスをパッと見られる方法は無いものか。
この場合、真っ先に思いつくのは、いわゆる監視ツールに分類されるもの。
そこで Google で 『メトリクス 監視』『サーバ 監視』などと検索してみるが、でてくるのは ガチなやつばかり がヒットする。
それらはきっとリリース後には重要になるんだろうけど、その前段階で必要なのは、もっと手軽に色々見れるものだ。
やりたいこと
- サーバ・ミドルウェア・アプリケーションのあらゆる 『状態』を一括で見たい
- サーバのリソース情報の可視化
- ミドルウェア情報の可視化
- 作成したアプリケーションの各メトリクス
- Apdex, レスポンスタイム、エラー率、GC ...
- 環境構築自体もサクッとしたい
- ハードウェアリソースはデフォルトで
- ミドルウェアもデフォルト対応 or プラグイン導入で簡単に追加可能
- アプリケーションのクライアントが豊富・登録も簡単
- できれば、そのまま本番でも利用できればなお良い
- 通知系は不要
- slack 通知くらいはあったらいいな、程度
ガチの監視ツール
お手軽に行く前に、いわゆるガチな監視ツールというとどんなものがあるのか、ざっと並べてみる。
SaaS 系監視ツール
メトリクス監視を考える場合、最近ではまずは SaaS 系を考えるのではないだろうか。
とにかく管理が楽で、エージェント入れたらほぼ終わりが多い。
ただ、無料で制限なく利用できるものは (ほぼ) 無く、お遊びレベルのサーバにはなかなか使えなかったりする。
定番監視ツール
以下のような定番のツールも検討した。
これらツールは、情報もそれなりに豊富であり、そこそこ枯れているので安定もしている。
しかし、今回の目的からすると、
- 設定が複雑 (本格派だから仕方ない)
- ツール自体がデータベース等のミドルウェアに依存
- このツール自体の負荷もそこそこ高い
- 自作アプリケーションからメトリクスを登録しようにも手間がかかる / 方法が無い
- 新技術・新ツールに対応していないものもある
だったりして、もっと他に何か無いだろうかと思ってしまう。
最終候補
検索対象を広め『metrics monitoring』『performance monitoring』『resource monitoring』などでも検索し、良さそうなものとして以下に絞った。
- Prometheus
- Netdata
- Telegraf
● Prometheus
動的なサービス志向アーキテクチャのメトリクス収集を得意とするモニタリングツール。
https://prometheus.io/
https://github.com/prometheus/prometheus
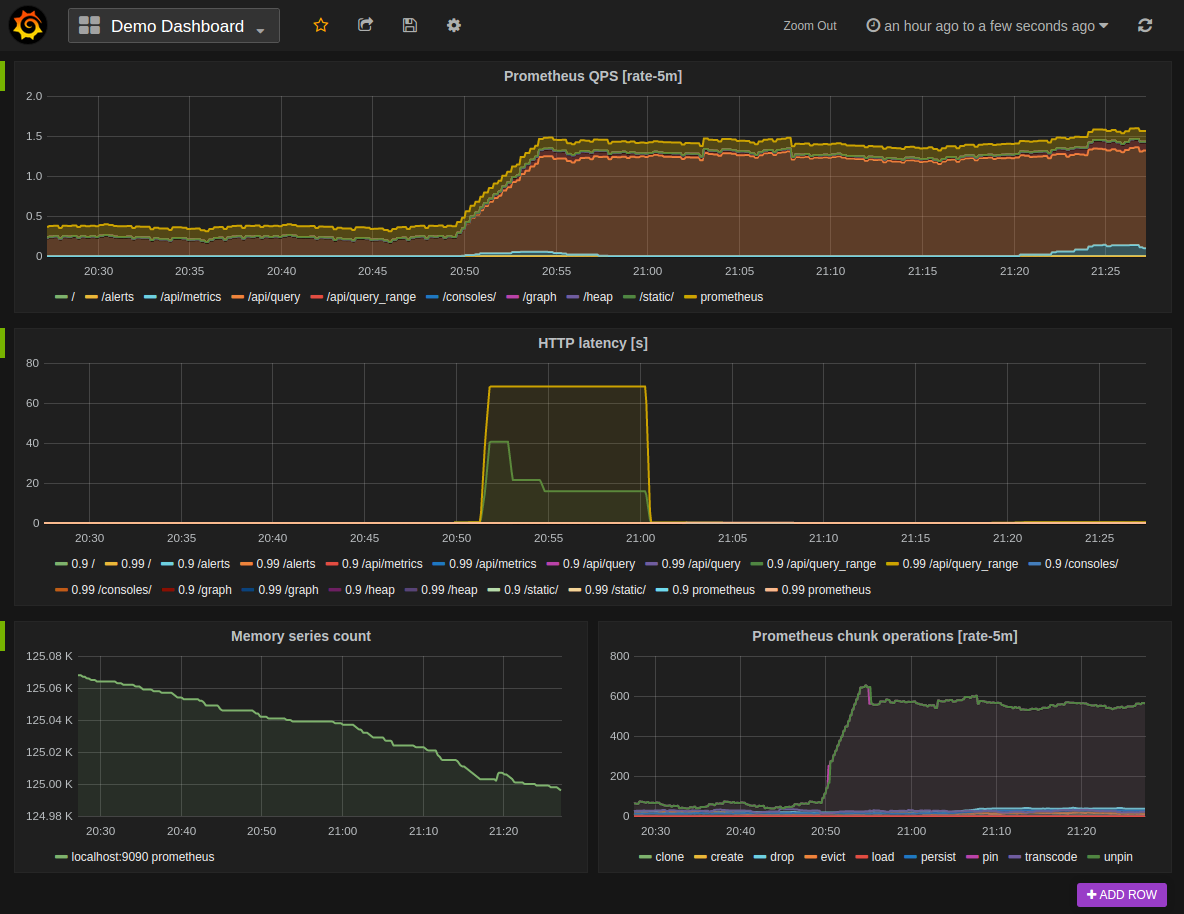
