はじめに
AIを運用する方法として、ChatGPTやClaudeなどのクラウド型サービスが主流となっています。クラウド型はインフラ設備無しで運用できるため手軽に始められます。ChatGPT等の場合はサイトにアクセスするだけで使用可能なお手軽さがあります。しかしながら、これらのサービスでは
- AIに送信したデータに対する秘匿性の課題
- サーバーはどこの国にあるのか?実行中の一時データはどこに保存している?
- 問い合わせ内容を学習されないか?
- 従量課金制で料金が読みにくい
- 出力に検閲が入りやすく出せる内容に制限がある
等、ビジネス上で使用する際の課題があります。
そのため、特に「外部に流失してほしくない情報」を含む場合にはローカル環境で実行するのが望ましいこともあります。
一方でローカルモデルの場合、現行のクラウド型AIと比較して性能が低い傾向にあります。
たとえば、ローカルAIを動かそうとしている方の記事を見てみると、
- ハイスペックGPUを搭載したハイエンドデスクトップが必須
- H100というGPU1枚だけで実行可能(このGPUは1枚数百万円)
等の話が多いために、実行にはサーバーなど高額な環境が必要でLLMの導入にはハードルが高いと感じられるでしょう。
しかし、エッジデバイス向けに軽量化されたモデルを開発している事例もあり、スマホやノートパソコンでも動作を想定したモデルが存在します。
今回は、LLMには不向きだと思われるような「一般的なノートパソコン」でどこまでLLMが活用できるのか、「レシートのスキャン」というテストケースをもとに考察していきます。
量子化の話
