はじめに
思い立ったのでおうちで自前画像の画像分類してみました.
ついでに気になったのでMobilenetv2でFine tuningの精度をいろいろ比べてみたのを記事にします.
※おうちPC環境
iMac (Retina 4K, 21.5-inch, 2017)
3.6 GHz クアッドコアIntel Core i7
16 GB 2400 MHz DDR4
忙しい人のためのなんちゃら
・Mobilenetv2でFineTuningいろいろしてみたよ
・犬/猫/鳥の3分類のタスクだよ
・Flickrで画像収集したよ
・FineTuningなし/16,15,14,13,12,11,10,9,8,7,6,5,4,3,2,1層目以降を再学習/全て再学習で精度を比べてみたよ
・今回は14層目以降学習と11層目以降学習が同じ正解率(94.4%)で精度が良かったよ
タスクの設定と画像収集
2値分類だとなんとなくなんでもできちゃいそうだから3値分類,でもわかりやすく結果が出るのがいいから動物の分類やってみたいなと思い,よくやられている「犬」「猫」の分類に「鳥」を付け加えた3値分類やってみることにしました.
そうと決まれば画像の収集です.
ウェブから集めたくてなんかいろいろみてみていたらflickrで集めるのが良さそうだったのでflickrで集めることにしました.
参考にしたのはこちらの記事です.
pythonでflickrから画像データをスクレイピングする方法
115*115サイズの画像を最大500枚まで一度にダウンロードできます.(欲張って1000枚ダウンロードしようとしたら500枚しかできなかった)
「dog」「cat」「bird」を引数にそれぞれ500枚ずつ集めました.
その中から被写体が小さすぎる画像やら人間や他の動物が入っちゃってる画像やらを取り除いて450枚ずつを採用することにしました.
その中から30枚ずつをtest,validationに振り分け,残りの390枚をtrainに使いました.
画像はこんな感じ.PCがかわいい犬まみれです.
以下のような構成のフォルダにそれぞれ画像を振り分けます.
├── data
│ ├── test
│ │ ├── bird
│ │ ├── cat
│ │ └── dog
│ ├── train
│ │ ├── bird
│ │ ├── cat
│ │ └── dog
│ └── val
│ ├── bird
│ ├── cat
│ └── dog
学習とFineTuning
コードはこちら
https://github.com/fu-a-sak/mobilenetv2_keras
FineTuningの層の設定は,いつも参考にさせていただいているこちらのページを参考にしました.
TensorFlow, Kerasで転移学習・ファインチューニング(画像分類の例)
fineTuningしていない学習は学習率0.001始まり,50epoch学習させました.
fineTuningした学習は一律学習率0.0001始まり,30epoch学習させました.
バッチサイズは一律8に,画像は9696にリサイズしています(学習済み重みが9696のものがあるため)
今回Optimizerは論文にならってRMSpropを使っています.(はじめSGDを使っていたけどそれよりRMSpropの方が精度出ました.今回は詳しくやってませんがこの辺比べてみるのも面白いのかも)
以下結果です.
学習曲線とテスト画像での結果のコンフュージョンマトリックスを示します.学習曲線はお恥ずかしながら軸がなんなのか書き忘れてしまったんですけど,縦軸がそれぞれ(正解率とloss)の値,横軸がepoch数です.
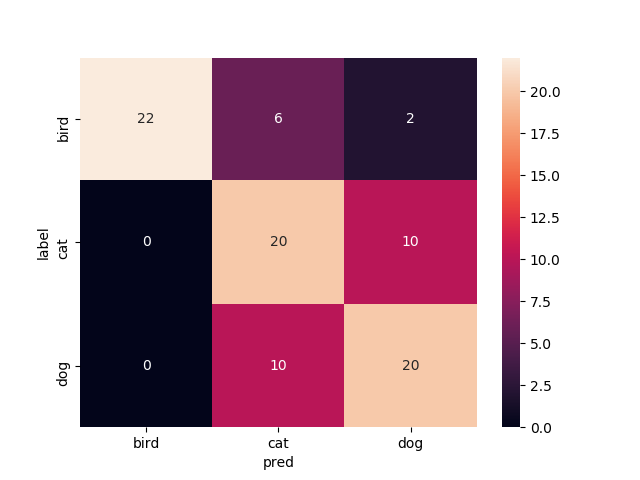
FineTuningなし
Mobilenetv2のweightをNoneで学習させたものです.
いい感じで学習できてますがtrainもvalも正解率が60%前後をうろうろしてます.もうちょっと精度出て欲しいですね
test画像での正解率は68.9%です