(公式より引用。Prometheus の画面ではなく、Prometheus と統合された Grafana の画面)
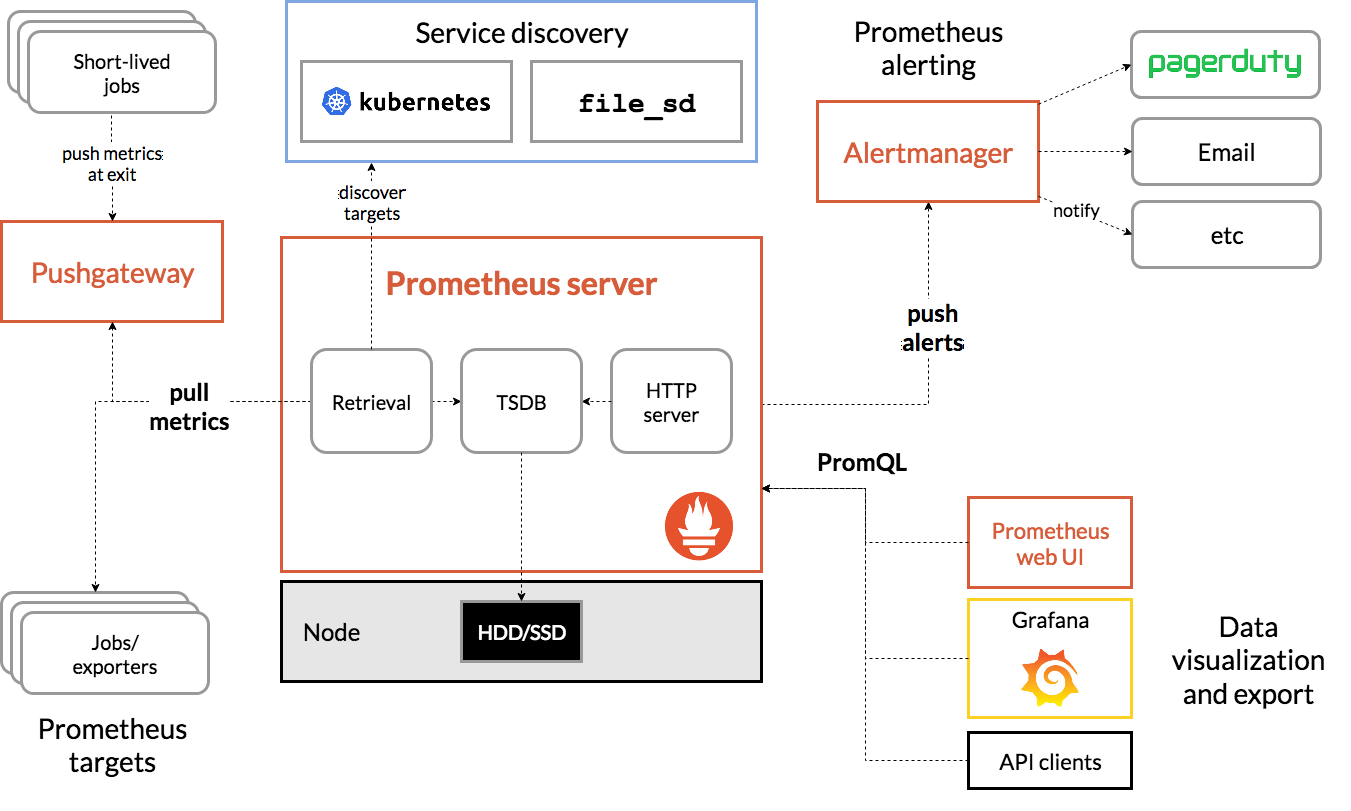
(公式より引用)
- 多次元データモデル
- メトリクス名とそのラベル ( 属性のセット ) で識別されるデータを、時間方向に蓄積
- ex.
api_http_requests_total{method="POST", handler="/messages"}- メトリクス名 : api_http_requests_total
- ラベル : method="POST", handler="/messages"
- データタイプは、4種類
-
counter- インクリメンタルな数値 -
gauge- 普通の数値 -
histogram- bucket ( ラベルに対する範囲指定 ) 毎の発生回数 or 合計 -
summary- クライアントサイドによるストリーミング集計
-
- 独自のクエリ言語をもち、そのクエリ結果を視覚化できる
- ラベルによるフィルター
-
sumやavgなどの集計 - 論理演算子と算術演算子
- Pull 型の収集 ( 詳細後述 )
- 静的な収集対象の指定
- サービスディスカバリによる動的な収集対象の指定
- 独自のデータストアを内包し、外部ストレージに依拠しない
- 組み込みの Web UI で最低限の視覚化が可能
- 本格的ダッシュボードを求めるなら Grafana との統合も
- バイナリでデプロイでき、外部依存がない
元々はコンテナの監視用途でよく採用されていたイメージだったが、今では用途問わず広く利用される監視ツールになったようだ。
自分は、本格的な監視ツールを導入するならまず第一候補として考える。
構築の手軽さ
バイナリ 1 つでデプロイが可能 というのはとても大きい。
$ wget https://github.com/prometheus/prometheus/releases/download/v2.5.0/prometheus-2.5.0.linux-amd64.tar.gz
$ tar xvfz prometheus-2.5.0.linux-amd64.tar.gz
$ cd prometheus-2.5.0.linux-amd64
$ ./prometheus
メトリクス収集
Prometheus は、Pull 型の収集 を行う。
これは、メトリクス公開側が HTTP エンドポイントを設けて待ち受けし、Prometheus 側が一定間隔でそこにアクセスして収集していくという収集モデル。
これにより、メトリクス公開側はエンドポイントを設けるだけで済み、接続情報管理や過負荷時の対処等の面倒事はすべて考慮する必要がなくなる。ただそれ故に Prometheus 側は収集対象を知っている必要があり、クラスタのサイズによっては kubernetes や Consul などのサービスディスカバリに頼らざるを得ない。