AIモデルをノートパソコンで実行するにあたり、課題になるのがモデルサイズです。例えばGPT-OSSの120Bではおよそ60-70GBのモデルサイズです。実行するにはそれに加えてコンテクスト分のメモリも必要なるため
- モデルサイズ+α(コンテキスト分のメモリ)
このサイズのメモリが求められます。一般的なノートパソコンのメモリは16GBで増設交換できないモデルが多いです。ストレージから逐次読み込みで動作させることも理論上可能ですが、実行速度が現実的ではありません。
今回の場合、OSなどもメモリを使用するため実質的には8GB程度のモデルがノートパソコンの上限と考えられます。
※ノートパソコンの場合内臓グラフィックを用いて計算を実施します。5年以上前の古いノートPCの場合こちらの性能が大きく劣っており、実行速度に大きな差が出る場合あります。
一方でモデルサイズが小さいとパラメータが少ないために性能が落ちるという課題があります。このジレンマを緩和する方法として量子化が用いられます。
下の図は実際に量子化をした例です。
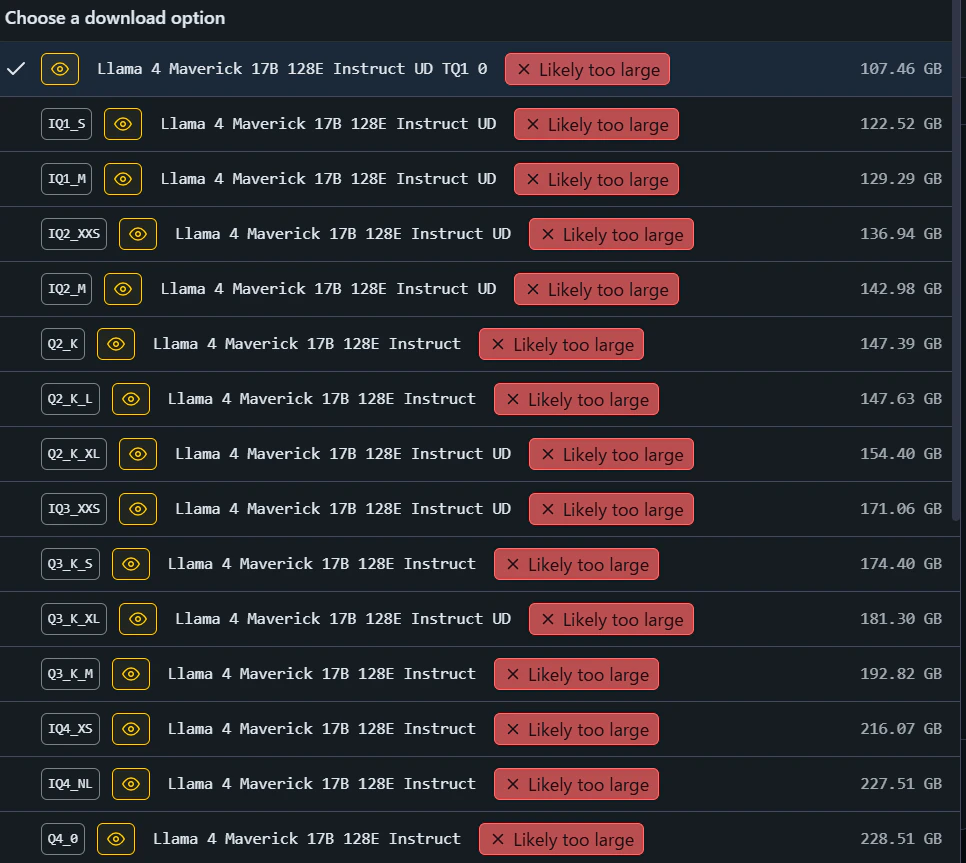
元々のモデルサイズは16ビット符号化状態で800GB程度あり、非常に巨大なモデルです。しかしながら量子化モデルでは図表にあります通り4ビット量子化で228GB、1ビットまで圧縮すると107GBになります。
量子化というのは符号長をうまく短くしてデータサイズをコンパクトにするというのが大まかな流れなのですが、情報量を減らしたら精度が落ちるのではないかという懸念があります。しかしながら量子化による劣化は4ビット程度までは軽微であることが知られており、データサイズの圧縮の際には4ビットバージョンが見られます。