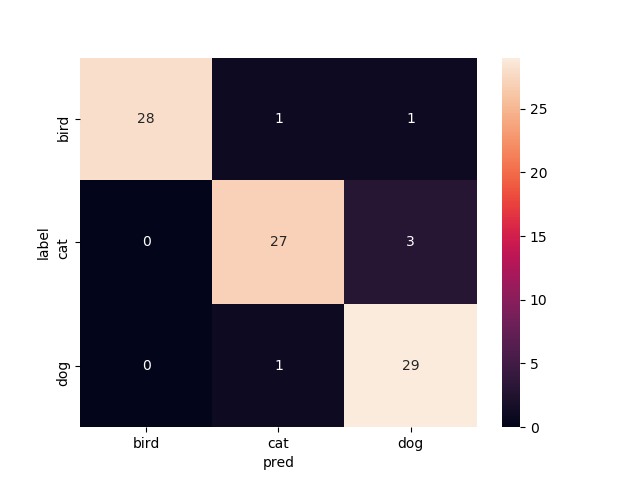
16層目以降を再学習
Mobilenetv2のweightをimagenetにし,16層目以降を再学習させたものです
valの正解率がやたら高いですね.
test画像での正解率は93.3%です

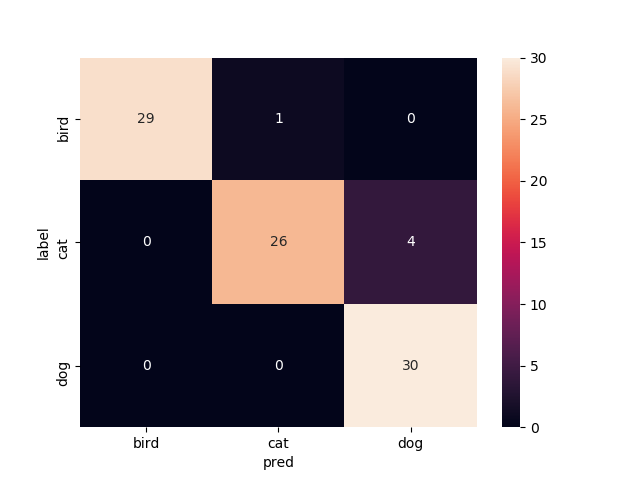
15層目以降を再学習
Mobilenetv2のweightをimagenetにし,15層目以降を再学習させたものです
これまたvalの正解率がやたら高いですね.
test画像での正解率は90.0%です


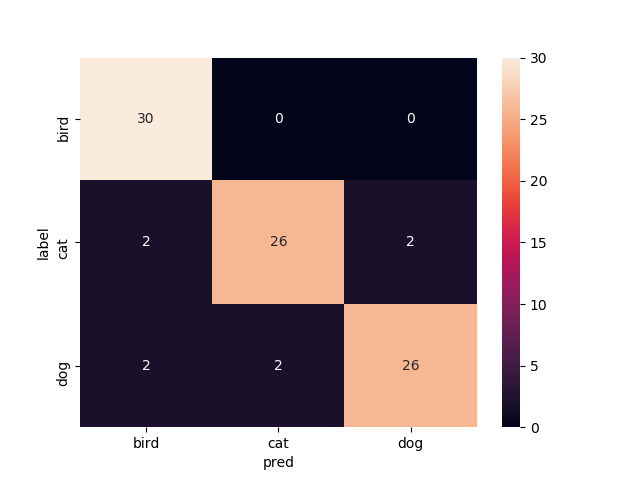
14層目以降を再学習
Mobilenetv2のweightをimagenetにし,14層目以降を再学習させたものです
test画像での正解率は94.4%.いい感じです.