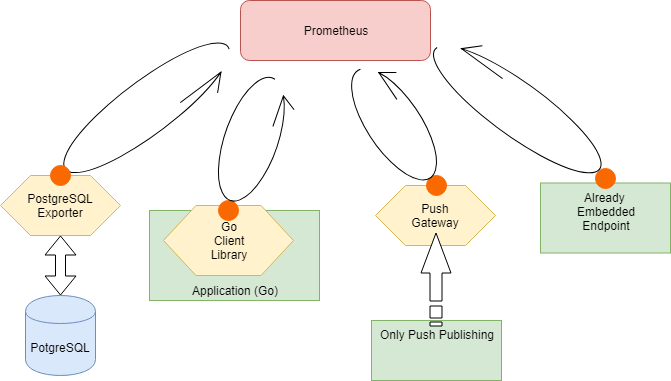
このメトリクスを公開するためのツールを、Exporter と呼ぶ。
1. サーバ (ハードウェア) メトリクス
サーバリソースメトリクスを収集するためには、node-exporter が公式に提供されている。
github.com/prometheus/node_exporter
基本的なメトリクスはこれで十分だったりする。導入もバイナリ置いてサービス化するだけ。Docker ならもっと楽に導入できる。
$ wget https://github.com/prometheus/node_exporter/releases/download/v0.17.0/node_exporter-0.17.0.linux-amd64.tar.gz
$ tar xvfz node_exporter-0.17.0.linux-amd64.tar.gz
$ cd node_exporter-0.17.0.linux-amd64
$ ./node_exporter
2. ミドルウェア
ミドルウェア対応も充実している。
Third-party exporters - Docs
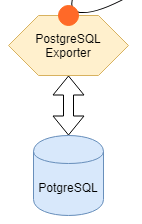
例えば、PostgreSQL のメトリクスを収集するためには、 postgres_exporter を配置して接続情報を指定して動かすだけ。
コンテナなら、サイドカーパターン的に寄生させる感じなのかな。
$ wget https://github.com/wrouesnel/postgres_exporter/releases/download/v0.4.7/postgres_exporter_v0.4.7_linux-amd64.tar.gz
$ tar xvfz postgres_exporter_v0.4.7_linux-amd64.tar.gz
$ cd postgres_exporter_v0.4.7_linux-amd64
$ export DATA_SOURCE_NAME="postgresql://login:password@hostname:port/dbname"
$ ./postgres_exporter
また、ミドルウェア自体に Prometheus 向けのメトリクス公開エンドポイントを持つものもいくつか存在する。
Software exposing Prometheus metrics - Docs
やはりコンテナ系やオーケストレーション系、分散ストレージ等が多く、その辺の用途で使われているんだなぁと実感。
3. アプリケーション
アプリケーションにメトリクス公開のエンドポイントを追加するには、クライアントライブラリを組み込むのが早い。