以下はモデルの正確さと量子化度合いを表にまとめた図となります。
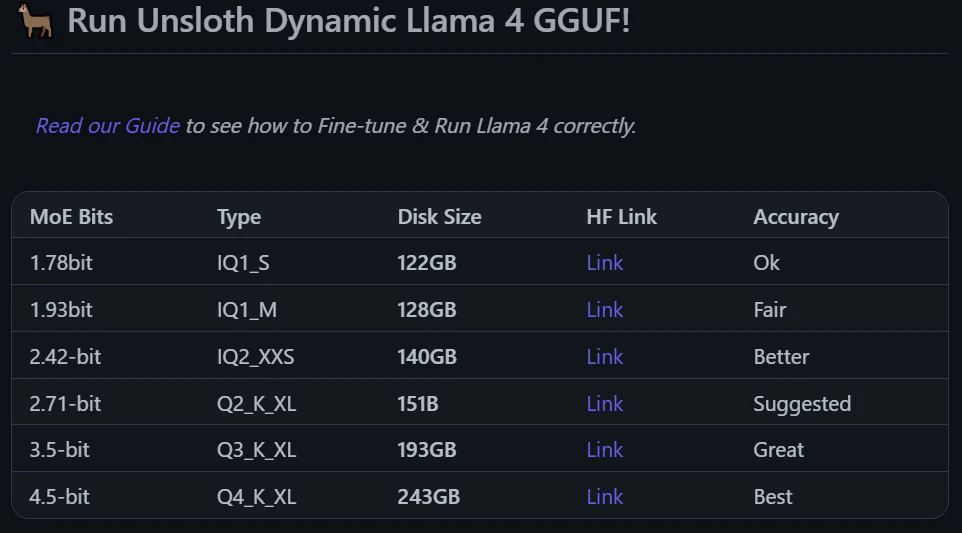
OKやBestといった基準は人それぞれに感じる面はありますが、4ビットを下回る付近から圧縮に対する劣化が顕著に出ることが知られています。
このため、データサイズの圧縮を行うことによる性能とモデルサイズのバランス調整は、主に4ビット量子化を用いることで進める方針が有効です。(AIプロバイダーソフト側でも4ビット量子化前後のモデルをデフォルト値にしている場合あり。)
実際にやってみる
実行環境について
今回はノートパソコンと家に余っていたRTX4090(24GB)搭載デスクトップパソコンを利用してLLMの性能調査を実施しました。「ノートパソコンでどこまで処理できるか」という観点に主眼を置き、デスクトップパソコンはノートパソコンで出来なかった処理の代替や、速度差の比較検討のために補助的に使用します。
なおノートパソコンはWindows環境で動作させるが、デスクトップPCではサーバーなども想定しUbuntu環境を用いて実施しました。
AIモデルの実行環境としてLMStudioを採用しました。採用した理由は以下の通りです。
- セットアップが簡単(Windowsだとインストーラー入れるだけ、Linuxではダウンロードした実行ファイルを動かすだけ)
- 11月のアップデートで画像入力時のピクセル上限が上げられるようになった
- Ollama等は現在1000×1000程度の画像を入力すると自動で縮小され、情報が失われる仕様