13層目以降を再学習
Mobilenetv2のweightをimagenetにし,13層目以降を再学習させたものです
test画像での正解率は86.7%です.ちょっと下がった?

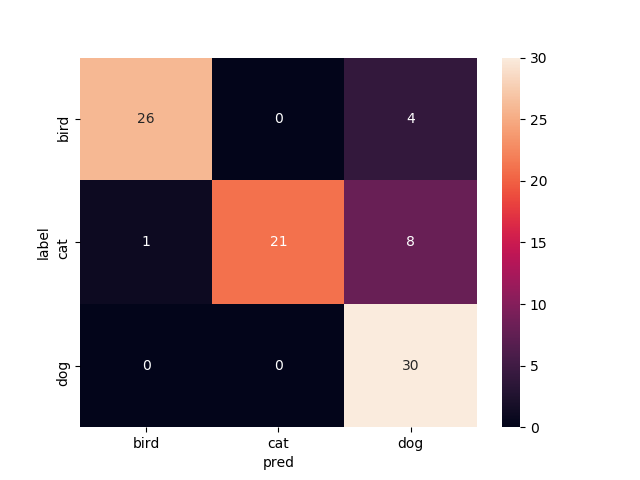
12層目以降を再学習
Mobilenetv2のweightをimagenetにし,12層目以降を再学習させたものです
test画像での正解率は86.6%です

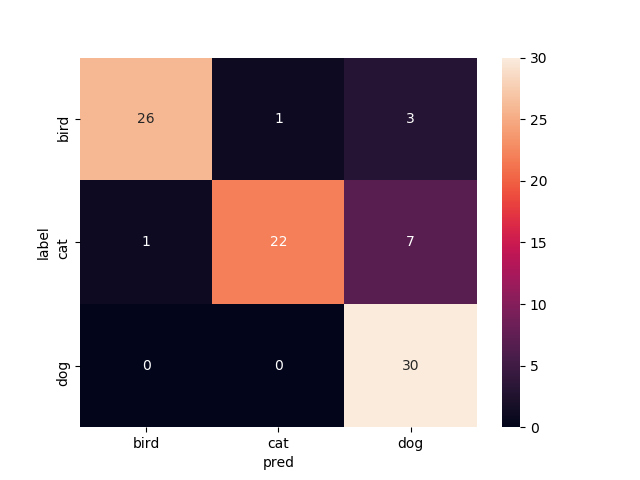
11層目以降を再学習
Mobilenetv2のweightをimagenetにし,11層目以降を再学習させたものです
test画像での正解率は94.4%です.ここに来てまた上がった

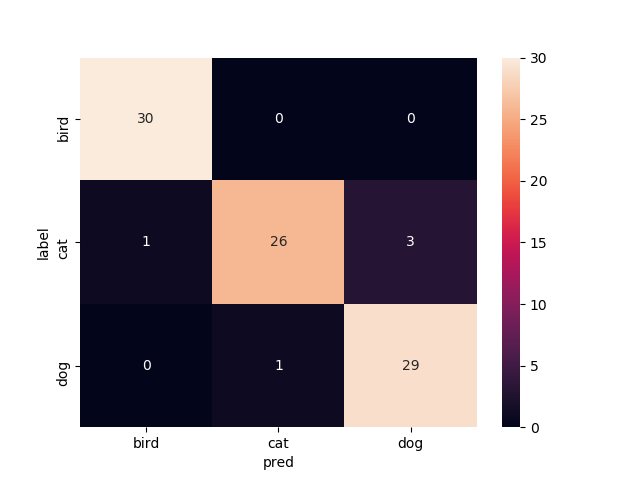
10層目以降を再学習
Mobilenetv2のweightをimagenetにし,10層目以降を再学習させたものです
test画像での正解率は88.9%です