Client Libraries - Docs
例えば、Go 言語であれば、公式に クライアント が提供されている。
import (
"net/http"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
func main() {
http.Handle("/metrics", promhttp.Handler())
http.ListenAndServe(":8080", nil)
}
また、Prometheus の Pull リクエストを待つ間に起動 ~ 終了してしまうようなライフタイムの短いタスクは、PushGateway を噛ませる事で収集対象とすることができる。
ついでにアラーム
Prometheus 本体にはアラーム機能はない。
AlertManager という独立したサービスを導入し、連携させる必要がある。
● Netdata
設定せずとも対象を自動で検出・勝手にメトリクスを収集する、高速で効率的なリアルタイム志向の監視ツール。
https://my-netdata.io/
https://github.com/netdata/netdata

(公式より引用)
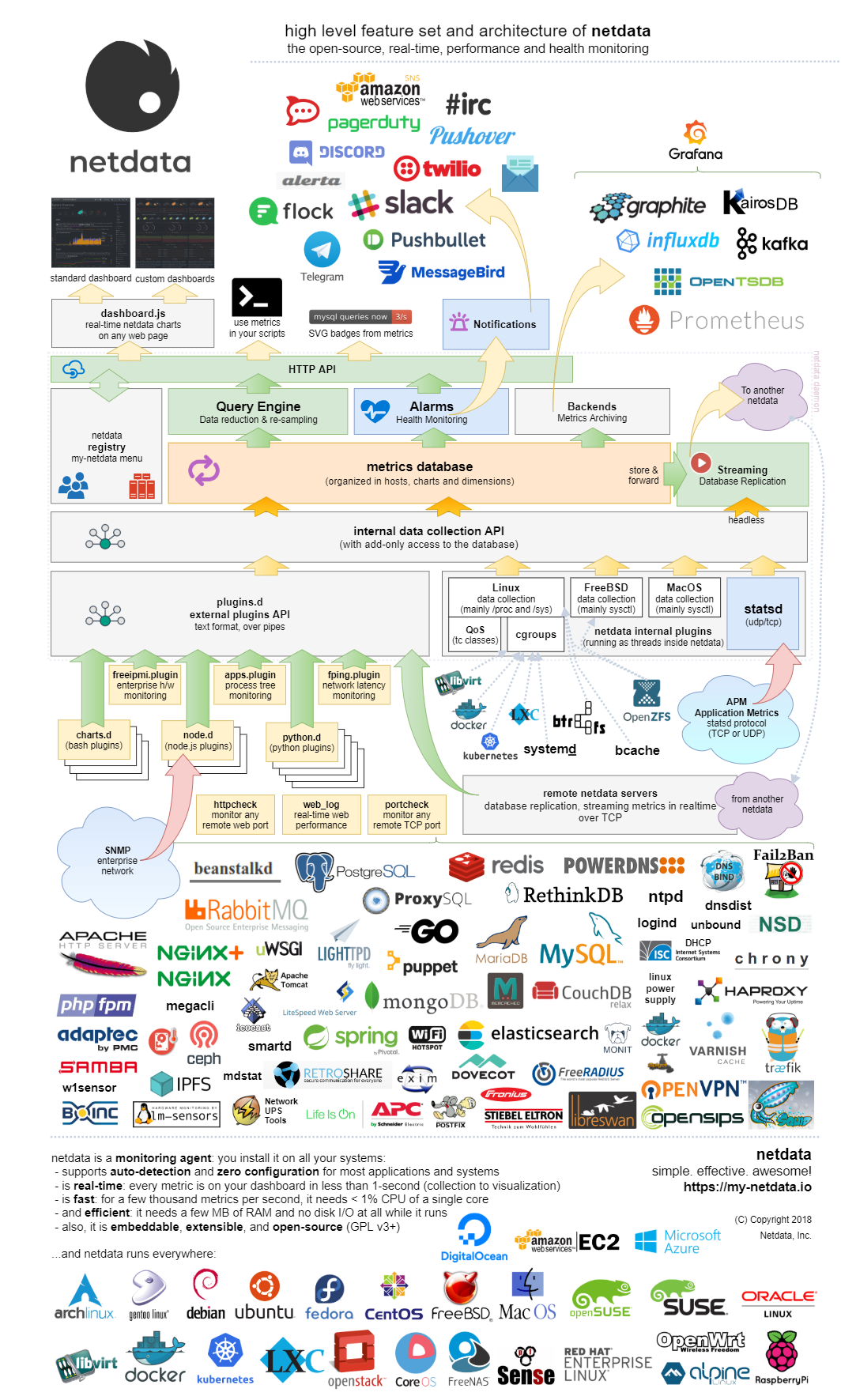
(公式サイトのインフォグラフィック のキャプチャ)
- 1秒データを収集
- デフォルトの保存期間は 1 時間
- リアルタイム監視に特化
- 収集可能なメトリクスは自動で検出して全て収集
- 高速、高効率
- CPU : コア 1 つの 1% まで
- Memory : デフォルトで 25MB ( これで約1時間保存可能 )
- Disc IO : なし
- 依存なし
- バイナリ一つというわけではない
サーバパフォーマンスを監視するツールと勝手に思い込んでいたが、実は様々なアプリケーション・ミドルウェアのメトリクスにも対応していた。
自分はサーバ作ったら、取り敢えず入れている。
構築の手軽さ
コマンド一つで導入は可能。
$ bash <(curl -Ss https://my-netdata.io/kickstart.sh)
メトリクス収集
Netdata は、基本的には監視対象を自分で設定する必要はない。
インストールされているアプリケーション・ミドルウェアや利用状況を自動で識別し、勝手に収集対象を決める。
What does it monitor - Netdata Documentation
収集はプラグインが担当し、拡張も可能だ。
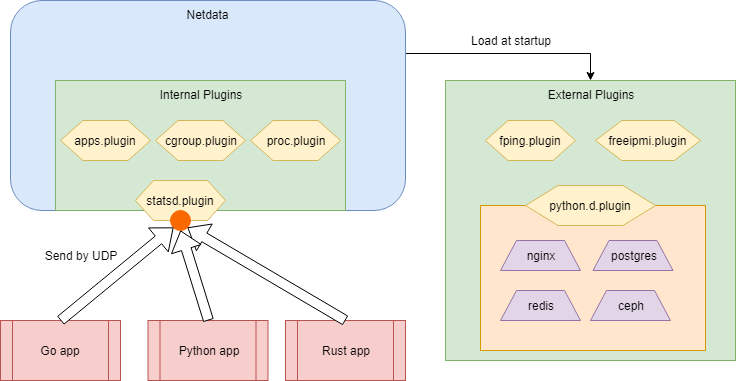
注意する点として、すべてのメトリクスは1秒間隔で収集され、内部に持つラウンドロビンデータベースにデフォルトで 1 時間分だけ蓄積する ( 収集周期、蓄積容量ともに設定変更可能 )。