- つまり高解像度の画像を取り込んでも情報が失われにくい(画像サイズが大きいとトークンが増えるのでマシンスペックと要相談)
- Ollama等は現在1000×1000程度の画像を入力すると自動で縮小され、情報が失われる仕様
- アプリ内でモデルのダウンロードなどの管理もできるため視覚的に操作しやすい
今回はLMStudio上でモデルを動かして結果を確認する方法により実施をします。
調査方法
今回はノートパソコンで動くことを前提とした軽量LLMと、一般モデルを量子化した少し大きいLLMで実施をいたしました。
実験には次のモデルを利用しました。
1. gemma-3n-e4b
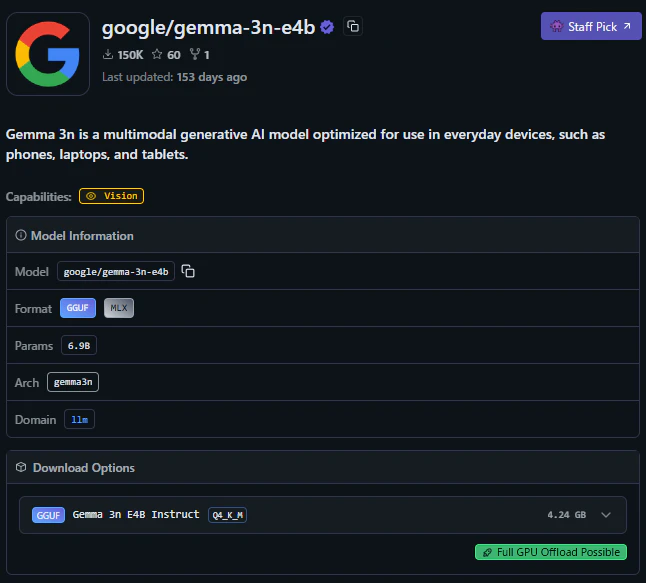
Gemmaはモバイルや軽量環境向けに設計されたモデルです。モデルサイズが小さく、メモリやCPU、GPUの制約があるノートパソコンでも比較的快適に動作します。省リソースでありながら、その割には性能が高いという評判です。
2. qwen3-vl-8b
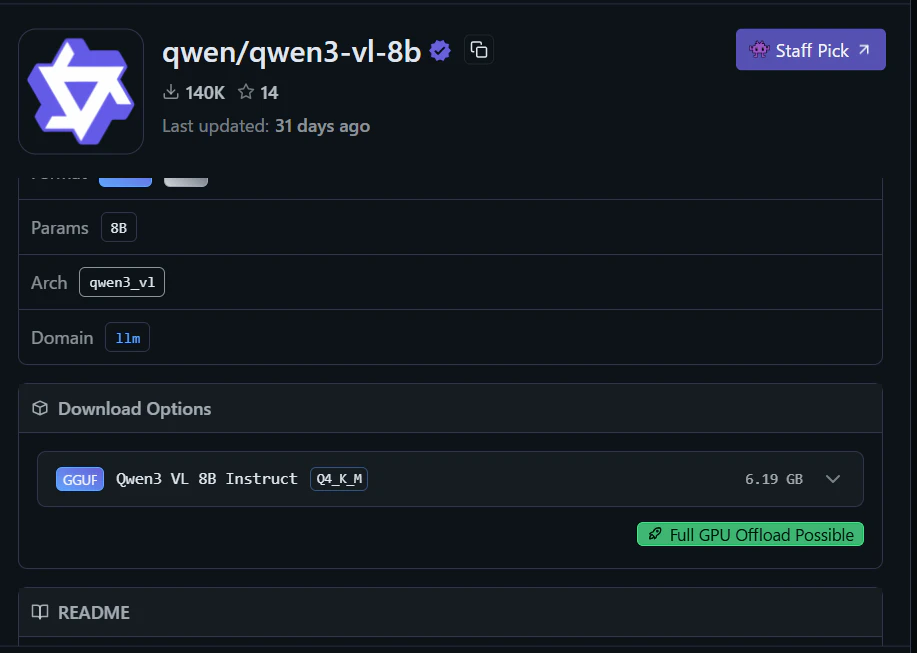
Qwen3はGemma-3n-e4bよりもやや大きなモデルで、性能面ではより高精度な処理が可能です。ただし、モデルサイズが大きいため、動作にはより多くのメモリと計算能力が必要です。
3. gemma-3-27b
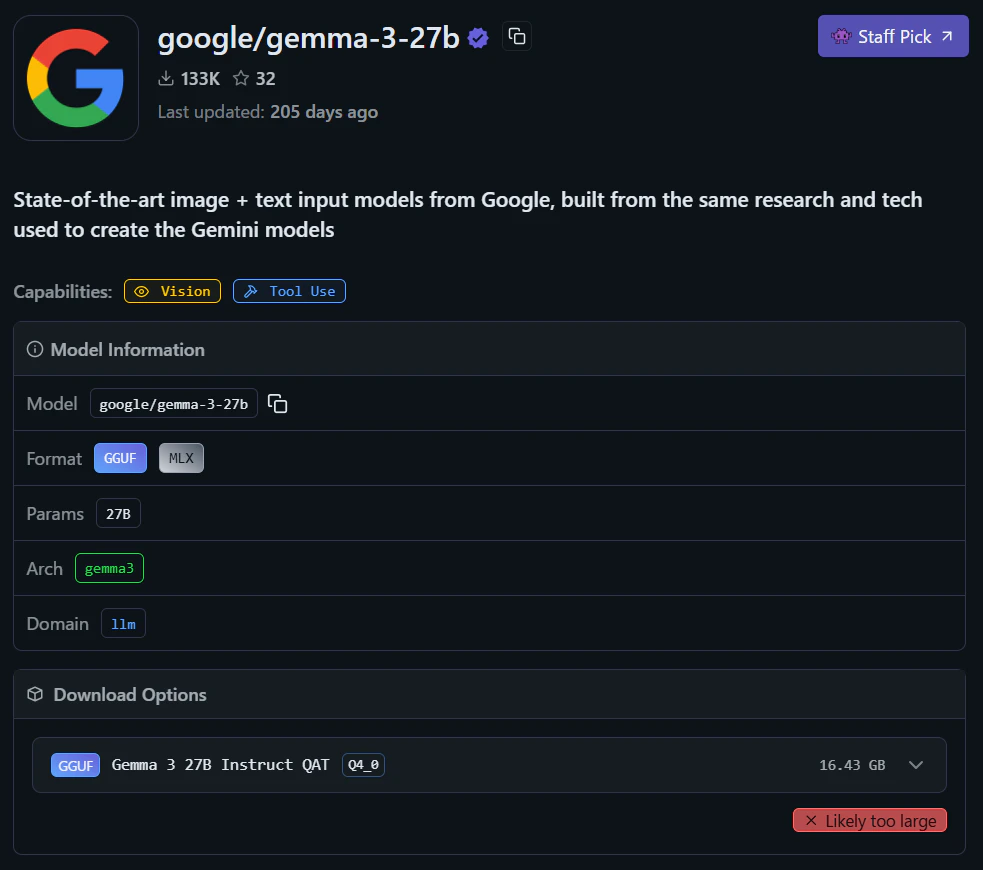
先ほどのe4nと比べて大幅にスケールアップしているモデルです。ただしサイズが大きいためエッジデバイスでは動作が難しいので、デスクトップ向きです。