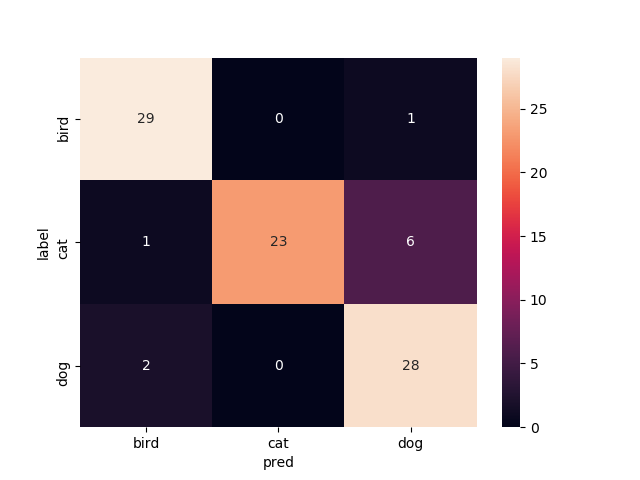
9層目以降を再学習
Mobilenetv2のweightをimagenetにし,9層目以降を再学習させたものです
test画像での正解率は92.2%です

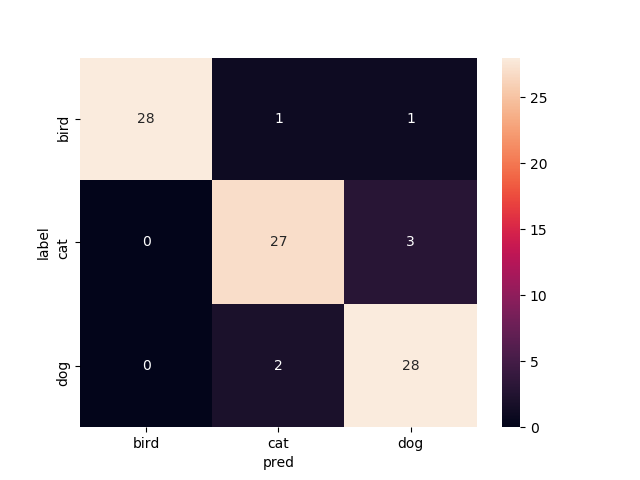
8層目以降を再学習
Mobilenetv2のweightをimagenetにし,8層目以降を再学習させたものです
test画像での正解率92.2%です

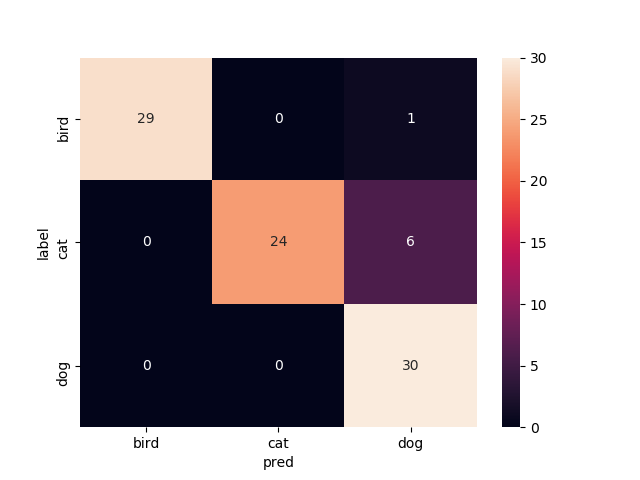
7層目以降を再学習
Mobilenetv2のweightをimagenetにし,7層目以降を再学習させたものです
test画像での正解率は85.6%です