まさに、リアルタイムなメトリクス を見るためのツールだ。
1. サーバ (ハードウェア) メトリクス
インストールするだけで、サーバメトリクスは自動で収集される。
これらのほとんどは、internal plugins と呼ばれる本体に組み込まれたプラグインによって収集される。
- apps.plugin - Netdata Documentation
- proc.plugin - Netdata Documentation
- cgroups.plugin - Netdata Documentation
一部、デバイス系やネットワーク系のメトリクスは external plugins と呼ばれる本体からは独立したプラグインによって提供されるものもある。
- fping.plugin - Netdata Documentation
- freeipmi.plugin - Netdata Documentation
- SNMP Data Collector - Node modules - Netdata Documentation
2. ミドルウェア
驚きなのが、ミドルウェアのメトリクスも設定無しで勝手に収集対象を判定してくれること。
既存のプラグインで対応可能なミドルウェアのみ監視するのであれば、本当に設定無しで利用できる。
例えば、PostgreSQL を監視するなら、何もしなくてもやってくれる。
対応ミドルウェアの追加
もし、対応するプラグインがない場合はどうするか。
ミドルウェア収集は主に external plugins と呼ばれる本体からは独立したプラグインによって提供される。
その中にある、python.d.plugin, node.d.plugin, charts.d.plugin は少し特殊。
それ自体が Netdata のプラグインであるが、自身もプラグイン機構を持つプラグインである。
これにより、馴染んだ言語で拡張を書けるという意味でプラグイン導入の敷居を下げている。
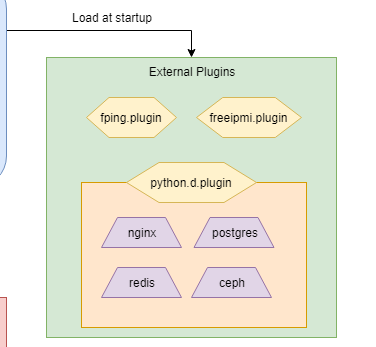
対象ミドルウェアを増やすには、python.d.plugin や node.d.plugin の子プラグインを作るのが一番早そうだ。
実際のプラグイン を真似れば、案外簡単にできそう。
議論中のミドルウェア
また、他のメトリクス収集ツールと比較して足りないモジュールが以下にまとめらているが、その多くが Issues を立てられ議論されており、これからも意欲的に対応アプリケーション・ミドルウェアを増やしていくようだ。
https://github.com/netdata/netdata/issues/4574
例えば JMX 対応はここ 1 年、熱く議論がなされ続けている。
3. アプリケーション