4. qwen3-vl-30b
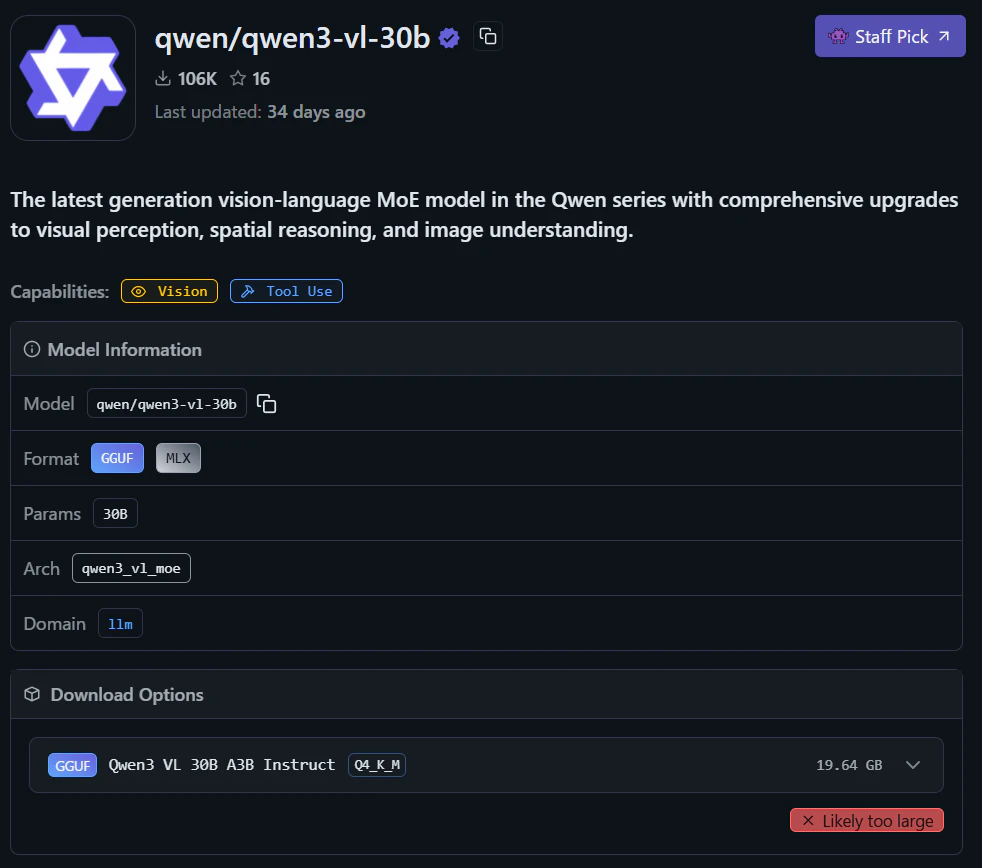
先ほどの8Bモデルより大規模なバージョンです。性能は高い代わりにサイズも大きいのでデスクトップ向きです。
今回は1,2のモデルをノートパソコンで使用し、2,3,4のモデルをデスクトップで使用します。
実験手順
LMStudioを用いて、プロンプトの項に示すテキストをそのまま張り付けて、画像とセットでAIに送信します。この結果を比較検討することにより性能を調査します。
プロンプト
次のレシート画像またはテキストを解析して、以下の形式で結果をまとめてください。
出力は必ずMarkdownの表形式で出力してください。
【出力フォーマット】
### 店舗情報
店名:◯◯◯(レシートから読み取った店名を記載)
### 商品一覧
| 商品名 | 税込み金額 | 税率 |
|--------|--------------|------|
| (商品A) | (金額) | (税率) |
| (商品B) | (金額) | (税率) |
### 合計情報
| 合計金額 | 内税 |
|-----------|-------|
| (金額) | (金額) |
### 決済方法
(レシートに記載された決済方法)
【出力条件】
- レシートに書かれていない情報は「不明」と記載。
- 金額は数値と「円」を必ずつけて表示。
- 商品が複数ある場合は全て列挙。
- 表以外の余分なコメントは書かない。
ノートパソコン上での実行結果
コンビニのレシート
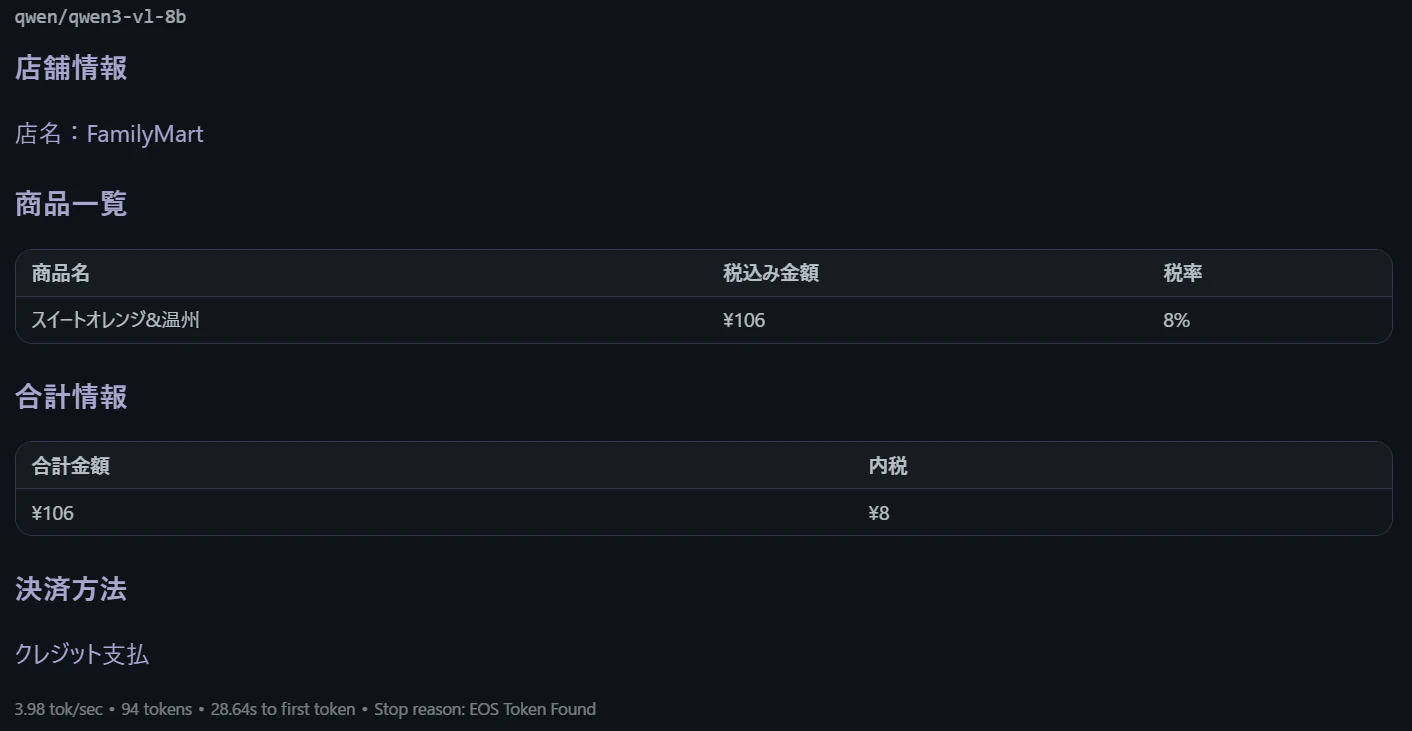