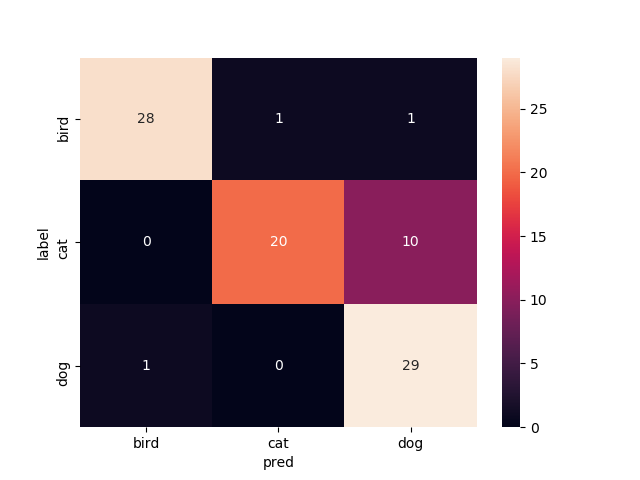
6層目以降を再学習
Mobilenetv2のweightをimagenetにし,6層目以降を再学習させたものです
test画像での正解率は87.8%です

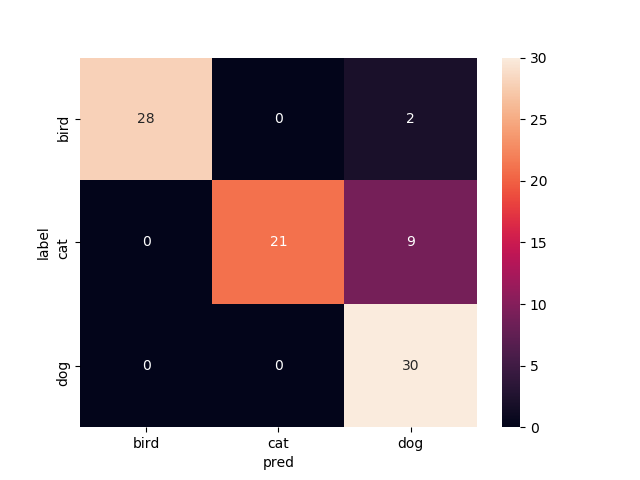
5層目以降を再学習
Mobilenetv2のweightをimagenetにし,5層目以降を再学習させたものです
test画像での正解率は90.0%です

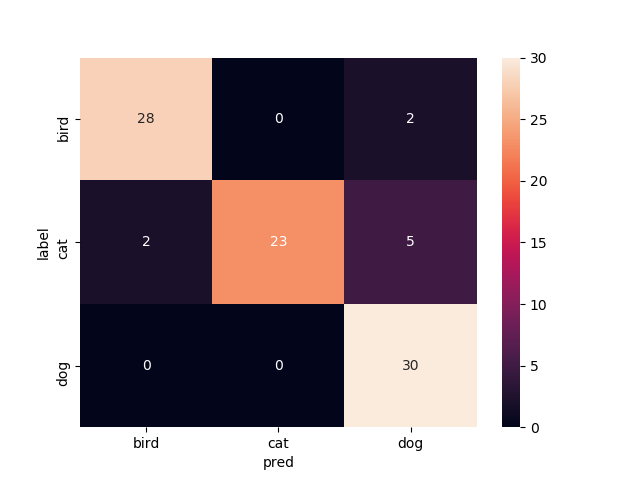
4層目以降を再学習
Mobilenetv2のweightをimagenetにし,4層目以降を再学習させたものです
test画像での正解率は86.7%です