1, 2 までは本当に Zero Configuration で対応できたが、自作のアプリケーションに組み込もうとすると少し手間がいる。
Netdata は、 StatsD と API 互換のサーバ機能を internal plugins として持っているので、通常はそれを利用する。
StatsD
StatsD は、アプリケーションからのメトリクスを集約して収集し、Graphite 等時系列データベースへ送る、いわば中継サーバ。
https://github.com/etsy/statsd
- 独自プロトコル
- 通常は UCP を使う ( TCP も可能 )
- 接続不可時でもクライアント側にエラー対策が不要
- データタイプは、4 種類
-
counting- 回数 ( StatsD 上で rate 計算 ) -
timing- 経過時間 ( StatsD 上で Uppser/lower bound, mean, percentile, count を計算 ) -
gauge- 統計処理されない数値 -
set- キーに渡されたユニークな値の発生頻度
-
- クライアントライブラリが豊富
- アプリケーションメトリクス収集のプラットフォームとしては非常にポピュラー
- Datadog では StatsD 互換の agent を提供
- NewRelic では NerRelic agent をバックエンド化する npm パッケージを提供
- 実際にポピュラーなのは、実装ではなくプロトコル?
- その割に日本語のまとまった情報がとても少ない
例えば、Go 言語であれば、いくつかクライアントライブラリが存在するが、今回はこれ を使って、
import (
"net/http"
"time"
"fmt"
"runtime"
statsd "github.com/smira/go-statsd"
)
func main() {
client := statsd.NewClient("localhost:8125",
statsd.MaxPacketSize(1400),
statsd.MetricPrefix("app.web."))
defer client.Close()
http.HandleFunc("/hello", func(res http.ResponseWriter, req *http.Request) {
start := time.Now()
client.Incr("requests.http", 1) // count
client.SetAdd("requests.user", user.Id) // set
// ...
fmt.Fprint(res, "Hello")
client.PrecisionTiming("requests.route.api.latency", time.Since(start)) // timing