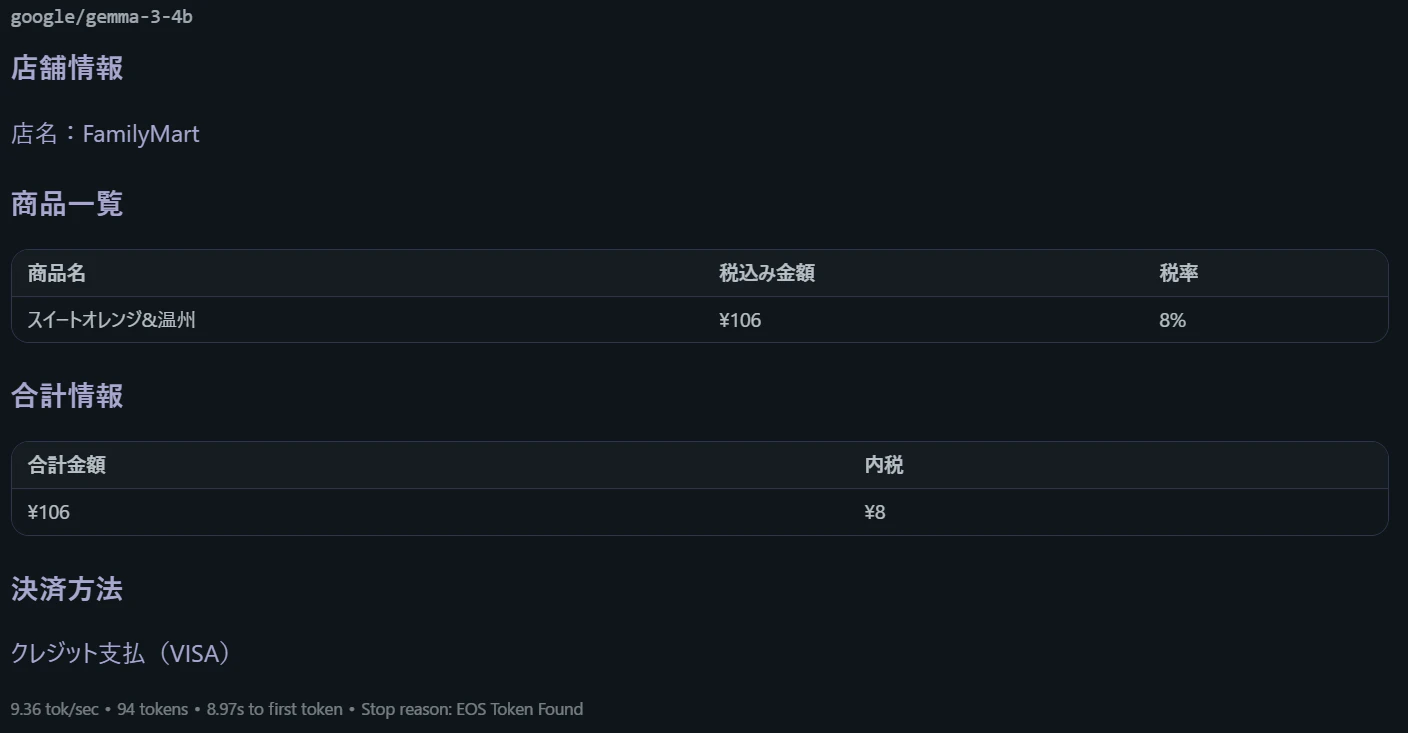
コンビニのレシート2
qwen3-vl-8b


サイゼリヤのレシート(上記二つのレシート画像より高解像度の画像を使用)
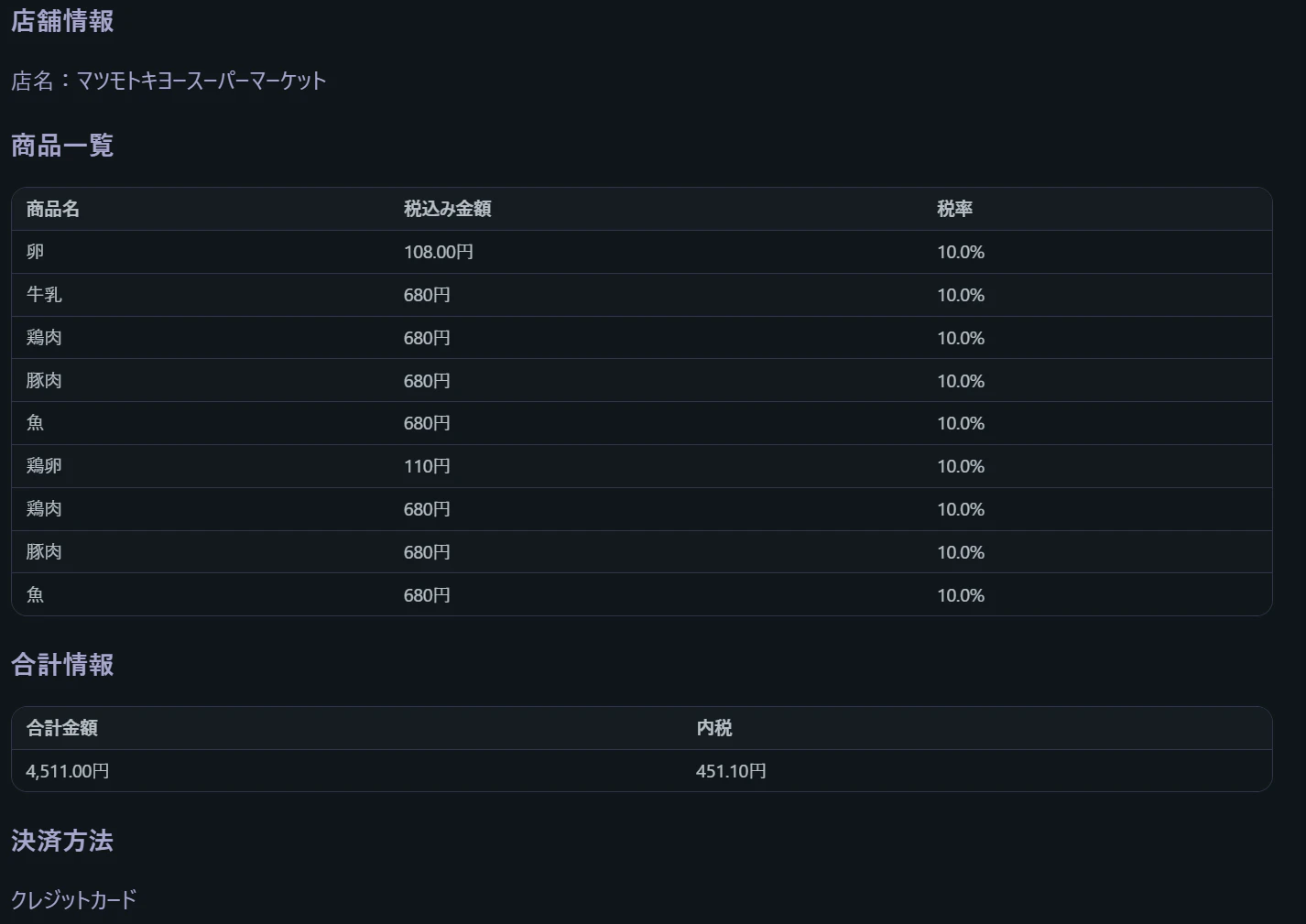
gemma3では明らかに画像を読み込まず妄想して出力している結果となりました。
※Qwenの方は処理が終わらず失敗したのでスクリーンショット無しです。
デスクトップパソコンでの実験結果
デスクトップ上でそのままモデルを読み込む際にエラーが発生しました。
エラーの内容はコンテクスト長の上限である4096を超過するので処理できないというものでした。
そのためまず、コンテクスト長の延長をモデルの設定から実施しました。
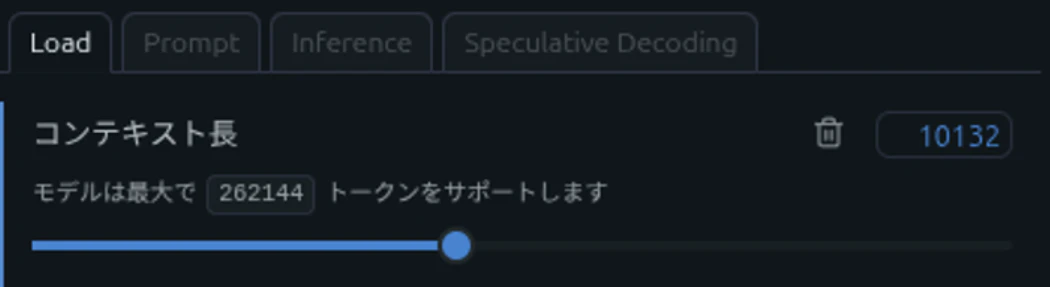
なおコンテクスト長の上限はモデルにより異なります。一般的長いほど多くの情報をまとめて処理できるとされています。今回の場合は5000程度必要であることがわかっており、コンテクスト長の上限を大きくしました。
結果を以下に示します。
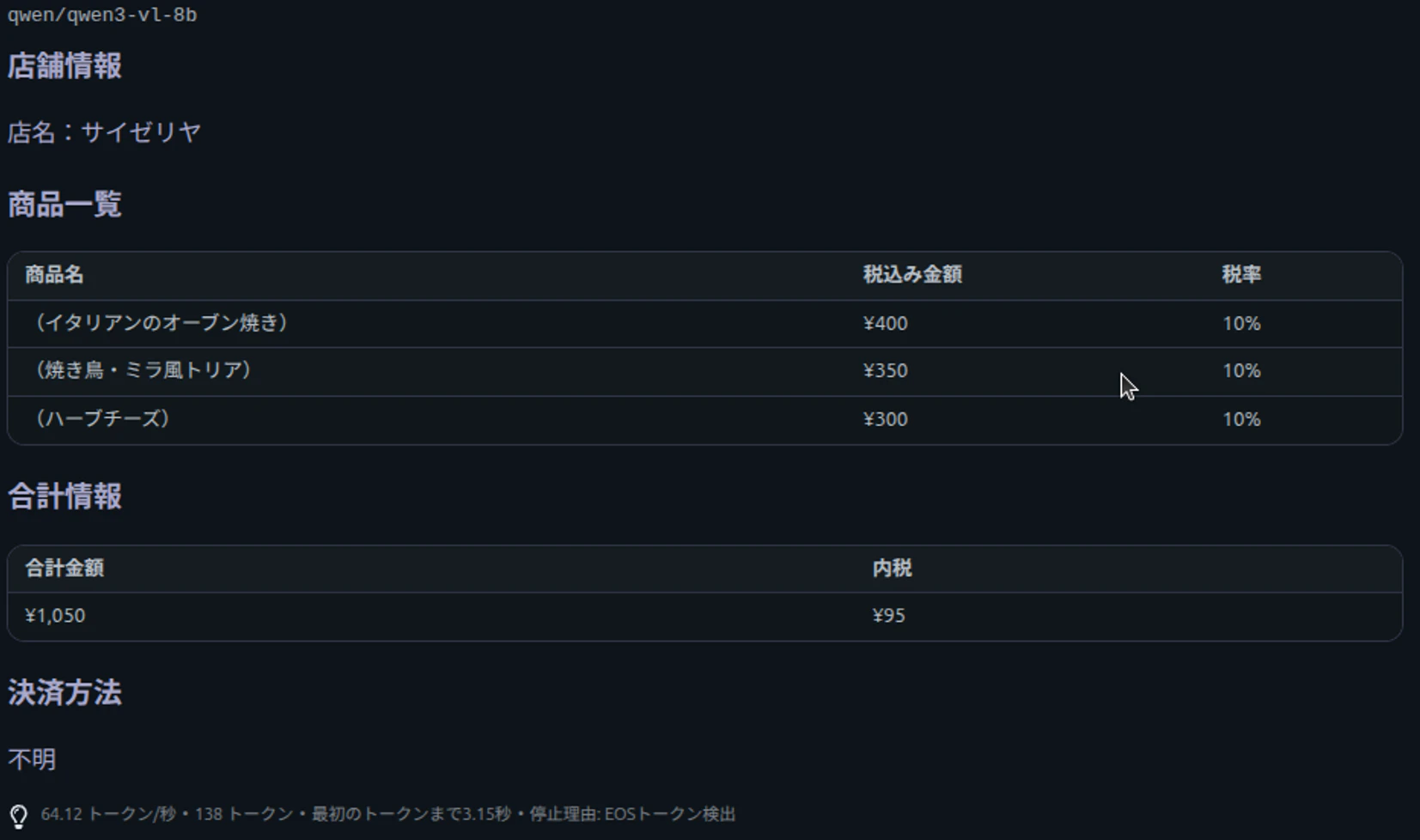
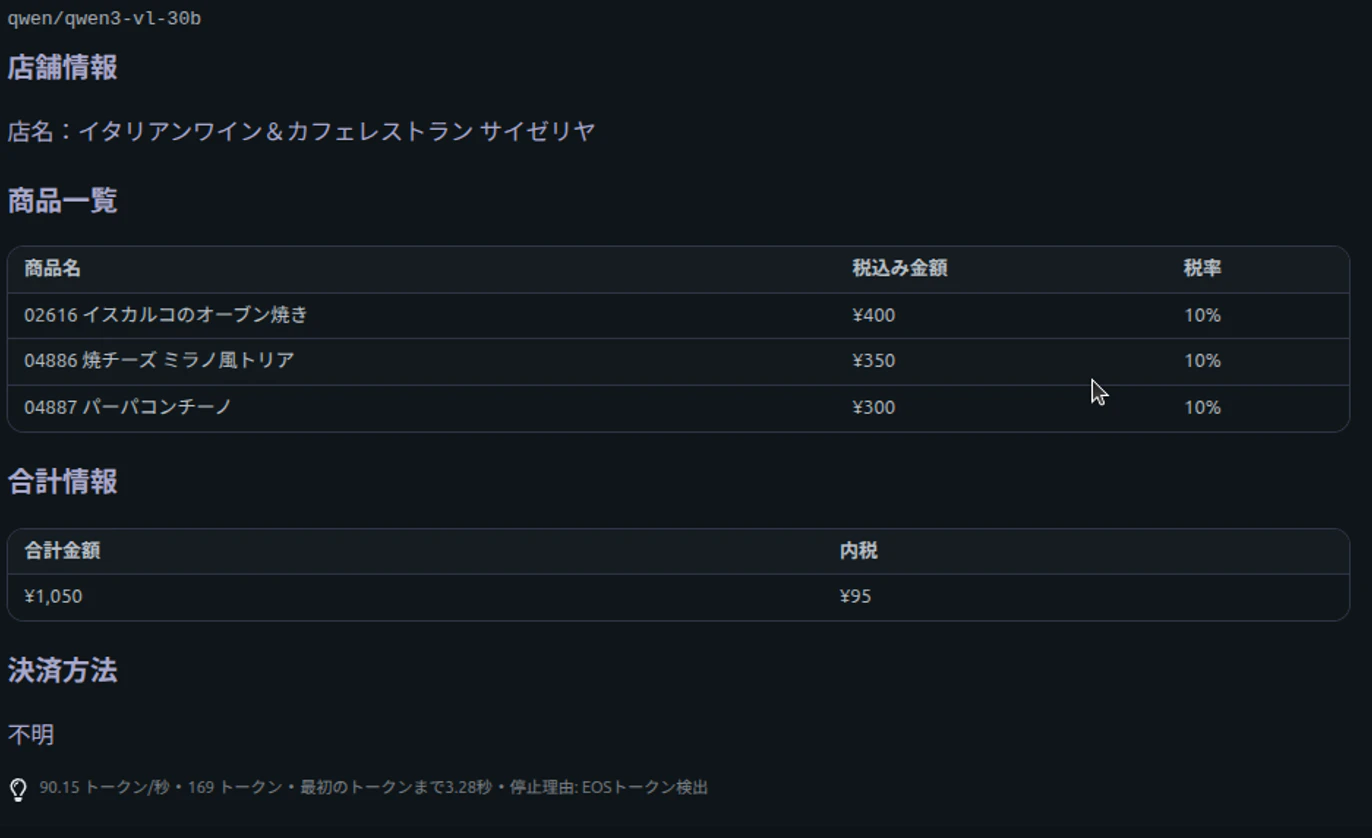
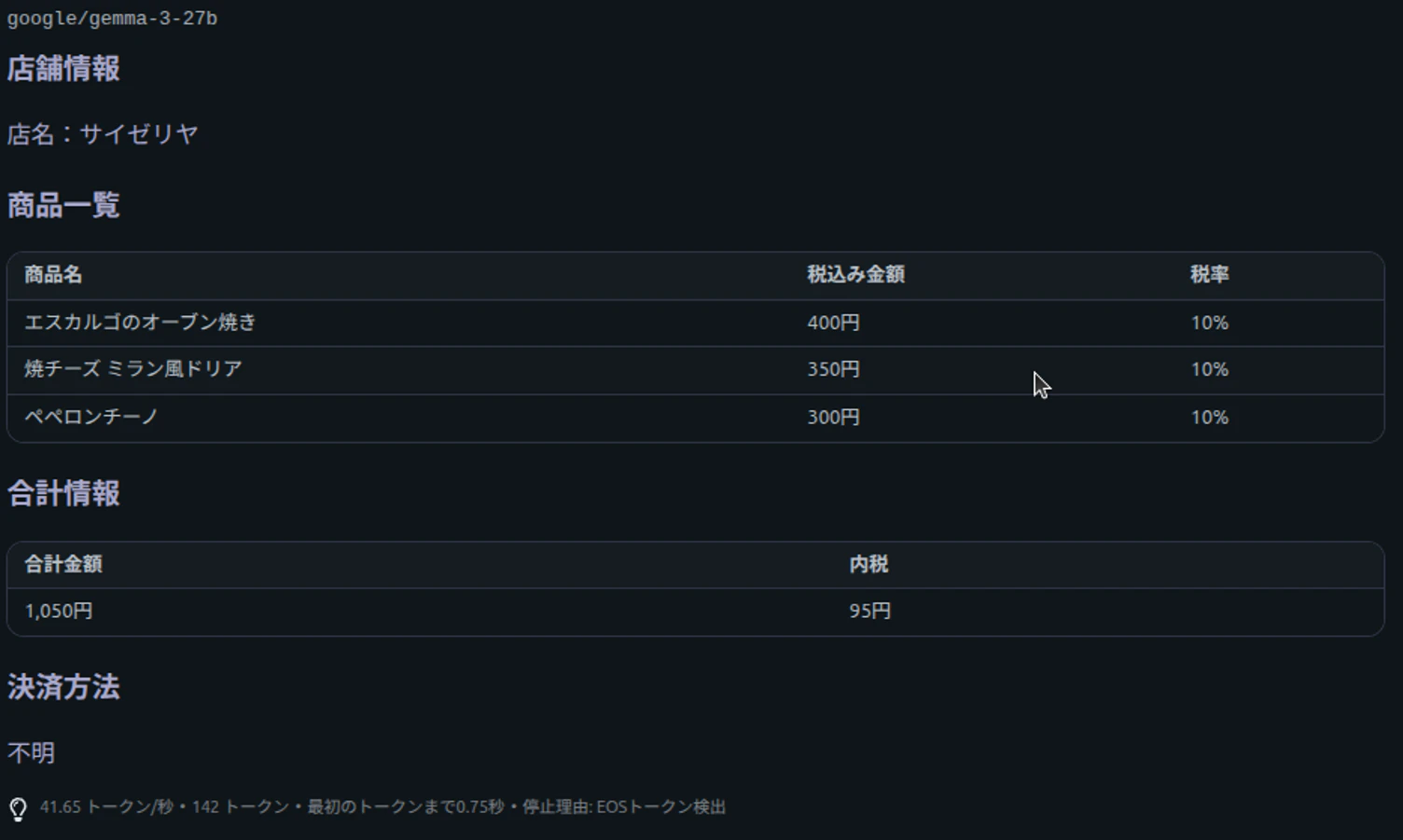
結果を表にまとめました
| 比較項目 | ノートPC | デスクPC |
|---|---|---|
| 主なモデル例 | gemma3n-e4b、qwen3 7B | gemma3 27B、qwen3 30B |