3層目以降を再学習
Mobilenetv2のweightをimagenetにし,3層目以降を再学習させたものです
test画像での正解率は88.9%です

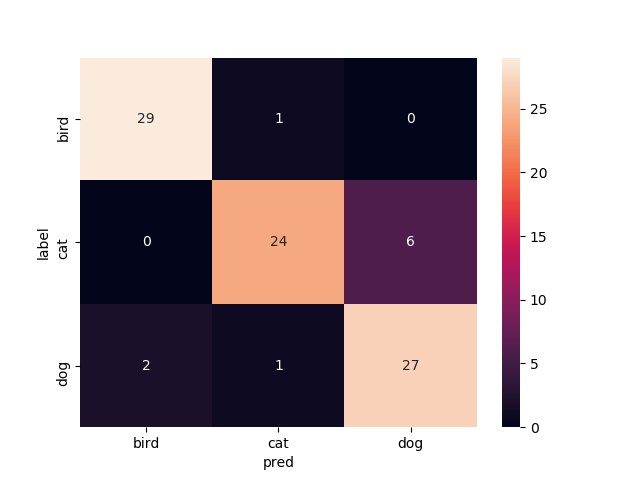
2層目以降を再学習
Mobilenetv2のweightをimagenetにし,2層目以降を再学習させたものです
test画像での正解率は83.3%です

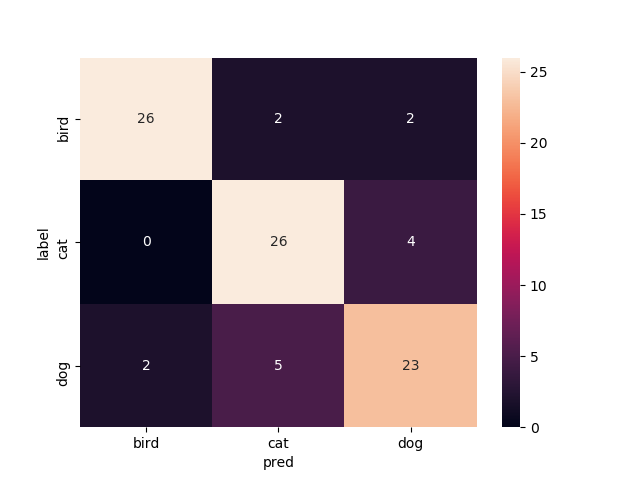
1層目以降を再学習
Mobilenetv2のweightをimagenetにし,1層目以降を再学習させたものです
test画像での正解率は90.0%です

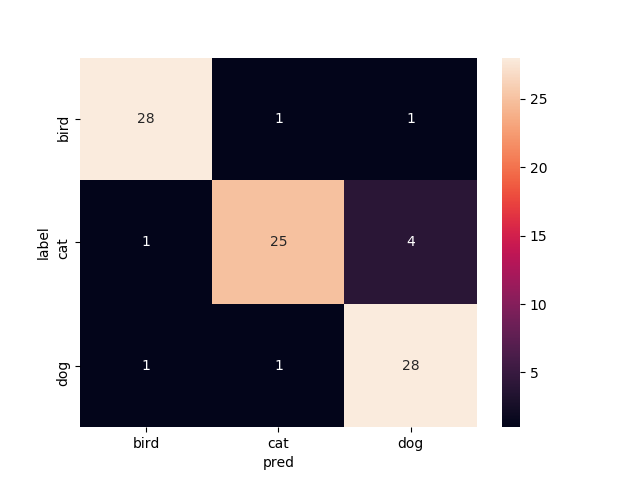
全てを再学習
Mobilenetv2のweightをimagenetにし,どの層もFreezeさせずに学習してみた結果です.
test画像での正解率は91.1%です

まとめ
今回の正解率だけでみると14層目以降再学習と11層目以降再学習が同点(94.4%)で良い,という結果になりました.
なんとなく終わりの層の方だけを再学習させて精度出るのがFineTuningで,前の層の方まで再学習させていくと精度悪くなっていくのかなあと思ってましたがそこまで悪くなんなかったなってのが印象です.
そもそもimagenetの重み使って学習するだけでだいぶ精度が向上するので,そんなに違いがでないってところなのかなあと思ったりしています.
終わりに
正直全部結果載せるのめちゃめんどくさかった...
しかしながらなんとなく,これからは14層目以降再学習のFineTuningをまず試してみようかなという指標はできました.
そういう意味ではやって良かった気がします
休みの日に余力があったらこれをスマホアプリとして実装してみたいなあなんて思っているので,これからもぼちぼちやろうと思います.