})
client.Gauge("goroutine.count", runtime.NumGoroutine()) // gauge
http.ListenAndServe(":8080", nil)
}
こんな感じに書ける。
接続先問題
Prometheus とは違い Push 型の収集となるため、全てのアプリケーションが接続先を知る必要がある。
StatsD では、通信プロトコルに UDP を利用することで、接続不可時のエラー対策が不要となるので、相手がいるかどうかに神経質になる必要はない。
が、接続ができないならメトリクスは集められず意味がない。結局、アプリケーション側に接続先をコンテキストに合わせ変更する機構は必要だ。
ついでにアラーム
アラーム機能も組み込まれている。
リアルタイム監視がメインなので、異常時にはアラートを発生させるというのは合理的。
● Telegraf
TICK stack の一角をなす、プラグインベースの王道監視ツール。
https://www.influxdata.com/time-series-platform/telegraf/
https://github.com/influxdata/telegraf
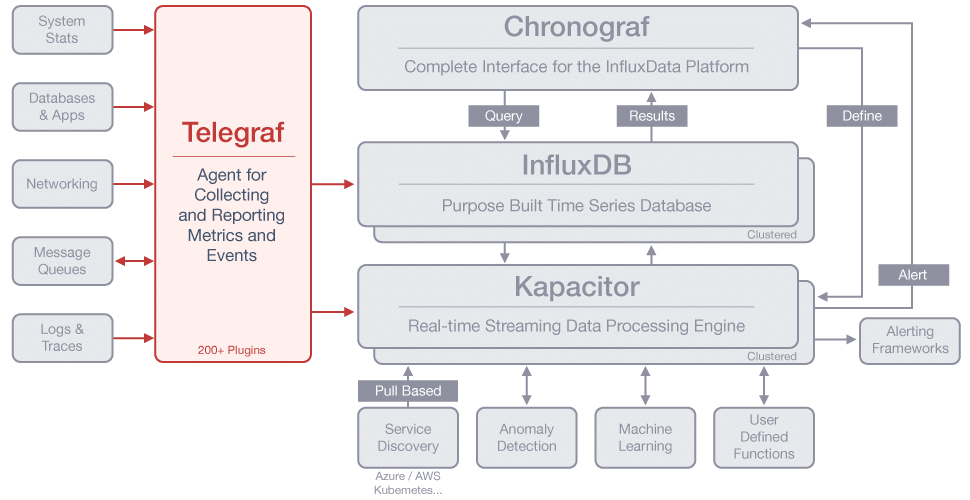
(公式より引用)
-
Inflaxdata が提供する TICK stack の一角
- Telegraf - メトリクス収集
- InfluxDB - 時系列DB
- Chronograf - 可視化
- Kapacitor - Stream processing
- とはいえ、InfluxDB 以外へもアウトプットできる
- でも、通常は InfluxDB を使うと思う
- プラグインベース
- メモリフットプリント小さい
- バイナリでデプロイでき、外部依存がない
元々は、InfluxDB が時系列 DB としてとても魅力的だったので、その流れで Telegraf を知ったという経緯がある。
今回の用途に対してはデカすぎるスタックではあるが、一度構築して使い心地を知りたくもある。
選定結果
理想的には、開発段階では Netdata 使って、次第にマジになってきたら Prometheus を使う こと。
本当はどちらか一つが良いとは思うが。
それを実現するためには、
- アプリケーションを StatsD に対応させ、Prometheus 対応は StatsD Exporter を使う
- アプリケーションを Prometheus に対応させ、Netdata に Prometheus Exporter のフォーマットを読むことができるプラグインを追加する
のどちらか。
1. アプリケーションを StatsD に対応のパターン
- 利点