| 精度(コンビニのレシート2) | qwen3:割引の表示が出ず。gemma3:「ベーコン」→「レバーコン」誤読、ただし「値引き」行の生成はレシートに実在(正解) | (該当記載なし)—主にはサイゼリヤで比較 |
| 精度(サイゼリヤのレシート) | 画像サイズが大きく、実行失敗 | gemma3 27B が商品名抽出で優秀。qwen3 30Bはサイズが大きいが精度は劣るケースあり |
| 日本語商品名の抽出 | 軽量モデルでは誤字・誤読が発生しやすい | 日本語での抽出精度は gemma3 27B が優勢(今回の事例) |
| モデルサイズと精度の関係 | 軽量モデルは精度に上限。誤字・脱字が出やすい | サイズが大きくても精度が高いとは限らない(qwen3 30B < gemma3 27B の事例) |
| 処理速度(qwen3 7B) | 約 3 tok/s | 約 64 tok/s(約20倍の高速化) |
| 体感所要時間 | 数分かかることがある | 数秒〜十数秒で完了することが多い |
| 快適さ・運用感 | 「簡単なAI処理は可能」。ただし誤読が目立つ時がある | 専用PC+高性能GPU(RTX 4090)で快適。精度・速度ともに有利 |
考察
結論としては、gemma3n-e4bとqwen3どちらもノートパソコン上で動くモデルとしては高い精度でスキャンできている印象でした。コンビニのレシート2の結果を見ると、qwen3側は割引が表示できていませんでしたが、gemma3側ではベーコンをレバーコンと誤読しており、その点ではマイナスでした。
また、値引きという商品項目をgemma3では生成していましたが、レシート上には値引きの表示があったので正解ではあります。qwenの方はそのような表示がなかったので、その点では優れていました。(金額も値引き前なので合計金額と乖離が出ている。)
一方で、デスクトップで動く高性能モデルを確認してみましたが、今回のサイゼリヤのレシートの結果を見ると明らかにgemma3の27Bモデルが正確に商品名を取り出せていました。qwen3の30Bの方がgemma3の27Bよりも大きなモデルでしたが、結果としては逆転という形でした。レシートが日本語なので日本語に対する性能の差の可能性がありますが、このように単にモデルサイズだけで性能が決まるわけでもないことがわかりました。
実行速度の観点で見ますと、qwen3の7Bにおいてノートパソコンでは3tok/sの処理速度でしたがデスクトップパソコンでは64tok/sと20倍ほどの処理速度が出ていました。RTX4090の素の性能が高いこともありますが、やはり専用のPCの方が実行の快適さでは便利な結果になりました。(実際ノートパソコンだと数分かかることがあるが、デスクトップでは数秒で終わることもあった。)
今回のようにレシートの文字を読み取りその結果を出力できるデモから、すでにノートパソコンでも簡単なAI処理であれば実行できることがわかります。ただし精度に関しては軽量モデルの場合上限があり、どうしても誤字脱字などが起きたりする事例が多いです。ただしノートパソコン上でAIモデルを動かすこと自体は既に可能で、モデルの最適化やPC自体の進化によりローカルで動かせるようになる領域は、今後増えるのではないかと考えました。