- 何か特別なものを作る必要はない
- 欠点
- Prometheus のクライアントライブラリが持つ機能が使えない
- ライブラリがデフォルトで必要そうなメトリクスをあらかじめ収集してくれるものが多い
- 全体的に、StatsD より Prometheus の方がクライアントライブラリの質が高い ( 印象 )
- Prometheus 特有のデータ (属性) が使えない可能性
- Summary や Histgram データは対応できない
- Label は、DogStatsD 形式で送った Tag を変換することで対応できる
- Prometheus のクライアントライブラリが持つ機能が使えない
そして何より、公式があまり推奨していない感じ
We recommend this only as an intermediate solution and recommend switching to native Prometheus instrumentation in the long term.
(多分、意味合い的には 『既に StatD が動いている場合は、これを Backend に使ってください。とはいえ、この Exporter があるからとアプリケーションに StatsD のクライアントライブラリを入れるのは推奨しません。Prometheus のクライアントライブラリを使ってください』みたいな感じだろうか)
2. アプリケーションは Prometheus に対応のパターン
- 利点
- Prometheus のクライアントライブラリが使える
- Prometheus の機能がフルに使える
- 欠点
- Netdata のプラグインを作成する必要がある
- 開発段階だけ利用するという意味では、デプロイや長期運用は深く考えなくて良さそう
- Netdata のプラグインを作成する必要がある
何となく、後者の方が良さそう。
ということで、2 の方針でやってみようと思っています。
感想
DevOps というと、Branch strategy, CI, Deploy, Infrastructure as Code, Container, Orchestration, Log Aggregation とかその辺ばかりに目が行ってしまっていたが、もう一つ重要な要素としての Monitoring についても、もう少し関心を持たねばと思った。
Prometheus や Netdata には Dev と Ops をつなぐ力があると感じたので、バシバシ使っていきたい。
あと、InfluxDB 好きなので Telegraf ももっときちんと調べたい。
ぜひ、Twelve-Factor App の 13 個目にメトリクス監視に対する方針を追加して欲しい。
あとがき
※ この記事は個人の見解であり、所属する組織を代表するものではありません。